Downloaded 558 times




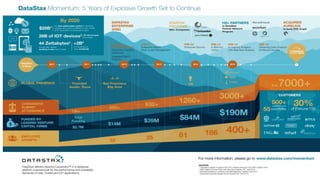

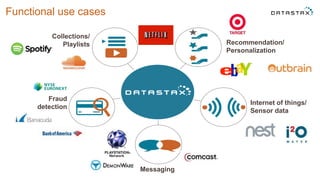
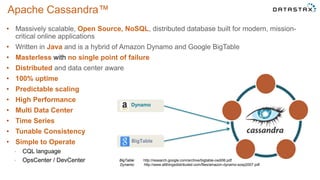



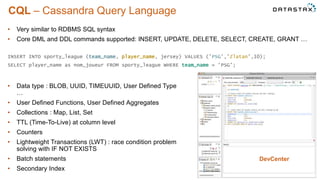









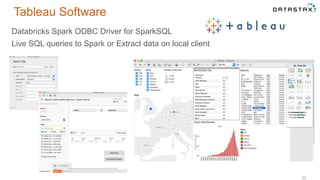


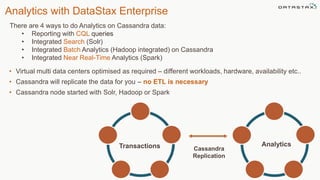

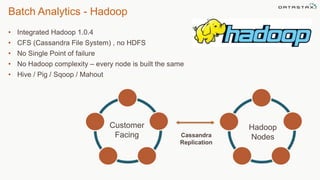
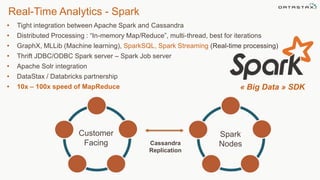
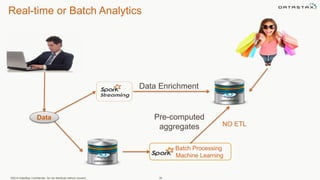
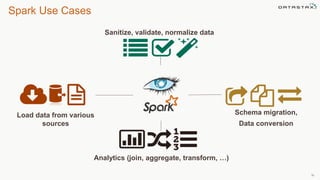

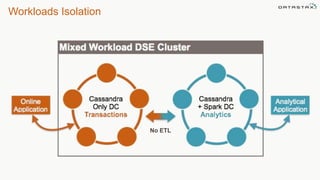
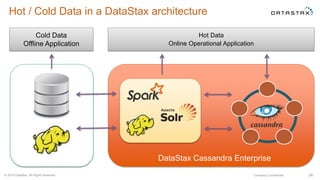
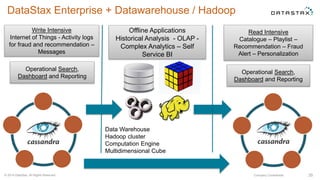

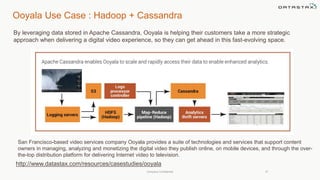
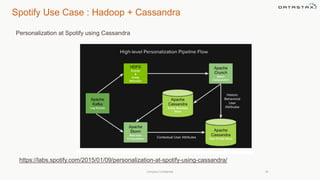





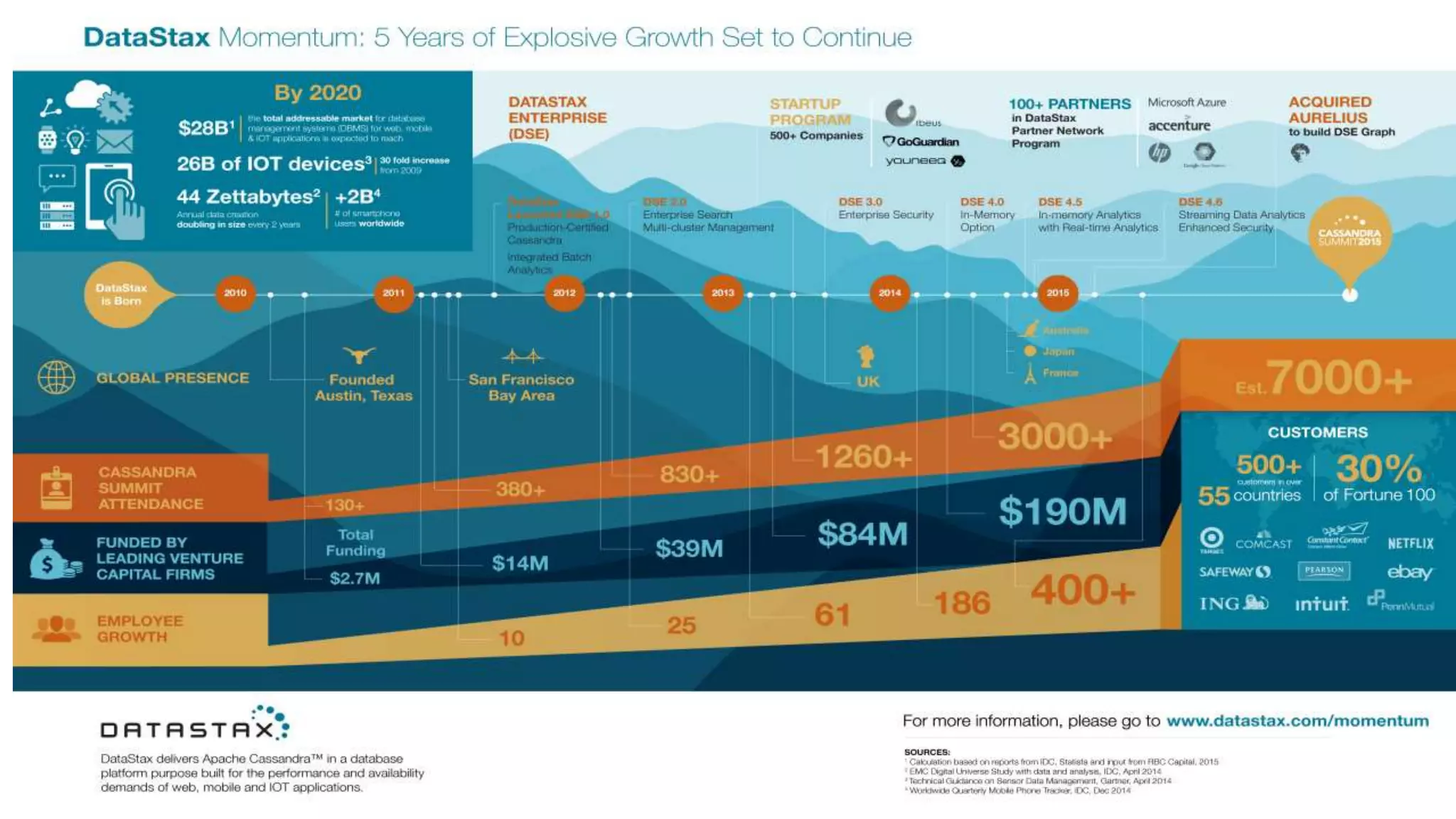


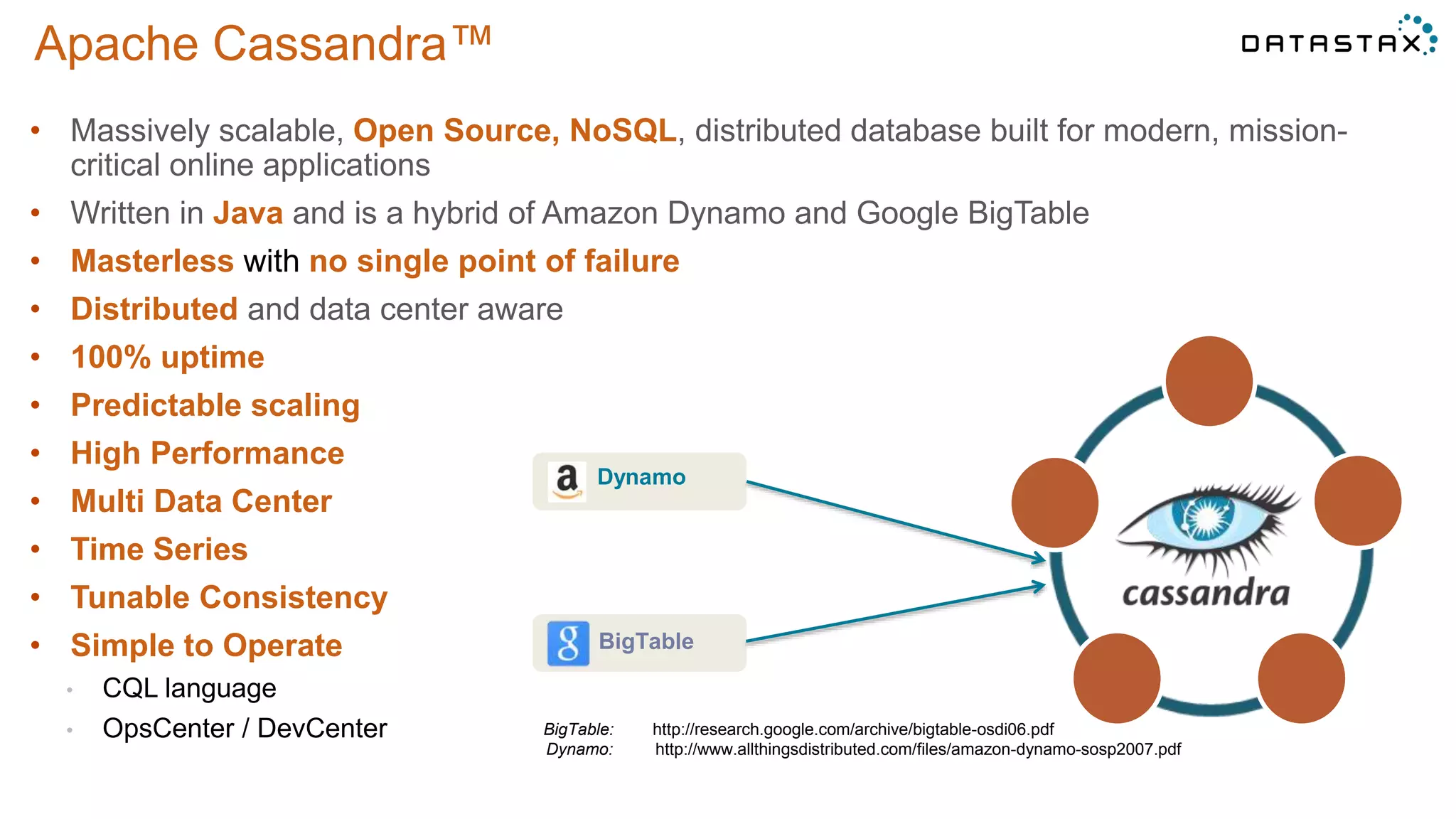













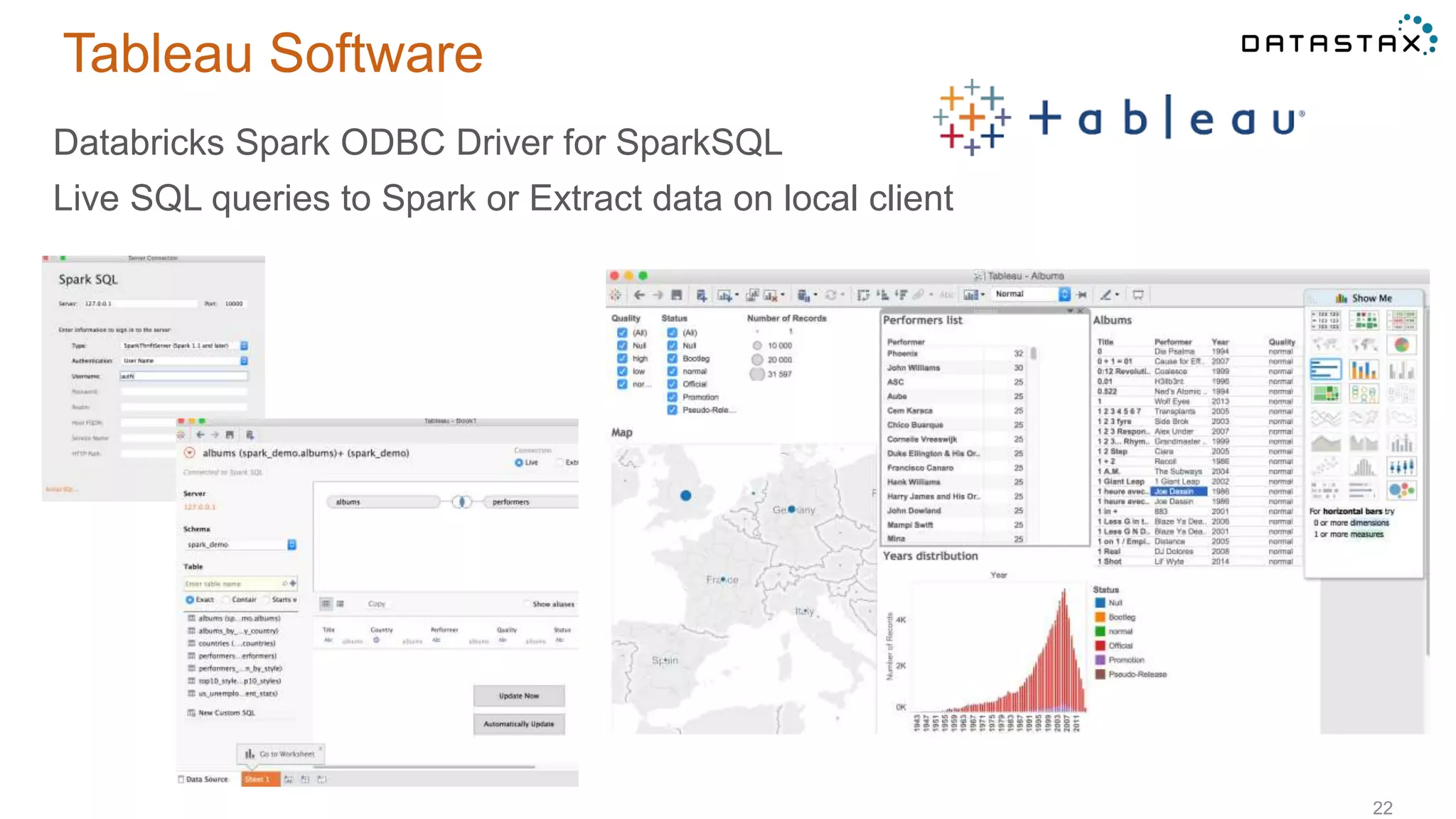



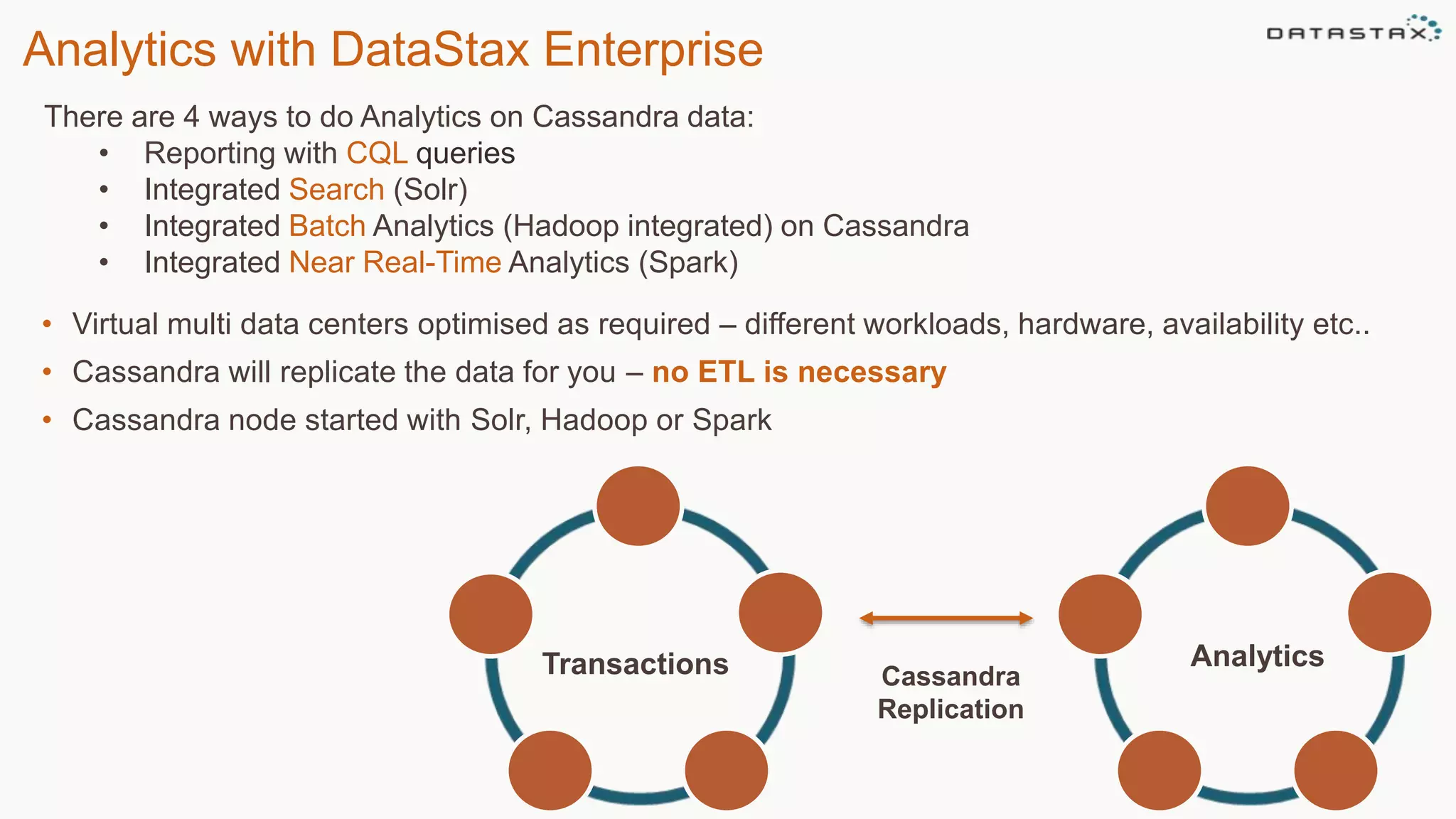

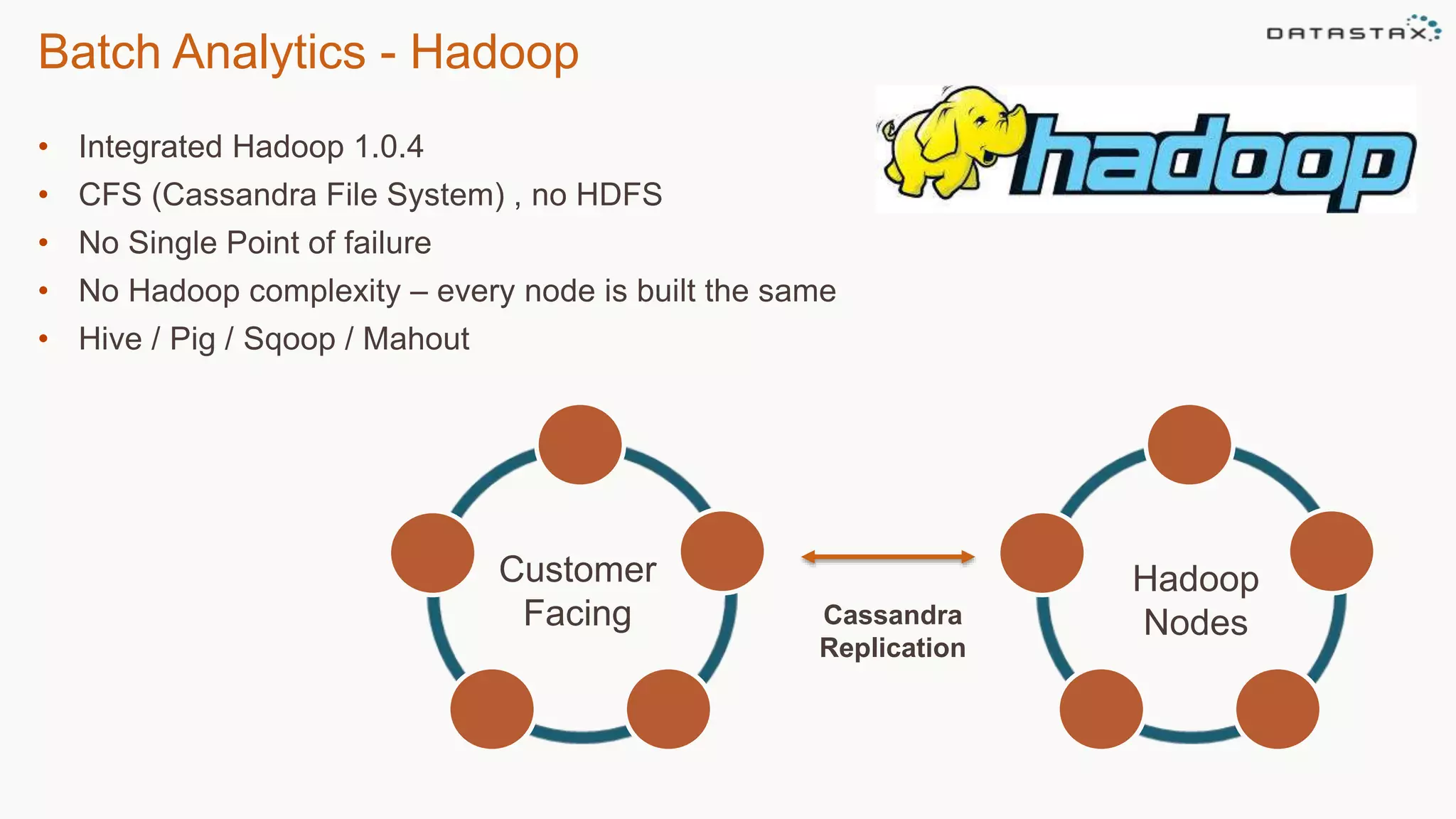

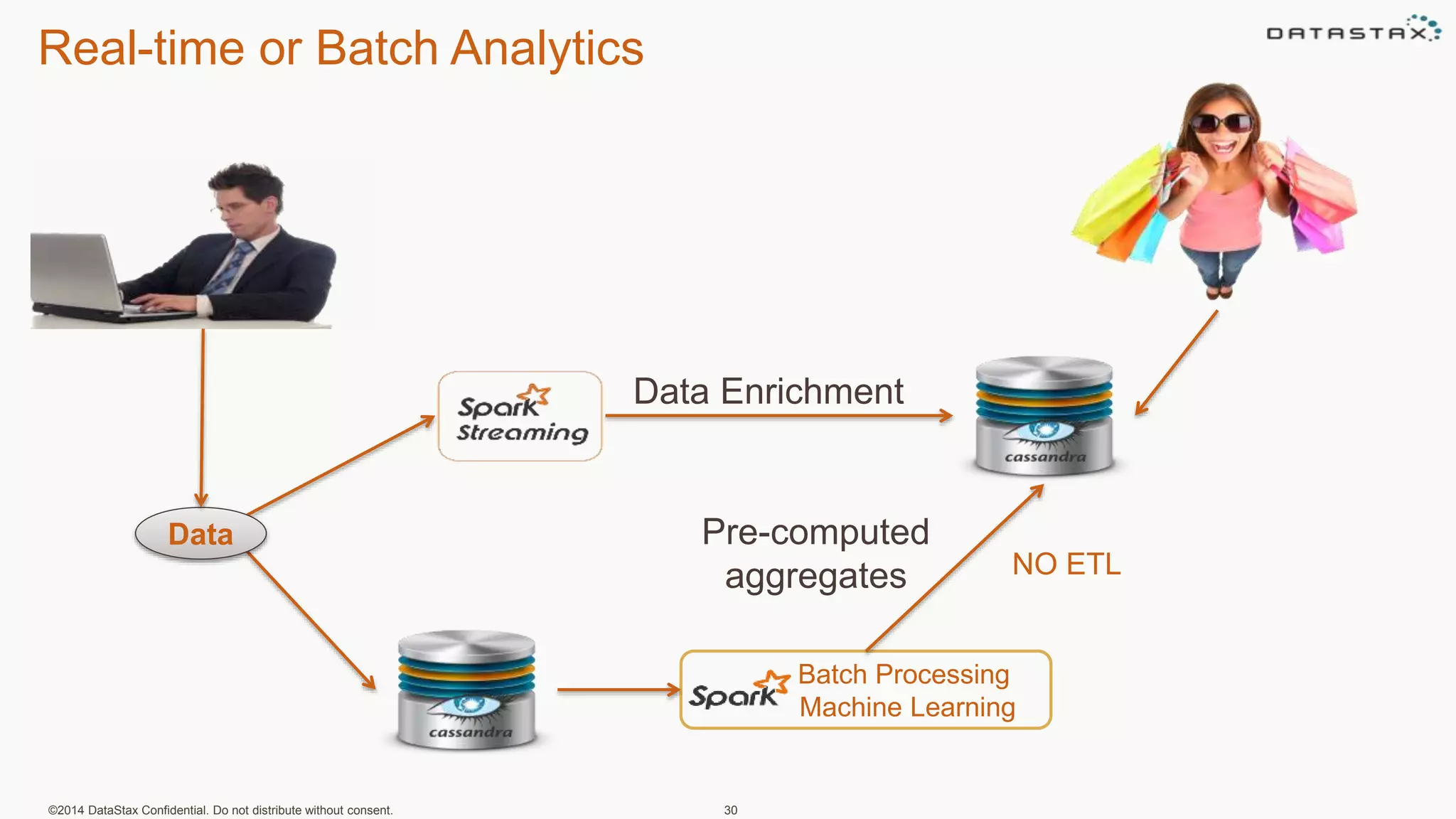
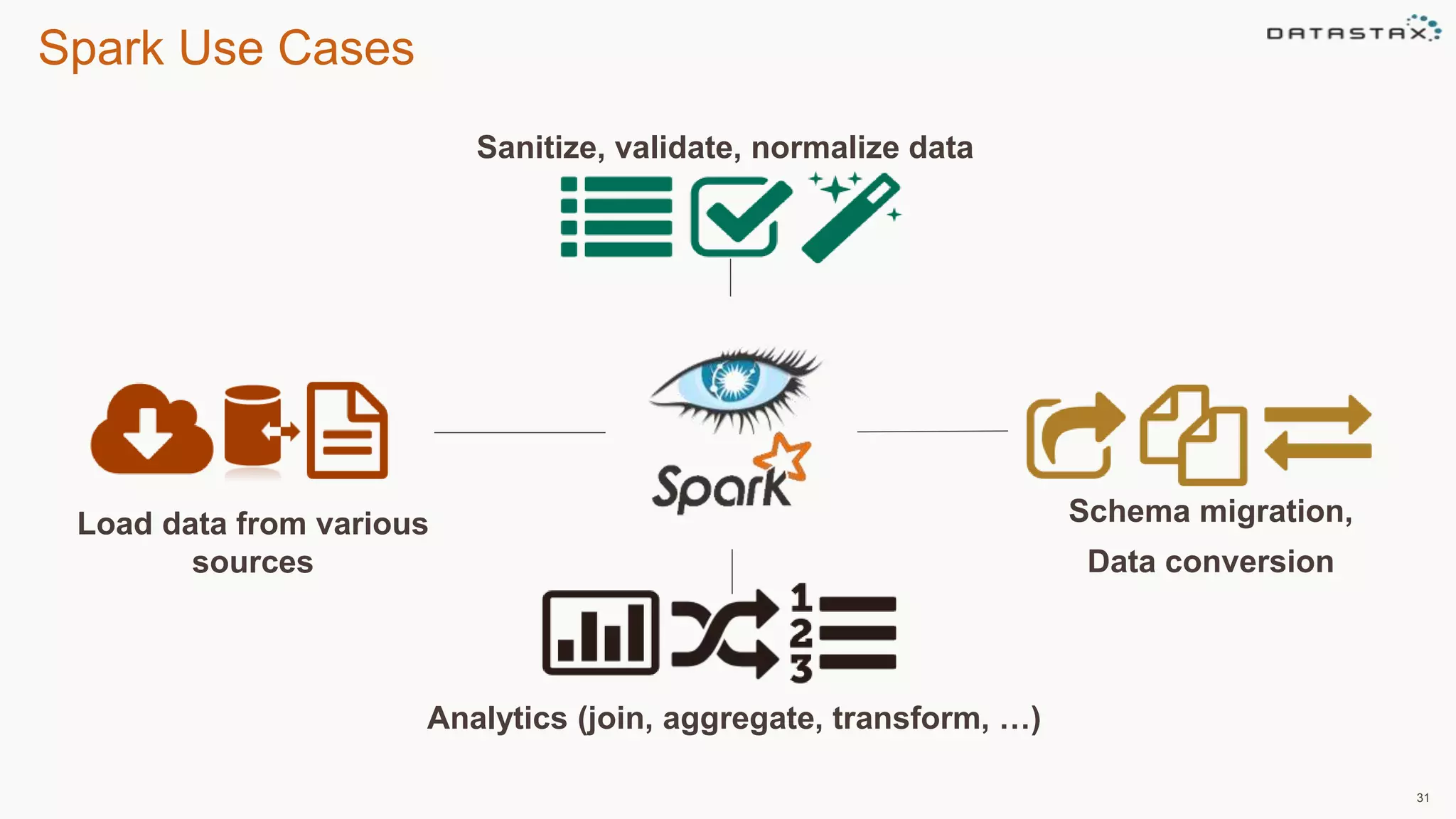

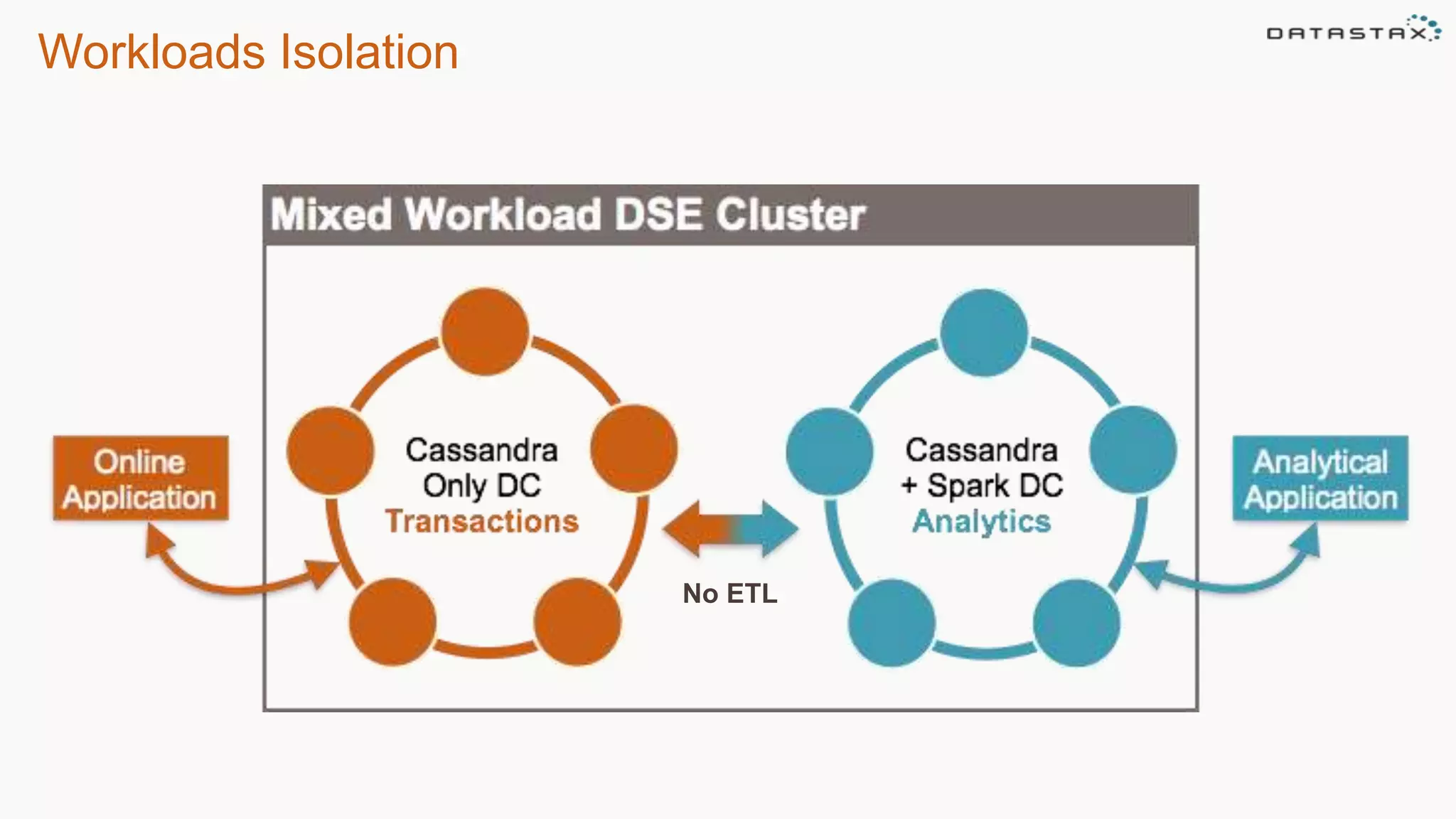
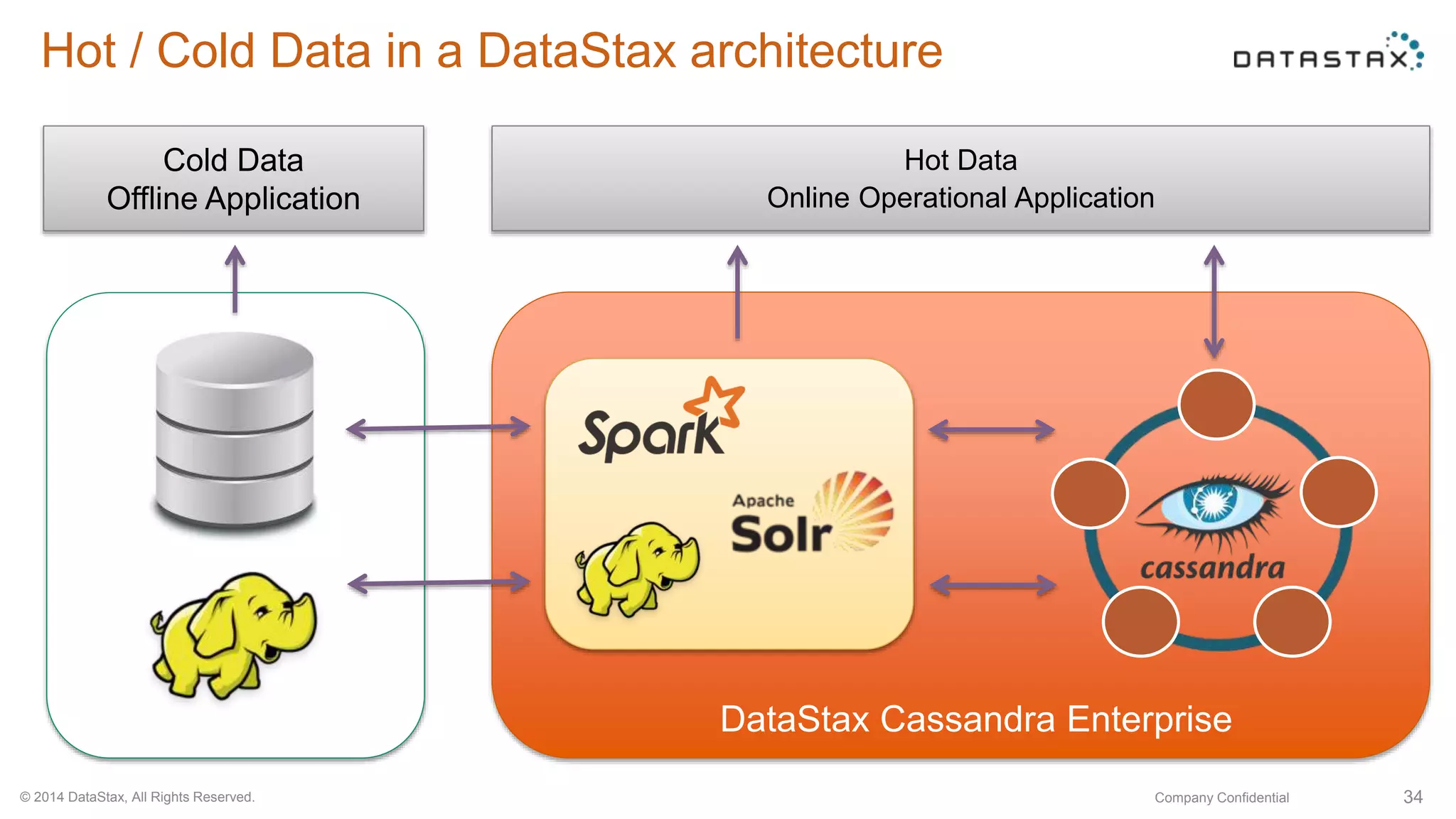
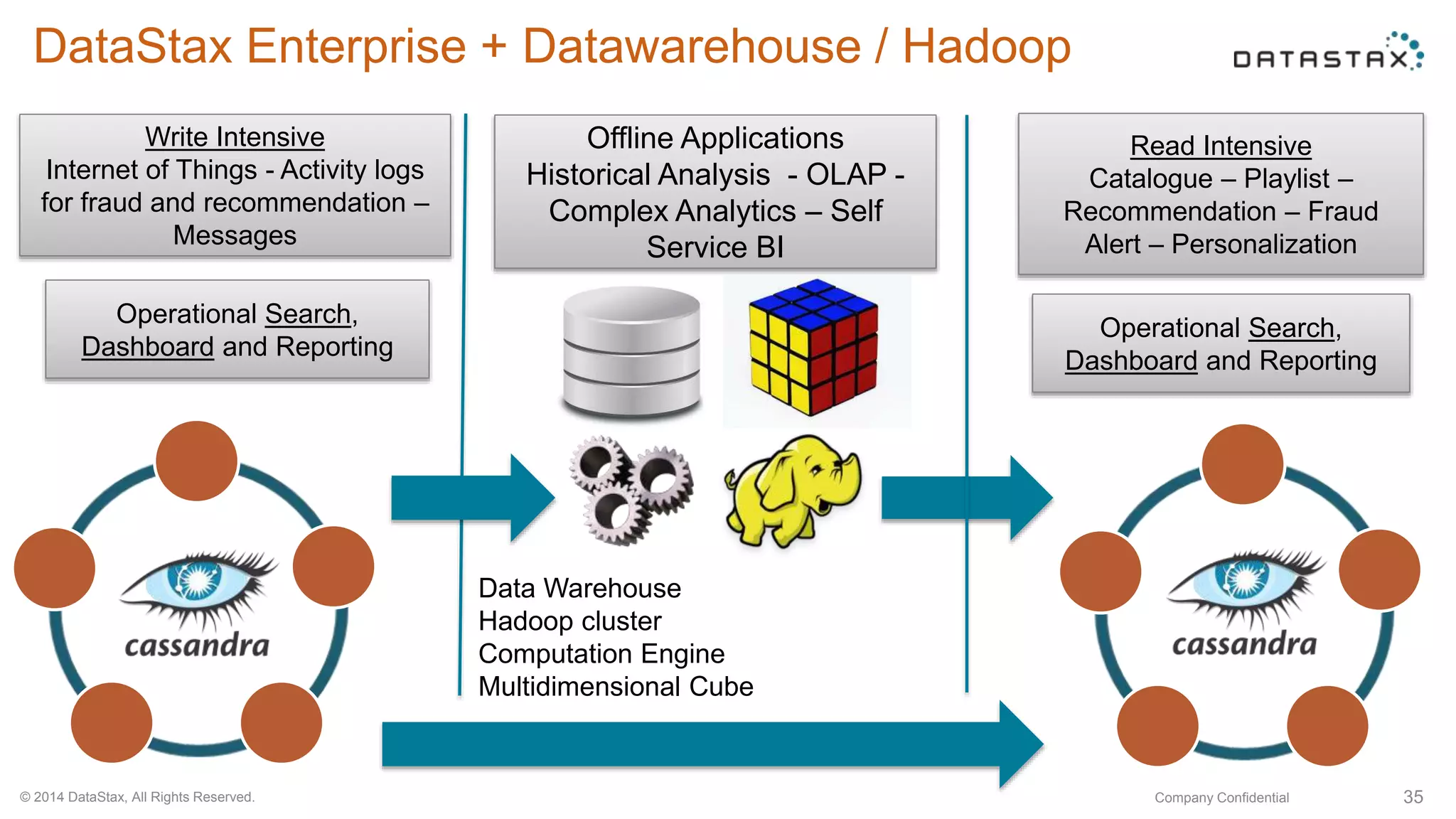

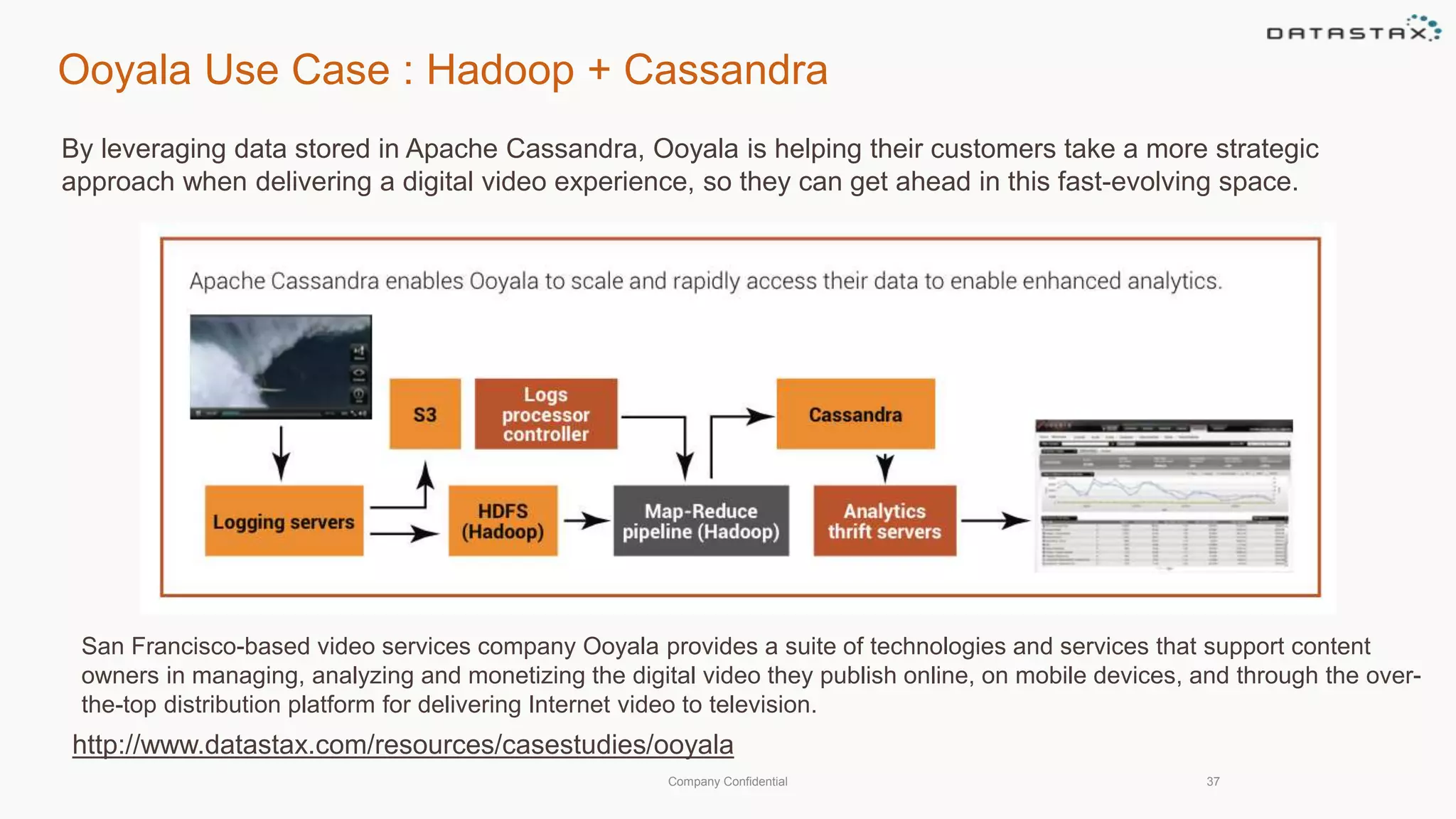
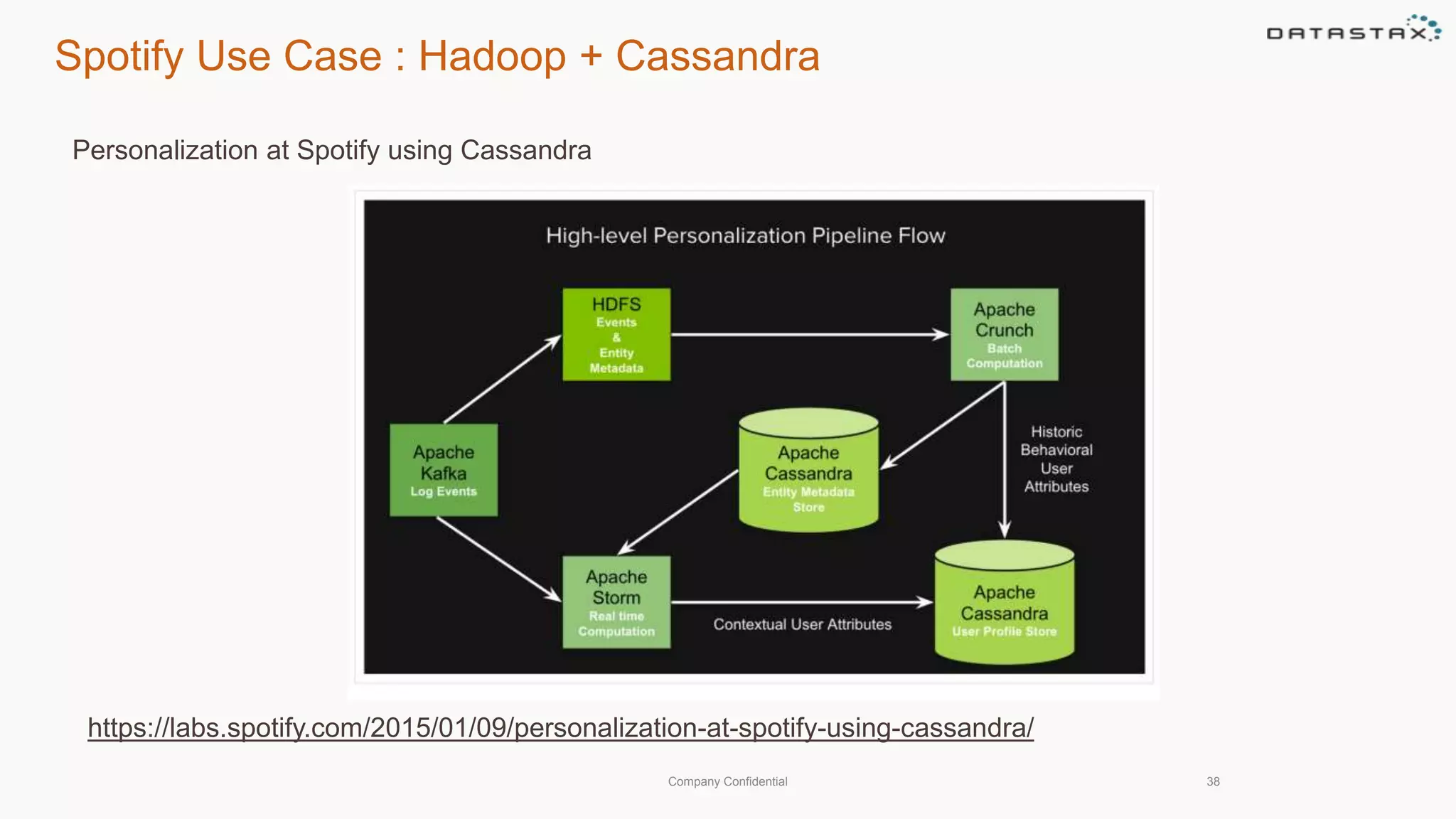


This document discusses using Apache Cassandra for business intelligence, reporting and analytics. It covers: - Data modeling and querying Cassandra data using CQL - Accessing Cassandra data through drivers, ODBC/JDBC, and analytics frameworks like Spark and Hadoop - Doing reporting, dashboards, and analytics on Cassandra data using CQL, Solr, Spark, and BI tools - Capabilities of DataStax Enterprise for integrated search, batch analytics, and real-time analytics on Cassandra - Example architectures that isolate workloads and handle hot vs cold data
















































































