0% found this document useful (0 votes)
12 views8 pages2 Module 4 Routing
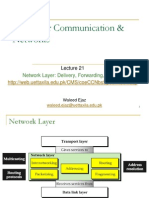
The Distance Vector Routing Algorithm is a dynamic, iterative, asynchronous, and distributed method used primarily in ARPANET and RIP, where each router maintains a distance table and shares knowledge with its neighbors. It involves periodic updates of routing information based on the Bellman-Ford equation and can be classified into adaptive, non-adaptive, and hybrid algorithms. Additionally, Border Gateway Protocol (BGP) and Open Shortest Path First (OSPF) are discussed as important routing protocols, with BGP focusing on inter-autonomous system communication and OSPF utilizing a link-state approach for efficient routing within a network.
Uploaded by
sakshishetyecmpnCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
12 views8 pages2 Module 4 Routing
The Distance Vector Routing Algorithm is a dynamic, iterative, asynchronous, and distributed method used primarily in ARPANET and RIP, where each router maintains a distance table and shares knowledge with its neighbors. It involves periodic updates of routing information based on the Bellman-Ford equation and can be classified into adaptive, non-adaptive, and hybrid algorithms. Additionally, Border Gateway Protocol (BGP) and Open Shortest Path First (OSPF) are discussed as important routing protocols, with BGP focusing on inter-autonomous system communication and OSPF utilizing a link-state approach for efficient routing within a network.
Uploaded by
sakshishetyecmpnCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 8