0% found this document useful (0 votes)
35 views5 pagesL-2 (Data Frame Part 1) .Ipynb - Colab
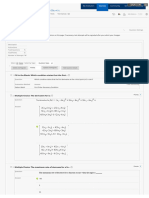
The document is a Jupyter notebook that demonstrates basic operations on data frames using Python's pandas library. It covers importing data, renaming columns, finding smallest and largest values, filtering data, and performing statistical functions like mean, median, mode, and standard deviation. Additionally, it includes examples of cumulative sums and products, as well as correlation and covariance calculations.
Uploaded by
ashishpal2804Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
35 views5 pagesL-2 (Data Frame Part 1) .Ipynb - Colab
The document is a Jupyter notebook that demonstrates basic operations on data frames using Python's pandas library. It covers importing data, renaming columns, finding smallest and largest values, filtering data, and performing statistical functions like mean, median, mode, and standard deviation. Additionally, it includes examples of cumulative sums and products, as well as correlation and covariance calculations.
Uploaded by
ashishpal2804Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 5