0% found this document useful (0 votes)
69 views9 pages1 Simple Linear Regression
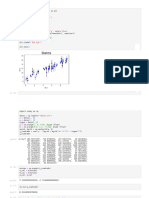
The document discusses analyzing the relationship between waist circumference (Waist) and abdominal adipose tissue (AT) using Python. It loads waist and AT data from a CSV file into a Pandas dataframe. It then: 1) Plots a scatter plot of Waist vs AT and calculates their correlation; 2) Fits linear regression models to predict AT from Waist; 3) Splits data into train and test sets for model validation; 4) Trains a linear regression model on the train set and uses it to predict AT on the test set.
Uploaded by
venkatesh mCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
69 views9 pages1 Simple Linear Regression
The document discusses analyzing the relationship between waist circumference (Waist) and abdominal adipose tissue (AT) using Python. It loads waist and AT data from a CSV file into a Pandas dataframe. It then: 1) Plots a scatter plot of Waist vs AT and calculates their correlation; 2) Fits linear regression models to predict AT from Waist; 3) Splits data into train and test sets for model validation; 4) Trains a linear regression model on the train set and uses it to predict AT on the test set.
Uploaded by
venkatesh mCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 9