RULE BASED CLASSIFICATION
Rule-Based Classification
Model Rules
Set of IF-THEN rules
IF age = youth AND student = yes THEN
buys_computer = yes
Rule antecedent/precondition vs. rule consequent
Assessment of a rule: coverage and accuracy
ncovers = # of tuples covered by R
ncorrect = # of tuples correctly classified by R
coverage(R) = ncovers /|D| /* D: training data set
*/
accuracy(R) = ncorrect / ncovers
Rule Accuracy and Coverage
If-Then Rules
Rule Triggering
Input X satisfies a rule
Several rules are triggered Conflict Resolution
Size Ordering
Highest priority to toughest (rule antecedent
size) rule
Rule Ordering
Rules are prioritized before-hand
Class based ordering
Rules for most prevalent class comes first
or based on mis-classification cost / class
Rule-based ordering
Rule Quality based measures
Ordered list Decision list Must be
processed strictly in order
No rule is triggered Default rule
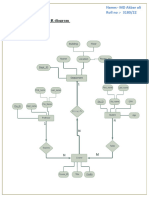
�Rule Extraction from a Decision Tree
Example: Rule extraction from the buys_computer
decision-tree
IF age = young AND student = no THEN
buys_computer = no
IF age = young AND student = yes THEN
buys_computer = yes
IF age = mid-age THEN buys_computer = yes
IF age = old AND credit_rating = excellent THEN
buys_computer = yes
IF age = young AND credit_rating = fair THEN
buys_computer = no
Set of extracted rules very high
Pruning may be required
Rule Generalization For a given rule
antecedent any condition that does not improve
the estimated accuracy can be dropped
Side-effects of pruning
Mutually Exclusive? / Exhaustive?
C4.5 Class Ordering for Conflict resolution
All rules for a single class are grouped
together
Class rule sets are ranked to minimize falsepositive errors
Default class one that contains most training
tuples not covered by any rule
Rule Extraction from the Training Data
Sequential covering algorithm: Extracts rules
directly from training data
Associative Classification Algorithms may also
be used
Typical sequential covering algorithms: FOIL (First
Order Inductive Learner), AQ, CN2, RIPPER
Rules are learned sequentially, each rule for a given
class Ci will cover many tuples of Ci but none (or
few) of the tuples of other classes
Steps:
Rules are learned one at a time
Each time a rule is learned, the tuples covered by
the rules are removed
The process repeats on the remaining tuples
unless termination condition, e.g., when no more
training examples or when the quality of a rule
returned is below a user-specified threshold
Algorithm: Sequential Covering
Input: D, Att_vals
Output: If-Then rules
Method:
Rule_set = {}
For each class c do
Repeat
Rule = Learn_One_Rule(D, Att_vals, c) //
Finds best rule for given class
Remove tuples covered by Rule from D
Until terminating condition
Rule_set = Rule_set + Rule
End for
Return Rule_Set
Start with the most general rule possible: condition =
empty
Adding new attributes by adopting a greedy depthfirst strategy
Picks the one that most improves the rule quality
Example:
Start with IF _ THEN loan_decision = accept
Consider IF loan_term=short THEN.. / IF
loan_term=long THEN.. / IF income = high
THEN.. / IF income = medium THEN.. /
If best one is IF income = high THEN
loan_decision = accept expand it further
Rule Quality measures
Coverage or Accuracy independently will not be
sufficient
Rule-Quality measures: consider both coverage and
accuracy
Foil-gain (in FOIL & RIPPER): assesses
info_gain by extending condition
It favors rules that have high accuracy and cover
many positive tuples
R Existing rule; R Extended rule
Likelihood Ratio Statistic
m
Likelihood_Ratio = 2 i=1
fi log(fi/ei)
Greater this value higher the significance
Rule pruning based on an independent set of test
tuples
Pos/neg are # of positive/negative tuples covered
by R.
If FOIL_Prune is higher for the pruned version of
R, prune R