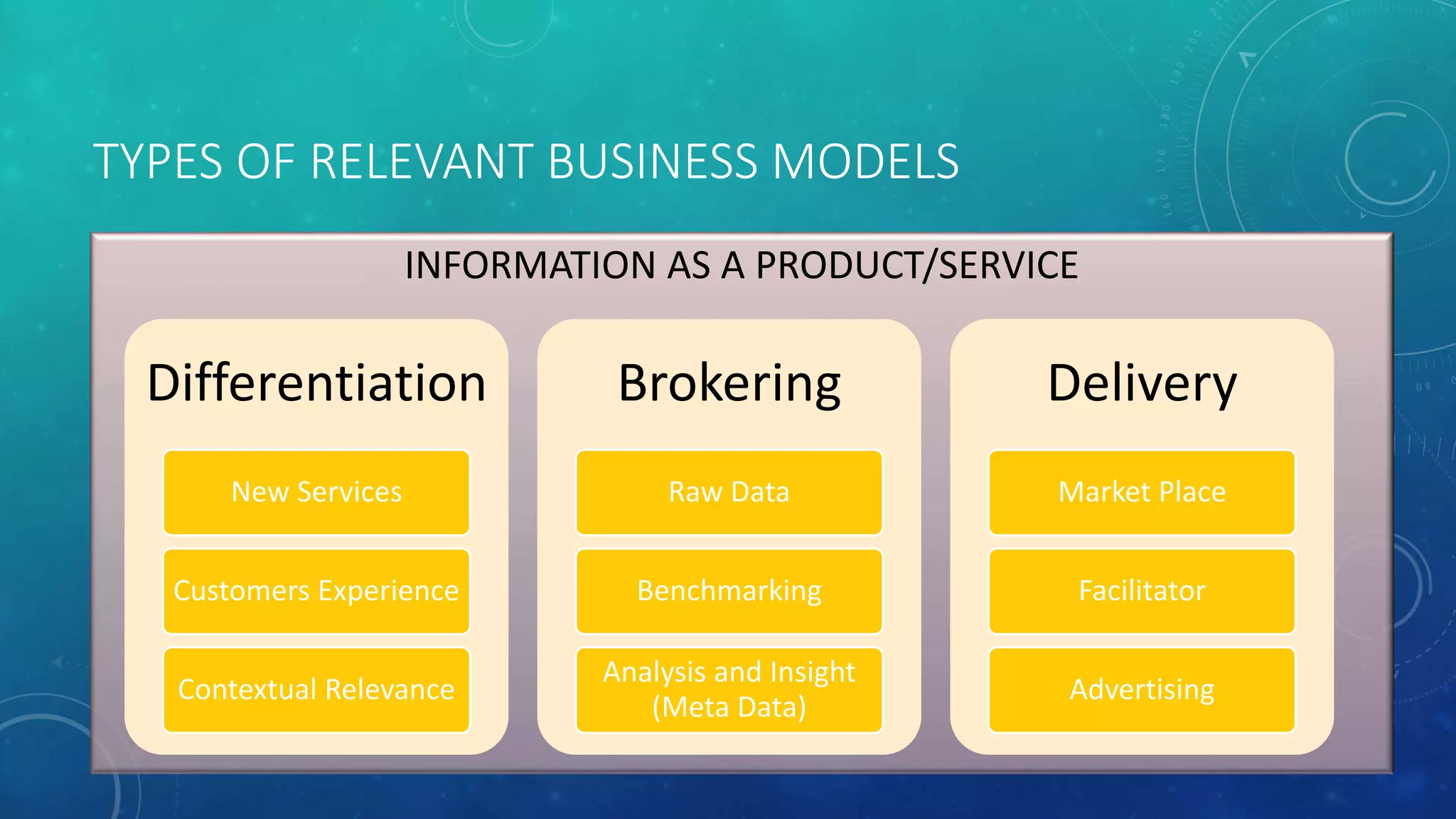
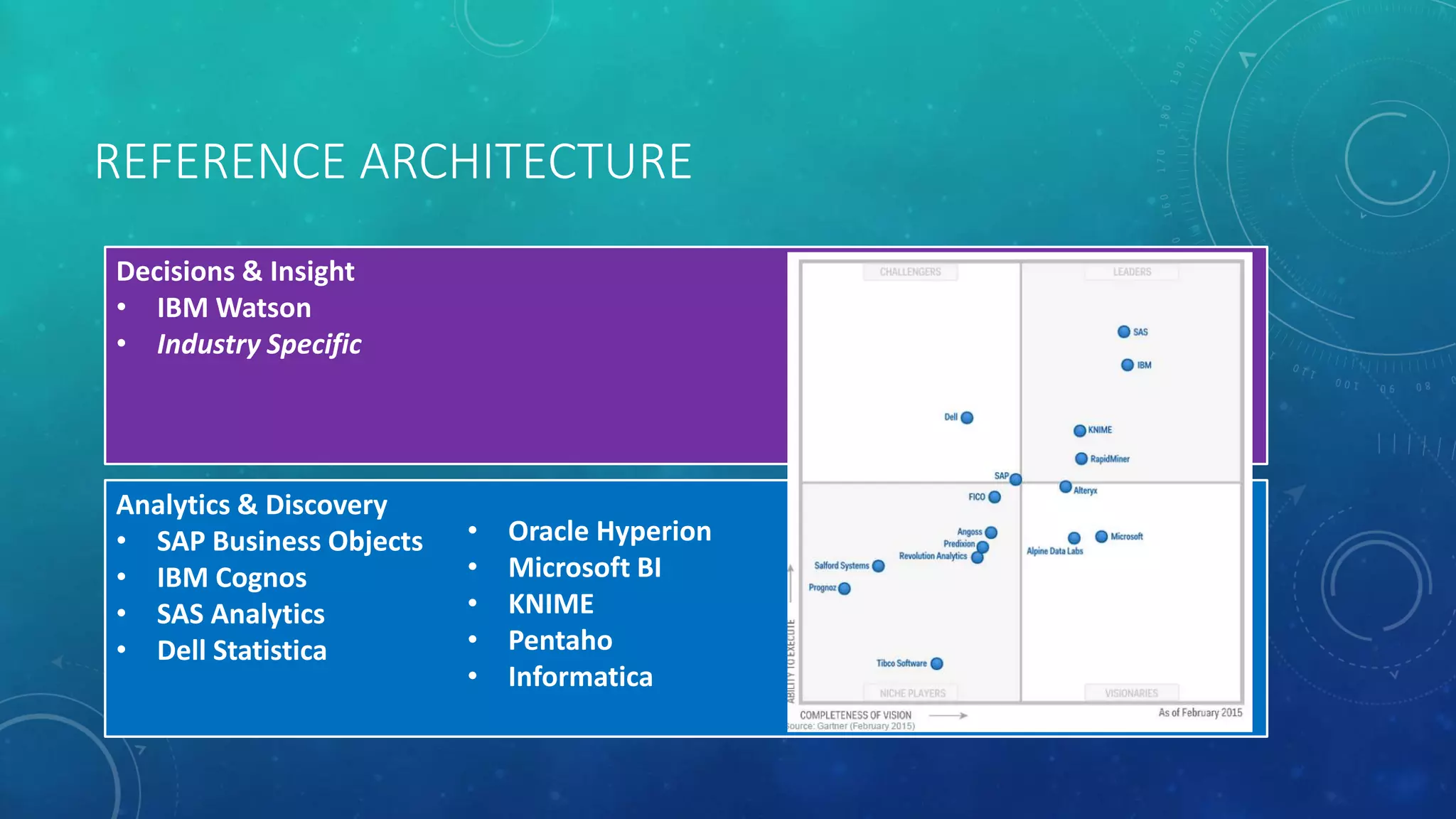
This document provides guidance for starting a data science startup, including key focus areas, funding stages, business planning steps, challenges, and a reference architecture. It recommends initially focusing on research, defining the problem and business model, and identifying the target market. Key planning steps include analyzing business needs, evaluating and selecting technologies, and obtaining funding and sponsorships. Challenges may include time pressures, lack of resources, and integrating with existing systems. The reference architecture outlines technology options at different layers, from infrastructure to analytics and decision-making tools.