아키텍처 관련 기본원칙
각 단계별 독립화된 시스템 구성
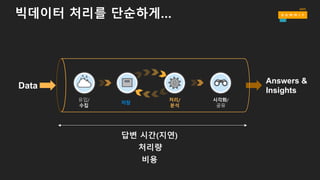
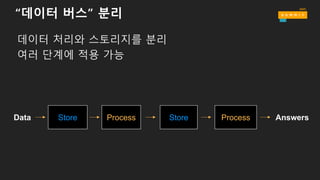
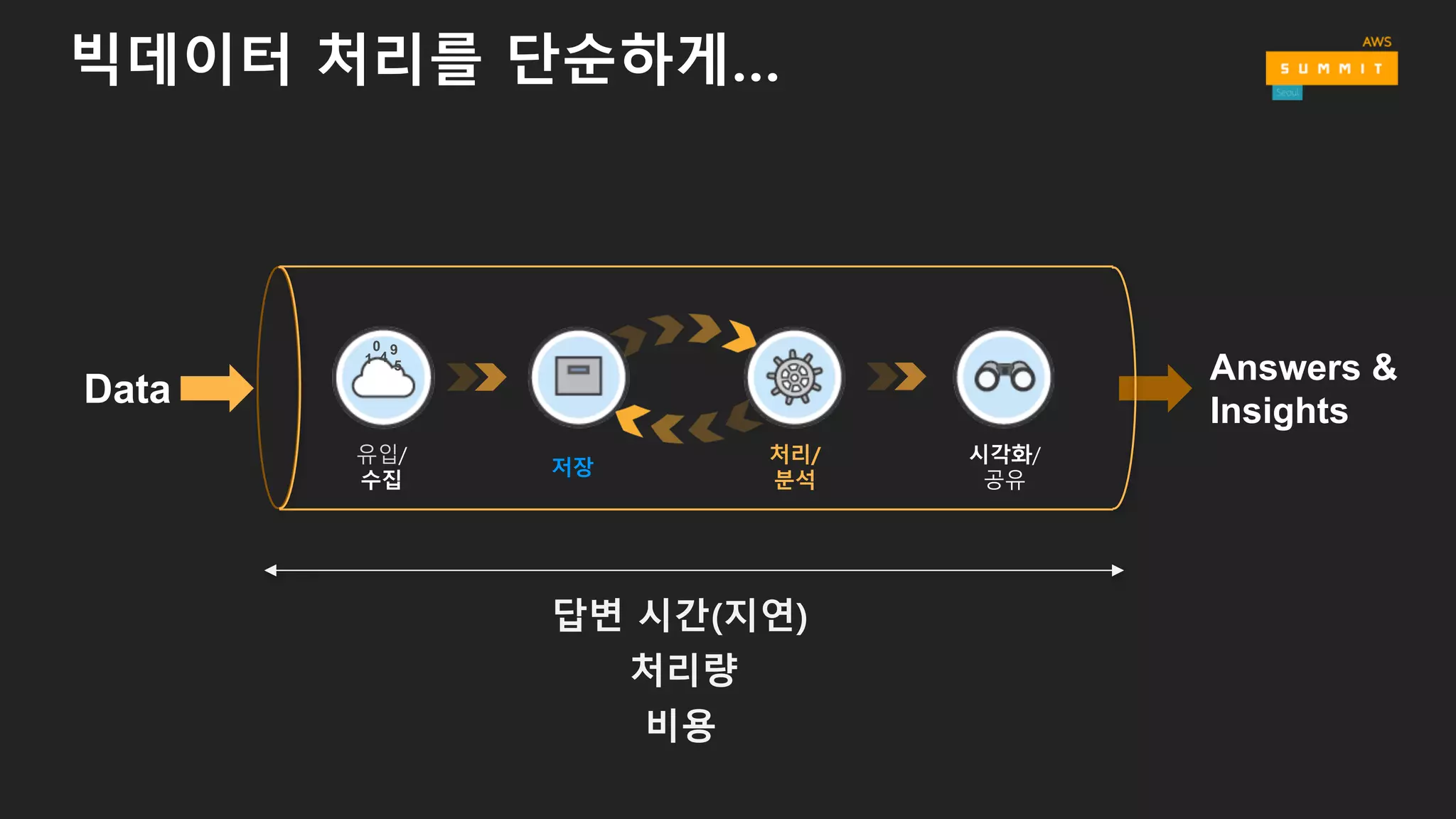
• Data → Store → Process → Store → Analyze → Answers
작업에 적합한 툴을 사용
• Data structure, Latency, Throughput, Access patterns
AWS 관리형 서비스의 적용 및 활용
• Scalable/elastic, Available, Reliable, Secure, No(or Low) admin
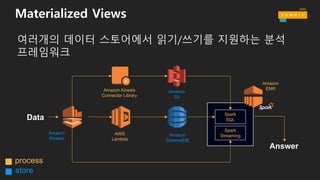
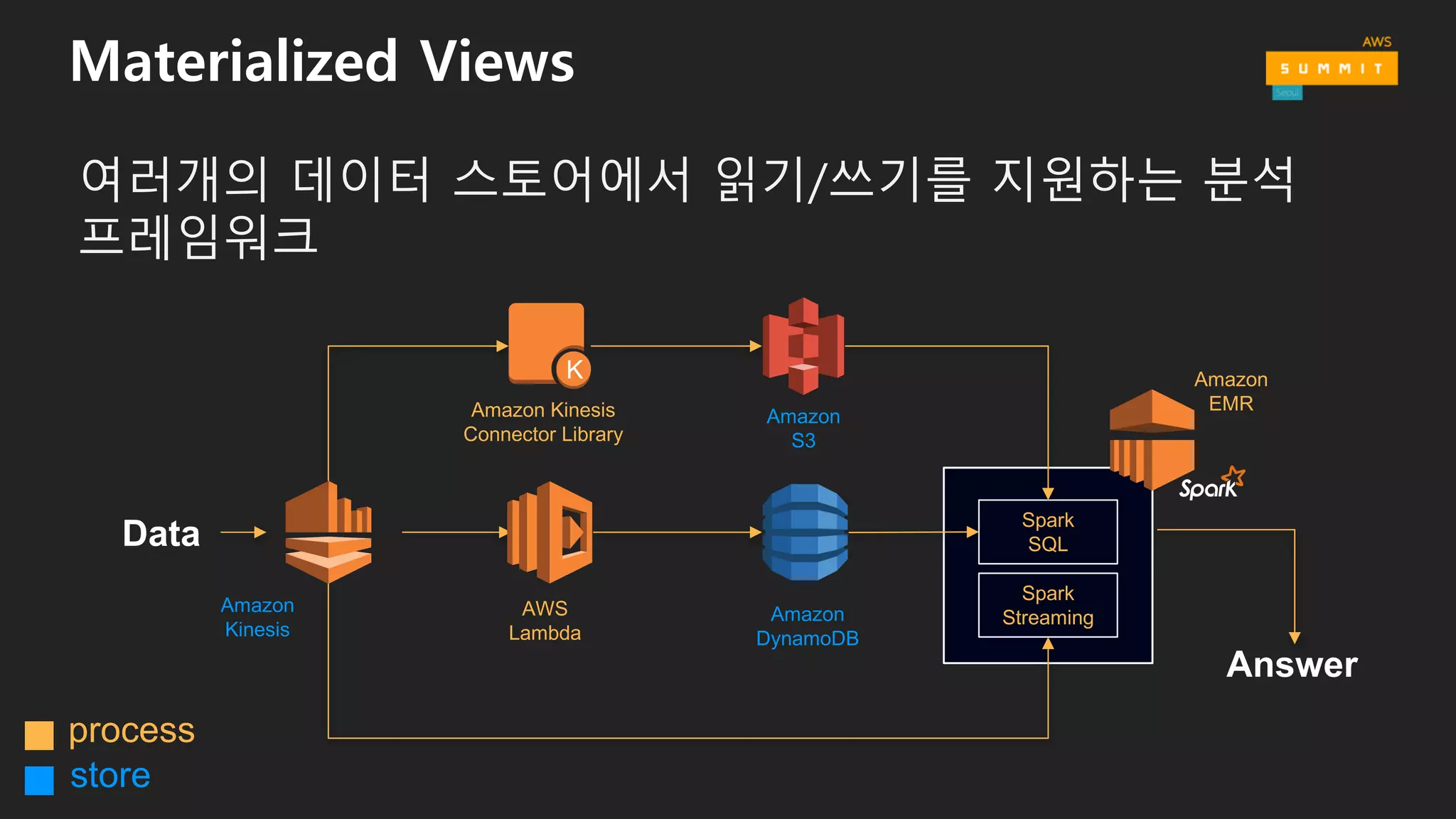
로그 데이터 특화형 디자인 패턴
• Immutable logs, Materialized views
비용에 대한 고려
• Big data ≠ Big cost
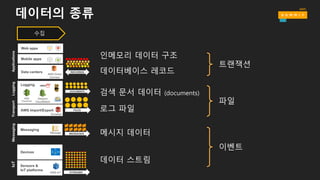
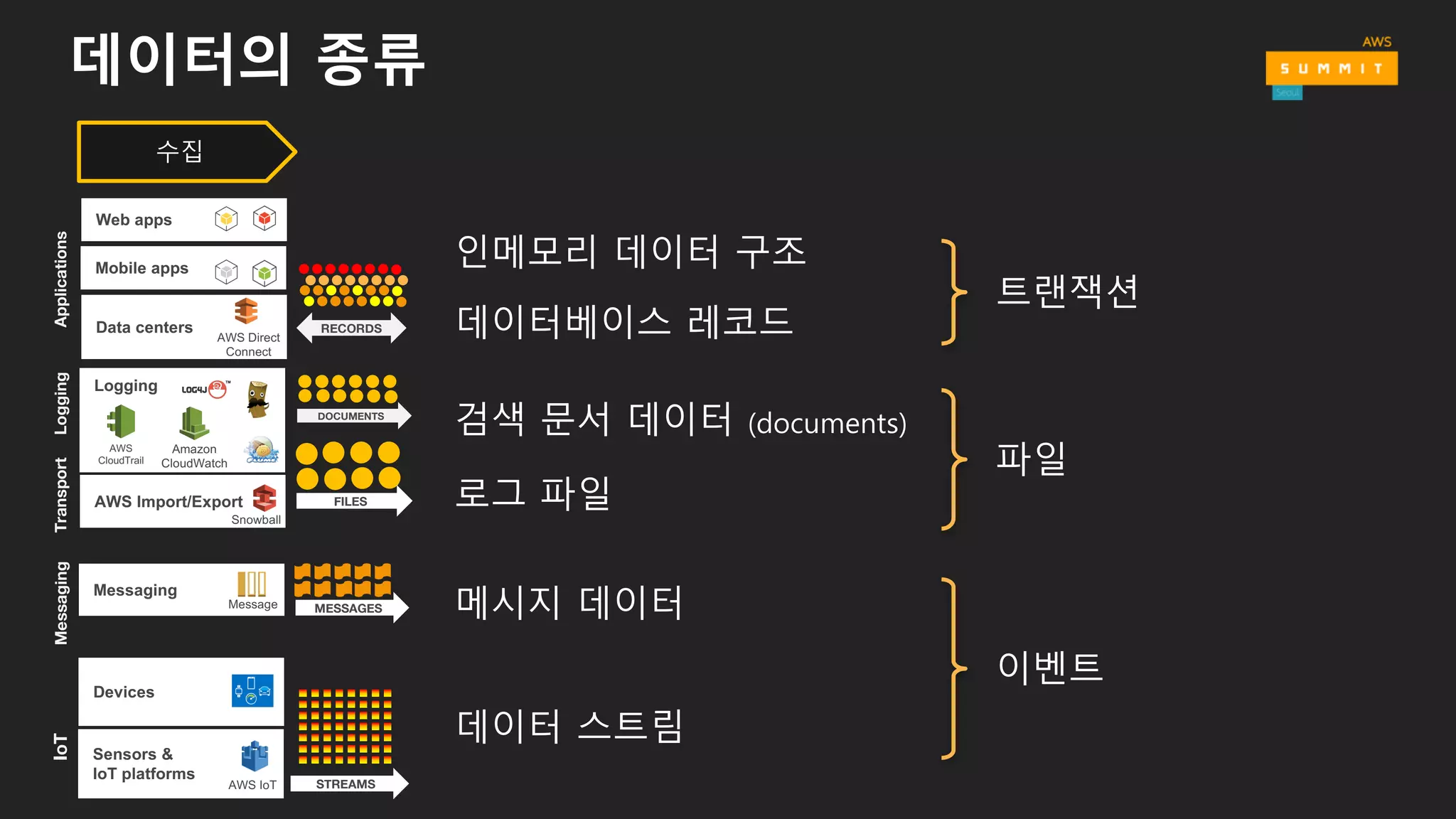
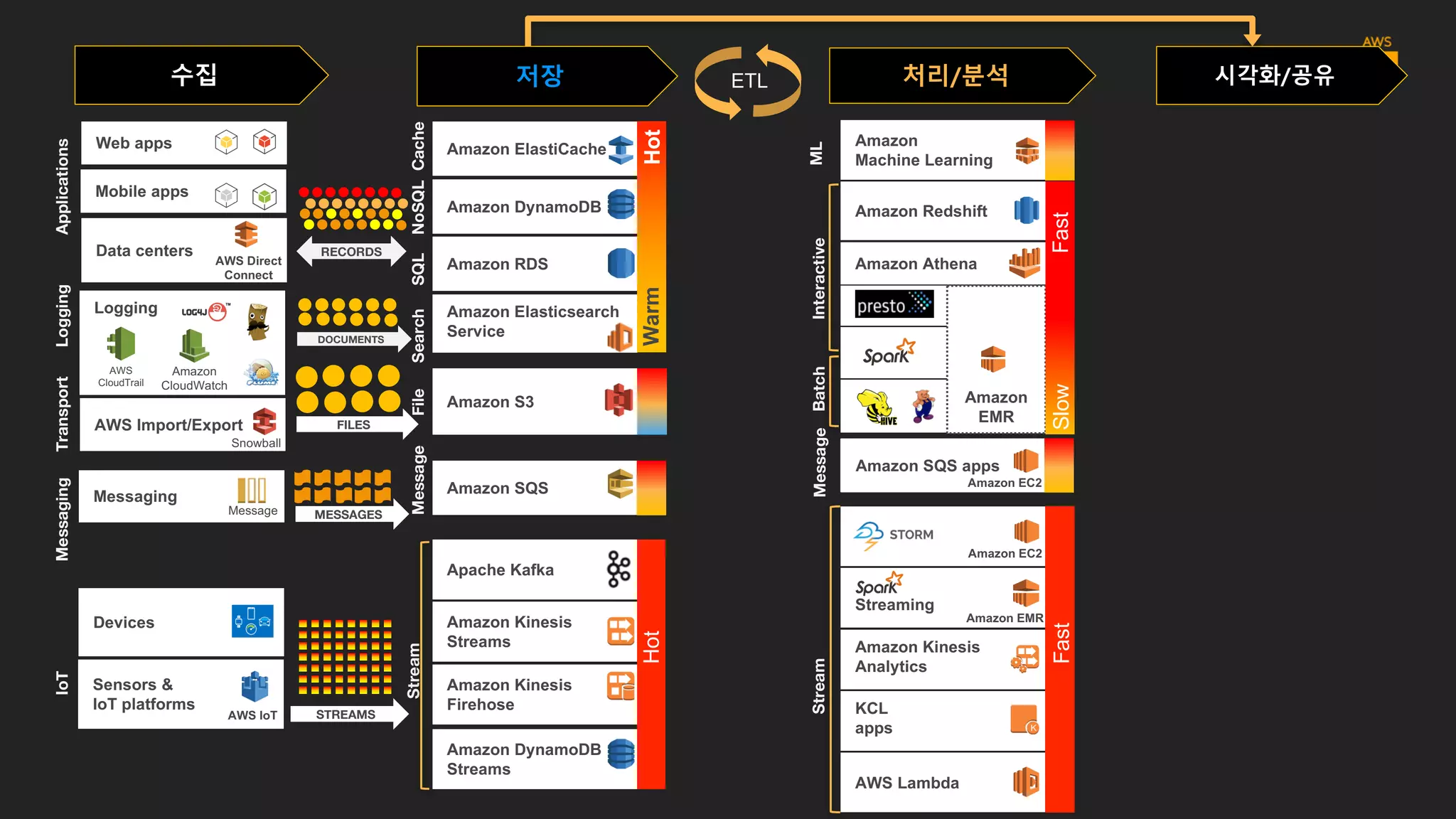
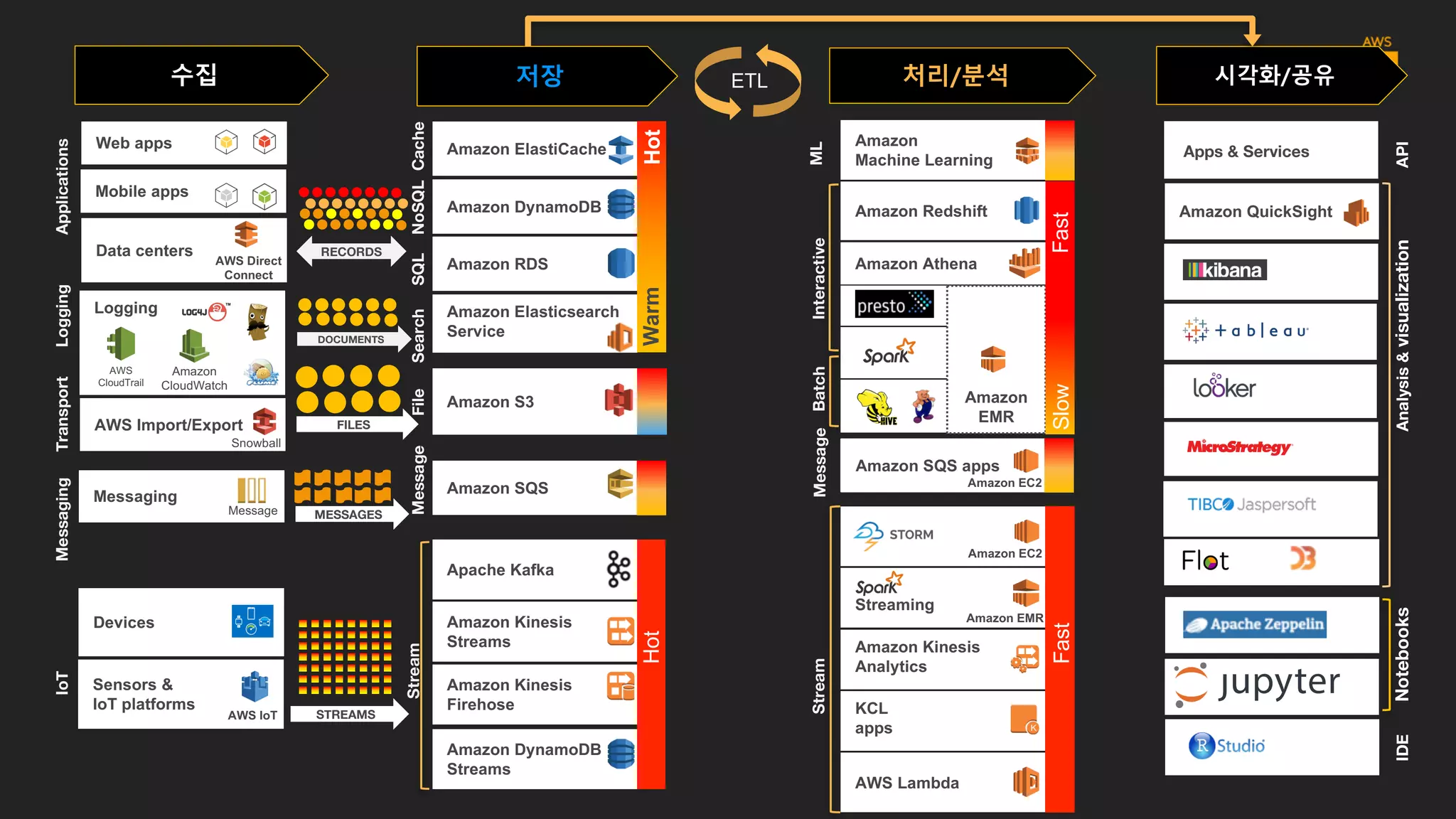
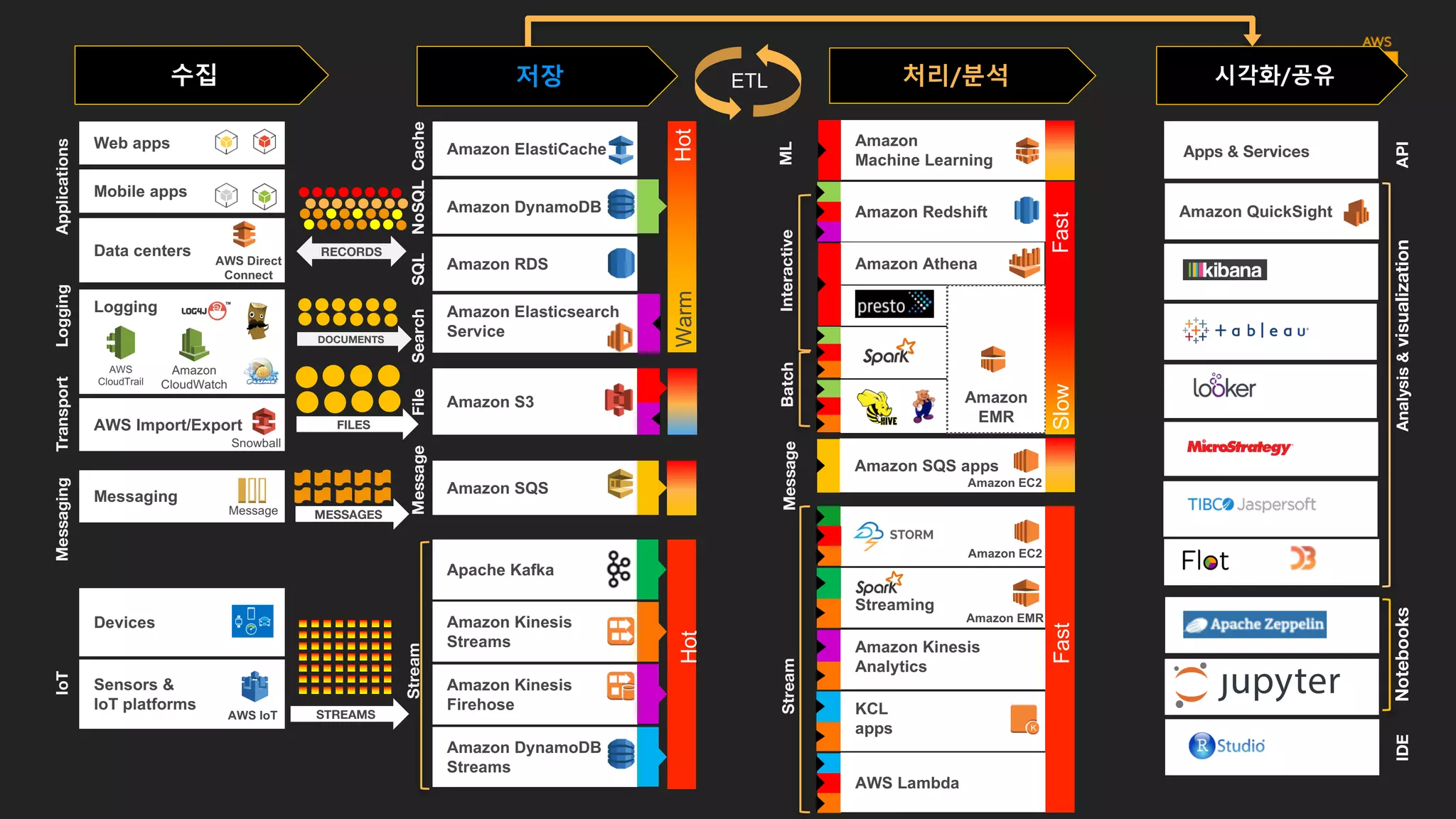
데이터의 종류
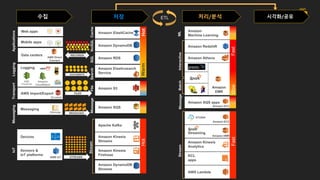
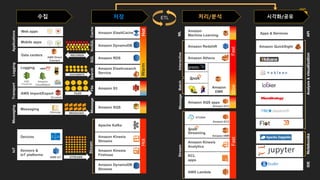
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
인메모리 데이터 구조
AWS Import/Export
Snowball
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoT
데이터 스트림
트랜잭션
파일
이벤트
데이터베이스 레코드
Logging
메시지 데이터
로그 파일
검색 문서 데이터 (documents)
Logging
Amazon
CloudWatch
AWS
CloudTrail
데이터 스토어의 종류
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
캐시, 데이터 구조 서버
AWS Import/Export
Snowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoT
pub/sub 메시지 큐
SQL & NoSQL 데이터베이스
Logging
메시지 큐
파일 시스템
검색 엔진
저장
In-memory
Database
Search
File Store
Queue
Stream
Storage
14.
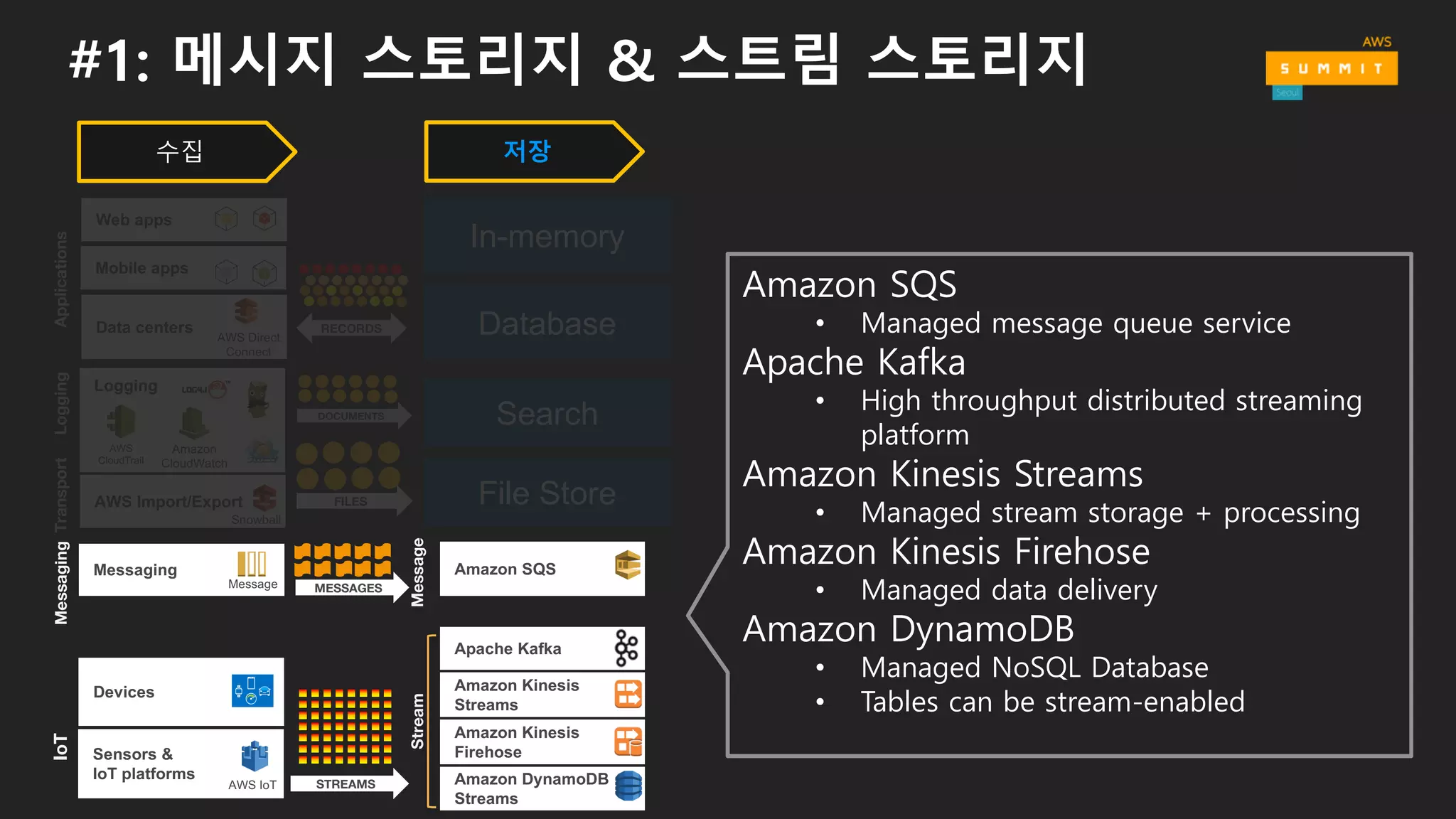
#1: 메시지 스토리지& 스트림 스토리지
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
AWS Import/Export
Snowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoTLogging
저장
In-memory
Database
Search
File Store
Amazon Kinesis
Firehose
Amazon Kinesis
Streams
Apache Kafka
Amazon DynamoDB
Streams
Amazon SQS
MessageStream
Amazon SQS
• Managed message queue service
Apache Kafka
• High throughput distributed streaming
platform
Amazon Kinesis Streams
• Managed stream storage + processing
Amazon Kinesis Firehose
• Managed data delivery
Amazon DynamoDB
• Managed NoSQL Database
• Tables can be stream-enabled
15.
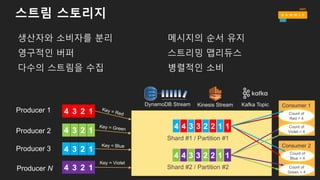
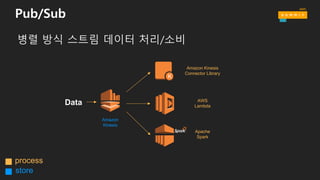
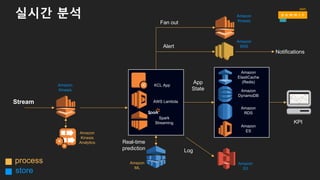
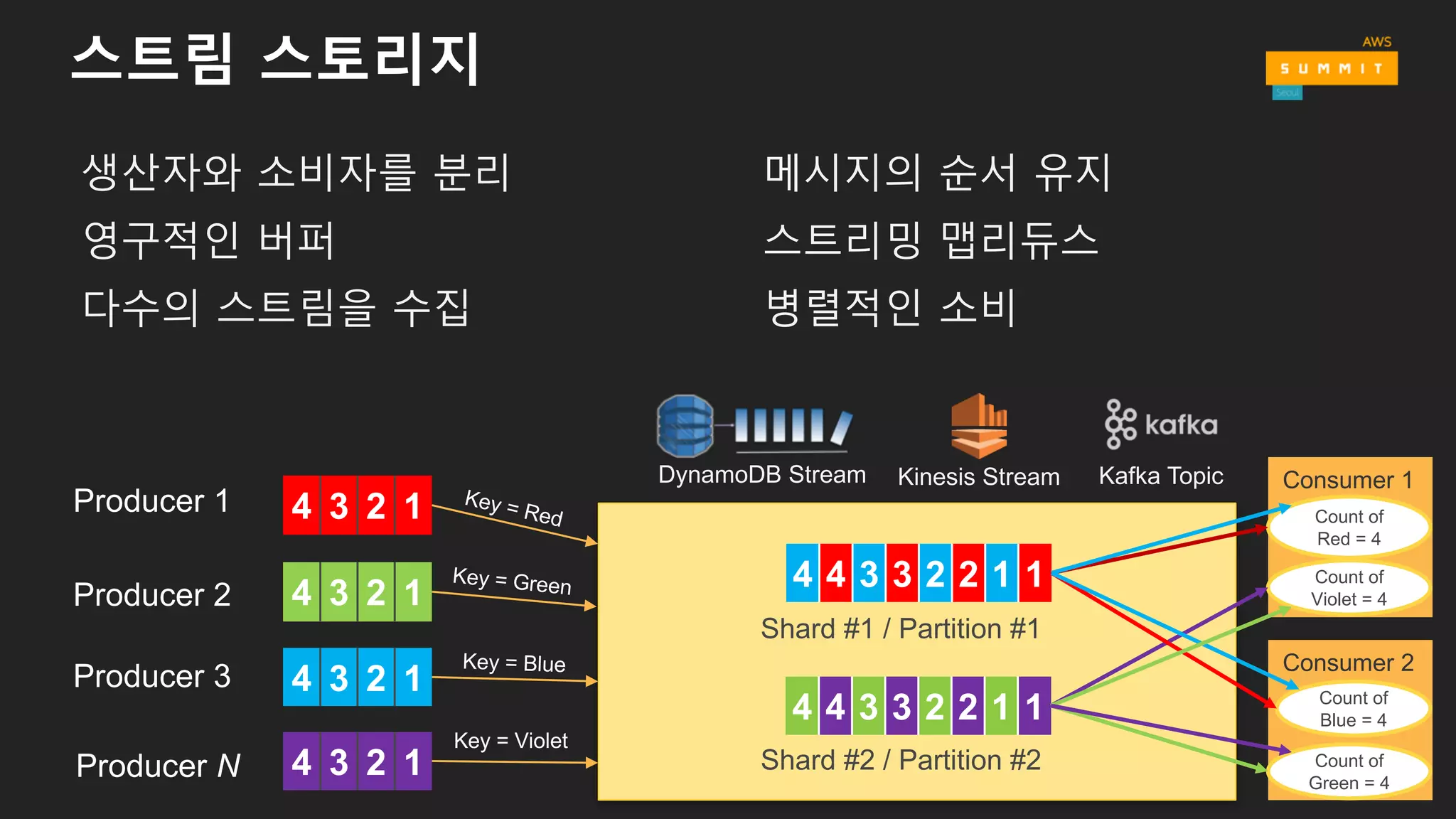
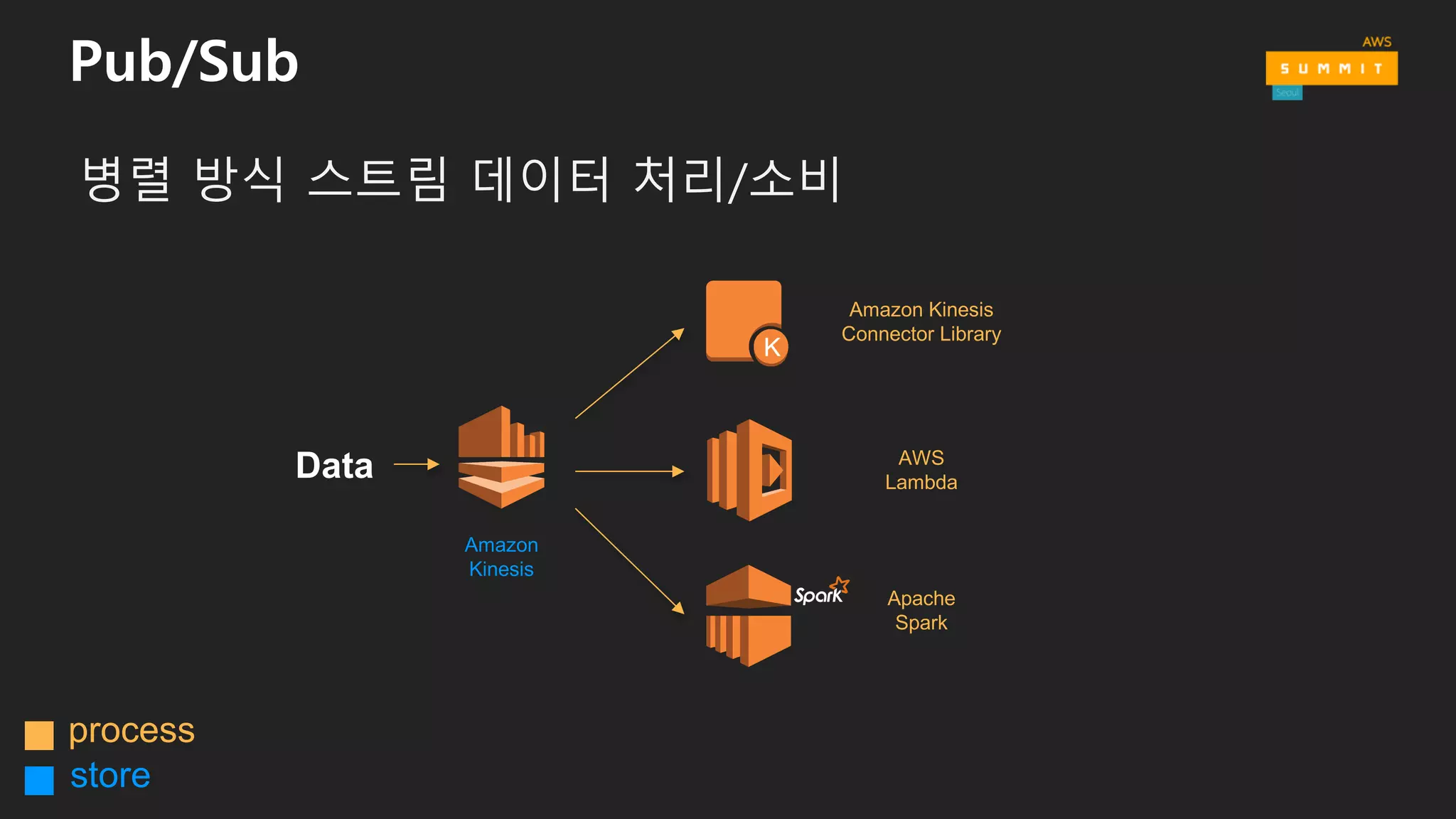
왜 스트림 스토리지가필요할까요?
생산자와 소비자를 분리
영구적인 버퍼
다수의 스트림을 수집
메시지의 순서 유지
스트리밍 맵리듀스
병렬적인 소비
4 4 3 3 2 2 1 1
4 3 2 1
4 3 2 1
4 3 2 1
4 3 2 1
4 4 3 3 2 2 1 1
Shard #1 / Partition #1
Shard #2 / Partition #2
Consumer 1
Count of
Red = 4
Count of
Violet = 4
Consumer 2
Count of
Blue = 4
Count of
Green = 4
DynamoDB Stream Kinesis Stream Kafka Topic
16.
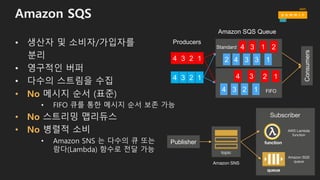
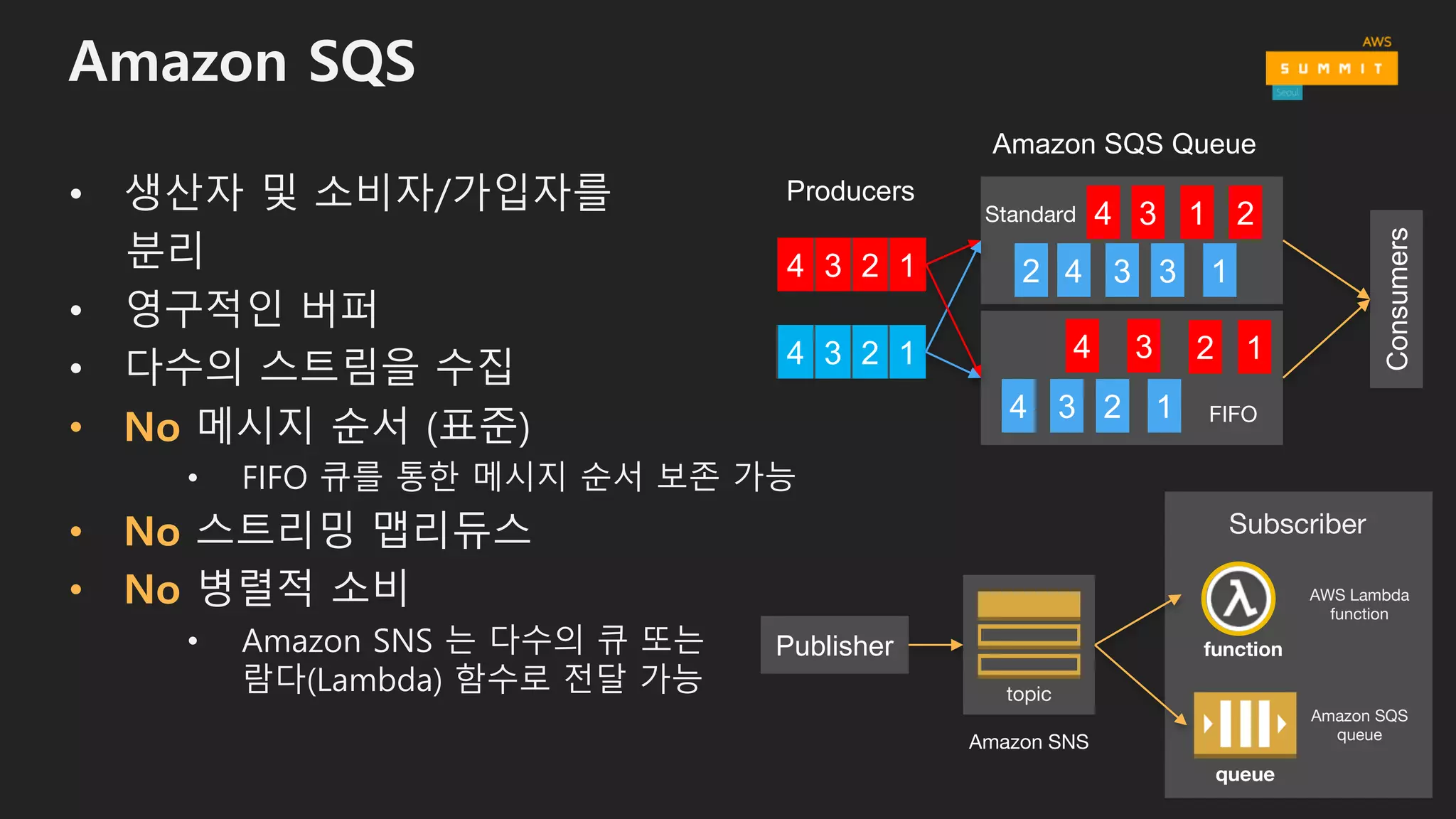
Amazon SQS
• 생산자및 소비자/가입자를
분리
• 영구적인 버퍼
• 다수의 스트림을 수집
• No 메시지 순서 (표준)
• FIFO 큐를 통한 메시지 순서 보존 가능
• No 스트리밍 맵리듀스
• No 병렬적 소비
• Amazon SNS 는 다수의 큐 또는
람다(Lambda) 함수로 전달 가능
Consumers
4 3 2 1
12344 3 2 1
1234
2134
13342
Standard
FIFO
Publisher
Amazon SNS
topic
function
AWS Lambda
function
Amazon SQS
queue
queue
Subscriber
17.
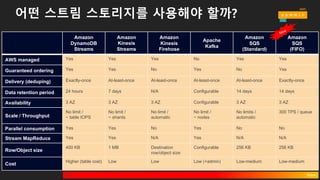
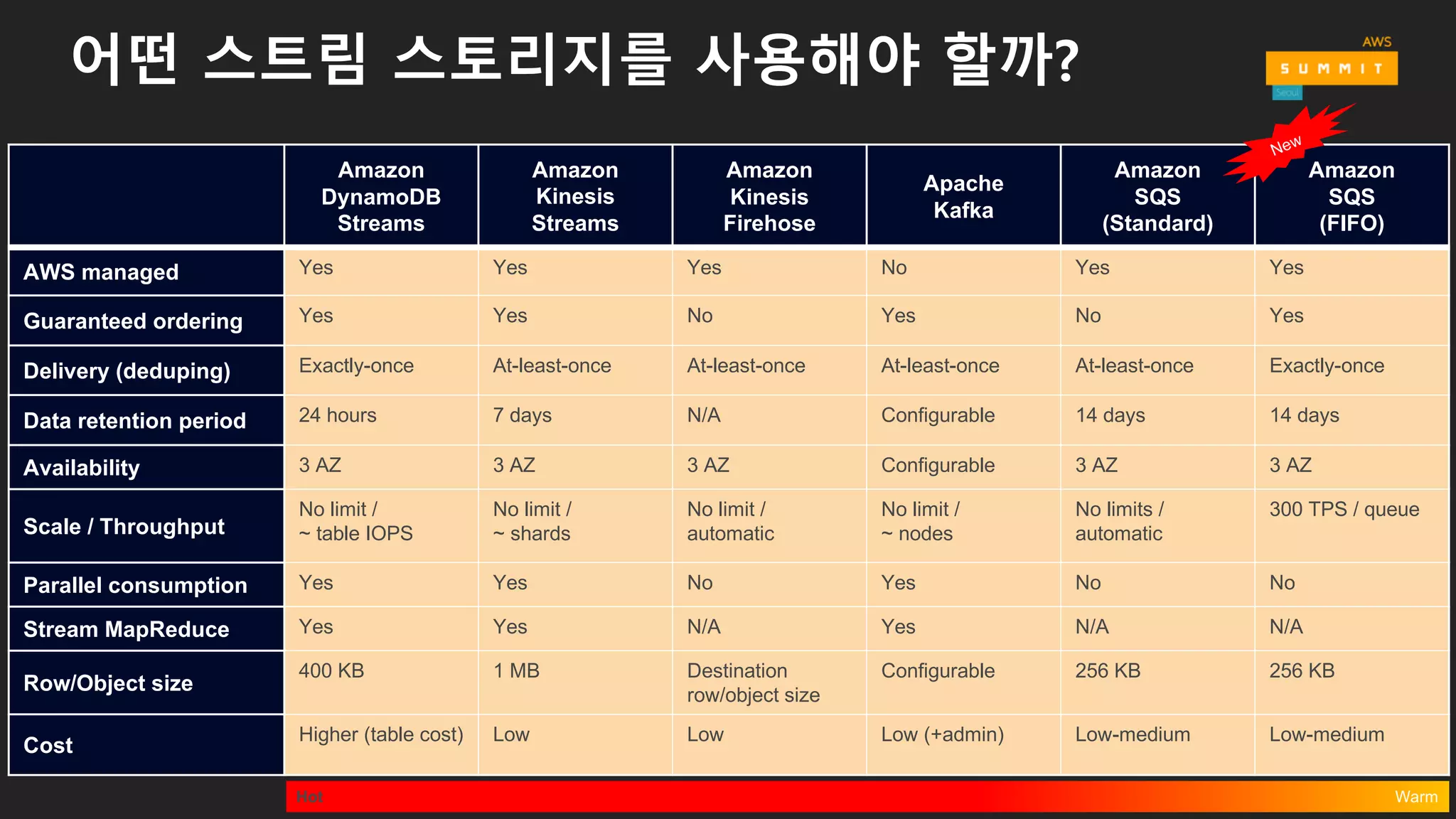
어떤 스트림 스토리지를사용해야 할까?
Amazon
DynamoDB
Streams
Amazon
Kinesis
Streams
Amazon
Kinesis
Firehose
Apache
Kafka
Amazon
SQS
(Standard)
Amazon
SQS
(FIFO)
AWS managed Yes Yes Yes No Yes Yes
Guaranteed ordering Yes Yes No Yes No Yes
Delivery (deduping) Exactly-once At-least-once At-least-once At-least-once At-least-once Exactly-once
Data retention period 24 hours 7 days N/A Configurable 14 days 14 days
Availability 3 AZ 3 AZ 3 AZ Configurable 3 AZ 3 AZ
Scale / Throughput
No limit /
~ table IOPS
No limit /
~ shards
No limit /
automatic
No limit /
~ nodes
No limits /
automatic
300 TPS / queue
Parallel consumption Yes Yes No Yes No No
Stream MapReduce Yes Yes N/A Yes N/A N/A
Row/Object size
400 KB 1 MB Destination
row/object size
Configurable 256 KB 256 KB
Cost
Higher (table cost) Low Low Low (+admin) Low-medium Low-medium
Hot Warm
18.
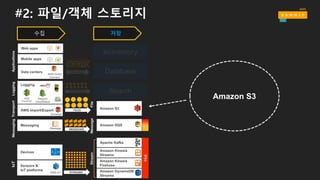
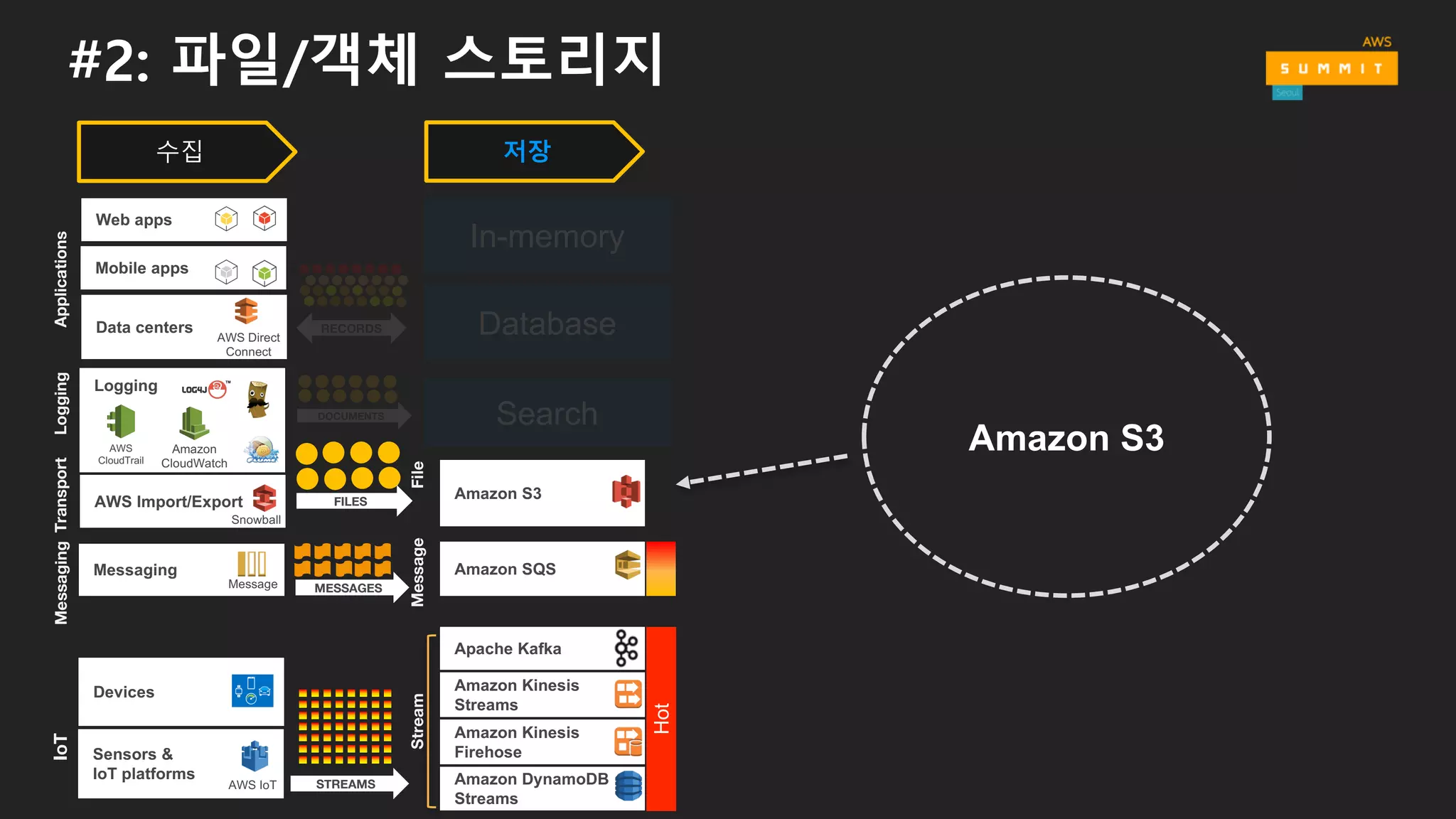
#2: 파일/객체 스토리지
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
AWS Import/Export
Snowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoTLogging
저장
In-memory
Database
Search
Amazon Kinesis
Firehose
Amazon Kinesis
Streams
Apache Kafka
Amazon DynamoDB
Streams
Amazon SQS
MessageStream
Amazon S3
File
Amazon S3
Hot
19.
왜 Amazon S3가빅데이터에 좋은가?
• 기본적으로 빅데이터 프레임워크 지원(Spark, Hive, Presto, etc.)
• Amazon EC2 스팟 인스턴스를 활용하여 하둡 클러스터 운영 가능
• 오브젝트 갯수 무제한
• 고 가용성 – AZ 장애 극복
• 데이터 복제에 대한 추가 비용 없음
• 수명주기를 활용한 계층-스토리지 (Standard, IA, Amazon Glacier)
• 저비용
20.
왜 Amazon S3가빅데이터에 좋은가?
• 스토리지를 위한 컴퓨팅 클러스터가 불필요 (HDFS와 다름)
• 동일한 데이터로 여러 종류(Spark, Hive, Presto) 클러스터를 동시에 사용
• 매우 높은 대역폭 – 총 처리량(throughput) 제한 없음
• 99.999999999%의 내구성을 위한 설계
• 버전 관리를 기본 기능으로 지원
• 보안 – SSL, client/server-side encryption at rest
21.
적절한 파일/객체 스토리지선택 가이드
• (Hot Data) 사용 빈도가 매우 높은 데이터는
HDFS를 사용
• 자주 접근하는 데이터는 Amazon S3
Standard를 사용
• 접근 빈도가 낮은 데이터는 Amazon S3
Standard – IA 를 사용
• (Cold Data) 거의 접근하지 않는 데이터는
Amazon Glacier를 이용하여 아카이브함
22.
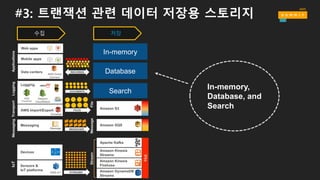
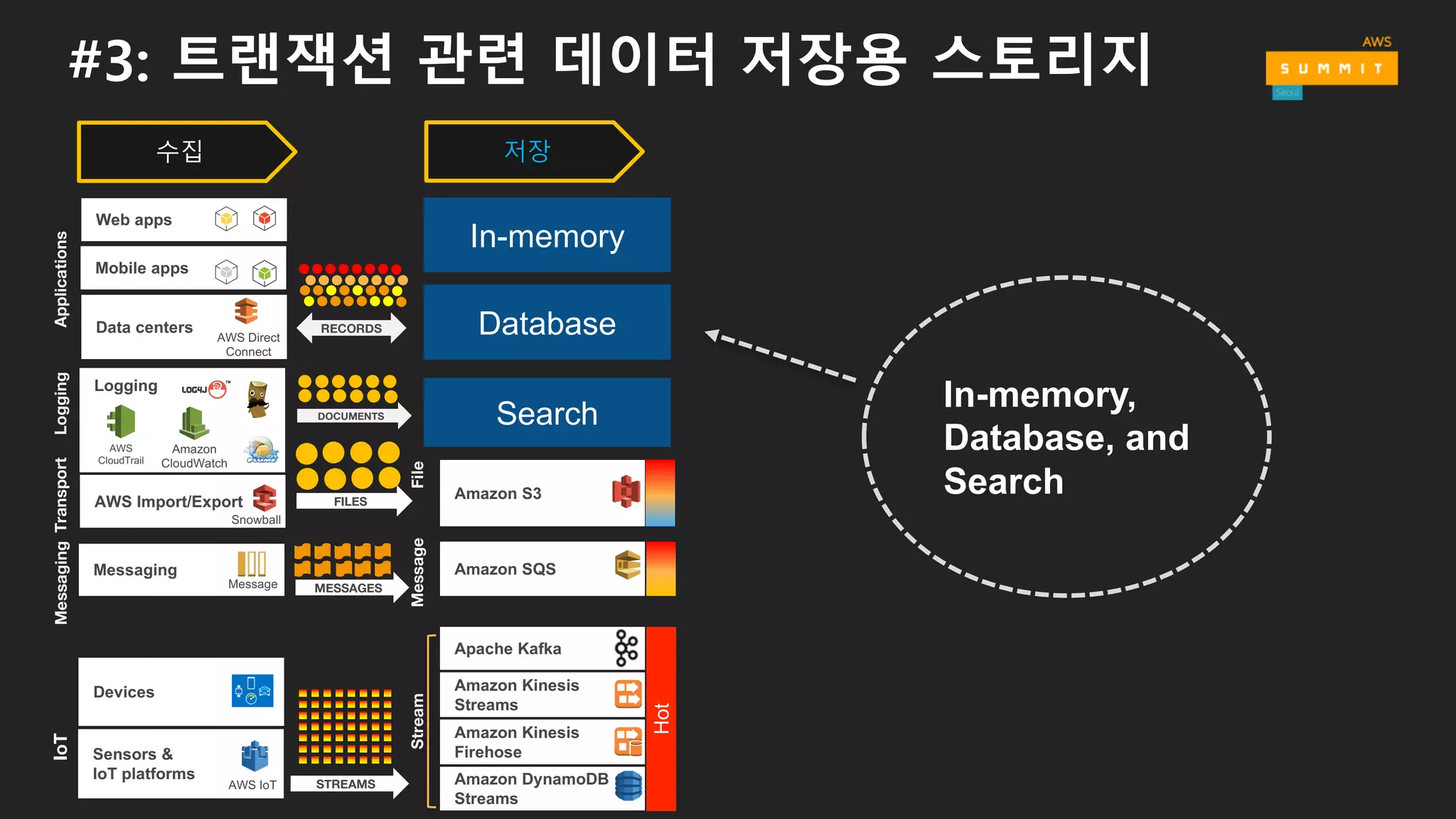
#3: 트랜잭션 관련데이터 저장용 스토리지
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
AWS Import/Export
Snowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoTLogging
저장
In-memory
Database
Search
Amazon Kinesis
Firehose
Amazon Kinesis
Streams
Apache Kafka
Amazon DynamoDB
Streams
Amazon SQS
MessageStream
Amazon S3
File
In-memory,
Database, and
Search
Hot
23.
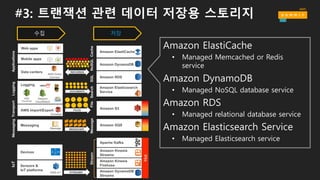
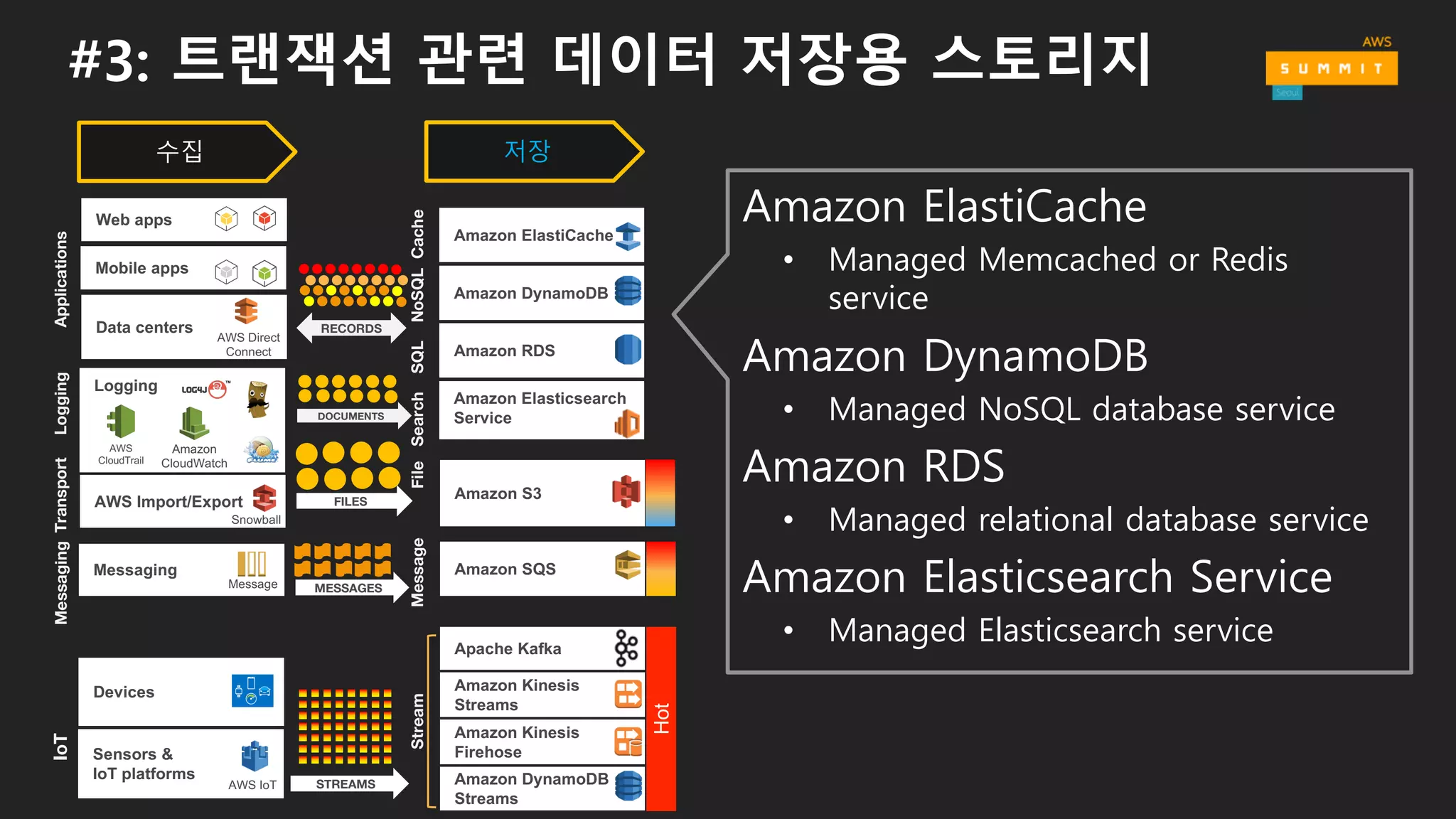
#3: 트랜잭션 관련데이터 저장용 스토리지
수집
Mobile apps
Web apps
Data centers
AWS Direct
Connect
RECORDS
Applications
AWS Import/Export
Snowball
Logging
Amazon
CloudWatch
AWS
CloudTrail
DOCUMENTS
FILES
Transport
Messaging
Message MESSAGES
Messaging
Devices
Sensors &
IoT platforms
AWS IoT STREAMS
IoTLogging
저장
Amazon Kinesis
Firehose
Amazon Kinesis
Streams
Apache Kafka
Amazon DynamoDB
Streams
Amazon SQS
MessageStream
Amazon S3
File
Hot
Amazon Elasticsearch
Service
Amazon DynamoDB
Amazon ElastiCache
Amazon RDS
SearchSQLNoSQLCache
Amazon ElastiCache
• Managed Memcached or Redis
service
Amazon DynamoDB
• Managed NoSQL database service
Amazon RDS
• Managed relational database service
Amazon Elasticsearch Service
• Managed Elasticsearch service
24.
정리: 데이터 스토어선택 기준 가이드
• 데이터 구조
→ 고정 스키마, JSON, 키-밸류
• 액세스 패턴
→ 향후 액세스 포맷을 고려하여
데이터를 저장
• 데이터 특성 (접근 빈도) → Hot, Warm, and Cold
• 비용 → 합리적인 비용
데이터 구조 What to use?
Fixed schema SQL, NoSQL
Schema-free (JSON) NoSQL, Search
(Key, value) In-memory, NoSQL
액세스 패턴 What to use?
Put/Get (key, value) In-memory, NoSQL
Simple relationships → 1:N, M:N NoSQL
Multi-table joins, transaction, SQL SQL
Faceting, search Search
25.
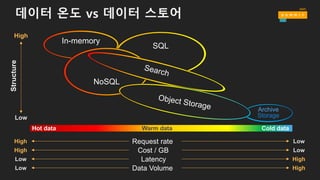
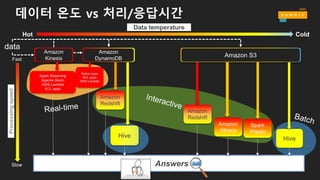
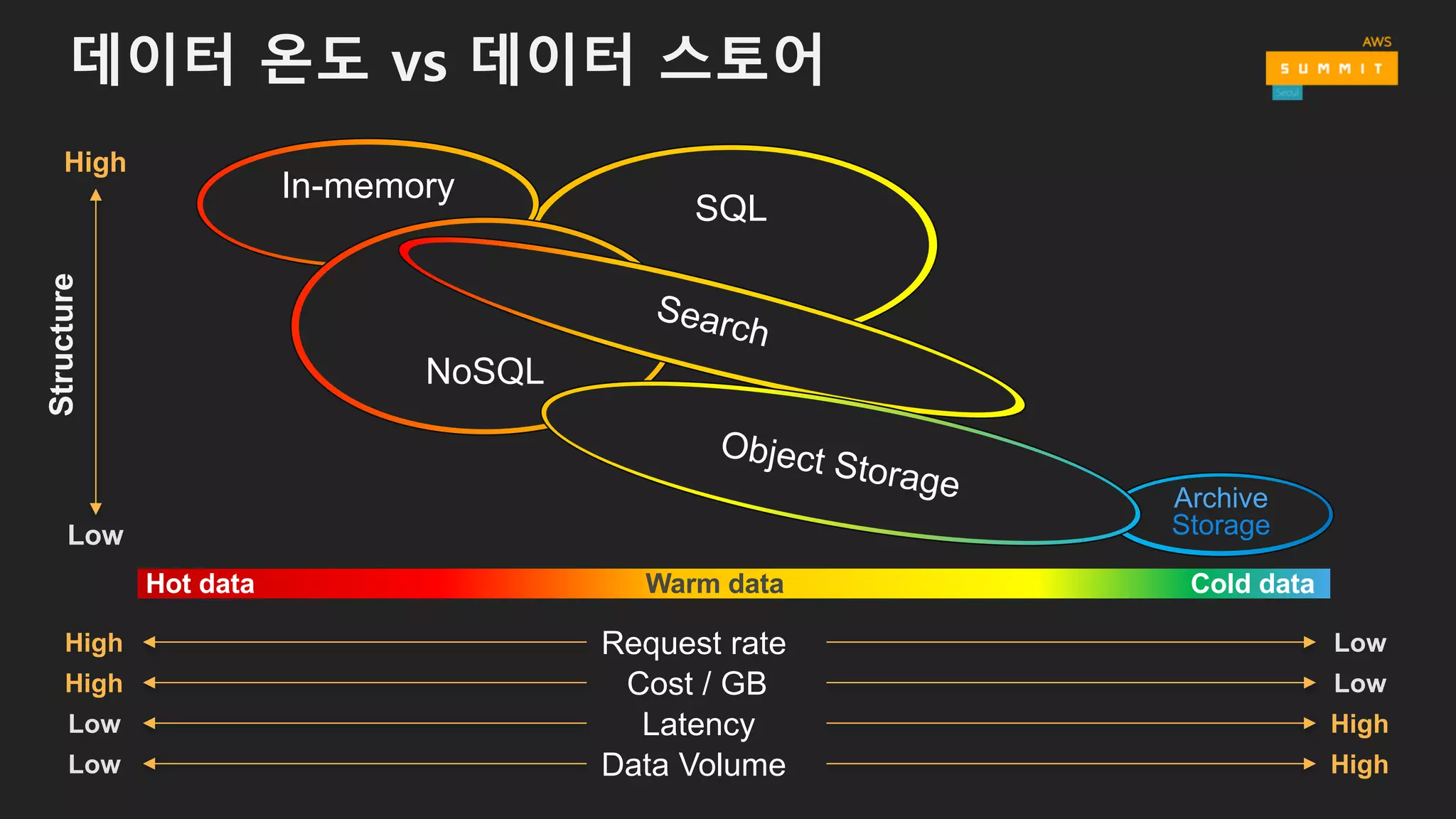
데이터 온도 vs데이터 스토어
SQL
Archive
Storage
Structure
Hot data Warm data Cold data
Low
High
High Request rate
LowHigh Cost / GB
Low HighLatency
Low HighData Volume
Low
In-memory
NoSQL
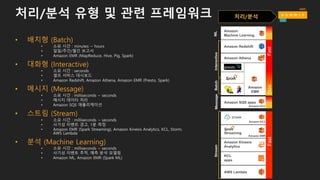
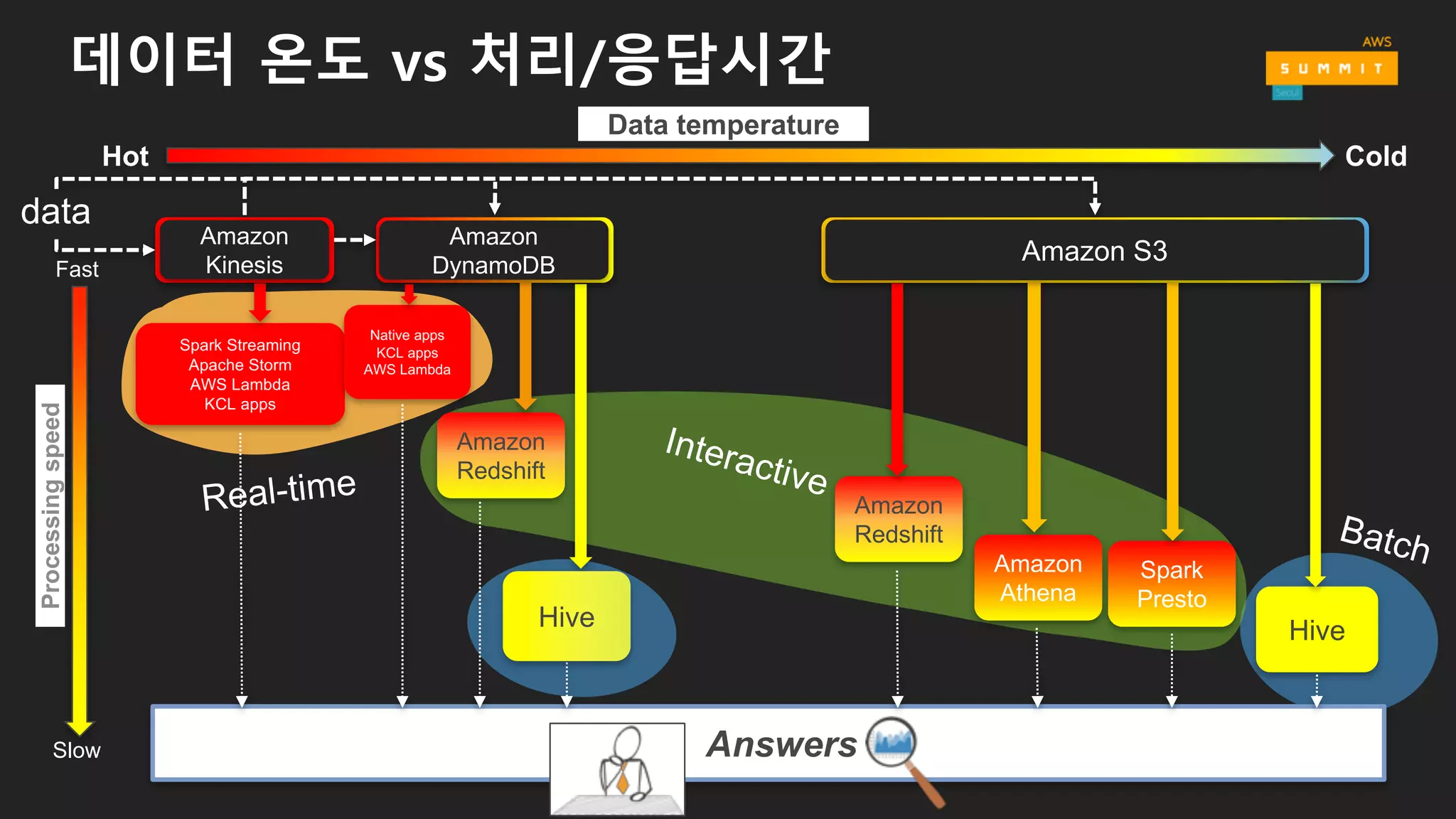
처리/분석 유형 및관련 프레임워크
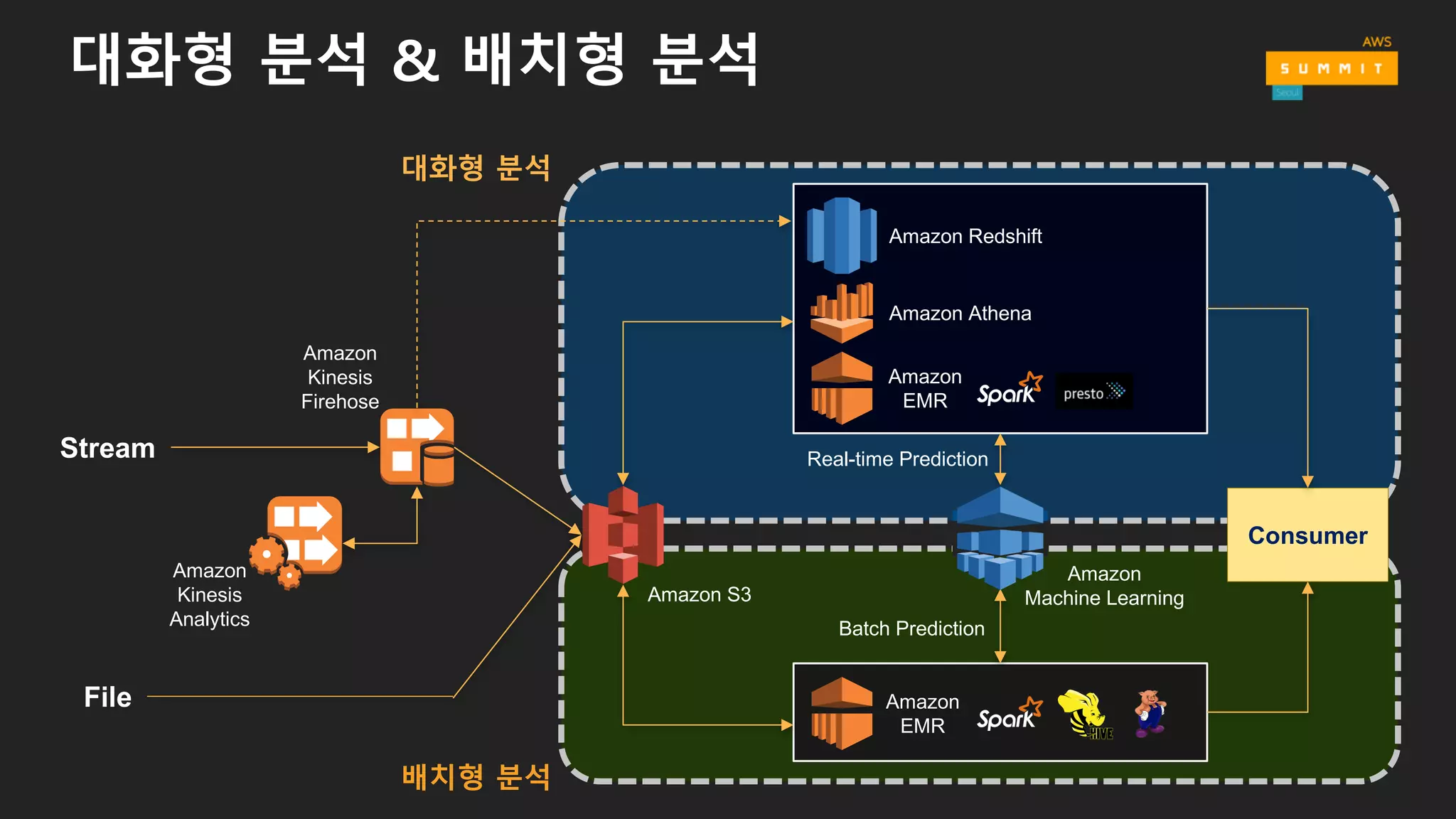
• 배치형 (Batch)
• 소요 시간 : minutes ~ hours
• 일일/주간/월간 보고서
• Amazon EMR (MapReduce, Hive, Pig, Spark)
• 대화형 (Interactive)
• 소요 시간 : seconds
• 셀프 서비스 대시보드
• Amazon Redshift, Amazon Athena, Amazon EMR (Presto, Spark)
• 메시지 (Message)
• 소요 시간 : milliseconds ~ seconds
• 메시지 데이터 처리
• Amazon SQS 애플리케이션
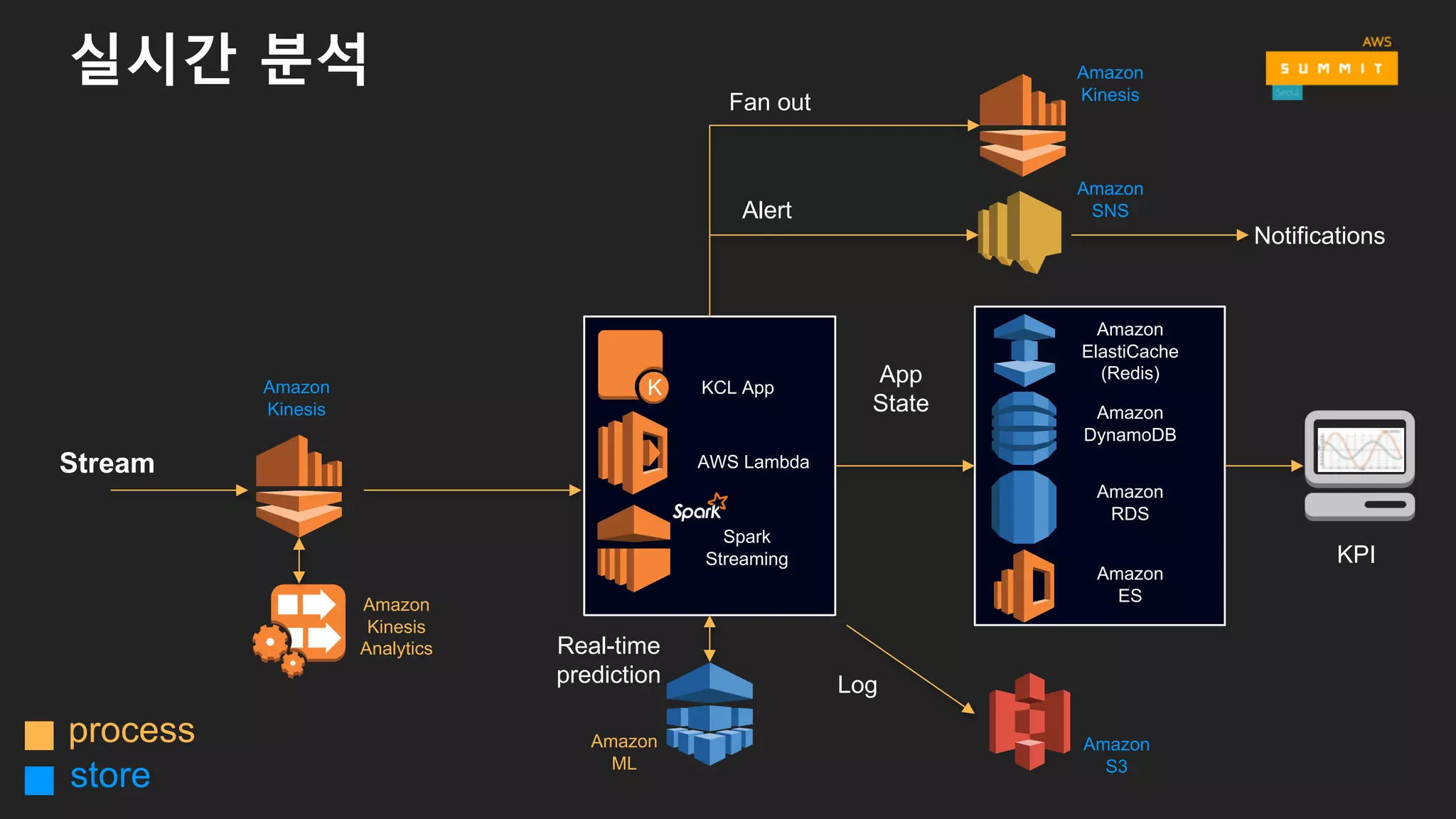
• 스트림 (Stream)
• 소요 시간 : milliseconds ~ seconds
• 사기성 이벤트 경고, 1분 측정
• Amazon EMR (Spark Streaming), Amazon Kinesis Analytics, KCL, Storm,
AWS Lambda
• 분석 (Machine Learning)
• 소요 시간 : milliseconds ~ seconds
• 사기성 이벤트 추적, 예측 분석 모델링
• Amazon ML, Amazon EMR (Spark ML)
Streaming
Amazon Kinesis
Analytics
KCL
apps
AWS Lambda
처리/분석
Fast
Stream
Amazon EC2
Amazon EMR
Amazon SQS apps
Amazon Redshift
Amazon
Machine Learning
Presto
Amazon
EMR
FastSlow
Amazon EC2
Amazon Athena
BatchMessageInteractiveML
28.
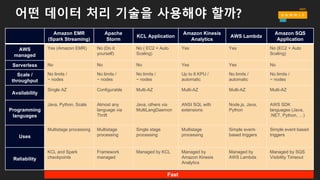
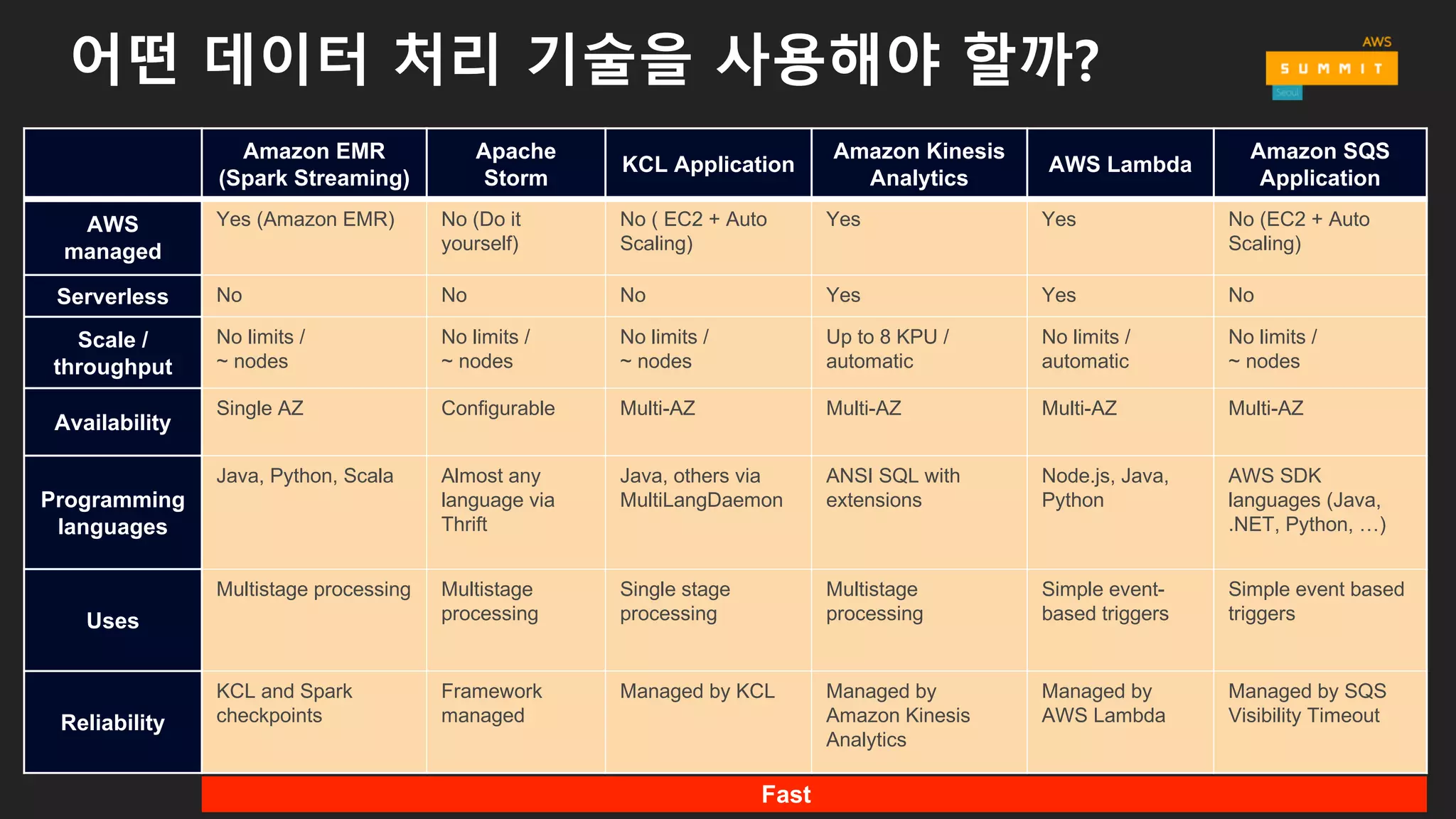
어떤 데이터 처리기술을 사용해야 할까?
Amazon EMR
(Spark Streaming)
Apache
Storm
KCL Application
Amazon Kinesis
Analytics
AWS Lambda
Amazon SQS
Application
AWS
managed
Yes (Amazon EMR) No (Do it
yourself)
No ( EC2 + Auto
Scaling)
Yes Yes No (EC2 + Auto
Scaling)
Serverless No No No Yes Yes No
Scale /
throughput
No limits /
~ nodes
No limits /
~ nodes
No limits /
~ nodes
Up to 8 KPU /
automatic
No limits /
automatic
No limits /
~ nodes
Availability
Single AZ Configurable Multi-AZ Multi-AZ Multi-AZ Multi-AZ
Programming
languages
Java, Python, Scala Almost any
language via
Thrift
Java, others via
MultiLangDaemon
ANSI SQL with
extensions
Node.js, Java,
Python
AWS SDK
languages (Java,
.NET, Python, …)
Uses
Multistage processing Multistage
processing
Single stage
processing
Multistage
processing
Simple event-
based triggers
Simple event based
triggers
Reliability
KCL and Spark
checkpoints
Framework
managed
Managed by KCL Managed by
Amazon Kinesis
Analytics
Managed by
AWS Lambda
Managed by SQS
Visibility Timeout
29.
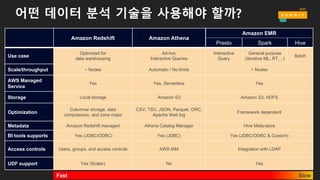
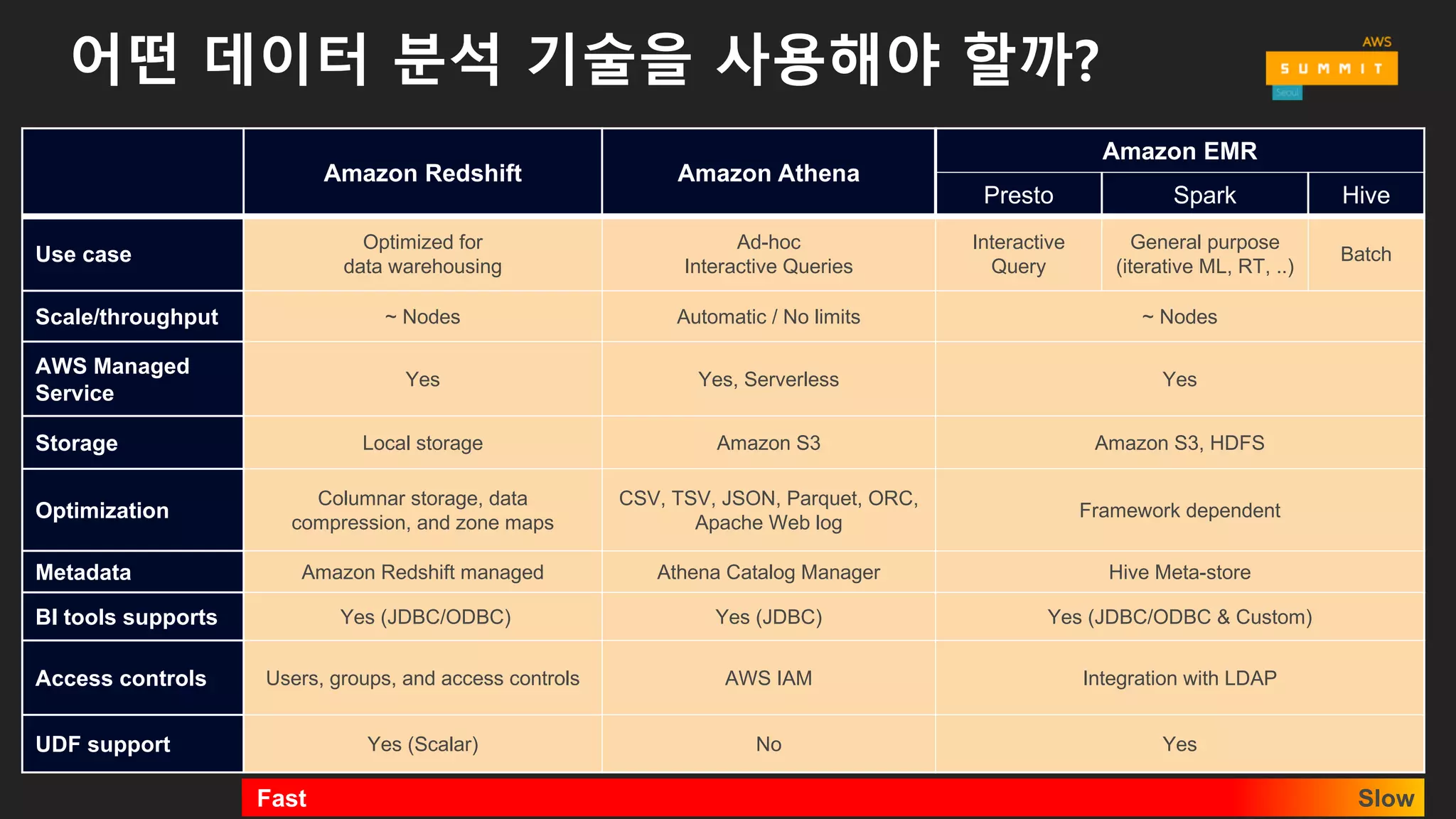
어떤 데이터 분석기술을 사용해야 할까?
Amazon Redshift Amazon Athena
Amazon EMR
Presto Spark Hive
Use case
Optimized for
data warehousing
Ad-hoc
Interactive Queries
Interactive
Query
General purpose
(iterative ML, RT, ..)
Batch
Scale/throughput ~ Nodes Automatic / No limits ~ Nodes
AWS Managed
Service
Yes Yes, Serverless Yes
Storage Local storage Amazon S3 Amazon S3, HDFS
Optimization
Columnar storage, data
compression, and zone maps
CSV, TSV, JSON, Parquet, ORC,
Apache Web log
Framework dependent
Metadata Amazon Redshift managed Athena Catalog Manager Hive Meta-store
BI tools supports Yes (JDBC/ODBC) Yes (JDBC) Yes (JDBC/ODBC & Custom)
Access controls Users, groups, and access controls AWS IAM Integration with LDAP
UDF support Yes (Scalar) No Yes
Slow
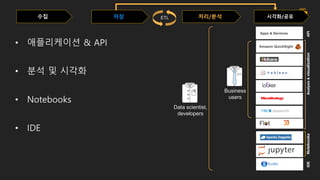
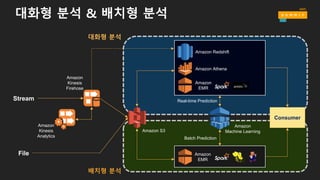
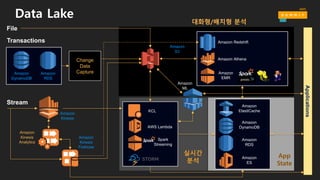
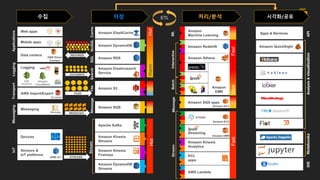
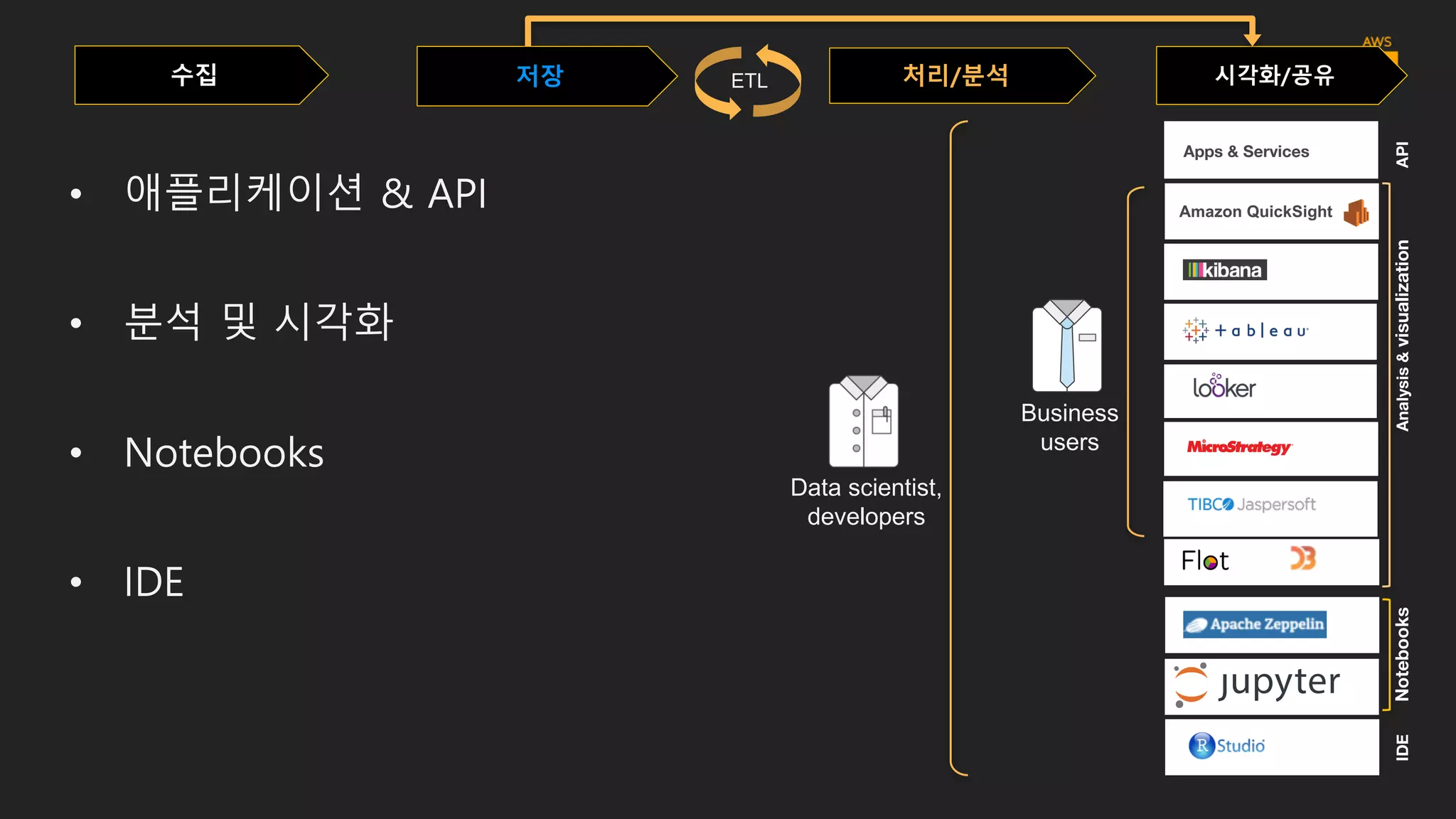
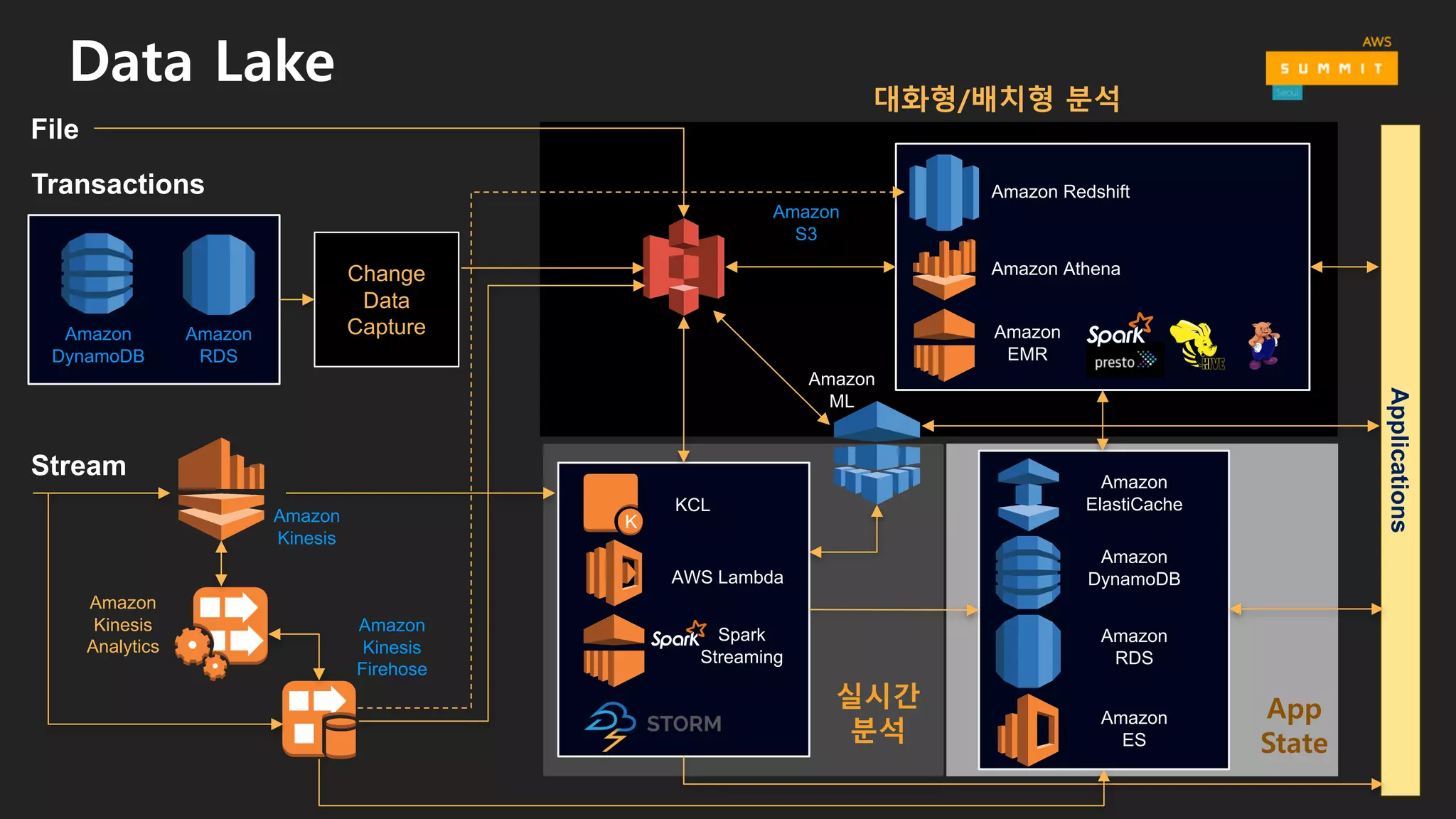
수집 저장 시각화/공유처리/분석
AmazonQuickSight
Apps & Services
Analysis&visualizationNotebooksIDEAPI
ETL
• 애플리케이션 & API
• 분석 및 시각화
• Notebooks
• IDE
Business
users
Data scientist,
developers
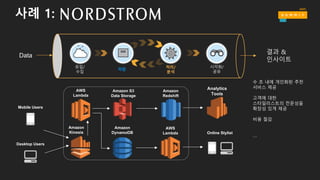
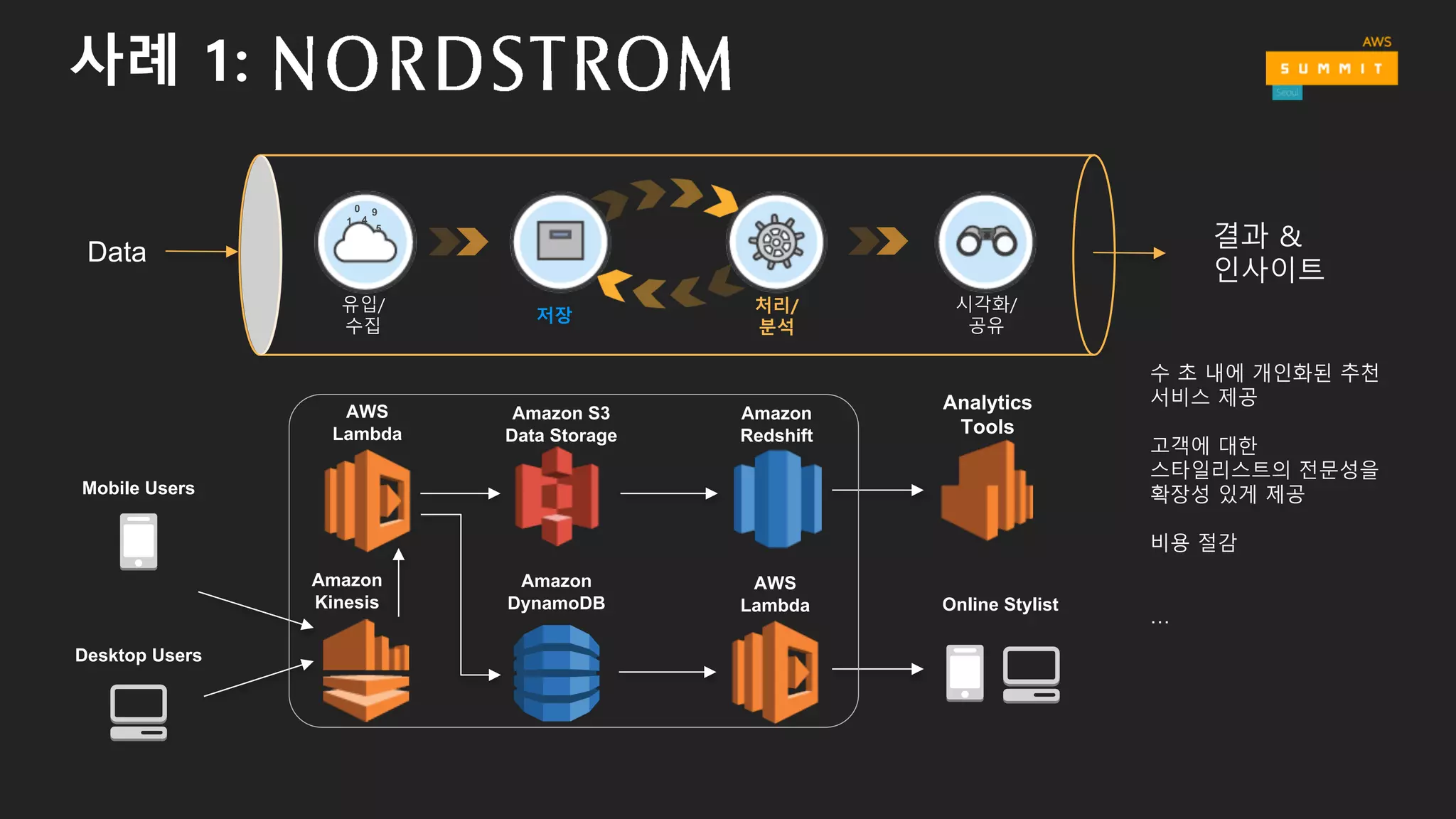
사례 1:
수 초내에 개인화된 추천
서비스 제공
고객에 대한
스타일리스트의 전문성을
확장성 있게 제공
비용 절감
…
Mobile Users
Desktop Users
Analytics
Tools
Online Stylist
Amazon
Redshift
Amazon
Kinesis
AWS
Lambda
Amazon
DynamoDB
AWS
Lambda
Amazon S3
Data Storage
유입/
수집
시각화/
공유
저장
처리/
분석
Data
1 4
0 9
5
Answers &
Insights
46.
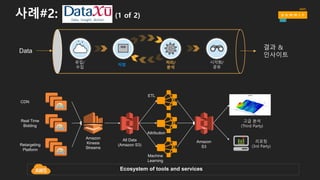
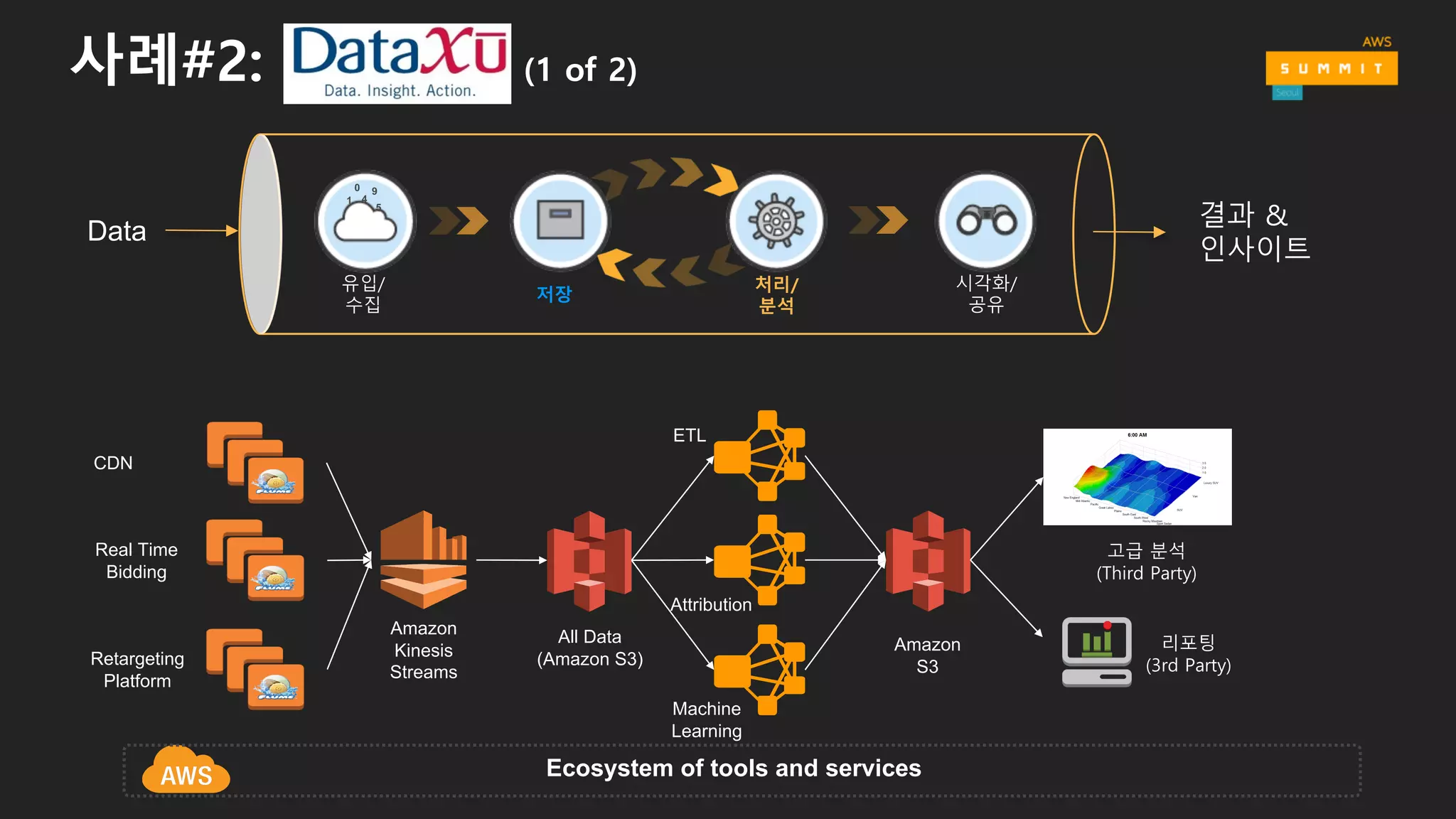
사례#2: (1 of2)
CDN
Real Time
Bidding
Retargeting
Platform
Amazon
Kinesis
Streams
리포팅
(3rd Party)
Machine
Learning
Amazon
S3
All Data
(Amazon S3)
ETL
Attribution
Ecosystem of tools and services
고급 분석
(Third Party)
유입/
수집
시각화/
공유
저장
처리/
분석
Data
1 4
0 9
5
Answers &
Insights
47.
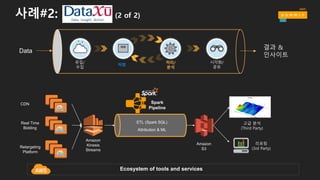
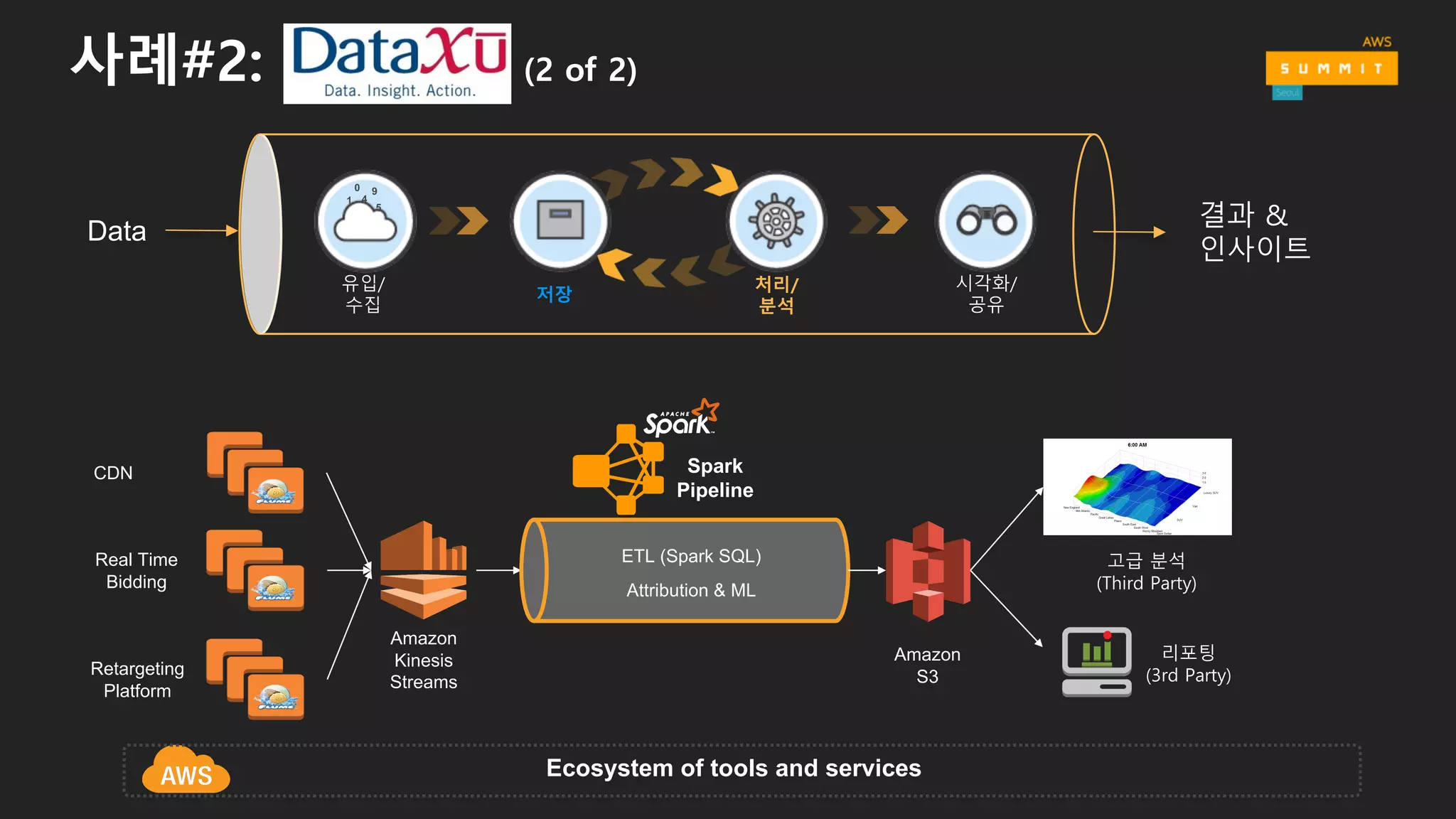
사례#2: (2 of2)
CDN
Real Time
Bidding
Retargeting
Platform
Amazon
Kinesis
Streams
리포팅
(3rd Party)
Amazon
S3
Ecosystem of tools and services
고급 분석
(Third Party)
Spark
Pipeline
ETL (Spark SQL)
Attribution & ML
유입/
수집
시각화/
공유
저장
처리/
분석
Data
1 4
0 9
5
Answers &
Insights
요약
각 단계별로 구분된시스템 구성
• Data → Store → Process → Store → Analyze → Answers
해당 작업에 적합한 툴의 사용
• Data structure, Latency, Throughput, Access patterns
AWS 관리형 서비스의 적용 및 활용
• Scalable/elastic, Available, Reliable, Secure, No(or Low) admin
로그 데이터 특화형 디자인 패턴의 사용
• Immutable logs, Materialized views
비용에 대한 고려
• Big data ≠ Big cost
51.
본 강연이 끝난후…
• AWS 기반 빅데이터 서비스:
https://aws.amazon.com/ko/big-data/
• AWS Big Data Blog:
https://aws.amazon.com/ko/blogs/big-data/
• AWS 한국 블로그:
https://aws.amazon.com/ko/blogs/korea/category/korea-techtips/
• Big Data on AWS 교육:
https://aws.amazon.com/ko/training/course-descriptions/bigdata/
https://www.awssummit.kr
AWS Summit 모바일앱을 통해 지금 세션 평가에
참여하시면, 행사후 기념품을 드립니다.
#AWSSummitKR 해시태그로 소셜 미디어에
여러분의 행사 소감을 올려주세요.
발표 자료 및 녹화 동영상은 AWS Korea 공식 소셜
채널로 공유될 예정입니다.
여러분의 피드백을 기다립니다!




























































![[115]쿠팡 서비스 클라우드 마이그레이션 통해 배운것들](https://cdn.slidesharecdn.com/ss_thumbnails/115coupang-181011031522-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



![[AWS Builders] AWS와 함께하는 클라우드 컴퓨팅](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudcomputingchoelkang-190305081301-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








![[Retail & CPG Day 2019] 유통 고객의 AWS 도입 동향 - 박동국, AWS 어카운트 매니저, 김준성, AWS어카운트 매니저](https://cdn.slidesharecdn.com/ss_thumbnails/dongkukpark-191024042355-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















![[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략](https://cdn.slidesharecdn.com/ss_thumbnails/datafreedomdatabase-171027021754-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



