SSMDA Notes Unit 2
Uploaded by
sehor15182SSMDA Notes Unit 2
Uploaded by
sehor15182lOMoARcPSD|44438987
Unit - II
Statistical Modeling
Statistical modeling is a process of using statistical techniques to describe,
analyze, and make predictions about relationships and patterns within data. It
involves formulating mathematical models that represent the underlying structure
of data and capturing the relationships between variables. Statistical models are
used to test hypotheses, make predictions, and infer information about
populations based on sample data. Statistical modeling is widely employed across
various disciplines, including economics, finance, biology, sociology, and
engineering, to understand complex phenomena and inform decision-making.
Key Concepts:
Model Formulation:
Model formulation involves specifying the mathematical relationship
between variables based on theoretical understanding, empirical
evidence, or domain knowledge.
The choice of model depends on the nature of the data, the research
question, and the assumptions underlying the modeling process.
Parameter Estimation:
Parameter estimation involves determining the values of model parameters
that best fit the observed data.
Estimation techniques include maximum likelihood estimation, method of
moments, least squares estimation, and Bayesian inference.
Model Evaluation:
Model evaluation assesses the adequacy of the model in representing the
data and making predictions.
Techniques for model evaluation include goodness-of-fit tests, diagnostic
plots, cross-validation, and information criteria such as AIC Akaike
Information Criterion) and BIC Bayesian Information Criterion).
Model Selection:
Statistics, Statistical Modelling & Data Analytics 41
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Model selection involves comparing multiple candidate models to
determine the most appropriate model for the data.
Criteria for model selection include simplicity Occam's razor), goodness-
of-fit, and predictive performance.
Inference and Prediction:
Inference involves using the fitted model to draw conclusions about
population parameters and test hypotheses.
Prediction involves using the model to forecast future observations or
estimate unobserved values.
Types of Statistical Models:
Linear Regression Models: Used to model the relationship between one or
more independent variables and a continuous dependent variable.
Logistic Regression Models: Used for binary classification problems where
the dependent variable is binary or categorical.
Time Series Models: Used to analyze and forecast time-dependent data,
including autoregressive AR, moving average MA, and autoregressive
integrated moving average ARIMA models.
Generalized Linear Models GLMs): Extensions of linear regression models
that accommodate non-normal response variables and non-constant variance.
Survival Analysis Models: Used to analyze time-to-event data, such as time
until death or failure, using techniques like Kaplan-Meier estimation and Cox
proportional hazards models.
Applications:
Econometrics: Statistical modeling is used in econometrics to analyze
economic relationships, forecast economic indicators, and evaluate the impact
of policies and interventions.
Marketing and Customer Analytics: Statistical models are used in marketing
to segment customers, predict consumer behavior, and optimize marketing
strategies and campaigns.
Statistics, Statistical Modelling & Data Analytics 42
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Healthcare and Epidemiology: Statistical modeling is applied in healthcare to
analyze patient outcomes, model disease progression, and assess the
effectiveness of treatments and interventions.
Environmental Science: Statistical models are used in environmental science
to analyze environmental data, model ecological systems, and assess the
impact of human activities on the environment.
Example:
Suppose a pharmaceutical company wants to develop a statistical model to
predict the effectiveness of a new drug in treating a particular medical condition.
They collect data on patient characteristics, disease severity, treatment dosage,
and treatment outcomes from clinical trials.
Using statistical modeling:
The company formulates a regression model to predict treatment outcomes
based on patient characteristics and treatment variables.
They estimate the model parameters using maximum likelihood estimation or
least squares estimation.
The model is evaluated using goodness-of-fit tests and cross-validation
techniques to assess its predictive performance.
Once validated, the model can be used to predict treatment outcomes for new
patients and inform clinical decision-making.
By employing statistical modeling techniques, the pharmaceutical company can
improve treatment decision-making, optimize treatment protocols, and develop
more effective therapies for patients.
Statistical modeling provides a powerful framework for understanding complex
relationships in data, making predictions, and informing decision-making across
various domains. It enables researchers and practitioners to extract valuable
insights from data and derive actionable conclusions to address real-world
problems.
Analysis of Variance (ANOVA)
Statistics, Statistical Modelling & Data Analytics 43
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
watch: https://www.khanacademy.org/math/statistics-probability/analysis-of-
variance-anova-library/analysis-of-variance-anova/v/anova-1-calculating-sst-
total-sum-of-squares
https://youtu.be/0Vj2V2qRU10?si=1ZGk9n7xTUk9yE8t
Analysis of variance ANOVA is a statistical technique used to analyze differences
between two or more groups or treatments by comparing the variability within
groups to the variability between groups. ANOVA allows researchers to determine
whether there are significant differences in means among groups and to
understand the sources of variability in a dataset. It is a powerful tool for
hypothesis testing and is widely used in various fields for experimental design,
data analysis, and inference.
Key Concepts:
Variability:
ANOVA decomposes the total variability in a dataset into two components:
variability between groups and variability within groups.
Variability between groups reflects differences in means among the
groups being compared.
Variability within groups represents random variation or error within each
group.
Hypothesis Testing:
ANOVA tests the null hypothesis that the means of all groups are equal
against the alternative hypothesis that at least one group mean is different.
The test statistic used in ANOVA is the F-statistic, which compares the
ratio of between-group variability to within-group variability.
Types of ANOVA
One-Way ANOVA Used when comparing the means of two or more
independent groups or treatments.
Two-Way ANOVA Extends one-way ANOVA to analyze the effects of two
categorical independent variables (factors) on a continuous dependent
variable.
Statistics, Statistical Modelling & Data Analytics 44
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Multi-Way ANOVA Allows for the analysis of the effects of multiple
categorical independent variables on a continuous dependent variable.
Assumptions:
ANOVA assumes that the data within each group are normally distributed,
the variances of the groups are homogeneous (equal), and the
observations are independent.
Applications in Various Fields:
Experimental Design in Science: ANOVA is commonly used in scientific
research to compare the effects of different treatments or interventions on
experimental outcomes. It is used in fields such as biology, chemistry, and
medicine to analyze experimental data and identify significant treatment
effects.
Quality Control in Manufacturing: ANOVA is used in manufacturing and
engineering to assess the variability in production processes and identify
factors that affect product quality. It helps identify sources of variation and
optimize production processes to improve product consistency and reliability.
Social Sciences and Education: ANOVA is applied in social science research,
psychology, and education to analyze survey data, experimental studies, and
observational studies. It is used to compare the effectiveness of different
teaching methods, interventions, or treatment programs on student outcomes.
Market Research and Consumer Behavior: ANOVA is used in market research
to analyze consumer preferences, product testing, and advertising
effectiveness. It helps businesses understand the impact of marketing
strategies and product features on consumer behavior and purchase
decisions.
Agricultural Research: ANOVA is used in agriculture to compare the effects of
different fertilizers, irrigation methods, and crop varieties on crop yields. It
helps farmers and agricultural researchers identify optimal growing conditions
and practices to maximize agricultural productivity.
Example:
Suppose a researcher wants to compare the effectiveness of three different
training programs on employee performance. They randomly assign employees to
Statistics, Statistical Modelling & Data Analytics 45
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
three groups: Group A receives training program 1, Group B receives training
program 2, and Group C receives training program 3.
Using ANOVA
The researcher collects performance data from each group and conducts a
one-way ANOVA to compare the mean performance scores across the three
groups.
If the ANOVA results indicate a significant difference in mean performance
scores among the groups, post-hoc tests (e.g., Tukey's HSD can be
conducted to identify specific pairwise differences between groups.
By using ANOVA, the researcher can determine whether there are significant
differences in performance outcomes among the training programs and make
informed decisions about which program is most effective for improving employee
performance.
Analysis of variance is a versatile statistical technique with widespread
applications in experimental design, quality control, social sciences, and many
other fields. It provides valuable insights into group differences and helps
researchers draw meaningful conclusions from their data.
Here's a simplified explanation:
Analysis of Variance ANOVA
1. Variability:
ANOVA breaks down the total variation in data into two parts:
Variation between groups: Differences in means among groups or
treatments.
Variation within groups: Random variation or error within each group.
It's like comparing how much people in different classes score on a test
compared to how much each person's score varies within their own class.
Statistics, Statistical Modelling & Data Analytics 46
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
2. Hypothesis Testing:
ANOVA checks if there are significant differences in means among groups.
It uses the F-statistic, which compares the variability between groups to the
variability within groups.
For instance, it's like seeing if there's a big difference in test scores between
classes compared to how much scores vary within each class.
3. Types of ANOVA
One-Way ANOVA Compares means of different groups or treatments.
Two-Way ANOVA Considers the effects of two factors on a variable.
Multi-Way ANOVA Looks at the effects of multiple factors.
For example, it's like comparing test scores based on different teaching
methods (one-way) or considering both teaching method and study time (two-
way).
4. Assumptions:
ANOVA assumes data in each group are normally distributed, group variances
are equal, and observations are independent.
Imagine it as assuming each class's test scores follow a bell curve, have
similar spreads, and aren't influenced by other classes.
Statistics, Statistical Modelling & Data Analytics 47
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Applications:
Science: Compares effects of treatments in experiments.
Manufacturing: Identifies factors affecting product quality.
Education: Assesses effectiveness of teaching methods.
Market Research: Analyzes consumer preferences.
Agriculture: Evaluates effects of farming practices.
Example:
Imagine comparing test scores of students in three different study groups.
ANOVA tells if there's a significant difference in scores among groups.
If significant, further tests reveal which groups differ from each other.
In summary, ANOVA helps understand differences between groups or treatments
by comparing their variability. It's like comparing apples, oranges, and bananas to
see which one people prefer, while also considering how much individuals within
each group like the fruit.
Gauss-Markov Theorem
The Gauss-Markov theorem, also known as the Gauss-Markov linear model
theorem, is a fundamental result in the theory of linear regression analysis. It
provides conditions under which the ordinary least squares OLS estimator is the
best linear unbiased estimator BLUE of the coefficients in a linear regression
model. The theorem plays a crucial role in understanding the properties of OLS
estimation and the efficiency of estimators in the context of linear regression.
Key Concepts:
Linear Regression Model:
In a linear regression model, the relationship between the dependent
variable Y and one or more independent variables X is assumed to be
linear.
The model is expressed as Y β0 β1X1 β2X2 ... + βkXk + ε, where
β0, β1, β2, ..., βk are the coefficients, X1, X2, ..., Xk are the independent
Statistics, Statistical Modelling & Data Analytics 48
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
variables, and ε is the error term.
Ordinary Least Squares OLS Estimation:
OLS estimation is a method used to estimate the coefficients of a linear
regression model by minimizing the sum of squared residuals (differences
between observed and predicted values).
The OLS estimator provides estimates of the coefficients that best fit the
observed data points in a least squares sense.
Gauss-Markov Theorem:
The Gauss-Markov theorem states that under certain conditions, the OLS
estimator is the best linear unbiased estimator BLUE of the coefficients in
a linear regression model.
Specifically, if the errors (residuals) in the model have a mean of zero, are
uncorrelated, and have constant variance (homoscedasticity), then the
OLS estimator is unbiased and has minimum variance among all linear
unbiased estimators.
Properties of OLS Estimator:
The Gauss-Markov theorem ensures that the OLS estimator is unbiased,
meaning that it provides estimates that, on average, are equal to the true
population parameters.
Additionally, the OLS estimator is efficient in the sense that it achieves the
smallest possible variance among all linear unbiased estimators, making it
the most precise estimator under the specified conditions.
Applications and Importance:
Econometrics: The Gauss-Markov theorem is widely used in econometrics to
estimate parameters in linear regression models, analyze economic
relationships, and make predictions about economic variables.
Social Sciences: The theorem is applied in social science research to model
and analyze relationships between variables in areas such as sociology,
psychology, and political science.
Statistics, Statistical Modelling & Data Analytics 49
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Engineering and Sciences: In engineering and scientific disciplines, the
theorem is used to estimate parameters in mathematical models, analyze
experimental data, and make predictions about physical systems.
Finance and Business: In finance and business analytics, the theorem is used
to model relationships between financial variables, forecast future trends, and
assess the impact of business decisions.
Example:
Suppose a researcher wants to estimate the relationship between advertising
spending X and sales revenue Y for a particular product. They collect data on
advertising expenditures and corresponding sales revenue for several months and
fit a linear regression model to the data using OLS estimation.
Using the Gauss-Markov theorem:
If the assumptions of the theorem hold (e.g., errors have zero mean, are
uncorrelated, and have constant variance), then the OLS estimator provides
unbiased and efficient estimates of the regression coefficients.
The researcher can use the OLS estimates to assess the impact of advertising
spending on sales revenue and make predictions about future sales based on
advertising budgets.
By applying the Gauss-Markov theorem, researchers can ensure that their
regression estimates are statistically valid and provide reliable insights into the
relationships between variables.
In summary, the Gauss-Markov theorem is a fundamental result in linear
regression analysis that establishes the properties of the OLS estimator under
certain conditions. It provides a theoretical foundation for regression analysis and
ensures that OLS estimation produces unbiased and efficient estimates of
regression coefficients when the underlying assumptions are met.
Let's break it down into simpler terms:
The Gauss-Markov Theorem Explained Like You're Five:
What's a Linear Regression Model?
Statistics, Statistical Modelling & Data Analytics 50
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Imagine you have a bunch of points on a graph, and you want to draw a
straight line that goes through them as best as possible. That's what a
linear regression model does. It helps us understand how one thing (like
how much we spend on advertising) affects another thing (like how much
stuff we sell).
What's Ordinary Least Squares OLS Estimation?
OLS is like drawing that line through the points by minimizing the distance
between the line and each point. It's like trying to draw the best line that
gets as close as possible to all the points.
The Gauss-Markov Theorem:
This is a fancy rule that says if we follow certain rules when drawing our
line (like making sure the errors are not too big and don't have any
patterns), then the line we draw using OLS will be the best one we can
make. It's like saying, "If we play by the rules, the line we draw will be the
most accurate one."
Why is this Important?
It's like having a superpower when we're trying to understand how things
are connected. We can trust that the line we draw using OLS will give us
the best idea of how one thing affects another thing. This helps us make
better predictions and understand the world around us.
Examples:
Let's say you're trying to figure out if eating more vegetables makes you grow
taller. You collect data from a bunch of kids and use OLS to draw a line
showing how eating veggies affects height. The Gauss-Markov theorem tells
you that if you follow its rules, that line will be the most accurate prediction of
how veggies affect height.
Or imagine you're a scientist studying how temperature affects how fast ice
cream melts. By following the rules of the Gauss-Markov theorem when using
OLS, you can trust that the line you draw will give you the best understanding
of how temperature affects melting speed.
In simple terms, the Gauss-Markov theorem is like a set of rules that, when
followed, help us draw the best line to understand how things are connected in the
Statistics, Statistical Modelling & Data Analytics 51
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
world. It's like having a secret tool that helps us make really good guesses about
how things work!
Geometry of Least Squares
watch: https://www.youtube.com/watch?
v=8o5Cmfpeo6g&list=PLE7DDD91010BC51F8&index=7&pp=iAQB
https://www.youtube.com/watch?
v=osh80YCg_GM&list=PLE7DDD91010BC51F8&index=17&pp=iAQB
The geometry of least squares provides a geometric interpretation of the ordinary
least squares OLS estimation method used in linear regression analysis. It offers
insight into how OLS estimation works geometrically by visualizing the relationship
between the observed data points and the fitted regression line. Understanding
the geometry of least squares helps in grasping the intuition behind the OLS
estimator and its properties.
Key Concepts:
Data Points and Regression Line:
In a simple linear regression model with one independent variable, the
observed data consists of pairs (xᵢ, yᵢ) where xᵢ is the independent variable
and yᵢ is the dependent variable for each observation i.
The OLS regression line is the line that best fits the observed data points
by minimizing the sum of squared vertical distances (residuals) between
the observed yᵢ values and the corresponding predicted values on the
regression line.
Residuals and Orthogonality:
The residual for each observation is the vertical distance between the
observed yᵢ value and the predicted value on the regression line.
In the geometry of least squares, the OLS regression line is constructed
such that the sum of squared residuals is minimized, making the residuals
orthogonal (perpendicular) to the regression line.
Projection onto Regression Line:
Statistics, Statistical Modelling & Data Analytics 52
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Each observed data point (xᵢ, yᵢ) can be projected onto the regression line
to obtain the predicted value ȳᵢ.
The vertical distance between the observed data point and its projection
onto the regression line represents the residual for that observation.
Minimization of Residuals:
The OLS estimation method minimizes the sum of squared residuals,
which corresponds to finding the regression line that minimizes the
perpendicular distances between the observed data points and the
regression line.
Geometrically, this minimization problem is equivalent to finding the
regression line that maximizes the vertical distance (orthogonal projection)
between the observed data points and the line.
Applications and Importance:
Visualization of Regression Analysis: The geometry of least squares
provides a visual representation of how the OLS regression line is fitted to the
observed data points, making it easier to understand the estimation process
intuitively.
Assessment of Model Fit: Geometric insights can help assess the adequacy
of the regression model by examining the distribution of residuals around the
regression line. A good fit is indicated by residuals that are randomly scattered
around the line with no discernible pattern.
Understanding OLS Properties: The geometric interpretation helps in
understanding the properties of OLS estimation, such as the minimization of
the sum of squared residuals and the orthogonality of residuals to the
regression line.
Diagnostic Checks: Geometric intuition can aid in diagnosing potential issues
with the regression model, such as outliers, influential observations, or
violations of regression assumptions, by examining the pattern of residuals
relative to the regression line.
Example:
Statistics, Statistical Modelling & Data Analytics 53
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Consider a scatterplot of data points representing the relationship between hours
of study (xᵢ) and exam scores (yᵢ) for a group of students. The OLS regression line
is fitted to the data points such that it minimizes the sum of squared vertical
distances between the observed exam scores and the predicted scores on the
line.
Using the geometry of least squares:
Each observed data point can be projected onto the regression line to obtain
the predicted exam score.
The vertical distance between each data point and its projection onto the
regression line represents the residual for that observation.
The OLS regression line is chosen to minimize the sum of squared residuals,
ensuring that the residuals are orthogonal to the line.
By understanding the geometry of least squares, analysts can gain insights into
how the OLS estimator works geometrically, facilitating better interpretation and
application of regression analysis in various fields.
In summary, the geometry of least squares provides a geometric perspective on
the OLS estimation method in linear regression analysis. It visualizes the
relationship between observed data points and the fitted regression line, aiding in
understanding OLS properties, model diagnostics, and interpretation of regression
results.
other way:
Statistics, Statistical Modelling & Data Analytics 54
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Statistics, Statistical Modelling & Data Analytics 55
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Subspace Formulation of Linear Models
Statistics, Statistical Modelling & Data Analytics 56
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
The subspace formulation of linear models provides an alternative perspective on
linear regression analysis by framing it within the context of vector spaces and
subspaces. This formulation emphasizes the linear algebraic structure underlying
linear models, facilitating a deeper understanding of their properties and
relationships.
Key Concepts:
Vector Space Representation:
In the subspace formulation, the observed data points and regression
coefficients are represented as vectors in a high-dimensional vector
space.
Each observed data point corresponds to a vector in the space, where the
components represent the values of the independent variables.
The regression coefficients are also represented as a vector in the space,
with each component corresponding to the coefficient of an independent
variable.
Subspaces and Basis Vectors:
A subspace is a subset of a vector space that is closed under addition and
scalar multiplication.
In the context of linear models, the space spanned by the observed data
points is the data subspace, while the space spanned by the regression
coefficients is the coefficient subspace.
Basis vectors are vectors that span a subspace, meaning that any vector in
the subspace can be expressed as a linear combination of the basis
vectors.
Projection and Residuals:
The projection of a data point onto the coefficient subspace represents the
predicted response value for that data point based on the linear model.
The difference between the observed response value and the projected
value is the residual, representing the error or discrepancy between the
observed data and the model prediction.
Statistics, Statistical Modelling & Data Analytics 57
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Orthogonal Decomposition:
The subspace formulation allows for the orthogonal decomposition of the
data space into the coefficient subspace and its orthogonal complement,
the residual subspace.
This decomposition provides a geometric interpretation of the regression
model, where the data subspace is decomposed into the fitted model
space (coefficient subspace) and the error space (residual subspace).
Applications and Importance:
Geometric Interpretation: The subspace formulation provides a geometric
interpretation of linear regression analysis, illustrating how the observed data
points are projected onto the coefficient subspace to obtain the model
predictions.
Model Decomposition: By decomposing the data space into the coefficient
subspace and residual subspace, the subspace formulation helps in
understanding the structure of linear models and the sources of variability in
the data.
Basis Selection: In the context of high-dimensional data, selecting an
appropriate basis for the coefficient subspace can help reduce the
dimensionality of the regression model and improve interpretability.
Regularization Techniques: Techniques such as ridge regression and Lasso
regression can be framed within the subspace formulation framework, where
they correspond to imposing constraints on the coefficients or modifying the
basis vectors.
Example:
Consider a simple linear regression model with one independent variable (x) and
one dependent variable (y). The subspace formulation represents the observed
data points (xᵢ, yᵢ) as vectors in a two-dimensional space, where xᵢ is the
independent variable value and yᵢ is the corresponding dependent variable value.
Using the subspace formulation:
The coefficient subspace is spanned by the regression coefficient vector,
representing the slope of the regression line.
Statistics, Statistical Modelling & Data Analytics 58
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
The data subspace is spanned by the observed data points, representing the
space of possible values for the dependent variable given the independent
variable.
The regression line is the projection of the data subspace onto the coefficient
subspace, representing the best linear approximation to the relationship
between x and y.
By understanding the subspace formulation of linear models, analysts can gain
insights into the geometric structure of regression analysis, facilitating
interpretation, model diagnostics, and further developments in the field.
In summary, the subspace formulation of linear models provides a valuable
framework for understanding regression analysis from a geometric perspective,
emphasizing the linear algebraic structure underlying linear models and their
relationship to vector spaces and subspaces.
Let's break down some fundamental concepts in linear algebra in an easy-to-
understand manner:
Vectors:
A vector is a mathematical object that has both magnitude and direction.
In simple terms, it's like an arrow with a certain length and direction in
space.
Vectors are often represented as ordered lists of numbers or as geometric
objects in space.
For example, in 2D space, a vector can be represented as (x , y) are the
components of the vector along the x-axis and y-axis, respectively.
Subspaces:
A subspace is a subset of a vector space that is closed under addition and
scalar multiplication.
In other words, it contains all linear combinations of its vectors.
For example, in 2D space, a line passing through the origin is a subspace,
as it contains all scalar multiples of its direction vector.
Statistics, Statistical Modelling & Data Analytics 59
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Basis:
A basis for a vector space is a set of vectors that are linearly independent
and span the space.
Linear independence means that none of the vectors in the basis can be
expressed as a linear combination of the others.
Spanning means that every vector in the space can be expressed as a
linear combination of the basis vectors.
For example, in 2D space, the vectors 1,0 and 0,1 form a basis, as they
are linearly independent and can represent any vector in the plane.
Linear Independence:
A set of vectors is linearly independent if no vector in the set can be
expressed as a linear combination of the others.
In other words, none of the vectors in the set "redundantly" contribute to
the span of the space.
For example, in 2D space, the vectors 1,0 and 0,1 are linearly
independent because neither can be written as a scalar multiple of the
other.
Understanding these concepts lays a strong foundation for more advanced topics
in linear algebra and helps in solving problems involving vectors, subspaces, and
linear transformations.
Statistics, Statistical Modelling & Data Analytics 60
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Orthogonal Projections
https://youtu.be/5B8XluiqdHM?si=uvhg24qroSLd-k-
Orthogonal projections are a fundamental concept in linear algebra and geometry,
particularly in the context of vector spaces and subspaces. An orthogonal
projection represents the process of projecting one vector onto another vector in
a way that minimizes the distance between them and preserves orthogonality
(perpendicularity). Orthogonal projections have wide-ranging applications in
various fields, including linear regression analysis, signal processing, computer
graphics, and physics.
Key Concepts:
Statistics, Statistical Modelling & Data Analytics 61
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Applications:
Linear Regression Analysis: In linear regression, orthogonal projections are
used to project the observed data onto the space spanned by the regression
coefficients, enabling the estimation of the regression parameters.
Signal Processing: Orthogonal projections are employed in signal processing
for noise reduction, signal denoising, and signal decomposition using
techniques such as principal component analysis PCA and singular value
decomposition SVD.
Computer Graphics: In computer graphics, orthogonal projections are used to
project three-dimensional objects onto a two-dimensional screen, enabling
rendering and visualization of 3D scenes.
Statistics, Statistical Modelling & Data Analytics 62
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Physics: Orthogonal projections are utilized in physics for analyzing vectors in
multi-dimensional spaces, such as in quantum mechanics, where projections
onto certain subspaces represent observable quantities.
Example:
In summary, orthogonal projections are a fundamental concept in linear algebra
and geometry, with wide-ranging applications across
Orthogonal Projections in Regression Models
In the context of regression models, orthogonal projections play a crucial role in
understanding the relationship between predictor variables and response
variables. Orthogonal projections are utilized to estimate regression coefficients,
assess model fit, and diagnose potential issues in the regression analysis.
Key Concepts:
Projection of Data onto Model Space:
In regression analysis, the observed data points are projected onto the
model space defined by the regression coefficients.
Statistics, Statistical Modelling & Data Analytics 63
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
The goal is to find the best-fitting regression line or hyperplane that
minimizes the sum of squared residuals, which represents the orthogonal
distances between observed data points and the model.
Orthogonality of Residuals:
In a well-fitted regression model, the residuals (the differences between
observed and predicted values) are orthogonal to the model space.
This orthogonality property ensures that the model captures as much
variability in the data as possible, with the residuals representing the
unexplained variation.
Least Squares Estimation:
Orthogonal projections are central to the least squares estimation method
used in regression analysis.
The least squares criterion aims to minimize the sum of squared residuals,
which is equivalent to finding the orthogonal projection of the data onto
the model space.
Orthogonal Decomposition:
Regression analysis involves decomposing the total variability in the
response variable into components that can be attributed to the predictor
variables and the error term.
Orthogonal decomposition separates the model space (spanned by the
predictor variables) from the residual space (representing unexplained
variation), providing insights into the contributions of each component to
the overall variability.
Applications:
Estimation of Regression Coefficients:
Orthogonal projections are used to estimate the regression coefficients by
projecting the observed data onto the model space defined by the
predictor variables.
The estimated coefficients represent the best-fitting linear combination of
the predictor variables that explain the variation in the response variable.
Statistics, Statistical Modelling & Data Analytics 64
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Assessment of Model Fit:
Orthogonal projections are employed to assess the goodness of fit of the
regression model by examining the pattern of residuals relative to the
model space.
A well-fitted model exhibits residuals that are orthogonal to the model
space, indicating that the model captures the underlying relationship
between predictor and response variables.
Diagnosis of Model Assumptions:
Orthogonal projections are used to diagnose potential violations of
regression assumptions, such as linearity, homoscedasticity, and
independence of errors.
Deviations from orthogonality in the residuals may indicate issues with
model specification or violations of underlying assumptions.
Example:
Consider a simple linear regression model with one predictor variable X and one
response variable Y. The goal is to estimate the regression coefficients
(intercept and slope) that best describe the relationship between X and Y.
Using least squares estimation:
The observed data points Xᵢ, Yᵢ) are projected onto the model space spanned
by the predictor variable X.
The regression coefficients are estimated by minimizing the sum of squared
residuals, which corresponds to finding the orthogonal projection of the data
onto the model space.
The estimated coefficients represent the best-fitting linear relationship
between X and Y that minimizes the discrepancy between observed and
predicted values.
By leveraging orthogonal projections, regression analysis provides a robust
framework for modeling relationships between variables, estimating parameters,
and making predictions in various fields, including economics, finance,
psychology, and engineering.
Statistics, Statistical Modelling & Data Analytics 65
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Factorial Experiments
What are Factorial Experiments?
Imagine you're doing a science experiment where you want to see how
different things affect a plant's growth, like temperature and humidity.
Instead of just changing one thing at a time, like only changing the
temperature or only changing the humidity, you change both at the same time
in different combinations.
So, you might have some plants in high temperature and high humidity, some
in high temperature and low humidity, and so on. Each of these combinations
is called a "treatment condition."
Key Concepts:
Factorial Design:
This just means you're changing more than one thing at a time in your
experiment.
For example, in our plant experiment, we're changing both temperature
and humidity simultaneously.
Each combination of different levels of temperature and humidity forms a
treatment condition.
Main Effects:
This is like looking at how each thing you change affects the plant's
growth on its own, without considering anything else.
So, we'd look at how temperature affects the plant's growth, ignoring
humidity, and vice versa.
Interaction Effects:
Sometimes, how one thing affects the plant depends on what's happening
with the other thing.
For example, maybe high temperature helps the plant grow more, but only
if the humidity is also high. If the humidity is low, high temperature might
not make much difference.
Statistics, Statistical Modelling & Data Analytics 66
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
These interactions tell us that the combined effect of temperature and
humidity is different from just adding up their individual effects.
Factorial Notation:
This is just a fancy way of writing down what you're doing in your
experiment.
For example, if you have two factors, like temperature and humidity, each
with two levels (high and low), you'd write it as a "22" factorial design.
Advantages:
Efficiency:
You can learn more from your experiment by changing multiple things at
once, rather than doing separate experiments for each factor.
Comprehensiveness:
Factorial designs give you a lot of information about how different factors
affect your outcome, including main effects and interaction effects.
Flexibility:
You can study real-world situations where lots of things are changing at
once, like in nature or in product development.
Applications:
Factorial experiments are used in lots of fields, like:
Making better products
Improving medical treatments
Growing crops more efficiently
Understanding human behavior and thinking
Example:
In our plant experiment, we're changing both temperature and humidity to see
how they affect plant growth. By looking at the growth rates of plants under
different conditions, we can figure out how each factor affects growth on its
own and if their effects change when they're combined.
Statistics, Statistical Modelling & Data Analytics 67
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
In simple terms, factorial experiments help scientists understand how different
things work together to affect outcomes, like how temperature and humidity
together affect plant growth. It's like doing a puzzle where you change more than
one piece at a time to see how the whole picture changes!
Analysis of Covariance (ANCOVA) and Model
Formulae
https://youtu.be/0e8BI2u6DU0?si=92sxkPza4bXLNzhY
Analysis of Covariance ANCOVA is a statistical technique used to compare group
means while statistically controlling for the effects of one or more covariates. It
extends the principles of analysis of variance ANOVA by incorporating
continuous covariates into the analysis, allowing for a more accurate assessment
of group differences. Model formulae in ANCOVA specify the relationship between
the dependent variable, independent variables (factors), covariates, and error
term in the statistical model.
Key Concepts:
ANOVA vs. ANCOVA
In ANOVA, group means are compared based on categorical independent
variables (factors) while ignoring continuous covariates.
In ANCOVA, group means are compared while statistically adjusting for the
effects of one or more continuous covariates. This adjustment helps
reduce error variance and increase the sensitivity of the analysis.
Model Formula:
The general model formula for ANCOVA is:
Statistics, Statistical Modelling & Data Analytics 68
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Assumptions:
ANCOVA assumes that the relationship between the dependent variable
and covariate(s) is linear.
It also assumes homogeneity of regression slopes, meaning that the
relationship between the dependent variable and covariate(s) is the same
across groups.
Hypothesis Testing:
Hypothesis tests in ANCOVA evaluate the significance of group
differences in the dependent variable after adjusting for the effects of
covariates.
The main focus is typically on testing the significance of group means
(factor effects) while controlling for covariates.
Applications:
Clinical Trials: ANCOVA is used in clinical trials to compare treatment groups
while controlling for baseline differences in covariates such as age, gender, or
disease severity.
Education Research: ANCOVA is employed in education research to assess
the effectiveness of different teaching methods or interventions while
controlling for pre-existing differences in student characteristics.
Psychological Studies: ANCOVA is utilized in psychological studies to
examine group differences in outcome measures while adjusting for covariates
such as personality traits or intelligence.
Statistics, Statistical Modelling & Data Analytics 69
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Biomedical Research: ANCOVA is applied in biomedical research to compare
biological markers or clinical outcomes among patient groups while
accounting for relevant covariates such as BMI or blood pressure.
In summary, ANCOVA allows researchers to compare group means while
accounting for the influence of covariates, providing a more accurate assessment
of group differences in various research settings. The model formula specifies the
relationship between the dependent variable, independent variables, covariates,
and error term in the ANCOVA analysis.
Lets see in a easier way:
Analysis of Covariance ANCOVA is a method to compare groups while making
sure other factors don't mess up our results.
Imagine this:
You want to compare two groups, like students who study with Method 1 and
students who study with Method 2, to see if one method is better for test
Statistics, Statistical Modelling & Data Analytics 70
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
scores.
But there's a twist! You also know that students' scores before the test (let's
call them "pre-test scores") might affect their test scores.
ANCOVA helps us compare the groups while considering these pre-test
scores, so we can be more confident in our results.
Here's how it works:
ANCOVA looks at the differences in test scores between the two groups
Method 1 and Method 2 while taking into account the pre-test scores.
It's like saying, "Okay, let's see if Method 1 students have higher test scores
than Method 2 students, but let's also make sure any differences aren't just
because Method 1 students started with higher pre-test scores."
Key Terms:
Covariate: This is just a fancy word for another factor we think might affect
the outcome. In our example, the pre-test scores are the covariate because
we think they could influence test scores.
Model Formula: This is just the math equation ANCOVA uses to do its job. It
looks at how the independent variables (like the teaching method) and the
covariate (like pre-test scores) affect the outcome (test scores).
Why it's Helpful:
ANCOVA helps us get a clearer picture by considering all the factors that
could affect our results. It's like wearing glasses to see better!
Example:
Let's say we find out that Method 1 students have higher test scores than
Method 2 students. But, without ANCOVA, we might wonder if this is because
Method 1 is truly better or just because Method 1 students had higher pre-test
scores to begin with. ANCOVA helps us tease out the real answer.
So, ANCOVA is like a super detective that helps us compare groups while making
sure we're not missing anything important!
Statistics, Statistical Modelling & Data Analytics 71
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Regression Diagnostics, Residuals, and Influence
Diagnostics
Regression diagnostics are essential tools used to assess the quality and
appropriateness of regression models. They help analysts identify potential
problems or violations of assumptions in the model, such as nonlinearity,
heteroscedasticity, outliers, and influential data points. Residuals and influence
diagnostics are two key components of regression diagnostics that provide
valuable information about the adequacy and reliability of regression models.
Key Concepts:
Residuals:
Residuals are the differences between observed values of the dependent
variable and the values predicted by the regression model.
They represent the unexplained variability in the data and serve as
indicators of model fit and predictive accuracy.
Residual analysis involves examining the pattern and distribution of
residuals to detect potential issues with the regression model, such as
nonlinearity, heteroscedasticity, and outliers.
Types of Residuals:
Ordinary Residuals Raw Residuals): The differences between observed
and predicted values of the dependent variable.
Standardized Residuals: Residuals standardized by dividing by their
standard deviation, allowing for comparison across different models and
datasets.
Studentized Residuals: Residuals adjusted for leverage, providing a
measure of how influential individual data points are on the regression
model.
Residual Analysis:
Residual plots, such as scatterplots of residuals against fitted values or
independent variables, are commonly used to visually inspect the pattern
of residuals.
Statistics, Statistical Modelling & Data Analytics 72
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Deviations from randomness or homoscedasticity in residual plots may
indicate violations of regression assumptions.
Influence Diagnostics:
Influence diagnostics assess the impact of individual data points on the
regression model's parameters and predictions.
Common measures of influence include leverage, Cook's distance, and
DFBETAS, which quantify the effect of removing a data point on the
regression coefficients and predicted values.
Statistics, Statistical Modelling & Data Analytics 73
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Advantages:
Model Assessment: Regression diagnostics provide a systematic framework
for evaluating the goodness of fit and appropriateness of regression models.
Identifying Problems: Residual analysis and influence diagnostics help
identify potential problems such as outliers, influential data points,
nonlinearity, and heteroscedasticity that may affect the validity of regression
results.
Model Improvement: By identifying problematic data points or violations of
assumptions, regression diagnostics guide model refinement and
improvement, leading to more reliable and accurate predictions.
Applications:
Economic Forecasting: Regression diagnostics are used in economic
forecasting to evaluate the performance of regression models predicting
economic indicators such as GDP growth, inflation rates, and unemployment
rates.
Healthcare Research: In healthcare research, regression diagnostics help
assess the predictive accuracy of regression models for clinical outcomes and
identify influential factors affecting patient outcomes.
Marketing Analysis: Regression diagnostics play a crucial role in marketing
analysis by evaluating the effectiveness of marketing campaigns, identifying
influential factors influencing consumer behavior, and detecting outliers or
anomalies in sales data.
Environmental Studies: Regression diagnostics are applied in environmental
studies to assess the relationships between environmental variables (e.g.,
pollution levels, temperature) and ecological outcomes (e.g., species
abundance, biodiversity), ensuring the validity of regression-based analyses.
Example:
Suppose a researcher conducts a multiple linear regression analysis to predict
housing prices based on various predictor variables such as square footage,
number of bedrooms, and location. After fitting the regression model, the
researcher performs regression diagnostics to evaluate the model's performance
and reliability.
Statistics, Statistical Modelling & Data Analytics 74
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
The researcher conducts the following diagnostic checks:
Residual Analysis: The researcher examines residual plots, including
scatterplots of residuals against fitted values and histograms of residuals, to
assess whether the residuals exhibit randomness and homoscedasticity. Any
systematic patterns or non-randomness in the residual plots may indicate
problems with the regression model.
Influence Diagnostics: The researcher calculates leverage, Cook's distance,
and DFBETAS for each data point to identify influential observations that exert
a disproportionate influence on the regression coefficients and predictions.
High leverage points or large Cook's distances may indicate influential outliers
that warrant further investigation.
By conducting regression diagnostics, the researcher can assess the validity of
the regression model, identify potential issues or outliers, and make informed
decisions about model refinement or data adjustments to improve the accuracy
and reliability of predictions.
In summary, regression diagnostics, including residual analysis and influence
diagnostics, are essential tools for evaluating the quality and reliability of
regression models, identifying potential problems or violations of assumptions,
and guiding model improvement in various fields of research and analysis.
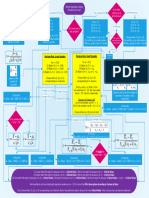
Transformations in Regression Analysis
Transformations are a powerful technique used in regression analysis to address
issues such as nonlinearity, heteroscedasticity, and non-normality in the
relationship between variables. By applying mathematical transformations to the
predictor or response variables, analysts can often improve model fit, stabilize
variance, and meet the assumptions of linear regression. Common
transformations include logarithmic, square root, and reciprocal transformations,
among others.
Key Concepts:
Logarithmic Transformation:
Logarithmic transformations involve taking the logarithm of the variable,
typically base 10 or natural logarithm (ln).
Statistics, Statistical Modelling & Data Analytics 75
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Log transformations are useful for dealing with data that exhibit
exponential growth or decay, such as financial data, population growth
rates, or reaction kinetics.
Square Root Transformation:
Square root transformations involve taking the square root of the variable.
Square root transformations are effective for stabilizing variance in data
that exhibit heteroscedasticity, where the spread of the data increases or
decreases with the mean.
Reciprocal Transformation:
Reciprocal transformations involve taking the reciprocal (1/x) of the
variable.
Reciprocal transformations are useful for dealing with data that exhibit a
curvilinear relationship, where the effect of the predictor variable on the
response variable diminishes as the predictor variable increases.
Exponential Transformation:
Exponential transformations involve raising the variable to a power, such
as squaring or cubing the variable.
Exponential transformations are beneficial for capturing nonlinear
relationships or interactions between variables.
Choosing Transformations:
Visual Inspection:
Analysts often visually inspect scatterplots of the variables to identify
patterns or relationships that may suggest appropriate transformations.
For example, if the relationship between variables appears curved or
exponential, a logarithmic or exponential transformation may be
appropriate.
Statistical Tests:
Statistical tests, such as the Shapiro-Wilk test for normality or the
Breusch-Pagan test for heteroscedasticity, can provide quantitative
evidence of the need for transformations.
Statistics, Statistical Modelling & Data Analytics 76
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
If assumptions of normality or constant variance are violated,
transformations may be necessary to meet these assumptions.
Trial and Error:
Analysts may experiment with different transformations and assess their
impact on model fit and assumptions.
Diagnostic tools, such as residual plots and goodness-of-fit statistics, can
help evaluate the effectiveness of transformations.
Applications:
Economics: Transformations are commonly used in economic research to
model relationships between economic variables, such as income, inflation
rates, and GDP growth, which may exhibit nonlinear or non-constant variance
patterns.
Biostatistics: In biostatistics, transformations are applied to biological data,
such as enzyme activity, gene expression levels, or drug concentrations, to
improve the linearity of relationships and stabilize variance.
Environmental Science: Transformations are used in environmental science to
analyze environmental data, such as pollutant concentrations, temperature
gradients, and species abundance, which may exhibit complex nonlinear
relationships.
Market Research: Transformations are employed in market research to
analyze consumer behavior data, such as purchasing patterns, product
preferences, and demographic characteristics, to identify underlying trends
and relationships.
Example:
Suppose a researcher conducts a regression analysis to predict house prices
based on square footage X1 and number of bedrooms X2. However, the
scatterplot of house prices against square footage shows a curved relationship,
indicating the need for a transformation.
The researcher decides to apply a logarithmic transformation to the square
footage variable X1_log) before fitting the regression model. The transformed
model becomes:
Statistics, Statistical Modelling & Data Analytics 77
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
By transforming the square footage variable using a logarithmic transformation,
the researcher aims to capture the nonlinear relationship between square footage
and house prices more effectively. The transformed model may lead to better
model fit and more accurate predictions compared to the original model without
transformation.
In summary, transformations are valuable tools in regression analysis for
addressing issues such as nonlinearity and heteroscedasticity, improving model
fit, and meeting the assumptions of linear regression. By carefully selecting and
applying appropriate transformations, analysts can enhance the reliability and
interpretability of regression models in various fields of study.
Sure! Let's make transformations in regression analysis easy to understand:
1. What are Transformations?
Transformations in regression analysis involve modifying the predictor or
response variables to meet the assumptions of linear regression.
2. Why Transform?
Sometimes, the relationship between variables isn't linear, or the data doesn't
meet regression assumptions like normality or constant variance.
Transformations help make the relationship more linear or meet assumptions,
improving the model's accuracy.
3. Common Transformations:
Log Transformation: Use the natural logarithm to reduce skewness in
positively skewed data or to stabilize variance.
Square Root Transformation: Reduces right skewness and stabilizes variance.
Inverse Transformation: Use the reciprocal to handle data with a negative
skew.
Box-Cox Transformation: A family of transformations that includes
logarithmic, square root, and inverse transformations, chosen based on the
Statistics, Statistical Modelling & Data Analytics 78
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
data's characteristics.
4. How to Apply Transformations:
Identify the issue: Check for nonlinearity, non-constant variance, or non-
normality in residuals.
Choose the appropriate transformation based on the data's characteristics
and the desired outcome.
Apply the transformation to the predictor or response variable, or both, using
mathematical functions like logarithms or square roots.
Fit the transformed model and evaluate its performance.
5. Advantages of Transformations:
Improves linearity: Helps make the relationship between variables more linear.
Stabilizes variance: Reduces heteroscedasticity, where the spread of residuals
varies across levels of the predictor.
Normalizes distribution: Makes the data more normally distributed, meeting
regression assumptions.
6. Example:
Suppose you're analyzing the relationship between income and spending
habits. The relationship appears curved, indicating nonlinearity.
You apply a log transformation to income to reduce skewness and stabilize
variance.
After transformation, the relationship becomes more linear, improving the
model's accuracy.
7. Caution:
Transformations can alter interpretation: Be cautious when interpreting
coefficients or predictions after transformation.
Not always necessary: Transformations should only be applied when
necessary to address specific issues in the data.
In summary, transformations in regression analysis modify variables to meet
assumptions, improve linearity, stabilize variance, and normalize distributions.
Statistics, Statistical Modelling & Data Analytics 79
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Choosing the right transformation is crucial for enhancing model accuracy and
ensuring valid interpretations of results.
Box-Cox Transformation
The Box-Cox transformation is a widely used technique in statistics for stabilizing
variance and improving the normality of data distributions. It is particularly useful
in regression analysis when the assumptions of constant variance
(homoscedasticity) and normality of residuals are violated. The Box-Cox
transformation provides a family of power transformations that can be applied to
the response variable to achieve better adherence to the assumptions of linear
regression.
Key Concepts:
Statistics, Statistical Modelling & Data Analytics 80
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Assumptions:
The Box-Cox transformation assumes that the data are strictly positive;
therefore, it is not suitable for non-positive data.
Additionally, the Box-Cox transformation assumes that the relationship
between the response variable and the predictors is approximately linear
after transformation.
Applications:
Regression Analysis: The Box-Cox transformation is commonly used in
regression analysis to stabilize variance and improve the normality of
residuals, thereby meeting the assumptions of linear regression models.
Time Series Analysis: In time series analysis, the Box-Cox transformation can
be applied to stabilize the variance of time series data and remove trends or
seasonal patterns.
Biostatistics: In biostatistics, the Box-Cox transformation is used to transform
skewed biological data, such as enzyme activity levels, gene expression
values, or drug concentrations, to achieve normality and homoscedasticity.
In summary, the Box-Cox transformation is a versatile tool for stabilizing variance
and achieving normality in regression analysis and other statistical applications.
Statistics, Statistical Modelling & Data Analytics 81
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
By selecting an appropriate transformation parameter lambda, analysts can
enhance the validity and interpretability of their models and make more reliable
predictions.
Model Selection and Building Strategies
Model selection and building strategies are essential processes in statistical
modeling and machine learning aimed at identifying the most appropriate and
reliable models for predicting outcomes or explaining relationships between
variables. These strategies involve selecting the appropriate variables, choosing
the model complexity, assessing model performance, and validating the model's
predictive accuracy. Several techniques and methodologies are employed in
model selection and building to ensure robust and interpretable models.
Key Concepts:
Variable Selection:
Variable selection involves identifying the most relevant predictor variables
that have a significant impact on the response variable.
Techniques for variable selection include stepwise regression, forward
selection, backward elimination, regularization methods (e.g., Lasso,
Ridge), and feature importance ranking (e.g., Random Forest, Gradient
Boosting).
Model Complexity:
Model complexity refers to the number of predictor variables and the
functional form of the model.
Balancing model complexity is crucial to prevent overfitting (model
capturing noise) or underfitting (model oversimplified), which can lead to
poor generalization performance.
Strategies for managing model complexity include cross-validation,
regularization, and model averaging.
Assessment of Model Performance:
Model performance assessment involves evaluating how well the model
fits the data and how accurately it predicts outcomes on unseen data.
Statistics, Statistical Modelling & Data Analytics 82
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Common metrics for assessing model performance include mean squared
error MSE, R-squared (coefficient of determination), accuracy, precision,
recall, and area under the ROC curve AUCROC.
Techniques such as cross-validation, bootstrapping, and holdout
validation are used to estimate the model's performance on unseen data.
Model Interpretability:
Model interpretability refers to the ease with which the model's predictions
can be explained and understood by stakeholders.
Simpler models with fewer variables and transparent structures (e.g.,
linear regression, decision trees) are often preferred when interpretability
is critical.
Strategies:
Start Simple: Begin with a simple model that includes only the most important
predictor variables and assess its performance.
Iterative Model Building: Iteratively add or remove variables from the model
based on their significance and contribution to model performance.
Cross-validation: Use cross-validation techniques (e.g., k-fold cross-
validation) to assess the generalization performance of the model and avoid
overfitting.
Regularization: Apply regularization techniques (e.g., Lasso, Ridge
regression) to penalize model complexity and prevent overfitting.
Ensemble Methods: Combine multiple models (e.g., bagging, boosting) to
improve predictive accuracy and robustness.
Model Comparison: Compare the performance of different models using
appropriate evaluation metrics and select the one with the best performance
on validation data.
Applications:
Predictive Modeling: Model selection and building strategies are used in
predictive modeling tasks such as sales forecasting, risk assessment, and
customer churn prediction.
Statistics, Statistical Modelling & Data Analytics 83
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Regression Analysis: In regression analysis, model selection strategies are
employed to identify the most relevant predictor variables and determine the
optimal model complexity.
Classification: In classification tasks, model selection involves choosing the
appropriate classifier algorithm and tuning its parameters to achieve the best
classification performance.
Feature Engineering: Model building strategies often involve feature
engineering techniques to create new features or transform existing ones to
improve model performance.
Example:
Suppose a data scientist is tasked with building a predictive model to forecast
housing prices based on various predictor variables such as square footage,
number of bedrooms, location, and neighborhood characteristics. The data
scientist follows the following model selection and building strategies:
Data Exploration: Conduct exploratory data analysis to understand the
relationships between predictor variables and the target variable (housing
prices) and identify potential outliers or missing values.
Variable Selection: Use feature importance ranking techniques (e.g., Random
Forest feature importance) to identify the most important predictor variables
that contribute significantly to predicting housing prices.
Model Building: Start with a simple linear regression model using the selected
predictor variables and assess its performance using cross-validation
techniques (e.g., k-fold cross-validation).
Iterative Improvement: Iteratively refine the model by adding or removing
predictor variables based on their significance and contribution to model
performance, using techniques such as stepwise regression or regularization.
Model Evaluation: Evaluate the final model's performance using appropriate
metrics (e.g., mean squared error, R-squared) on a holdout validation dataset
to assess its predictive accuracy and generalization performance.
By following these model selection and building strategies, the data scientist can
develop a reliable predictive model for housing price forecasting that effectively
Statistics, Statistical Modelling & Data Analytics 84
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
captures the relationships between predictor variables and housing prices while
ensuring robustness and generalizability.
Logistic Regression Models
Logistic regression is a statistical method used for modeling the relationship
between a binary dependent variable and one or more independent variables. It is
commonly employed in classification tasks where the outcome variable is
categorical and has two levels, such as "yes/no," "success/failure," or "0/1."
Logistic regression estimates the probability that an observation belongs to a
particular category based on the values of the predictor variables.
Key Concepts:
Assumptions:
Statistics, Statistical Modelling & Data Analytics 85
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
Linearity in the Logit: The relationship between the predictor variables and
the log-odds of the outcome is assumed to be linear.
Independence of Observations: Observations are assumed to be
independent of each other.
No Multicollinearity: Predictor variables should not be highly correlated with
each other.
Large Sample Size: Logistic regression performs well with large sample sizes.
Applications:
Medical Research: Logistic regression is widely used in medical research for
predicting patient outcomes, such as disease occurrence, mortality, or
treatment response.
Marketing: In marketing, logistic regression is employed to predict customer
behavior, such as purchase decisions, churn, or response to marketing
campaigns.
Credit Risk Assessment: Logistic regression is used in banking and finance to
assess credit risk and predict the likelihood of default based on borrower
characteristics.
Social Sciences: Logistic regression is applied in social sciences to model
binary outcomes, such as voting behavior, employment status, or educational
attainment.
Example:
Suppose a bank wants to predict whether a credit card transaction is fraudulent
based on transaction features such as transaction amount, merchant category,
and time of day. The bank collects historical data on credit card transactions,
including whether each transaction was fraudulent or not.
The bank decides to use logistic regression to build a predictive model. They
preprocess the data, splitting it into training and testing datasets. Then, they fit a
logistic regression model to the training data, with transaction features as
predictor variables and the binary outcome variable (fraudulent or not) as the
response variable.
Statistics, Statistical Modelling & Data Analytics 86
Downloaded by shipra lakra (shipralakra7222@gmail.com)
lOMoARcPSD|44438987
After fitting the model, they evaluate its performance using metrics such as
accuracy, precision, recall, and the area under the ROC curve AUCROC on the
testing dataset. The bank uses these metrics to assess the model's predictive
accuracy and determine its suitability for detecting fraudulent transactions in real-
time.
In summary, logistic regression models are valuable tools for predicting binary
outcomes in various fields, providing insights into the factors that influence the
likelihood of an event occurring. They are widely used in practice due to their
simplicity, interpretability, and effectiveness in classification tasks.
Poisson Regression Models
Poisson regression is a statistical method used for modeling count data, where the
outcome variable represents the number of occurrences of an event within a fixed
interval of time or space. It is commonly employed when the outcome variable
follows a Poisson distribution, characterized by non-negative integer values and a
single parameter representing the mean and variance. Poisson regression models
the relationship between the predictor variables and the expected count of the
event, allowing for inference about the factors influencing the event rate.
Key Concepts:
Statistics, Statistical Modelling & Data Analytics 87
Downloaded by shipra lakra (shipralakra7222@gmail.com)
You might also like
- Introduction To Statistical Modeling With SAS/STAT SoftwareNo ratings yetIntroduction To Statistical Modeling With SAS/STAT Software60 pages
- STAT2 Modelling With Regression and ANOVA 2nd Edition Ann R. Cannon PDF DownloadNo ratings yetSTAT2 Modelling With Regression and ANOVA 2nd Edition Ann R. Cannon PDF Download175 pages
- Introduction To Business Statistics Sixth Edition Ronald M. Weiers No Waiting TimeNo ratings yetIntroduction To Business Statistics Sixth Edition Ronald M. Weiers No Waiting Time163 pages
- Introduction To Business Statistics Sixth Edition Ronald M. Weiers Full AccessNo ratings yetIntroduction To Business Statistics Sixth Edition Ronald M. Weiers Full Access87 pages
- Statistical Models 1st Edition A.C. Davison Instant DownloadNo ratings yetStatistical Models 1st Edition A.C. Davison Instant Download78 pages
- Comprehensive Guide To PHD Concept Note Development Part 2No ratings yetComprehensive Guide To PHD Concept Note Development Part 24 pages
- 1 - Introduction To Environmental ModellingNo ratings yet1 - Introduction To Environmental Modelling13 pages
- Introduction To Business Statistics Sixth Edition Ronald M. Weiers Instant DownloadNo ratings yetIntroduction To Business Statistics Sixth Edition Ronald M. Weiers Instant Download52 pages
- Introduction To Business Statistics Sixth Edition Ronald M. Weiers Latest PDF 2025No ratings yetIntroduction To Business Statistics Sixth Edition Ronald M. Weiers Latest PDF 202597 pages
- (Ebook PDF) Stat2: Modeling With Regression and Anova 2Nd Edition PDF DownloadNo ratings yet(Ebook PDF) Stat2: Modeling With Regression and Anova 2Nd Edition PDF Download48 pages
- Statistical Regression and Classification - From Linear Models To Machine Learning100% (10)Statistical Regression and Classification - From Linear Models To Machine Learning532 pages
- Introduction To Statistical Methods For Financial Models100% (2)Introduction To Statistical Methods For Financial Models387 pages
- LBOE2112 Module 2 Multivariate Data Analysis - 2024-2025 - AllNo ratings yetLBOE2112 Module 2 Multivariate Data Analysis - 2024-2025 - All155 pages
- Ekstrøm, Claus Thorn - Sørensen, Helle - Introduction To Statistical Data Analysis For The Life Sciences-CRC Press (2014)No ratings yetEkstrøm, Claus Thorn - Sørensen, Helle - Introduction To Statistical Data Analysis For The Life Sciences-CRC Press (2014)521 pages
- +part 01 - AMEFA - 2024 - Introduction and RepetitionNo ratings yet+part 01 - AMEFA - 2024 - Introduction and Repetition68 pages
- Foundations of Applied Statistical Methods 2nd Edition Hang Lee Instant Download Full ChaptersNo ratings yetFoundations of Applied Statistical Methods 2nd Edition Hang Lee Instant Download Full Chapters87 pages
- Analysis of Variance and Covariance How To Choose and Construct Models For The Life Sciences, 1st Edition PDF DOCX DownloadNo ratings yetAnalysis of Variance and Covariance How To Choose and Construct Models For The Life Sciences, 1st Edition PDF DOCX Download14 pages
- Psychological Statistics and Psychometrics Using Stata, 1st Edition ISBN 1597183032, 9781597183031 Ebook DownloadNo ratings yetPsychological Statistics and Psychometrics Using Stata, 1st Edition ISBN 1597183032, 9781597183031 Ebook Download17 pages
- Introduction To Business Statistics 6th Edition Ronald M. Weiers Download Full Chapters100% (2)Introduction To Business Statistics 6th Edition Ronald M. Weiers Download Full Chapters93 pages
- 124 Stochastic Processes From Applications To Theory Pierre Del Moral Spiridon Penev Edisi 1 2016100% (2)124 Stochastic Processes From Applications To Theory Pierre Del Moral Spiridon Penev Edisi 1 2016916 pages
- Foundations of Applied Statistical Methods 2nd Edition Hang Lee Newest Edition 2025No ratings yetFoundations of Applied Statistical Methods 2nd Edition Hang Lee Newest Edition 2025152 pages
- Stochastic Objects: Probability & Inference100% (3)Stochastic Objects: Probability & Inference409 pages
- Modelling Survival Data in Medical Research PDF100% (7)Modelling Survival Data in Medical Research PDF538 pages
- Modelling Survival Data in Medical Research 3rd Ed by Collett and Kimber - 1 PDF67% (6)Modelling Survival Data in Medical Research 3rd Ed by Collett and Kimber - 1 PDF538 pages
- Macroeconomic Regression Model in ExcelNo ratings yetMacroeconomic Regression Model in Excel10 pages
- Statistics For People Who Think They Hate Statistics 7th Edition Textbook50% (2)Statistics For People Who Think They Hate Statistics 7th Edition Textbook25 pages
- Introduction To Research in The Health Sciences (Stephen Polgar Shane Thomas)100% (2)Introduction To Research in The Health Sciences (Stephen Polgar Shane Thomas)583 pages
- Psychological Assessment and Theory Tests 8th Edition Kaplan Test BankNo ratings yetPsychological Assessment and Theory Tests 8th Edition Kaplan Test Bank12 pages
- Repaso Final - Estadistica, Spring 2022 - WebAssignNo ratings yetRepaso Final - Estadistica, Spring 2022 - WebAssign20 pages
- Introductory Econometrics For Finance Chris Brooks Solutions To Review Questions - Chapter 6No ratings yetIntroductory Econometrics For Finance Chris Brooks Solutions To Review Questions - Chapter 611 pages
- Pilot-Pivotal Trials For Average BioequivalenceNo ratings yetPilot-Pivotal Trials For Average Bioequivalence11 pages
- PDF Introduction To Statistics and Data Analysis 3rd Edition Roxy Peck Download100% (8)PDF Introduction To Statistics and Data Analysis 3rd Edition Roxy Peck Download84 pages
- Integrated Time Series and Cointegration: Course: Applied Econometrics Lecturer: Zhigang LiNo ratings yetIntegrated Time Series and Cointegration: Course: Applied Econometrics Lecturer: Zhigang Li14 pages
- Chi-Square Test and Its Application in HypothesisNo ratings yetChi-Square Test and Its Application in Hypothesis3 pages
- Formulating Hypotheses for Population MeanNo ratings yetFormulating Hypotheses for Population Mean3 pages
- Hypothesis Testing Flowchart v0.2 2017 02 03No ratings yetHypothesis Testing Flowchart v0.2 2017 02 031 page
- Course Guide: Department of Industrial EngineeringNo ratings yetCourse Guide: Department of Industrial Engineering2 pages
- Survival Analysis, Part 3: Cox Regression: Statistics and Research DesignNo ratings yetSurvival Analysis, Part 3: Cox Regression: Statistics and Research Design2 pages