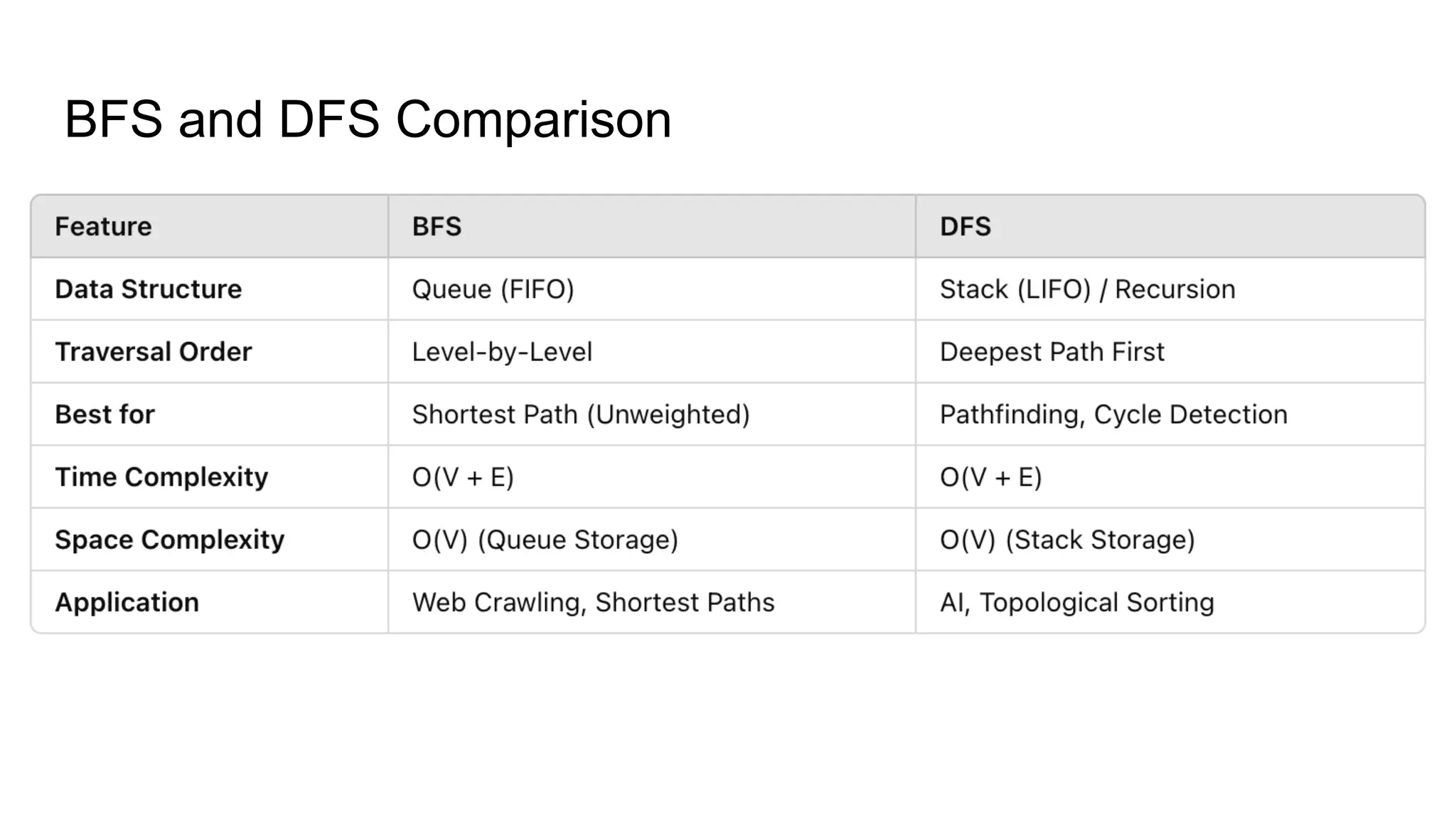
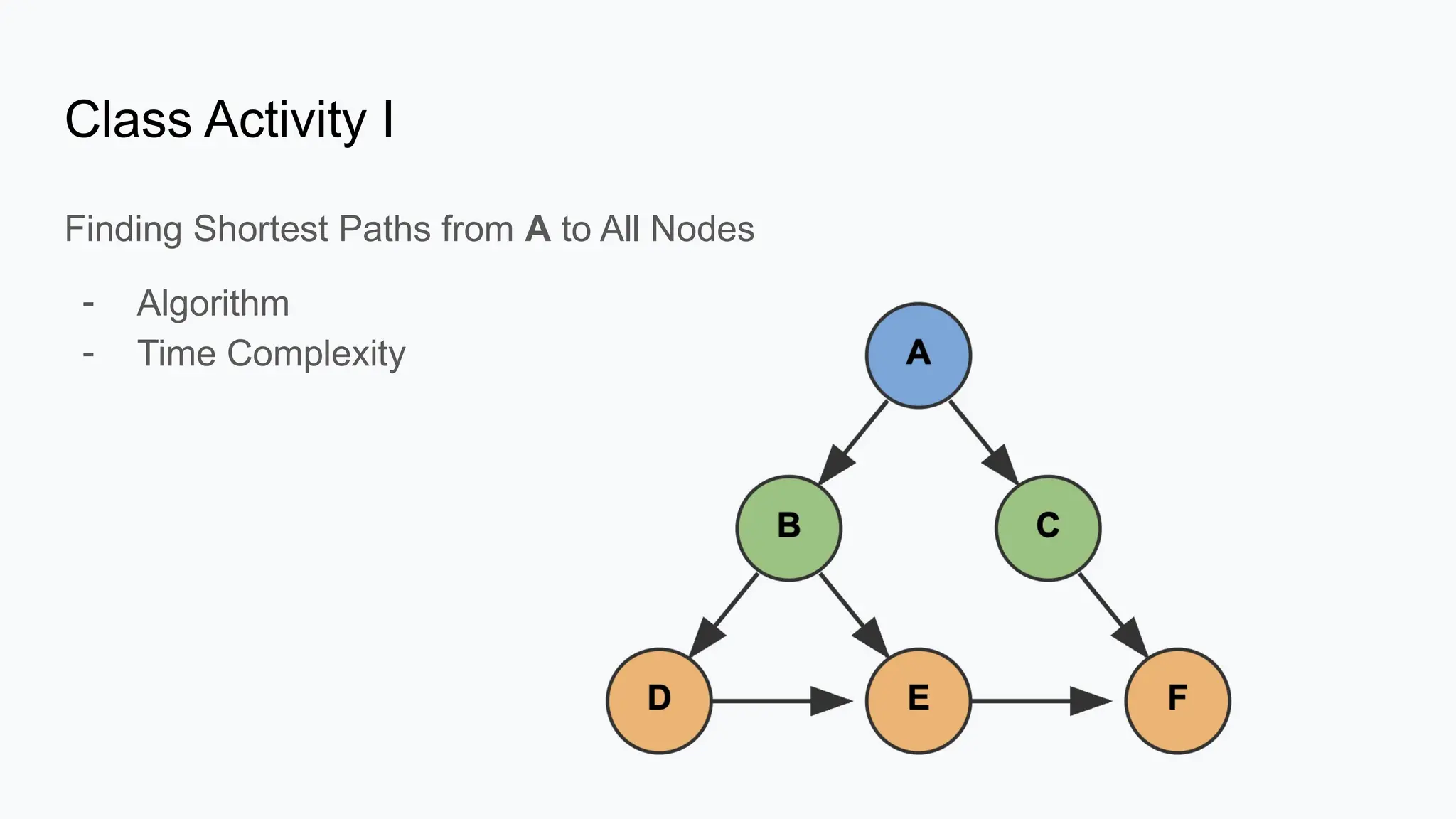
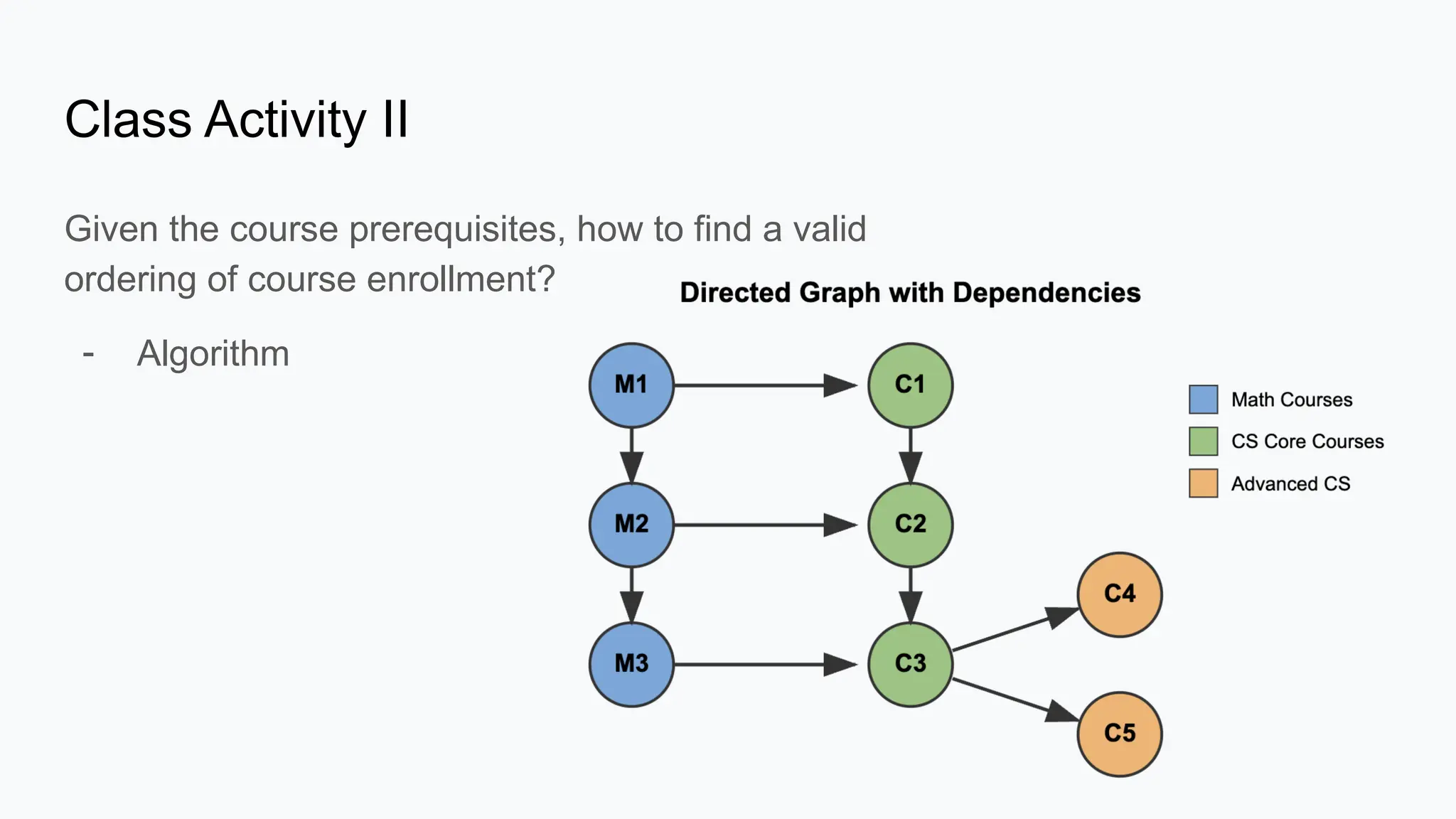
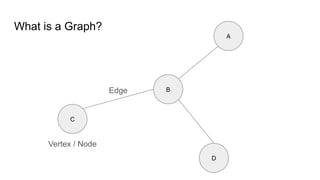
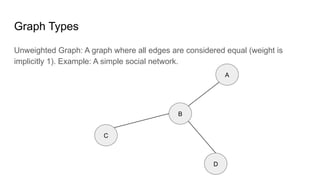
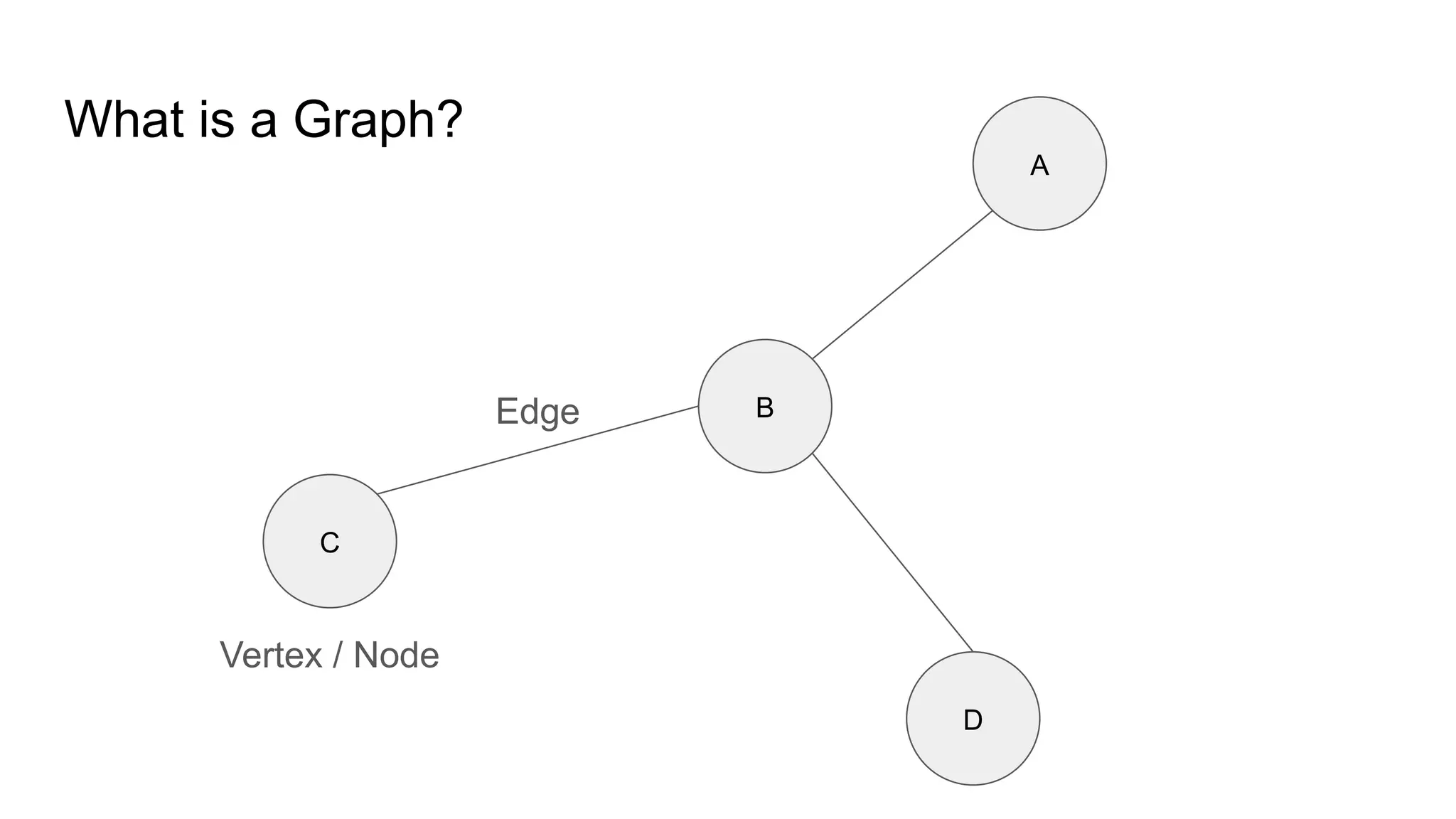
Basic Graph Algorithms Vertex (Node): A fundamental unit of a graph, representing an entity (e.g., a person in a social network, a city in a transportation network).
Edge: A connection between two vertices, representing a relationship (e.g., a friendship, a road between cities).



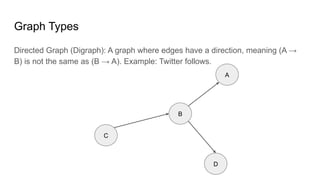
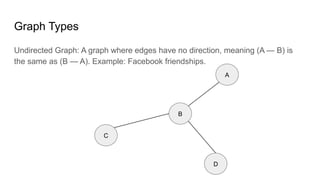


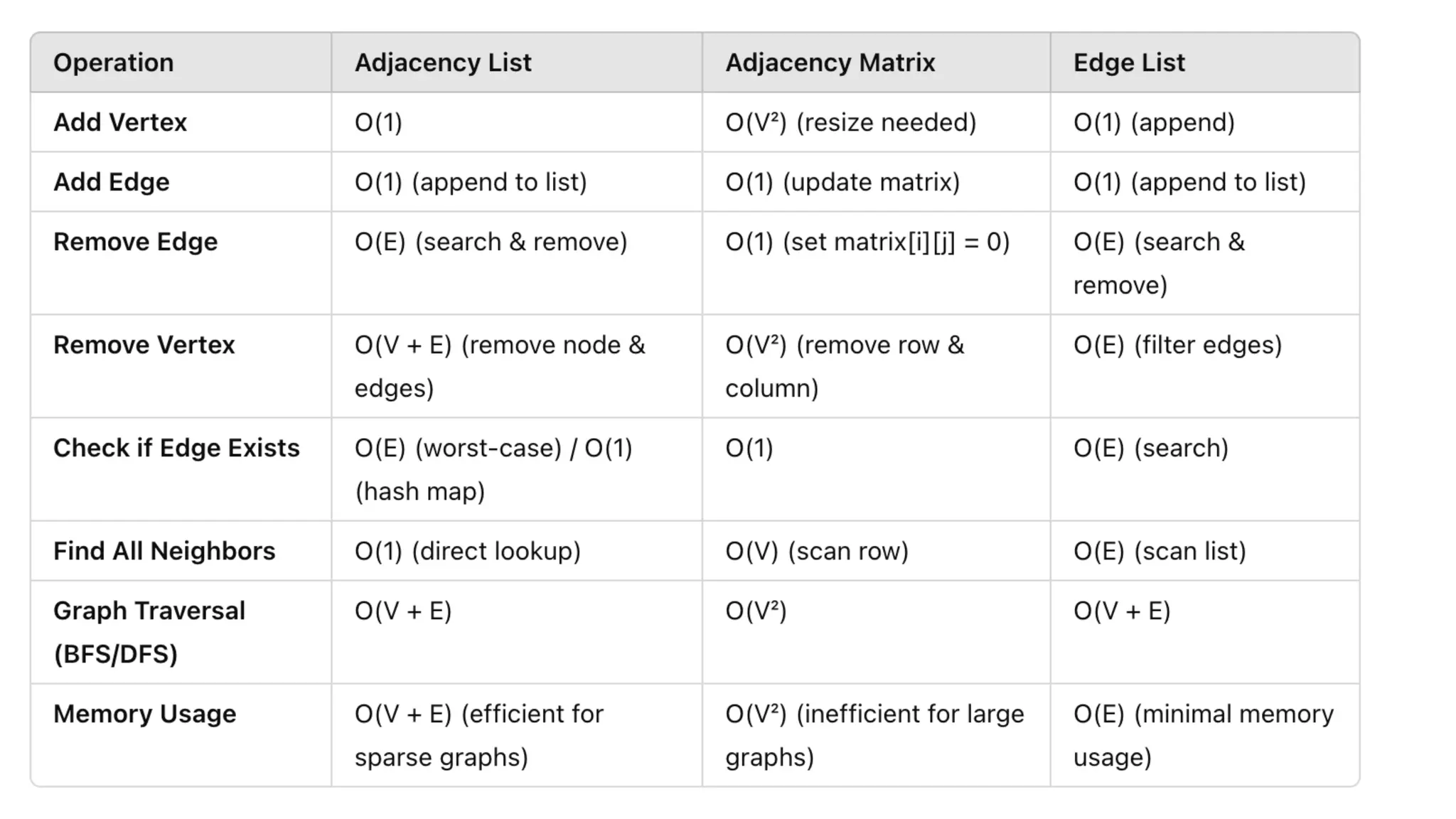
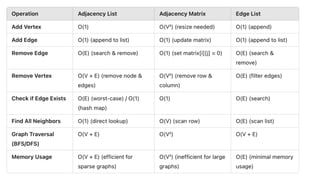
![Adjacency List: This representation stores the neighbors of each node as a list.
A — B — C
|
D E
Pros: It is efficient for sparse graphs (few edges compared to nodes). Space is O(|V|+|E|), adding edges
and vertices is O(1), fast graph traversal.
Cons: No object representing edges, slower random access query than matrices.
Representation
graph = {
"A": ["B", "D"],
"B": ["A", "C", "E"],
"C": ["B"],
"D": ["A"],
"E": ["B"]
}](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/85/Basic-Graph-Algorithms-Vertex-Node-lk-11-320.jpg)
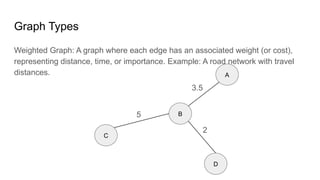
![Adjacency Matrix: A 2D matrix where matrix[i][j] = 1 if an edge exists between nodes i and j, otherwise 0.
A — B — C
|
D E
Pros: Efficient for dense graphs (many edges). Constant time for random access, and adding/removing
edges.
Cons: Takes O(|V|^2) size, and O(|V|^2) time to add/remove vertices.
Representation](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/85/Basic-Graph-Algorithms-Vertex-Node-lk-12-320.jpg)
![Edge List: A list of (node1, node2) pairs, optionally with weights.
A — B — C
|
D E
Pros: Memory efficient for sparse graphs (only stores existing edges).
Representation
[('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'E')]](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/85/Basic-Graph-Algorithms-Vertex-Node-lk-13-320.jpg)















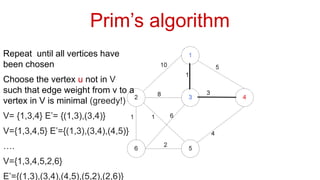
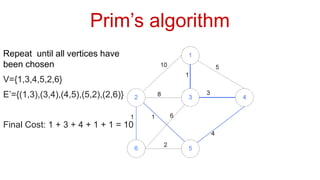



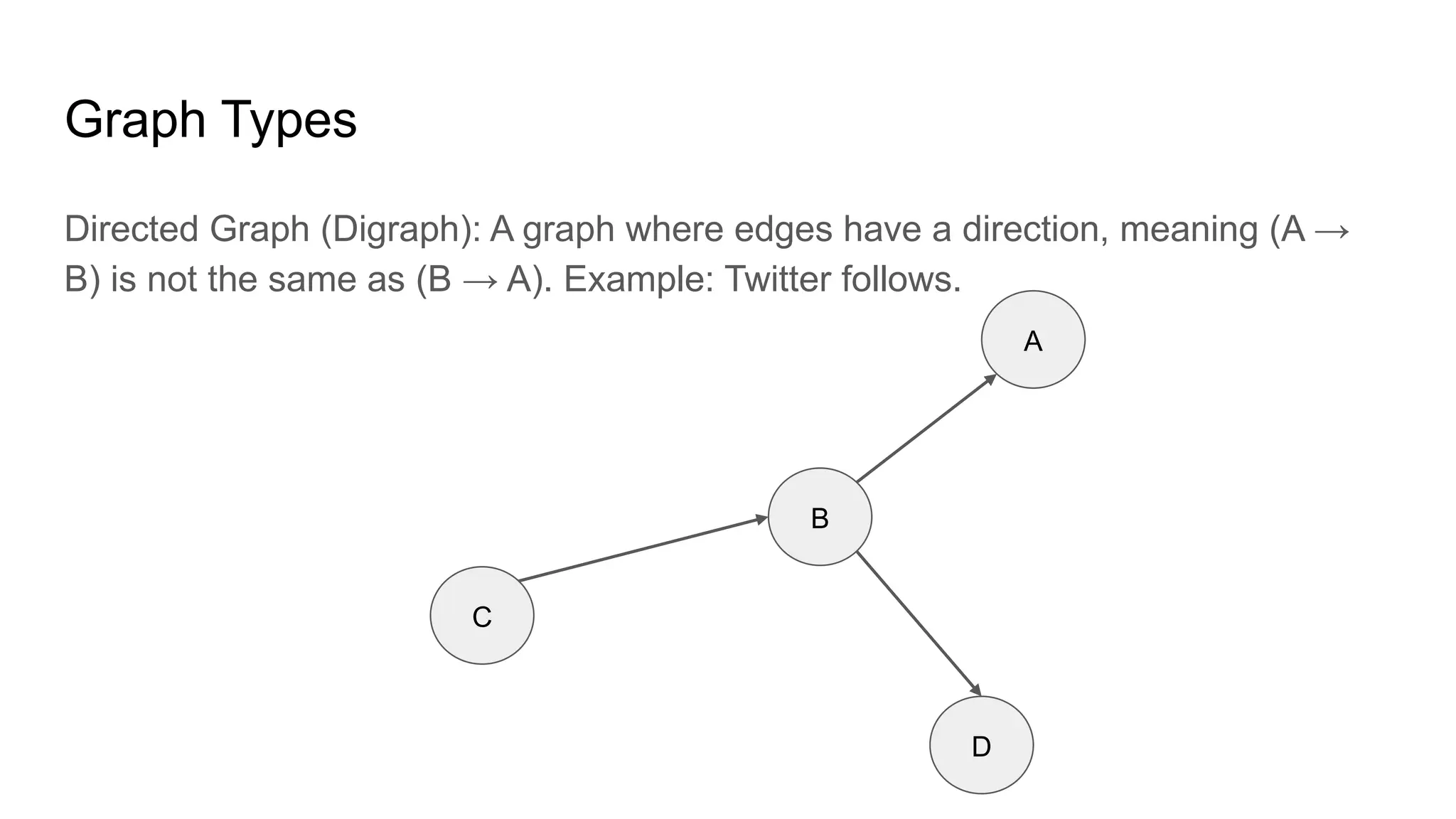
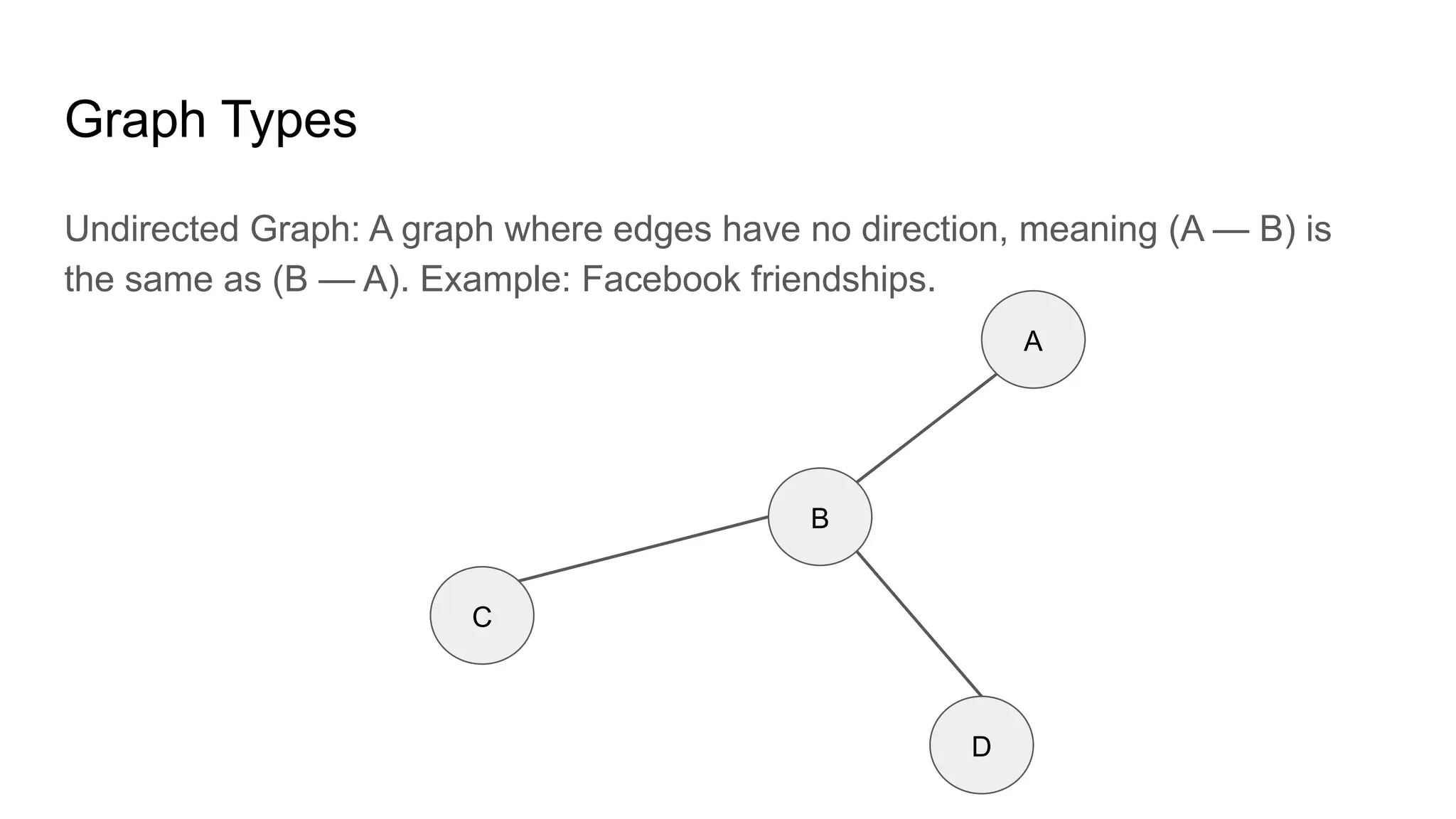
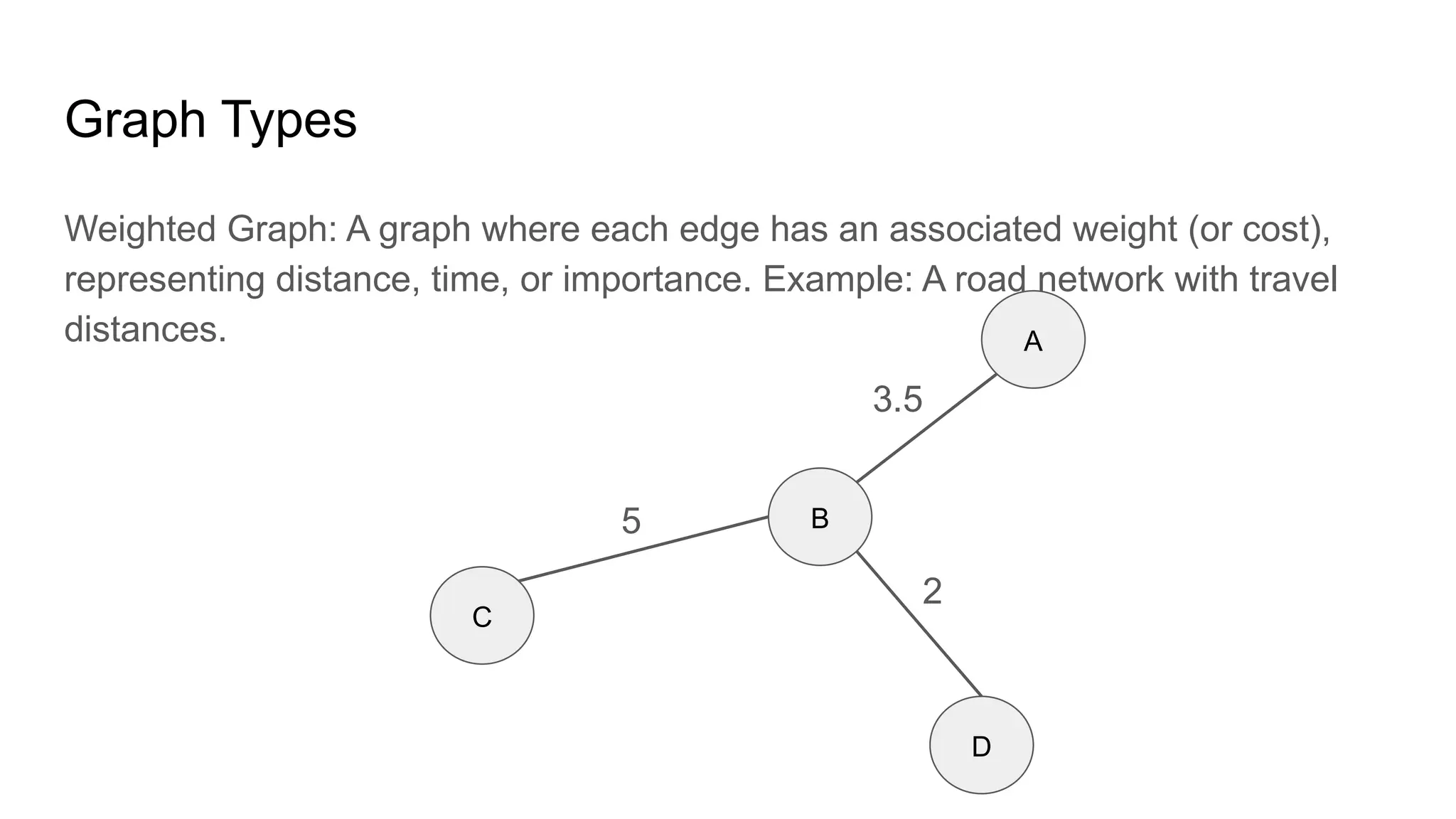
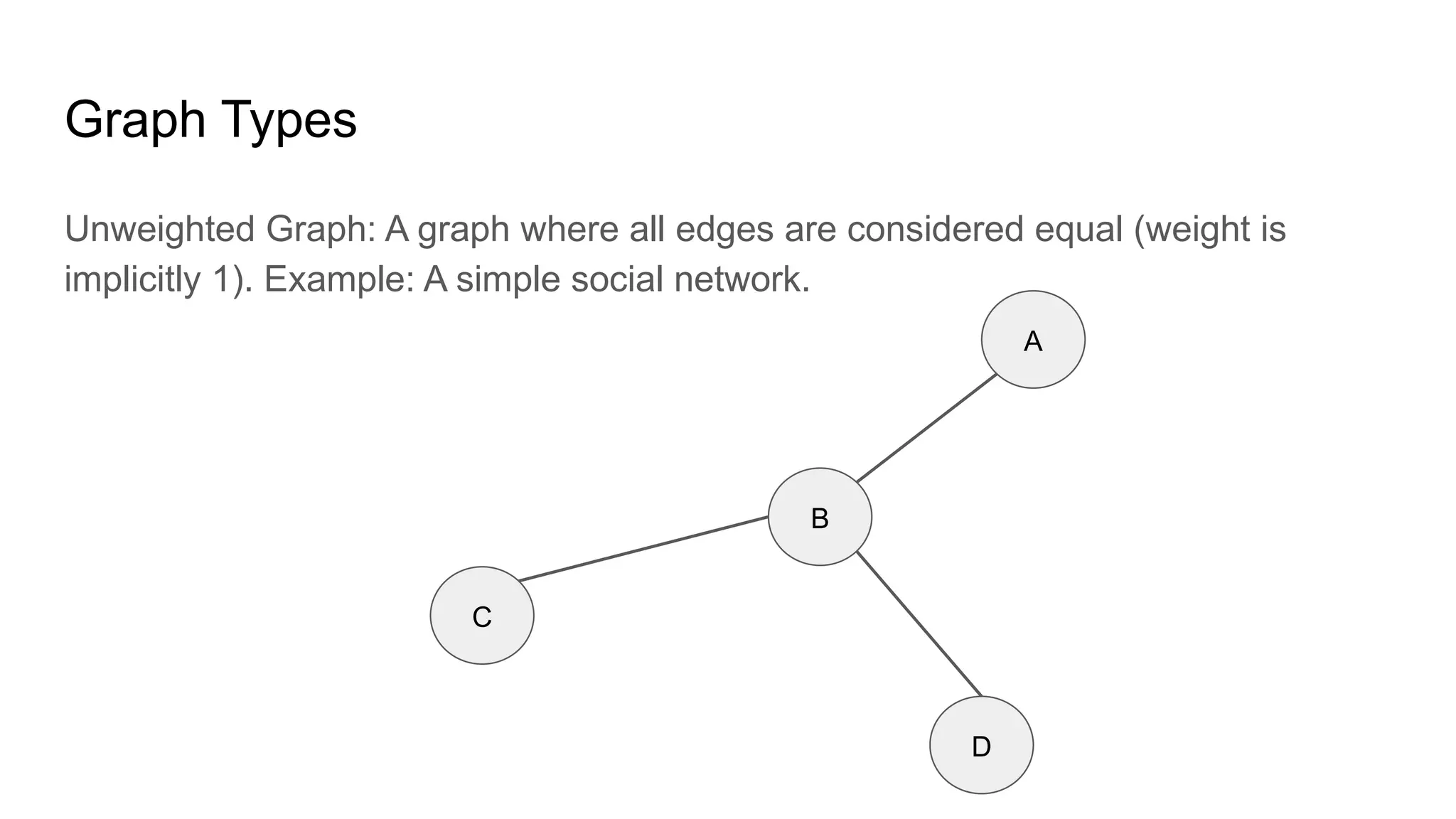


![Adjacency List: This representation stores the neighbors of each node as a list.
A — B — C
|
D E
Pros: It is efficient for sparse graphs (few edges compared to nodes). Space is O(|V|+|E|), adding edges
and vertices is O(1), fast graph traversal.
Cons: No object representing edges, slower random access query than matrices.
Representation
graph = {
"A": ["B", "D"],
"B": ["A", "C", "E"],
"C": ["B"],
"D": ["A"],
"E": ["B"]
}](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/75/Basic-Graph-Algorithms-Vertex-Node-lk-11-2048.jpg)
![Adjacency Matrix: A 2D matrix where matrix[i][j] = 1 if an edge exists between nodes i and j, otherwise 0.
A — B — C
|
D E
Pros: Efficient for dense graphs (many edges). Constant time for random access, and adding/removing
edges.
Cons: Takes O(|V|^2) size, and O(|V|^2) time to add/remove vertices.
Representation](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/75/Basic-Graph-Algorithms-Vertex-Node-lk-12-2048.jpg)
![Edge List: A list of (node1, node2) pairs, optionally with weights.
A — B — C
|
D E
Pros: Memory efficient for sparse graphs (only stores existing edges).
Representation
[('A', 'B'), ('A', 'D'), ('B', 'C'), ('B', 'E')]](https://image.slidesharecdn.com/basicgraphalgorithms1-250525195020-106d810d/75/Basic-Graph-Algorithms-Vertex-Node-lk-13-2048.jpg)