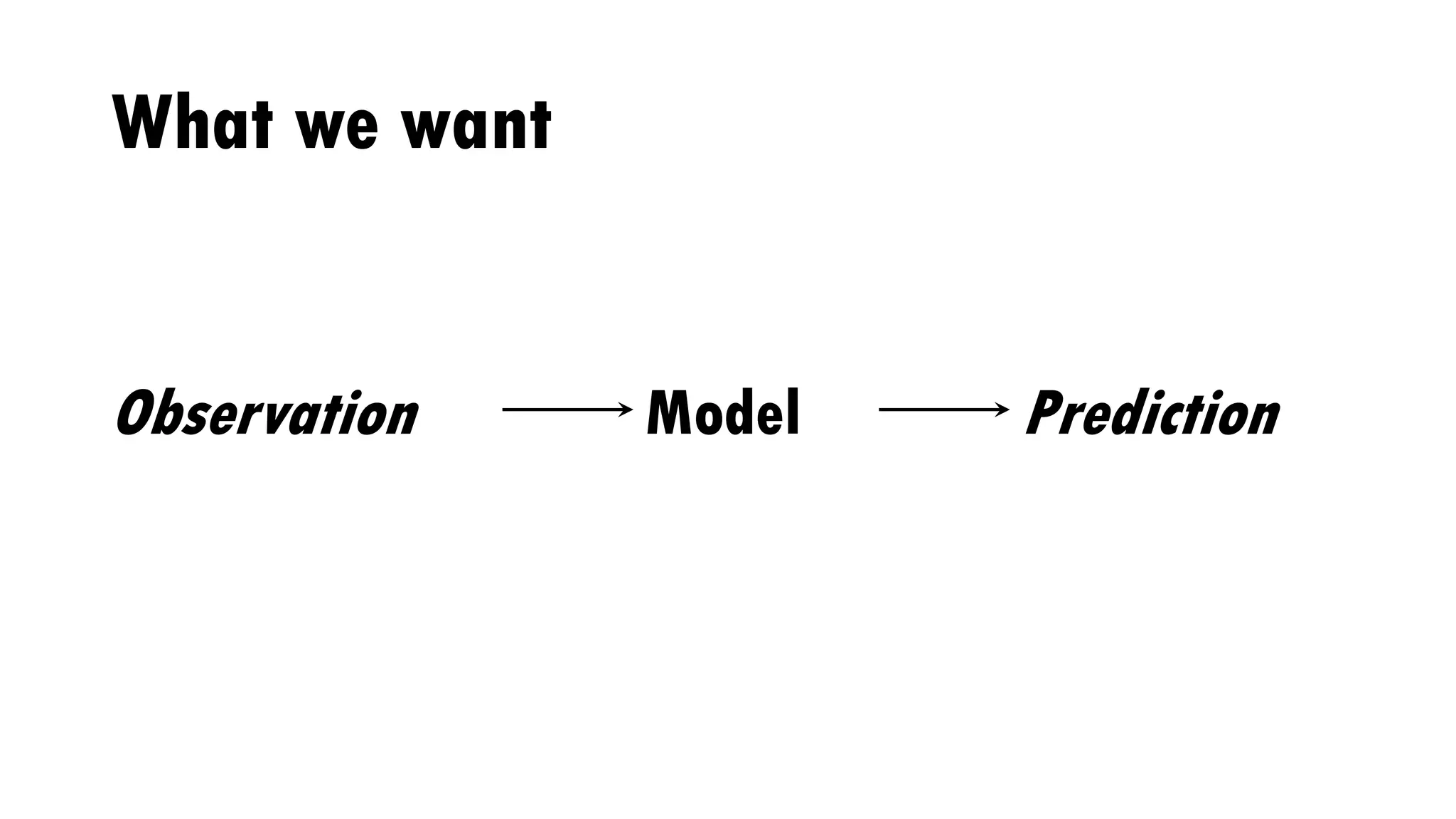
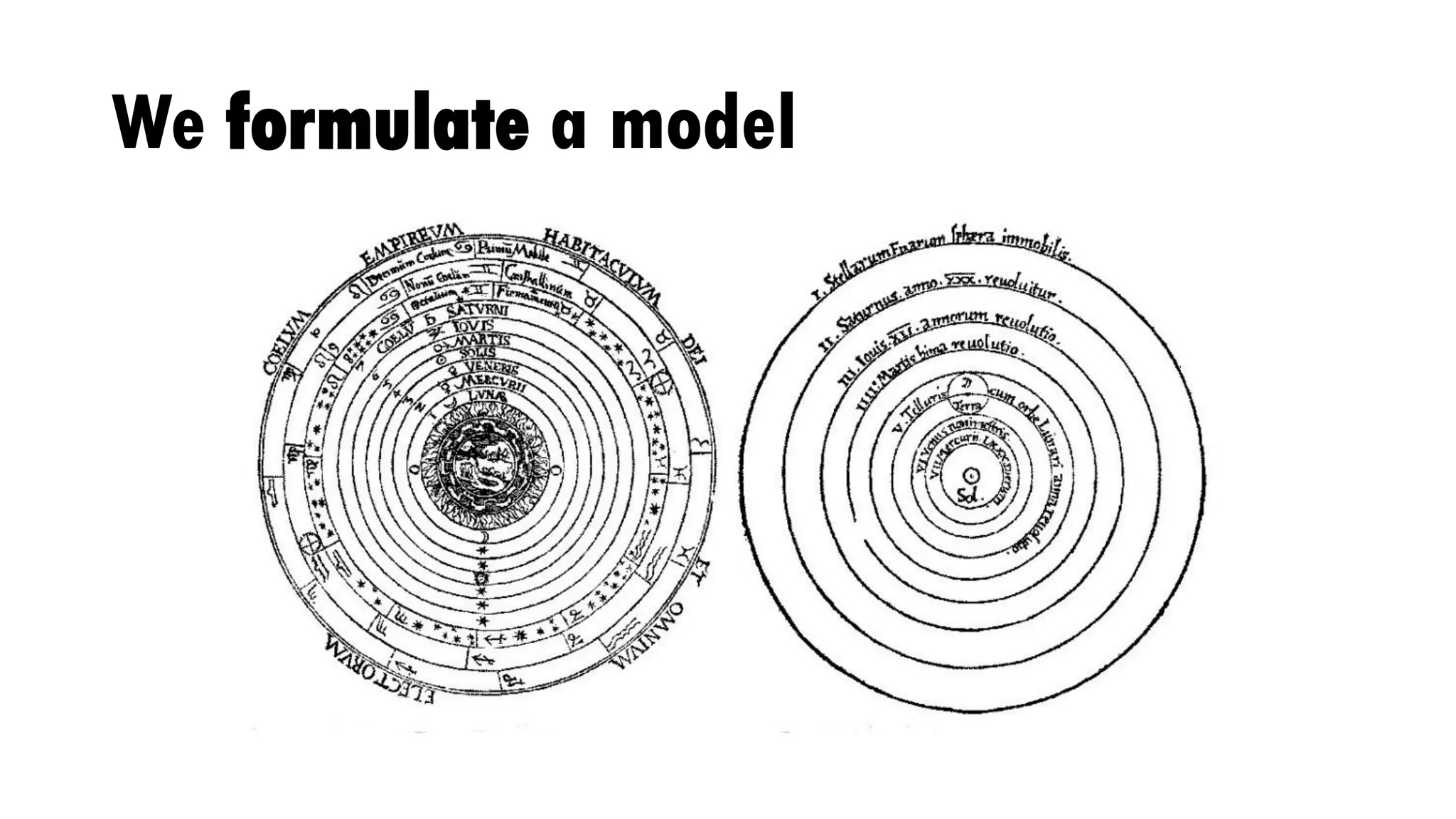
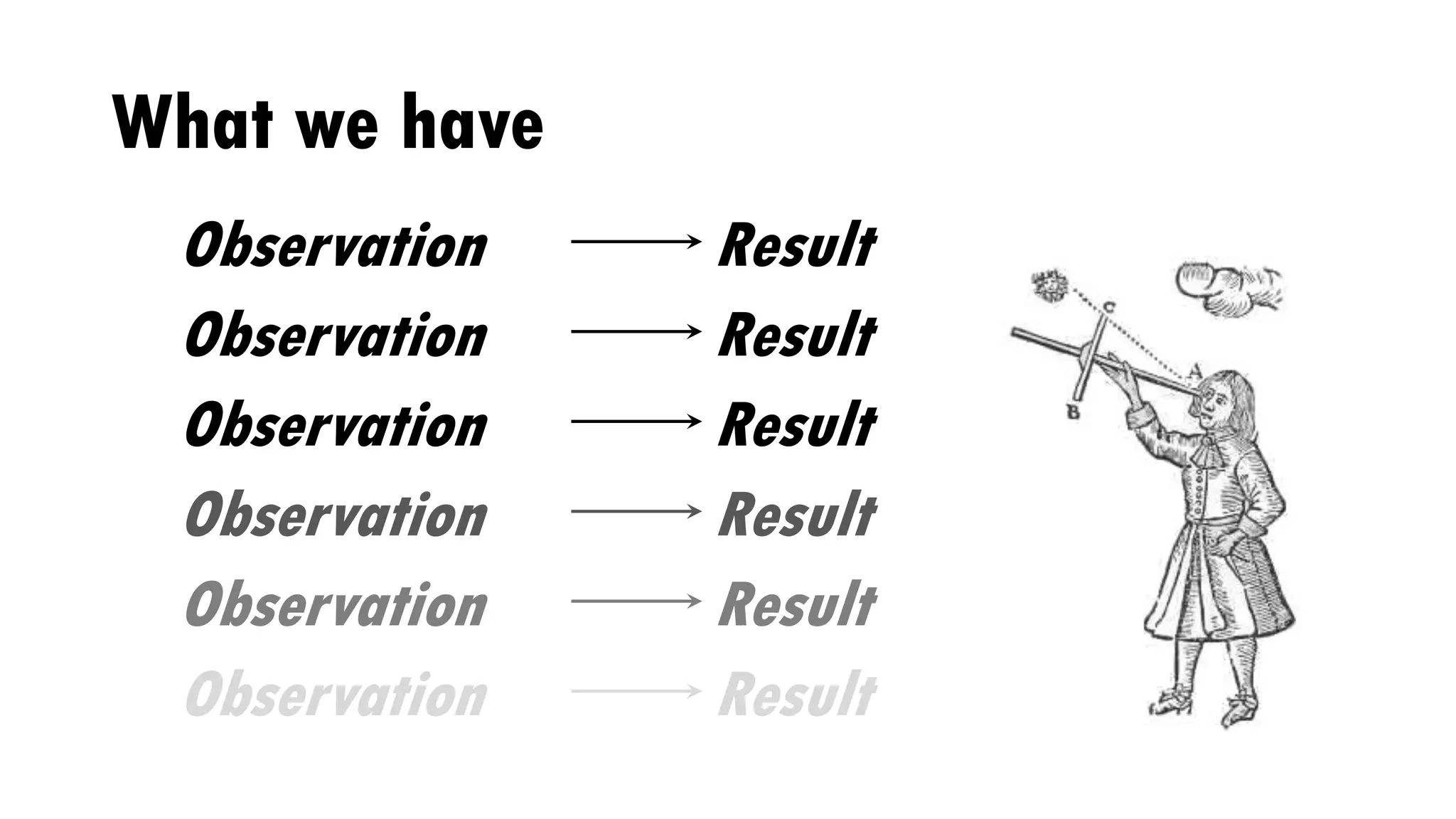
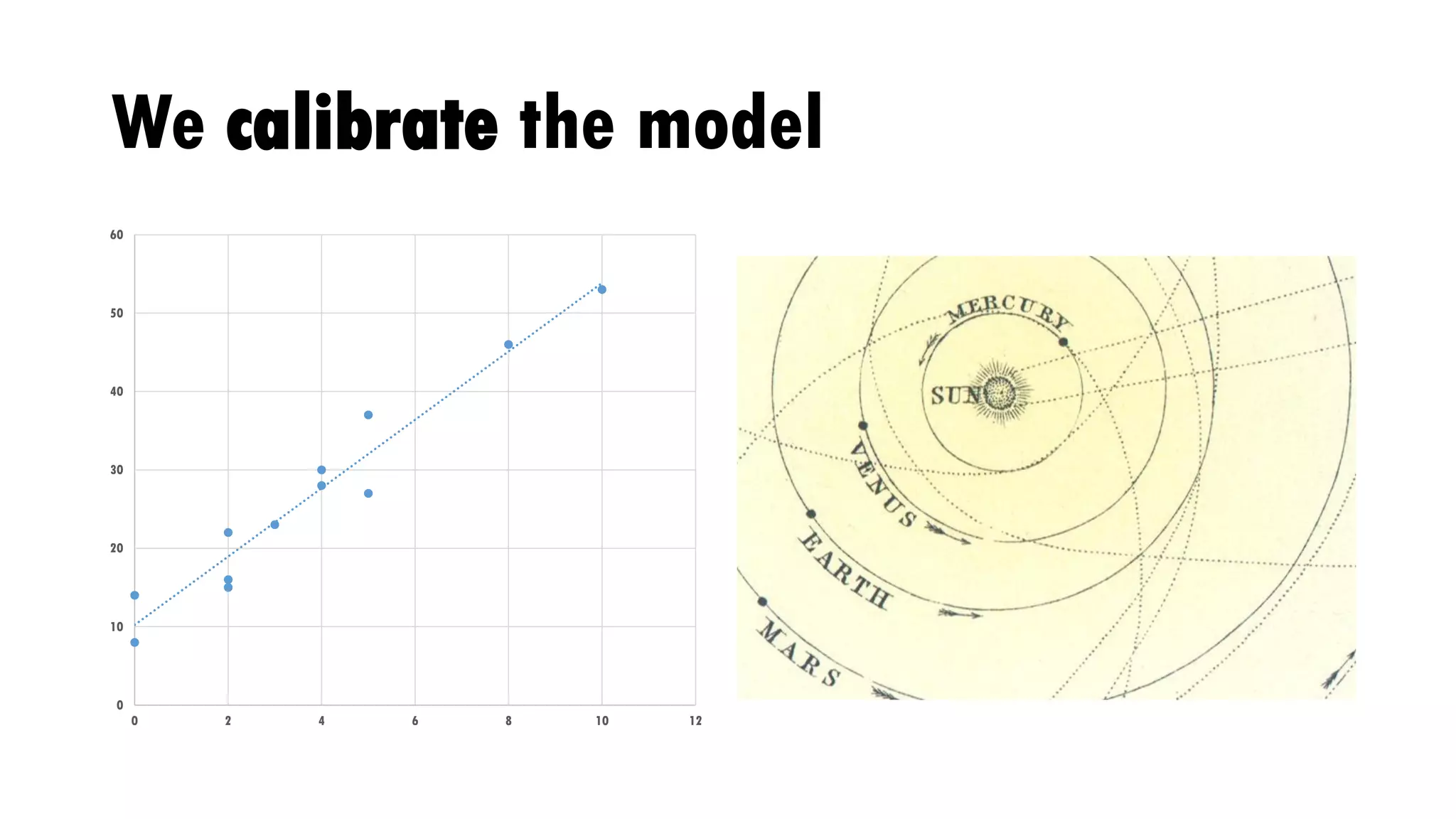
Download to read offline























![Modelling
• Transform Observation into Vector
• Ex: Search length, % matching words, …
• [17.0; 0.35; 3.5; …]
• Learn f, such that f(vector)~Relevance](https://image.slidesharecdn.com/agile-machine-learning-170612071447/85/Agile-experiments-in-Machine-Learning-with-F-30-320.jpg)









![Core model
type Observation = {
Search: string
Product: string }
type Relevance : float
type Predictor = Observation -> Relevance
type Feature = Observation -> float
type Example = Relevance * Observation
type Model = Feature []
type Learning = Model -> Example [] -> Predictor](https://image.slidesharecdn.com/agile-machine-learning-170612071447/85/Agile-experiments-in-Machine-Learning-with-F-41-320.jpg)

![Experiments
// shared/common data loading code
let model = [|
``search length``
``product title length``
``matching words``
|]
let predictor = RandomForest.regression model training
Let quality = evaluate predictor validation](https://image.slidesharecdn.com/agile-machine-learning-170612071447/85/Agile-experiments-in-Machine-Learning-with-F-43-320.jpg)


![Domain modelling?
// Object oriented style
type Observation = {
Search: string
Product: string }
with member this.SearchLength =
this.Search.Length
// Properties as functions
type Observation = {
Search: string
Product: string }
let searchLength (obs:Observation) =
obs.Search.Length
// "object" as a bag of functions
let model = [
fun obs -> searchLength obs
]](https://image.slidesharecdn.com/agile-machine-learning-170612071447/85/Agile-experiments-in-Machine-Learning-with-F-47-320.jpg)







































![Modelling
• Transform Observation into Vector
• Ex: Search length, % matching words, …
• [17.0; 0.35; 3.5; …]
• Learn f, such that f(vector)~Relevance](https://image.slidesharecdn.com/agile-machine-learning-170612071447/75/Agile-experiments-in-Machine-Learning-with-F-30-2048.jpg)









![Core model
type Observation = {
Search: string
Product: string }
type Relevance : float
type Predictor = Observation -> Relevance
type Feature = Observation -> float
type Example = Relevance * Observation
type Model = Feature []
type Learning = Model -> Example [] -> Predictor](https://image.slidesharecdn.com/agile-machine-learning-170612071447/75/Agile-experiments-in-Machine-Learning-with-F-41-2048.jpg)

![Experiments
// shared/common data loading code
let model = [|
``search length``
``product title length``
``matching words``
|]
let predictor = RandomForest.regression model training
Let quality = evaluate predictor validation](https://image.slidesharecdn.com/agile-machine-learning-170612071447/75/Agile-experiments-in-Machine-Learning-with-F-43-2048.jpg)


![Domain modelling?
// Object oriented style
type Observation = {
Search: string
Product: string }
with member this.SearchLength =
this.Search.Length
// Properties as functions
type Observation = {
Search: string
Product: string }
let searchLength (obs:Observation) =
obs.Search.Length
// "object" as a bag of functions
let model = [
fun obs -> searchLength obs
]](https://image.slidesharecdn.com/agile-machine-learning-170612071447/75/Agile-experiments-in-Machine-Learning-with-F-47-2048.jpg)








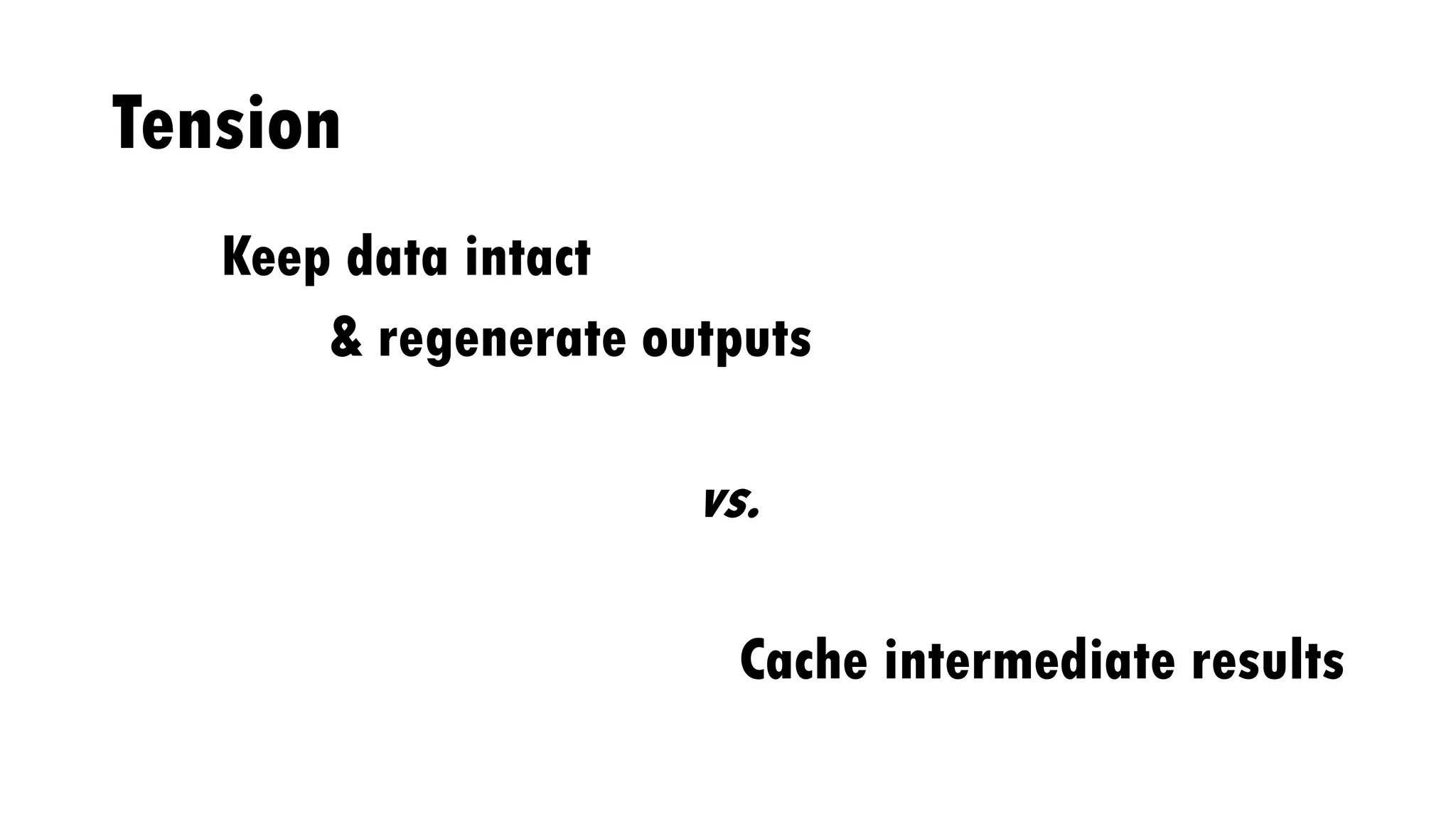


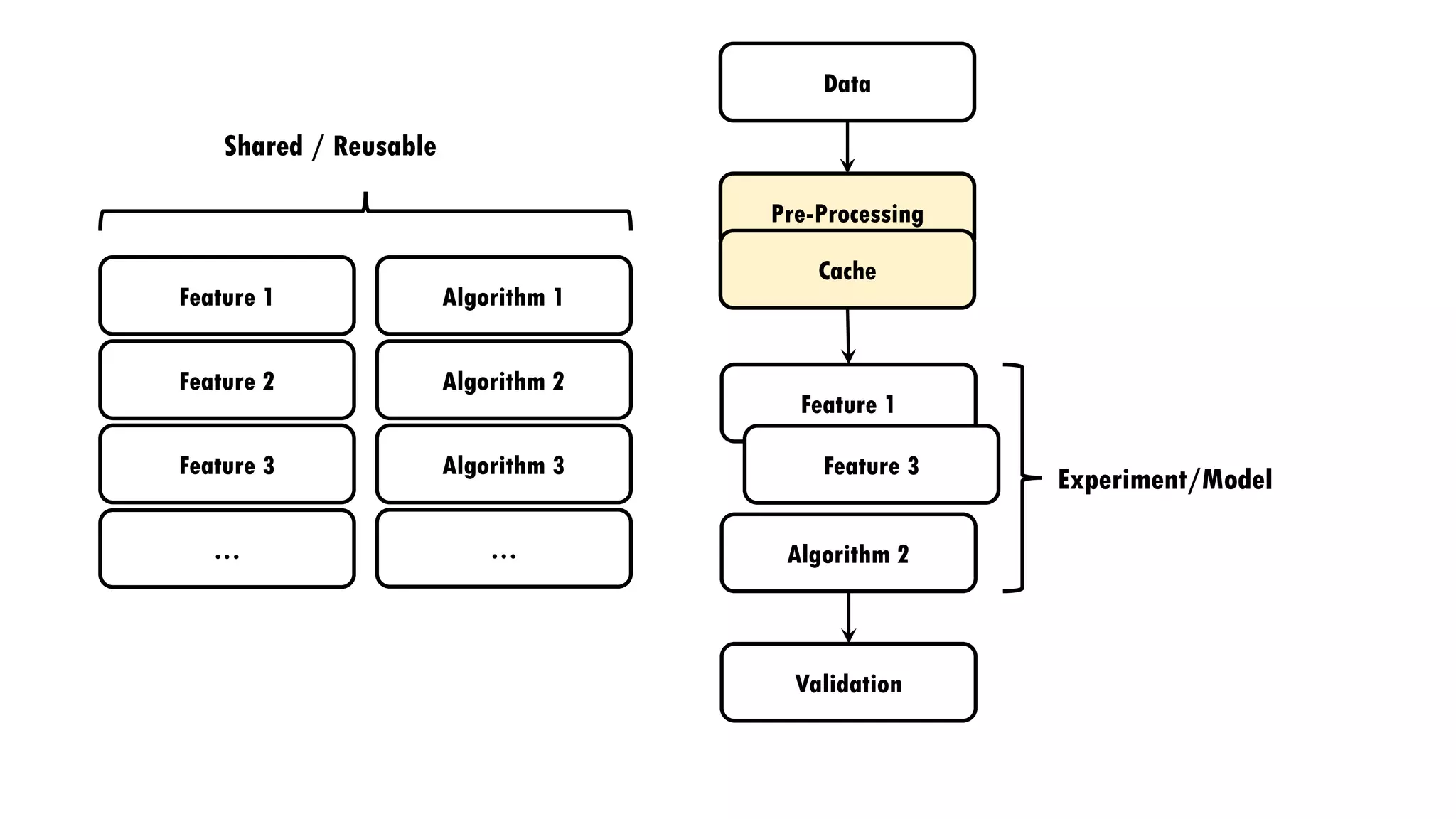







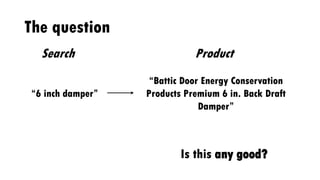
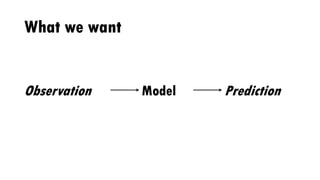
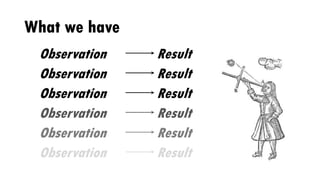
The document discusses the author's experiences and strategies in a machine learning competition, particularly focused on predicting the relevance of product recommendations based on search queries. It emphasizes the importance of iterative model development, feature extraction, and the challenges of data pre-processing while suggesting strategies for automating processes to improve efficiency. Additionally, it highlights the significance of types in defining clear domain models and encourages flexibility and experimentation in machine learning practices.
































![[DSC Europe 22] Engineers guide for shepherding models in to production - Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/markodimitrijevic-engineersguideforshepherdingmodelsintoproduction2-221130080720-6e979b6f-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






















































