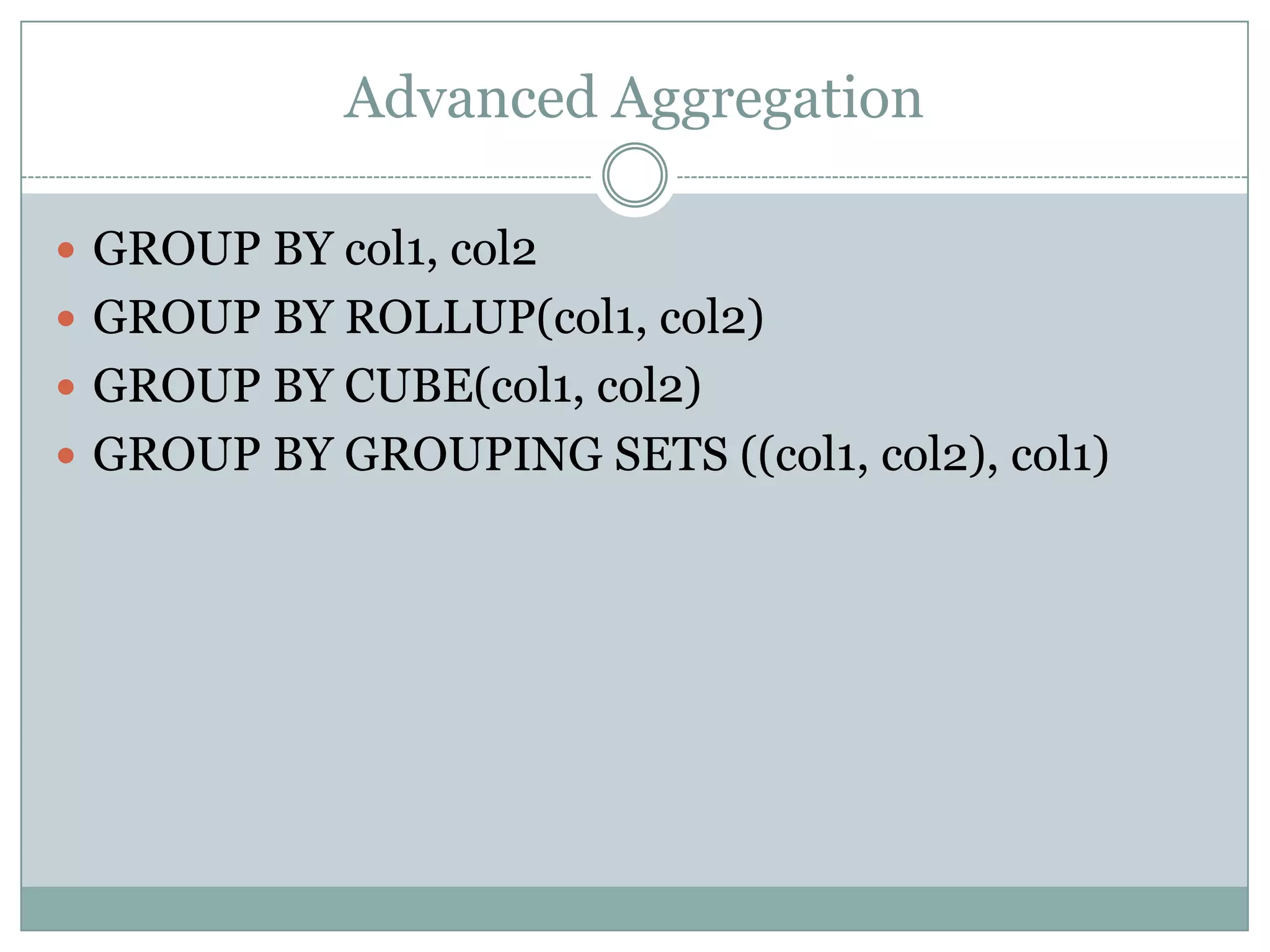
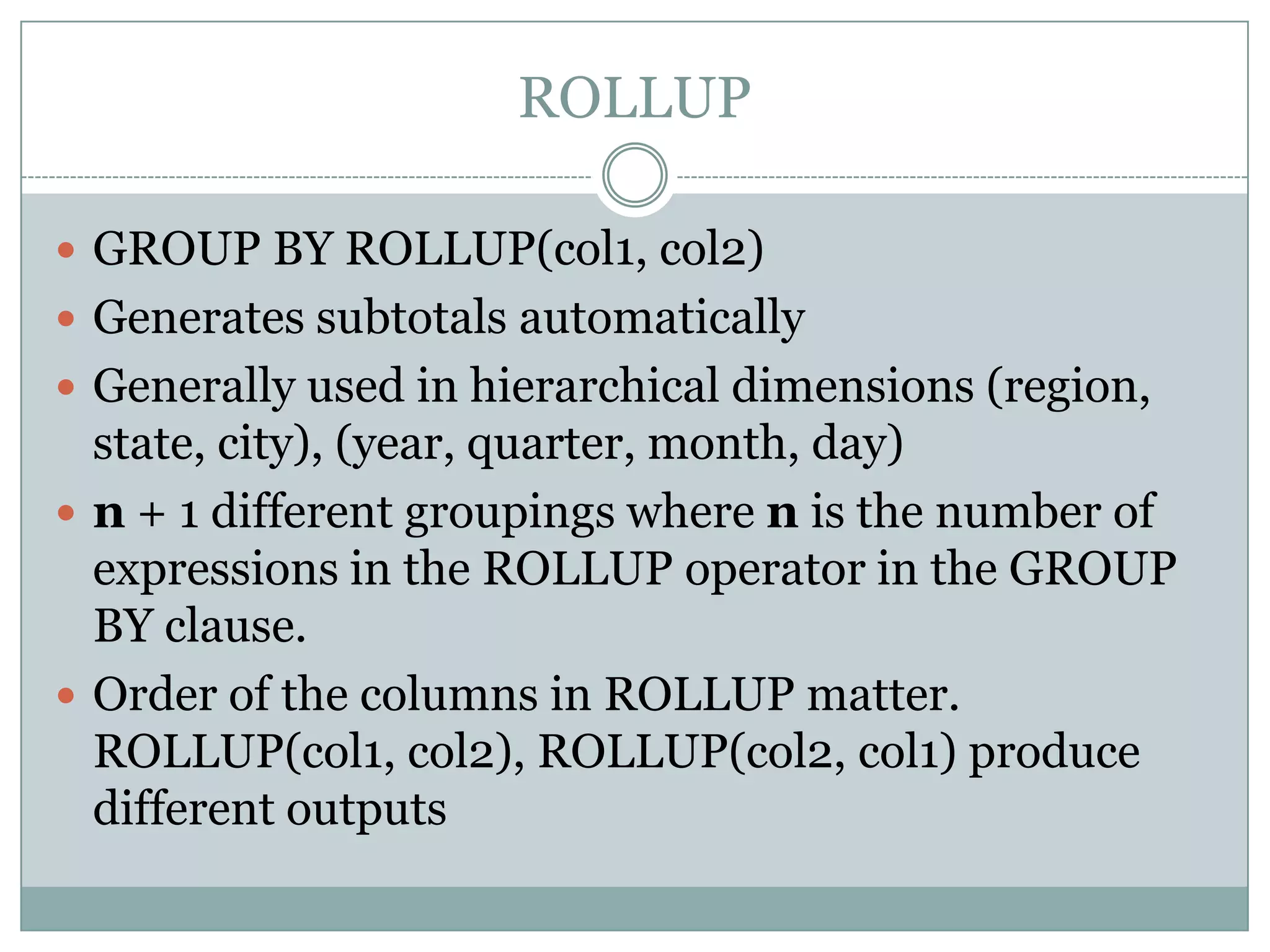
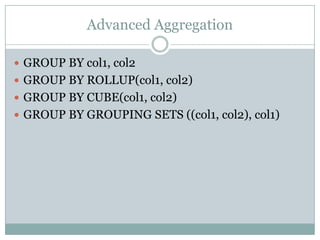
The document provides an overview of analytic and window functions in Oracle, detailing the differences between aggregate and analytic functions, as well as examples of various analytic functions like ranking, lag, and reporting. It discusses the use of advanced aggregation techniques like rollup and cube, as well as specific applications such as calculating cumulative totals and handling data densification. Additionally, it highlights when to use or avoid analytic functions and summarizes best practices for their efficient use.




![Anatomy of an analytic funcion
function (arg1, ..., argN) OVER ([partition_by_clause]
[order_by_clause [windowing_clause]])
The OVER keyword
partition_by_clause: Optional. Not related to table/index
partitions. Analogous to GROUP BY
order_by_clause: Mandatory for Ranking and Windowing
functions. Optional or meaningless for others
windowing_clause: Optional. Should always be preceded by
ORDER BY clause](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-6-320.jpg)

![Ranking Functions
ROW_NUMBER()
RANK() – Skips ranks after duplicate ranks
DENSE_RANK() – Doesn't skip rank after duplicate ranks
NTILE(n) – Sorts the rows into N equi-sized buckets
CUME_DIST() – % of rows with values lower or equal
PERCENT_RANK() - (rank of row -1)/(#rows – 1)
function OVER ([PARTITION BY <c1,c2..>] ORDER BY
<c3, ..>)
PARTITION BY clause: Optional
ORDER BY clause: Mandatory
rank_dense_rank.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-8-320.jpg)
![FIRST_VALUE/LAST_VALUE/NTH_VALUE
Returns the first/last/nth value from an ordered set
FIRST_VALUE(expr, [IGNORE NULLS]) OVER
([partitonby_clause] orderby_clause)
IGNORE NULLS options helps you "carry forward".
Often used in "Data Densification"
Operates on Default Window (unbounded preceding
and current row) when a window is not explicitly
specified.
NTH_VALUE introduced in 11gR2
flnth_value.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-9-320.jpg)
![Window functions
Used for computing cumulative/running totals (YTD, MTD,
QTD), moving/centered averages
function(args) OVER([partition_by_clause] order_by_clause
[windowing_clause])
ORDER BY clause: mandatory.
Windowing Clause: Optional. Defaults to: UNBOUNDED
PRECEDING and CURRENT ROW
anchored or sliding windows
Two ways to specify windows: ROWS, RANGE
[ROW | RANGE ] BETWEEN <start_exp> AND <end_exp>
window.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-10-320.jpg)
![ROWS type windows
Physical offset. Number of rows before or after current
row
Non deterministic results if rows are not sorted uniquely
Any number of columns in the ORDER BY clause
ORDER BY columns can be of any type
function(args) OVER ([partition_by_clause] order by c1,
.., cN ROWS between <start_exp> and <end_exp>)
windows_rows.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-11-320.jpg)
![RANGE type Windows
Logical offset
non-unique rows treated as one logical row
Only one column allowed in ORDER BY clause
ORDER BY column should be numeric or date
function(args) OVER ([partition_by_clause] order
by c1 RANGE between <start_exp> and <end_exp>)
windows_range.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-12-320.jpg)
![Reporting function
Computes the ratio of a value to the sum of a set of
values
RATIO_TO_REPORT(arg) OVER ([PARTITION BY
<c1, .., cN>]
PARTITION BY clause: Optional.
ratio_to_report.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-13-320.jpg)
![LAG/LEAD
Gives the ability to access other rows without self-join.
Allows you to treat cursor as an array
Useful for making inter-row calculations (year-over-year
comparison, time between events)
LEAD (expr, <offset>, <default value>) [IGNORE
NULLS] OVER ([partioning_clause] orderby_clause)
Physical offset. Can be fixed or varying. default offset is 1
default value: value returned if offset points to a non-
existent row
IGNORE NULLS determines whether null values of are
included or eliminated from the calculation.
lead_lag.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-14-320.jpg)
![FIRST/LAST
Very different from FIRST_VALUE/LAST_VALUE
Returns the results of aggregate/analytic function applied
on column B on the first or last ranked rows sorted by
column A
function (expr_with_colB) KEEP (DENSE_RANK
FIRST/LAST ORDER BY colA) [OVER
(<partitioning_clause)>)]
Slightly different syntax. Note the word KEEP
analytic clause is optional.
first_last.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/85/Analytic-Windowing-functions-in-oracle-15-320.jpg)


























![Anatomy of an analytic funcion
function (arg1, ..., argN) OVER ([partition_by_clause]
[order_by_clause [windowing_clause]])
The OVER keyword
partition_by_clause: Optional. Not related to table/index
partitions. Analogous to GROUP BY
order_by_clause: Mandatory for Ranking and Windowing
functions. Optional or meaningless for others
windowing_clause: Optional. Should always be preceded by
ORDER BY clause](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-6-2048.jpg)

![Ranking Functions
ROW_NUMBER()
RANK() – Skips ranks after duplicate ranks
DENSE_RANK() – Doesn't skip rank after duplicate ranks
NTILE(n) – Sorts the rows into N equi-sized buckets
CUME_DIST() – % of rows with values lower or equal
PERCENT_RANK() - (rank of row -1)/(#rows – 1)
function OVER ([PARTITION BY <c1,c2..>] ORDER BY
<c3, ..>)
PARTITION BY clause: Optional
ORDER BY clause: Mandatory
rank_dense_rank.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-8-2048.jpg)
![FIRST_VALUE/LAST_VALUE/NTH_VALUE
Returns the first/last/nth value from an ordered set
FIRST_VALUE(expr, [IGNORE NULLS]) OVER
([partitonby_clause] orderby_clause)
IGNORE NULLS options helps you "carry forward".
Often used in "Data Densification"
Operates on Default Window (unbounded preceding
and current row) when a window is not explicitly
specified.
NTH_VALUE introduced in 11gR2
flnth_value.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-9-2048.jpg)
![Window functions
Used for computing cumulative/running totals (YTD, MTD,
QTD), moving/centered averages
function(args) OVER([partition_by_clause] order_by_clause
[windowing_clause])
ORDER BY clause: mandatory.
Windowing Clause: Optional. Defaults to: UNBOUNDED
PRECEDING and CURRENT ROW
anchored or sliding windows
Two ways to specify windows: ROWS, RANGE
[ROW | RANGE ] BETWEEN <start_exp> AND <end_exp>
window.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-10-2048.jpg)
![ROWS type windows
Physical offset. Number of rows before or after current
row
Non deterministic results if rows are not sorted uniquely
Any number of columns in the ORDER BY clause
ORDER BY columns can be of any type
function(args) OVER ([partition_by_clause] order by c1,
.., cN ROWS between <start_exp> and <end_exp>)
windows_rows.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-11-2048.jpg)
![RANGE type Windows
Logical offset
non-unique rows treated as one logical row
Only one column allowed in ORDER BY clause
ORDER BY column should be numeric or date
function(args) OVER ([partition_by_clause] order
by c1 RANGE between <start_exp> and <end_exp>)
windows_range.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-12-2048.jpg)
![Reporting function
Computes the ratio of a value to the sum of a set of
values
RATIO_TO_REPORT(arg) OVER ([PARTITION BY
<c1, .., cN>]
PARTITION BY clause: Optional.
ratio_to_report.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-13-2048.jpg)
![LAG/LEAD
Gives the ability to access other rows without self-join.
Allows you to treat cursor as an array
Useful for making inter-row calculations (year-over-year
comparison, time between events)
LEAD (expr, <offset>, <default value>) [IGNORE
NULLS] OVER ([partioning_clause] orderby_clause)
Physical offset. Can be fixed or varying. default offset is 1
default value: value returned if offset points to a non-
existent row
IGNORE NULLS determines whether null values of are
included or eliminated from the calculation.
lead_lag.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-14-2048.jpg)
![FIRST/LAST
Very different from FIRST_VALUE/LAST_VALUE
Returns the results of aggregate/analytic function applied
on column B on the first or last ranked rows sorted by
column A
function (expr_with_colB) KEEP (DENSE_RANK
FIRST/LAST ORDER BY colA) [OVER
(<partitioning_clause)>)]
Slightly different syntax. Note the word KEEP
analytic clause is optional.
first_last.sql](https://image.slidesharecdn.com/analyticfunctionsinoracle-120508160143-phpapp02/75/Analytic-Windowing-functions-in-oracle-15-2048.jpg)