Principles of a modern extension compatibility model
If you are an experienced developer in the Visual Studio ecosystem, you’re probably well-acquainted with vsixmanifest files and managing the version ranges in installation targets. Traditionally, each major release of Visual Studio meant updating the upper bound of your supported version range and checking for potential compatibility issues. However, with Visual Studio 2026, this routine has changed - extensions built for Visual Studio 2022 have transferred seamlessly to Visual Studio 2026 without any modifications required. The new extension compatibility model for Visual Studio is guided by three core principles:- Extensions specify the API versions they are built against. Visual Studio evaluates which API versions are supported at load time and only loads extensions compatible with those versions. This represents a shift from the previous approach, where extensions indicated the Visual Studio versions they supported. We understand that there are many parts to what make up the full API set for extending Visual Studio, and we are working on providing a clearer picture going forward.
- The Visual Studio platform aims to minimize or eliminate breaking changes to stable APIs. We understand that Visual Studio 2022 was a disruptive transition for many extension authors with our shift from 32 to 64 bit. Going forward, we commit to a smoother and more streamlined migration process.
- Additive changes will undergo an iterative process prior to being released as stable. As new features are introduced, we will add new APIs to extend these features. However, new APIs require a period of iteration during which modifications and potential breaks may occur. Preview APIs will be made available for evaluation, but extenders should refrain from using them in production extensions due to the possibility of breaking changes.
Impact to Visual Studio 2026 extensions
What does this mean for Visual Studio 2026? Simply put, if you have a Visual Studio 2022 extension, you don’t need to modify it for compatibility with Visual Studio 2026. This is because Visual Studio 2026 supports API version 17.x, and we determine API compatibility using only the lower bound of the installation target version range - ignoring the upper bound from now on. The following example demonstrates an extension that works with Visual Studio 2022, and no updates are necessary if this describes your situation.<InstallationTarget Id="Microsoft.VisualStudio.Community" Version="[17.0, 18.0)">If you use Visual Studio 2026 to create new extensions, you’ll notice that the lower bound will be automatically set to 17.0, with the upper bound left empty, as demonstrated in the example below.
<InstallationTarget Id="Microsoft.VisualStudio.Community" Version="[17.0,)">This means that any new extensions created will now automatically target both Visual Studio 2022 and Visual Studio 2026! Despite the easy migration process, we still recommend that extenders test their extensions on Visual Studio 2026 to catch any compatibility bugs. If you find an issue is likely caused by the platform, please file a feedback ticket using Report a Problem. The smooth migration process for getting extensions in Visual Studio only applies to VSIX-based extensions. Developers who maintain MSI-based extensions are responsible for managing how users install them, and these MSI installers would need to adapt to this updated approach. Our general recommendation is that extension authors do not create MSI installers and just use VSIX to distribute their extensions.
What’s next?
Are you wondering about new APIs that will support extending new features in Visual Studio 2026? These are part of the ongoing additive changes, and we're not ready to release them yet because we are still refining their design. Once they are ready, we'll make them available as preview packages first, allowing interested developers to test them and share feedback. Keep in mind that extensions built with these preview APIs cannot be uploaded to the Marketplace, since breaking changes are likely to impact extension users. As Visual Studio keeps evolving, we are updating every part of extensibility to meet the needs of both extension developers and users. This includes new APIs in VisualStudio.Extensibility, improvements in extension build tooling, Marketplace enhancements, and easier extension acquisition. We’ll share more updates as development progresses.We want to hear from you!
Thank you for sharing your issues and suggestions with us, and we hope you'll keep providing feedback about what you like and what we can improve in Visual Studio. We understand this is a shift in how to think about extension compatibility in Visual Studio, so we are providing an opportunity for interested extension developers to engage with us directly through ecosystem partner calls. If you are interested, please fill out this survey to get on the list. For those new and experienced to extending Visual Studio, we invite you to visit our documentation to learn more, or watch the video series on Visual Studio Toolbox where Visual Studio engineers take you through how to build extensions using our samples on GitHub. Feel free to share feedback with us via Developer Community: report any bugs or issues via report a problem and share your suggestions for new features or improvements to existing ones. If you want a closer engagement with other partners in the ecosystem, please visit our GitHub repo to report issues as well. Stay connected with the Visual Studio team by following us on YouTube, Twitter, LinkedIn, Twitch and on Microsoft Learn.]]>All sales forecasts have this hockey stick shape because the people who do sales forecasts are all optimists.
The Microsoft finance division has their own variation on the hockey stick: The hockey stick on wheels.
Consider a team which presents their forecasts in the form of a hockey stick graph. They come back the next year with their revised forecasts, and they are the same as last year's forecast, just delayed one year. If you overlay this revised hockey stick forecast on top of the previous year's forecast, it looks like what happened is that the hockey stick slid forward one year. When this happens, the finance people jokingly call it a "hockey stick on wheels" because it looks like somebody bolted wheels onto the bottom of the hockey stick graph and is just rolling it forward by one year each year.
Net profit, net profit.
I love ya, net profit.
You're always a year away.
An example of a hockey stick on wheels is the first few years of the infamous Itanium sales forecast chart. Notice that the first four lines are basically the same, just shifted forward by one year. It is only at the fifth year that the shape of the line changes.
]]>{kind=link}
What you can do in Account Throughput
From Account Throughput you can:- View your account’s total provisioned throughput
- Set a custom throughput limit for cost control
- Keep your free-tier account safely within its included RU/s allowance
Where to find it
In the Azure portal, open your Azure Cosmos DB account from the left navigation side bar→ Settings → Account Throughput. This update does not change how the feature works, only where you will find it and what it is called. It remains the same useful tool to help you manage your account’s overall provisioned RU/s more effectively. [cta-button text="Learn more about Account Throughput" url="https://learn.microsoft.com/azure/cosmos-db/limit-total-account-throughput" color="btn-primary"]
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.]]>But what about pifmgr.dll?
The pifmgr.dll file was added in Windows 95. Its job was, as the name might suggest, to manage PIF files, which are Program Information Files that describe how to set up a virtual MS-DOS session for running a specific application.
Whereas the icons in moricons.dll were created with specific programs in mind (list) and the icons in progman.exe were created for general categories of applications, the story behind the icons in pifmgr.dll is much less complicated.
The icons in pifmgr.dll were created just for fun. They were not created with any particular programs in mind, with one obvious exception. They were just a fun mix of icons for people to use for their own homemade shortcut files.
 |
MS-DOS logo |
 |
Umbrella |
 |
Play block |
 |
Newspaper |
 |
Apple with bite |
 |
Cloud with lightning |
 |
Tuba |
 |
Beach ball |
 |
Light bulb |
 |
Architectural column |
 |
Money |
 |
Desktop computer |
 |
Keyboard |
 |
Filing cabinet |
 |
Desk calendar |
 |
Clipped documents |
 |
Crayon with document |
 |
Pencil |
 |
Pencil with document |
 |
Dice |
 |
Window with clouds |
 |
Eye chart with magnifying class |
 |
Dominos |
 |
Hand holding playing cards |
 |
Soccer ball |
 |
Purse |
 |
Decorated tree Wizard's hat with wand |
 |
Race car with checkered flag |
 |
Cruise ship |
 |
Biplane |
 |
Inflatable raft |
 |
Traffic light |
 |
Rabbit |
 |
Satellite dish |
 |
Crossed swords |
 |
Sword and shield |
 |
Flail weapon |
 |
Dynamite and plunger |
I don't know if it was intentional, but I find it interesting that clouds were the theme image for Windows 95, and we have a window with clouds. At the same time we have an apple with a bite, but the bite is on the left hand side, as opposed to the right hand side in the logo of Apple Computer.
Coincidence? Tip of the hat? Subtle jab? You decide.
]]>What Makes This Release Special
After extensive beta testing, we're proud to deliver a stable release that combines performance, intelligence, and developer productivity. The features in this release have been proven in real-world scenarios, including powering some of the most demanding AI workloads in the world.
🚀 Major New Features
Semantic Reranking - AI powered document intelligence (Preview)
One of the most exciting additions is our new Semantic Reranking API, currently a private preview feature that brings AI-powered document reranking directly to your Cosmos DB containers. This feature leverages Azure's inference services to intelligently rank documents based on semantic relevance. If you want to be onboarded to the semantic re-ranking private preview - sign up here. For more information, contact us at CosmosDBSemanticReranker@Microsoft.com. Check out our demo sample here to test drive this, and other powerful semantic search features, in Python for Azure Cosmos DB.
from azure.cosmos import CosmosClient
# Initialize your client
client = CosmosClient(endpoint, key)
container = client.get_database("MyDatabase").get_container("MyContainer")
# Perform semantic reranking
results = container.semantic_rerank(
context="What is the capital of France?",
documents=[
"Berlin is the capital of Germany.",
"Paris is the capital of France.",
"Madrid is the capital of Spain."
],
options={
"return_documents": True,
"top_k": 10,
"batch_size": 32,
"sort": True
}
)
# Results are intelligently ranked by relevance
print(results)
# Output:
# {
# "Scores": [
# {
# "index": 1,
# "document": "Paris is the capital of France.",
# "score": 0.9921875
# },
# ...
# ]
# }
This feature enables you to build more intelligent applications that can understand context and meaning, not just keyword matching. Perfect for RAG (Retrieval-Augmented Generation) patterns in AI applications.
Read Many Items - Optimized Batch Retrieval
The new read_items API revolutionizes how you retrieve multiple documents, offering significant performance improvements and cost savings over individual point reads.
# Define the items you want to retrieve
item_list = [
("item1", "partition1"),
("item2", "partition1"),
("item3", "partition2")
]
# Retrieve all items in a single optimized request
items = list(container.read_items(
items=item_list,
max_concurrency=100
))
# The SDK intelligently groups items by partition and uses
# optimized backend queries (often IN clauses) to minimize
# network round trips and RU consumption
Performance Benefits:
- Reduces network round trips by up to 90%
- Lower RU consumption compared to individual reads
- Intelligent query optimization based on partition distribution
Automatic Write Retries - Enhanced Resilience
Say goodbye to manual retry logic for write operations! The SDK now includes built-in retry capabilities for write operations that encounter transient failures.
# Enable retries at the client level
client = CosmosClient(
endpoint,
key,
connection_policy=ConnectionPolicy(retry_write=1)
)
# Or enable per-request
container.create_item(
body=my_document,
retry_write=1 # Automatic retry on timeouts/server errors
)
What Gets Retried:
- Timeout errors (408)
- Server errors (5xx status codes)
- Transient connectivity issues
Smart Retry Logic:
- Single-region accounts: One additional attempt to the same region
- Multi-region accounts: Cross-regional failover capability
- Patch operations require explicit opt-in due to potential non-idempotency
Enhanced Developer Experience
Client-Level Configuration Options
Custom User Agent: Identify your applications in telemetry:
# Set custom user agent suffix for better tracking
client = CosmosClient(
endpoint,
key,
user_agent_suffix="MyApplication/1.0"
)
Throughput Bucket Headers: Optimize performance monitoring (see here for more information on throughput buckets):
# Enable throughput bucket headers for detailed RU tracking
client = CosmosClient(
endpoint,
key,
throughput_bucket=2 # Set at client level
)
# Or set per request
container.create_item(
body=document,
throughput_bucket=2
)
Excluded Locations: Fine-tune regional preferences:
# Exclude specific regions at client level
client = CosmosClient(
endpoint,
key,
excluded_locations=["West US", "East Asia"]
)
# Or exclude regions for specific requests
container.read_item(
item="item-id",
partition_key="partition-key",
excluded_locations=["Central US"]
)
Return Properties with Container Operations
Streamline your workflows with the new return_properties parameter:
# Get both the container proxy and properties in one call
container, properties = database.create_container(
id="MyContainer",
partition_key=PartitionKey(path="/id"),
return_properties=True
)
# Now you have immediate access to container metadata
print(f"Container RID: {properties['_rid']}")
print(f"Index Policy: {properties['indexingPolicy']}")
Feed Range Support in Queries
Unlock advanced parallel change feed processing capabilities:
# Get feed ranges for parallel processing
feed_ranges = container.get_feed_ranges()
# Query specific feed ranges for optimal parallelism
for feed_range in feed_ranges:
items = container.query_items(
query="SELECT * FROM c WHERE c.category = @category",
parameters=[{"name": "@category", "value": "electronics"}],
feed_range=feed_range
)
Enhanced Change Feed: More flexible change feed processing:
# New change feed mode support for fine-grained control
change_feed_iter = container.query_items_change_feed(
feed_range=feed_range,
mode="Incremental", # New mode support
start_time=datetime.utcnow() - timedelta(hours=1)
)Vector Embedding Policy Management
Enhanced support for AI workloads with vector embedding policy updates:
# Update indexing policy for containers with vector embeddings
indexing_policy = {
"indexingMode": "consistent",
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
# Now you can replace indexing policies even when vector embeddings are present
container.replace_container(
container=container_properties,
indexing_policy=indexing_policy
)
Advanced Query Capabilities
Weighted RRF for Hybrid Search: Enhance your search relevance with Reciprocal Rank Fusion:
# Use weighted RRF in hybrid search queries
query = """
SELECT c.id, c.title, c.content
FROM c
WHERE CONTAINS(c.title, "machine learning")
ORDER BY RRF(VectorDistance(c.embedding, @vector),
FullTextScore(c.content, "artificial intelligence"),
[0.7, 0.3])
"""
items = container.query_items(query=query, parameters=[
{"name": "@vector", "value": search_vector}
])Computed Properties (Now GA)
Computed Properties have graduated from preview to general availability:
# Define computed properties for efficient querying
computed_properties = [
{
"name": "lowerCaseName",
"query": "SELECT VALUE LOWER(c.name) FROM c"
}
]
# Replace container with computed properties
container.replace_container(
container=container_properties,
computed_properties=computed_properties
)
# Query using computed properties for better performance
items = container.query_items(
query="SELECT * FROM c WHERE c.lowerCaseName = 'john doe'"
)
Reliability and Performance Improvements
Advanced Session Management
The SDK now includes sophisticated session token management:
- Automatically optimizes session tokens
- Sends only relevant partition-local tokens for reads
- Eliminates unnecessary session tokens for single-region writes
- Improves performance and reduces request size
Circuit Breaker Support
Enable partition-level circuit breakers for enhanced fault tolerance:
import os
# Enable circuit breaker via environment variable
os.environ['AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER'] = 'true'
# The SDK will automatically isolate failing partitions
# while keeping healthy partitions available
Enhanced Error Handling
More resilient retry logic with cross-regional capabilities.
Monitoring and Diagnostics
Enhanced Logging and Diagnostics
Automatic failover improvements:- Better handling of bounded staleness consistency
- Cross-region retries when no preferred locations are set
- Improved database account call resilience
import logging
from azure.cosmos import CosmosHttpLoggingPolicy # Set up enhanced logging logging.basicConfig(level=logging.INFO) client = CosmosClient( endpoint, key, logging_policy=CosmosHttpLoggingPolicy(logger=logging.getLogger()) )The OpenAI Connection
Many of these features were developed in collaboration with OpenAI, who use Cosmos DB extensively for ChatGPT's data storage needs. This partnership ensures our SDK can handle:
- Massive Scale: Billions of operations per day
- Low Latency: Sub-10ms response times for AI workloads
- High Availability: 99.999% uptime requirements
- Global Distribution: Seamless worldwide data replication
When you use the Python SDK for Azure Cosmos DB, you're leveraging the same technology that powers some of the world's most advanced AI applications.
Real-World Impact
Performance Benchmarks
Based on testing with synthetic workloads:
- Read Many Items: Up to 85% reduction in latency for batch retrieval scenarios
- Write Retries: 99.5% reduction in transient failure impact
- Session Optimization: 60% reduction in session token overhead
- Circuit Breaker: 90% faster recovery from partition-level failures
Cost Optimization
- Reduced RU Consumption: Batch operations can reduce costs by up to 40%
- Fewer Network Calls: Significant bandwidth savings in high-throughput scenarios
- Optimized Retries: Intelligent retry logic prevents unnecessary RU charges
Breaking Changes (Important!)
If you have been using the beta versions of Python SDK (since the last stable version 4.9.0) there is one breaking change:Changed retry_write Parameter Type
# Before (4.13.x and earlier)
retry_write = True # boolean
# After (4.14.0)
retry_write = 3 # integer (number of retries)
This change aligns with other retry configuration options and provides more granular control.
Migration Guide
Upgrading from any beta higher than 4.9.0 to 4.14.0
-
Update your dependencies:
pip install azure-cosmos==4.14.0 -
Update retry_write usage (if applicable):
# Old way client = CosmosClient(endpoint, key, retry_write=True) # New way client = CosmosClient(endpoint, key, retry_write=3) -
Leverage new features (optional but recommended):
-
Take advantage of read_items for batch operations
-
Enable automatic write retries for resilience
-
Use return_properties to reduce API calls
-
What's Next?
This release establishes the foundation for even more exciting AI-focused features coming in future versions:
- Enhanced vector search capabilities
- Advanced semantic search integration
- Expanded AI inference service integrations
- Performance optimizations for RAG patterns
Additional Resources
- Full Changelog - Complete list of changes including bug fixes since 4.9.0
- SDK Documentation - Comprehensive API reference
- Sample Code - Working examples for all new features
- Migration Guide - Step-by-step upgrade instructions
Get Involved
Have feedback or questions? We'd love to hear from you!
- GitHub Issues: Report bugs or request features
- Stack Overflow: Tag your questions with
azure-cosmosdbandpython - Documentation: Contribute to our docs
Ready to upgrade? Install Azure Cosmos DB Python SDK v4.14.0 today and experience the power of AI-enhanced database operations!
pip install --upgrade azure-cosmos==4.14.0
The future of AI-powered applications starts with the right data foundation. With the latest Cosmos DB Python SDK, you have the tools to build intelligent, scalable, and resilient applications that can handle anything the world throws at them.
]]>
Illustrations of some of dogs' breeds images presented on the dataset.
We’ll use the Vision Fine-Tuning API and compare the results to a lightweight CNN baseline, so you can see the impact of modern Vision-Language Models versus traditional approaches. You’ll learn how to:- Prepare your data
- Run batch inference
- Fine-tune the model
- Evaluate metrics
- Weigh cost and latency trade-offs
What Is Image Classification and Why Is It Useful?
Computer Vision has been a key field of Artificial Intelligence / Machine Learning (AI/ML) for decades. It enables many use-cases across various industries with tasks such as Optical Character Recognition (OCR) or image classification. Let’s focus on image classification, it can enable filtering, routing, and you might already using it on your daily applications without noticing. The backbone of these models has been heavily based on Convolutional Neural Network (CNN) architecture and has been there since 1998 (LeNet). Since 2017 and the arrival of Large Language Models (LLMs), the field of AI/ML has completely evolved, leveraging new capabilities and enabling plenty of exciting use-cases. One of the latest capabilities of these models has been the introduction of vision (image / video) input in addition to text. This new type of Vision Language Model (VLM) like latest GPT-5 models from OpenAI, aims to not only generate text from an input but understand vision input to generate text. This has democratized access to computer vision while achieving great performance as these models have been trained on a large corpus of data, covering plethora of topics. Now, anyone can access to a VLM via a consumer app (e.g., ChatGPT, Le Chat, Claude) or via an API, upload an image (e.g., a picture of your dog), type the task you want the model to perform (e.g., “what is the dog’s breed in the picture?”) and run it.Getting Started: Choosing and Deploying Your Vision-Language Model on Azure
Azure AI Foundry lets you choose from thousands of models of any type (LLM, Embeddings, Voice) from our partners such as OpenAI, Mistral AI, Meta, Cohere, Hugging Face, etc. In this post, we’ll select Azure OpenAI GPT-4o (2024-08-06 model version) as our base model. This is also one of the models which supports both:- Azure OpenAI Batch API (batch inference for half the price)
- Azure OpenAI Vision Fine-Tuning API (teach base model to perform better or learn a new specific task)
Step 1: Run Cost-Effective Batch Inference with Azure OpenAI
Let’s measure performance of the GPT-4o on the Stanford Dogs Dataset. This dataset contains thousands of dogs’ images across 120 breeds. For the sake of cost management, we’ll down sampled this dataset and only keep 50 images per breed with the following split: 40 train / 5 validation / 5 test. With the following ratio, our dataset contains:- Train set (4,8k images)
- Validation set (600 images)
- Test set (600 images)
{"model": “gpt-4o-batch”,
"messages": [
{"role": "system", "content":"Classify the following input image into one of the following categories: [Affenpinscher, Afghan Hound, ... , Yorkshire Terrier]." },
{"role": "user", "content":
[ {"type": "image_url", "image_url": {"url": "b64", "detail": "low"}} ]} ]}- model deployment name (here a gpt-4o 2024-08-06 deployed for batch inference)
- system message (here is the image classification task described with list of potential breeds)
- user input (here is the dog’s image encoded in base64, with low detail resolution to be cost effective)
After having waited 15 minutes, the Batch API returned an output JSONL that contains for each line the model’s response.
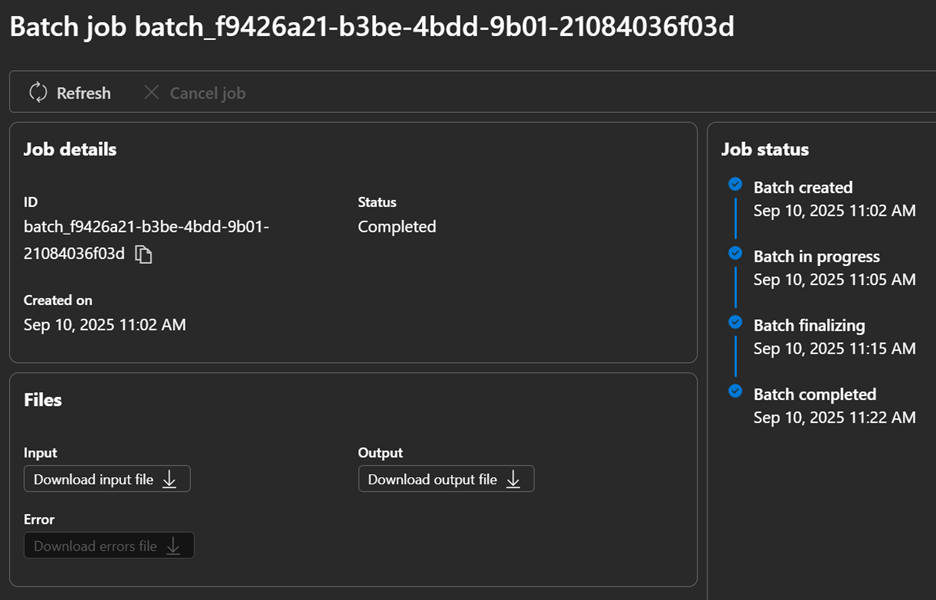
Azure AI Foundry Batch job details.
Now, let’s extract the Batch API output response and compute the performance of the base model against the test set that will become our baseline.Step 2: Fine-Tune GPT-4o for Your Images Using the Vision API
Fine-Tuning aims to post-train the model with new data that hasn’t been used during its initial training to make the model learn new knowledge, improve performance on certain tasks, or emphasis on a specific tone. This process can lead to better performance, decreasing latency and may be cost-effective as you might send less tokens to the fine-tuned model to set its guidelines.
Azure OpenAI enables Fine-Tuning among different models and with different alignment techniques such as Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO) and Reinforced Fine-Tuning (RFT).
In 2024, we introduced Vision Fine-Tuning, that takes image and text as inputs and passes over following hyperparameters which you can control (epochs, batch size, learning rate multiplier, etc.).
Fine-tuning job pricing differs from base model inference due to couple of factors:
This process can lead to better performance, decreasing latency and may be cost-effective as you might send less tokens to the fine-tuned model to set its guidelines.
Azure OpenAI enables Fine-Tuning among different models and with different alignment techniques such as Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO) and Reinforced Fine-Tuning (RFT).
In 2024, we introduced Vision Fine-Tuning, that takes image and text as inputs and passes over following hyperparameters which you can control (epochs, batch size, learning rate multiplier, etc.).
Fine-tuning job pricing differs from base model inference due to couple of factors:
- total tokens used during training job (number of tokens in the train/validation datasets multiplied by number of epochs)
- endpoint hosting (priced per hour)
- inference (input/outputs tokens)
{"messages": [
{"role": "system", "content": "Classify the following input image into one of the following categories: [Affenpinscher, Afghan Hound, ... , Yorkshire Terrier]."},
{"role": "user", "content":
[{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,<encoded_springer_spaniel_image_in_base64>", "detail": "low"}}]},
{"role": "assistant", "content": "Springer Spaniel"}
]}- Batch size: 6 (how many examples are processed per training step)
- Learning rate: 0.5 (adjusts how quickly the model learns during training)
- Epochs: 2 (number of times the model trains on the entire dataset)
- Seed: 42 (ensures training results are reproducible when using the same settings)

Azure AI Foundry Fine-Tuning job details
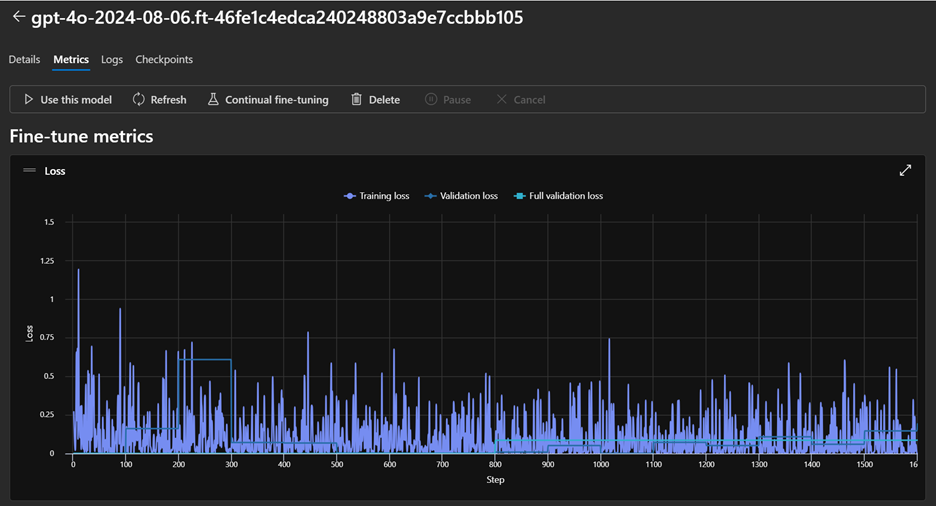
Azure AI Foundry Fine-Tuning job metrics
Step 3: Compare Against a Classic CNN Baseline
To provide another reference point, we trained a lightweight Convolutional Neural Network (CNN) on the same subset of the Stanford Dogs dataset used for the VLM experiments. This baseline is not meant to be state-of-the-art; its role is to show what a conventional, task-specific model can achieve with a relatively small architecture and limited training, compared to a large pre-trained Vision-Language Model. This baseline reached a mean accuracy of 61.67% on the test set (see the Comparison section below for numbers alongside GPT-4o base and fine-tuned). It trained in less than 30 minutes and can easily run locally or in Azure Machine Learning.Results at a Glance: Accuracy, Latency, and Cost
After having run our experimentations, let’s compare these 3 models (base VLM, fine-tuned VLM, lightweight CNN) on key metrics such as accuracy, latency and cost. Find below a table that consolidates these metrics.| Aspect | Base gpt-4o (zero-shot) | Fine-Tuned gpt-4o | CNN Baseline |
| Mean accuracy (more is better) | 73.67% | 82.67% (+9.0 pp vs base) | 61.67% (-12.0 pp vs base) |
| Mean latency (less is better) | 1665ms | 1506ms (-9.6%) | — (not benchmarked here) |
| Cost (less is better) | Inference costs only $$ | Training + Hosting + Inference $$$ | Local infra $ |
Accuracy
The fine-tuned GPT-4o model achieved a substantial boost in mean accuracy, reaching 82.67 % compared to 73.67 % for the zero-shot base model and 61.67 % for the lightweight CNN baseline. This shows how even a small amount of domain-specific fine-tuning on Azure OpenAI can significantly close the gap to a specialized classifier.
Latency
Inference with the base GPT-4o took on average 1.67 s per image, whereas the fine-tuned model reduced that to 1.51 s (around 9.6 % faster). This slight improvement reflects better task alignment. The CNN baseline was not benchmarked for latency here, but on commodity hardware it typically returns predictions in tens of milliseconds per image, which can be advantageous for ultra-low-latency scenarios.
Cost
Using the Azure OpenAI Batch API for the base model only incurs inference costs (at a 50 % discount vs. synchronous calls). Fine-tuning introduces additional costs for training and hosting the new model plus inference, but can be more economical in the long run when processing very large batches with higher accuracy. Here, the fine-tuning training job has costed $152 and inference is 10% more expensive than the base model across input, cached input, and output. The CNN baseline can be hosted locally or on inexpensive Azure Machine Learning compute; it has low inference cost but requires more effort to train and maintain (data pipelines, updates, and infrastructure).Key takeaways
Across all three models, the results highlight a clear trade-off between accuracy, latency, and cost.- Fine-tuning GPT-4o on Azure OpenAI produced the highest accuracy while also slightly reducing latency.
- The zero-shot GPT-4o base model requires no training and is the fastest path to production, but with lower accuracy.
- The lightweight CNN offers a low-cost, low-infrastructure option, yet its accuracy lags far behind and it demands more engineering effort to train and maintain.
Next Steps: How to Apply This in Your Own Projects
This walkthrough demonstrated how you can take a pre-trained Vision-Language Model (GPT-4o) on Azure AI Foundry, fine-tune it with your own labeled images using the Vision Fine-Tuning API, and benchmark it against both zero-shot performance and a traditional CNN baseline. By combining Batch API inference for cost-efficient evaluation with Vision Fine-Tuning for task-specific adaptation, you can unlock higher accuracy and better latency without building and training large models from scratch. If you’d like to access more insights on the comparison, replicate or extend this experiment, check out the GitHub repository for code, JSONL templates, and evaluation scripts. From here, you can:- Try other datasets or tasks (classification, OCR, multimodal prompts).
- Experiment with different fine-tuning parameters.
- Integrate the resulting model into your own applications or pipelines.
Learn More
▶️Register for Ignite’s AI fine-tuning in Azure AI Foundry to make your agents unstoppable 👩💻Explore fine-tuning with Azure AI Foundry documentation 👋Continue the conversation on Discord]]>What is Azure Advisor?
Azure Advisor is your cloud optimization assistant. It analyzes your Azure resources and configurations, then delivers personalized, actionable recommendations to help you:- Improve performance
- Enhance security
- Boost reliability
- Reduce costs
How Does Azure Advisor Help Cosmos DB Users?
Whether you’re new to Azure Cosmos DB or an experienced developer, Azure Advisor provides guidance in four key areas:- High Availability: Suggestions for geo-redundancy and disaster recovery.
- Security: Alerts for tightening network security rules.
- Performance: Tips like increasing throughput to avoid throttling.
- Cost Optimization: Recommendations to right-size resources and reduce spending.
Best Practices for using Azure Advisors
- Proactive Monitoring: Set up live alerts and availability scorecards to stay ahead of issues. Azure Advisor’s recommendations are embedded in the portal, making it easy to act on guidance without leaving your Azure Cosmos DB experience.

- Integrated Experience: Using the new Cosmos DB Account Overview Hub in Azure portal, you get a view of all the recommendations.

Next Steps
The recommendations are built on Azure Well Architected Framework and are tailored to your workload, helping you get the most out of Azure Cosmos DB. Start exploring the recommendations you have today.⭐Leave a review
Tell us about your Azure Cosmos DB experience! Leave a review on PeerSpot and we’ll gift you $50. Get started here.☁️About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn. ]]>🔄What’s changing
Until now, configuring Dev Box pools with Azure Marketplace images or custom images from Compute Galleries required a pre-defined Dev Box definition at the Dev Center. These definitions packaged the image along with compute and storage SKUs, and were then referenced by project-level pools. While this model provided centralized control, it also introduced friction:- Creating Dev Box definitions was a separate prerequisite step
- Every change in image or SKU required definition updates at the Dev Center
- Definitions were visible to all projects tied to the Dev Center, limiting project-specific guardrails

🛡️Built on project policies
This new experience builds on project policies, which allow platform engineers to define:- Which images a project can use
- Which compute and storage SKUs are permitted
- Which networks can be leveraged
- Platform teams define the guardrails
- Project teams configure environments within those boundaries
🧰 Leverage in-built customizations and imaging
This new capability enhances image-based configuration, and Dev Box continues to support powerful team customizations and Dev Center imaging capabilities that let you pre-configure dev boxes tailored to your team's needs. These in-built capabilities allow you to:- Pre-configure all the required tools, packages, dependencies, and policies that reflect your team’s needs
- Build custom images to flatten the configured customizations
- Create ready-to-code, project-specific Dev Boxes tailored to each developer scenario
💡Why it matters
By enabling direct configuration of pools using images and SKUs, this change unlocks:- Streamlined setup — skip the Dev Box definition step
- Faster onboarding — spin up new project environments quickly
- Granular controls — enforce per-project policies for SKUs, images, and networks
- Reduced overhead — simplify lifecycle management across projects
✅Our recommendation
We recommend taking full advantage of this new configuration model. By managing your guardrails through project policies and configuring pools directly with images or SKUs, you’ll get the best of both worlds: enterprise-grade control and team-level agility. Check out our step-by-step documentation to directly configure Dev Box pools with images and SKUs—no Dev Box definitions required. As always, we’d love to hear your feedback. Your input helps us shape the future of Dev Box.]]>This plan requires that the function that accepts the callback lambda never tries to copy the lambda, because our RAII type is not copyable. (If it were copyable, the one-time action will get executed twice, once when the original and destructs, and once when the copy destructs.) But what if the function requires a copyable lambda?
void MySpecialFeature::OnButtonClick()
{
auto ensureDismiss = wil::scope_exit([self = shared_from_this()]
{ self->DismissUI(); });
try {
auto folder = PickOutputFolder();
if (!folder) {
return;
}
if (ConfirmAction()) {
if (m_useAlgorithm1) {
// StartAlgorithm1 invokes the lambda when finished.
StartAlgorithm1(file,
[ensureDismiss = std::move(ensureDismiss)] { });
} else {
RunAlgorithm2(file);
}
}
} catch (...) {
}
}
Suppose that you get an error somewhere inside the call to StartAlgorithm1 because it tries to copy the non-copyable lambda. How can you make the lambda copyable while still getting the desired behavior of cleaning up exactly once, namely when the lambda is run?
Start by wrapping the RAII type inside a shared_ptr:
// StartAlgorithm1 invokes the lambda when finished.
StartAlgorithm1(file, [ensureDismiss =
std::make_shared<decltype(ensureDismiss)>(move(ensureDismiss))]
{ ⟦ ... ⟧ });
There's a bit of repetitiveness because shared_ does not infer the wrapped type if you are asking to make a shared_ by move-constructing from an existing object, so we have to write out the decltype(ensureDismiss).
Inside the body, we reset the RAII type, which calls the inner callable. Since all of the copies of the lambda share the same RAII object, the reset() call performs the cleanup operation on behalf of everybody.
// StartAlgorithm1 invokes the lambda when finished.
StartAlgorithm1(file, [ensureDismiss =
std::make_shared<decltype(ensureDismiss)>(move(ensureDismiss))]
{ ensureDismiss->reset(); });
In the weird case that all of the copies of the lambda are destructed without any of them ever being called, then when the final one destructs, it will destruct the RAII object, which will run the cleanup operation if it hasn't been done yet.
]]>- Automated onboarding for ISV & MAICPP partners: We’ve streamlined and automated the onboarding experience for eligible MAICPP and ISV partners! Now, developers can request their developer sandbox directly from the Microsoft 365 Developer Program portal using their corporate email ID. Eligible members will see ‘Set up E5 subscription’ right on their dashboard to request the sandbox, no manual steps required. This makes getting started faster and smoother than before.

- Support for Microsoft 365 Copilot license purchases: All new Developer Program eligible members will receive sandboxes that support add on license purchases including Microsoft 365 Copilot directly within their environment, with rollout planned around Microsoft Ignite 2025 (November 18-21). This means developers can now experiment, build, and test Microsoft 365 Copilot extensions in a real, production-like setup. They will have full flexibility to configure their tenant, connect data sources, and bring their Copilot scenarios to life, all within the Developer Program sandbox. Once the initial rollout is complete, later this year, existing program members will also be able to get access to commercially enabled sandboxes.
- Visual Studio subscription linking: In response to your feedback, we’re introducing a new self-service capability that lets developers link a new Visual Studio subscription to their existing Developer Program tenant. This is especially useful if your previous visual studio subscription has expired. This will prevent your sandbox from being deleted and ensure uninterrupted access to your environment.

- Microsoft 365 Copilot Starter Pack: We’re also excited to announce a new Starter Pack, designed to help you build your first Microsoft 365 Copilot extension, in matter of some minutes. The starter pack will automatically install all the prerequisites needed for Microsoft 365 Copilot extensibility development, giving you a ready-to-use environment and saving valuable setup time.