Downloaded 74 times


![Una visualizzazione [di una parte] del web
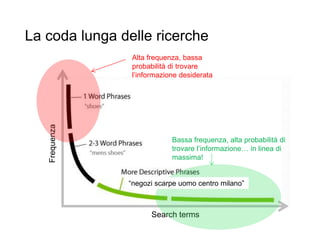
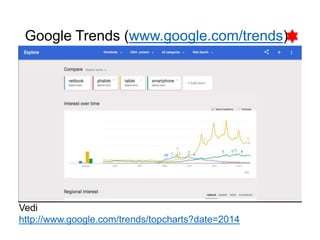
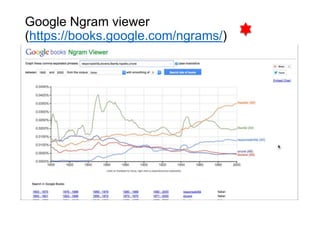
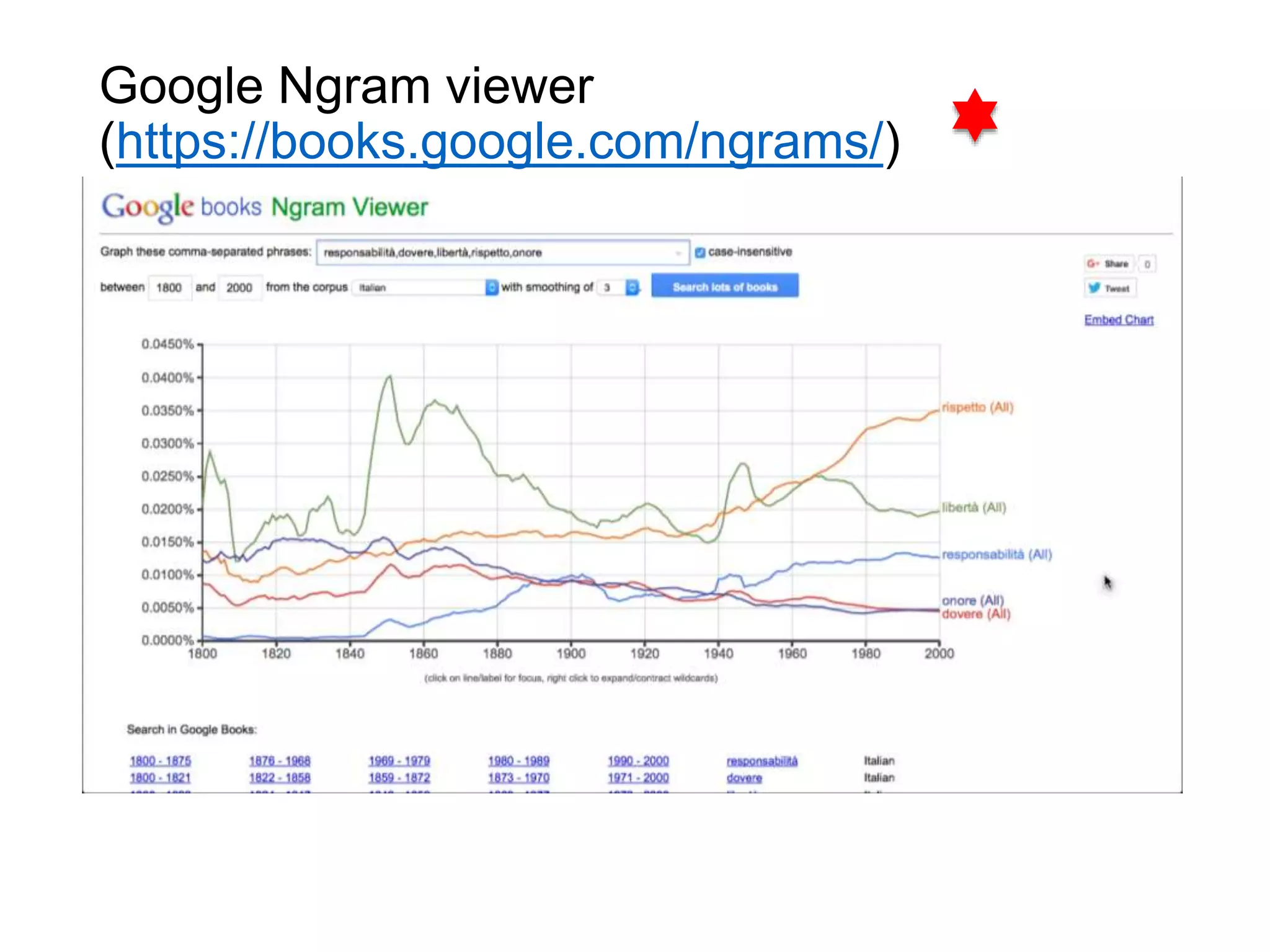
R.Polillo - Marzo 2015 3
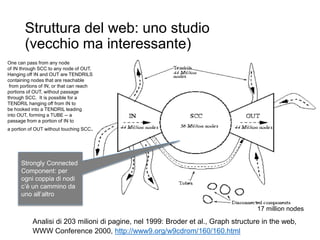
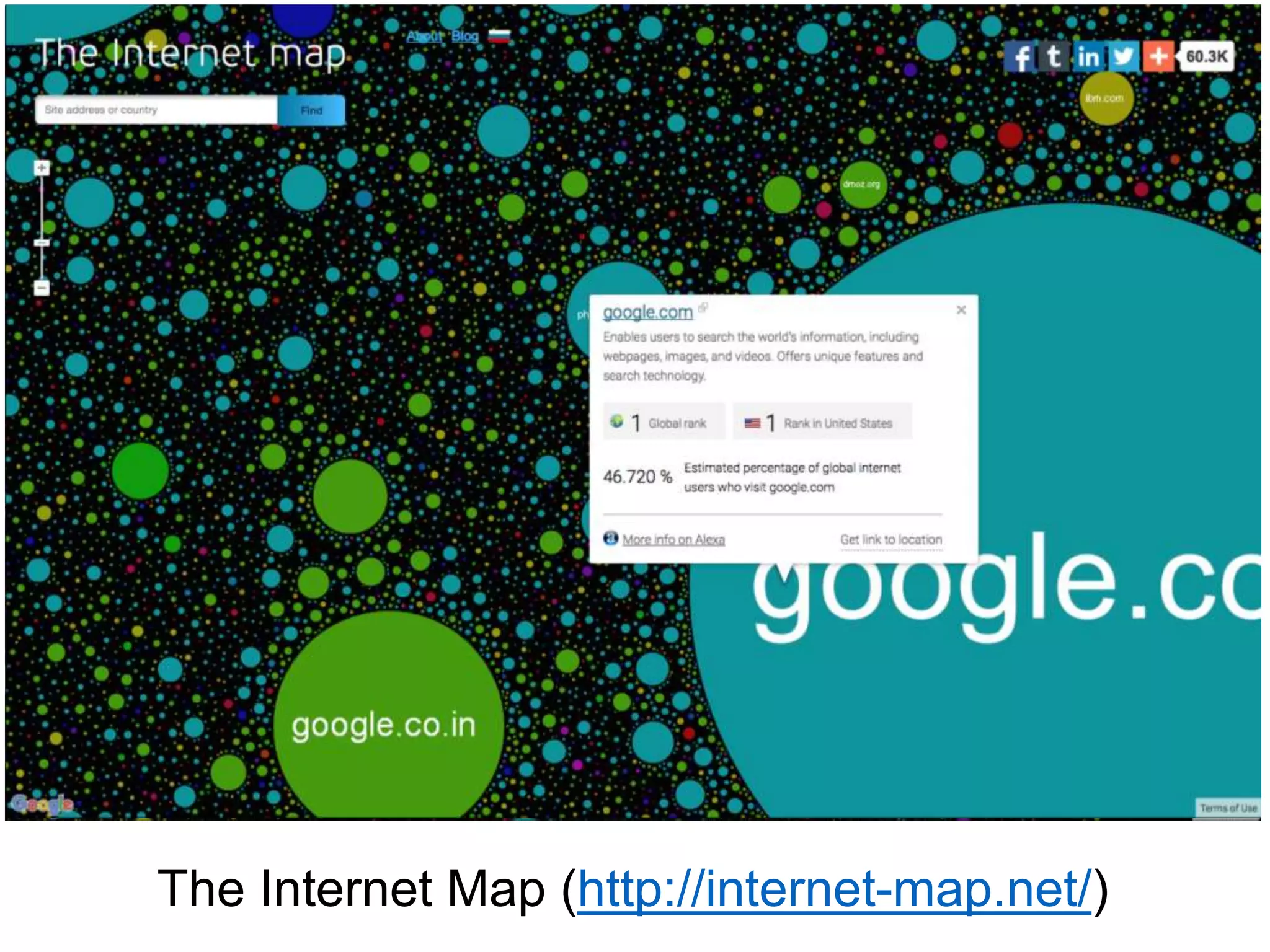
La immagine mostra una porzione di Internet costituita da 535.000 nodi e più di 600.000 links
WALRUS Visualization tool, 2001 http://www.caida.org/tools/visualization/walrus/](https://image.slidesharecdn.com/20161018-ricerca-161015150615/85/7-Ricercare-nel-web-16-17-3-320.jpg)
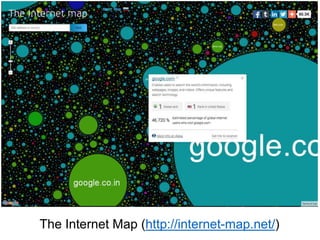




















![Una visualizzazione [di una parte] del web
R.Polillo - Marzo 2015 3
La immagine mostra una porzione di Internet costituita da 535.000 nodi e più di 600.000 links
WALRUS Visualization tool, 2001 http://www.caida.org/tools/visualization/walrus/](https://image.slidesharecdn.com/20161018-ricerca-161015150615/75/7-Ricercare-nel-web-16-17-3-2048.jpg)


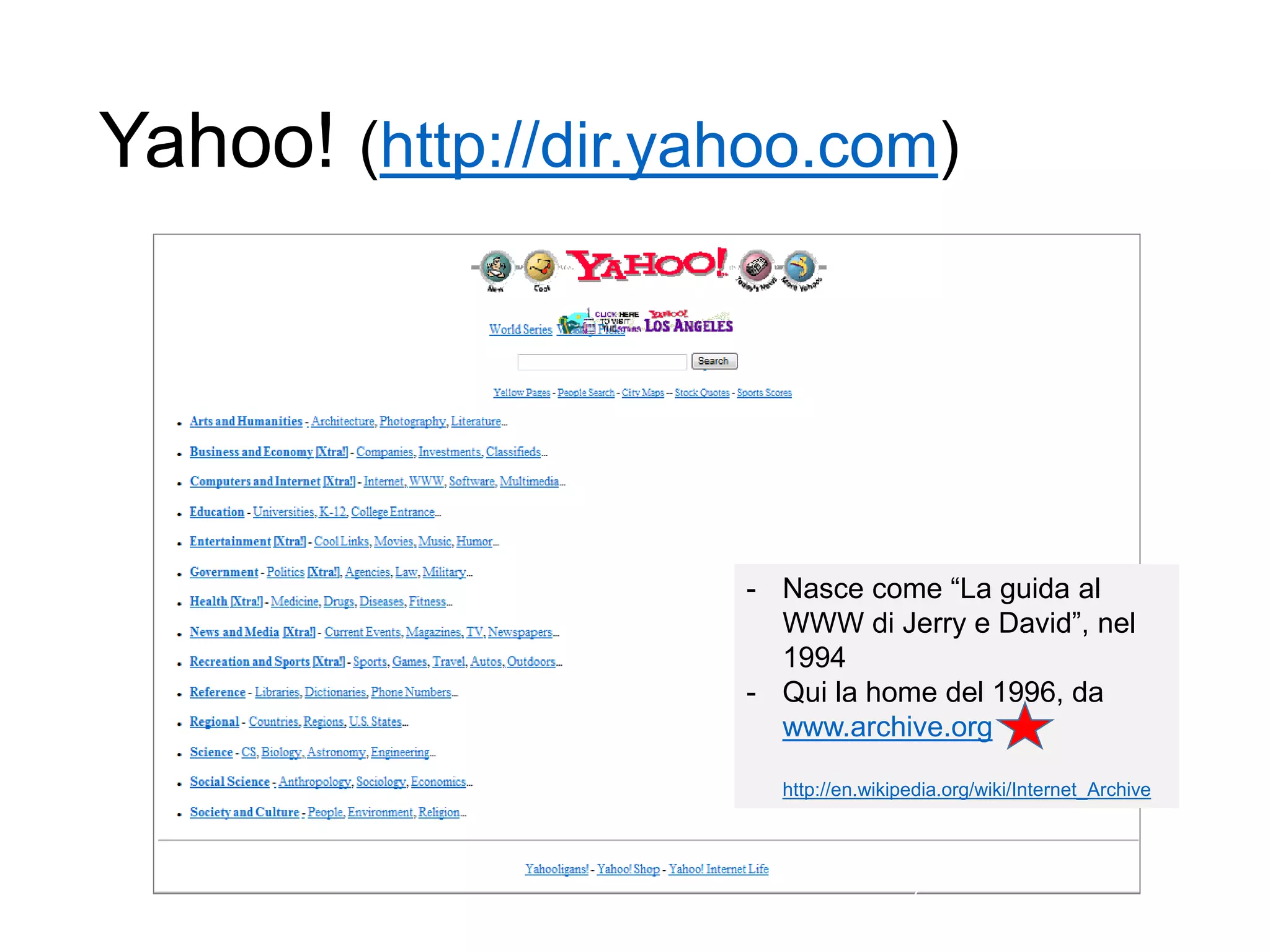






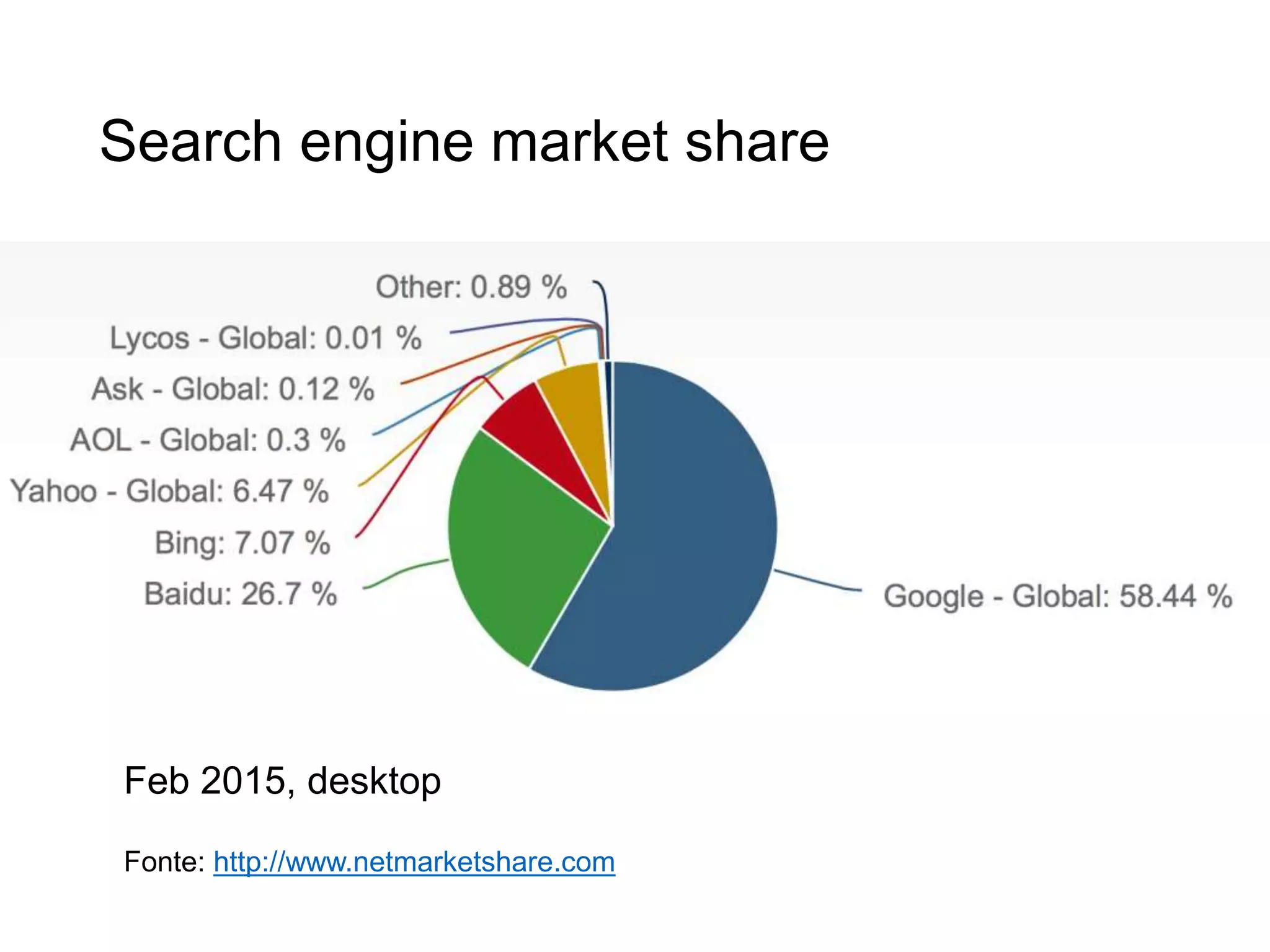
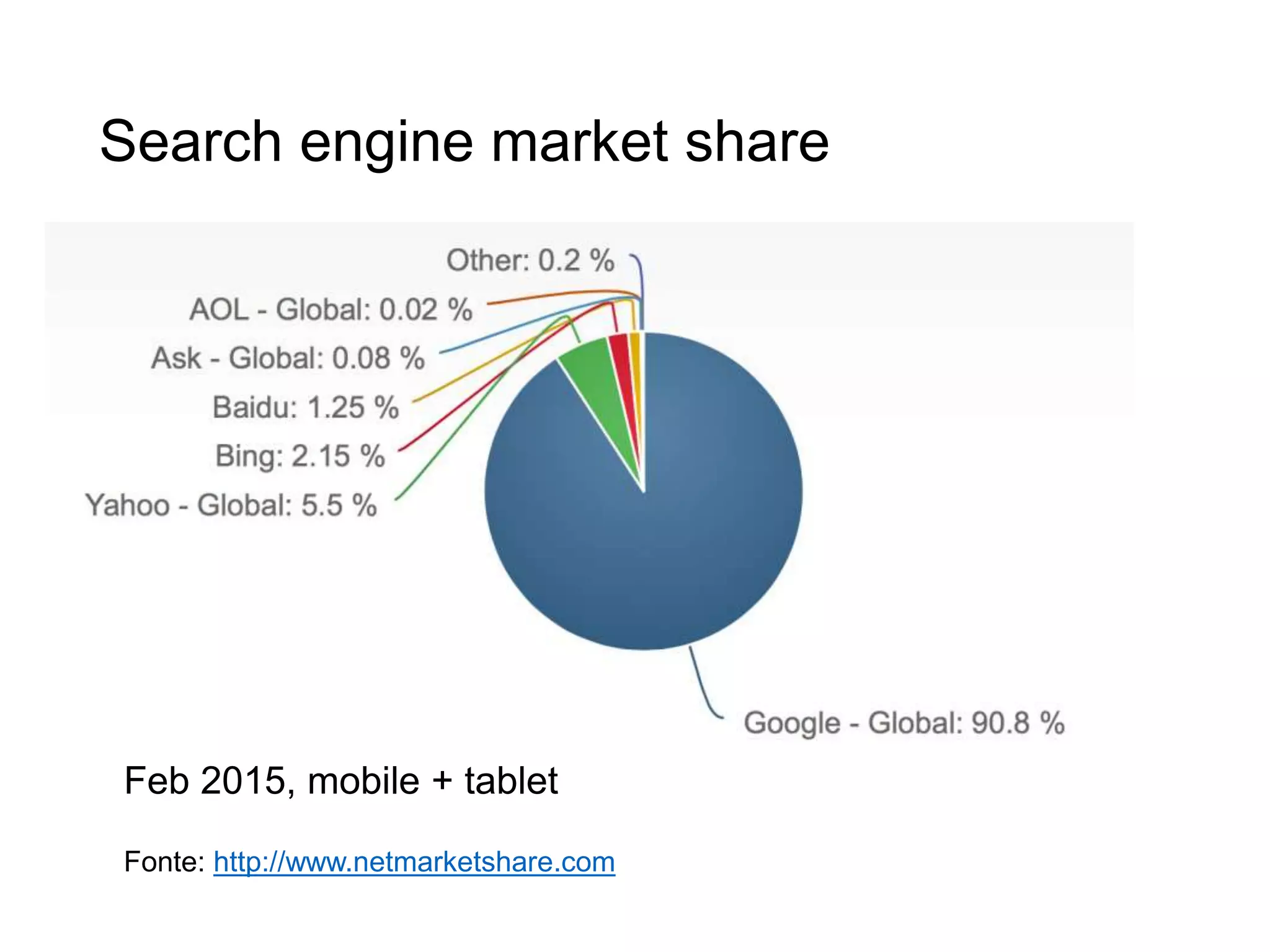
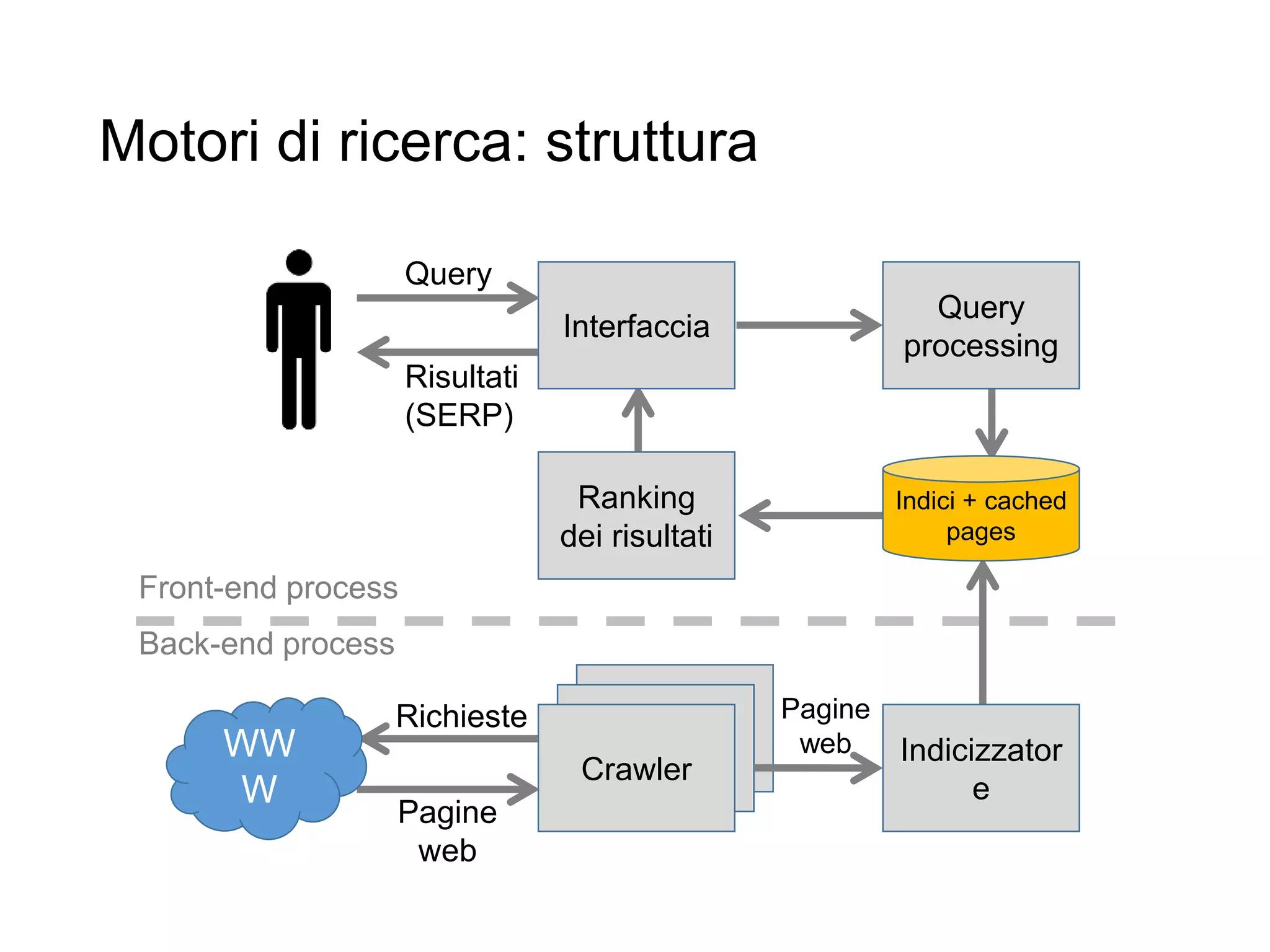


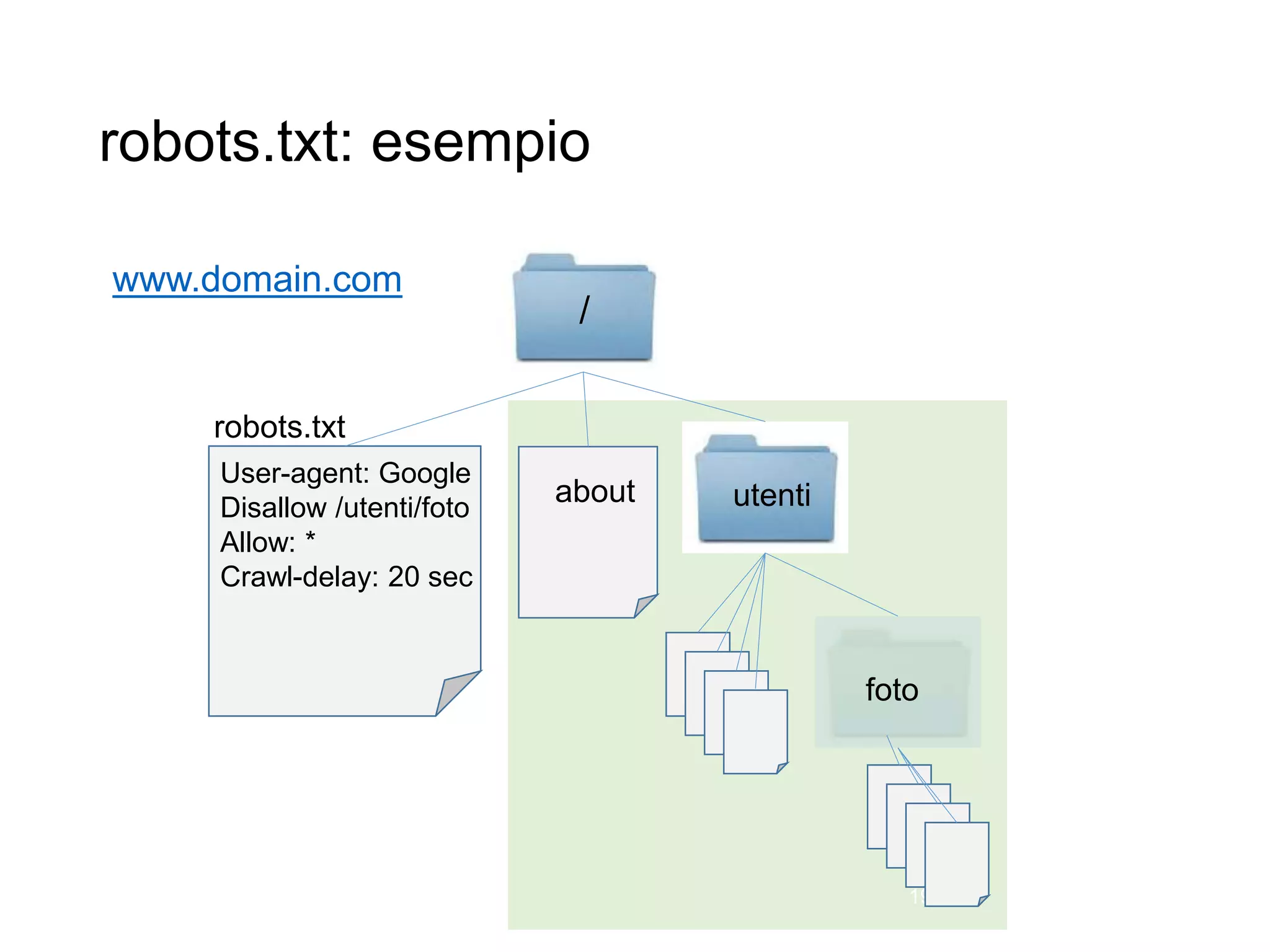

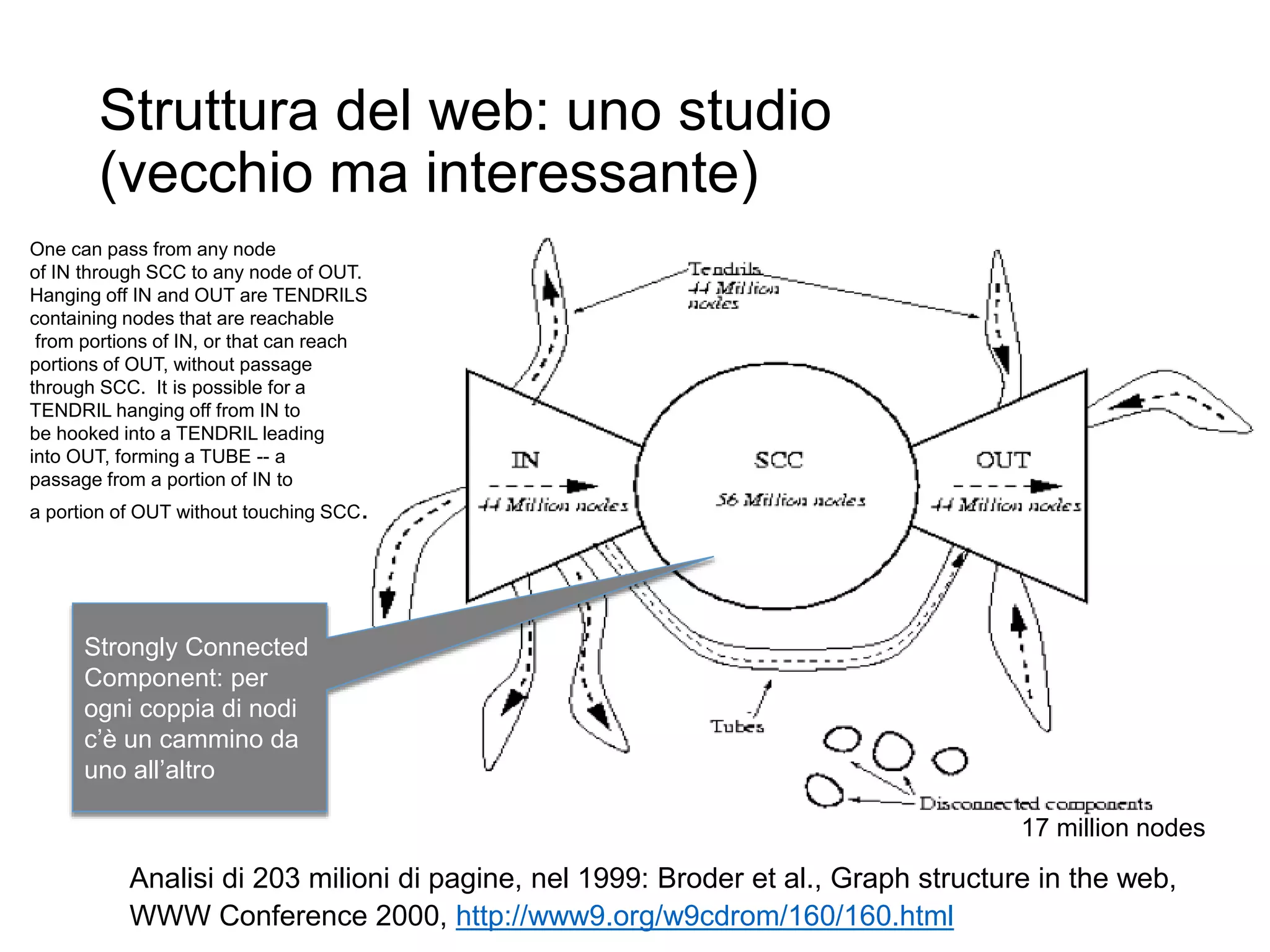
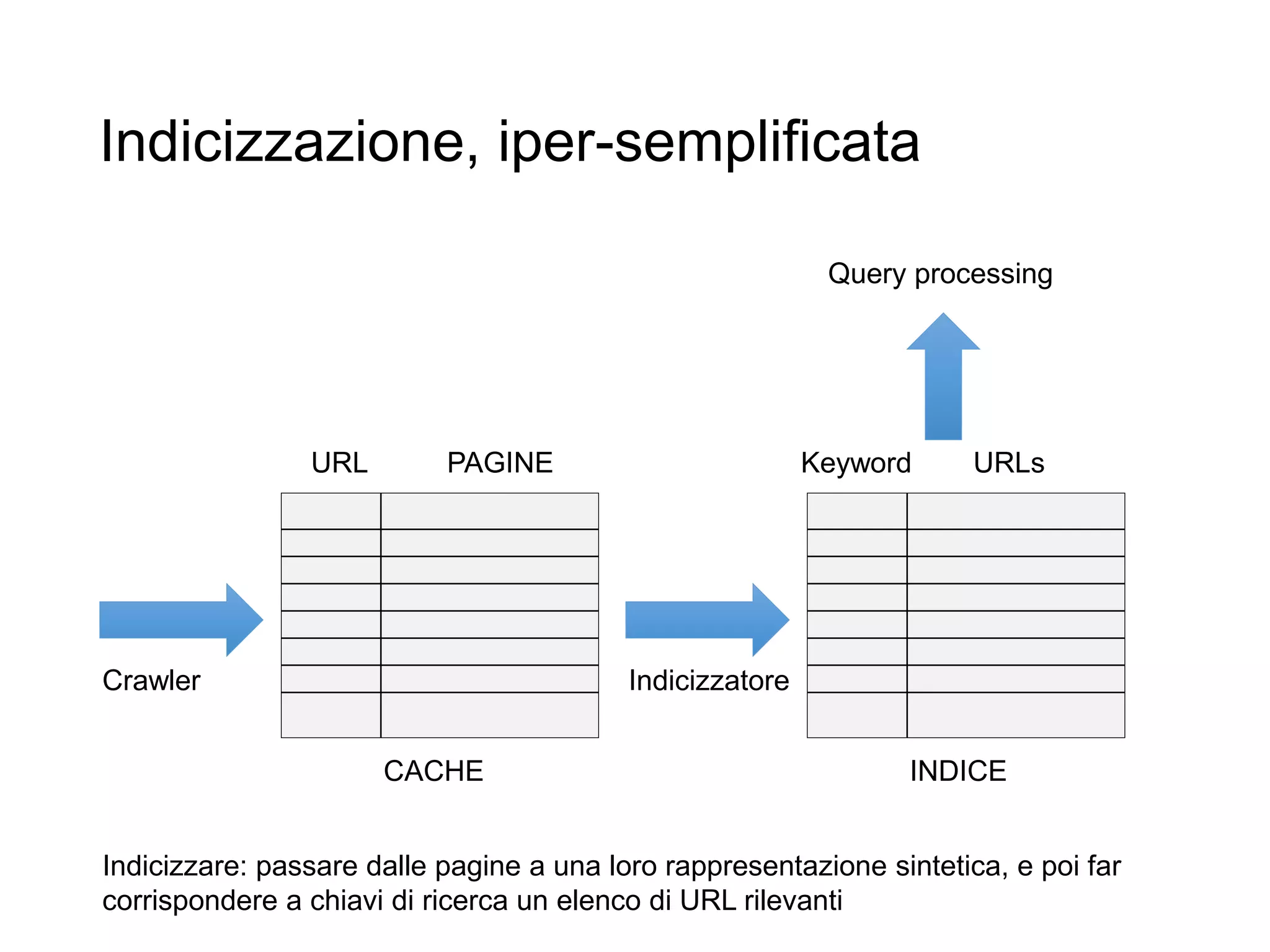
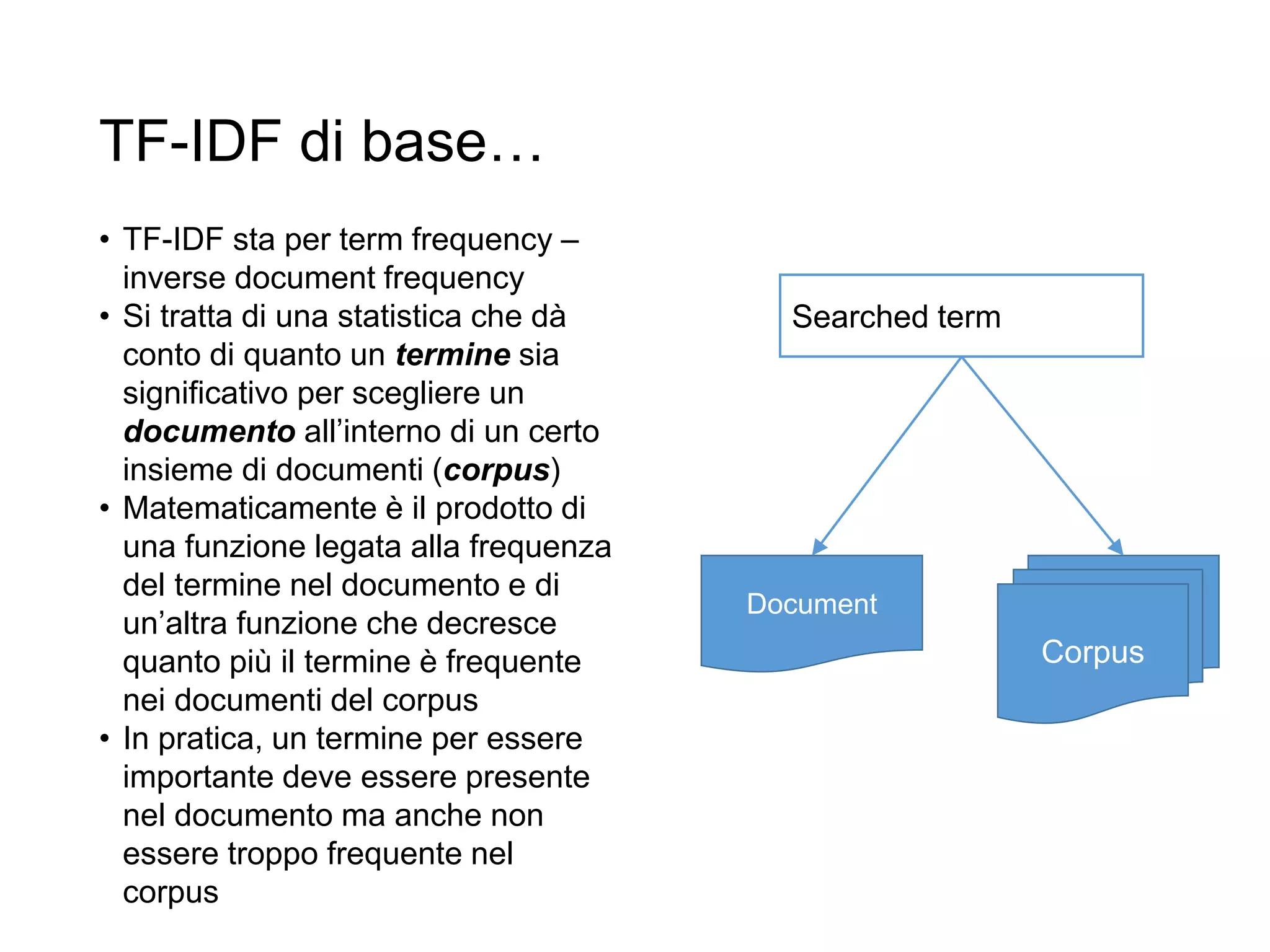
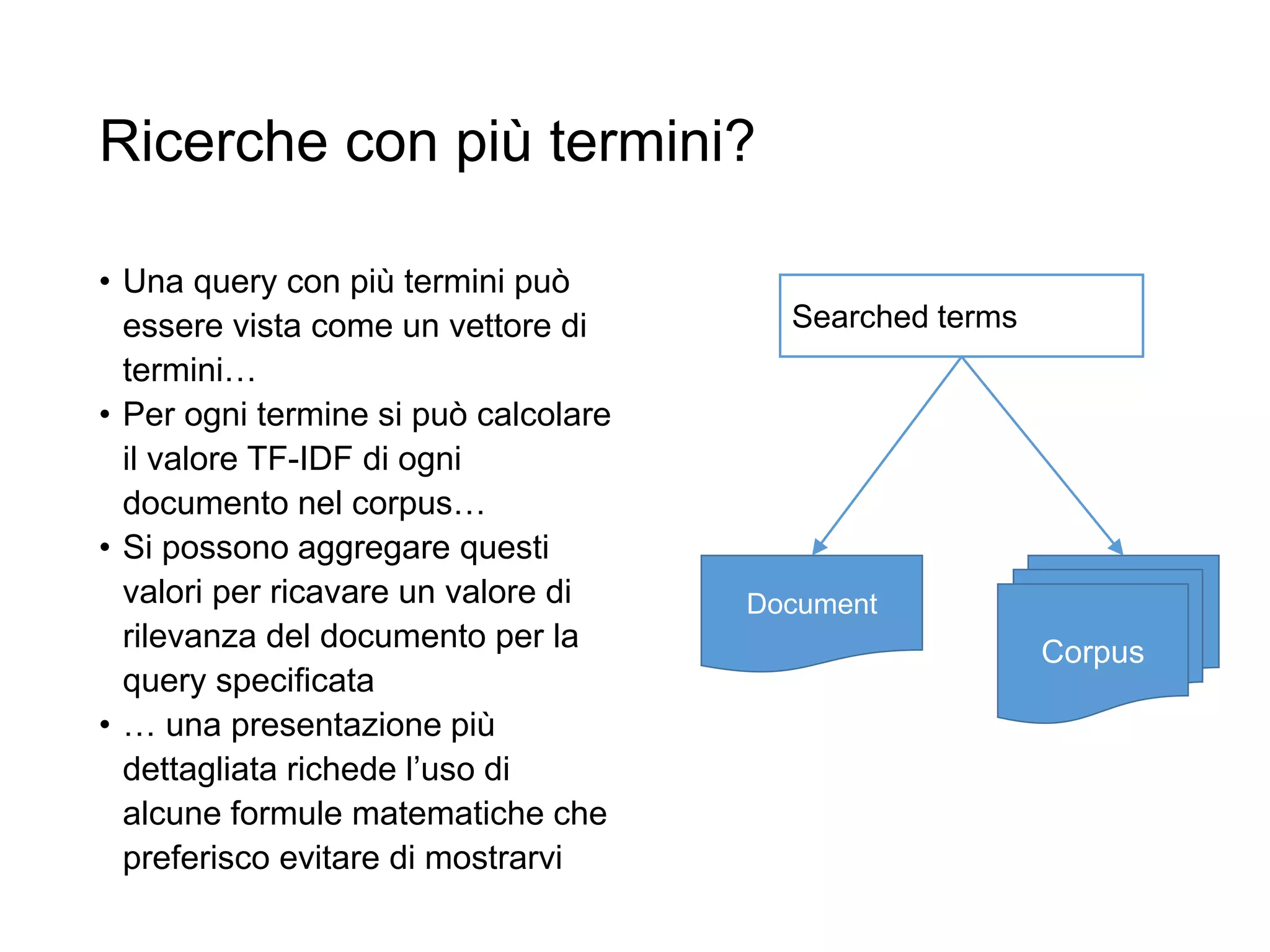


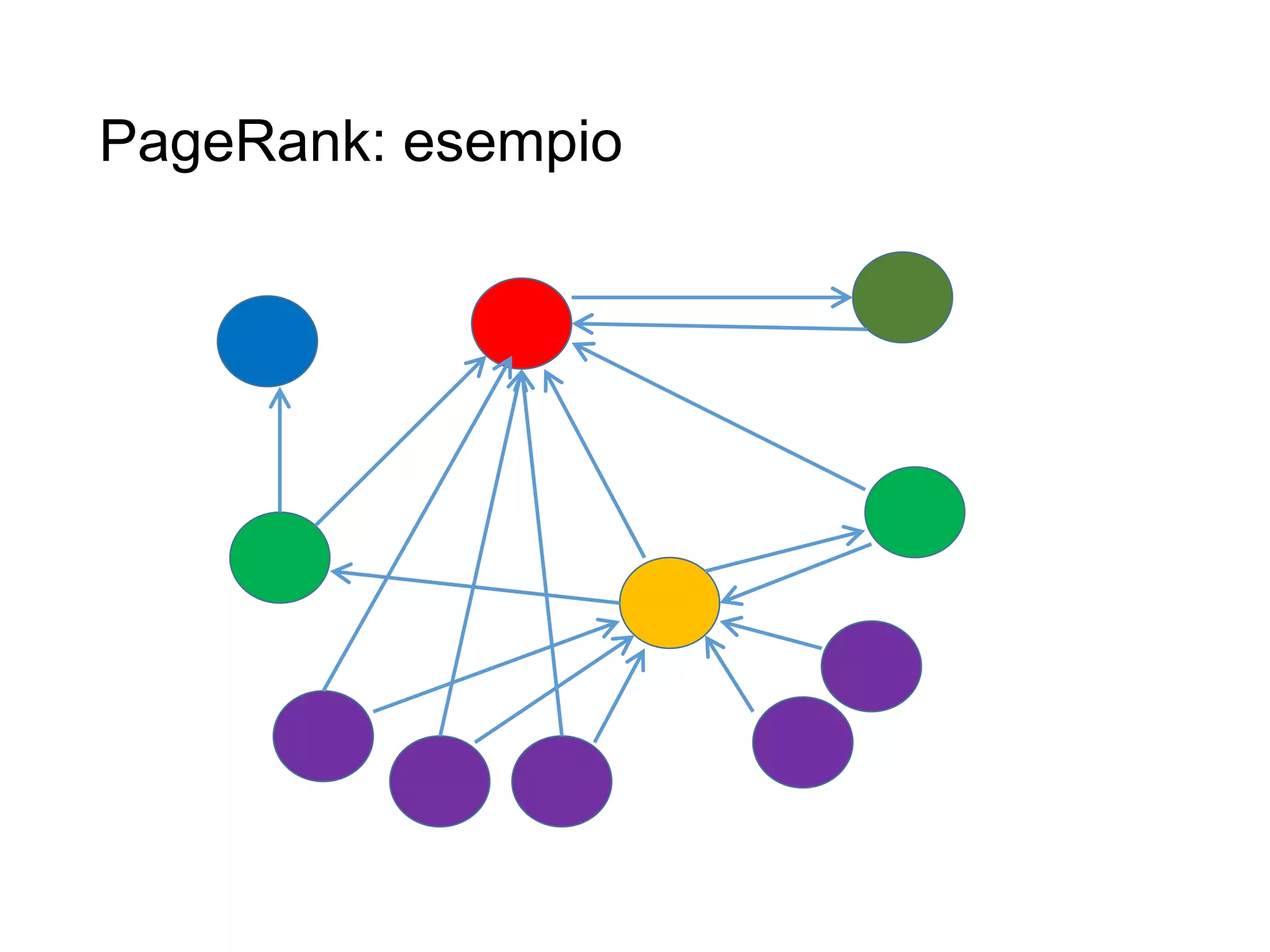
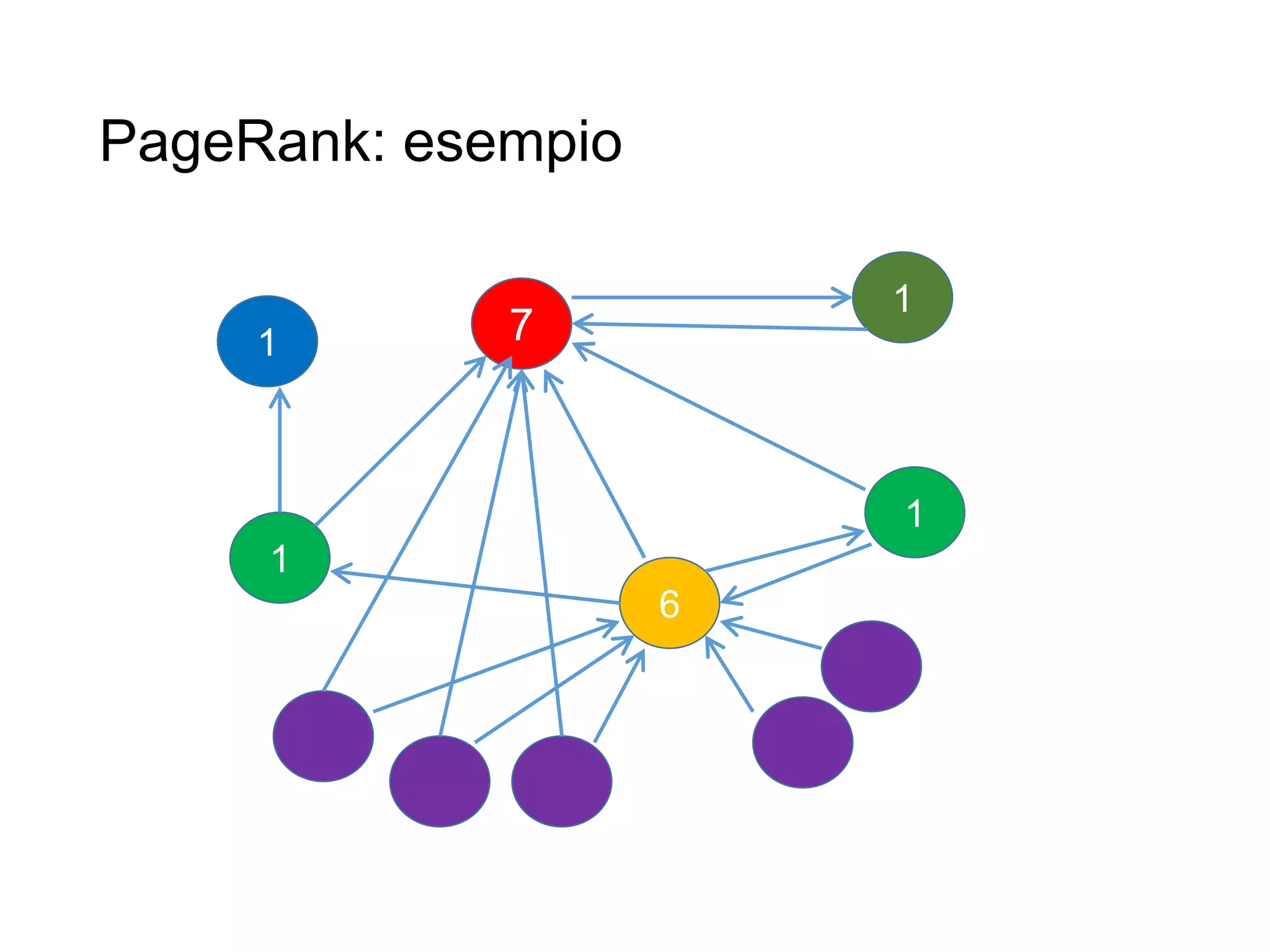
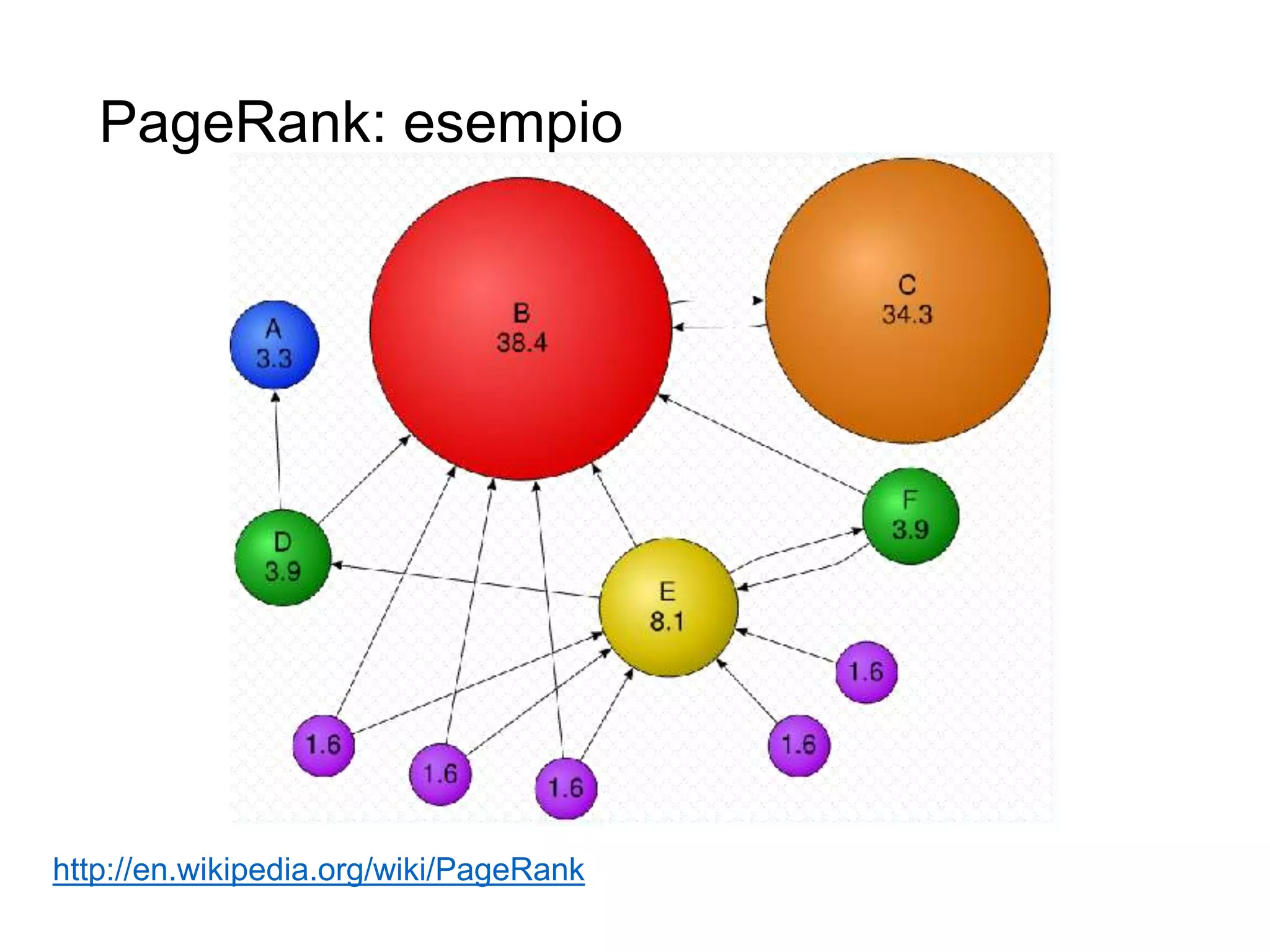






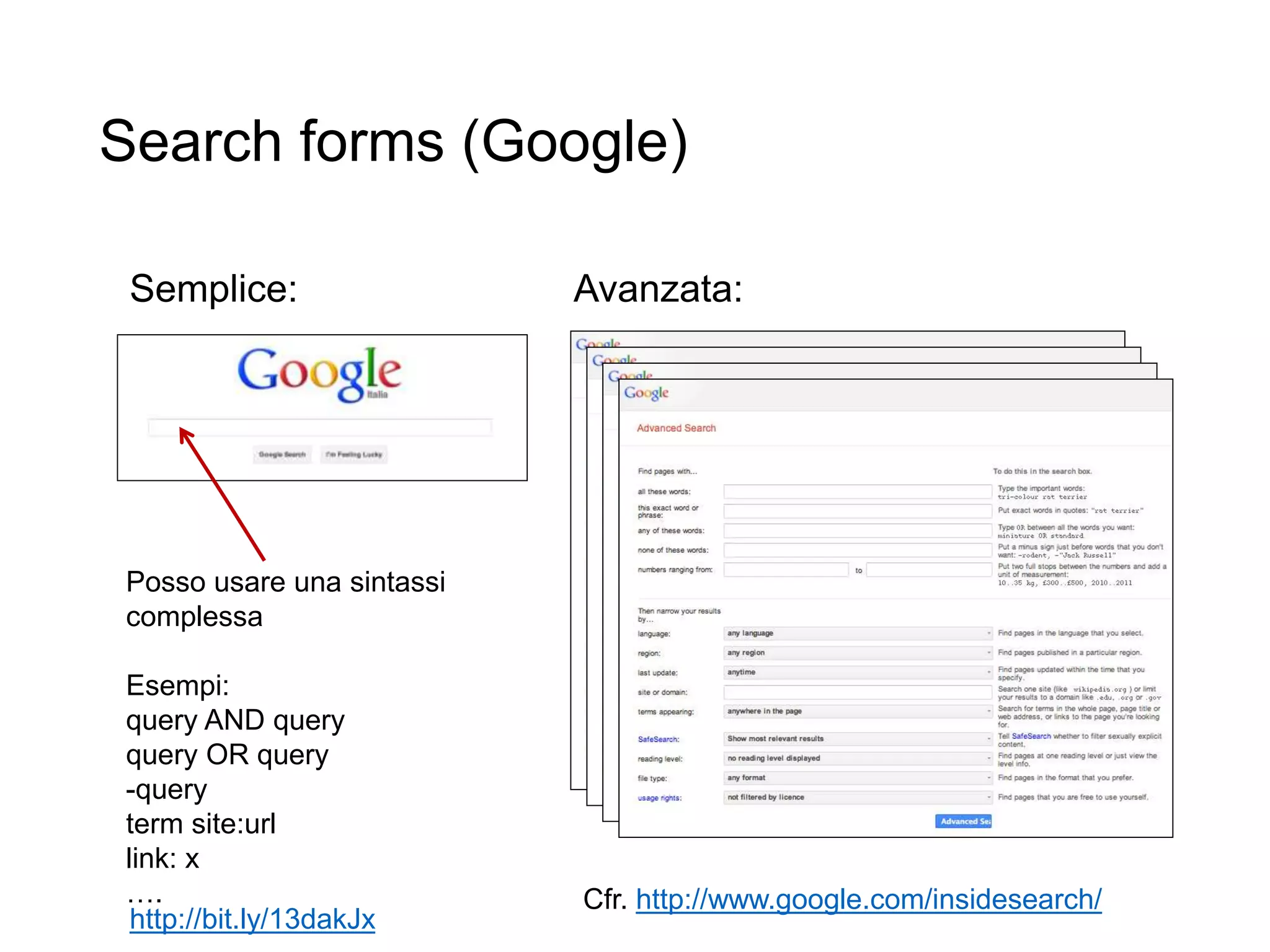
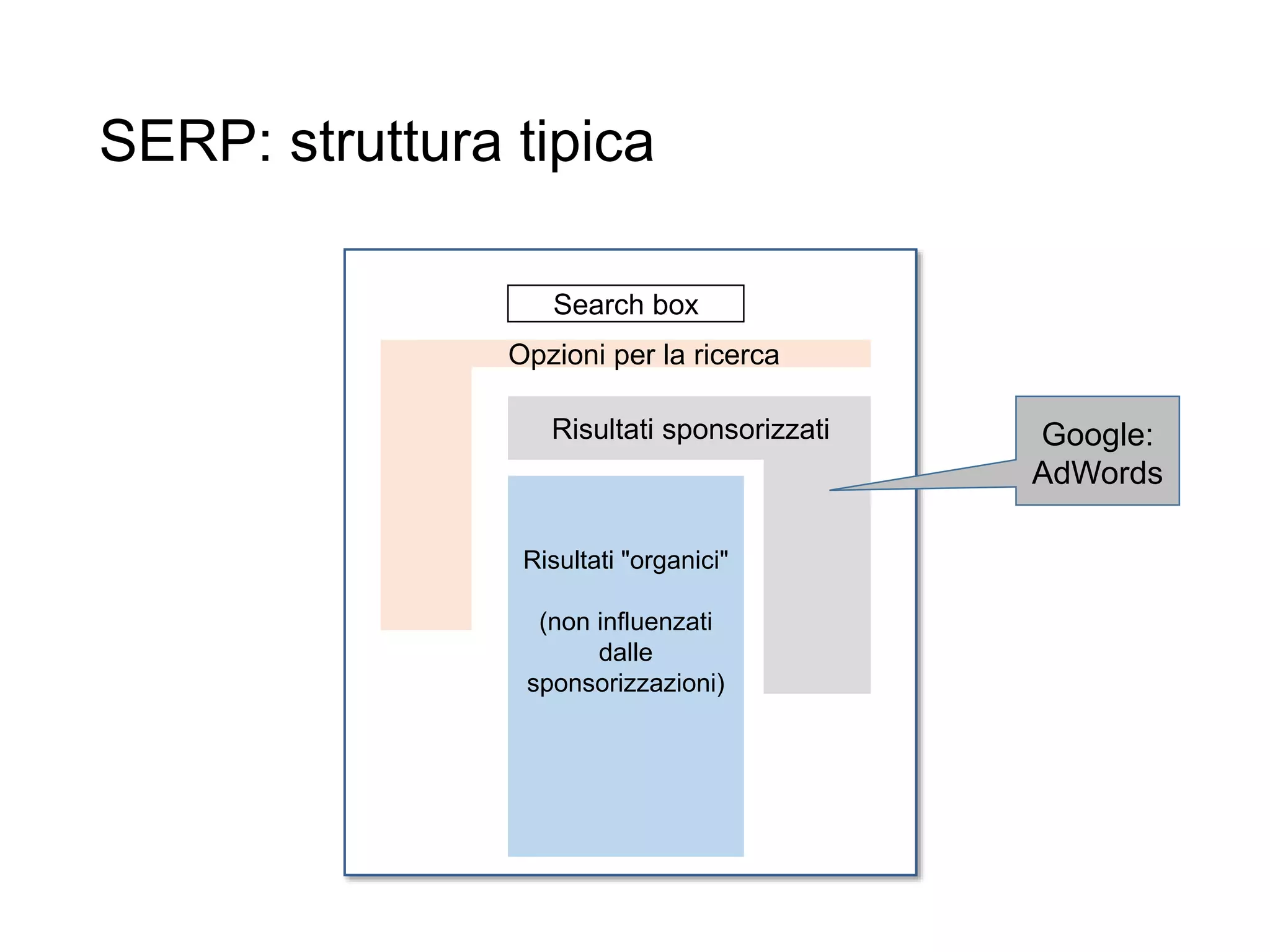
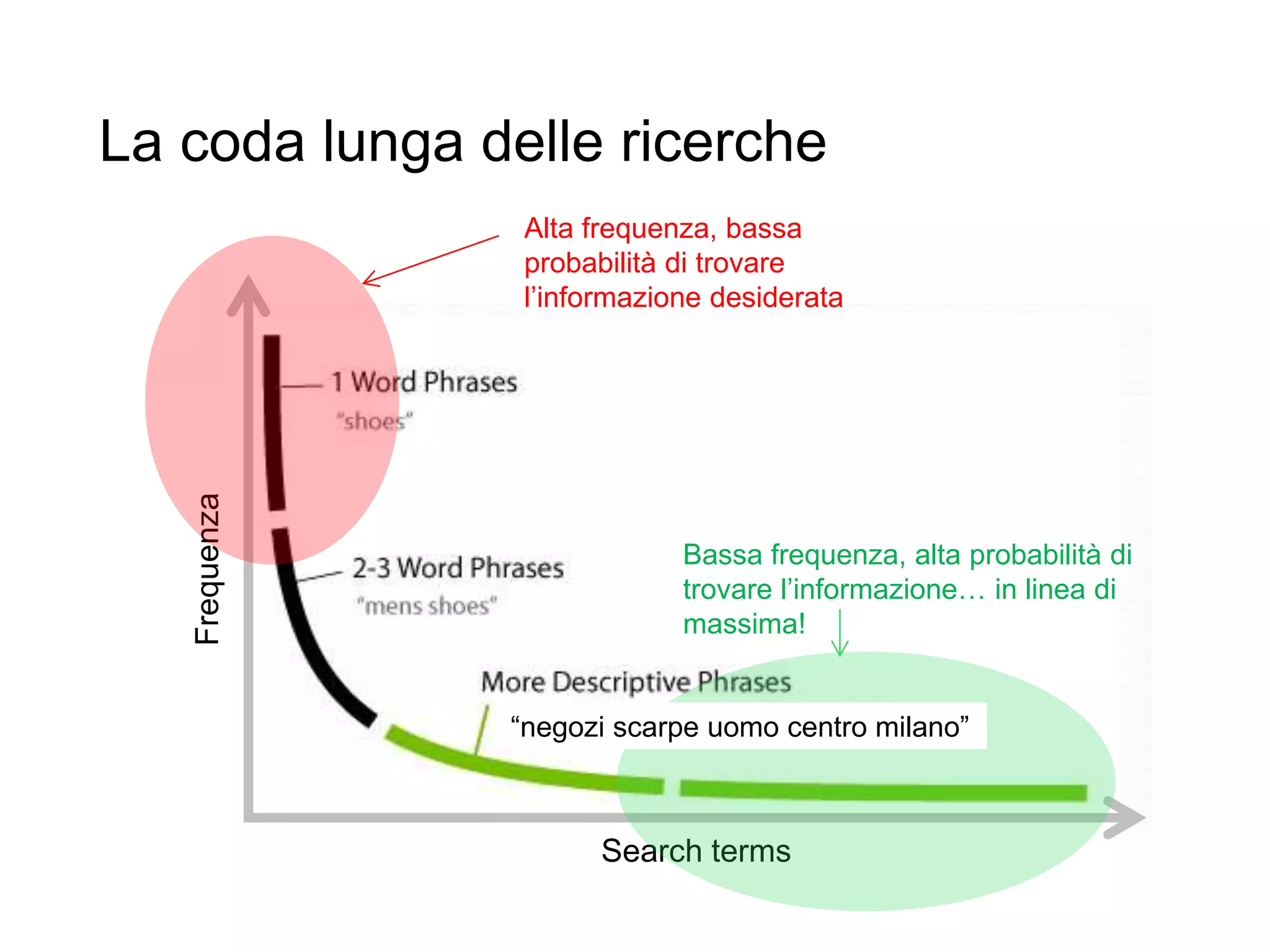
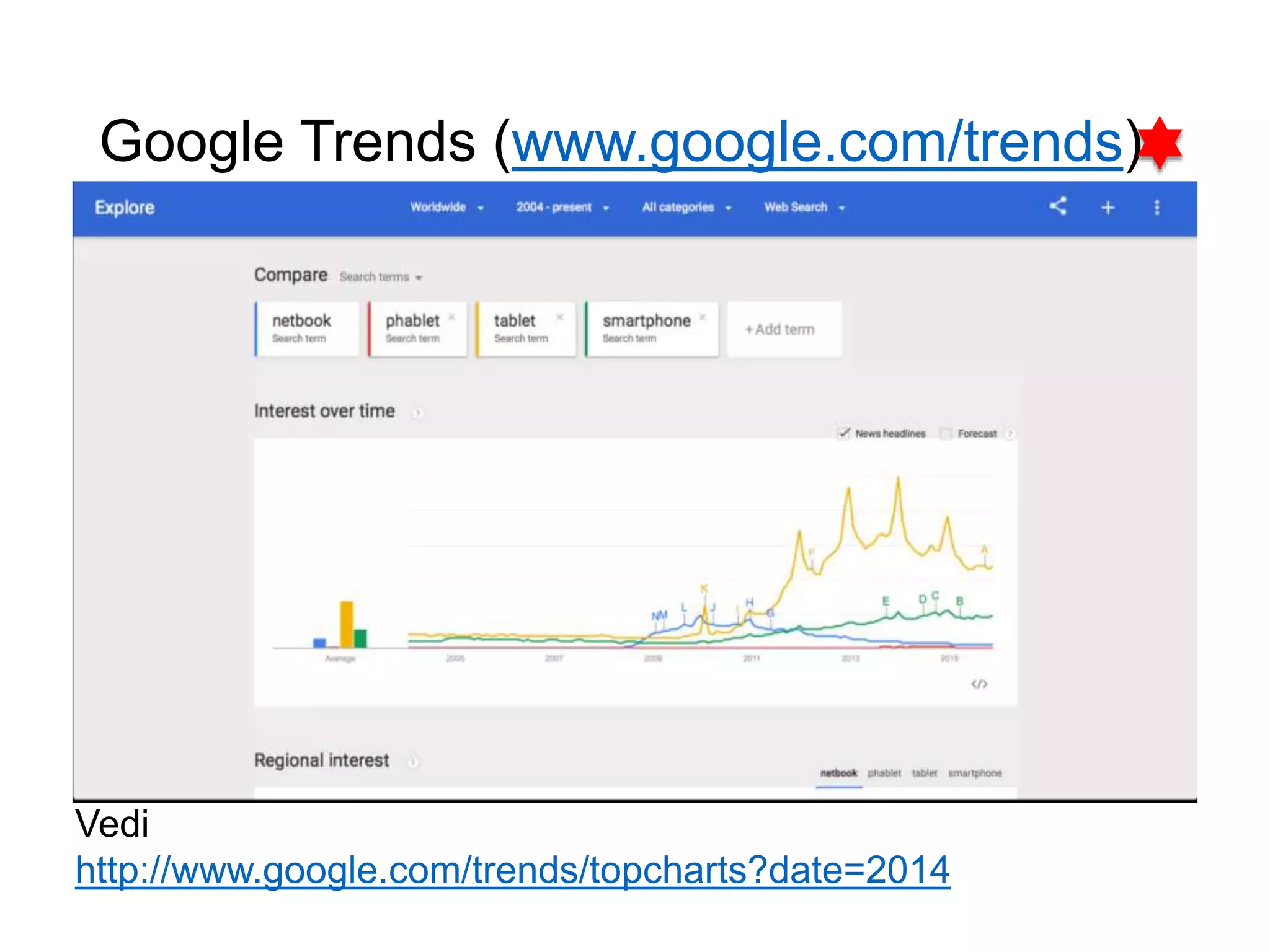

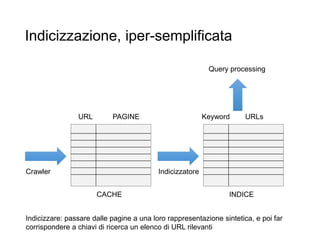
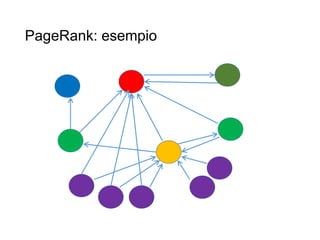
Il documento fornisce un'introduzione al corso universitario 'Strumenti e Applicazioni del Web', evidenziando modi per ricercare informazioni online attraverso directory, motori di ricerca e piattaforme come Wikipedia. Viene discusso il concetto di serendipità nella ricerca e si analizzano componenti e funzionamento dei motori di ricerca, inclusi algoritmi di ranking come PageRank. Infine, vengono menzionate le tecniche di SEO e SEM per migliorare la visibilità dei siti web nei risultati di ricerca.
































































































