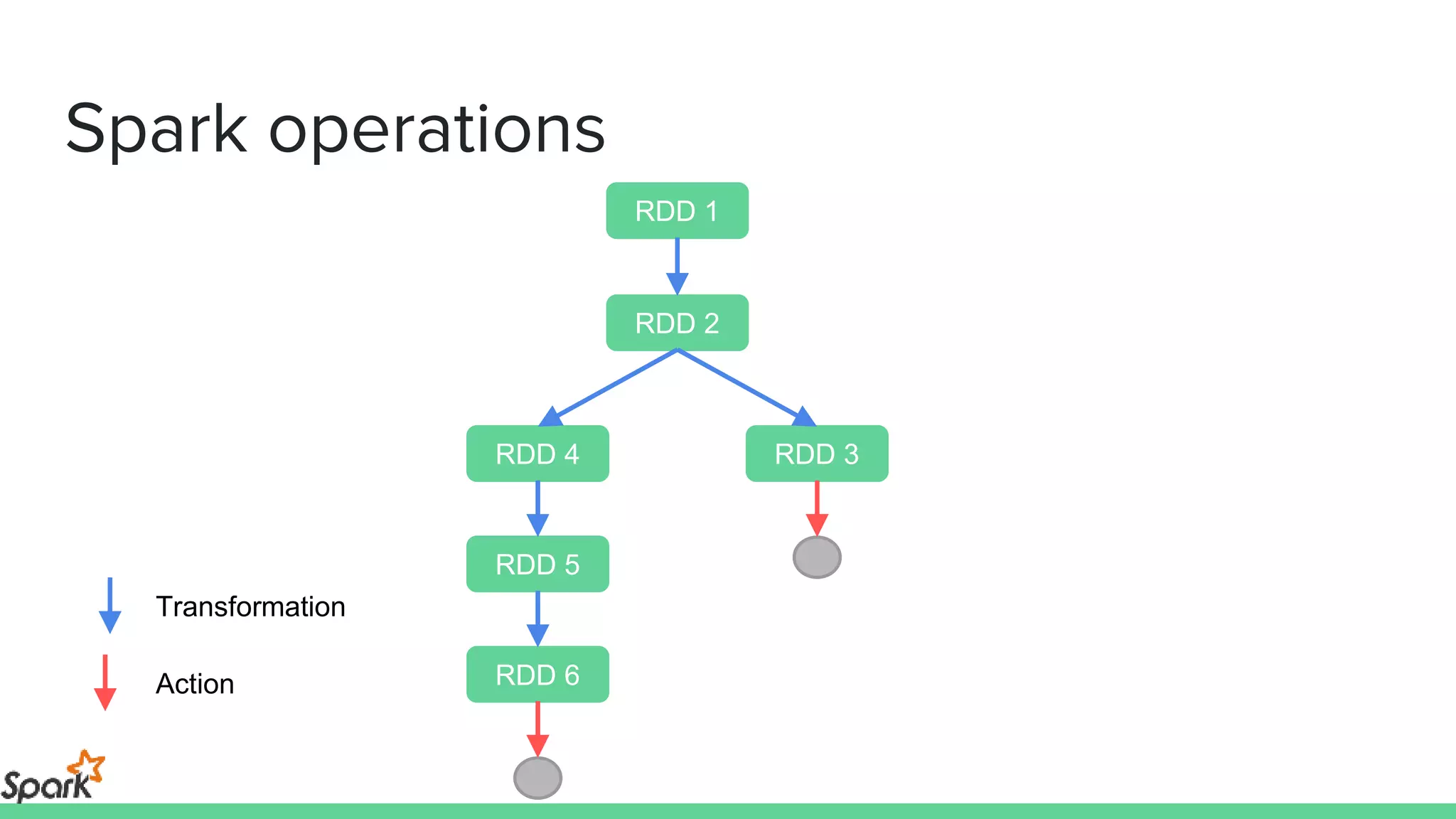
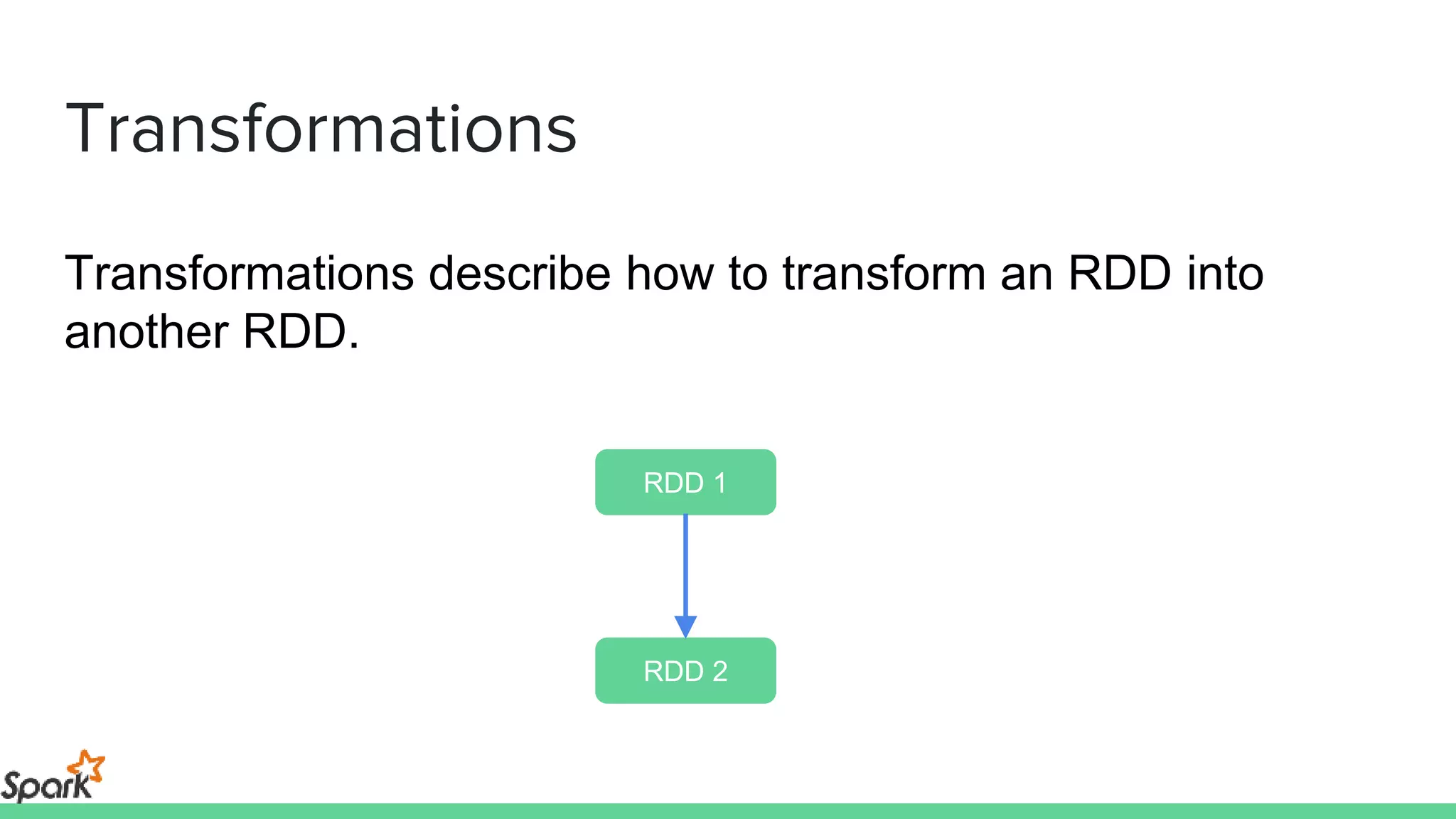
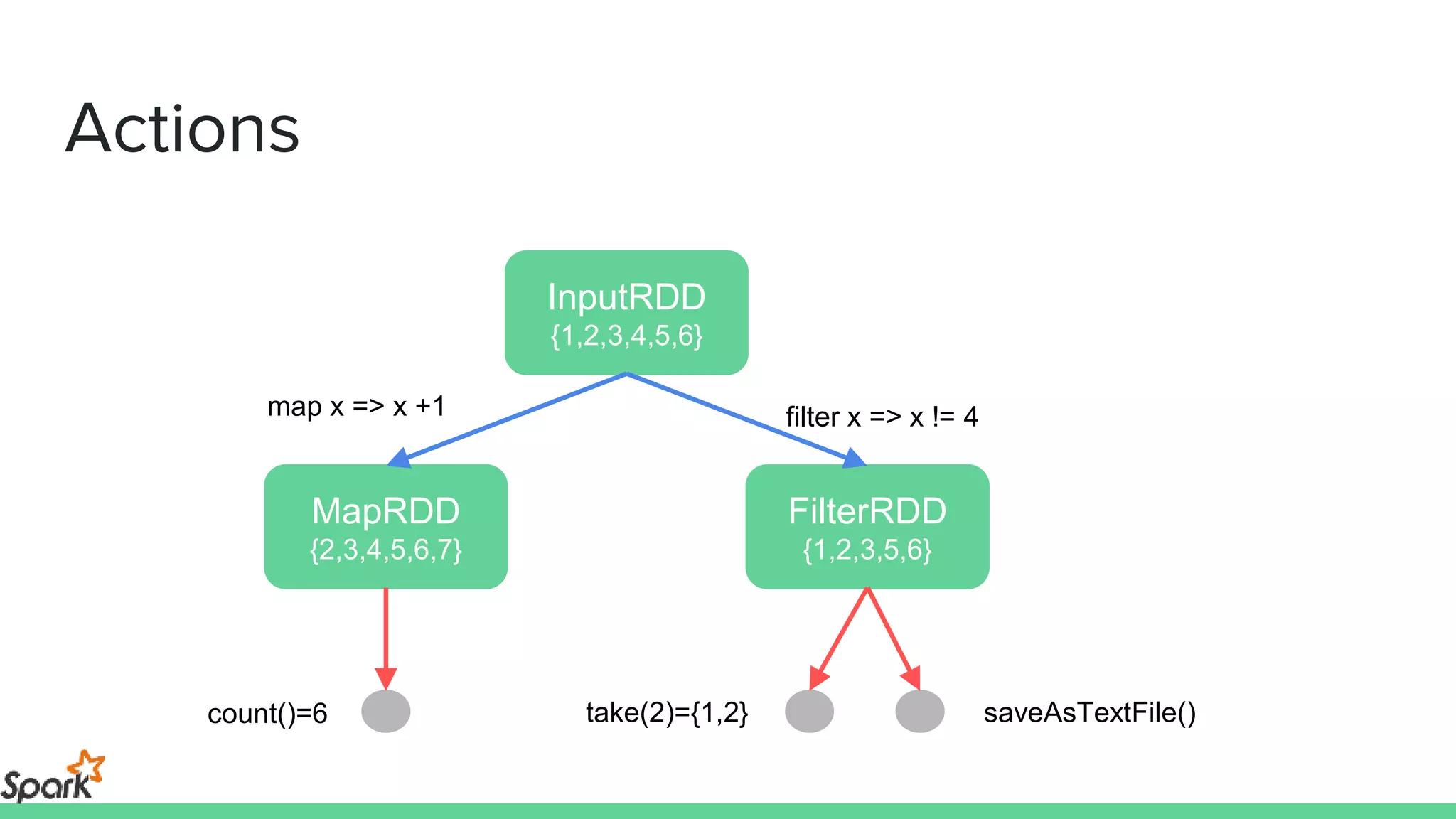
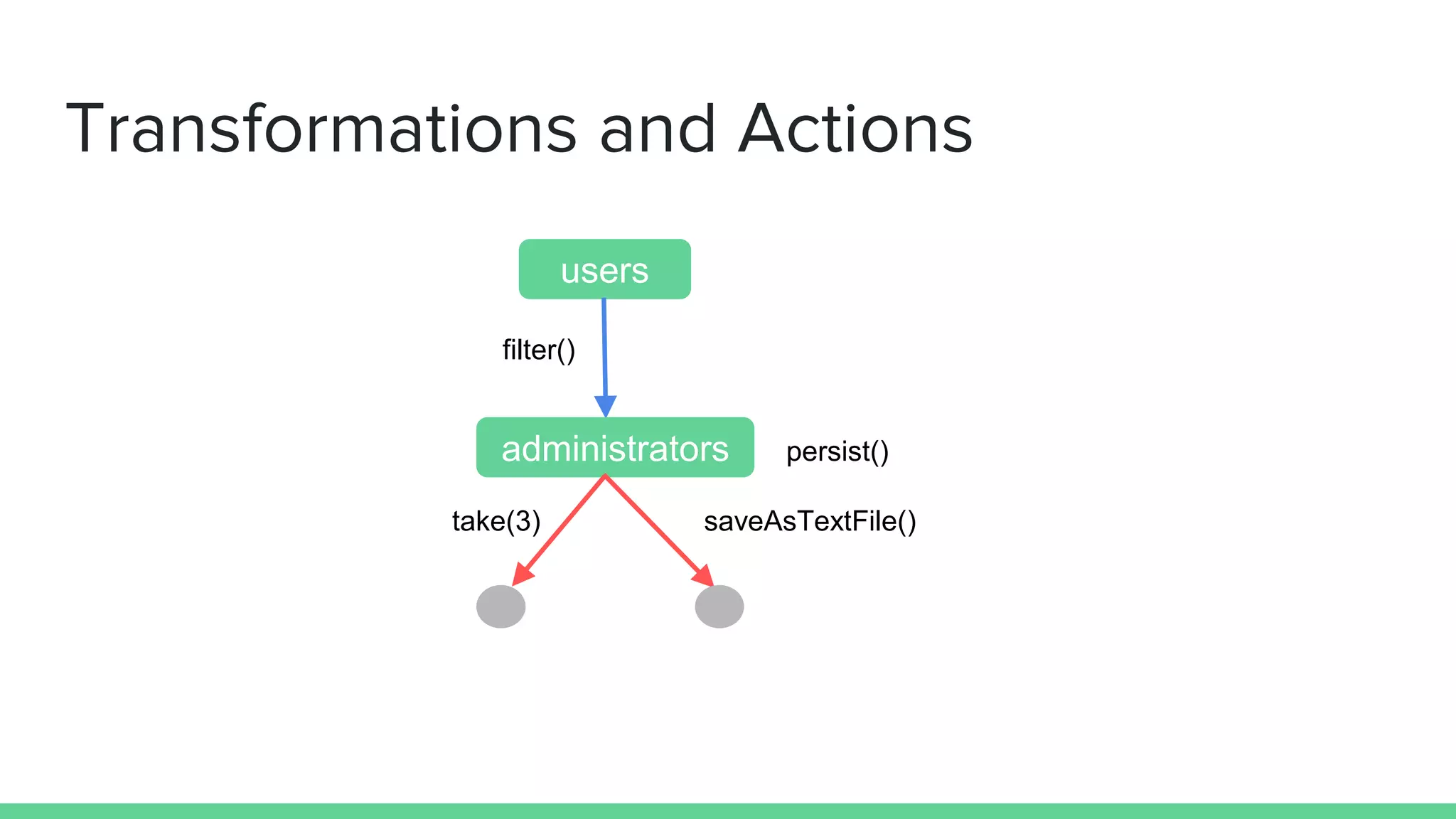
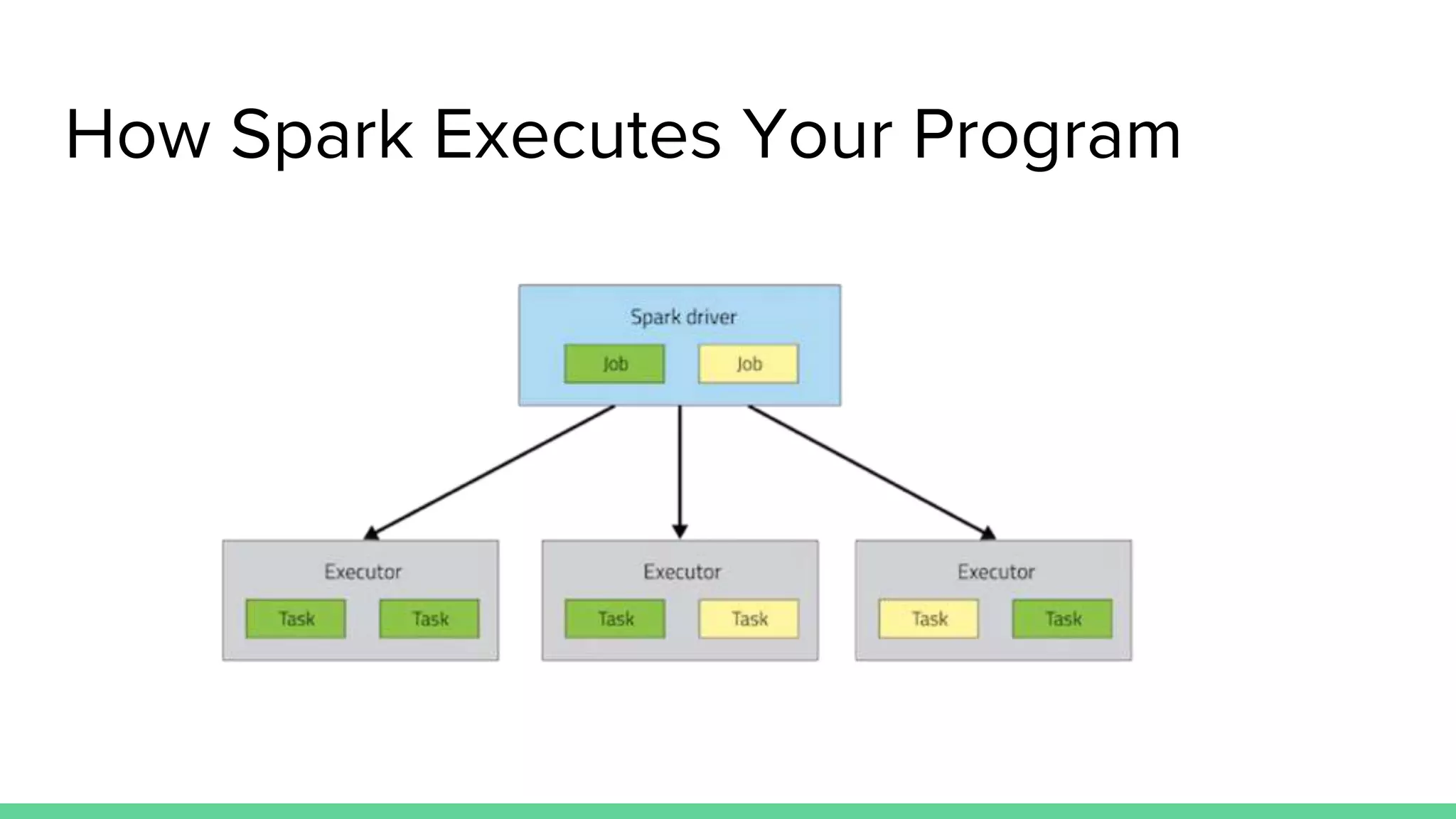
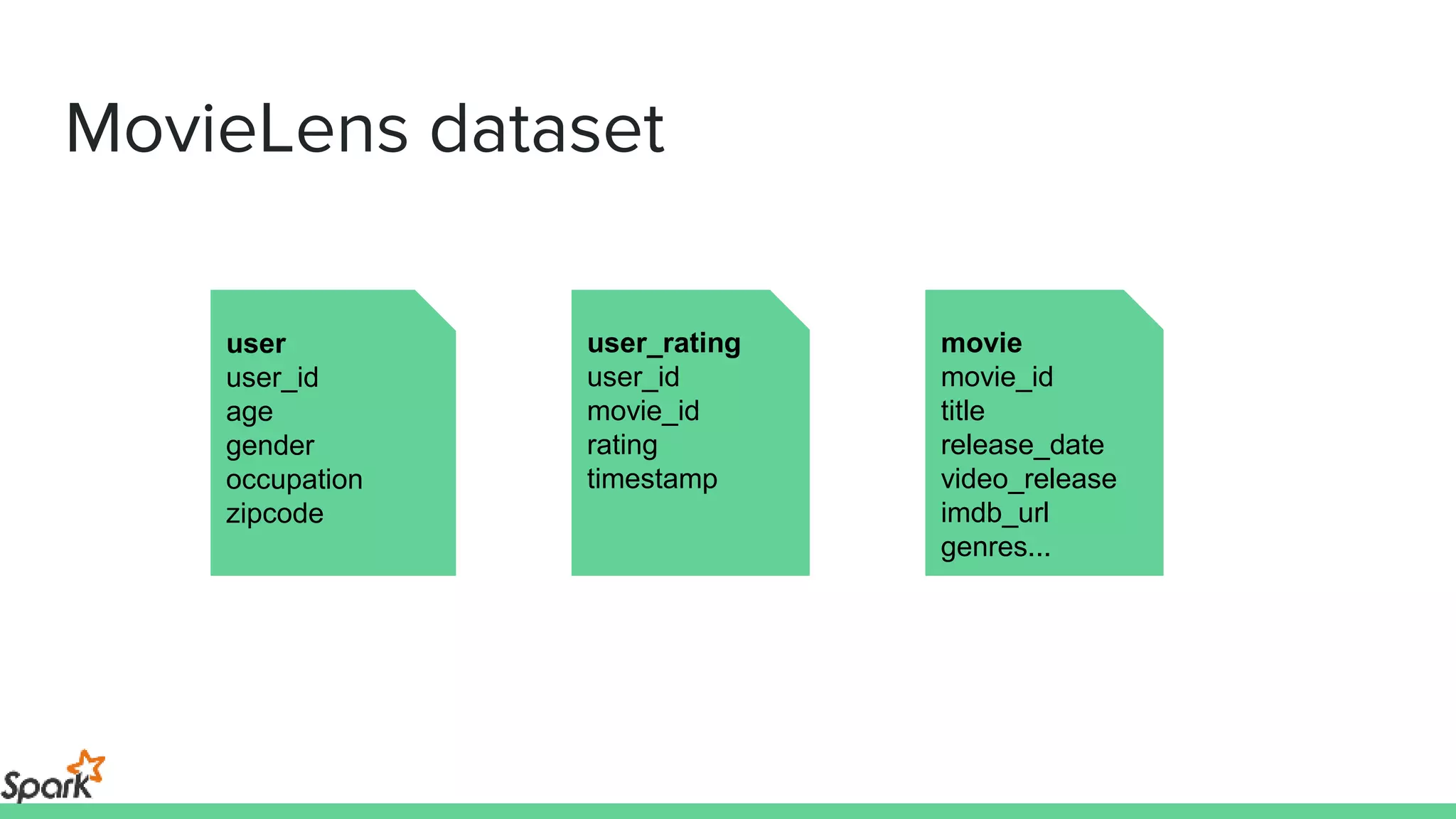
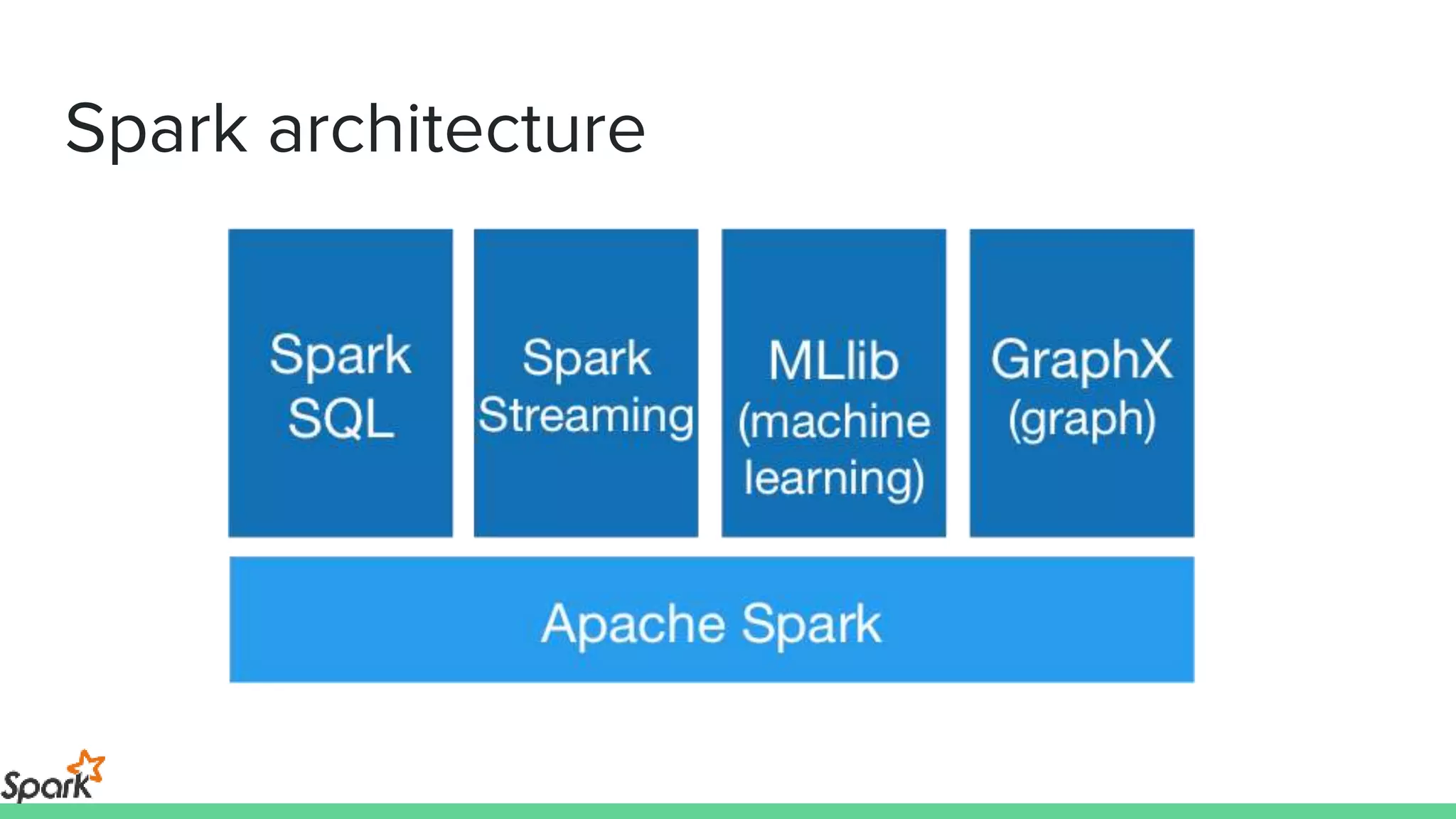
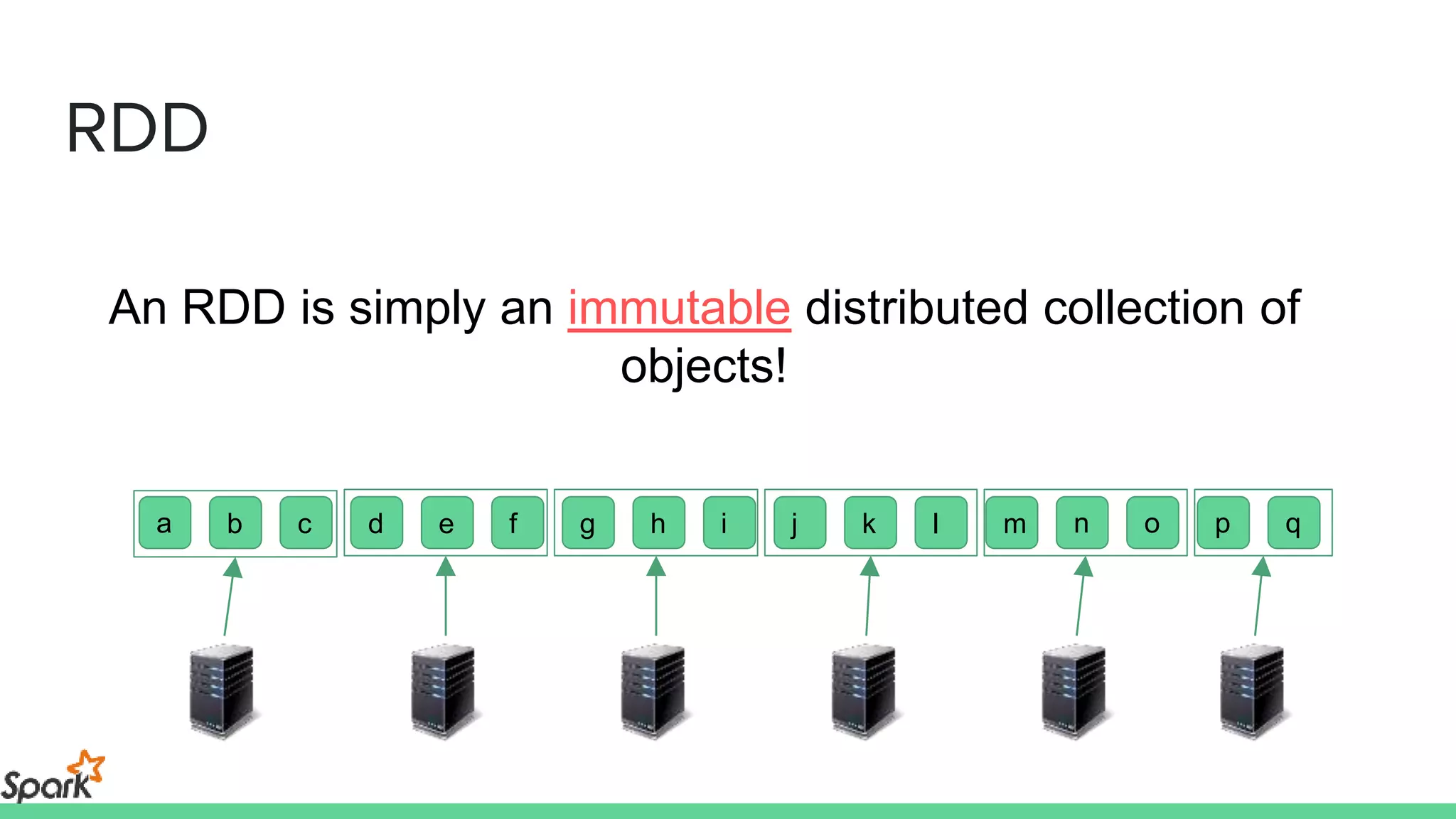
The document is an introductory workshop on Apache Spark, covering its history, architecture, and key concepts such as RDDs, transformations, and actions. It includes hands-on examples and exercises using the MovieLens dataset, demonstrating how to create RDDs and perform operations on them. Resources for further learning, as well as various deployment methods for Spark, are also mentioned.









![Creating RDD (I)
Python
lines = sc.parallelize([“workshop”, “spark”])
Scala
val lines = sc.parallelize(List(“workshop”, “spark”))
Java
JavaRDD<String> lines = sc.parallelize(Arrays.asList(“workshop”, “spark”))](https://image.slidesharecdn.com/g1swsys5arkgcgldlnkw-signature-a13204c4a85e44629d87b7e854cf1c5e2354b59452c3641288adfff2d563d781-poli-160314074815/85/Apache-spark-Intro-10-320.jpg)








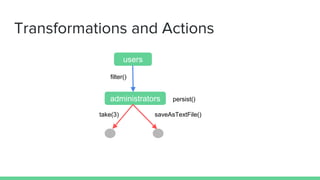
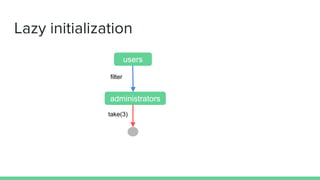













![Creating RDD (I)
Python
lines = sc.parallelize([“workshop”, “spark”])
Scala
val lines = sc.parallelize(List(“workshop”, “spark”))
Java
JavaRDD<String> lines = sc.parallelize(Arrays.asList(“workshop”, “spark”))](https://image.slidesharecdn.com/g1swsys5arkgcgldlnkw-signature-a13204c4a85e44629d87b7e854cf1c5e2354b59452c3641288adfff2d563d781-poli-160314074815/75/Apache-spark-Intro-10-2048.jpg)