Creating A Health Data Management Platform Using Hadoop
Creating A Health Data Management Platform Using Hadoop
Volume 7, Issue 2, February – 2022 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165
Creating a Health Data Management
Platform using Hadoop
Atul Bengeri#1, Dr. Amol C Goje^1
#1
Chairman, Board of Studies, Healthcare Management, Savitribhai Phule Pune University, Pune, India
^1
Chairman, Board of Studies, Computer Management, Savitribhai Phule Pune University, Pune, India
Abstract:- Customary, conventional healthcare Database II. METHODOLOGY
Management Systems are used as a repository of data and
to process structured data efficiently, but in case of diverse There are some open source software like OpenEMR and
variety and huge volumes of data it becomes arduous to DHIS2.org that aid healthcare data management and analysis
handle such mammoth volumes. The question arises of by supporting various data visualization features such as
what and how to process such data from various sources Tables, Charts, Pivot Table. The basic idea to these software
which could be structured as well as unstructured and in a was to get a brief of the schema used in real world healthcare
distributed manner? Hadoop is open source framework, organizations. There are also various random data generating
based on distributed computing, which is capable of sites like mockaroo.com. The interesting part is to obtain data
storing and processing Big Data, which may comprise of from diverse, disparate and different sources to load it in the
structured, unstructured as well as semi-structured data. Hadoop Distributed File System (HDFS) through an ETL
In this paper, we summarize the basic operations (Extract Transform Load) process and then populate the data
performed on healthcare data in a Data Management using sql scripts, sql command or a sql procedure.
Lifecycle.
In our paper, we present a brief idea about how
Keywords:- Big Data, Data Analysis, Distributed Computing, management and analysis of Healthcare data can be done using
ETL Hadoop, Healthcare, MapReduce. Hadoop framework.
I. INTRODUCTION Section III provides a brief on the Literature Survey and the
related work done by various researchers across the world
Huge amounts of data get generated by the healthcare Section IV gives a brief overview of the ETL process.
providers from record keeping of patient related data, health Section V throws light on the System Architecture and the
and medical device data, data regarding drug research, health Hadoop Ecosystem components used in our system.
insurance data, images with graphic, audio and video data and Section VI provides the details of implementation.
of late, patient generated data as well. This data thus generated Section VII is about the technologies.
could be structured or unstructured. Big Data includes Section VIII provide inputs on the future scope and
handling both structured (RDBMS) and unstructured conclusion.
(multimedia, flat files) data. Big data is assuring a tremendous
revolution in healthcare with important advancements from III. LITERATURE SURVEY
management activities of chronic diseases to prediction of
disease in prior stages through the observation of the In the paper “Designing A Health Data Management
symptoms. Many healthcare organizations are bringing big System Based Hadoop-Agent” by Fadoua Khennou, et al., they
data into practice which is of prime focus for researchers. The have presented an e-healthcare framework for health data
main focus remains at leveraging healthcare data and management that links several numerous Electronic Medical
obtaining insights from it and make right decisions in Records (EMRs) implemented for all the health organizations
appropriate time. Hadoop, due to its distributive nature helps and an Electronic Health Record (EHR) date warehouse kind
in making information available to all its stakeholders of as a centralized system. They also attempt to provide a
instantly. solution to the technical glitches of storing, loading and
managing the health data using the Hadoop ecosystem
The management and analytics activities are performed framework. Furthermore, they have offered the theory of
using systemized collection of patient and population, intermediary agents with a purpose that could play a vital role
electronically stored health information in digital format in smooth sharing of the medical data across distinct
known as an Electronic Medical Record (EMR) or Electronic establishments.[1]
Health Record (EHR). These records can be shared across
various healthcare enterprises via a secured network. These Yang Jin, et al., in their paper “A Distributed Storage
records generally contain broad range and diverse set of facts Model for EHR Based on HBase” have suggested a distributed
and figures such as medical history of patient, demographical stowage for electronic healthcare record (EHR) which is based
information, medication and any specific allergy of patient, on HBase. This model consists of an electronic healthcare
immunization status, laboratory results, personal information record storage that is used to organize the data and two
like age and weight, vital signs, and billing information. Namenodes such that they respond to the list of relevant
DataNodes.[2]
IJISRT22FEB711 www.ijisrt.com 535
Volume 7, Issue 2, February – 2022 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165
of this transformation step is to ensure that all the data
In the paper, “Research and Implementation of Massive conforms to the tidy data principles and constitutes a dataset
Healthcare Data Management and Analysis Based on that can be referred to as a uniform schema.
Hadoop” by Hongyong Yu and Deshuai Wang, they deliberate
around the Big data management, its handling and analysis 3. Load- This phase of the ETL process involves the stacking
solution based on Hadoop to achieve better scalability without and loading of the altered, transformed data into the end
compromising on the performance outcomes and taking into system for analyzing by applying machine learning
account the fault tolerance. They also elucidate on the 2 techniques. In numerous organizations, the ETL process is an
different data analysis methods constructed upon MapReduce iterative practice which is performed regularly for the sake of
and Hive.[3]. keeping the data warehouse updated with the tardiest data to
ensure the authenticity and the veracity of the data in all
Mimoh Ojha, Dr. Kirti Mathur in the paper, “Proposed aspects.
Application of Big Data Analytics in Healthcare at Maharaja
Yeshwantrao Hospital” mostly address the challenges faced V. SYSTEM ARCHITECTURE
by doctors and patients while they attempt to provide solution
to these problems as well.[4]
In the paper of Thara D.K., Dr. Premasudha B.G., Ravi
Ram V, Suma R “Impact of Big Data in Healthcare: A
Survey”, they examine various investigative attempts made in
the healthcare domain using concepts and strategies of Big
Data. Among these things, this paper likewise provides an
acumen for the budding scholars to distinguish and recognize
the impact of Big Data on healthcare and seek evidence around
the meagre research efforts made in the field of healthcare
using Big Data thus far.[5]
IV. OVRVIEW OF THE ETL PROCESS
ETL is a model in the data warehousing technology that
deals with conjoining the data from various sources into data
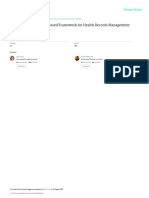
warehouse, data marts or relational database such that we can Fig 1
analyze the data for meaningful patterns and useful insights.
Heterogeneous data from diverse and disparate sources forms Handling diverse, disperate and voluminous data through
the input for the ETL to transform the data into standardized, conventional ETL or ELT datawarehouse process leads to
harmonized, homogeneous data. ETL process helps in were flaws related to handling Big data. A new distributed data
analysing heterogeneous data through an automated, storage and processing system known as Apache Hadoop has
programmatic and structured manner to derive business evolved over the years to not only provide a platform for
analysis and intelligence from it. storing and retrieving, but also for data evaluation and analysis
purposes. The data from various disperate data sources are
The robust data warehousing process of ETL consists of obtained and catalogued into different data repositories such
the usual three stages which can be interchanged to Extract, as Dataset1, Dataset2 and Dataset3 respectively. The
Load, Transform (ELT) process as well: catalogued, combined data is then imported into the Hadoop
framework using Flume or Sqoop. This approach of handling
1. Extract- This phase involves the mining or the extraction of Big data ETL circumscribes around Hadoop which is cost
data from disparate source systems. Common data-source effective and provides very efficient scalability and supple
formats include the flat files, relational databases, JSON and flexibility. The data in the Hadoop environment is processed
XML and they could possibly also include the unstructured much more effectively than RDBMS and that performs the
non-relational database structures too. The data thus extracted transformations efficiently.
from source systems can be used in multiple data warehouse,
data lake and data lakehouse systems. The Hadoop framework consists of the following
components:
2. Transform- In this phase of data transformation, wherein the
change or makeover of the data can be either constructive, Map Reduce is the default processing framework used
destructive, aesthetic or structural in nature. This is for writing applications to process in parallel and also used for
accomplished by a set of functions that get applied on the batch data processing.
extracted data (from the previous step) for the sake of
preparing the data which becomes suitable for analyzing by YARN is Yet Another Resource Negotiator that is used
loading onto the object target system. Some data may not not for resource allocation and management.
require any data manipulation or data transformation which is
recognized as direct move or pass through data. The objective HDFS is the distributed file system that is redundant in
IJISRT22FEB711 www.ijisrt.com 536
Volume 7, Issue 2, February – 2022 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165
nature and used by Hadoop to store the data show how healthcare related big data can be handled
effectively in Hadoop, for that the data collected from various
Hive is a data warehouse software project that provides sources needs to be populated. The volume of populated data
data summarization, query and analysis. needs to be at least in the range of terabytes. Various
techniques can be implemented to populate data such as by
The transformed data from Hadoop is then loaded into applying scripts, SQL queries or procedure. The populated
the data mart. The data in the data mart can be used for data is to be imported in HDFS using SQOOP, which is a tool
prediction purposes. for importing and exporting RDBMS data in HDFS.
Data so obtained from various sources must aim to VII. TECHNOLOGIES
possess the characteristics of big data, as elucidated below –
1] Volume: Enormous amounts of data is generated by the The healthcare data can be analysed using Hive. In Hive
healthcare organizations through numerous diverse sources. the data is stored in the form of tables. Various queries can be
Data generated by patient records, past medical history, processed on Hive using HiveQL, which is much similar to
diagnosis information and medical devices can be humongous SQL. Hive queries rely on Map Reduce jobs internally thereby
in size which can transcend into terabytes or petabytes or even reducing workload on developers to actually perform map
exabytes or zettabytes. reduce program. Although Hive performs efficiently, it is seen
2] Velocity: Different constituent divisions in the healthcare that its performance degrades for medium sized (10 to 200GB)
enterprises generate data simultaneously, which takes into data and it lacks resume capability.
account the speed of data generation and frequency of
delivery. The flow of data is massive and can be continuous It is an established fact that Big Data will help to
and is valuable for health analysts for making predictions of a revolutionize the way in which the healthcare organizations
possible illness, a disorder or a health condition. operate their clinical data in a more sophisticated way, obtain
3] Variety: As the name suggests, data so collected and meaningful insights from it and make good decisions as
collated can be either structured data or unstructured data or a compared to now. In near future we will see a lot of
mixed bag which may include flat files, spreadsheets, text, involvement of big data and Hadoop in healthcare
emails, photos, videos or even EMR and / or EHR too. organizations. This paper throws light on how Hadoop
4] Veracity: All the data so collated and collected has to be framework can be used in a cost effective manner for data
genuine and needs to be handled by the system. management and thus creating a platform ready for analysis on
5] Validity: In healthcare, data is mostly time dependent. healthcare data, utilizing the distributive computing nature and
Correct and accurate patient details should be made available its capability to handle heterogeneous data.
when needed.
6] Volatility: The record of the timeline on the validity of the VIII. CONCLUSIONS
data and the extent of time to which it is required to be stored
in the system. It is an established fact that Big Data will help to
revolutionize the way in which the healthcare organizations
VI. IMPLEMENTATION operate their clinical data in a more sophisticated way, obtain
meaningful insights from it and make good decisions as
For setting up of entire Hadoop multinode system, firstly compared to now. In near future we will see a lot of
installation of software packages is required from involvement of big data and Hadoop in healthcare
www.apache.org website. After the installation of packages, organizations. This paper throws light on how Hadoop
configuration of the xml files like coresite, mapred, hdfs-site, framework can be used in a cost effective manner for data
yarn is required along with setting of environment variables. management and thus creating a platform ready for analysis on
The default openjdk path is to be modified and is to be changed healthcare data, utilizing the distributive computing nature and
to default Hadoop’s path with correct specified version of jdk. its capability to handle heterogeneous data.
After single node cluster formation on different systems, we
need to link them in a way that forms master-slave REFERENCES
architecture. There are two types of nodes in cluster formation
i.e. Namenode and Datanode. Namenode acts as master node [1]. Fadoua Khennou, Youness Idrissi Khamlichi, and Nour
and there can be n number of datanodes. Namenode stores all El Houda Chaoui, “Designing A Health Data
the metadata of HDFS while all the actual data is stored in Management System Based Hadoop-Agent”, IEEE,
datanodes. Proper mapping of ip address and node in slave file 2016, pp. 71-76.
is to be done along with respective entries made in host file. [2]. Yang Jin, Tang Deyu, Zhou Yi, “A Distributed Storage
Model for EHR Based on HBase”, IEEE, 2011, pp. 369-
Sites like Dhis2.org and OpenEMR are some examples 372
from which sample data can be collected and which give a [3]. Hongyong Yu, Deshuai Wang, “Research and
brief overview of the schema that is suggestive in a healthcare Implementation of Massive Healthcare Data
management software. The examples can be used as reference Management and Analysis Based on Hadoop”, IEEE,
for building a prototypical schema design. Dhis2.org provides 2012, pp. 514-517
sample data in PostgreSQL database while OpenEMR [4]. Mimoh Ojha, Dr. Kirti Mathur, “Proposed Application of
provides sample data in SQL database. The main aim is to Big Data Analytics in Healthcare at Maharaja
IJISRT22FEB711 www.ijisrt.com 537
Volume 7, Issue 2, February – 2022 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165
Yeshwantrao Hospital”, IEEE, 2016
[5]. Thara D.K., Dr. Premasudha B.G., Ravi Ram V, Suma
R, “Impact of Big Data in Healthcare: A Survey”, IEEE,
2016, pp. 729-735
[6]. Mukesh Borana, Manish Giri, Sarang Kamble, Kiran
Deshpande, Shubhangi Edake, “Healthcare Data
Analysis using Hadoop”, IRJET, Vol-2 Issue-7, Oct-
2015, pp. 583-586