Download to read offline





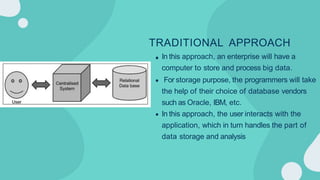


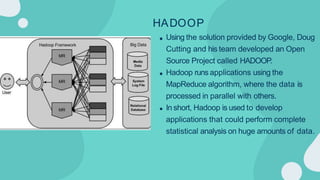





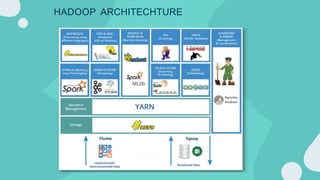

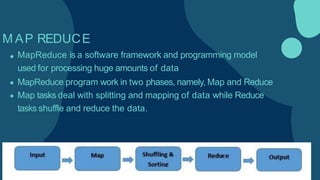













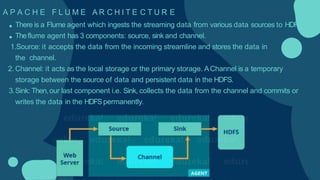

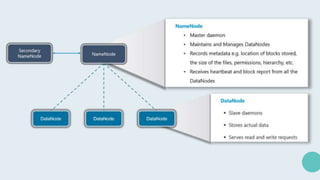
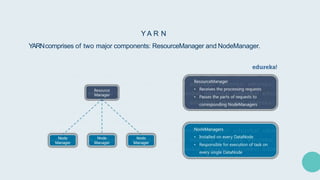






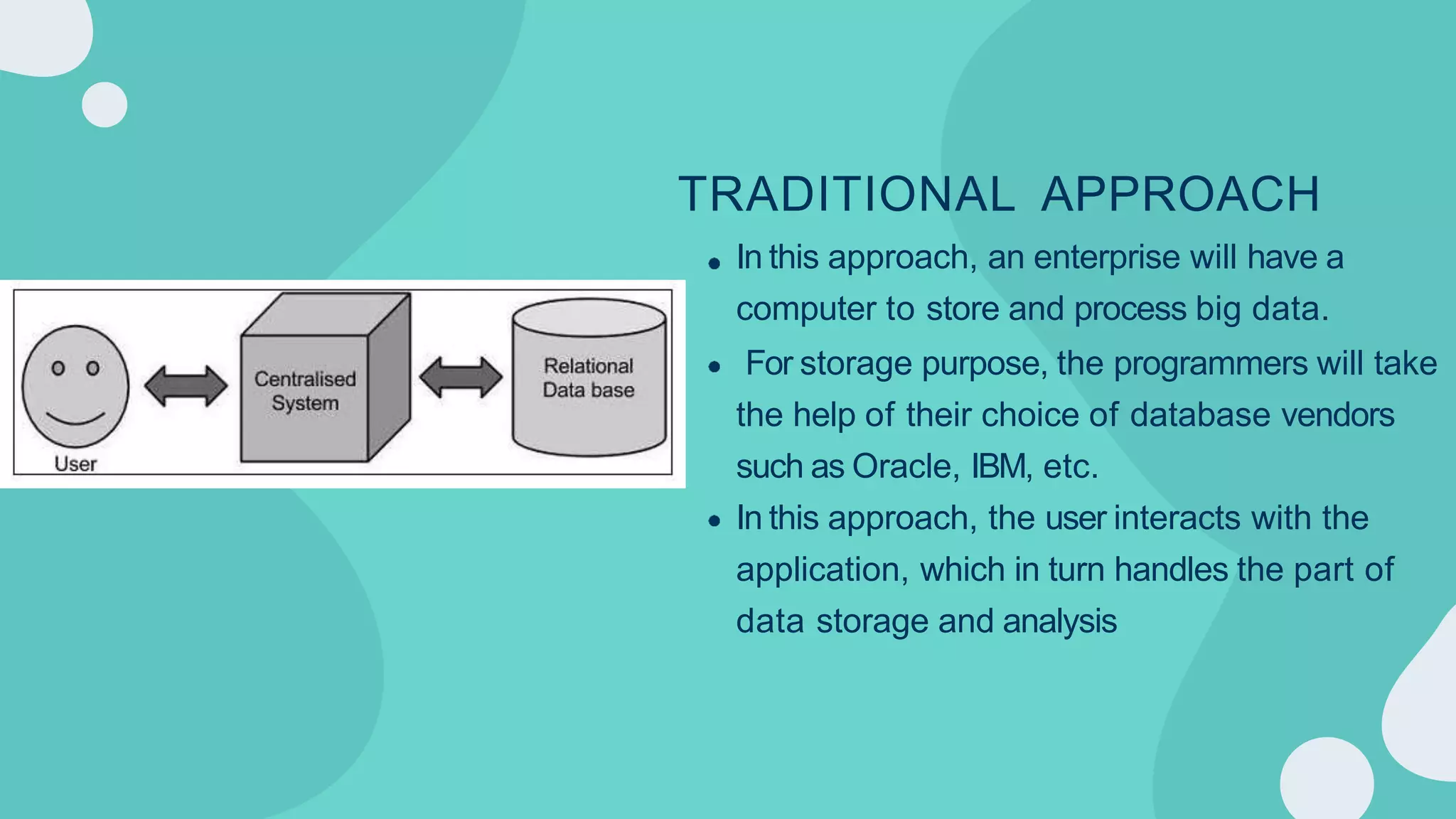
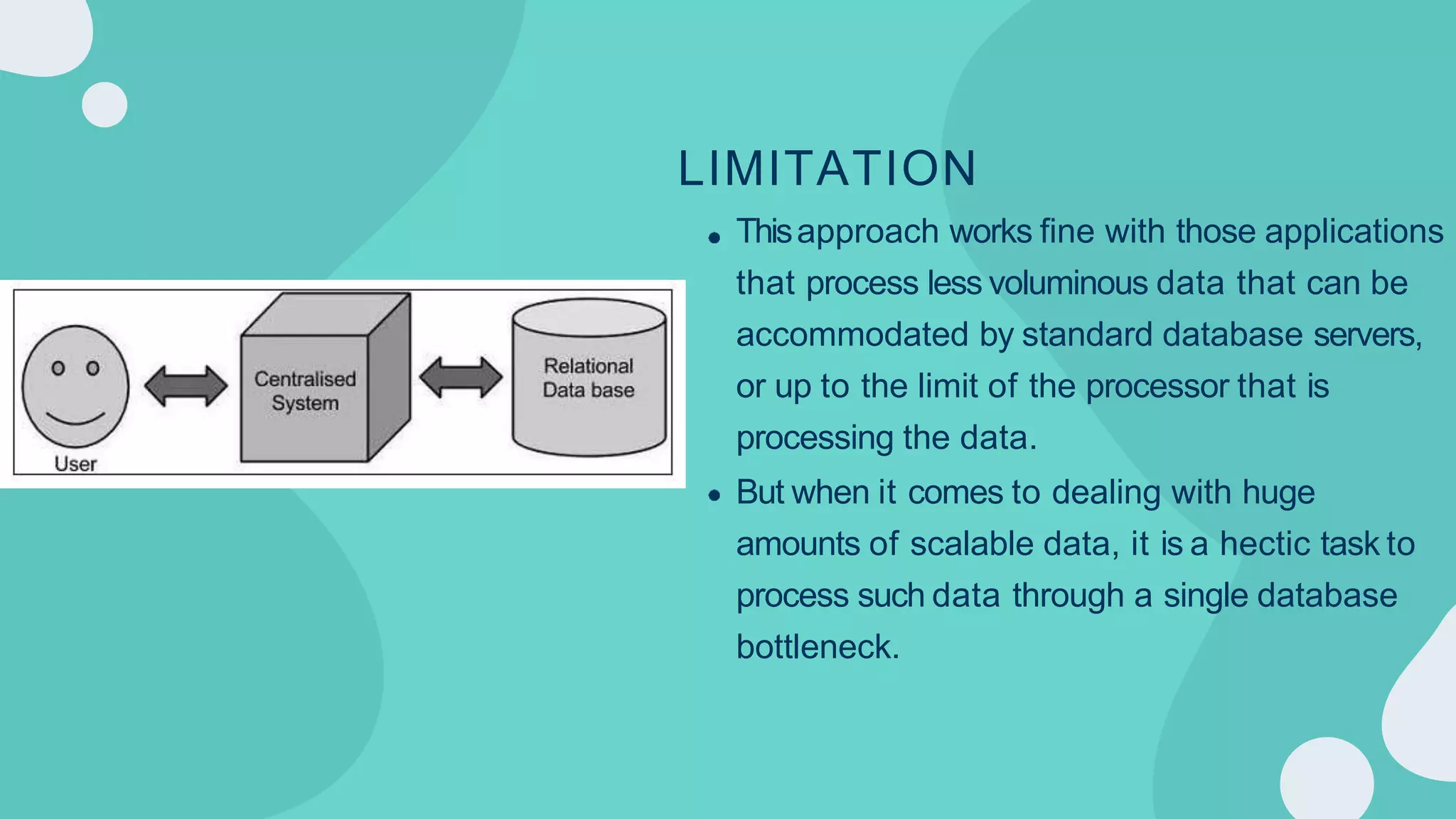
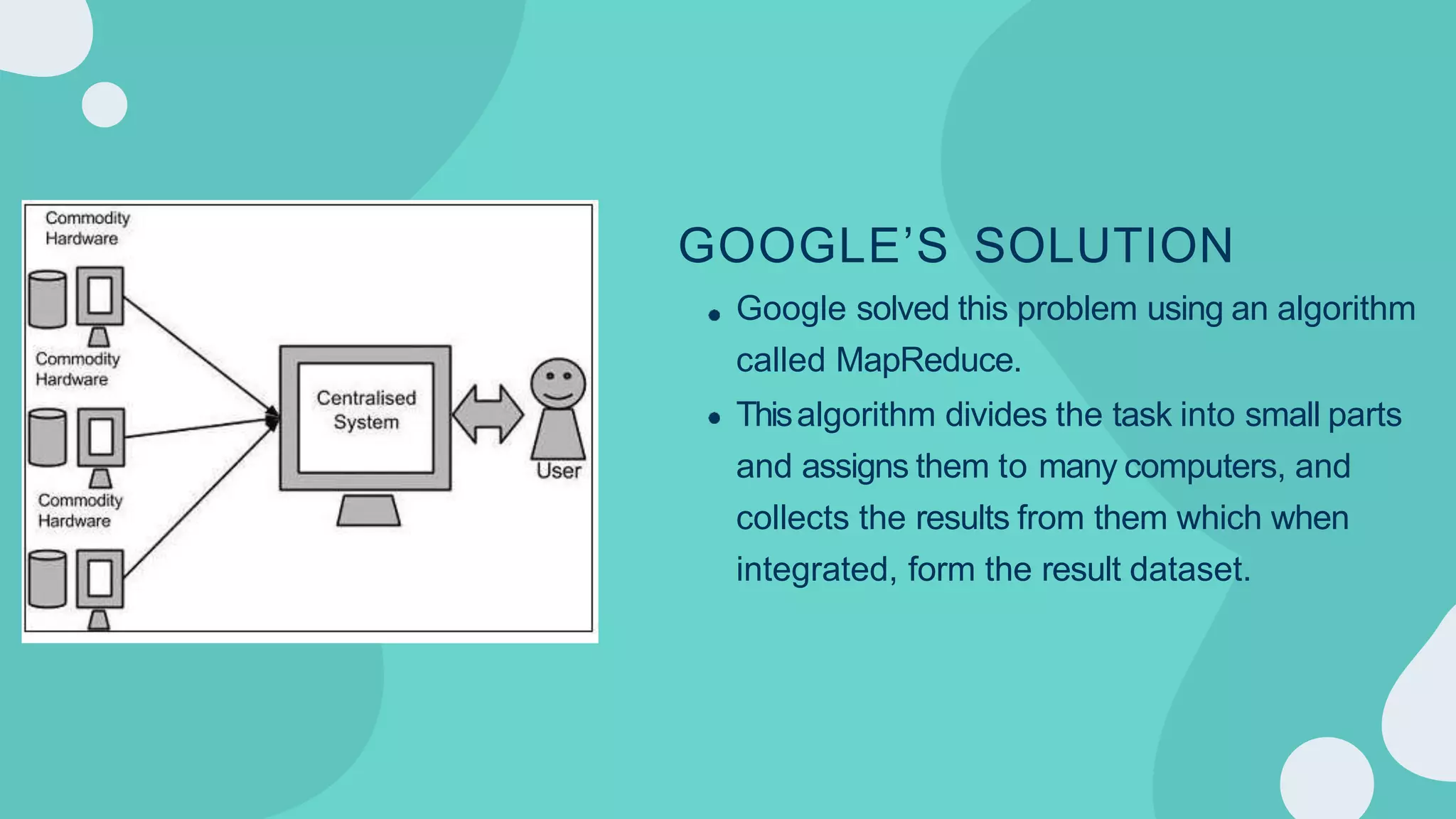
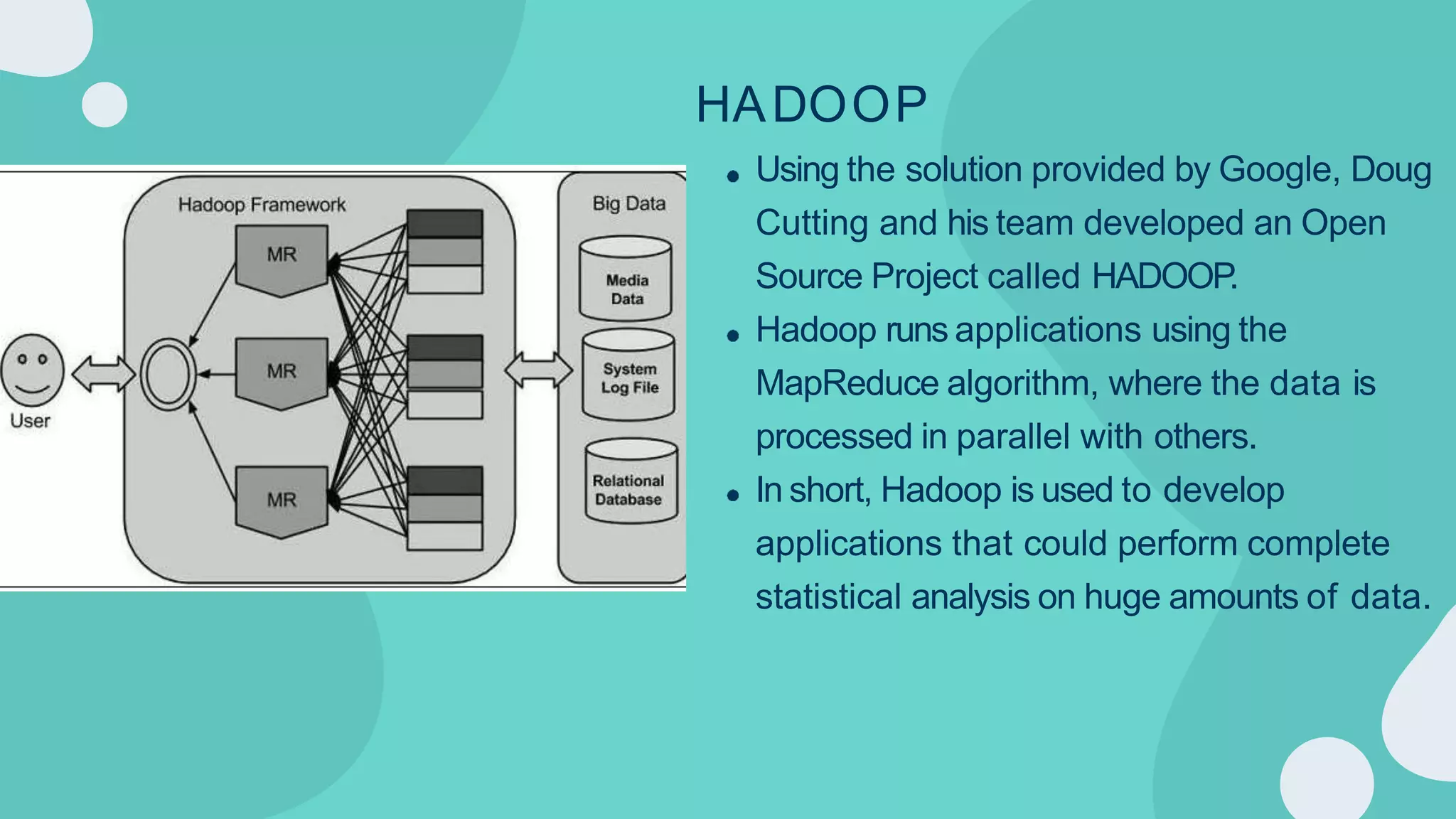





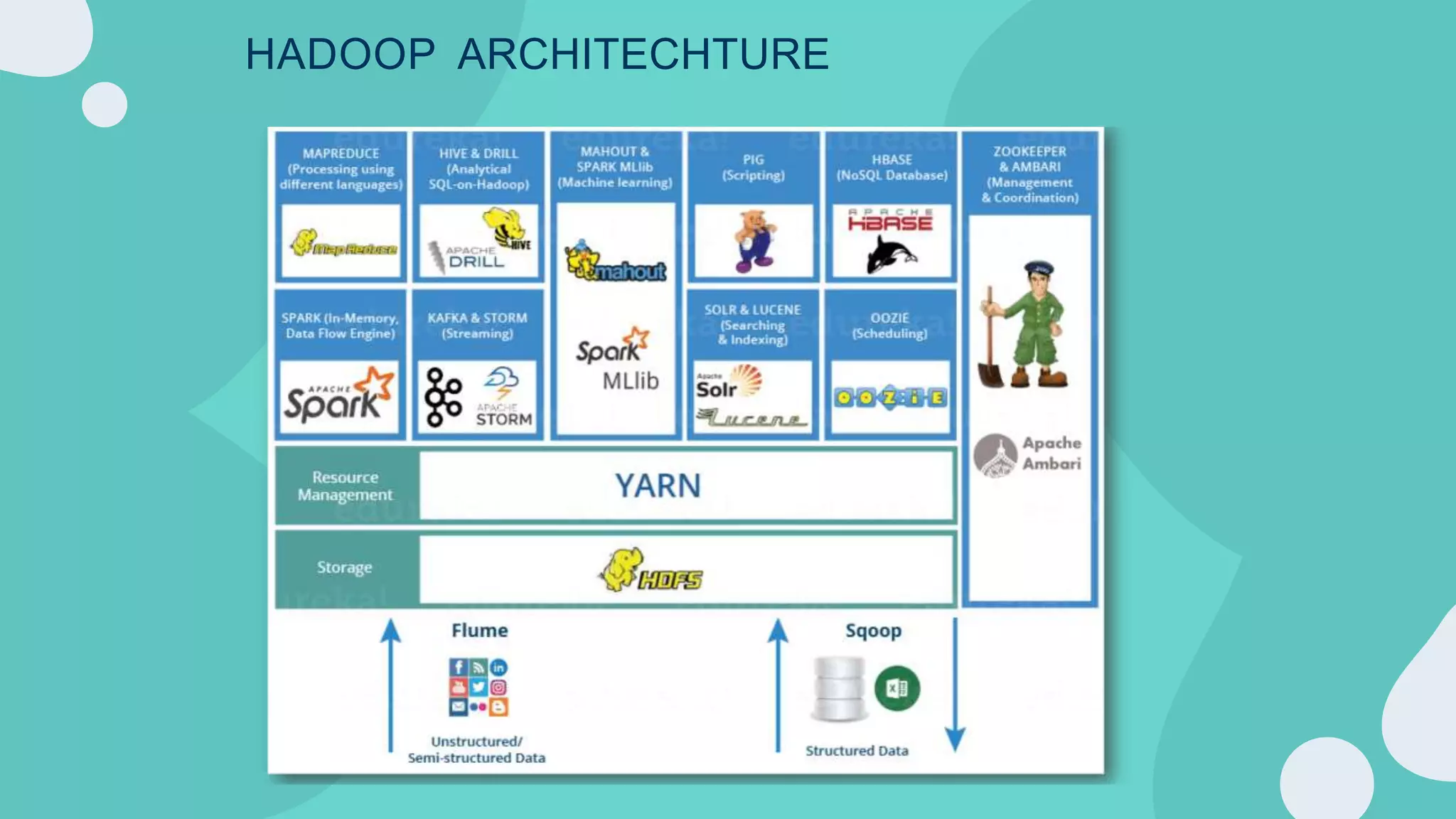
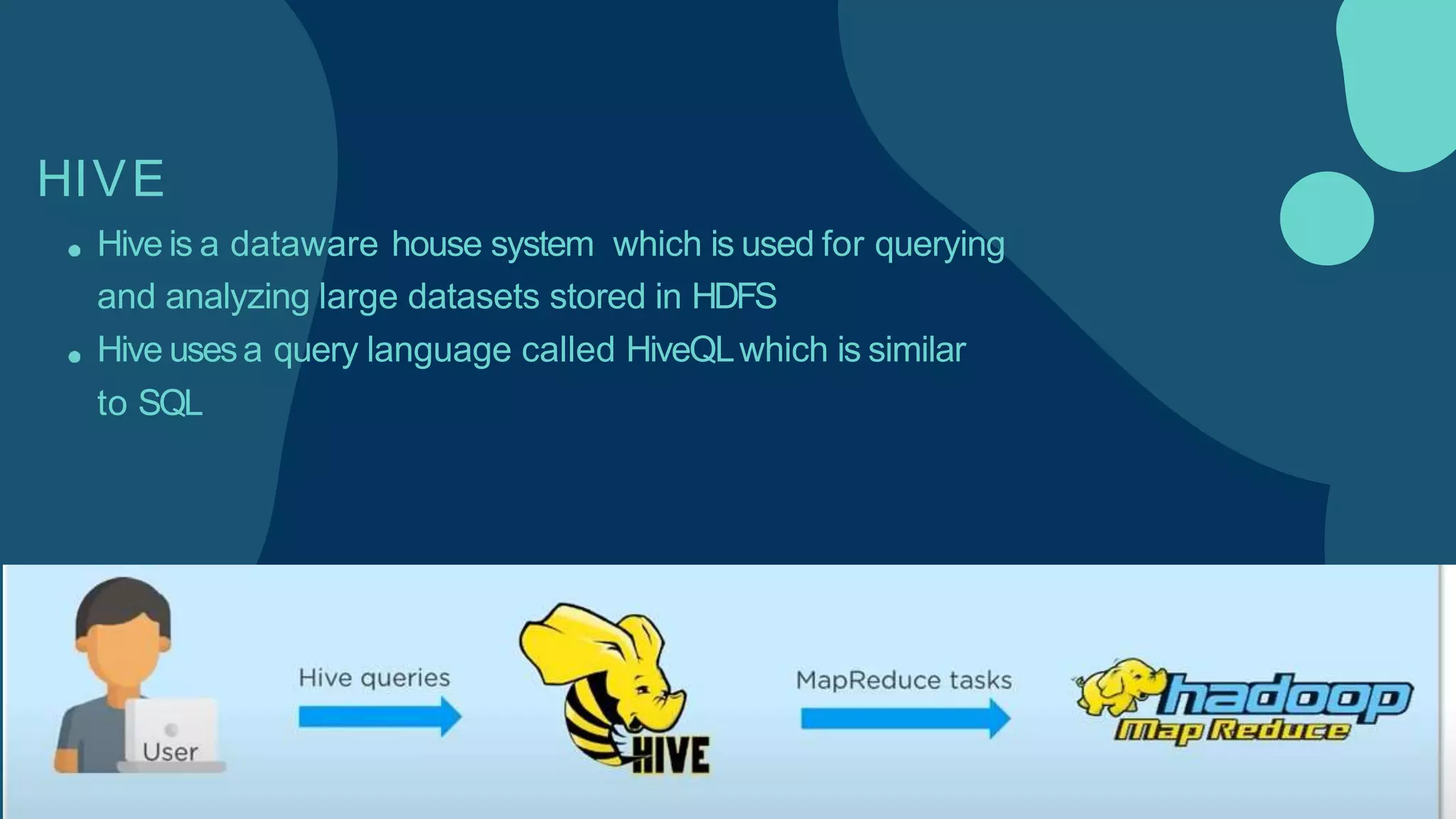
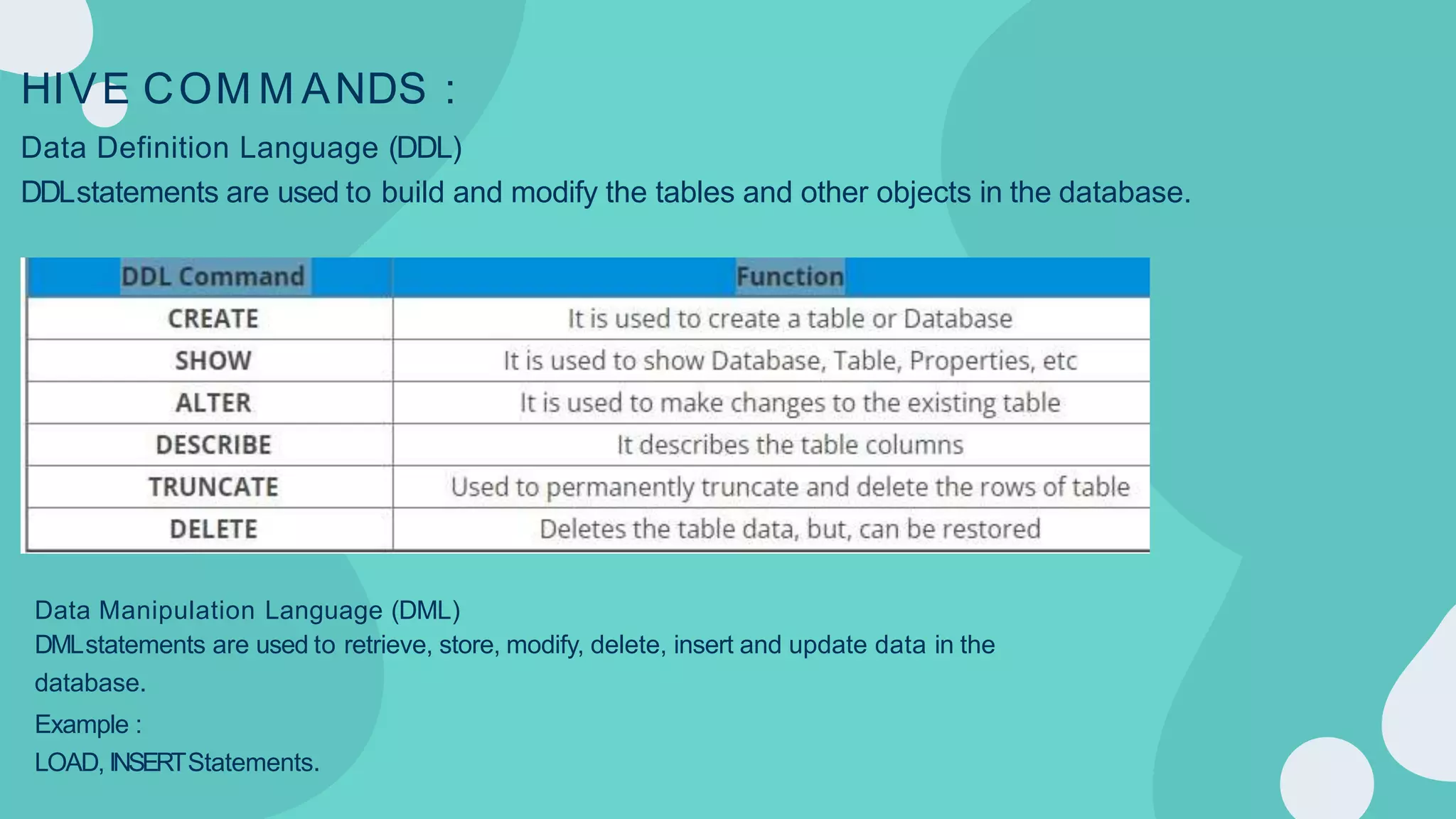
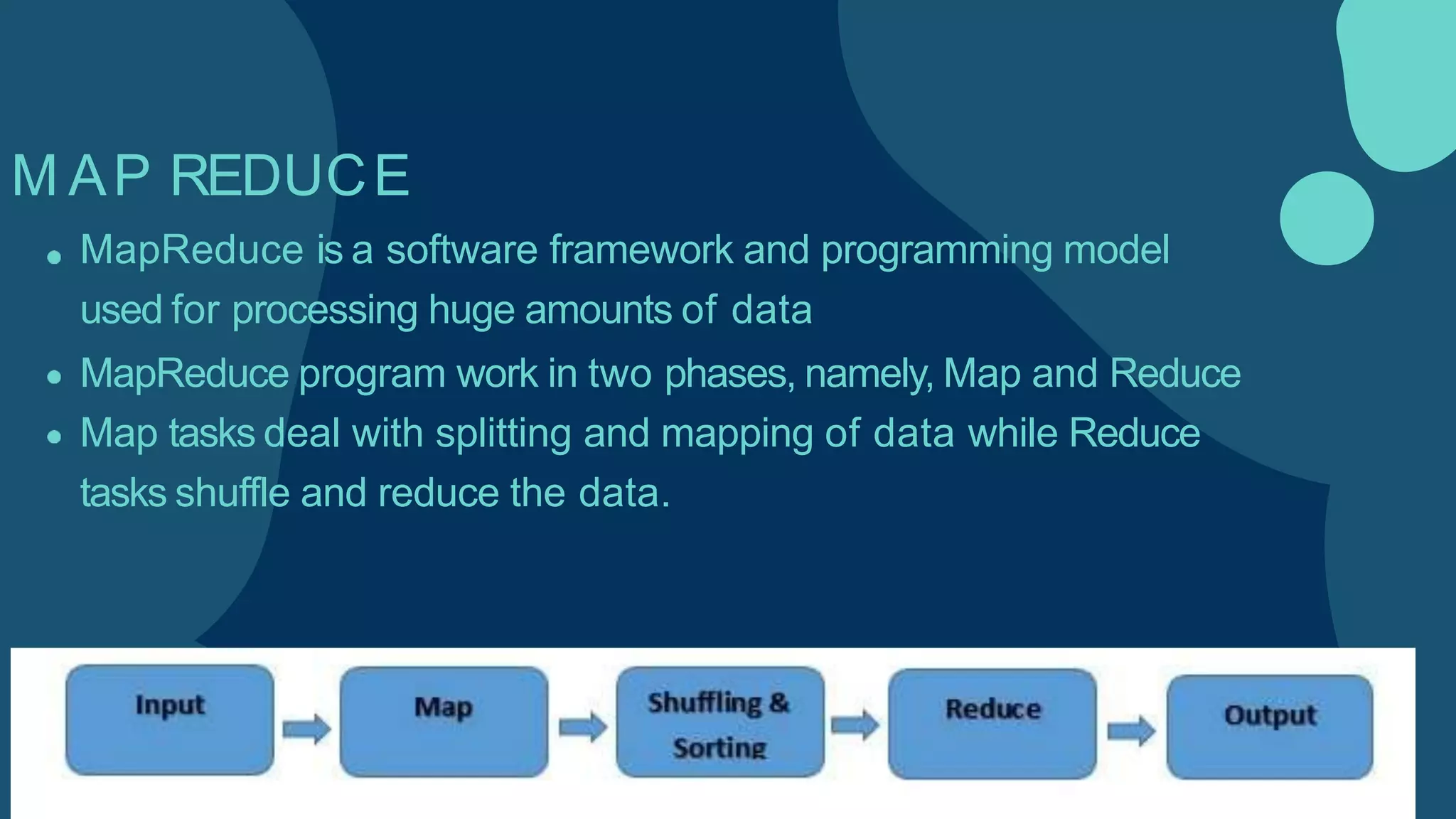













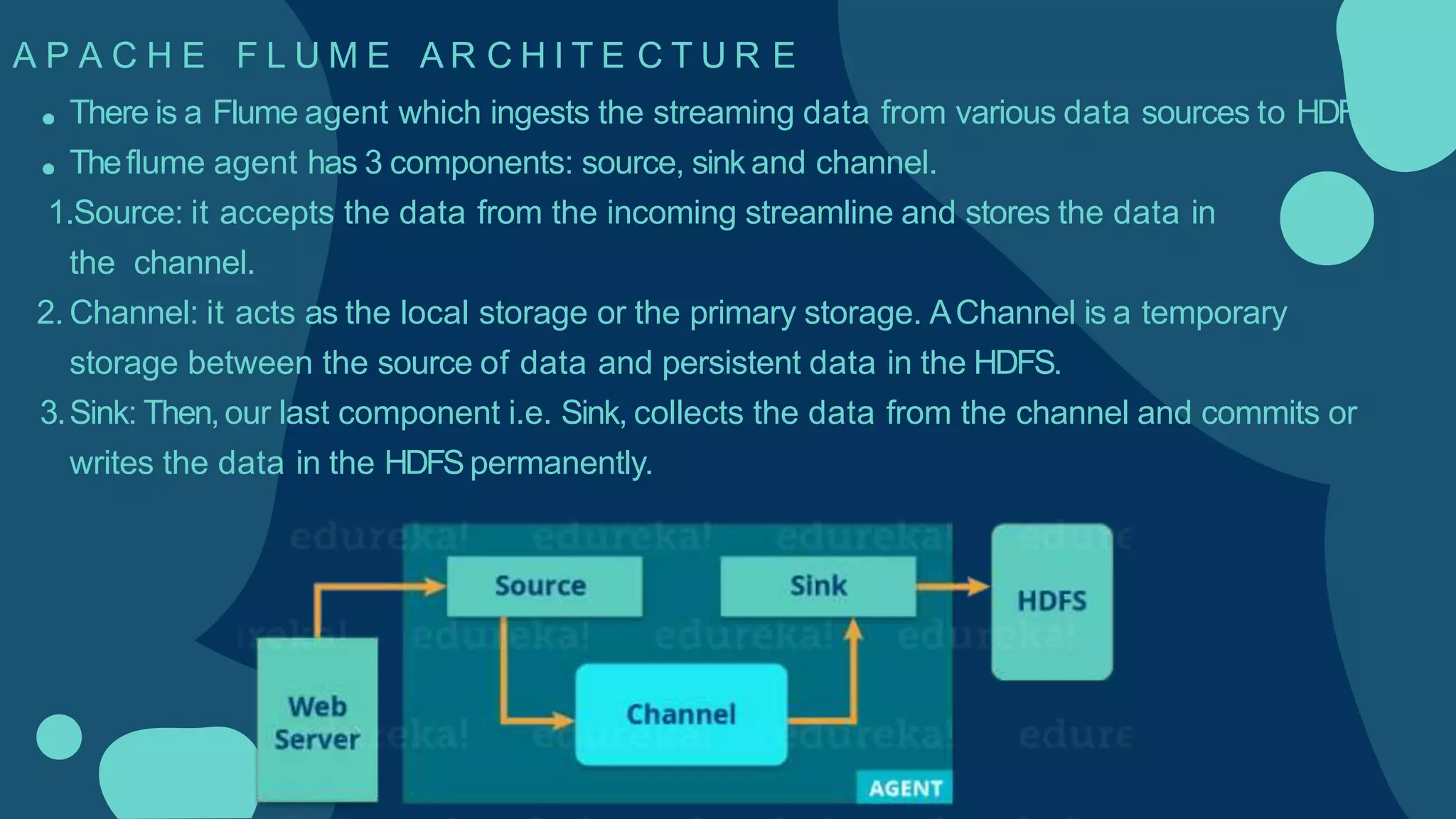

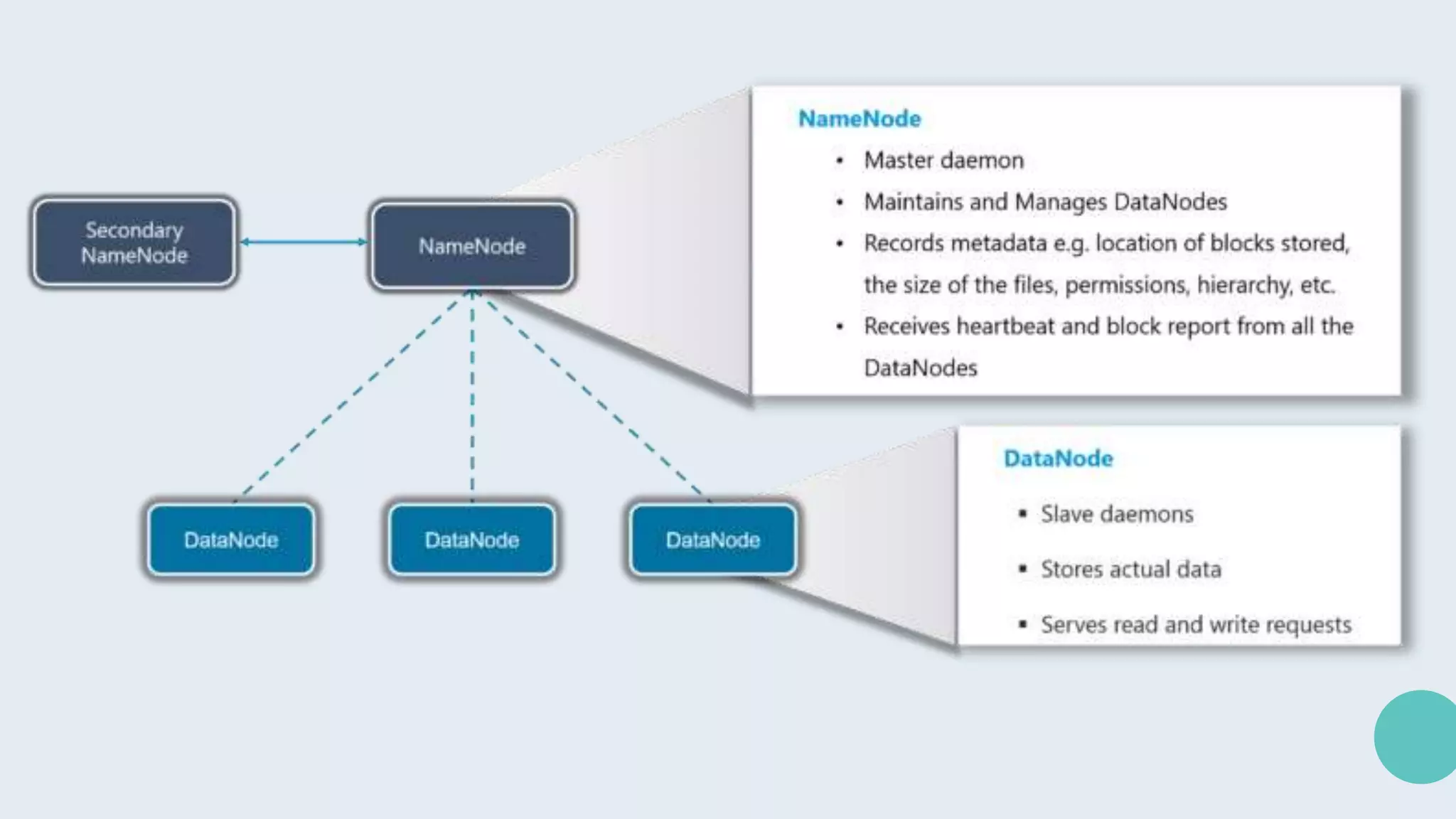
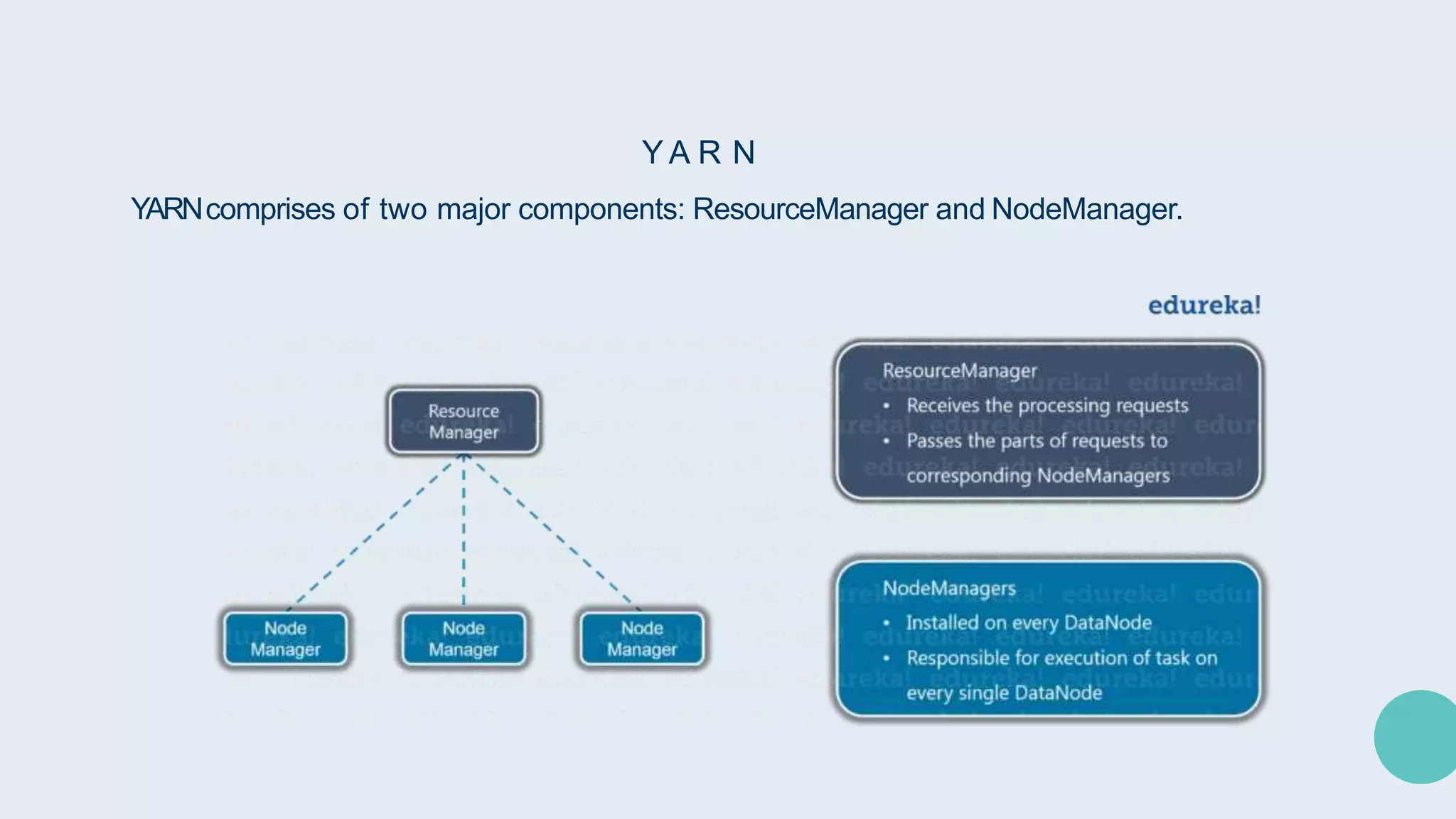


Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of computers. It allows for the reliable, scalable and distributed processing of large data sets across clusters of commodity hardware. The core of Hadoop is a storage part known as Hadoop Distributed File System (HDFS) and a processing part known as MapReduce. HDFS provides distributed storage and MapReduce enables distributed processing of large datasets in a reliable, fault-tolerant and scalable manner. Hadoop has become popular for distributed computing as it is reliable, economical and scalable to handle large and varying amounts of data.






















































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



