0% found this document useful (0 votes)
13 views2 pagesCode Iris
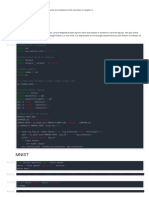
The document contains Python code that implements a machine learning model using the Stochastic Gradient Descent (SGD) classifier from the scikit-learn library. It trains the model on a provided dataset with both L1 and L2 penalties, evaluates the model's accuracy on a test set, and prints the results. The dataset is split into training and testing sets, and the model is trained and tested accordingly.
Uploaded by
jagadeshraoCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
13 views2 pagesCode Iris
The document contains Python code that implements a machine learning model using the Stochastic Gradient Descent (SGD) classifier from the scikit-learn library. It trains the model on a provided dataset with both L1 and L2 penalties, evaluates the model's accuracy on a test set, and prints the results. The dataset is split into training and testing sets, and the model is trained and tested accordingly.
Uploaded by
jagadeshraoCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 2