Download as PDF, PPTX








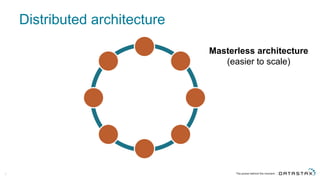

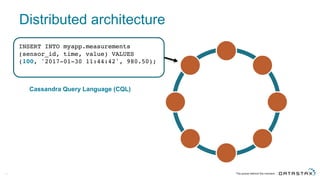
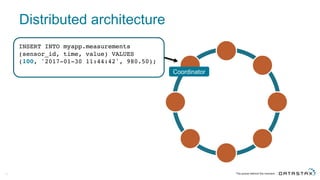
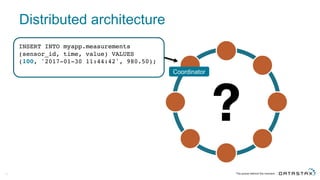
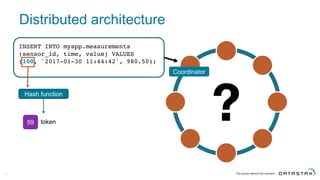
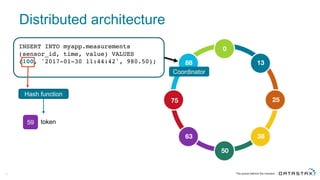
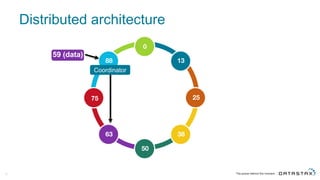

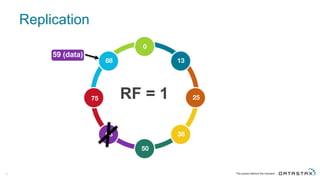
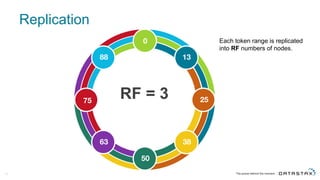
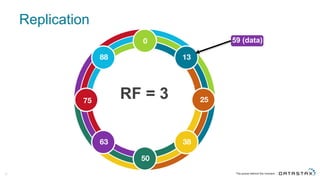
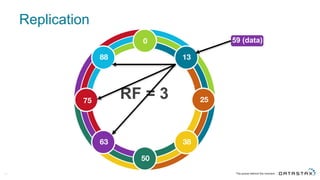
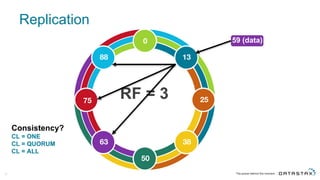


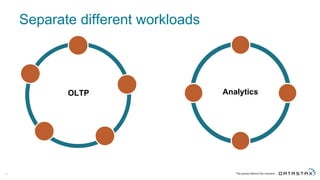
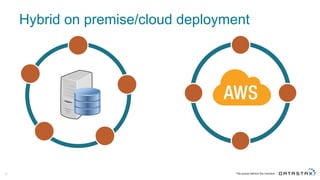
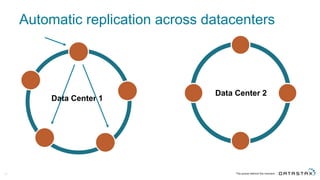
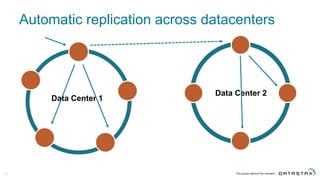





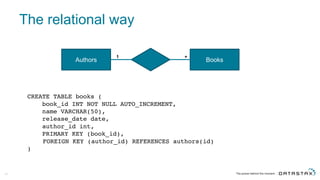





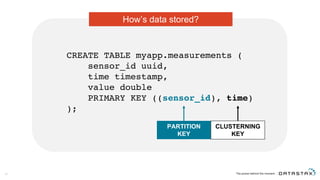
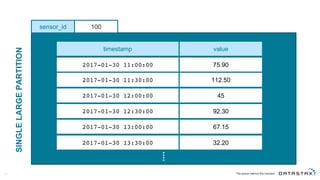

































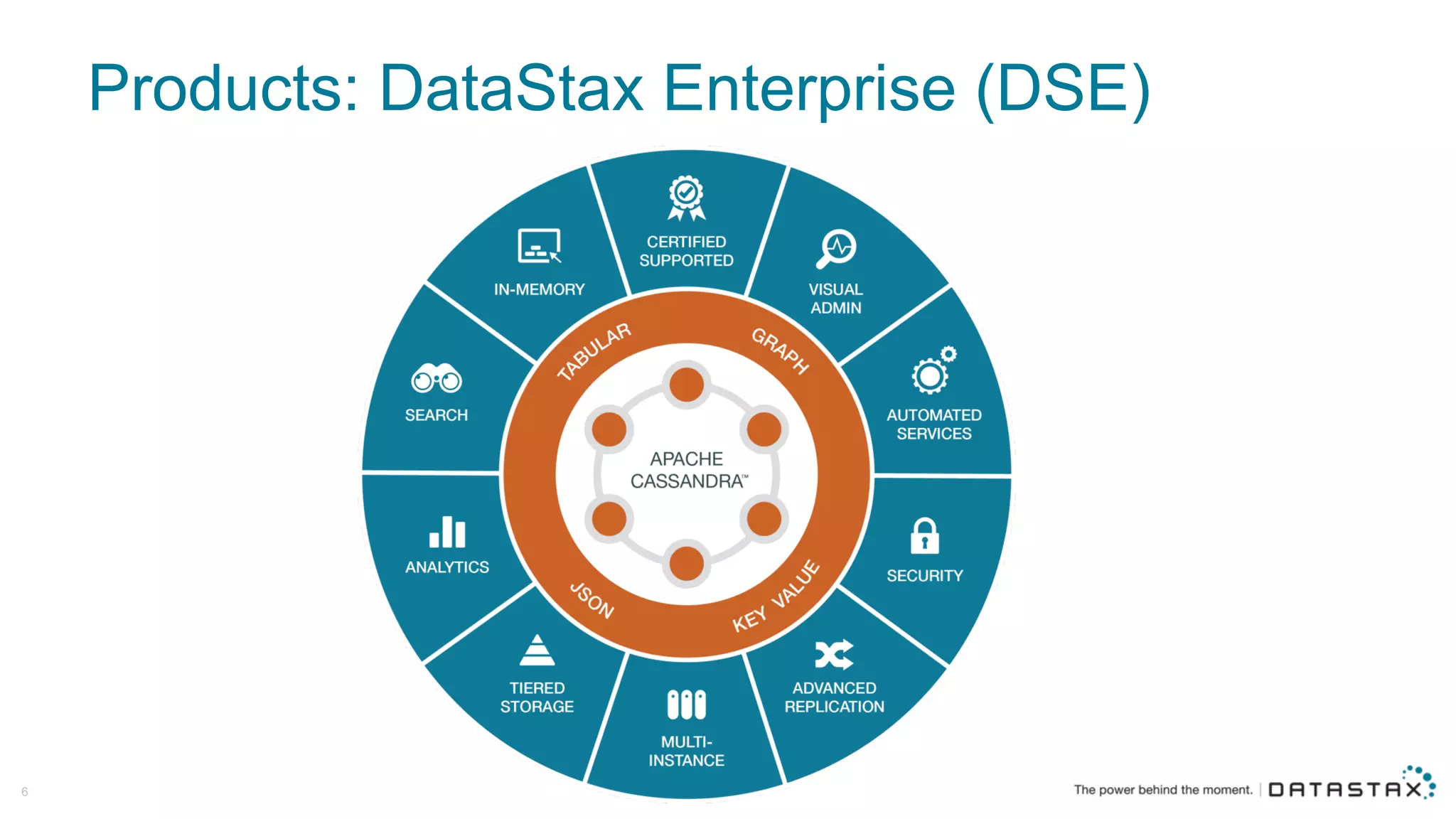


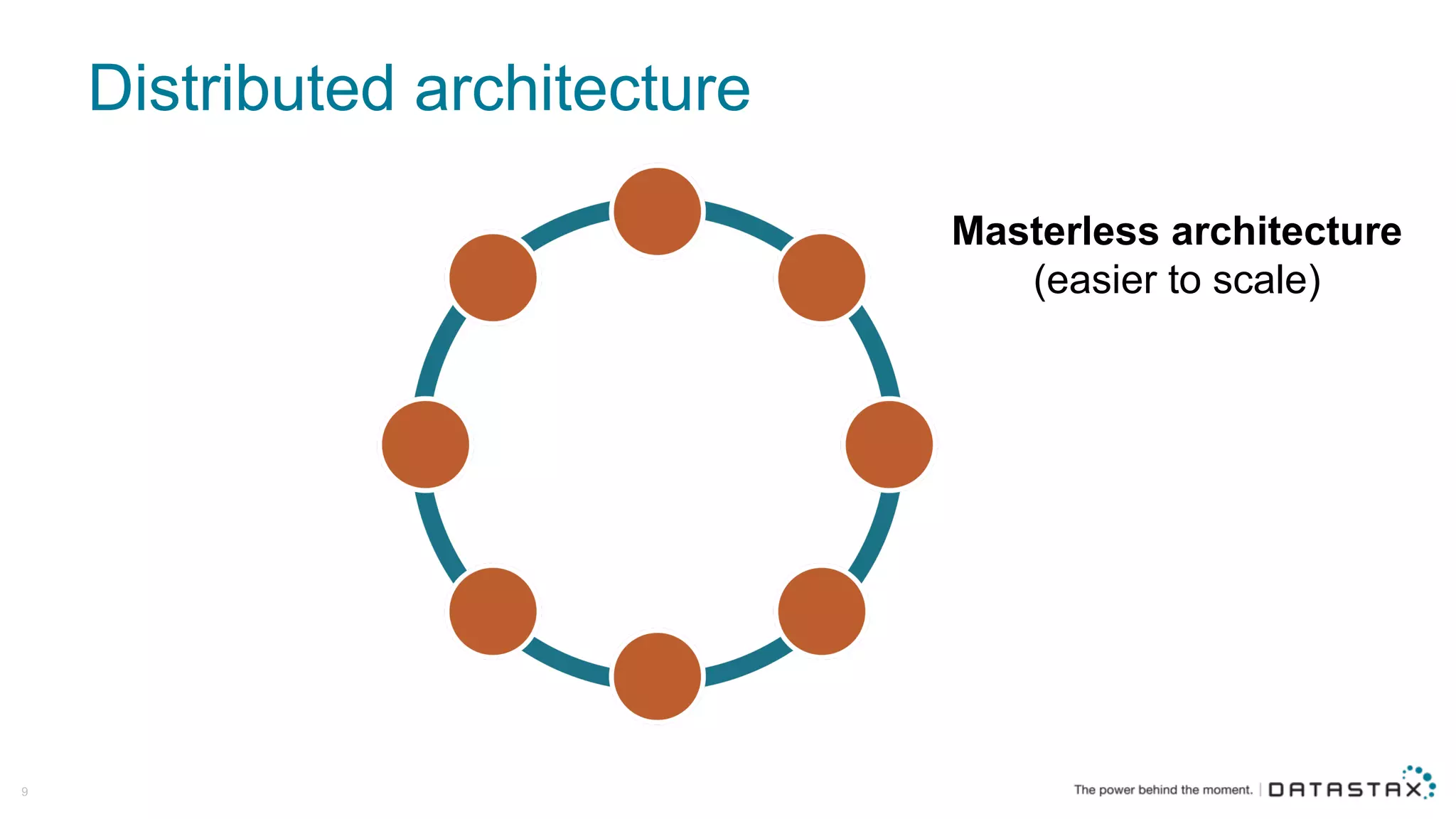

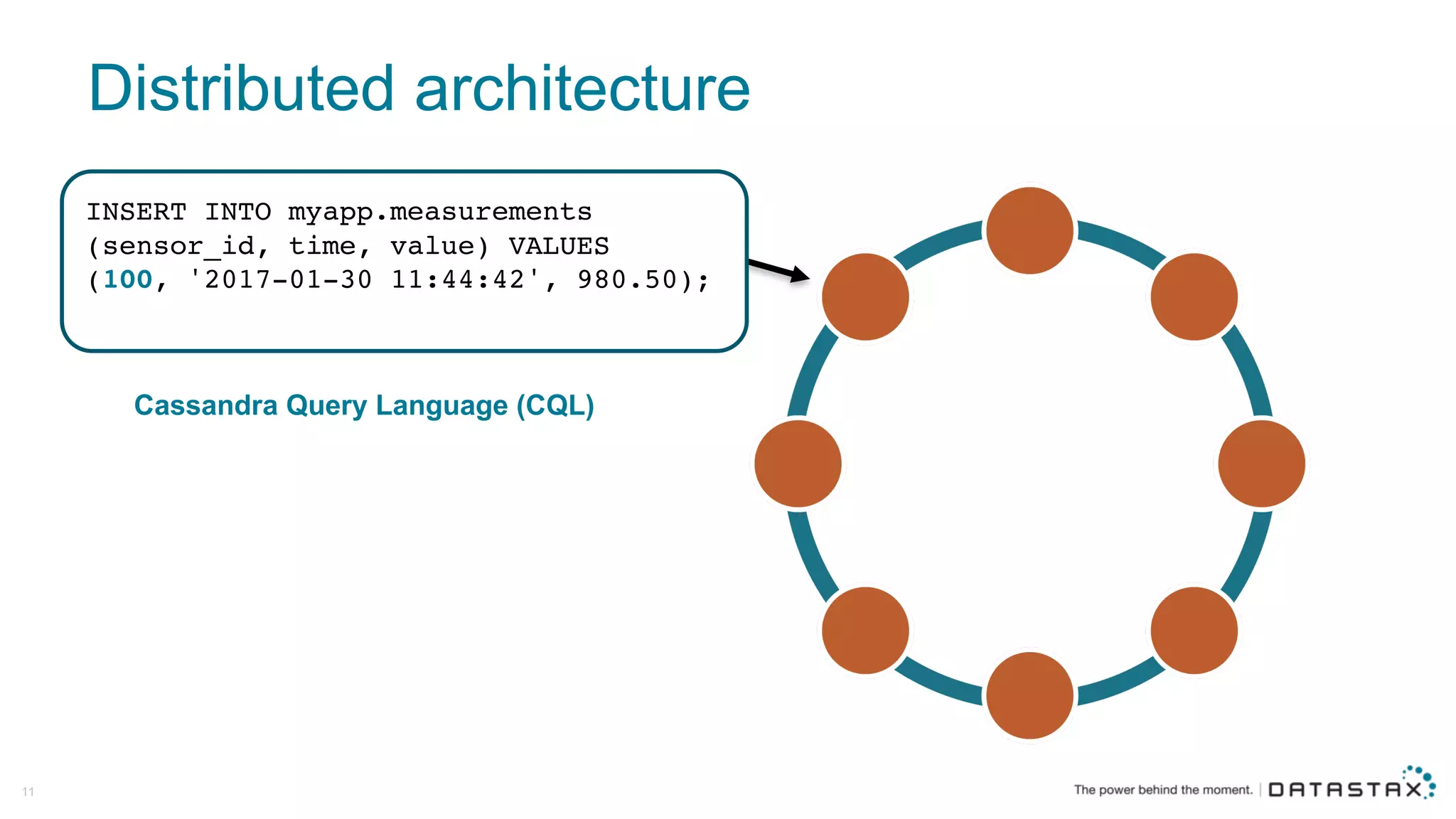
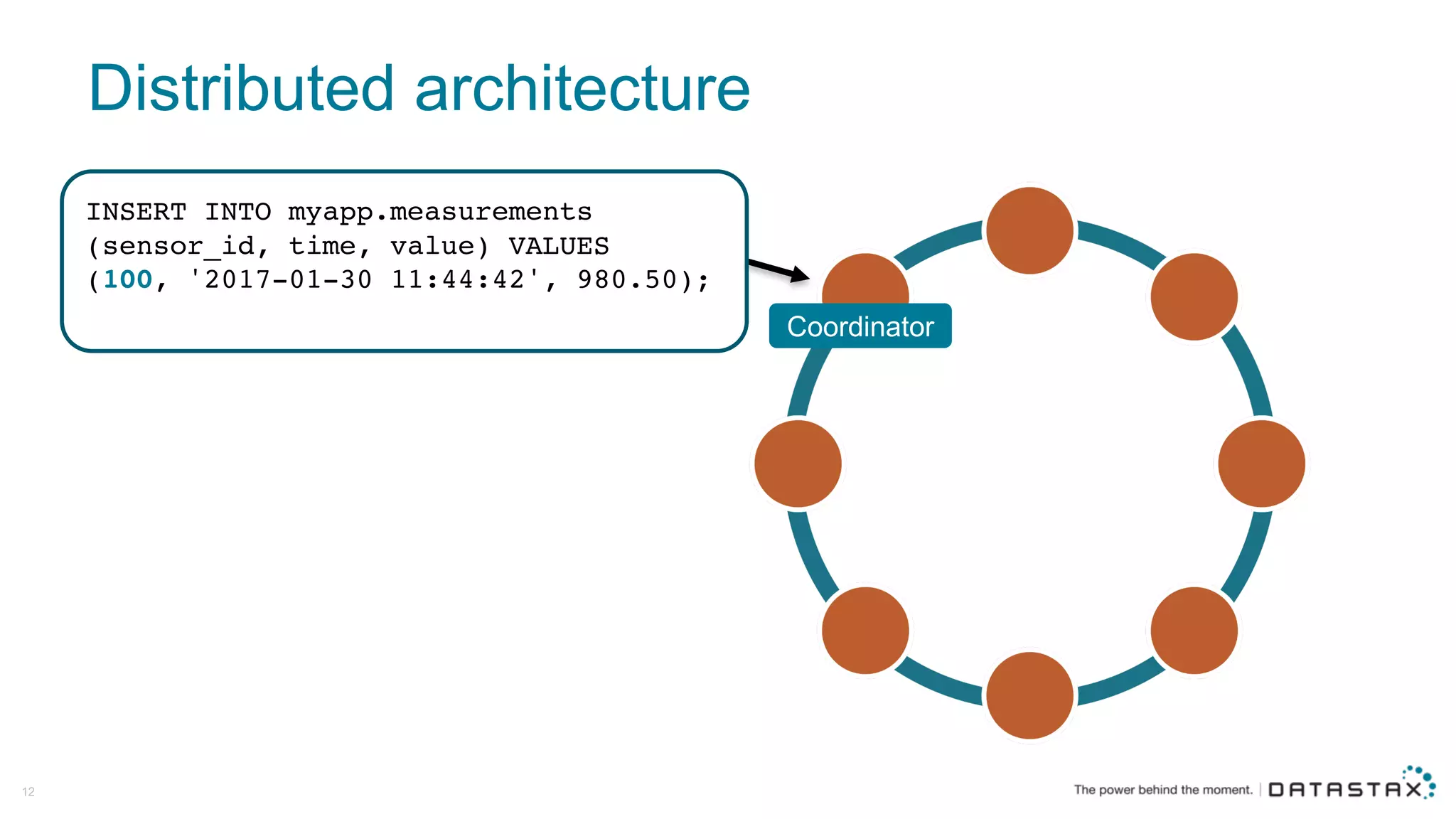
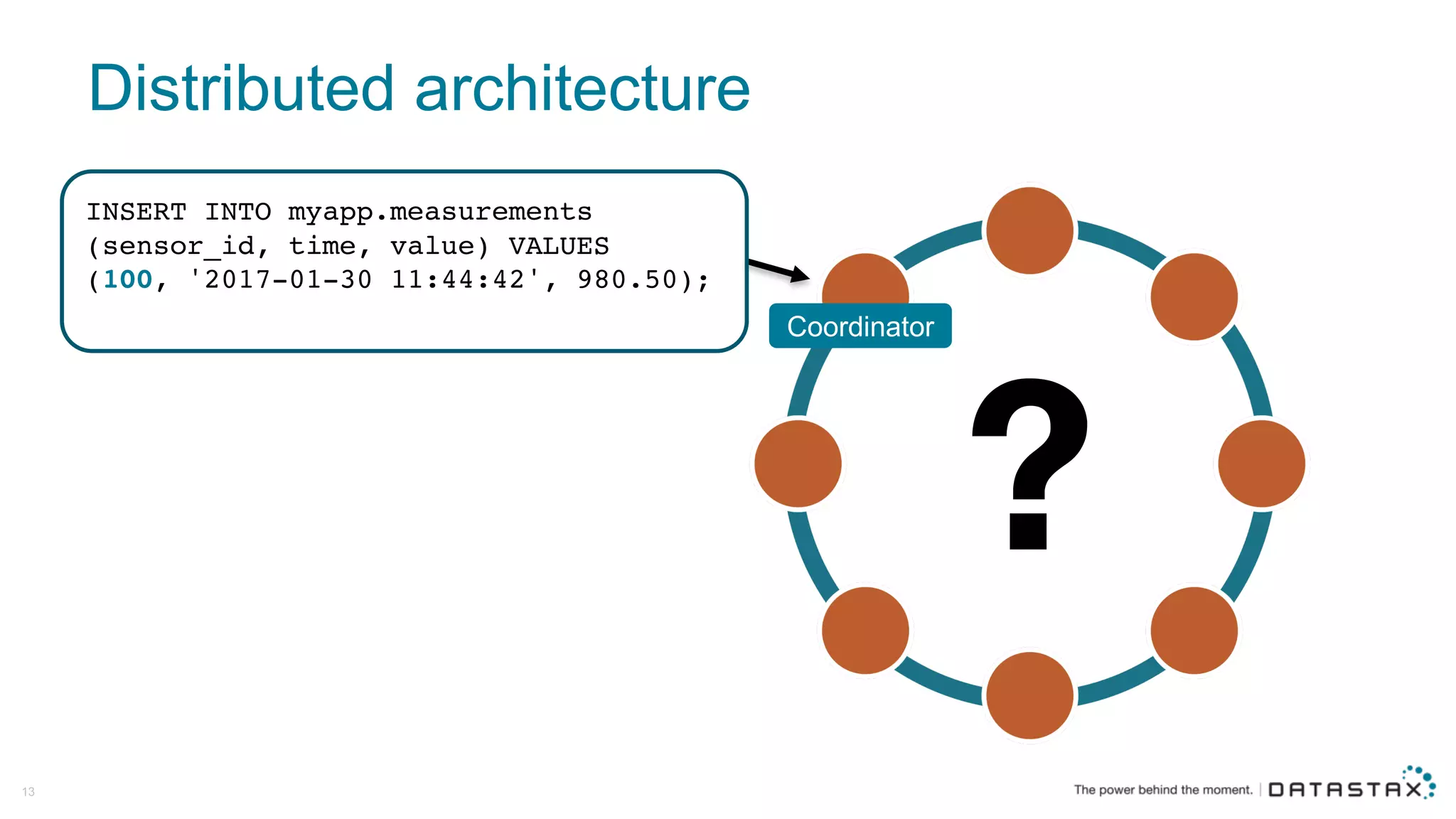
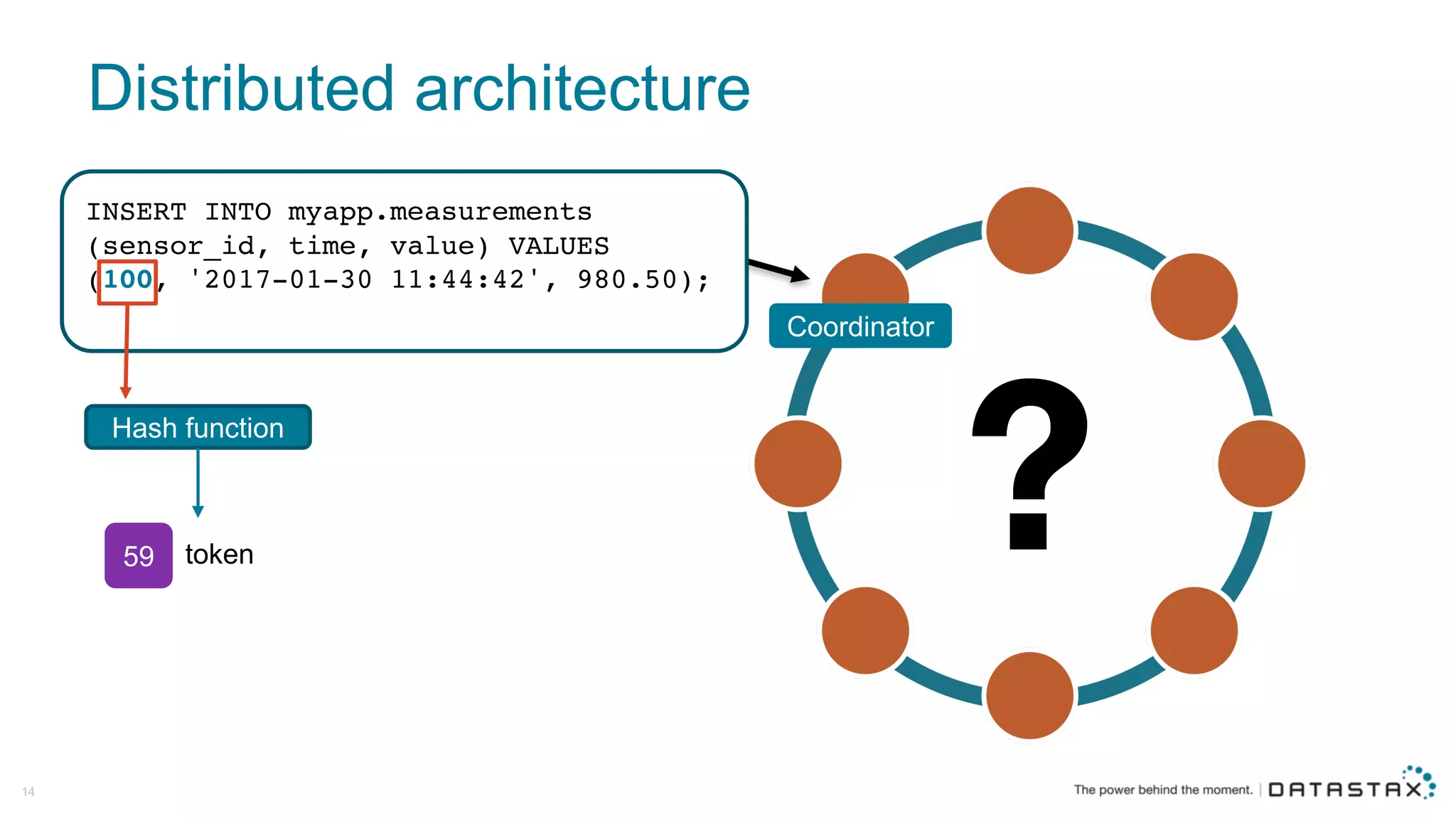
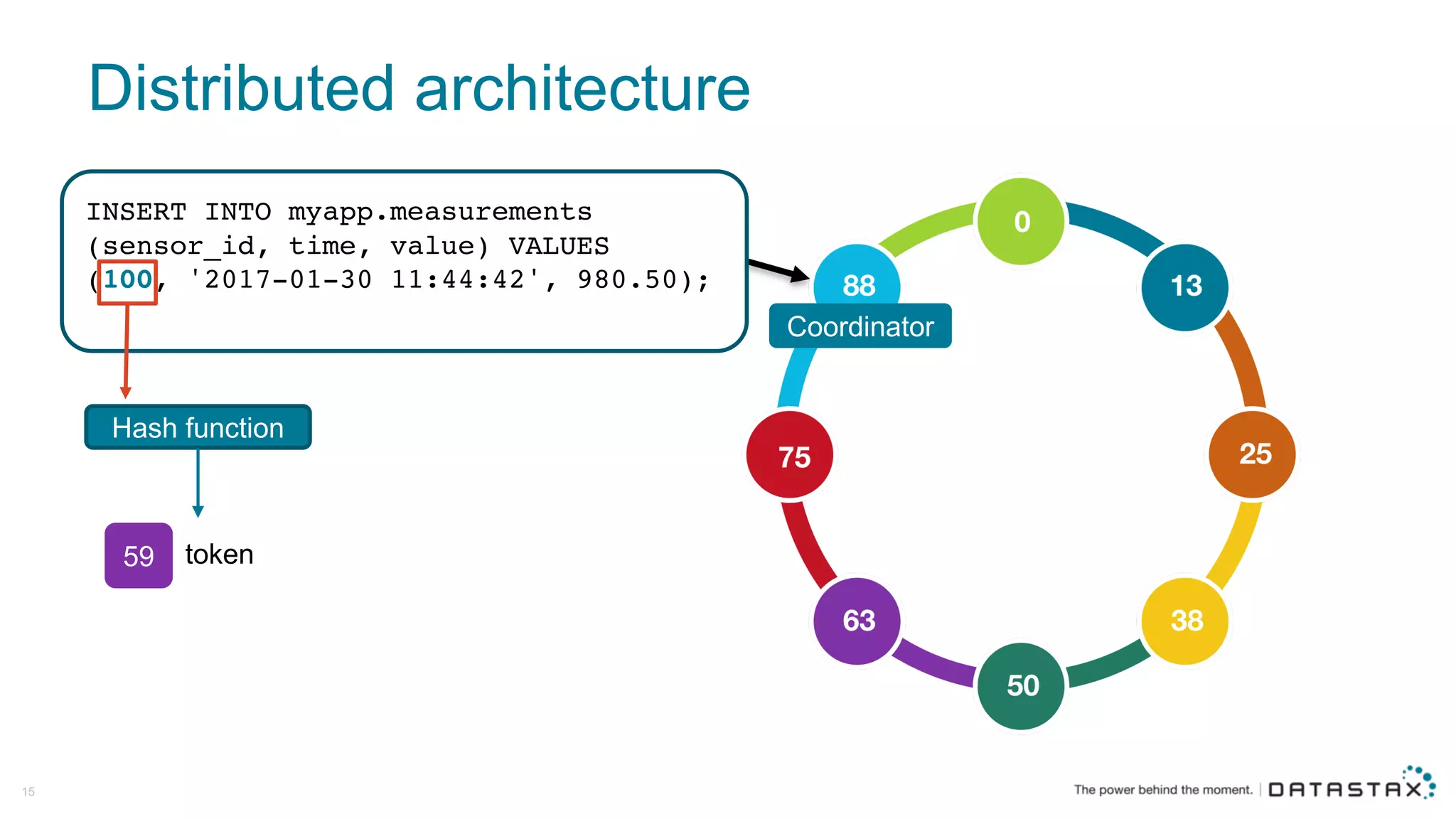
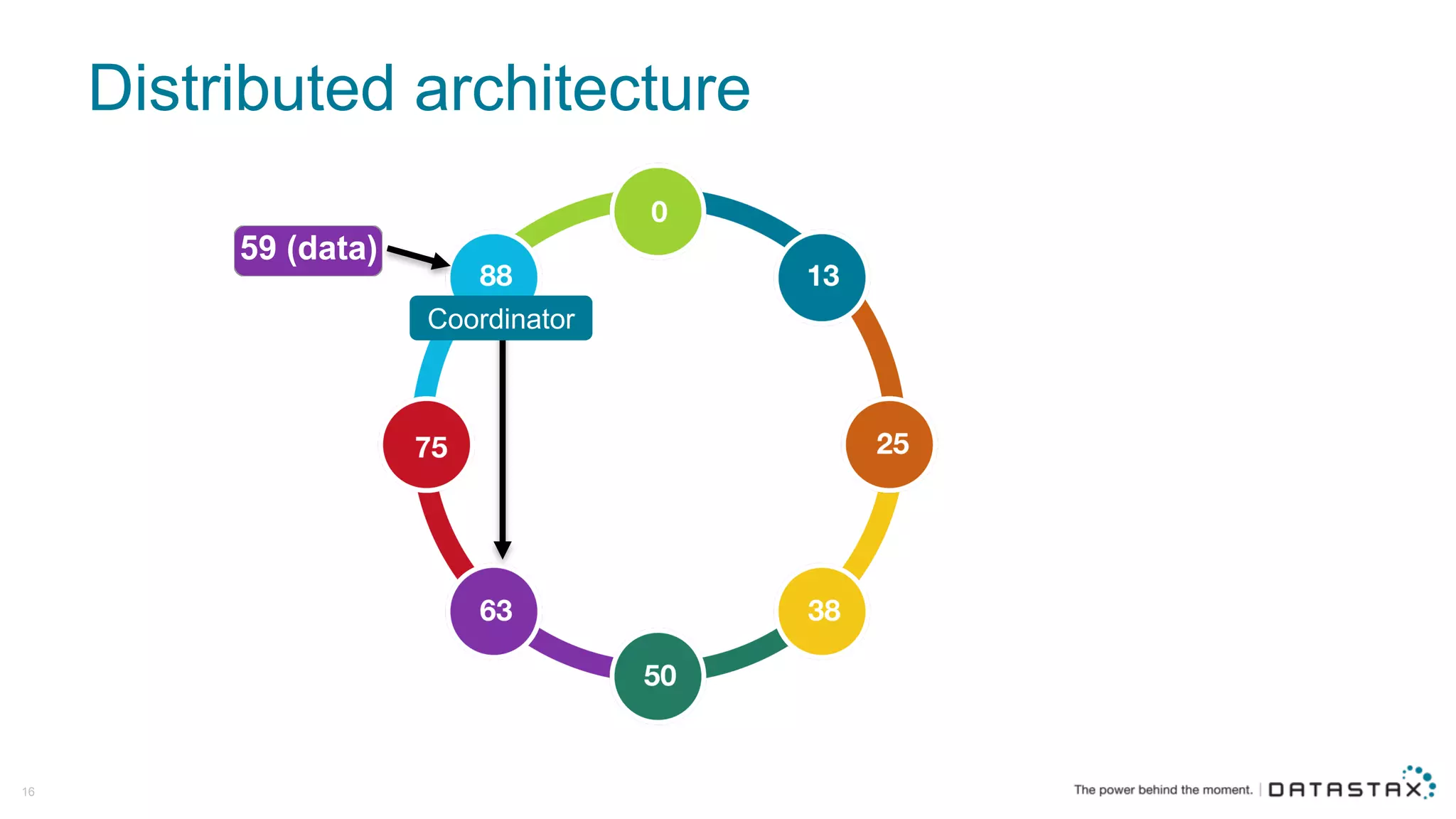

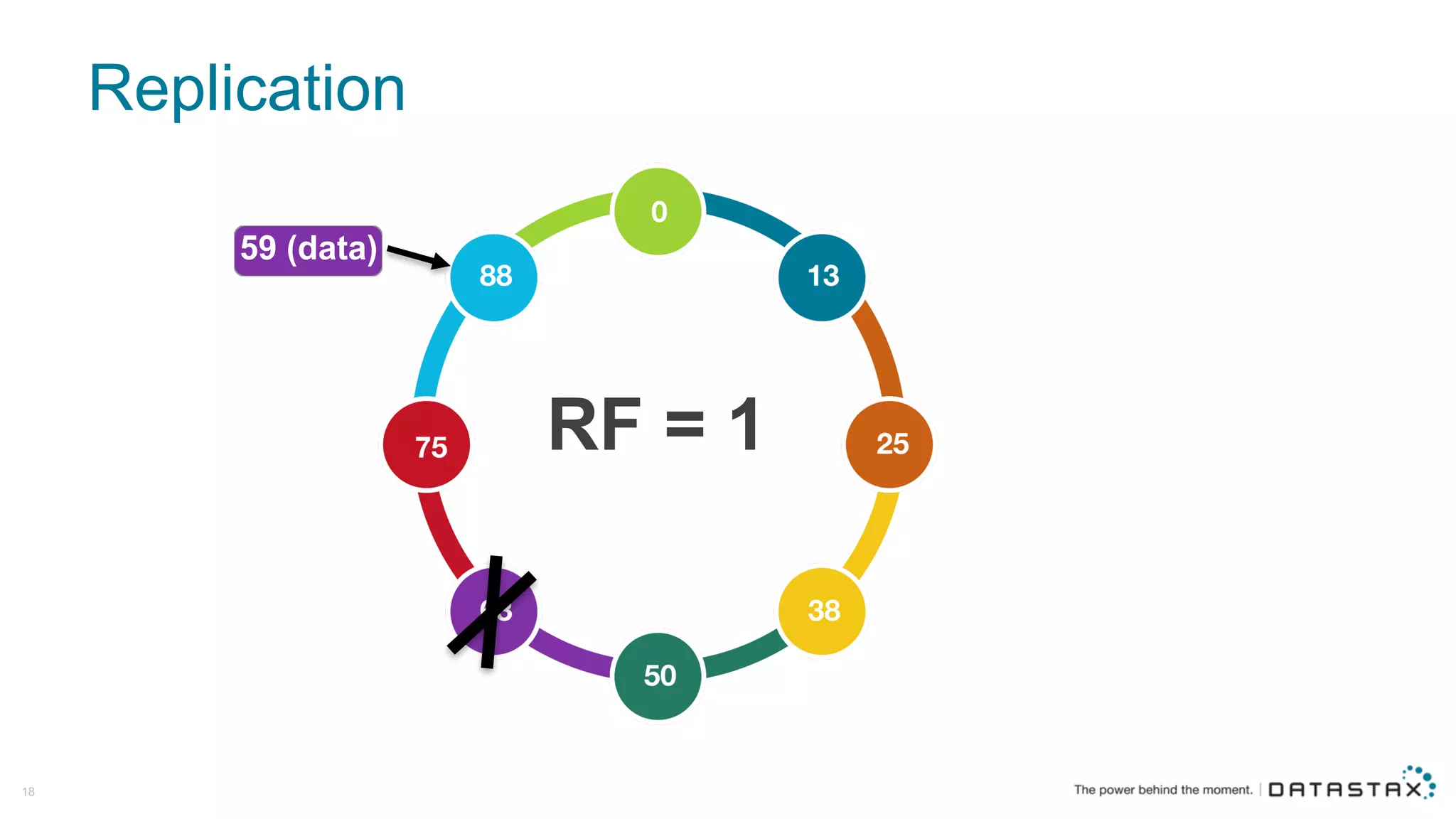
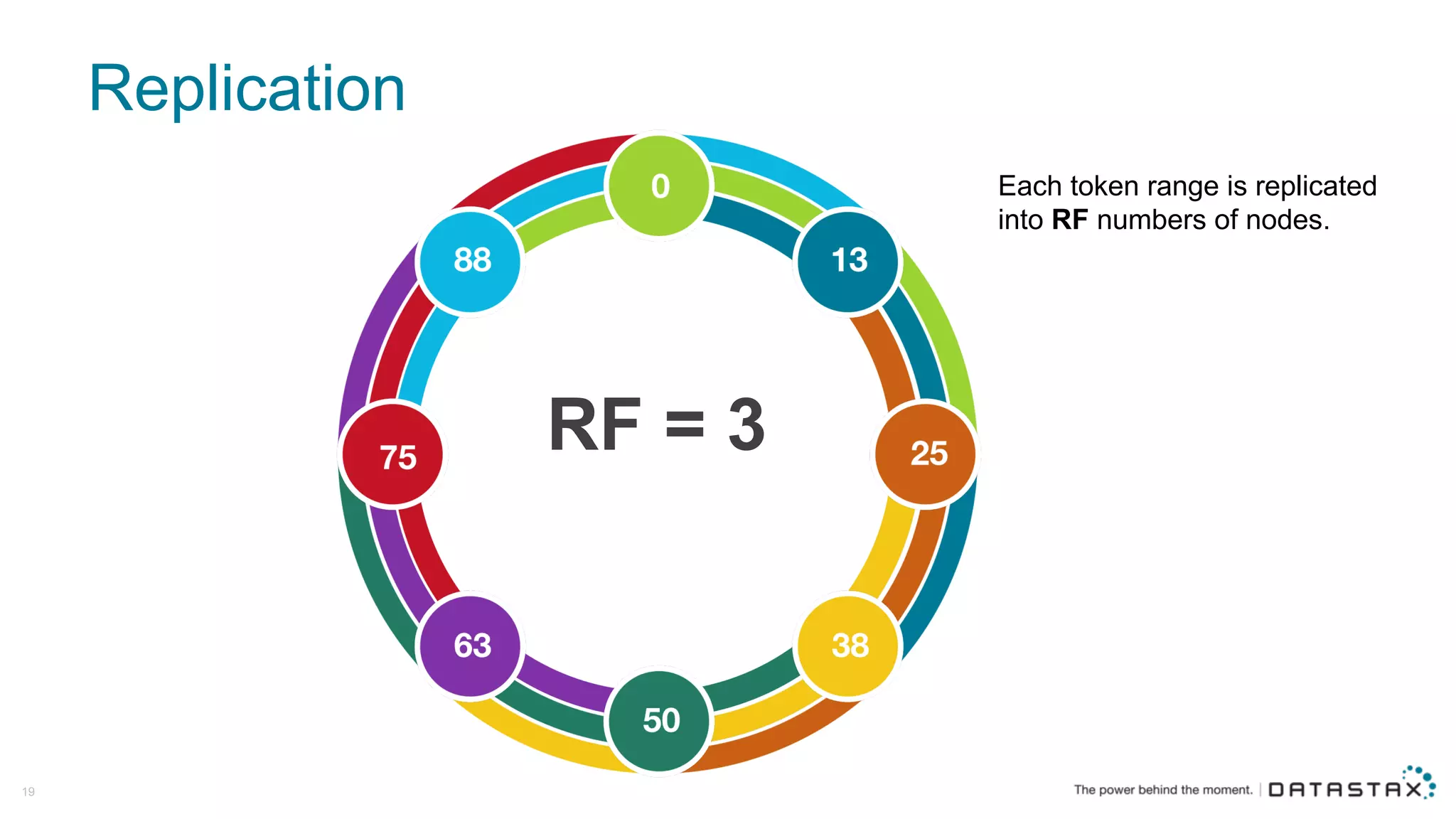

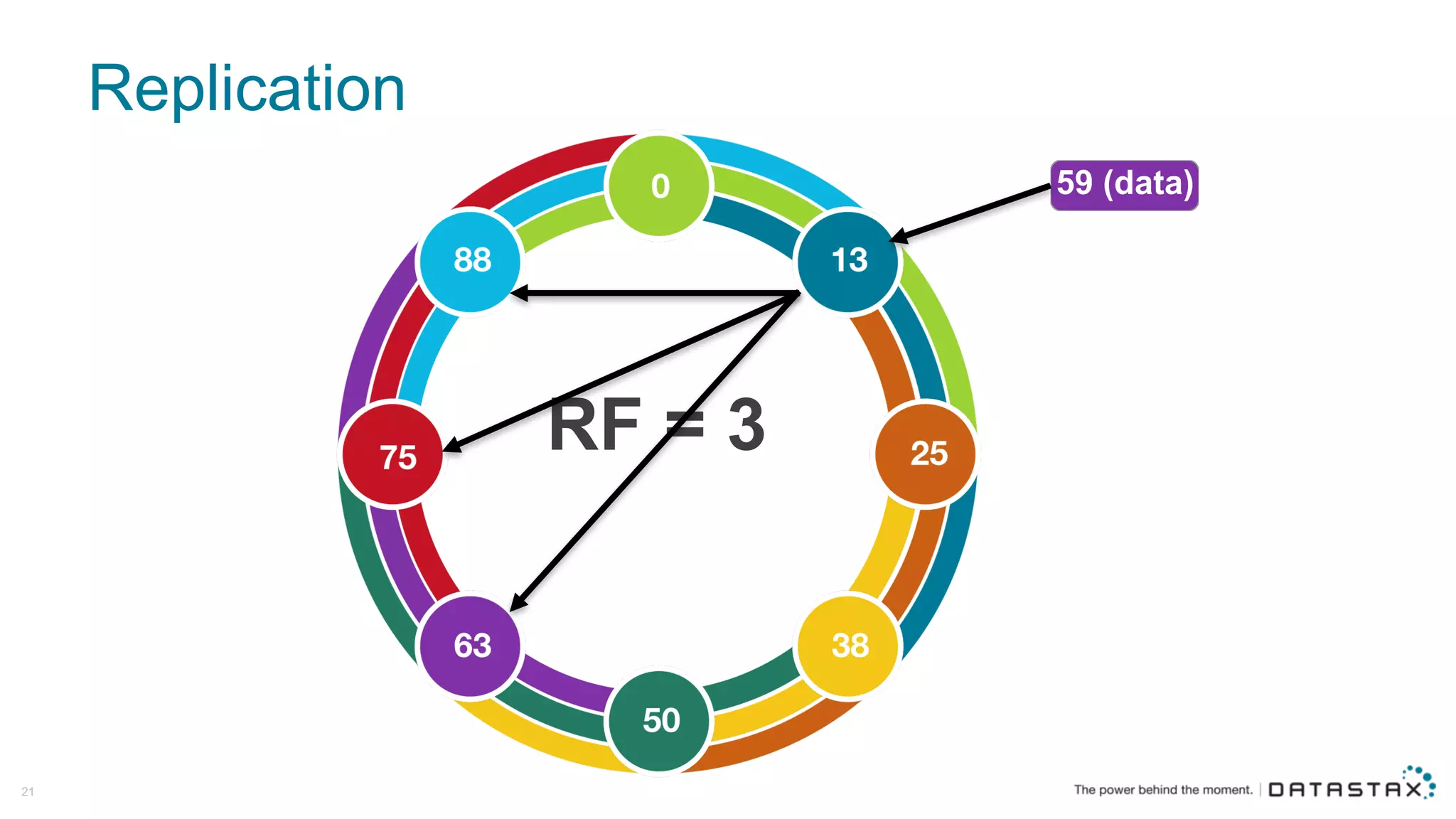
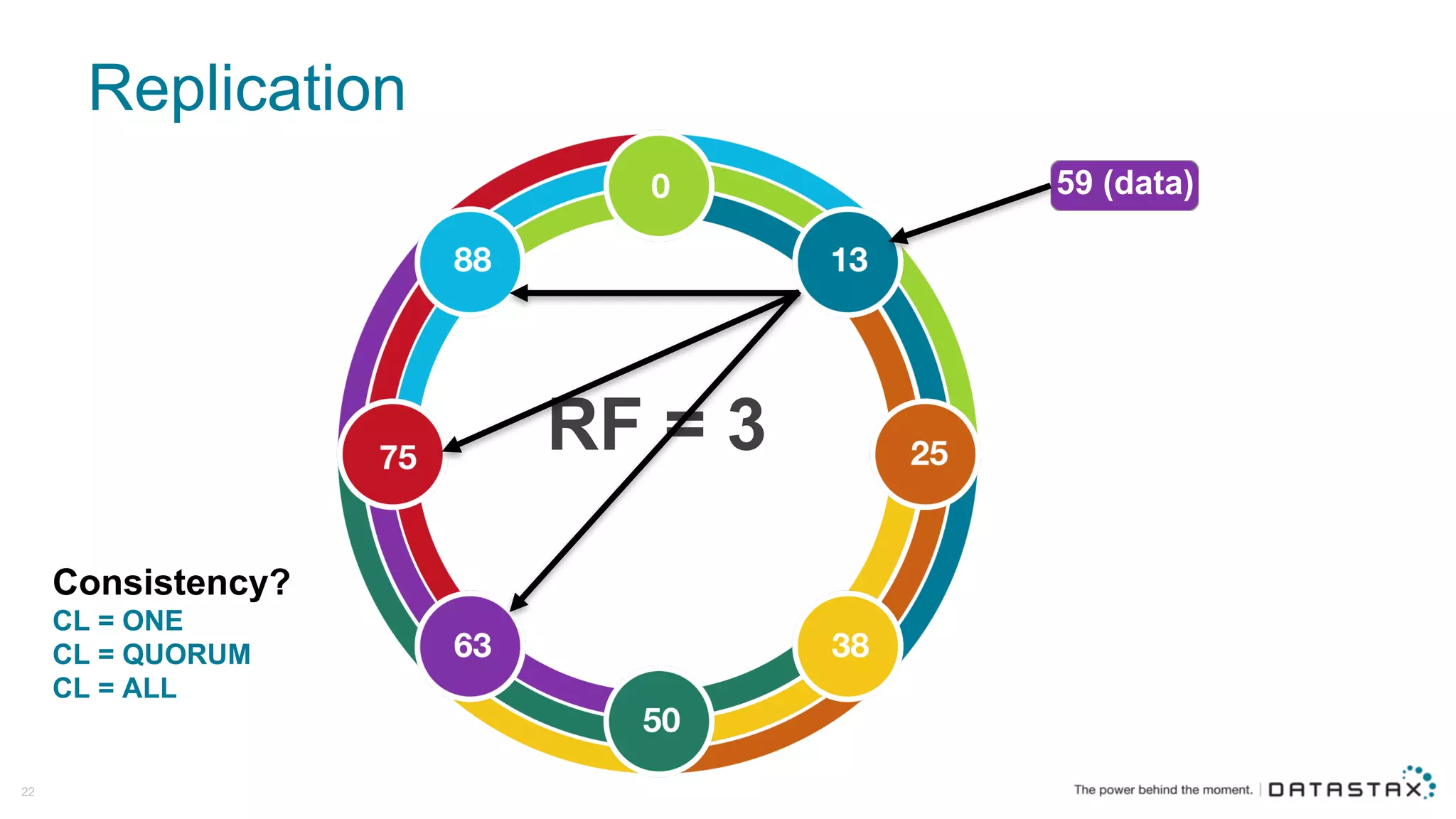

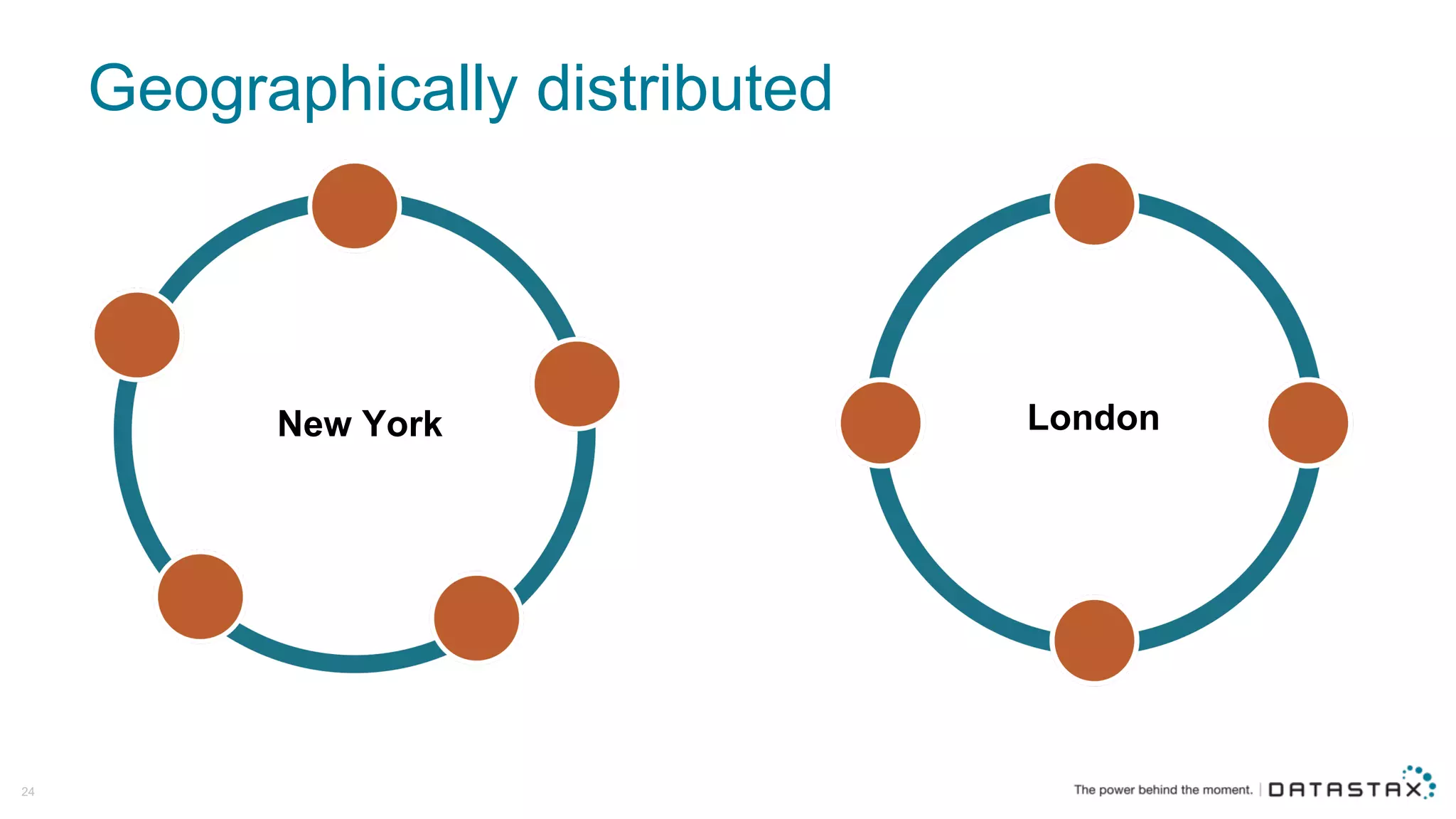
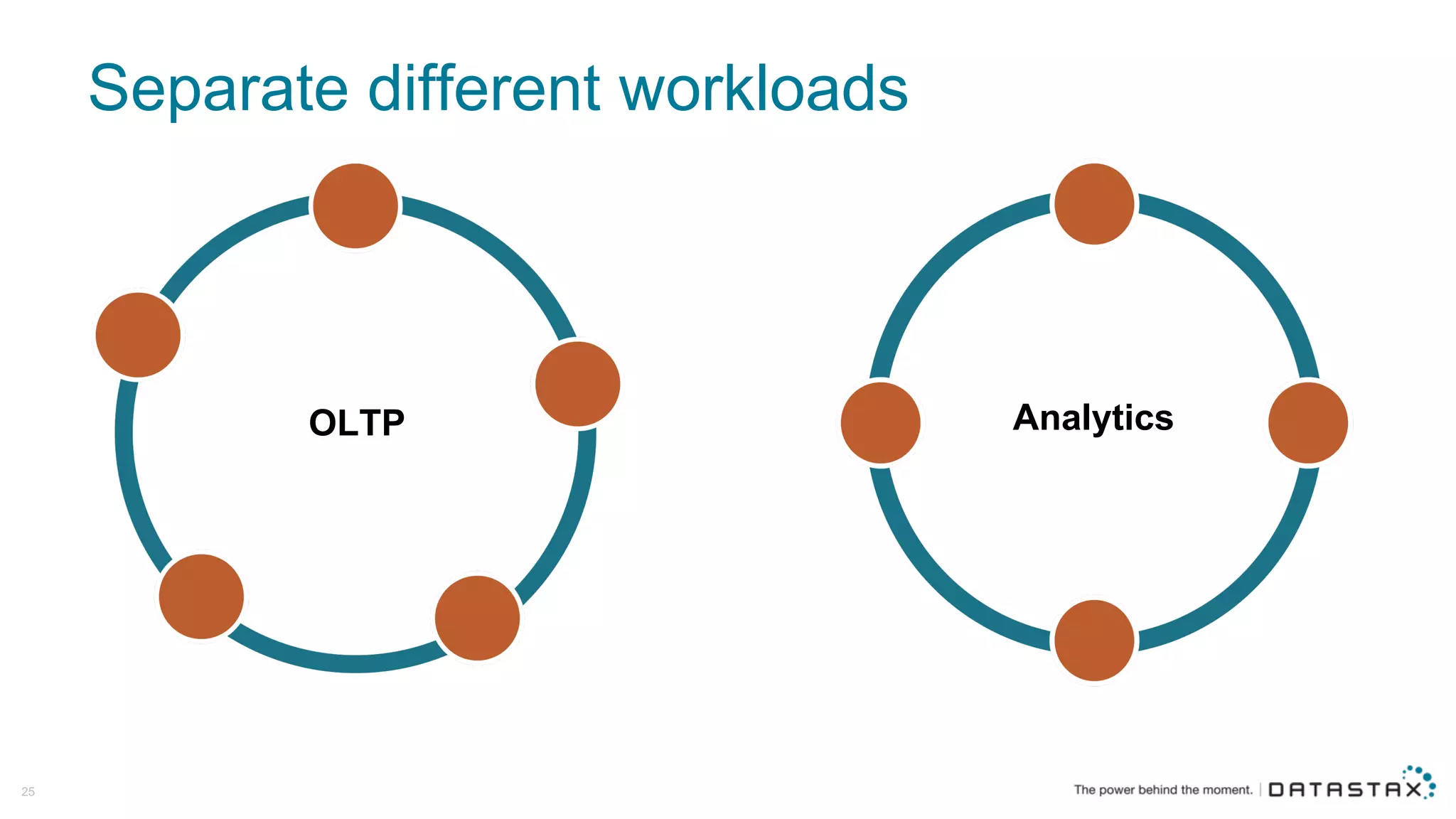
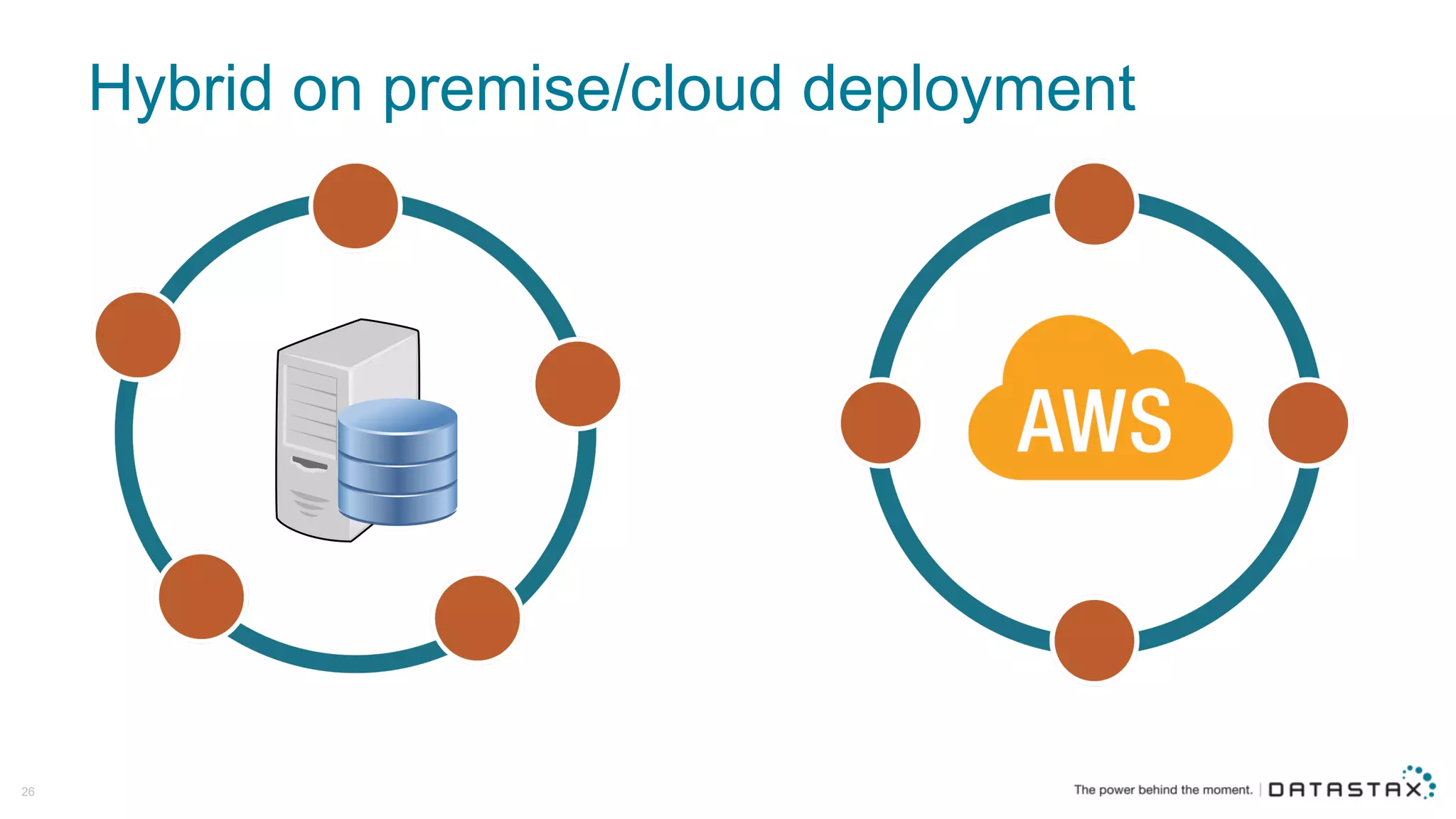
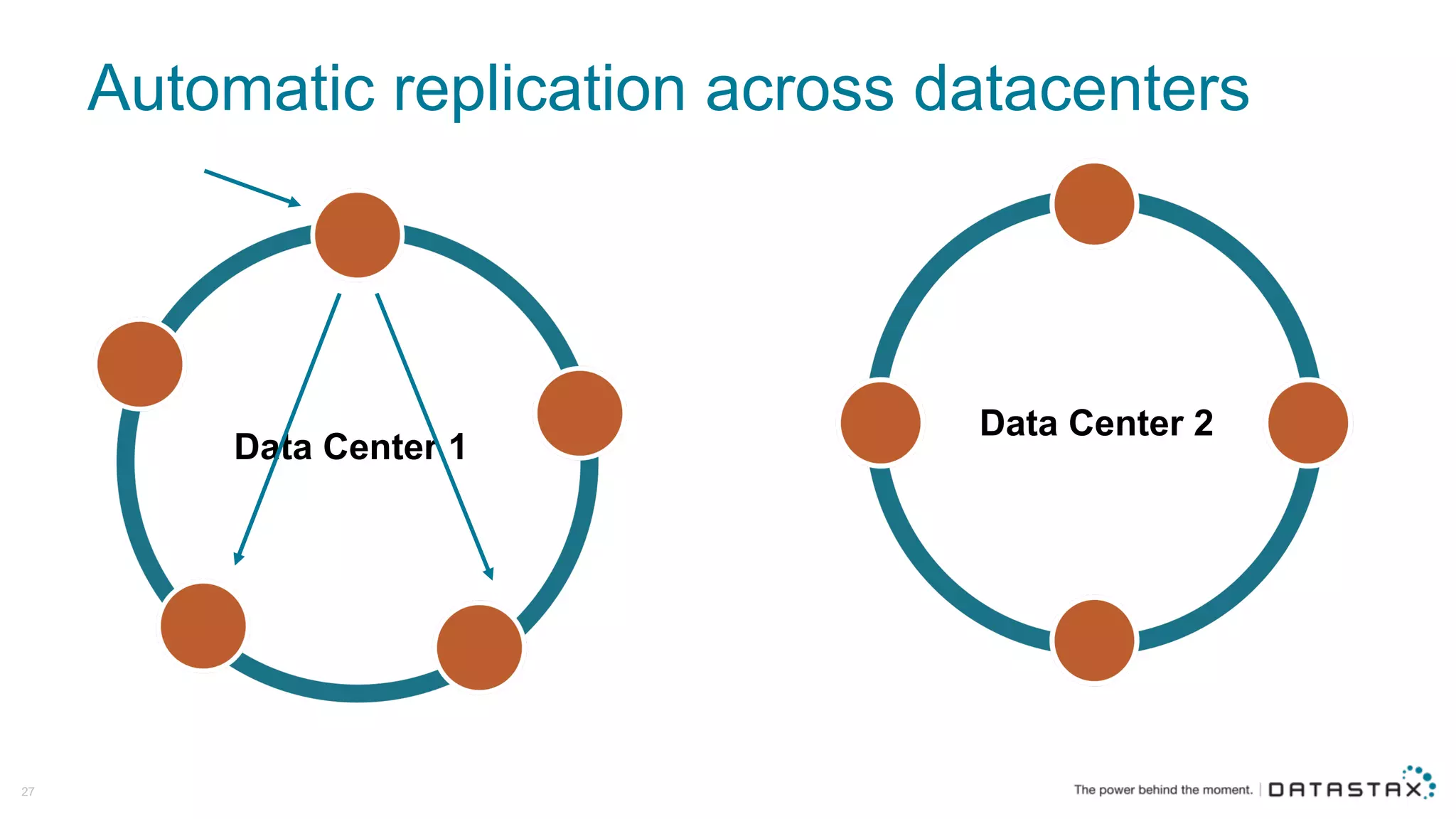
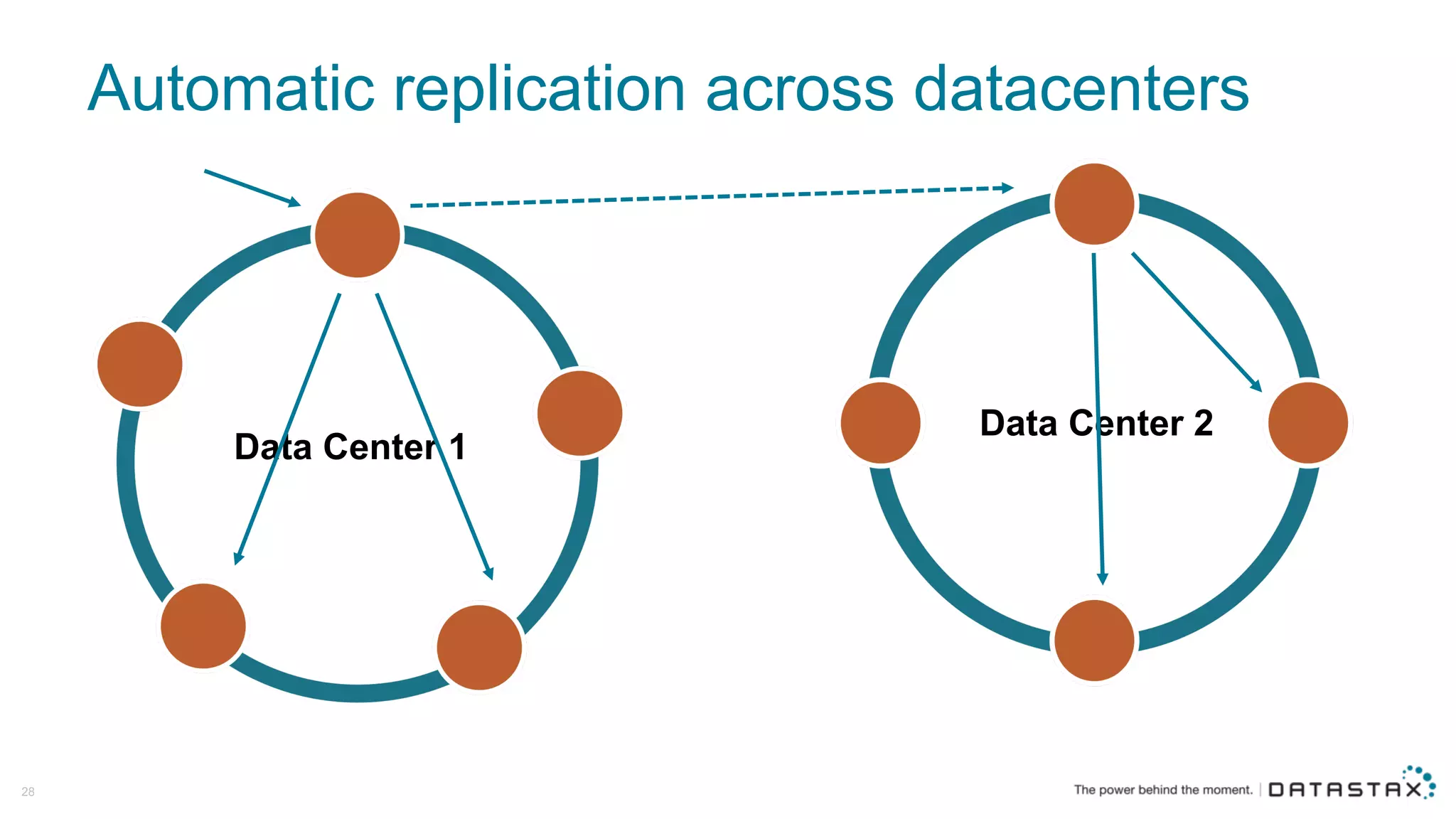





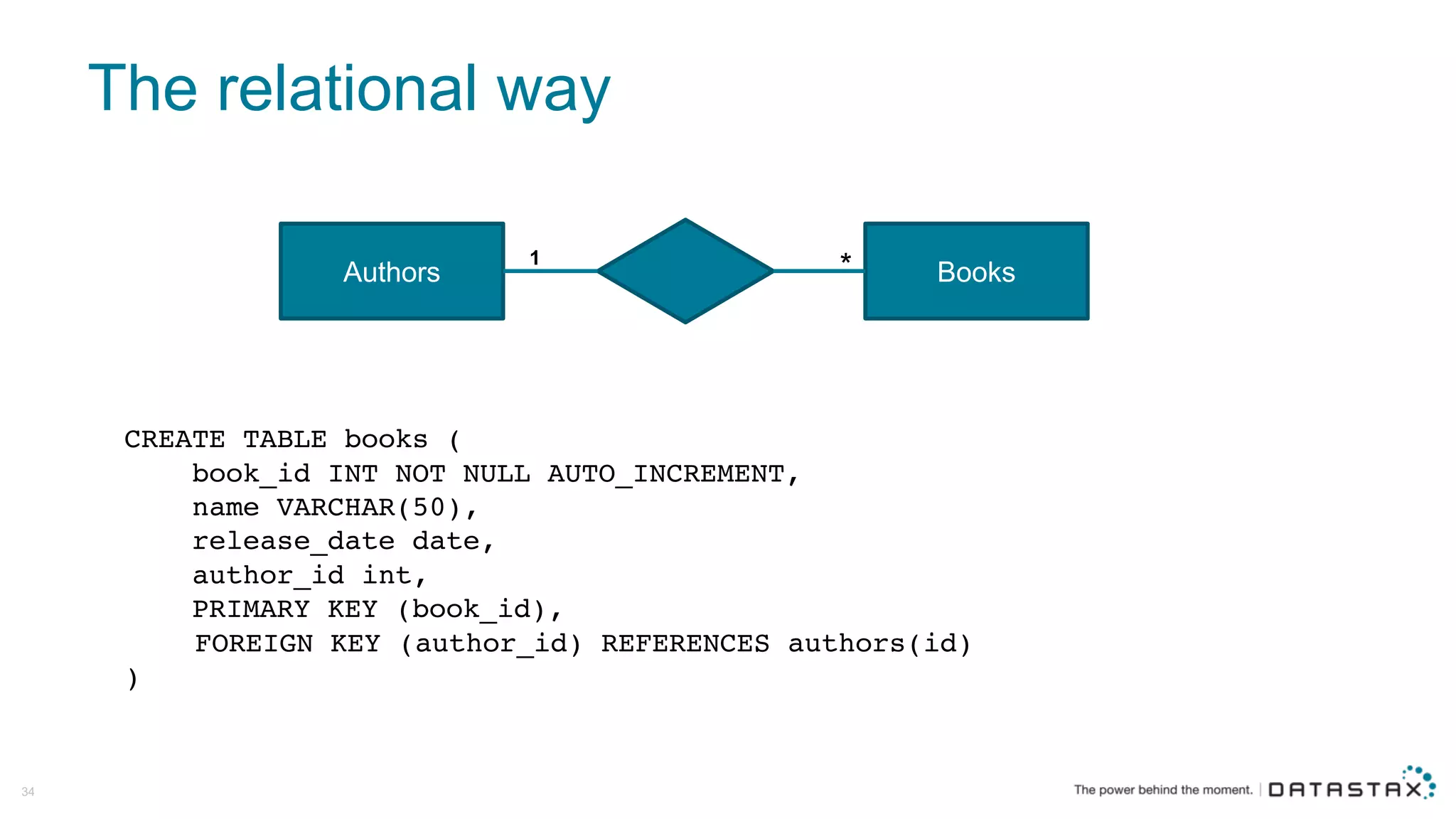





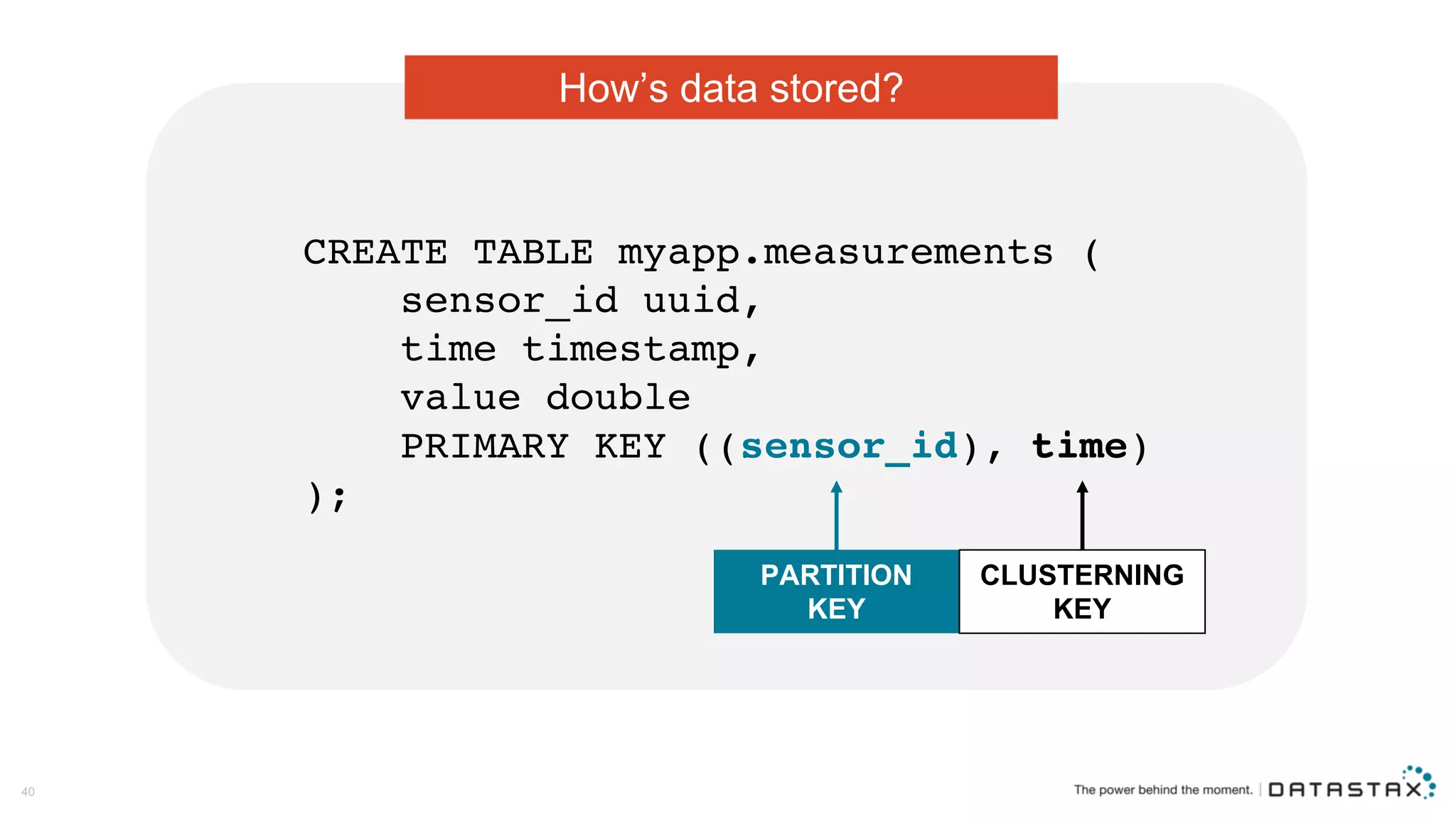






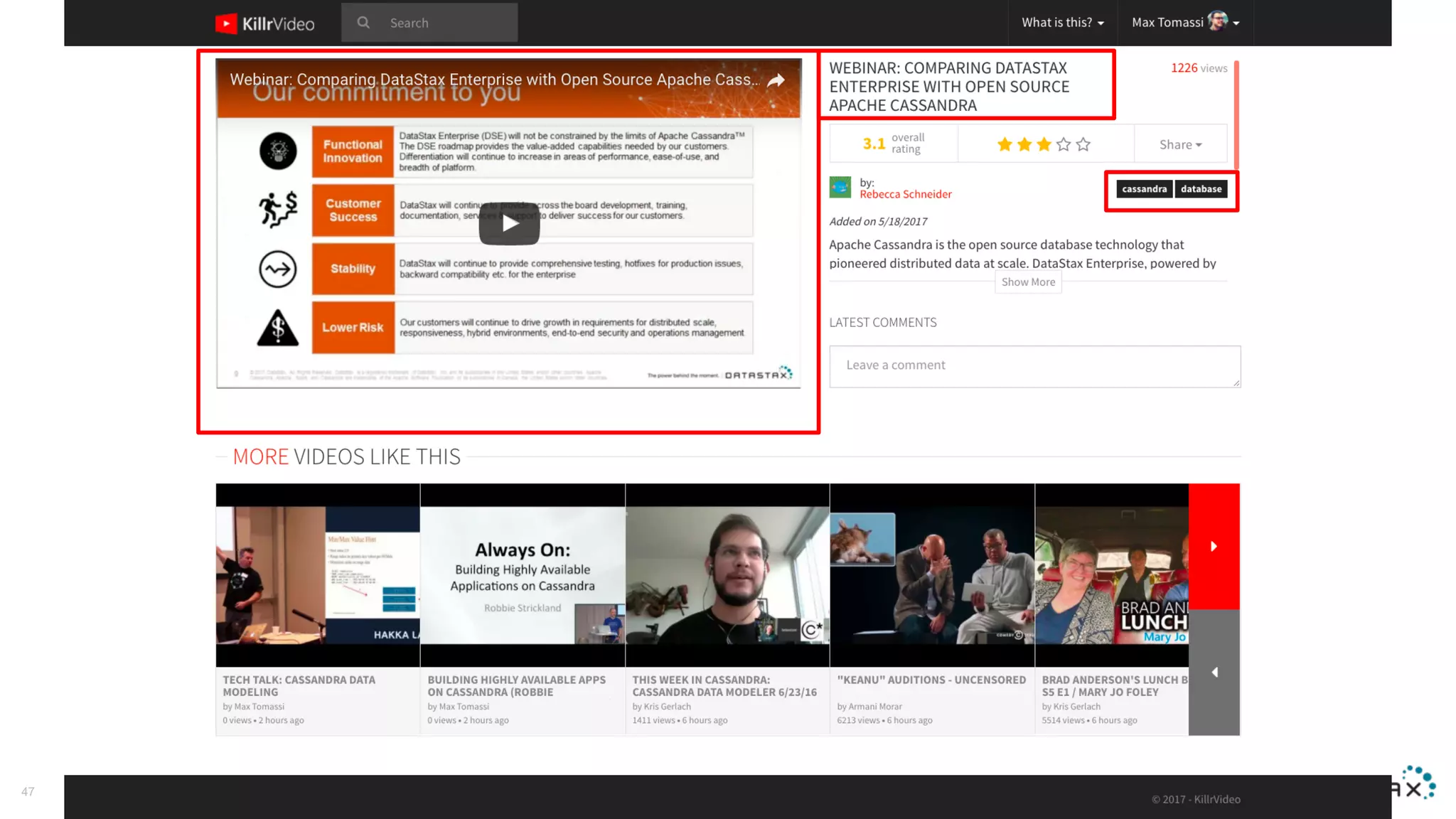







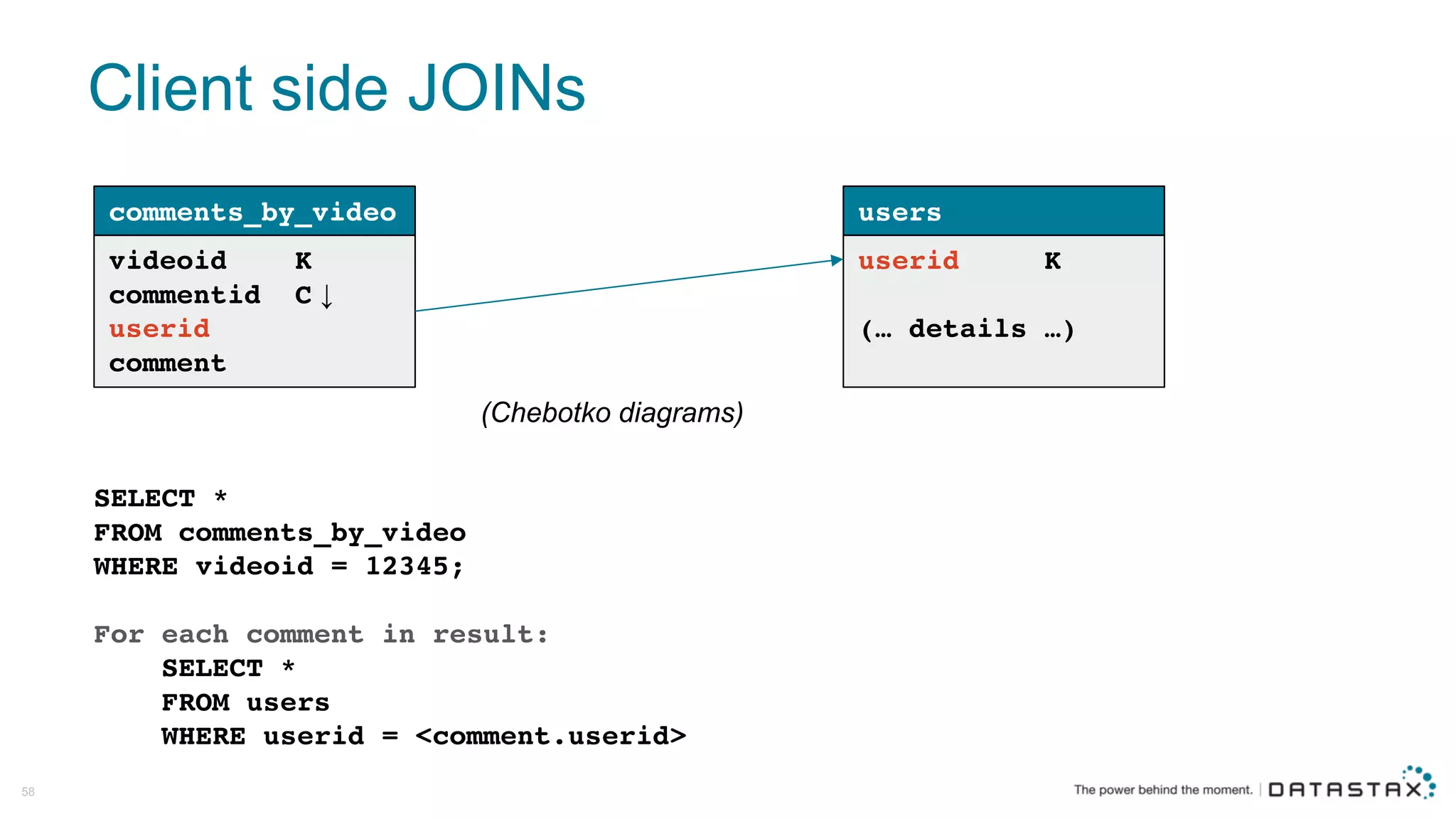















The document discusses Apache Cassandra and its data modeling, highlighting its distributed and masterless architecture, which facilitates scalability and real-time cloud applications. It provides examples of data modeling approaches in Cassandra versus relational databases, emphasizing the importance of denormalization and careful selection of partition and clustering keys. Additionally, it covers various use cases and solutions for common issues, such as data consistency and handling concurrent access.



































































