Downloaded 62 times

















![Операцииmutation(key, column, value) get(key, column)multi_get([k1, k2,…], column)get_slice(key, column_predicate). column_predicate: набор колонок или интервалget_range_slices(start_key, end_key, column_predicate)multi_get_sliceCounters: add/remove(key, column)](https://image.slidesharecdn.com/apachecassandra-nosql-111005041855-phpapp01/85/Apache-Cassandra-NoSQL-23-320.jpg)





























![Операцииmutation(key, column, value) get(key, column)multi_get([k1, k2,…], column)get_slice(key, column_predicate). column_predicate: набор колонок или интервалget_range_slices(start_key, end_key, column_predicate)multi_get_sliceCounters: add/remove(key, column)](https://image.slidesharecdn.com/apachecassandra-nosql-111005041855-phpapp01/75/Apache-Cassandra-NoSQL-23-2048.jpg)

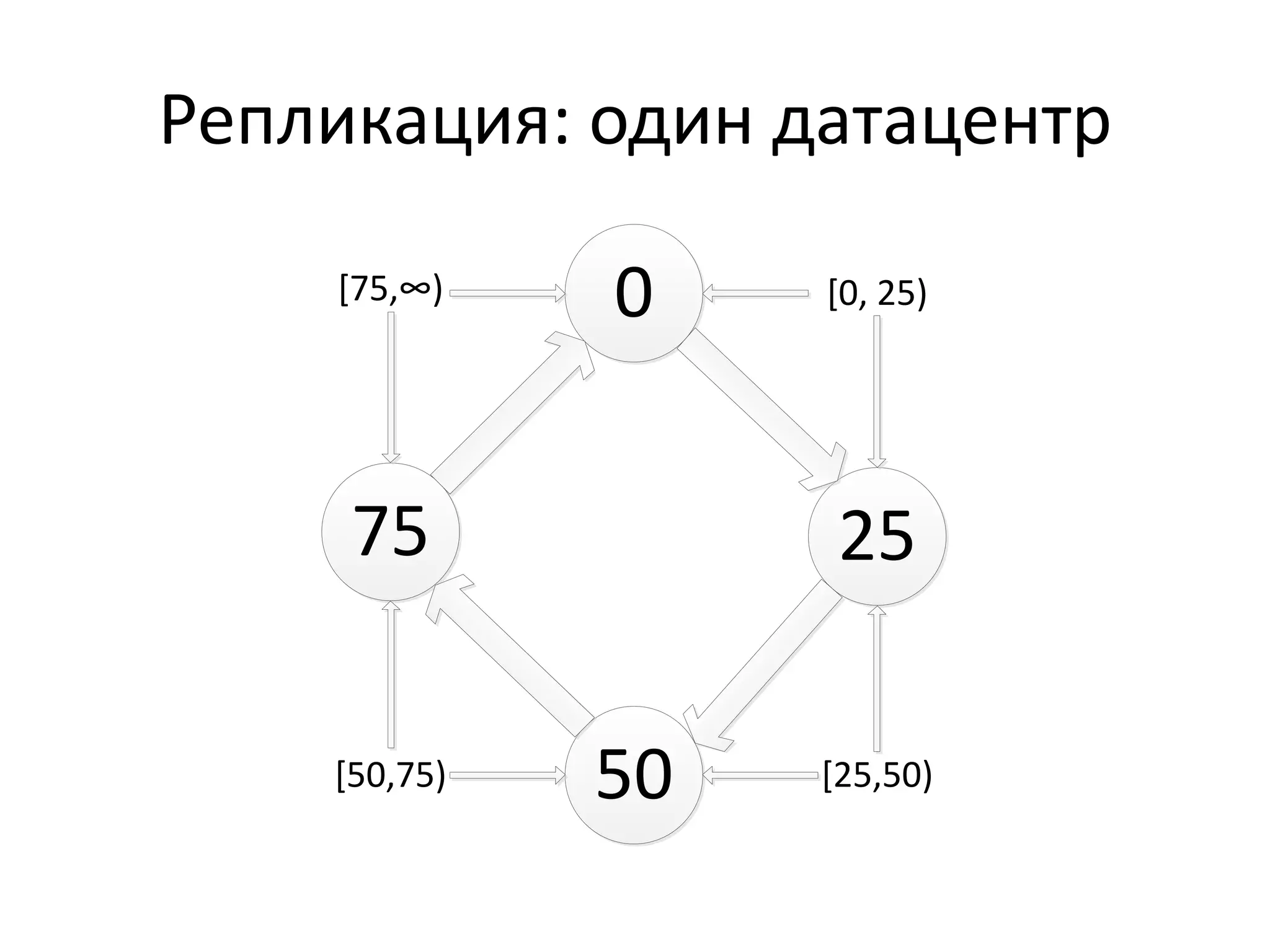
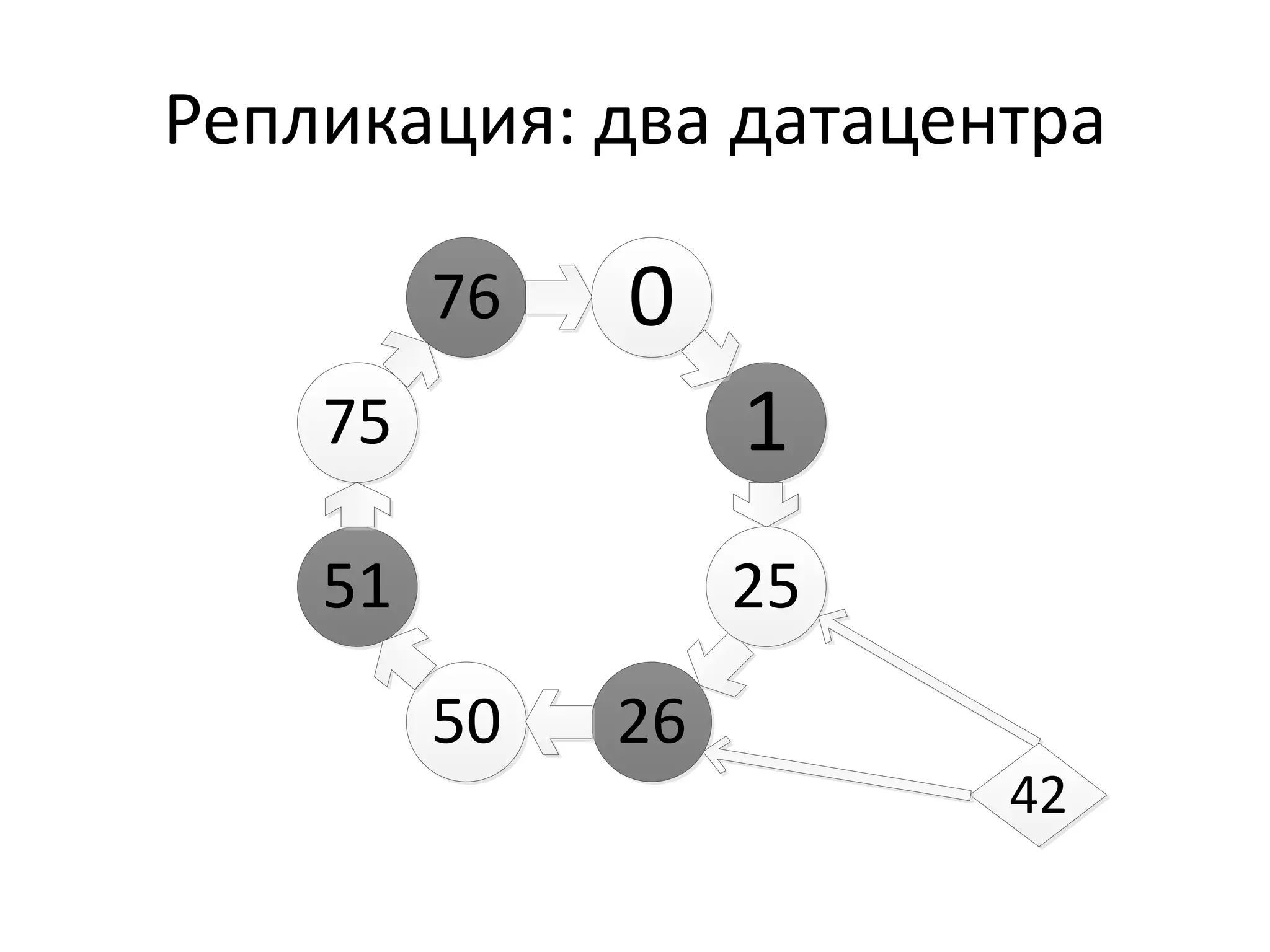






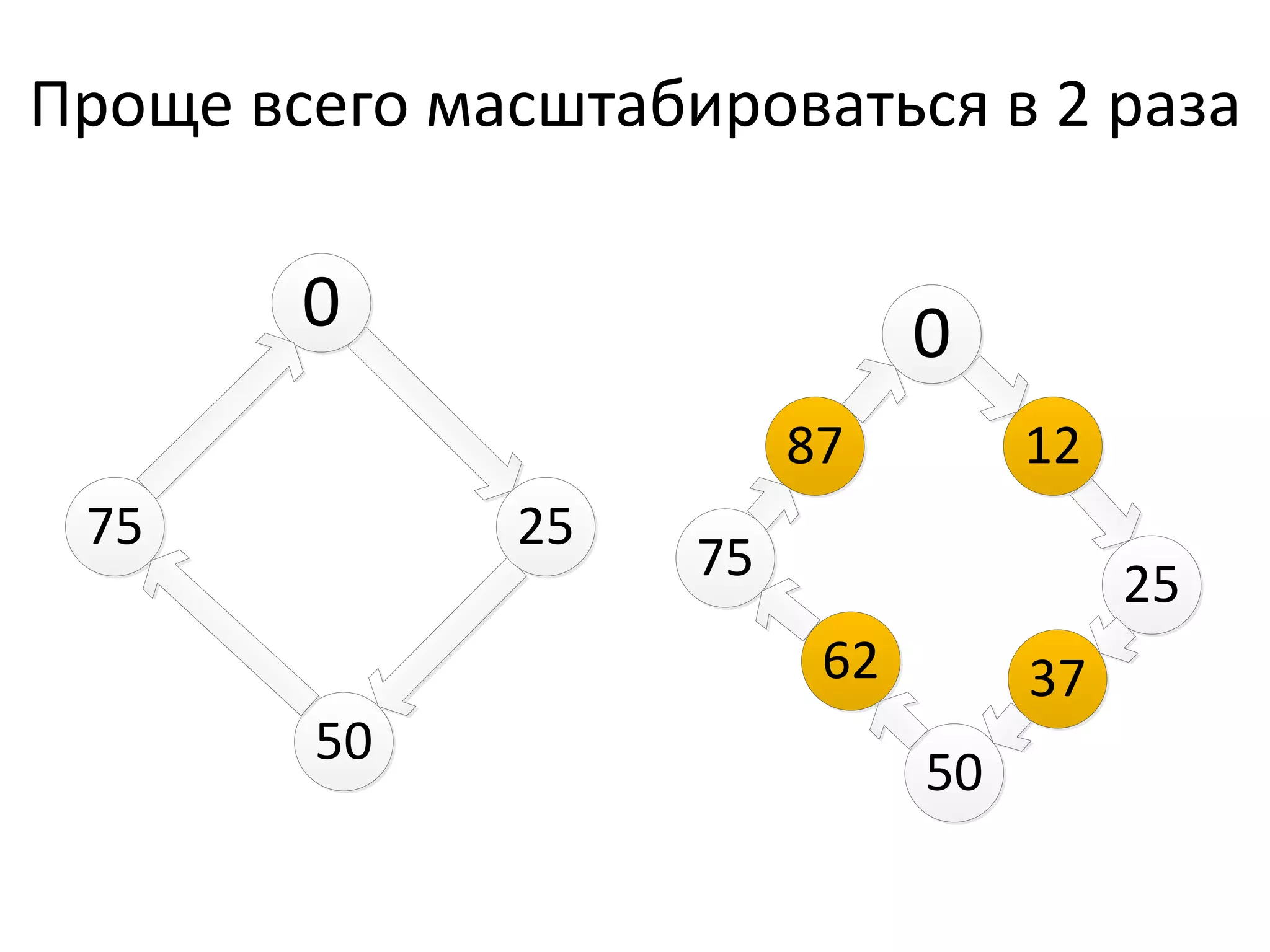







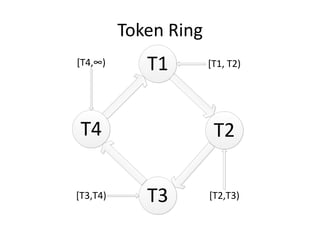
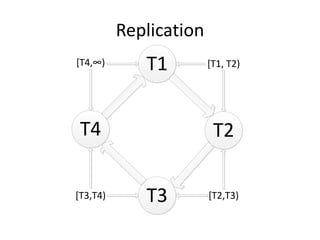
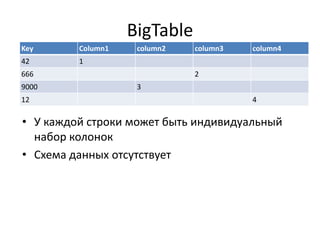
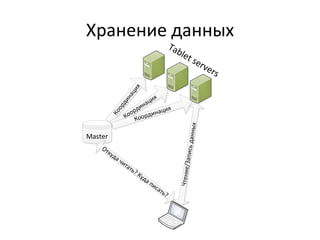
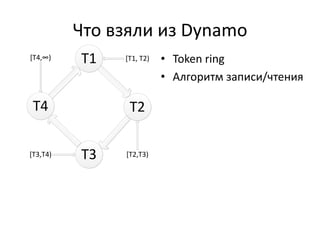
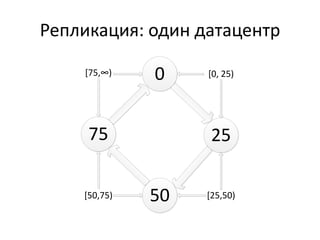
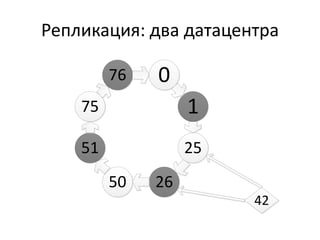
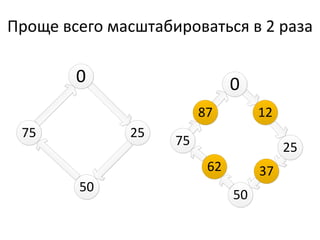
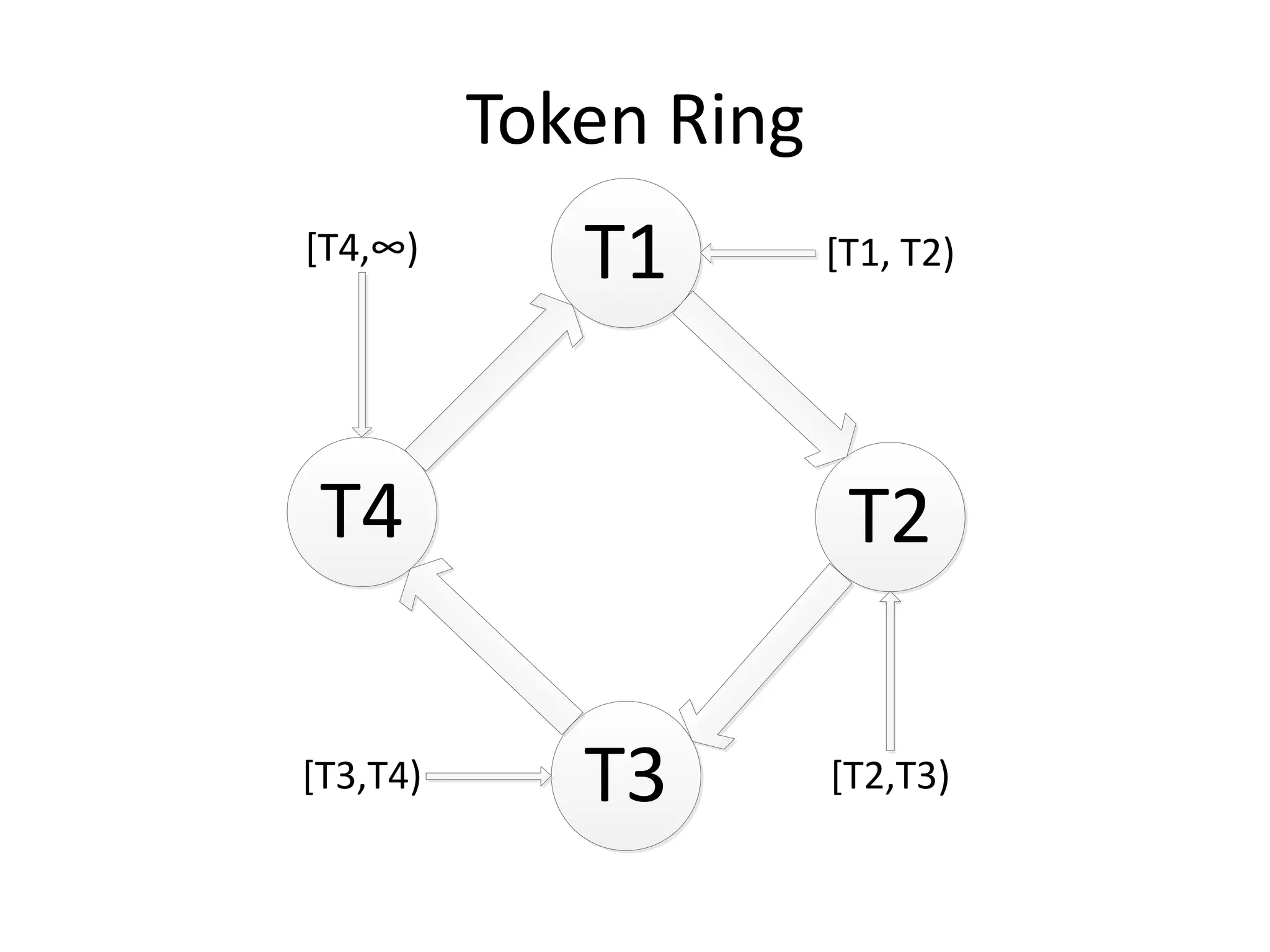
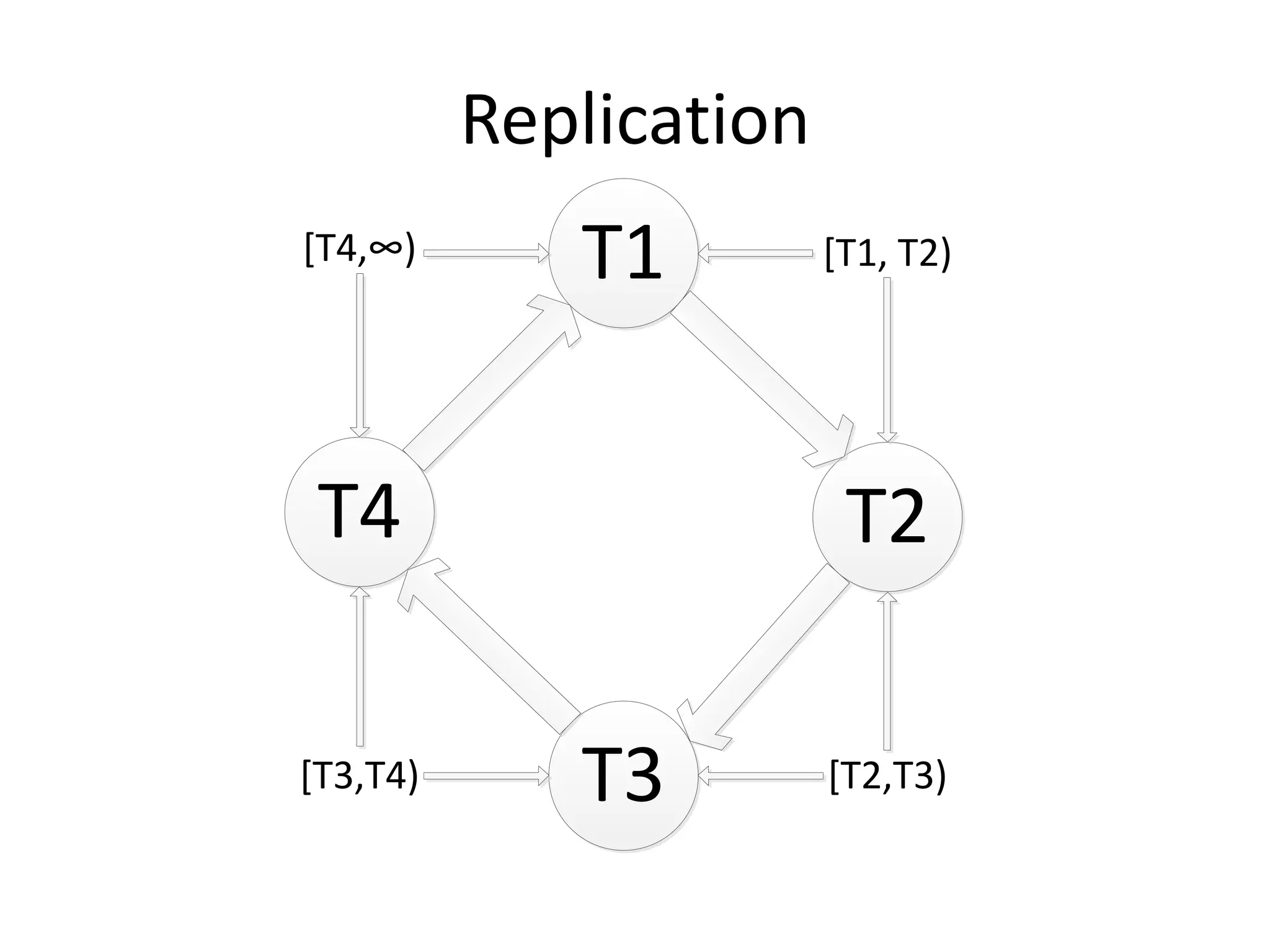
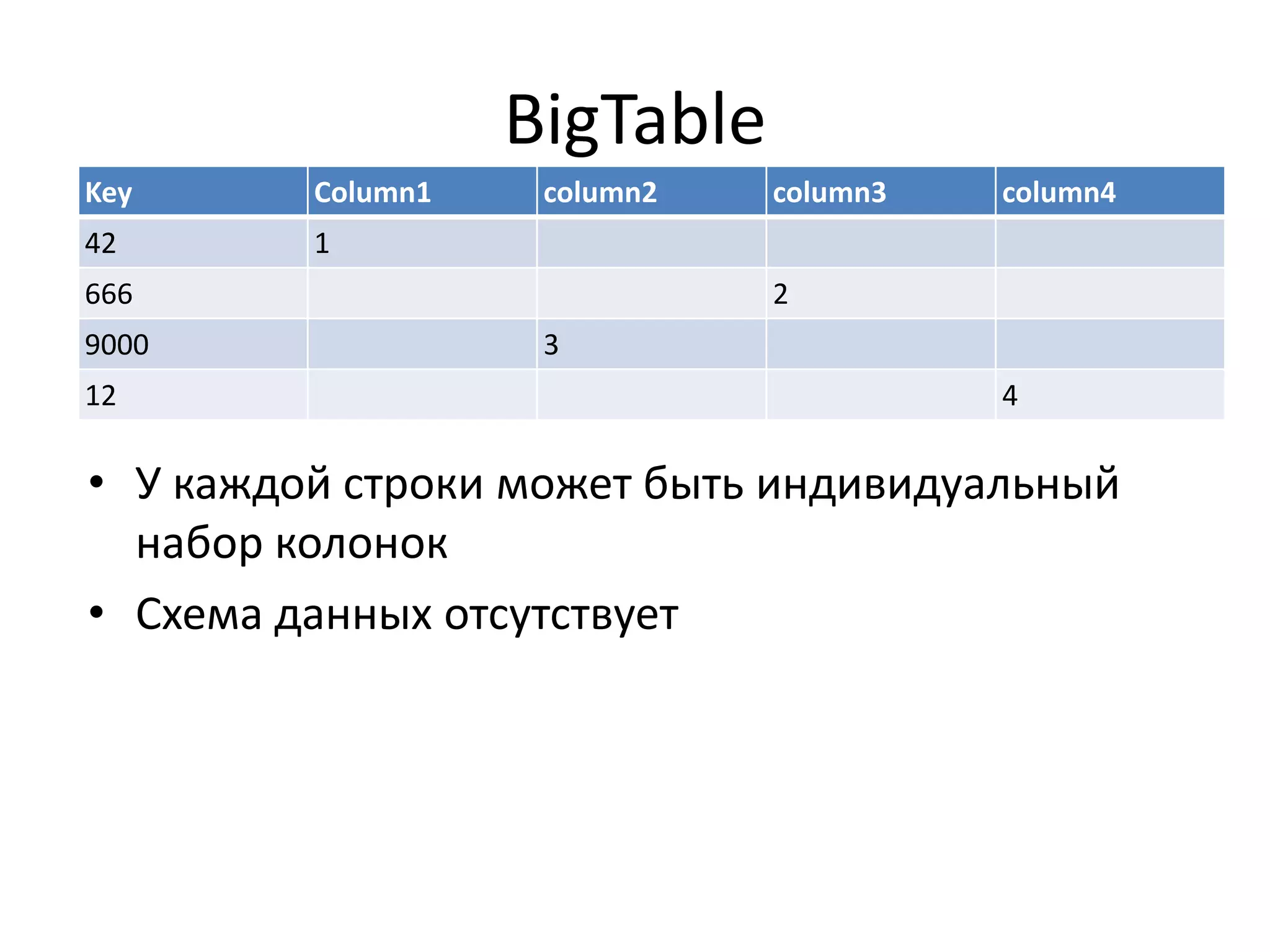
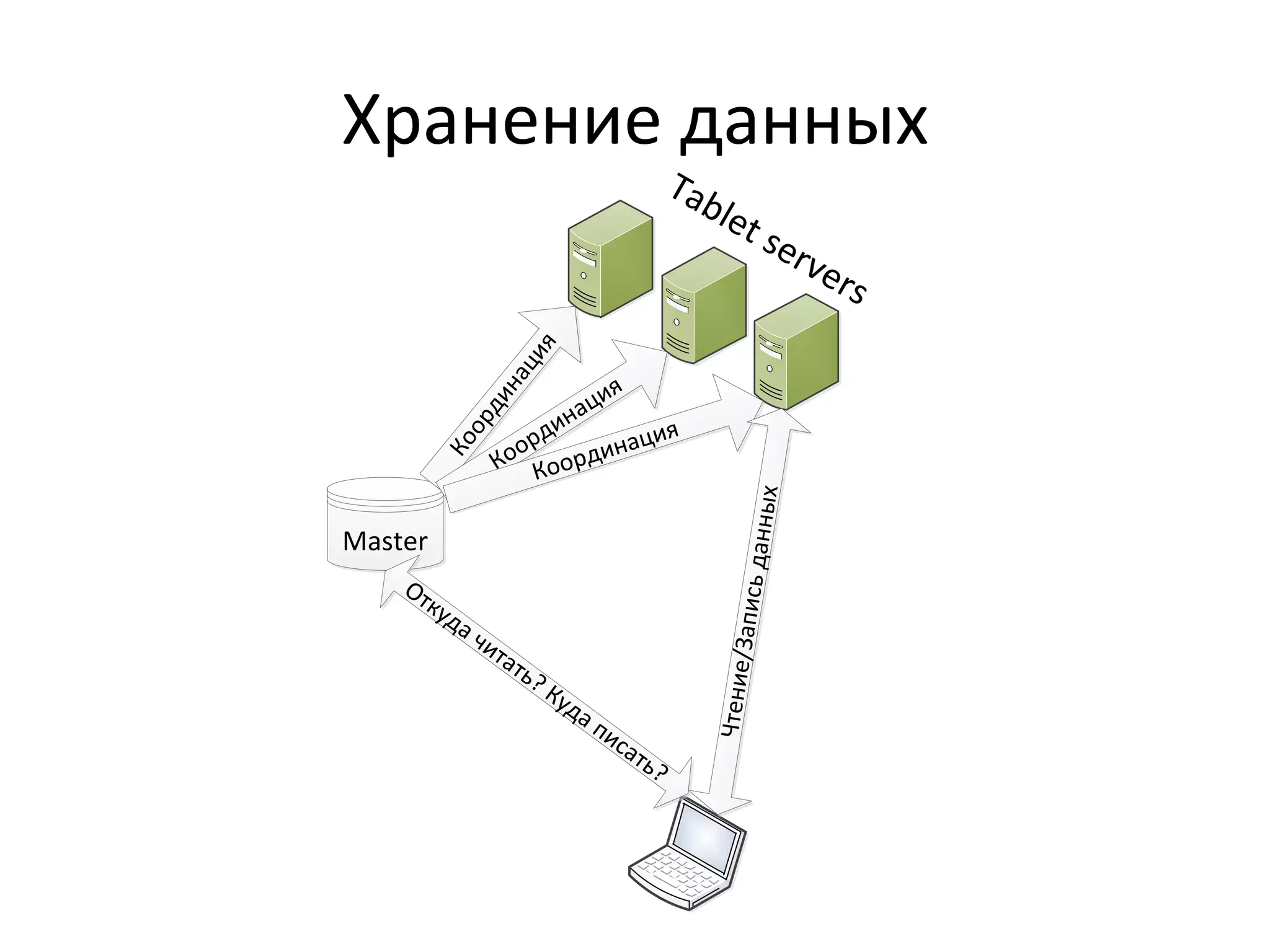
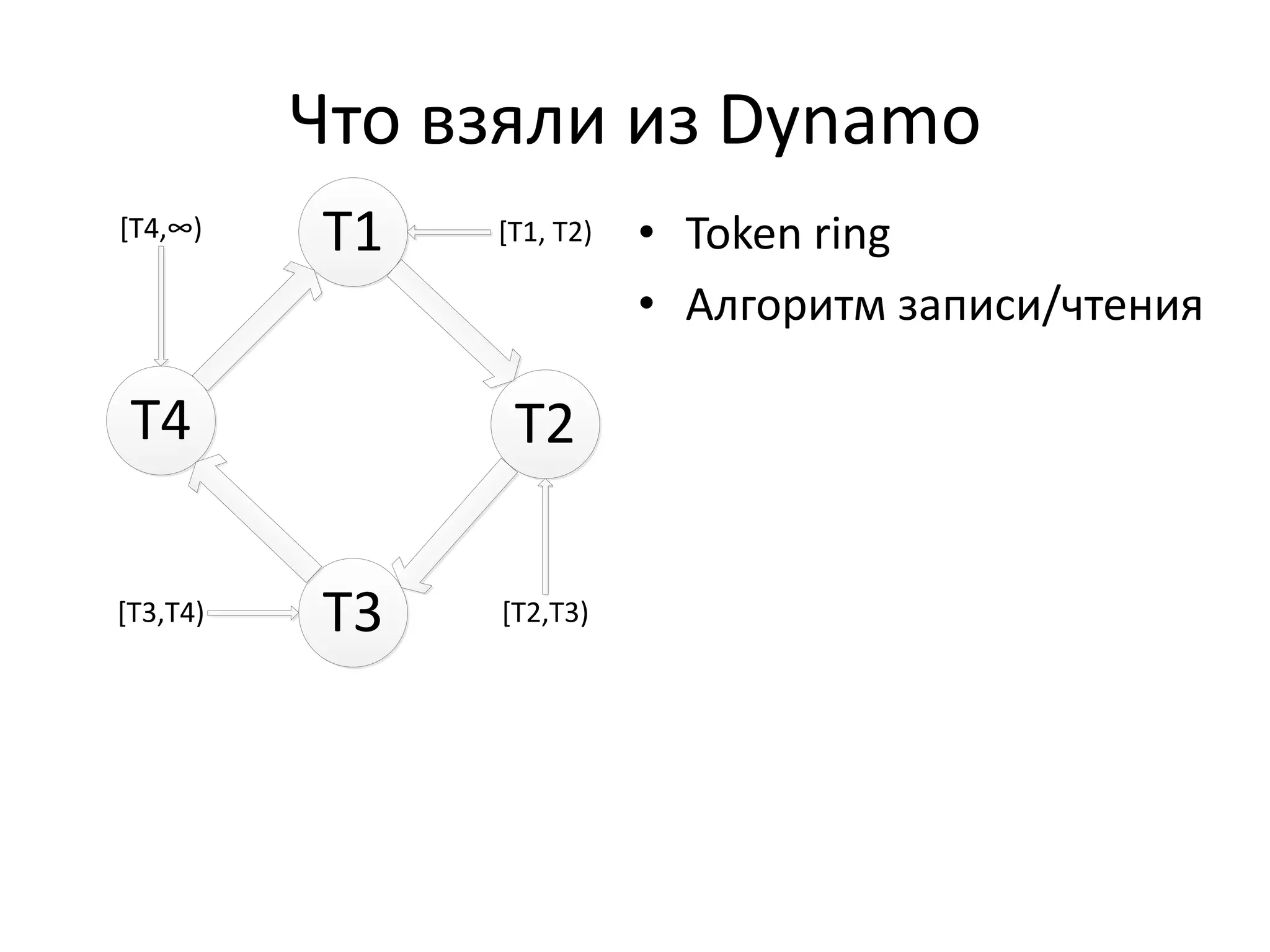
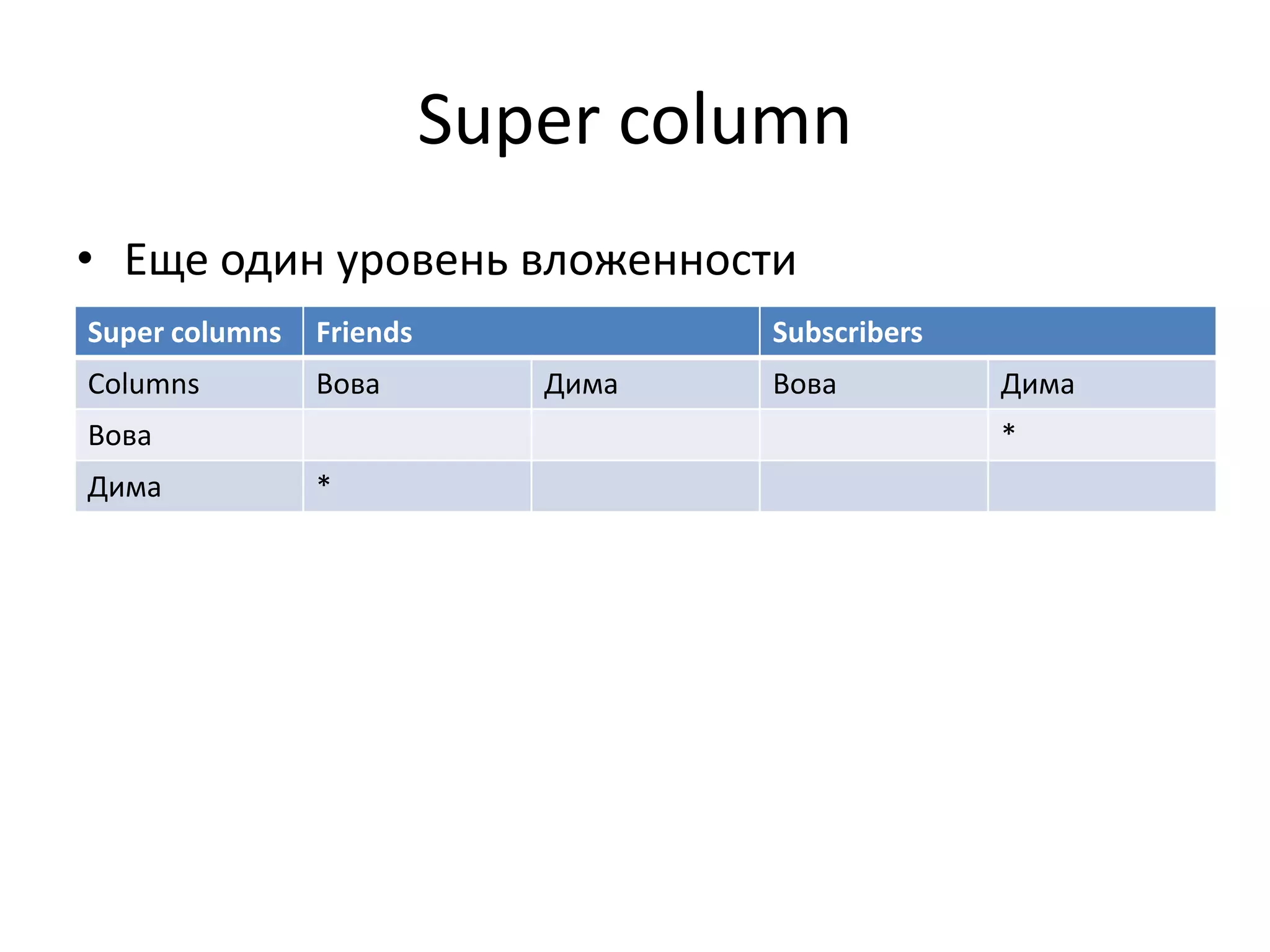
Документ обсуждает Apache Cassandra как одно из NoSQL-хранилищ данных, сравнивая его с Amazon Dynamo и Google Bigtable. Он объясняет внутренние механизмы архитектуры, такие как memtable, SSTable и принцип репликации, а также достоинства и недостатки системы, включая высокий уровень записи и проблемы с диапазонным сканированием. Также описываются примеры использования Cassandra для хранения событий в сфере онлайн-рекламы и приводятся результаты тестирования производительности кластера.























































































