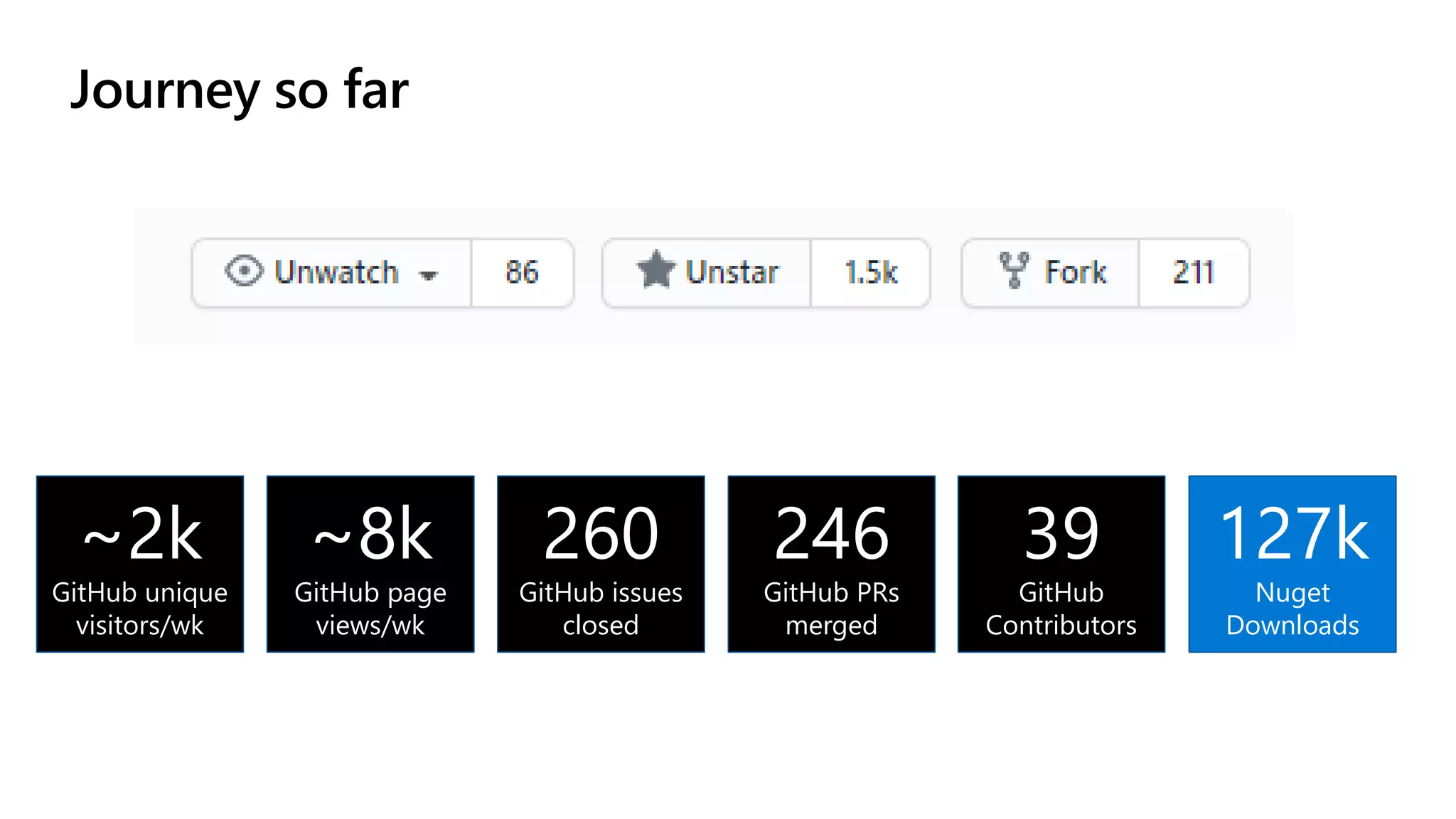
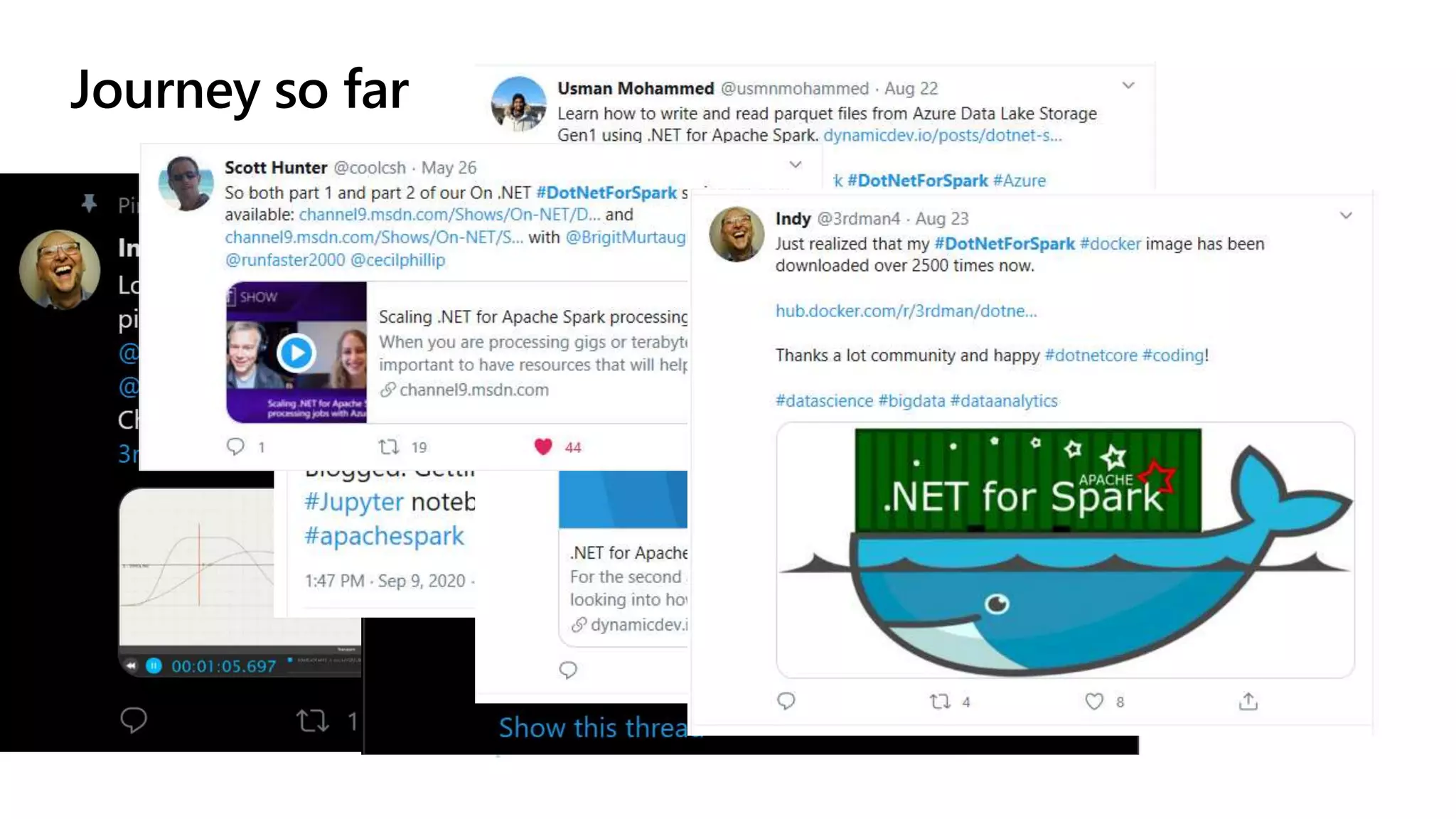
Download to read offline









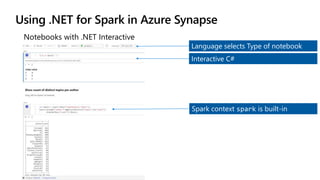
![.NET for Apache Spark programmability
var spark = SparkSession.Builder().GetOrCreate();
var dataframe =
spark.Read().Json(“input.json”);
dataframe.Filter(df["age"] > 21)
.Select(concat(df[“age”], df[“name”]).Show();
var concat =
Udf<int?, string, string>((age, name)=>name+age);](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/85/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-12-320.jpg)
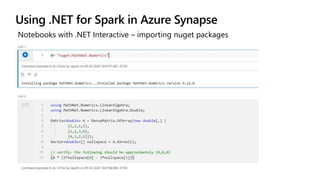
![Language comparison: TPC-H Query 2
val europe = region.filter($"r_name" === "EUROPE")
.join(nation, $"r_regionkey" === nation("n_regionkey"))
.join(supplier, $"n_nationkey" === supplier("s_nationkey"))
.join(partsupp,
supplier("s_suppkey") === partsupp("ps_suppkey"))
val brass = part.filter(part("p_size") === 15
&& part("p_type").endsWith("BRASS"))
.join(europe, europe("ps_partkey") === $"p_partkey")
val minCost = brass.groupBy(brass("ps_partkey"))
.agg(min("ps_supplycost").as("min"))
brass.join(minCost, brass("ps_partkey") === minCost("ps_partkey"))
.filter(brass("ps_supplycost") === minCost("min"))
.select("s_acctbal", "s_name", "n_name",
"p_partkey", "p_mfgr", "s_address",
"s_phone", "s_comment")
.sort($"s_acctbal".desc,
$"n_name", $"s_name", $"p_partkey")
.limit(100)
.show()
var europe = region.Filter(Col("r_name") == "EUROPE")
.Join(nation, Col("r_regionkey") == nation["n_regionkey"])
.Join(supplier, Col("n_nationkey") == supplier["s_nationkey"])
.Join(partsupp,
supplier["s_suppkey"] == partsupp["ps_suppkey"]);
var brass = part.Filter(part["p_size"] == 15
& part["p_type"].EndsWith("BRASS"))
.Join(europe, europe["ps_partkey"] == Col("p_partkey"));
var minCost = brass.GroupBy(brass["ps_partkey"])
.Agg(Min("ps_supplycost").As("min"));
brass.Join(minCost, brass["ps_partkey"] == minCost["ps_partkey"])
.Filter(brass["ps_supplycost"] == minCost["min"])
.Select("s_acctbal", "s_name", "n_name",
"p_partkey", "p_mfgr", "s_address",
"s_phone", "s_comment")
.Sort(Col("s_acctbal").Desc(),
Col("n_name"), Col("s_name"), Col("p_partkey"))
.Limit(100)
.Show();
Similar syntax – dangerously copy/paste friendly!
$”col_name” vs. Col(“col_name”) Capitalization
Scala C#
C# vs Scala (e.g., == vs ===)](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/85/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-13-320.jpg)



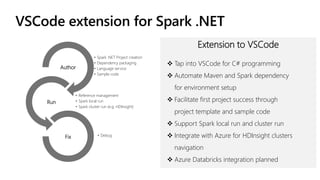
![df.GroupBy("age")
.Apply(
new StructType(new[]
{
new StructField("age", new IntegerType()),
new StructField("nameCharCount", new IntegerType())
}),
batch => CountCharacters(batch, "age", "name"))
.Show();
Simplifying experience with Arrow](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/85/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-21-320.jpg)
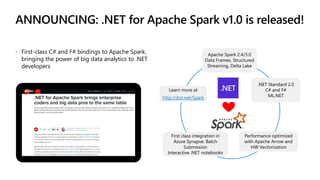
![private static FxDataFrame CountCharacters(
FxDataFrame df,
string groupColName,
string summaryColName)
{
int charCount = 0;
for (long i = 0; i < df.RowCount; ++i)
{
charCount += ((string)df[summaryColName][i]).Length;
}
return new FxDataFrame(new[] {
new PrimitiveColumn<int>(groupColName,
new[] { (int?)df[groupColName][0] }),
new PrimitiveColumn<int>(summaryColName,
new[] { charCount }) });
}
private static RecordBatch CountCharacters(
RecordBatch records,
string groupColName,
string summaryColName)
{
int summaryColIndex = records.Schema.GetFieldIndex(summaryColName);
StringArray stringValues = records.Column(summaryColIndex) as StringArray;
int charCount = 0;
for (int i = 0; i < stringValues.Length; ++i)
{
charCount += stringValues.GetString(i).Length;
}
int groupColIndex = records.Schema.GetFieldIndex(groupColName);
Field groupCol = records.Schema.GetFieldByIndex(groupColIndex);
return new RecordBatch(
new Schema.Builder()
.Field(groupCol)
.Field(f => f.Name(summaryColName).DataType(Int32Type.Default))
.Build(),
new IArrowArray[]
{
records.Column(groupColIndex),
new Int32Array.Builder().Append(charCount).Build()
},
records.Length);
}
Previous Experience New Experience
Simplifying experience with Arrow](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/85/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-22-320.jpg)
















![.NET for Apache Spark programmability
var spark = SparkSession.Builder().GetOrCreate();
var dataframe =
spark.Read().Json(“input.json”);
dataframe.Filter(df["age"] > 21)
.Select(concat(df[“age”], df[“name”]).Show();
var concat =
Udf<int?, string, string>((age, name)=>name+age);](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/75/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-12-2048.jpg)
![Language comparison: TPC-H Query 2
val europe = region.filter($"r_name" === "EUROPE")
.join(nation, $"r_regionkey" === nation("n_regionkey"))
.join(supplier, $"n_nationkey" === supplier("s_nationkey"))
.join(partsupp,
supplier("s_suppkey") === partsupp("ps_suppkey"))
val brass = part.filter(part("p_size") === 15
&& part("p_type").endsWith("BRASS"))
.join(europe, europe("ps_partkey") === $"p_partkey")
val minCost = brass.groupBy(brass("ps_partkey"))
.agg(min("ps_supplycost").as("min"))
brass.join(minCost, brass("ps_partkey") === minCost("ps_partkey"))
.filter(brass("ps_supplycost") === minCost("min"))
.select("s_acctbal", "s_name", "n_name",
"p_partkey", "p_mfgr", "s_address",
"s_phone", "s_comment")
.sort($"s_acctbal".desc,
$"n_name", $"s_name", $"p_partkey")
.limit(100)
.show()
var europe = region.Filter(Col("r_name") == "EUROPE")
.Join(nation, Col("r_regionkey") == nation["n_regionkey"])
.Join(supplier, Col("n_nationkey") == supplier["s_nationkey"])
.Join(partsupp,
supplier["s_suppkey"] == partsupp["ps_suppkey"]);
var brass = part.Filter(part["p_size"] == 15
& part["p_type"].EndsWith("BRASS"))
.Join(europe, europe["ps_partkey"] == Col("p_partkey"));
var minCost = brass.GroupBy(brass["ps_partkey"])
.Agg(Min("ps_supplycost").As("min"));
brass.Join(minCost, brass["ps_partkey"] == minCost["ps_partkey"])
.Filter(brass["ps_supplycost"] == minCost["min"])
.Select("s_acctbal", "s_name", "n_name",
"p_partkey", "p_mfgr", "s_address",
"s_phone", "s_comment")
.Sort(Col("s_acctbal").Desc(),
Col("n_name"), Col("s_name"), Col("p_partkey"))
.Limit(100)
.Show();
Similar syntax – dangerously copy/paste friendly!
$”col_name” vs. Col(“col_name”) Capitalization
Scala C#
C# vs Scala (e.g., == vs ===)](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/75/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-13-2048.jpg)


![df.GroupBy("age")
.Apply(
new StructType(new[]
{
new StructField("age", new IntegerType()),
new StructField("nameCharCount", new IntegerType())
}),
batch => CountCharacters(batch, "age", "name"))
.Show();
Simplifying experience with Arrow](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/75/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-21-2048.jpg)
![private static FxDataFrame CountCharacters(
FxDataFrame df,
string groupColName,
string summaryColName)
{
int charCount = 0;
for (long i = 0; i < df.RowCount; ++i)
{
charCount += ((string)df[summaryColName][i]).Length;
}
return new FxDataFrame(new[] {
new PrimitiveColumn<int>(groupColName,
new[] { (int?)df[groupColName][0] }),
new PrimitiveColumn<int>(summaryColName,
new[] { charCount }) });
}
private static RecordBatch CountCharacters(
RecordBatch records,
string groupColName,
string summaryColName)
{
int summaryColIndex = records.Schema.GetFieldIndex(summaryColName);
StringArray stringValues = records.Column(summaryColIndex) as StringArray;
int charCount = 0;
for (int i = 0; i < stringValues.Length; ++i)
{
charCount += stringValues.GetString(i).Length;
}
int groupColIndex = records.Schema.GetFieldIndex(groupColName);
Field groupCol = records.Schema.GetFieldByIndex(groupColIndex);
return new RecordBatch(
new Schema.Builder()
.Field(groupCol)
.Field(f => f.Name(summaryColName).DataType(Int32Type.Default))
.Build(),
new IArrowArray[]
{
records.Column(groupColIndex),
new Int32Array.Builder().Append(charCount).Build()
},
records.Length);
}
Previous Experience New Experience
Simplifying experience with Arrow](https://image.slidesharecdn.com/sqlbits2020dotnetsparkmrys-201002190310/75/Big-Data-Processing-with-NET-and-Spark-SQLBits-2020-22-2048.jpg)
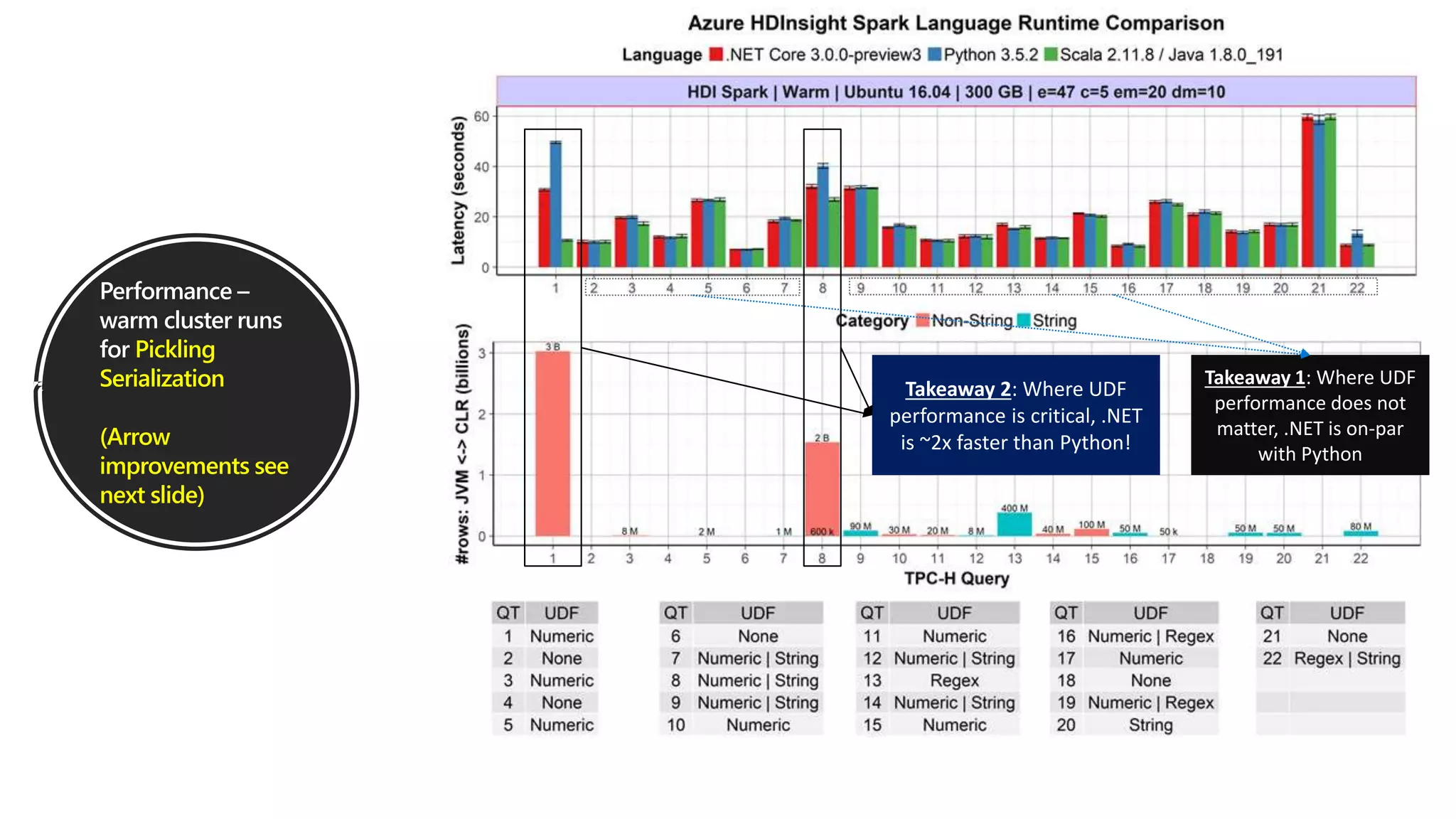
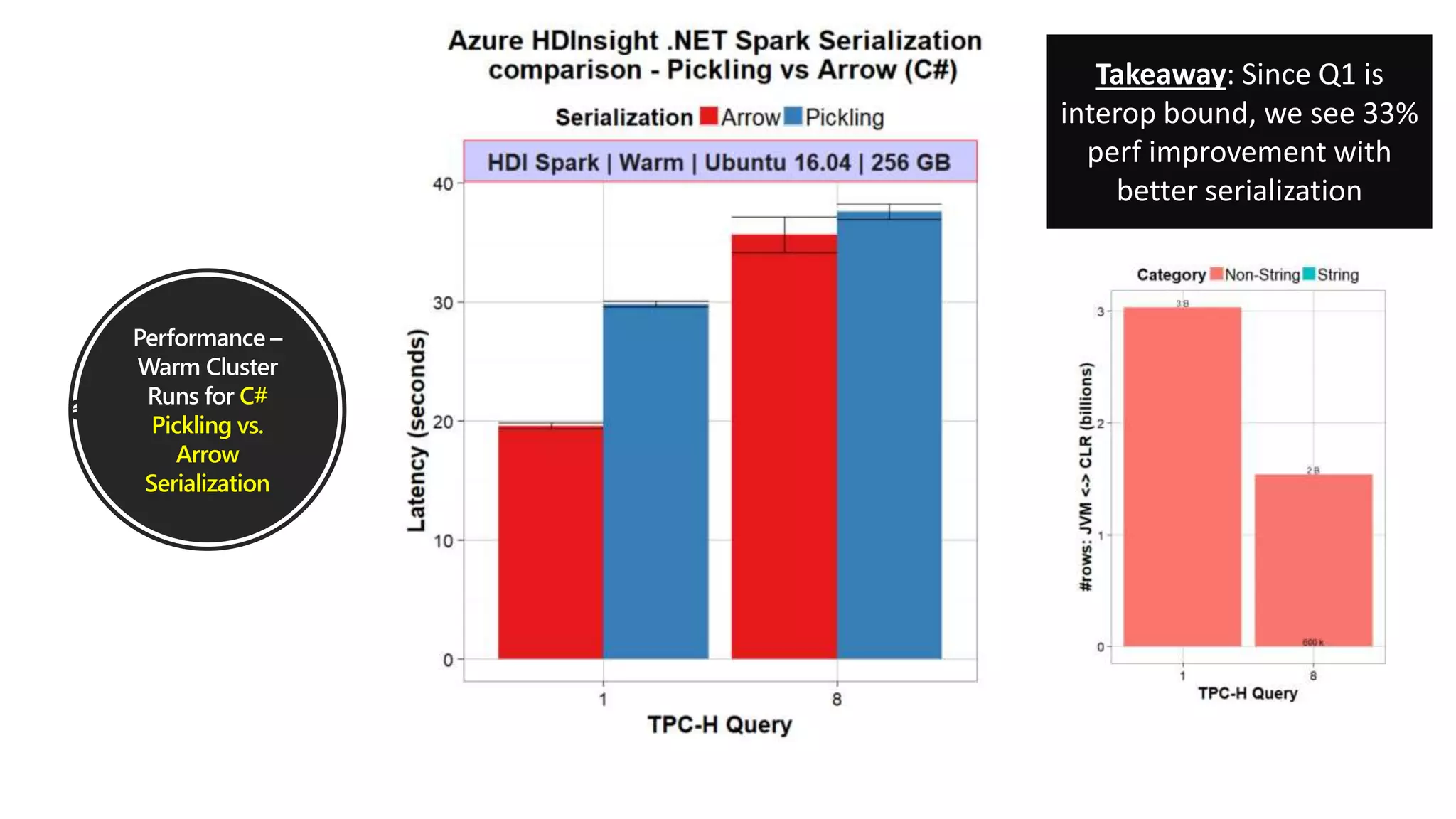
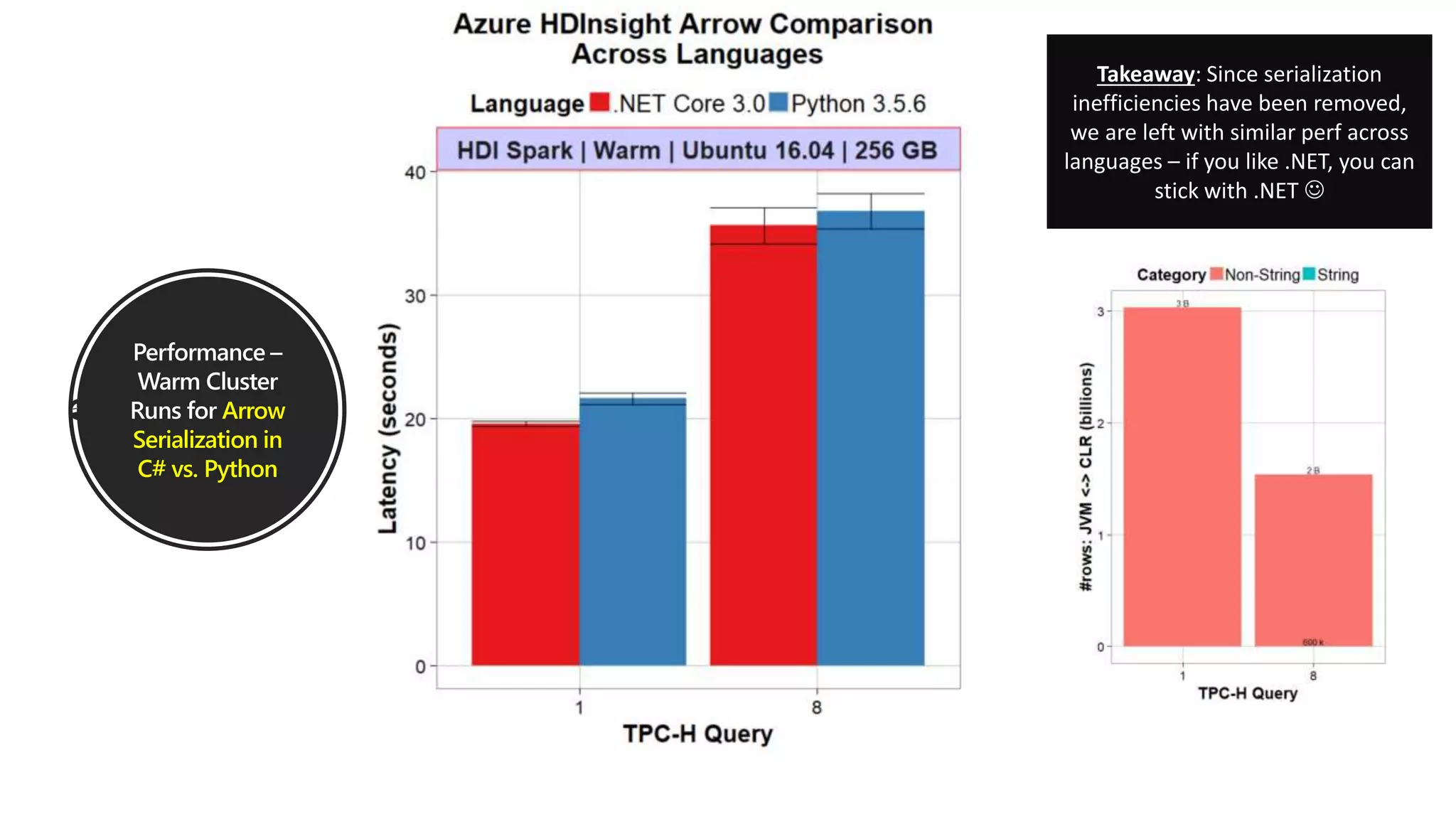
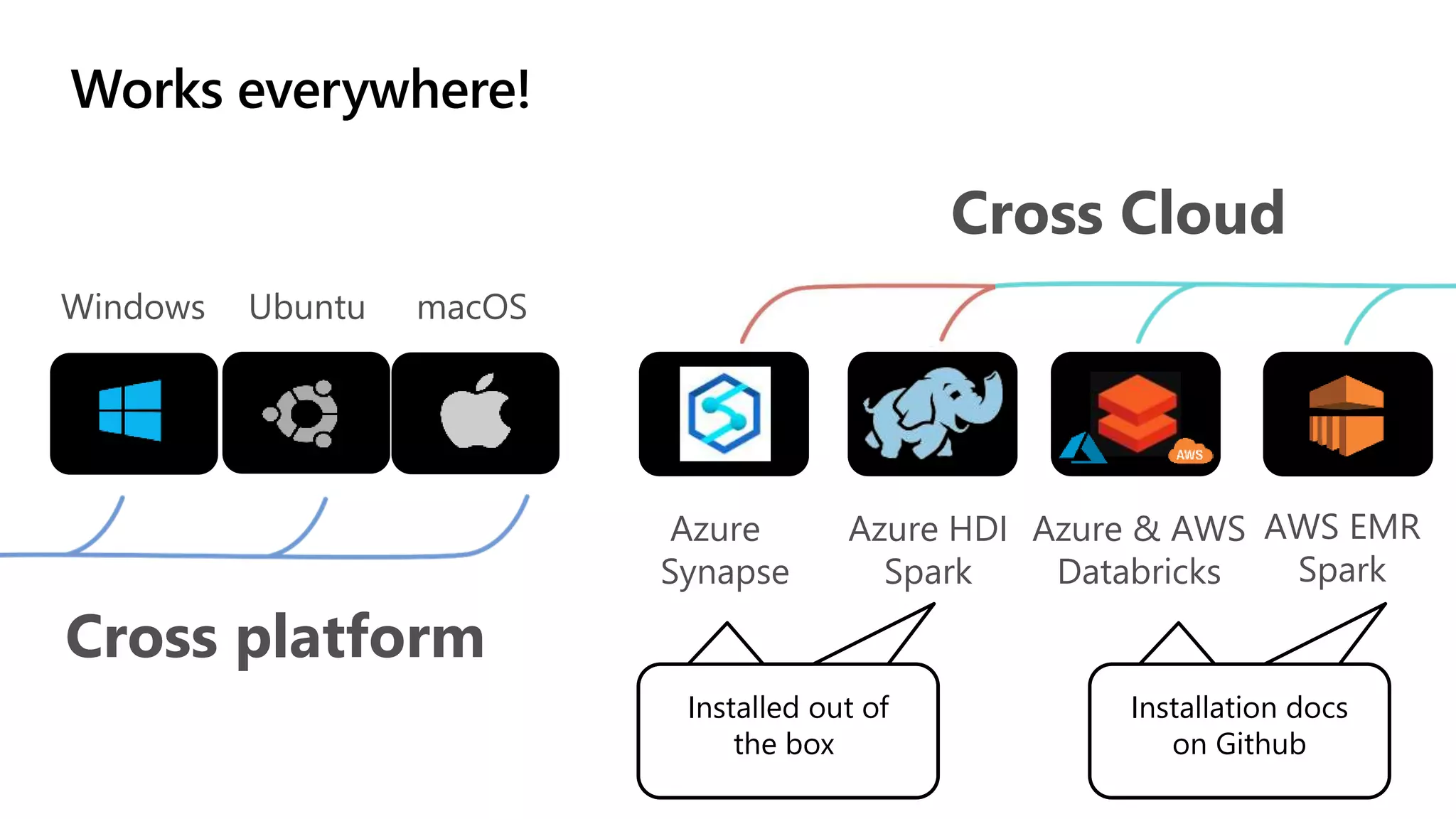








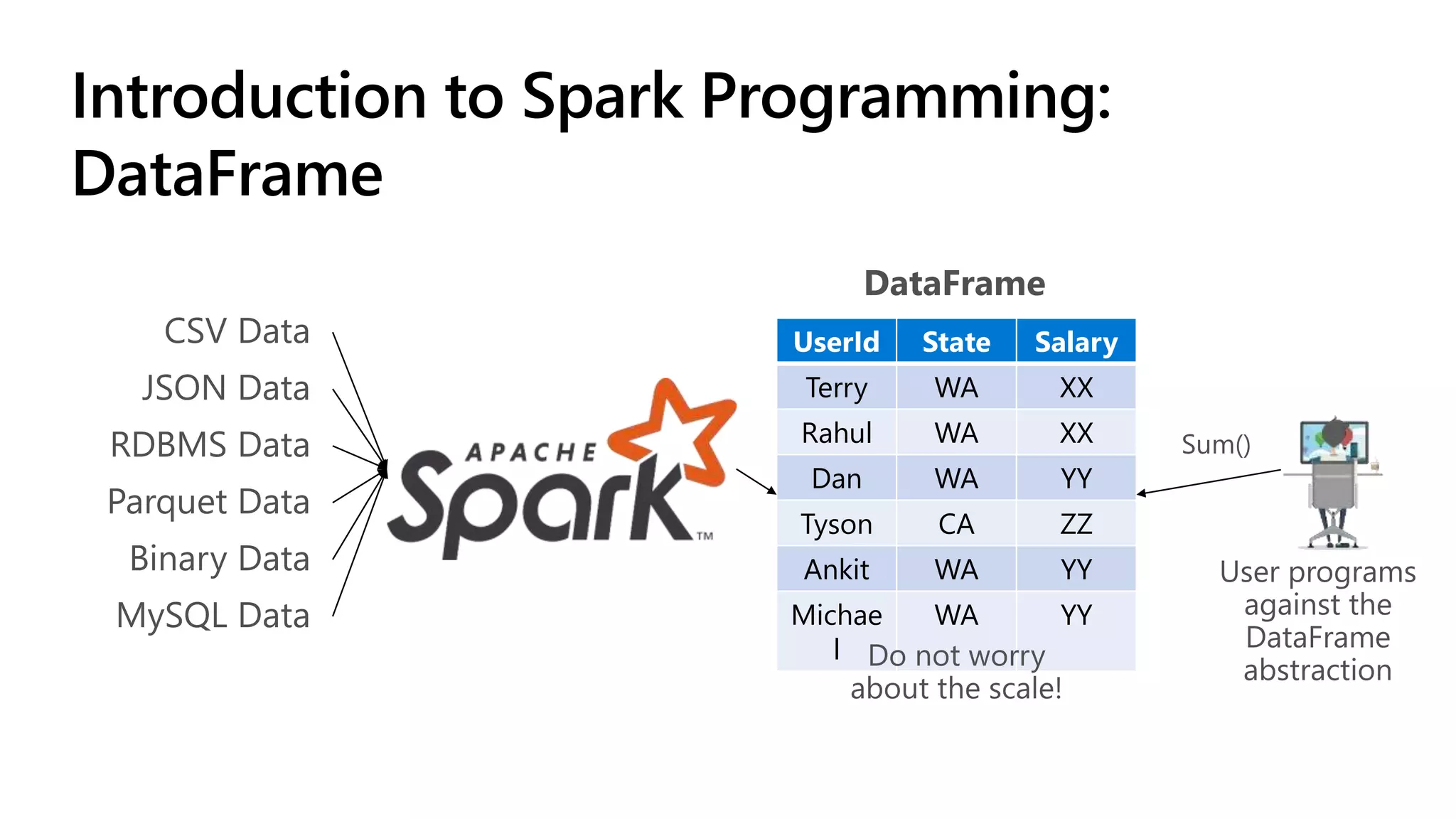
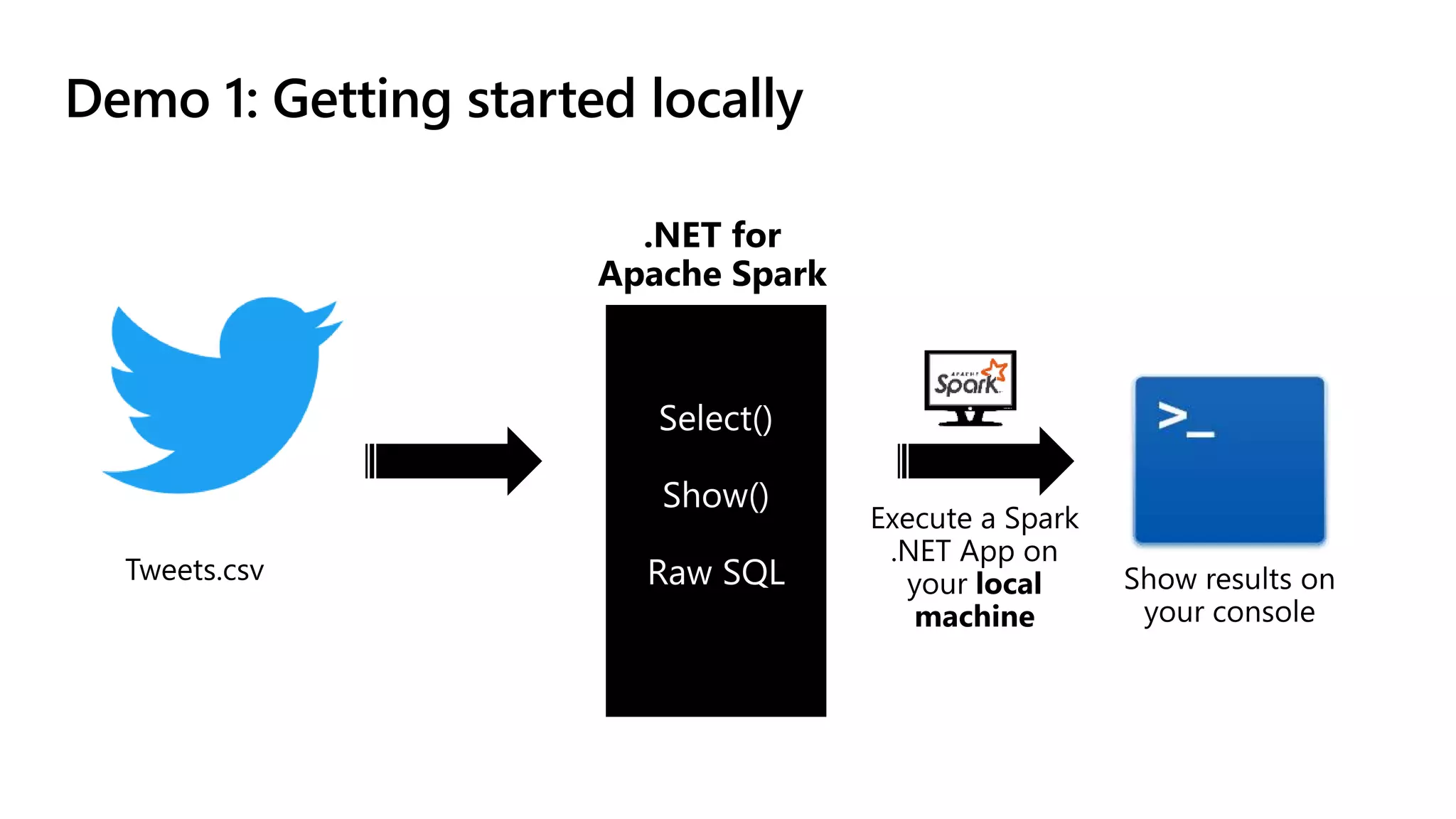
.NET for Apache Spark is aimed at providing .NET developers with a first-class experience for big data processing, allowing them to utilize existing business logic and libraries efficiently. The open-source project integrates with Azure services and offers features such as batch processing, streaming, and support for various programming paradigms while optimizing performance through Apache Arrow. The recent release of version 1.0 introduces comprehensive C# and F# bindings, enhancing usability for .NET developers in big data analytics.























































































