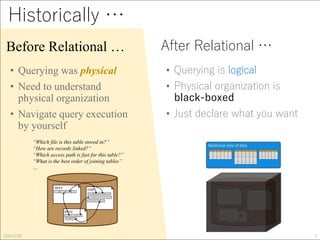
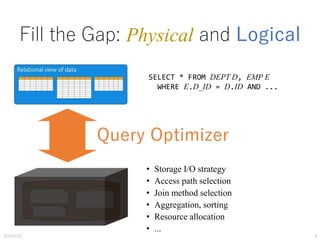
Download as PDF, PPTX









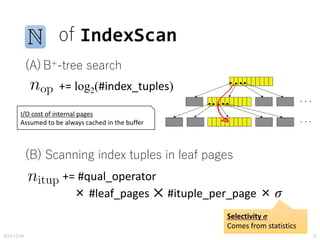
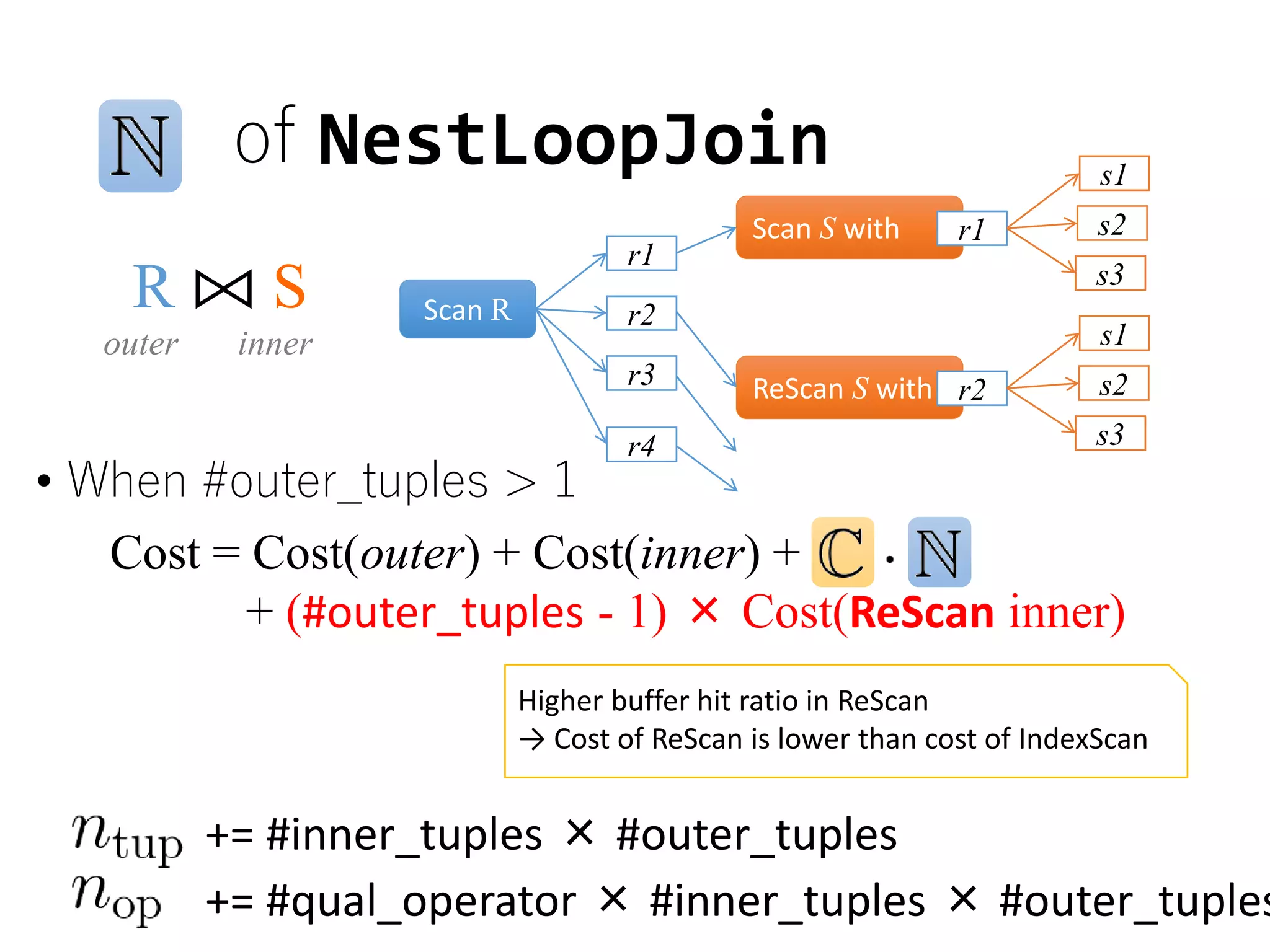
![Cost/Cardinality Estimation
• [#page fetched],[#storage API calls]
are estimated with cost formula and following
statistics
2016/5/20 12
CPU costI/O cost
COST = [#page fetched] + W * [#storage API calls]
weight parameter
• NCARD(T) ... the cardinality of relation T
• TCARD(T) ... the number of pages in relation T
• ICARD(I) ... the number of distinct keys in index I
• NINDX(I) ... the number of pages in index I](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-12-320.jpg)

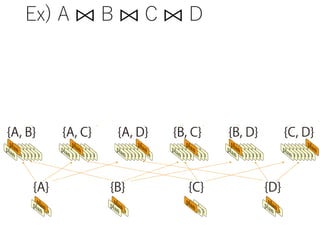
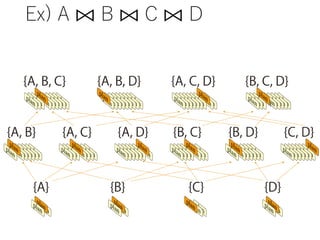
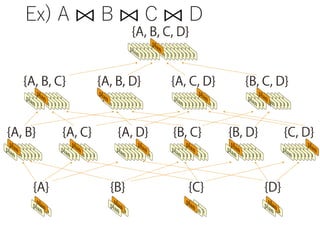


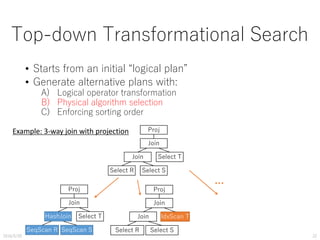














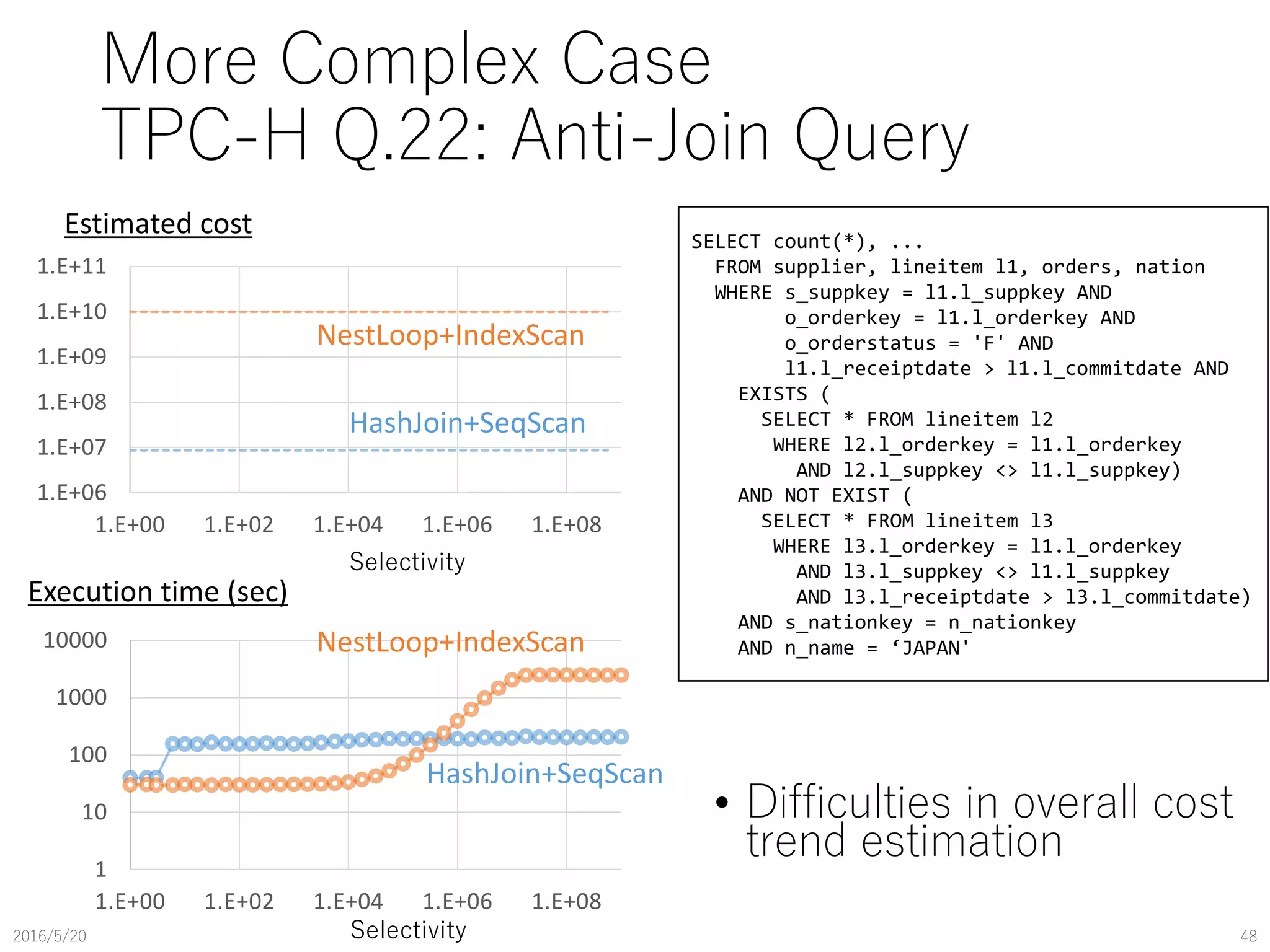
![TPC-H Q.1: The Simplest Case
2016/5/20 45
5.E+05
5.E+06
5.E+07
5.E+08
1 10 100 1000
Estimated cost
Selectivity (l_shipdate)
IndexScan
SeqScan
10
100
1000
10000
1 10 100 1000
Execution time (sec)
Selectivity(l_shipdate)
IndexScan
SeqScan
• Good trend estimation for each
method
• Estimated break-event point is
errorneus
• IndexScan should be more
expensive (need parameter
calibration)
SELECT count(*), ... FROM lineitem
WHERE l_shipdate BETWEEN [X] AND [Y]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-45-320.jpg)
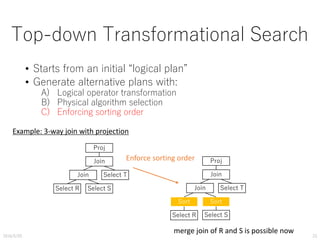
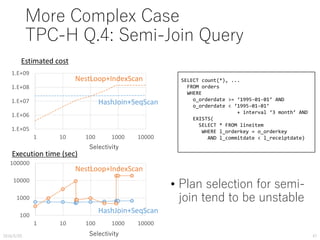
![TPC-H Q.3
2016/5/20 46
Estimated cost
SeqScan
customer
SeqScan
orders
SeqScan
lineitem
Hash
HashJoin
HashJoin
IndexScan
orders
IndexScan
lineitem
NestLoop
NestLoop
IndexScan
customer
Execution time (sec)
Selectivity
1.E+00
1.E+02
1.E+04
1.E+06
1.E+08
1 10 100 1000 10000 100000 1000000
1
10
100
1000
10000
1 10 100 1000 10000 100000 1000000
Selectivity
NestLoop+IndexScan
HashJoin+SeqScan
NestLoop+IndexScan
HashJoin+SeqScan Similar result as in Q.1
• Good trend estimation for each
• Erroneous break-event point
without parameter calibration
SELECT count(*), ...
FROM customer, orders, lineitem
WHERE c_custkey = o_custkey AND
o_orderkey = l_orderkey AND
c_custkey < [X] AND
c_mktsegment = ‘MACHINERY’;](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-46-320.jpg)


![Mid-query Re-optimization
• Detects sub-optimality of executing query plan
• Query plans are annotated for later estimation
improvement
• Runtime statistics collection
• Statistics collector probes are inserted into operators of
executing query plan
• Plan modification strategy
• Discard current execution and re-optimize whole plan
• Re-optimizer only subtree of the plan that are not
started yet
• Save partial execution result and generate new SQL
using the result
2016/5/20 52
[N. Kabra et.al., SIGMOD’98]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-52-320.jpg)
![Plan Bouquet
• Generate a set of plans for each selectivity range
• Estimation improvement with runtime statistics
collection
• Evaluation with PostgreSQL
2016/5/20 53
[A. Dutt et.al., SIGMOD’14]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-53-320.jpg)
![Bounding Impact of Estimation Error
• “Uncertainty” analysis of cost estimation
• Optimality sensitivity to estimation error
• Execute partially to reduce uncertainty
2016/5/20 54
[T. Neumann et.al., BTW Conf ‘13]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/85/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-54-320.jpg)











![Cost/Cardinality Estimation
• [#page fetched],[#storage API calls]
are estimated with cost formula and following
statistics
2016/5/20 12
CPU costI/O cost
COST = [#page fetched] + W * [#storage API calls]
weight parameter
• NCARD(T) ... the cardinality of relation T
• TCARD(T) ... the number of pages in relation T
• ICARD(I) ... the number of distinct keys in index I
• NINDX(I) ... the number of pages in index I](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-12-2048.jpg)
















![TPC-H Q.1: The Simplest Case
2016/5/20 45
5.E+05
5.E+06
5.E+07
5.E+08
1 10 100 1000
Estimated cost
Selectivity (l_shipdate)
IndexScan
SeqScan
10
100
1000
10000
1 10 100 1000
Execution time (sec)
Selectivity(l_shipdate)
IndexScan
SeqScan
• Good trend estimation for each
method
• Estimated break-event point is
errorneus
• IndexScan should be more
expensive (need parameter
calibration)
SELECT count(*), ... FROM lineitem
WHERE l_shipdate BETWEEN [X] AND [Y]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-45-2048.jpg)
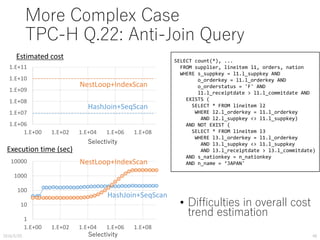
![TPC-H Q.3
2016/5/20 46
Estimated cost
SeqScan
customer
SeqScan
orders
SeqScan
lineitem
Hash
HashJoin
HashJoin
IndexScan
orders
IndexScan
lineitem
NestLoop
NestLoop
IndexScan
customer
Execution time (sec)
Selectivity
1.E+00
1.E+02
1.E+04
1.E+06
1.E+08
1 10 100 1000 10000 100000 1000000
1
10
100
1000
10000
1 10 100 1000 10000 100000 1000000
Selectivity
NestLoop+IndexScan
HashJoin+SeqScan
NestLoop+IndexScan
HashJoin+SeqScan Similar result as in Q.1
• Good trend estimation for each
• Erroneous break-event point
without parameter calibration
SELECT count(*), ...
FROM customer, orders, lineitem
WHERE c_custkey = o_custkey AND
o_orderkey = l_orderkey AND
c_custkey < [X] AND
c_mktsegment = ‘MACHINERY’;](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-46-2048.jpg)



![Mid-query Re-optimization
• Detects sub-optimality of executing query plan
• Query plans are annotated for later estimation
improvement
• Runtime statistics collection
• Statistics collector probes are inserted into operators of
executing query plan
• Plan modification strategy
• Discard current execution and re-optimize whole plan
• Re-optimizer only subtree of the plan that are not
started yet
• Save partial execution result and generate new SQL
using the result
2016/5/20 52
[N. Kabra et.al., SIGMOD’98]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-52-2048.jpg)
![Plan Bouquet
• Generate a set of plans for each selectivity range
• Estimation improvement with runtime statistics
collection
• Evaluation with PostgreSQL
2016/5/20 53
[A. Dutt et.al., SIGMOD’14]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-53-2048.jpg)
![Bounding Impact of Estimation Error
• “Uncertainty” analysis of cost estimation
• Optimality sensitivity to estimation error
• Execute partially to reduce uncertainty
2016/5/20 54
[T. Neumann et.al., BTW Conf ‘13]](https://image.slidesharecdn.com/pgcon2016beyondexplain-160527105225/75/Beyond-EXPLAIN-Query-Optimization-From-Theory-To-Code-54-2048.jpg)



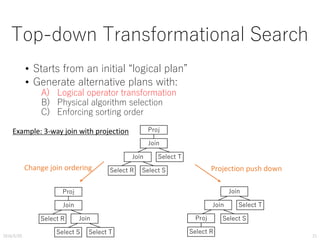
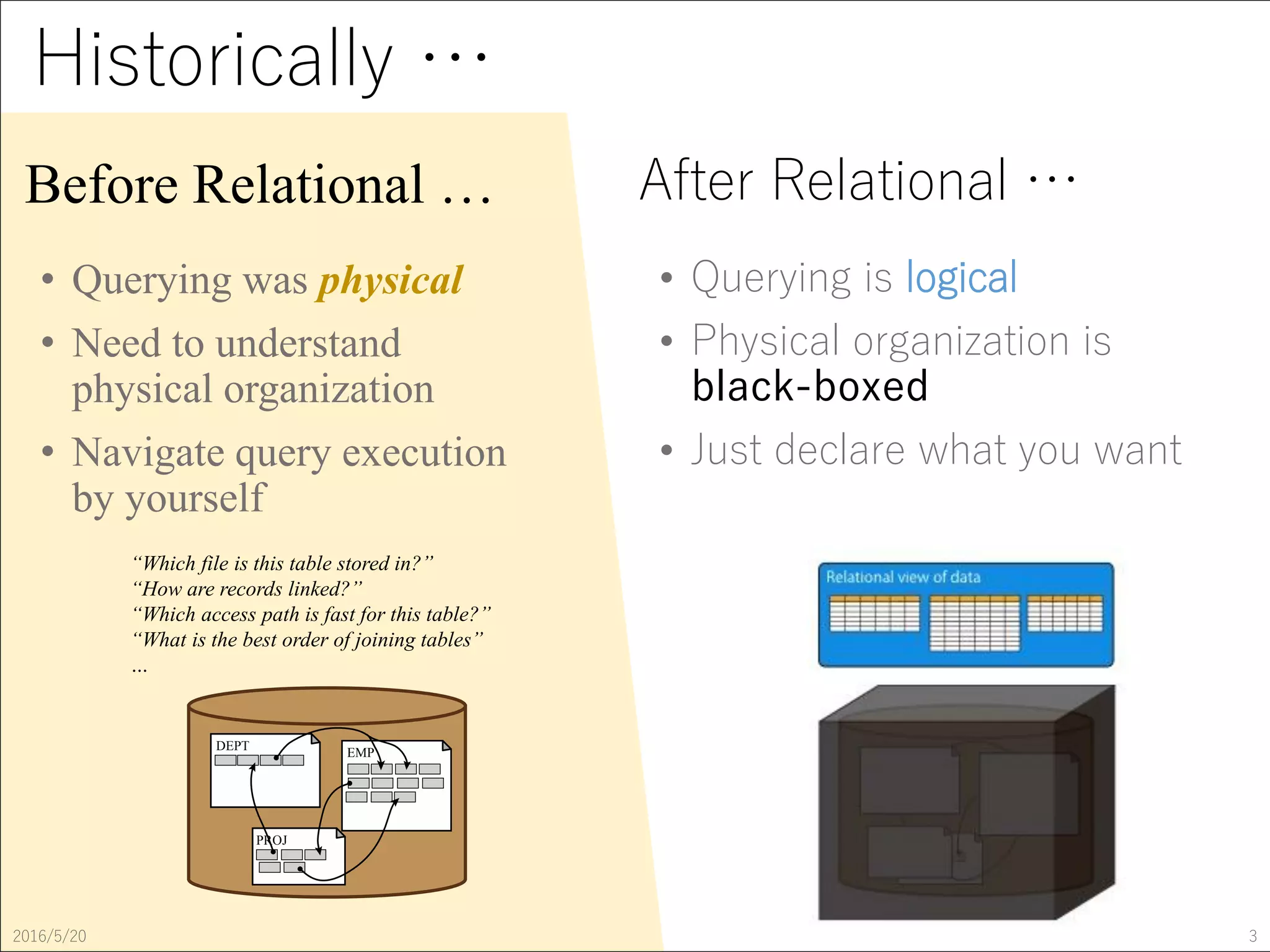
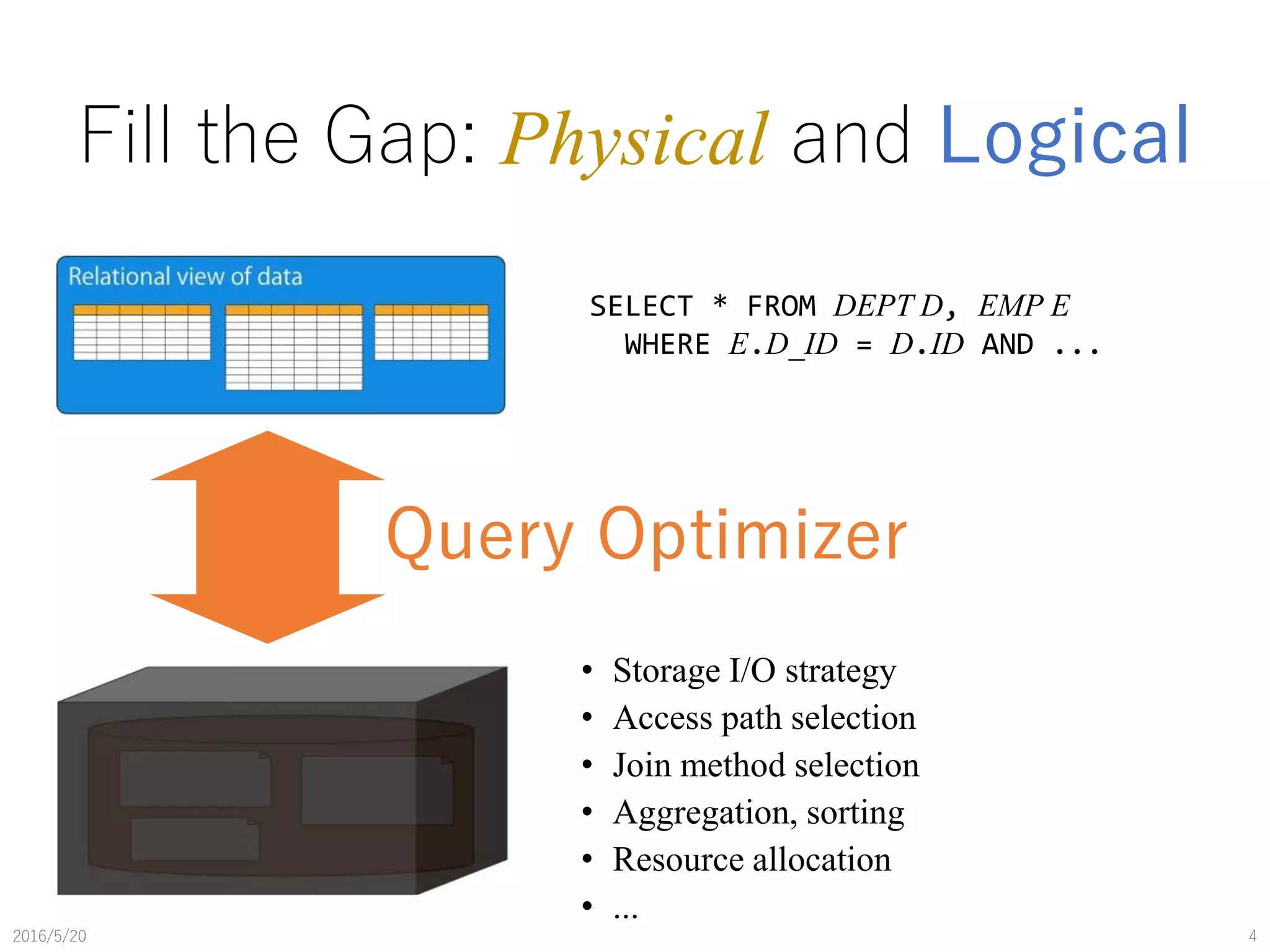
The document discusses the evolution of query optimization from physical to logical organization, highlighting the complexity of cost-based optimization in relational databases like PostgreSQL. It covers fundamental theories, implementation strategies, and challenges in managing physical behavior during query execution. Additionally, the study presents experimental observations using TPC-H benchmarks to evaluate the performance of various join methods and query plans.












































































