0% found this document useful (0 votes)
172 views463 pagesHow To Solve by Computer
Uploaded by
Simon KardusCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF or read online on Scribd
0% found this document useful (0 votes)
172 views463 pagesHow To Solve by Computer
Uploaded by
Simon KardusCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF or read online on Scribd
/ 463
PRENTICE-HALL
INTERNATIONAL
SERIES IN
OMPUTER
SCIENCE
R.G. Dromey
How fo Solve it
by Computer
C.A.R. HOARE SERIES EDITOR
HOW TO SOLVE IT
BY COMPUTER
by
R. G. DROMEY
Department of Computing Science
The University of Wollongong
ENGLEWOOD CLIFFS, NEW JERSEY LONDON NEW DELHI
SINGAPORE SYDNEY TOKYO TORONTO = WELLINGTON
Library of Congress Cataloging in Publication Data
DROMEY,R.G. —1946-
How to Solve it by Computer.
Bibliography: p.
Includes index
1, Mathematics—Data processing
2. Problem solving—Data processing
2. Electronic digital computers—Programming
1. Title,
QA76.95.D76 519.4 81-19164
ISBN 0-13-433995.9 AACR2
ISBN 0-13-434001-9 (pbk.)
British Library Cataloging in Publication Data
DROMEY, R. G.
How to Solve it by Computer.
1. Algorithms
1. Title
S118 QA9.58
ISBN 0-13-433995.9
ISBN 0-13-434001-9 (pbk)
© 1982 by PRENTICE-HALL INTERNATIONAL, INC., London
© 1982 by PRENTICE-HALL INC., Englewood Cliffs, N.J. 07632
All rights reserved. No part of this publication may be reproduced,
stored in a retrieval system, or transmitted, in any form or by any
means, electronic, mechanical, photocopying, recording or otherwise,
without the prior permission of the publisher.
ISBN O-13-433995-9
ISBN O-13-434001-9 {PBKT
PRENTICE-HALL INTERNATIONAL, INC., London
PRENTICE-HALL OF AUSTRALIA PTY. LTD., Sydney
PRENTICE-HALL CANADA, INC., Toronto
PRENTICE-HALL OF INDIA PRIVATE LTD., New Delhi
PRENTICE-HALL OF JAPAN, INC., Tokyo
PRENTICE-HALL OF SOUTHEAST ASIA PTE.,.LTD., Singapore
PRENTICE-HALL, INC., Englewood Cliff, New Jersey
WHITEHALL BOOKS LIMITED, Wellington, New Zealand
Printed in the United States of America
10987654321
This book is dedicated to
George Polya
We learn most when
We have to invent
Piaget
CONTENTS
PREFACE xi
ACKNOWLEDGEMENTS rod
INTRODUCTION TO COMPUTER PROBLEM-SOLVING 1
1.1 Introduction 1
1.2. The Problem-solving Aspect 3
1.3. Top-down Design 7
1.4 Implementation of Algorithms 14
1.5 Program Verification 19
1.6 The Efficiency of Algorithms 29
1.7. The Analysis of Algorithms 33
Bibliography 39
FUNDAMENTAL ALGORITHMS 42
Introduction 42
Algorithm 2.1 Exchanging the Values of Two Variables 43
Algorithm 2.2 Counting 47
Algorithm 2.3 Summation of a Set of Numbers 51
Algorithm 2.4 Factorial Computation 56
Algorithm 2.5 Sine Function Computation 60
Algorithm 2.6 Generation of the Fibonacci Sequence 64
Algorithm 2.7 Reversing the Digits of an Integer 69
Algorithm 2.8 Base Conversion 74
Algorithm 2.9 Character to Number Conversion 80
Bibliography 84
x
3
CONTENTS
FACTORING METHODS 85
Intraduction 85
Algorithm 3.1 Finding the Square Root of a Number 86
Algorithm 3.2. The Smallest Divisor of an Integer 92
Algorithm 3.3 The Greatest Common Divisor of Two
Integers 97
Algorithm 3.4 Generating Prime Numbers 105
Algorithm 3.5 Computing the Prime Factors of an Integer 116
Algorithm 3.6 Generation of Pseudo-random Numbers 120
Algorithm 3.7 Raising a Number to a Large Power 124
Algorithm 3.8 Computing the mth Fibonacci Number 132
Bibliography 138
ARRAY TECHNIQUES 139
Introduction 139
Algorithm 4.1 Array Order Reversal 140
Algorithm 4.2 Array Counting or Histogramming 144
Algorithm 4.3 Finding the Maximum Number in a Set 147
Algorithm 4.4 Removal of Duplicates from an Ordered
Array 152
Algorithm 4.5. Partitioning an Array 156
Algorithm 4.6 Finding the kth Smallest Element 166
Algorithm 4.7 Longest Monotone Subsequence 174
Bibliography 180
MERGING, SORTING AND SEARCHING 181
Introduction 181
Algorithm 5.1 The Two-way Merge 182
Algorithm 5.2 Sorting by Selection 192
Algorithm 5.3. Sorting by Exchange 198
Algorithm 5.4 Sorting by Insertion 204
Algorithm 5.5 Sorting by Diminishing Increment 209
Algorithm 5.6 Sorting by Partitioning 216
Algorithm 5.7 Binary Search 227
Algorithm 5.8 Hash Searching 237
Bibliography 246
TEXT PROCESSING AND PATTERN SEARCHING 248
Introduction 248
Algorithm 6.1 Text Line Length Adjustment 249
Algorithm 6.2 Left and Right Justification of Text 256
Algorithm 6.3 Keyword Searching in Text 267
Algorithm 6.4 Text Line Editing 274
Algorithm 6.5 Linear Pattern Search 282
Algorithm 6.6 Sublinear Pattern Search 293
Bibliography 303
CONTENTS xi
DYNAMIC DATA STRUCTURE ALGORITHMS 304
Introduction 304
Algorithm 7.1. Stack Operations 306
Algorithm 7.2. Queue Addition and Deletion 314
Algorithm 7.3 Linked List Search 325
Algorithm 7.4 Linked List Insertion and Deletion 331
Algorithm 7.5 Binary Tree Search 342
Algorithm 7.6 Binary Tree Insertion and Deletion 349
Bibliography 366
RECURSIVE ALGORITHMS 367
Introduction 367
Algorithm 8.1 Binary Tree Traversal 373
Algorithm 8.2 Recursive Quicksort 383
Algorithm 8.3 Towers of Hanoi Problem 391
Algorithm 8.4 Sample Generation 404
Algorithm 8.5 Combination Generation 414
Algorithm 8.6 Permutation Generation 422
Bibliography 433
INDEX 435
PREFACE
The inspiration for this book has come from the classic work of Polya on
general and mathematical problem-solving. As in mathematics, many
beginners in computing science stumble not because they have difficulty
with learning a programming language but rather because they are ill-
prepared to handle the problem-solving aspects of the discipline. Unfortu-
nately, the school system seems to concentrate on training people to answer
questions and remember facts but not to really solve problems.
In response to this situation, it was felt there was a definite need for a
book written in the spirit of Polya’s work, but translated into the computing
science context. Much of Polya’s work is relevant in the new context but,
with computing problems, because of their general requirements for itera-
tive or recursive solutions, another dimension is added to the problem-
solving process.
If we can develop problem-solving skills and couple them with top-
down design principles, we are well on the way to becoming competent at
algorithm design and program implementation. Emphasis in the book has
been placed on presenting strategies that we might employ to “discover”
efficient, well-structured computer algorithms. Throughout, a conscious
effort has been made to convey something of the flavor of either a personal
dialogue or an instructor-student dialogue that might take place in the
solution of a problem. This style of presentation coupled with a carefully
chosen set of examples, should make the book attractive to a wide range of
readers.
The student embarking on a first course in Pascal should find that the
material provides a lot of useful guidance in separating the tasks of learning
how to develop computer algorithms and of then implementing them in a
programming language like Pascal. Too often, the end is confused with the
xiv PREFACE
means. A good way to work with the book for self-study is to read only as
much as you need to get started on a problem. Then, when you have
developed your own solution, compare it with the one given and consciously
reflect on the strategies that were helpful or hindersome in tackling the
problem. As Yohet has rightly pointed out “programming [computer
problem-solving] is an art [and] as in all art forms, each individual must
develop a style which seems natural and genuine.”
Instructors should also find the style of presentation very useful as
lecture material as it can be used to provide the cues for a balanced amount
of instructor-class dialogue. The author has found students receptive and
responsive to lectures presented in this style.
The home-computer hobbyist wishing to develop his or her problem-
solving and programming skills without any formal lectures should find the
completeness of presentation of the various algorithms a very valuable
supplement to any introductory Pascal text. It is hoped that even some of the
more advanced algorithms have been rendered more accessible to beginners
than is usually the case.
The material presented, although elementary for the most part, con-
tains some examples and topics which should be of sufficient interest and
challenge to spark, in the beginning student, the enthusiasm for computing
that we so often see in students who have begun to master their subject.
Readers are urged not to accept passively the algorithm solutions given.
Wherever it is possible and practical, the reader should strive for his or her
own simpler or better algorithms. As always, the limitations of space have
meant that some topics and examples of importance have either had to be
omitted or limited in scope. To some degree the discussions and supplemen-
tary problems that accompany each algorithm are intended to compensate
for this. The problem sets have been carefully designed to test, reinforce, and
extend the reader’s understanding of the strategies and concepts presented.
Readers are therefore strongly urged to attempt a considerable proportion
of these problems.
Each chapter starts off with a discussion of relatively simple, graded
examples, that are usually related in some fairly direct way. Towards the
middle and end of each chapter, the examples are somewhat more involved.
A good way to work with the book is to only consider the more fundamental
algorithms in each chapter at a first reading. This should allow the necessary
build-up of background needed to study in detail some of the more advanced
algorithms at a later stage.
The chapters are approximately ordered in increasing order of concep-
tual difficulty as usually experienced by students. The first chapter intro-
+ J.M. Yohe, “An overview of programming practices”, Comp. Surv., 6, 221-46
(1974).
PREFACE xv
duces the core aspects of computer problem-solving and algorithm design.
Ata first reading the last half of the chapter can be skimmed through. Where
possible, the ideas are reinforced with examples. The problem-solving dis-
cussion tries to come to grips with the sort of things we can do when we are
stuck with a problem. The important topic of program verification is pre-
sented in a way that should be relatively easy for the reader to grasp and
apply at least to simple algorithms. Examples are used to convey something
of the flavor of a probabilistic analysis of an algorithm.
The second chapter concentrates on developing the skill for formulating.
iterative solutions to problems—a skill we are likely to have had little
experience with before an encounter with computers. Several problems are
also considered which should allow us to come to a practical understanding
of how computers represent and manipulate information. The problem of
conversion from one representation to another is also addressed. The
algorithms in this chapter are all treated as if we were faced with the task of
discovering them for the first time. Since our aim is to foster skill in computer
problem-solving, this method of presentation would seem to be appropriate
from a pedagogical standpoint. Algorithms in the other chapters are also
discussed in this style.
In the third chapter, we consider a number of problems that have their
origin in number theory. These algorithms require an extension of the
iterative techniques developed in the first chapter. Because of their nature,
most of these problems can be solved in a number of ways and can differ
widely in their computational cost. Confronting the question of efficiency
adds an extra dimension to the problem-solving process. We set out to
“discover” these algorithms as if for the first time.
Array-processing algorithms are considered in detail in Chapter 4.
Facility with the use of arrays needs to be developed as soon as we have
understood and are able to use iteration in the development of algorithms.
Arrays, when coupled with iteration, provide us with a very powerful means
of performing computations on collections of data that share some common
attribute. Strategies for the efficient processing of array information raise
some interesting problem-solving issues. The algorithms discussed are
intended to address at least some of the more important of these issues.
Once arrays and iteration have been covered, we have the necessary
tools to consider merging, sorting and searching algorithms. These topics are
discussed in Chapter 5. The need to organize and subsequently efficiently
search large volumes of information is central in computing science. A
number of the most well-known internal sorting and searching algorithms
are considered. An attempt is made to provide the settings that would allow
us to “discover” these algorithms.
The sixth chapter on text and string processing represents a diversion
from the earlier emphasis on “numeric” computing. The nature and organ-
xvi PREFACE
ization of character information raises some important new problem-solving
issues. The demands for efficiency once again lead to the consideration of
some interesting algorithms that are very different from those reviewed in
earlier chapters. The algorithms in this chapter emphasize the need to
develop the skill of recognizing the essentials of a problem without being
confused or misled by extraneous detail. “Discovering” some of these
algorithms provides an interesting test-bed for us to apply some of the
problem-solving skills we should have absorbed after covering the first five
chapters.
Chapter 7 is devoted to the fundamental algorithms for maintaining and
searching the primary dynamic data structures (i.e. stacks, queues, lists, and
binary trees). The issues in this chapter arise mostly at the implementation
level and with the use of pointers.
In the final chapter, the topic of recursion is introduced. A recursive call
is presented as an extension of the conventional subprocedure call. The
simplest form of recursion, linear recursion, is only briefly treated because
the view is taken that there are almost always simple iterative schemes that
can be found for performing what amounts to linear recursion. Furthermore,
linear recursion does little to either convey anything of the power of recur-
sion or to really deepen our understanding of the mechanism. The same
cannot usually be said for problems involving either binary recursion or the
more general non-linear recursion. Algorithms that belong to both these
classes are discussed in detail, with special emphasis being placed on recog-
nizing their underlying similarities and deepening our understanding of
recursion mechanisms.
Asa concluding remark about the book, if the author were to hope that
this work may achieve anything, it would be that it stimulated students and
others to embark on a journey of discovering things for themselves!
A SUGGESTION FOR INSTRUCTORS
.any idea or problem or body of knowledge can be
presented in a form simple enough so that any particular
learner can understand it in a recognizable form.”
—Bruner.
In comparison with most other human intellectual activities, computing is in
its infancy despite the progress we seem to have made in such a short time.
Because the demand for computers and people with computing skills is so
great in our rapidly changing world, we have not had time to sit back and
A SUGGESTION FOR INSTRUCTORS _ xvii
reflect on the best way to convey the “computing concept” on a wide scale.
In time, computing will mature and evolve as a well-understood discipline
with clear and well-defined methods for introducing the subject to begin-
ners—but that is in the future. For the present, because we are not in this
happy situation, it is most prudent to look to other mature disciplines for
guidance on how we should introduce computing to beginners. Assuming we
want to have the highest possible success rate in introducing computing to
students (a situation which clearly at present does not prevail) and that we
want to teach computing on the widest possible scale, then the most obvious
discipline to turn to is that of learning to read and write.
Educators have mastered the process of teaching people to read and
write to the extent that these skills are able to be transmitted on a very wide
scale, efficiently, and with a very high rate of success. Putting aside the
various methods within the learning-to-read-and-write discipline we see that
there are some fundamental principles acknowledged by all methods that
are highly relevant to teaching computing.
In teaching people to read and write a very substantial time (years in
fact) is devoted to reading. Only after such preparation is it considered
appropriate that they should attempt to write stories or essays, or books, etc.
In fact, even before people attempt to learn to read they undergo several
years of listening to language, speaking, and being “read to”. Clearly, in
learning a language, the ultimate goal is to be able to verbalize and write
fluently in that language. Similarly in computing the goal is to be able to
program (or design and implement algorithms) effectively. In learning to
read and write it has long been recognized that reading is easier and that it
must precede writing by a considerable margin of time to allow the assimila-
tion of enough models and constructs of text to make writing possible.
In teaching computing we seem to have overlooked or neglected what
corresponds to the reading stage in the process of learning to read and write.
To put it strongly, asking people to design and write programs early on in
their computing experience is like expecting that they be able to competently
write essays before they have learned to read or even to write short sen-
tences—it is expecting just too much of a lot of people. It also probably
explains why many otherwise very able people just don’t get started in
computing.
What we are therefore proposing is that in teaching computing we
should draw as much as we can from the learning-to-read-and-write analogy.
This means that we must be able to provide the beginning student with his or
her “reading experience” in computing before embarking on the more
difficult computer problem-solving tasks which require considerably more
creative effort, discipline, and technical skill.
At this point it is important to recognize that the “reading experience”
cannot be gained by sitting down with a book of programs and attempting to
xviii PREFACE
“read” them. The problem with this approach is that program instructions as.
written on a piece of paper are a static representation of a computer
algorithm. As such they do not very fluently convey anything of the dynamic
aspect of computer algorithms and programs.
It can be argued that it is important to have a clear and in-depth
understanding of the dynamic character of programs before attempting
algorithm design and program implementation. What is needed is a practical
and economical method of giving students their “reading experience” in
computing. To gain this experience the students need to “see” programs
written in a high level language executing. Traditionally, all the student sees
is the output printed on the terminal or line printer and prompts by the
program when it requires input from the terminal. This level of “seeing” a
program execute is unsatisfactory for beginners because it conveys very little
about the program’s flow of control or about the effects of individual and
groups of program statements. What we need is much more explicit demon-
strations of what is happening in a program that causes it to produce the
outputs that it does. A far more transparent way to do this is to place before
the student on a terminal the text of the program being executed and then to
trace the execution on the displayed program while at the same time dynam-
ically updating on the screen the changes in program variables as they are
made and related to steps in the displayed program. This dynamic method of
studying algorithms can greatly assist the student in acquiring a level of
understanding necessary to design and implement his or her own algorithms.
The facilities and software tools needed to adequately demonstrate
execution of a program in this way are relatively economical to provide. All
that is needed is a terminal with cursor addressing facilities and a small set of
software tools (several hundred lines of code) that can be inserted into the
program being studied to make its execution “visible” on the screen. Only
one procedure call per statement of the program being studied is needed to
operate it in a visible mode (this software is available from the author). The
display software is transparent to the user. The appropriate tools allow us to
see a program execute in single-step mode while monitoring the changes in
variables as they are dynamically displayed on the screen. The student can
cause the program to execute the next statement at each stage by simply
pressing a single key (e.g. the RETURN) on the terminal.
As an example, the screen layout for “visible” execution of a selection
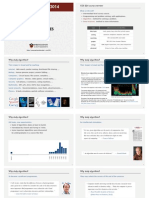
sorting procedure in Pascal is as illustrated in Fig. 1. The next statement to be
executed at each stage is tracked by having an arrow that can be moved from
statement to statement on the procedure text displayed on the screen. A
more complete description of the software is given elsewhere.’
+ R. G. Dromey, Before Programming—On Teaching Introductory Computing,
Technical Report No. 81/6, Dept. of Computing Science, University of Wollon-
gong (1981).
‘A SUGGESTION FOR INSTRUCTORS xix
procedure selectionsori(a:nelements; n:integer);
var i {index for sorted part}, j {index for unsorted part},
P {position of minimum}, min {minimum in unsorted part}: integer;
begin
for i
1 ton-1do ie leele | olf) 12)
ati];
for j := i+1 ton do
if af j] < min then
Lis
2 |afa:| 4
1 |afp}:| 12
end
array: 12 4 56 67 9 23 45
Uy
condition: af j]< min :
Fig. 1 Screen layout for visible program execution
The cause-and-effect nature of what is displayed when executing prog-
rams in this manner (automatic single-step mode) can accomplish a number
of things.
(1) Most importantly, it provides a good understanding of the dynamic
nature of algorithms—an essential prerequisite if students are to later
design and implement their own algorithms.
(2) It gives a deep insight into the basic laws of composition of computer
algorithms (sequence, selection, iteration, and modularity).
(3) Itis auseful vehicle for helping students to learn various programming
constructs. Actually observing constructs being used within different
programming contexts and linking these constructs to changes in the
values of variables and conditions gives the student the necessary
concrete demonstrations that will enable him or her to master the use
of these constructs.
(4) Itconveysin a very vivid fashion the workings of a particular algorithm.
For example, the selection sort algorithm when visibly executed con-
veys the difficult concept of how we can have one loop executing within
another loop. It also highlights the difference between subscripted
variables and subscripts.
xx PREFACE
(5) It also provides an ideal tool for teaching students debugging tech-
niques. That is, programs with logical bugs can be implemented and the
student asked to diagnose the problem after studying the program in
visible execution mode.
Visible program execution has the added advantage of being ideally
suited for use in the lecture room, classroom, or library. Most terminals have
the capability of video output which can be connected to a video recorder.
Using these facilities it is very easy and cheap to monitor and record the
visible program execution of a variety of programs for later use on video
monitors in the classroom or library. This gives us a teaching aid far superior
to handwritten blackboard examples when lecturing about algorithms in the
classroom. We have recorded and used a number of programs in this way.
We can take the visible mode of program execution a step further by
making it more active with respect to the student. At each step in the
program’s execution we can ask the student to supply the appropriate value
of the variable or condition etc. How this works can be best illustrated by
referring back to the figure. The arrow is indicating that the 7" statement
(ie. p := j) is the next one to be executed. What the software can do is move
the cursor to the “p” box on the screen and indicate to the student that he
must supply the appropriate value for p (in this case 2) before the program
will continue. If the user enters the wrong value the word ERROR will flash
in the p-box. This will be followed by a flashing of the INPUT sign to prompt
the user to again try to enter the proper p value. If the user gets it wrong twice
the software flashes VALUE in the p-box and then supplies the user with the
correct value, switches from interactive to automatic single step mode, and
moves to the next program statement to be executed.
Using a visible program in interactive single-step mode can in a very
direct way reinforce the student’s comprehension of how a program really
works and what individual program statements accomplish. At the same
time it can give the student very positive and direct feedback when he gets
something wrong.
What we are therefore advocating is that students be given considerable
exposure to visible “‘program-reading” in both the modes described as a
preparatory step to considering the problem-solving aspect of computer
algorithm design. Exposure to visible program execution (VPE) should be
accompanied by a study of the basic laws of composition of computer
algorithms (sequence, selection, iteration and modularity) including how
these laws of form relate to the way programs are executed. Concurrently, a
study should also be made of the syntax of the programming language being
read.
ACKNOWLEDGEMENTS
The inspiration for the approach taken in this book grew out of an admira-
tion for George Polya’s classic works on problem-solving. During the
summer and autumn of 1980, I had the pleasure of spending a number of
afternoons chatting with Professor and Mrs. Polya.
The influence of Polya’s work and that of the pioneers of the discipline
of computing science, E. W. Dijkstra, R. W. Floyd, C. A. R. Hoare, D. E.
Knuth, and N, Wirth, is freely acknowledged. There is also a strong influence
of Jeff Rohl’s work in the last chapter on recursion.
Isincerely appreciate the guidance and encouragement given to me by
Professor Hoare, Henry Hirschberg, Ron Decent, and my reviewers.
Iam also grateful to the University of Wollongong and Stanford Uni-
versity for the use of their facilities.
A number of people have generously given helpful comments and
support during the preparation of the manuscript. I would particularly like to
thank Tom Bailey, Miranda Baker, Harold Brown, Bruce Buchanan, Ann
Cartwright, John Farmer, Tony Guttman, Joan Hutchinson, Leanne Koring,
Donald Knuth, Rosalyn Maloney, Richard Miller, Ross Nealon, Jurg
Nievergelt, Richard Patis, Ian Pirie, Juris Reinfelds, Tom Richards, Michael
Shepanksi, Stanley Smerin and Natesa Sridharan and my students at Wol-
longong.
The understanding and encouragement throughout this whole project
that I have received from my wife Aziza is deeply appreciated.
Finally, I wish to extend my deepest gratitude to Bronwyn James for her
loyalty and untiring and able support in the preparation and typing of the
manuscript.
Chapter 1
INTRODUCTION TO COMPUTER
PROBLEM-SOLVING
1.1 INTRODUCTION
Computer problem-solving can be summed up in one word—it is demand-
ing! It is an intricate process requiring much thought, careful planning,
logical precision, persistence, and attention to detail. At the same time it can
be a challenging, exciting, and satisfying experience with considerable room
for personal creativity and expression. If computer problem-solving is
approached in this spirit then the chances of success are greatly amplified. In
the discussion which follows in this introductory chapter we will attempt to
lay the foundations for our study of computer problem-solving.
1.1.1 Programs and algorithms
The vehicle for the computer solution to a problem is a set of explicit and
unambiguous instructions expressed in a programming language. This set of
instructions is called a program. A program may also be thought of as an
algorithm expressed in a programming language. An algorithm therefore
corresponds to a solution to a problem that is independent of any program-
ming language.
To obtain the computer solution to a problem once we have the pro-
gram we usually have to supply the program with input or data. The program
then takes this input and manipulates it according to its instructions and
eventually produces an output which represents the computer solution to the
problem. The realization of the computer output is but the last step in a very
long chain of events that have led up to the computer solution to the
problem.
2 COMPUTER PROBLEM-SOLVING CHAP. 1
Our goal in this work is to study in depth the process of algorithm design
with particular emphasis on the problem-solving aspects of the task. There
are many definitions of an algorithm. The following definition is appropriate
in computing science. An algorithm consists of a set of explicit and unam-
biguous finite steps which, when carried out for a given set of initial condi-
tions, produce the corresponding output and terminate in a finite time.
1.1.2 Requirements for solving problems by computer
From time to time in our everyday activities, we employ algorithms to solve
problems. For example, to look up someone’s telephone number in a tele-
phone directory we need to employ an algorithm. Tasks such as this are
usually performed automatically without any thought to the complex under-
lying mechanism needed to effectively conduct the search. It therefore
comes as somewhat of a surprise to us when developing computer algorithms
that the solution must be specified with such logical precision and in such
detail. After studying even a small sample of computer problems it soon
becomes obvious that the conscious depth of understanding needed to design
effective computer algorithms is far greater than we are likely to encounter
in almost any other problem-solving situation.
Let us reflect for a moment on the telephone directory look-up prob-
lem. A telephone directory quite often contains hundreds of thousands of
names and telephone numbers yet we have little trouble finding the desired
telephone number we are seeking. We might therefore ask why do we have
so little difficulty with a problem of seemingly great size? The answer is
simple. We quite naturally take advantage of the order in the directory to
quickly eliminate large sections of the list and home in on the desired name
and number. We would never contemplate looking up the telephone number
of J. R. Nash by starting at page 1 and examining each name in turn until we
finally come to Nash’s name and telephone number. Nor are we likely to
contemplate looking up the name of the person whose number is 2987533.
To conduct such a search, there is no way in which we can take advantage of
the order in the directory and so we are faced with the prospect of doing a
number-by-number search starting at page 1. If, on the other hand, we had a
list of telephone numbers and names ordered by telephone number rather
than name, the task would be straightforward. What these examples serve to
emphasize is the important influence of the data organization on the perfor-
mance of algorithms. Only when a data structure is symbiotically linked with
an algorithm can we expect high performance. Before considering these and
other aspects of algorithm design we need to address the topic of problem-
solving in some detail.
SEC. 1.2 THE PROBLEM-SOLVING ASPECT 3
1.2. THE PROBLEM-SOLVING ASPECT
It is widely recognized that problem-solving is a creative process which
largely defies systematization and mechanization. This may not sound very
encouraging to the would-be problem-solver. To balance this, most people,
during their schooling, acquire at least a modest set of problem-solving skills
which they may or may not be aware of.
Even if one is not naturally skilled at problem-solving there are a
number of steps that can be taken to raise the level of one’s performance. It is
not implied or intended that the suggestions in what follows are in any way a
recipe for problem-solving. The plain fact of the matter is that there is no
universal method. Different strategies appear to work for different people.
Within this context, then, where can we begin to say anything useful
about computer problem-solving? We must start from the premise that
computer problem-solving is about understanding.
1.2.1 Problem definition phase
Success in solving any problem is only possible after we have made the effort
tocome to terms with or understand the problem at hand. We cannot hope to
make useful progress in solving a problem until we fully understand what it is
we are trying to solve. This preliminary investigation may be thought of as
the problem definition phase. In other words, what we must do during this
phase is work out what must be done rather than how to do it. That is, we
must try to extract from the problem statement (which is often quite impre-
cise and maybe even ambiguous) a set of precisely defined tasks. Inexperi-
enced problem-solvers too often gallop ahead with how they are going to
solve the problem only to find that they are either solving the wrong problem
or they are solving just a very special case of what is actually required. In
short, a lot of care should be taken in working out precisely what must be
done. The development of algorithms for finding the square root (algorithm
3.1) and the greatest common divisor (algorithm 3.3) are good illustrations
of how important it is to carefully define the problem. Then, from the
definitions, we are led in a natural way to algorithm designs for these two
problems.
1.2.2 Getting started on a problem
There are many ways to solve most problems and also many solutions to
most problems. This situation does not make the job of problem-solving
easy. When confronted with many possible lines of attack it is usually
4 COMPUTER PROBLEM-SOLVING CHAP. 1
difficult to recognize quickly which paths are likely to be fruitless and which
paths may be productive.
Perhaps the more common situation for people just starting to come to
grips with the computer solution to problems is that they just do not have any
idea where to start on the problem, even after the problem definition phase.
When confronted with this situation, what can we do? A block often occurs
at this point because people become concerned with details of the implemen-
tation before they have completely understood or worked out an
implementation-independent solution. The best advice here is not to be too
concerned about detail. That can come later when the complexity of the
problem as a whole has been brought under control. The old computer
proverb‘ which says “the sooner you start coding your program the longer it
is going to take” is usually painfully true.
1.2.3. The use of specific examples
A useful strategy when we are stuck is to use some props or heuristics (i.e.
rules of thumb) to try to get a start with the problem. An approach that often
allows us to make a start on a problem is to pick a specific example of the
general problem we wish to solve and try to work out the mechanism that will
allow us to solve this particular problem (e.g. if you want to find the
maximum in a set of numbers, choose a particular set of numbers and work
out the mechanism for finding the maximum in this set—see for example
algorithm 4.3). It is usually much easier to work out the details of a solution
to a specific problem because the relationship between the mechanism and
the particular problem is more clearly defined. Furthermore, a specific
problem often forces us to focus on details that are not so apparent when the
problem is considered abstractly. Geometrical or schematic diagrams rep-
resenting certain aspects of the problem can be usefully employed in many
instances (see, for example, algorithm 3.3).
This approach of focusing on a particular problem can often give us the
foothold we need for making a start on the solution to the general problem.
The method should, however, not be abused. It is very easy to fall into the
trap of thinking that the solution to a specific problem or a specific class of
problems is also a solution to the general problem. Sometimes this happens
but we should always be very wary of making such an assumption.
Ideally, the specifications for our particular problem need to be
examined very carefully to try to establish whether or not the proposed
algorithm can meet those requirements. If the full specifications are difficult
to formulate sometimes a well-chosen set of test cases can give us a degree of
+ H.F. Ledgard, Programming Proverbs, Hayden, Rochelle Park, N.J., 1975.
sec.12 THE PROBLEM-SOLVING ASPECT 5
confidence in the generality of our solution. However, nothing less than a
complete proof of correctness of our algorithm is entirely satisfactory. We
will discuss this matter in more detail a little later.
1.2.4 Simila
ies among problems
We have already seen that one way to make a start on a problem is by
considering a specific example. Another thing that we should always try to
do is bring as much past experience as possible to bear on the current
problem. In this respect it is important to see if there are any similarities
between the current problem and other problems that we have solved or we
have seen solved. Once we have had a little experience in computer
problem-solving it is unlikely that a new problem will be completely
divorced from other problems we have seen. A good habit therefore is to
always make an effort to be aware of the similarities among problems. The
more experience one has the more/tools and techniques one can bring to
bear in tackling a given problem. The contribution of experience to our
ability to solve problems is not always helpful. In fact, sometimes it blocks us
from discovering a desirable or better solution to a problem. A classic case of
experience blocking progress was Einstein’s discovery of relativity. For a
considerable time before Einstein made his discovery the scientists of the
day had the necessary facts that could have led them to relativity but it is
almost certain that their experience blocked them from even contemplating
such a proposal—Newton’s theory was correct and that was all there was to
it! On this point it is therefore probably best to place only cautious reliance
on past experience. In trying to get a better solution to a problem, sometimes
too much study of the existing solution or a similar problem forces us down
the same reasoning path (which may not be the best) and to the same dead
end. In trying to get a better solution to a problem, it is usually wise, in the
first instance at least, to try to independently solve the problem. We then give
ourselves a better chance of not falling into the same traps as our predeces-
sors. In the final analysis, every problem must be considered on its merits.
A skill that it is important to try to develop in problem-solving is the
ability to view a problem from a variety of angles. One must be able to
metaphorically turn a problem upside down, inside out, sideways, back-
wards, forwards and so on. Once one has developed this skill it should be
possible to get started on any problem.
1.2.5 Working backwards from the solution
There are still other things we can try when we do not know where to start on
a problem. We can, for example, in some cases assume that we already have
6 COMPUTER PROBLEM-SOLVING CHAP. 1
the solution to the problem and then try to work backwards to the starting
conditions. Even a guess at the solution to the problem may be enough to
give us a foothold to start on the problem. (See, for example, the square root
problem—algorithm 3.1). Whatever attempts that we make to get started on
a problem we should write down as we go along the various steps and
explorations made. This can be important in allowing us to systematize our
investigations and avoid duplication of effort. Another practice that helps us
develop our problem-solving skills is, once we have solved a problem, to
consciously reflect back on the way we went about discovering the solution.
This can help us significantly. The most crucial thing of all in developing
problem-solving skills is practice. Piaget summed this up very nicely with the
statement that “we learn most when we have to invent.”
1.2.6 General problem-solving strategies
There are a number of general and powerful computational strategies that
are repeatedly used in various guises in computing science. Often it is
possible to phrase a problem in terms of one of these strategies and achieve
very considerable gains in computational efficiency.
Probably the most widely known and most often used of these principles
is the divide-and-conquer strategy. The basic idea with divide-and-conquer is
to divide the original problem into two or more subproblems which can
hopefully be solved more efficiently by the same technique. If it is possible to
proceed with this splitting into smaller and smaller subproblems we will
eventually reach the stage where the subproblems are small enough to be
solved without further splitting. This way of breaking down the solution to a
problem has found wide application in particular with sorting, selection, and
searching algorithms. We will see later in Chapter 5 when we consider the
binary search algorithm how applying this strategy to an ordered data set
results in an algorithm that needs to make only log,” rather than n compari-
sons to locate a given item in an ordered list n elements long. When this
principle is used in sorting algorithms, the number of comparisons can be
reduced from the order of n? steps to n log,n steps, a substantial gain
particularly for large n. The same idea can be applied to file comparison and
in many other instances to give substantial gains in computational efficiency.
It is not absolutely necessary for divide-and-conquer to always exactly halve
the problem size. The algorithm used in Chapter 4 to find the k'* smallest
element repeatedly reduces the size of the problem. Although it does not
divide the problem in half at each step it has very good average performance.
It is also possible to apply the divide-and-conquer strategy essentially in
reverse to some problems. The resulting binary doubling strategy can give
the same sort of gains in computational efficiency. We will consider in
Chapter 3 how this complementary technique can be used to advantage to
SEC. 1.3 TOP-DOWN DESIGN 7
raise a number to a large power and to calculate the n'* Fibonacci number.
With this doubling strategy we need to express the next term n to be
computed in terms of the current term which is usually a function of n/2 in
order to avoid the need to generate intermediate terms.
Another general problem-solving strategy that we will briefly consider
is that of dynamic programming. This method is used most often when we
have to build up a solution to a problem via a sequence of intermediate steps.
The monotone subsequence problem in Chapter 4 uses a variant of the
dynamic programming method. This method relies on the idea that a good
solution to a large problem can sometimes be built up from good or optimal
solutions to smaller problems. This type of strategy is particularly relevant
for many optimization problems that one frequently encounters in opera-
tions research. The techniques of greedy search, backtracking and branch-
and-bound evaluations are all variations on the basic dynamic programming
idea. They all tend to guide a computation in such a way that the minimum
amount of effort is expended on exploring solutions that have been estab-
lished to be suboptimal. There are still other general computational
strategies that we could consider but because they are usually associated
with more advanced algorithms we will not proceed further in this direction.
1.3. TOP-DOWN DESIGN
The primary goal in computer problem-solving is an algorithm which is
capable of being implemented as a correct and efficient computer program.
In our discussion leading up to the consideration of algorithm design we have
been mostly concerned with the very broad aspects of problem-solving. We
now need to consider those aspects of problem-solving and algorithm design
which are closer to the algorithm implementation.
Once we have defined the problem to be solved and we have at least a
vague idea of how to solve it, we can begin to bring to bear powerful
techniques for designing algorithms. The key to being able to successfully
design algorithms lies in being able to manage the inherent complexity of
most problems that require computer solution. People as problem-solvers
are only able to focus on, and comprehend at one time, a very limited span of
logic or instructions. A technique for algorithm design that tries to accom-
modate this human limitation is known as top-down design or stepwise
refinement.
Top-down design is a strategy that we can apply to take the solution of a
computer problem from a vague outline to a precisely defined algorithm and
program implementation. Top-down design provides us with a way of hand-
ling the inherent logical complexity and detail frequently encountered in
8 COMPUTER PROBLEM-SOLVING CHAP. 1
computer algorithms. It allows us to build our solutions to a problem in a
stepwise fashion. In this way, specific and complex details of the implemen-
tation are encountered only at the stage when we have done sufficient
groundwork on the overall structure and relationships among the various
parts of the problem.
1.3.1 Breaking a problem into subproblems
Before we can apply top-down design to a problem we must first do the
problem-solving groundwork that gives us at least the broadest of outlines of
a solution. Sometimes this might demand a lengthy and creative investiga-
tion into the problem while at other times the problem description may in
itself provide the necessary starting point for top-down design. The general
outline may consist of a single statement or a set of statements. Top-down
design suggests that we take the general statements that we have about the
solution, one at a time, and break them down into a set of more precisely
defined subtasks. These subtasks should more accurately describe how the
final goal is to be reached. With each splitting of a task into subtasks it is
essential that the way in which the subtasks need to interact with each other
be precisely defined. Only in this way is it possible to preserve the overall
structure of the solution to the problem. Preservation of the overall structure
in the solution to a problem is important both for making the algorithm
comprehensible and also for making it possible to prove the correctness of
the solution. The process of repeatedly breaking a task down into subtasks
and then each subtask into still smaller subtasks must continue until we
eventually end up with subtasks that can be implemented as program state-
ments. For most algorithms we only need to go down to two or three levels
although obviously for large software projects this is not true. The larger and
more complex the problem, the more it will need to be broken down to
be made tractable. A schematic breakdown of a problem is shown in
Fig. 1.1.
The process of breaking down the solution to a problem into subtasks in
the manner described results in an implementable set of subtasks that fit
quite naturally into block-structured languages like Pascal and Algol. There
can therefore be a smooth and natural interface between the stepwise-
refined algorithm and the final program implementation—a highly desirable
situation for keeping the implementation task as simple as possible.
1.3.2 Choice of a suitable data structure
One of the most important decisions we have to make in formulating
computer solutions to problems is the choice of appropriate data structures.
SEC. 13 TOP-DOWN DESIGN 9
General outline
Input conditions Output requirements
Body of algorithm
Subtask 1 Subtask 3
Subtask 2
Subtask la
Subtask 2a
Fig. 1.1 Schematic breakdown of a problem into subtasks as employed in top-down design.
All programs operate on data and consequently the way the data is organ-
ized can have a profound effect on every aspect of the final solution. In
particular, an inappropriate choice of data structure often leads to clumsy,
inefficient, and difficult implementations. On the other hand, an appropriate
choice usually leads to a simple, transparent, and efficient implementation.
There is no hard and fast rule that tells us at what stage in the develop-
ment of an algorithm we need to make decisions about the associated data
structures. With some problems the data structure may need to be consi-
dered at the very outset of our problem-solving explorations before the
top-down design, while in other problems it may be postponed until we are
well advanced with the details of the implementation. In other cases still, it
can be refined as the algorithm is developed.
The key to effectively solving many problems really comes down to
making appropriate choices about the associated data structures. Data struc-
tures and algorithms are usually intimately linked to one another. A small
change in data organization can have a significant influence on the algorithm
required to solve the problem. It is not easy to formulate any generally
applicable rules that say for this class of problem this choice of data structure
10 COMPUTER PROBLEM-SOLVING CHAP. 1
is appropriate. Unfortunately with regard to data structures each problem
must be considered on its merits.
The sort of things we must however be aware of in setting up data
structures are such questions as:
(1) How can intermediate results be arranged to allow fast access to
information that will reduce the amount of computation required at a
later stage?
(2) Can the data structure be easily searched?
(3) Can the data structure be easily updated?
(4) Does the data structure provide a way of recovering an earlier state in
the computation?
(5) Does the data structure involve the excessive use of storage?
(6) Is it possible to impose some data structure on a problem that is not
initially apparent?
(7) Can the problem be formulated in terms of one of the common data
structures (e.g. array, set, queue, stack, tree, graph, list)?
These considerations are seemingly general but they give the flavor of the
sort of things we need to be asking as we proceed with the development of an
algorithm.
13.3 Construction of loops
In moving from general statements about the implementation towards sub-
tasks that can be realized as computations, almost invariably we are led toa
series of iterative constructs, or loops, and structures that are conditionally
executed. These structures, together with input/output statements, comput-
able expressions, and assignments, make up the heart of program implemen-
tations.
At the time when a subtask has been refined to something that can be
realized as an iterative construct, we can make the task of implementing the
loop easier by being aware of the essential structure of all loops. To construct
any loop we must take into account three things, the initial conditions that
need to apply before the loop begins to execute, the invariant relation that
must apply after each iteration of the loop, and the conditions under which
the iterative process must terminate.
In constructing loops people often have trouble in getting the initial
conditions correct and in getting the loop to execute the right number
SEC.1.3 TOP-DOWN DESIGN 11
of times rather than one too few or one too many times. For most prob-
lems there is a straightforward process that can be applied to avoid these
errors.
13.4 Establishing initial conditions for loops
To establish the initial conditions for a loop, a usually effective strategy is to
set the loop variables to the values that they would have to assume in order to
solve the smallest problem associated with the loop. Typically the number of
iterations n that must be made by a loop are in the range 00
sta{i]
The same two steps can be used to extend the solution from when n=1 to
when n= 2 and so on. These two steps will in general extend the solution
12 COMPUTER PROBLEM-SOLVING CHAP. 1
from the (i 1)"* case to the i* case (where i=1). They can therefore be used
as the basis of our iterative construct for solving the problem for n>1.
.) initialization conditions
g } for loop and solution to
* J summing problem when n=0
while i1
end
The process we have gone through to construct the loop is very similar to that
of mathematical induction. We will consider these ideas more closely when
proof of correctness and invariant relations are discussed.
The other consideration for constructing loops is concerned with the
setting up of the termination conditions.
1.3.6 Termination of loops
There are a number of ways in which loops can be terminated. In general the
termination conditions are dictated by the nature of the problem. The
simplest condition for terminating a loop occurs when it is known in advance
how many iterations need to be made. In these circumstances we can use
directly the termination facilities built into programming languages. For
example in Pascal the for-loop can be used for such computations:
for i:= 1 tondo
be;
end
This loop terminates unconditionally after n iterations.
A second way in which loops can terminate is when some conditional
expression becomes false. An example is:
while (x>0) and (x<10) do
begin
end
With loops of this type it cannot be directly determined in advance how
many iterations there will be before the loop will terminate. In fact there is
SEC.13 TOP-DOWN DESIGN 13
no guarantee that loops of this type will terminate at all. In these circum-
stances the responsibility for making sure that the loop will terminate rests
with the algorithm designer. If the model for the computation is straightfor-
ward it may be a simple matter to guarantee termination (e.g. in our example
above if x is changed with each iteration in either a monotonically increasing
or decreasing fashion, then eventually the conditional expression (x>0) and
(x<10) will become false. There are loops of this kind where it is very
difficult to prove that termination is guaranteed. Algorithm 3.1 (for comput-
ing square roots) contains a loop that is typical for this type of termination.
Yet another way in which termination of a loop can be set up is by
forcing the condition under which the loop will continue to iterate to become
false. This approach to termination can be very useful for simplifying the test
that must be made with each iteration. An example best illustrates this
method of loop termination. Suppose we wish to establish that an array of n
elements is in strictly ascending order (i.e. a[1]a[middle] then
lower := middle+1
else
upper := middle
n;
end
found := (x=allower})
For the search value x and the array a{1..] where x = 44 and n= 15 we may
have:
Initial a1) af15)
configuration [10]12]20]23]27] 30] 31] 39] 42|44]45]49] 57 [63] 70
t t t
lower middle upper
SEC. 1.4 IMPLEMENTATION OF ALGORITHMS 17
Then the associated execution table is given by Table 1.1.
Table 1.1 Stepwise execution table for binary search.
Iteration no. lower middle upper lower < upper almiddle] x > almiddle]
Initially eis true — _
1 9 Gb ow true 39 true
2 Oo 12 i true 49 false
3 9 10 10 true 44 false
4 10 9 10 false 42 true
NOTE: The values of variables associated with each iteration apply after the
iteration has been completed.
If we get to the stage where our program is executing but producing
incorrect results (e.g. it might be a sort routine that places most, but not all,
elements in order) the best idea is to first use a debugging trace to print out
strategic information. The next step is to follow the program through by
hand in a stepwise fashion checking against the computer’s debugging out-
put as we go. Whenever we embark on a debugging procedure of this kind we
should be careful to ensure that we follow in a straight line along the path of
execution. It is usually a wasted effort to assume that some things work and
only start a systematic study of the algorithm halfway through the execution
path. A good rule to follow when debugging is not to assume anything.
1.4.5 Program testing
In attempting to test whether or not a program will handle all variations of
the problem it was designed to solve we must make every effort to be sure
that it will cope with the limiting and unusual cases. Some of the things we
might check are whether the program solves the smallest possible problem,
whether it handles the case when all data values are the same, and so on.
Unusual cases like these are usually the ones that can cause a program to
falter.
Asan example, consider the testing we would need for the binary search
algorithm (i.e. algorithm 5.7). Appropriate data sets and tests are given in
Table 1.2.
It is often not possible or necessary to write programs that handle all
input conditions that may be supplied for a given problem. Wherever poss-
ible programs should be accompanied by input and output assertions as
described in the section on program verification. Although it is not always
practical to implement programs that can handle all possible input condi-
tions we should always strive to build into a program mechanisms that allow
it to gracefully and informatively respond to the user when it receives input
conditions it was not designed to handle.
18 COMPUTER PROBLEM-SOLVING
CHAP.1
Table 1.2 Appropriate data sets for testing binary search algorithm
Test
Search
value(s) x
Sample data
@
(i)
(iii)
(iv)
)
(vi)
(vii)
(ix)
Will the algorithm handle
the search of array of one
element?
Will it handle the case where
all array values are equal?
Will it handle the case where
the element sought equals
the first value in the array?
Will it handle the case where
the value sought equals the
ast value in the array?
Will it handle the case where
the value sought is less than
the first element in the
array?
Will it handle the case where
the value sought is greater
than the last value in the
array?
Will it handle the case where
the value sought is at an even
array location?
Will it handle the case where
the value sought is at an odd
array location?
Will it handle the case where
the value sought is absent
but within the range of array
values?
0, 1,2
a{t}=1
a{t}=1
a{i}=1
afi}=1
afi}=1
a{i]=1
afi}=1
a@{i]=1
afi}=2
a{2]=1
a{2]=2
af2]=2
af2]=2
a(2]=2
a(2]=2
a[2]=2
af2]=4
n=1
a{n}=1
aln}=n
anj=n
a{n}=n
anj=n
afnj=n
anj=n
a{n]=2n
The last statement should not, however, be taken to mean that we
should only design algorithms to solve specific problems. This approach
should be far from our goal. Almost without exception we should design
algorithms to be very general so that they will handle a whole class of
problems rather than just one specific case. The latter approach of writing
programs for specific cases usually, in the long run, amounts to a lot of wasted
effort and time. It is far better to do a thorough job in the first place and
produce a program that will solve a wide range of problems. This brings us to
a bad practice that beginning programmers (and some others) often adopt.
The practice referred to is that of using fixed constants where variables
SEC.15 PROGRAM VERIFICATION 19
should be used. For example, we should not use statements of the form
while i<100 do
The 100 should always be replaced by a variable, i.e.
while i 0). When there are no restrictions on the
values of the input variables the input assertion is given the logical value true.
The output assertion must specify symbolically the results that the program is
expected to produce for input data that satisfies the input assertion (e.g. if a
program is designed to calculate the quotient q and remainder r resulting
from the division of x by y then the output assertion can be written as:
(x= ry t+N(r=Q
where the logical connective ‘‘>” is read as “implies”. P is termed the
assumption and Q the conclusion. The associated truth table defining impli-
cation is given in Table 1.3.
Table 1.3 Truth table defining implication
P Q P2Q
true true true
true false _—_false
false true ‘true
false false true
In order to show that these implications or propositions are logically
true, it is necessary to take into account the effects of executing the program
for arbitrary inputs that satisfy the input assertion. A relatively straight-
forward way to do this is to use the technique of symbolic execution. With
symbolic execution, all input data values are replaced by symbolic values and
all arithmetic operations on numbers translate into algebraic manipulation
of symbolic expressions. As an example, consider the following program
segment labelled with input and output assertions:
22 COMPUTER PROBLEM-SOLVING CHAP. 1
A readin(x,y);
{assert: true}
x-Y3
x+y;
yrx
B {assert x = yOAy = x0}
where x0 and y0 refer to the initial values of x and y respectively.
Table 1.4 Normal and symbolic execution for exchange mechanism
Step Normal execution Symbolic execution
input values: x=3 y=1 input values:
xisx-ypx=3-1=2 0 x= a-y > x=a-B
yisxty > y=24+153
xis y-x > x=3-2=1
were
Both normal execution and symbolic execution, shown in Table 1.4, indicate
that the values of x and y are exchanged.
Symbolic execution enables us to transform the verification procedure
into proving that the input assertion with symbolic values substituted for all
input variables implies the output assertion with final symbolic values substi-
tuted for all variables. A proposition phrased in this way is referred to as a
verification condition (VC) over the program segment from the input asser-
tion to the output assertion.
To proceed with the verification procedure it is usually necessary to set
up a number of intermediate verification conditions between the input and
output assertions. Taken to the limit this involves carrying out the verifica-
tion procedure statement by statement. For practical purposes itis, however,
usually sufficient to only consider verification conditions for blocks of a
program as marked by straight-line segments, branching segments, and loop
segments. We will adopt the convention that VC(A — B) refers to the verifica-
tion condition over the program segment from A to B. We will now consider
the verification of each of these basic segment types in turn.
1.5.4 Verification of straight-line program segments
The best way to illustrate the verification procedure is by example. Our
exchange mechanism mentioned above will serve as an example of a
straight-line program segment.
SEC.1.5 PROGRAM VERIFICATION 23
The verification condition for this program segment is:
VC(A-B): true > {x= yOAy = x0}
On substitution of the initial and final values of all variables, we get:
VC(A-B): true > ((a—B)+B)—(a—B)) = BMa-B)+B)=a
The conclusion part of the verification condition can be simplified to yield
B=B and a=a which is clearly true and so the implication is true.
15.5 Verification of program segments with branches
To handle program segments that contain branches it is necessary to set up
and prove verification conditions for each branch separately. As an example,
consider the following program segment that ensures that x is less than or
equal to y.
readin(x,y);
A {assert P,: true}
if x>y then
begin
x
end
B {assert Pp: ((x<=y)Ax=x0Ay =y0))V(x= yOAy = x0)}
In general, the propositions that must be proved for the basic if construct
are:
P,AC,>P5
P,A~Cy>Pp5
where C, is the branch condition.
The two verification conditions needed in this case are given below,
where the initial values of x and y are respectively @ and B
VC(A-(1)—B): true Na>B>((a is true and the second part of the conclusion (i.e. a = «AB = ) is
true, the verification condition for the true path is true.
The verification condition for the false path is:
VC(A-(f)—B): true \~(a>B)>((a)> (af) and the conclusion (a = a = f) is true the verifica-
tion condition for the false path is true. It follows that the labelled program
segment (A—B) is true. Case statements can be treated similarly.
24 COMPUTER PROBLEM-SOLVING CHAP. 1
1.5.6 Verification of program segments with loops
There are problems with trying to verify loop segments directly by symbolic
execution because the number of iterations required is usually arbitrary. To
overcome this problem, a special kind of assertion called a loop invariant
must be employed, A loop invariant should be a property (predicate) that
captures the progressive computational role of the loop while at the same
time remaining true before and after each loop traversal irrespective of how
many times the loop is executed. Once the loop invariant is established,
there are several steps that must be taken to verify the loop segment. To
understand this loop verification procedure, we will use the following
single-loop program structure as our model.
A_ {input assertion P 4}
straight-line program segment
B- {loop invariant I}
while /oop-condition do
begin
loop-free program segment
end
C {output assertion Pc}
(a) The first step that must be taken is to show that the loop invariant is
true initially, before the loop is entered. This can be done by setting up
a verification condition VC(A— B) for the program segment from A to
B. That is, the input assertion, together with any changes to variables
caused by the segment A—B, must imply that the loop invariant is true.
We can use symbolic execution to carry out this verification step. That
is, we must show P4>/.
(b) The second part of verifying a loop involves showing that the loop
invariant is still true after the segment of program within the loop has
been executed. To do this we can set up a verification condition
VC(B-B). This involves showing that the loop invariant with initial
values of variables set, together with the condition for loop execution
C;, implies the truth of the loop invariant with final values of variables,
ie.
IpACg>I5
Symbolic execution can also be used to verify this step.
SEC.1.5 PROGRAM VERIFICATION 25
(c) Asa final step in verifying a loop segment, it is necessary to show that
the invariant, together with the negation of the loop-entry condition,
implies the assertion that applies on exiting from the loop. The verifica-
tion condition in this case for our basic loop structure will be VC(B— C).
The corresponding proposition will be:
Ig\~Cg>Pe
A better understanding of the application of the loop verification
technique can be gained by studying a specific example. Consider the follow-
ing program segment which can be used to compute factorial.
A {assert P,: n>=0}
a
fact 7
B_ {invariant I,: fact = i!\i Ip
: y2031=0!N0Iy
: B=a!Aax(a+1)8=(a+1)! is true.
Also asyNaPc
: B=alhaxyh ~(aB=y!
Since ~(ay
then ayoa
and so because a=y it follows that 8 = a!>B = y! is true
and so the verification condition VC(B-C) is true.
26 COMPUTER PROBLEM-SOLVING CHAP. 1
Since the verification conditions for all three program segments are correct,
the complete program segment is said to be partially correct.
What the verification method we have described gives us is only a proof
of partial correctness, with the implication that if the algorithm terminates
the result produced will be correct. For programs that contain loops we are
therefore left with the separate but necessary task of proving that the
program terminates in order to establish total correctness.
Before considering in detail a method for proof of termination, we will
consider setting up the verification conditions for a program example that
employs an array.
1.5.7. Verification of program segments that employ arrays
The idea of symbolic execution developed in the preceding sections can be
extended to some of the simpler examples that employ arrays although it
now becomes necessary to account for the symbolic values of all array
elements. As an example of verification of a program segment containing an
array we will set up the verification conditions for a program that finds the
position of the smallest element in the array.
The program annotated with assertions may take the following form:
A {assert P,: n>1}
lL:
pial
B {invariant Ig: (1(1SB+158)A(1SySB+t1)A (S04, 35 «+45 p41)
VC(B-C): (1SB<5)A(1€ >0
The condition e=0 becomes an invariant of the loop.
In some instances, the invariant used for establishing partial cor-
rectness is not sufficient for use in a proof of termination. This problem
can be overcome by attaching additional conditions (derived from
earlier assertions) to the invariant.
The second proposition that must be proven is to show that the loop
invariant Ig, together with the condition for loop execution, Cz, implies
that the value €) of the expression before execution is strictly greater
than its value € after loop execution, ie. for a loop B
TC2(B-B): Ip\C5>(60>€)A(e=0)
The final value of € can be obtained by symbolic execution of the
statements in the loop.
Once these two propositions have been shown to be true, we can
immediately conclude that the repetition process is finite since ¢ can only be
decreased a finite number of times while remaining positive as required by
TC1(B). The considerations of termination for repeat... until loops follow a
similar line of reasoning.
A proof of termination for the quotient/remainder program given
below will now be outlined.
ri=x3q:= 0;
B {invariant I: r=0Ax = y*q+r}
while y