0% found this document useful (0 votes)
172 views10 pagesActivation Functions in Neural Networks
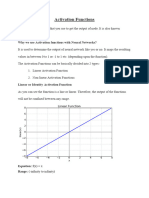
Activation functions are used in neural networks to determine the output of a node. There are two main types: linear and non-linear. Non-linear functions like sigmoid, tanh, ReLU, and leaky ReLU are most commonly used as they allow the network to learn complex patterns in data. These functions map input values to an output range and have specific properties like being monotonic or differentiable that make them suitable for training neural networks.
Uploaded by
isha.kapoor.cse.2021Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
172 views10 pagesActivation Functions in Neural Networks
Activation functions are used in neural networks to determine the output of a node. There are two main types: linear and non-linear. Non-linear functions like sigmoid, tanh, ReLU, and leaky ReLU are most commonly used as they allow the network to learn complex patterns in data. These functions map input values to an output range and have specific properties like being monotonic or differentiable that make them suitable for training neural networks.
Uploaded by
isha.kapoor.cse.2021Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 10