0% found this document useful (0 votes)
50 views13 pagesClass 7 Random Forest Algorithm
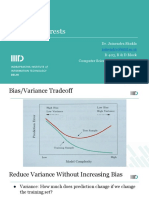
The document provides an overview of the Random Forest algorithm, a supervised machine learning technique that utilizes ensemble learning through multiple decision trees to improve prediction accuracy and reduce overfitting. It highlights the algorithm's features, advantages, and disadvantages, as well as its applications in classification and regression tasks. Additionally, it notes that Random Forest is less effective in cases of extrapolation and sparse data.
Uploaded by
quillsbotCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
50 views13 pagesClass 7 Random Forest Algorithm
The document provides an overview of the Random Forest algorithm, a supervised machine learning technique that utilizes ensemble learning through multiple decision trees to improve prediction accuracy and reduce overfitting. It highlights the algorithm's features, advantages, and disadvantages, as well as its applications in classification and regression tasks. Additionally, it notes that Random Forest is less effective in cases of extrapolation and sparse data.
Uploaded by
quillsbotCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
/ 13