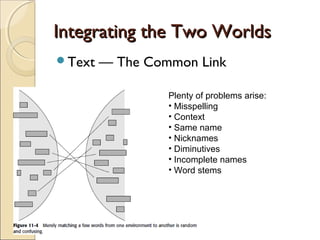
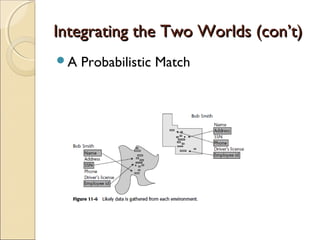
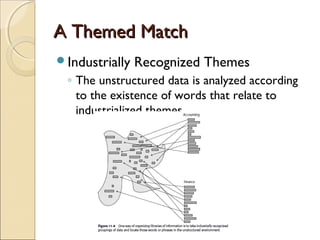
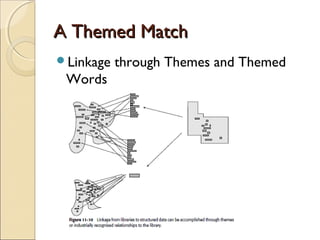
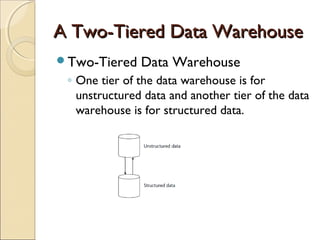
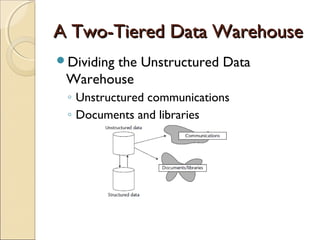
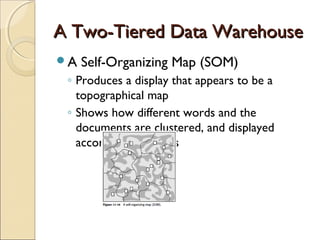
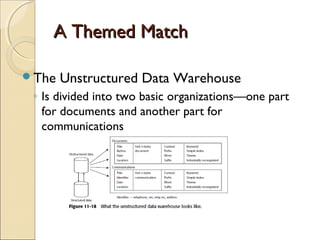
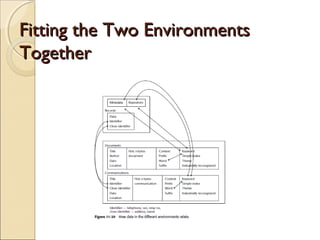
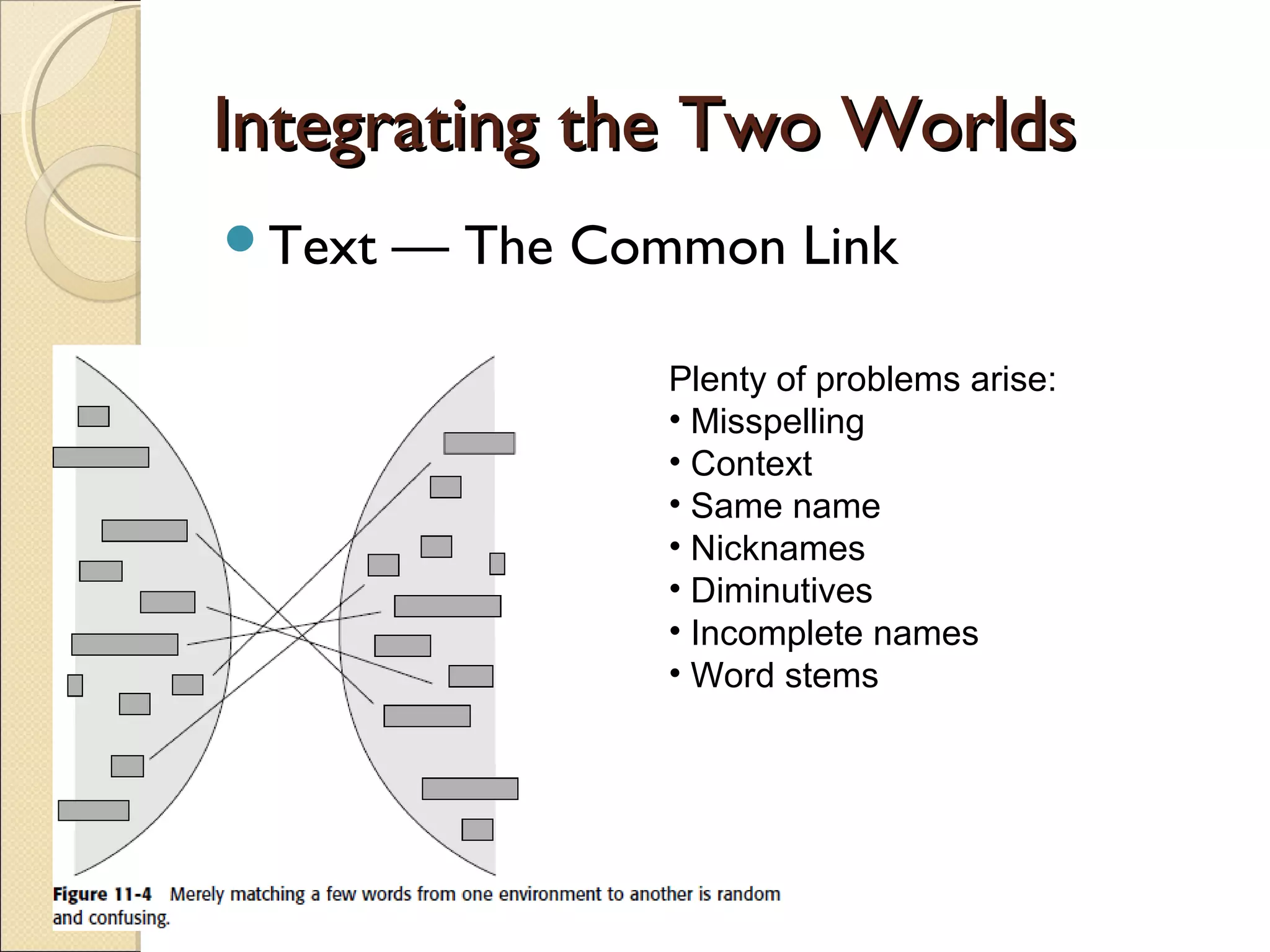
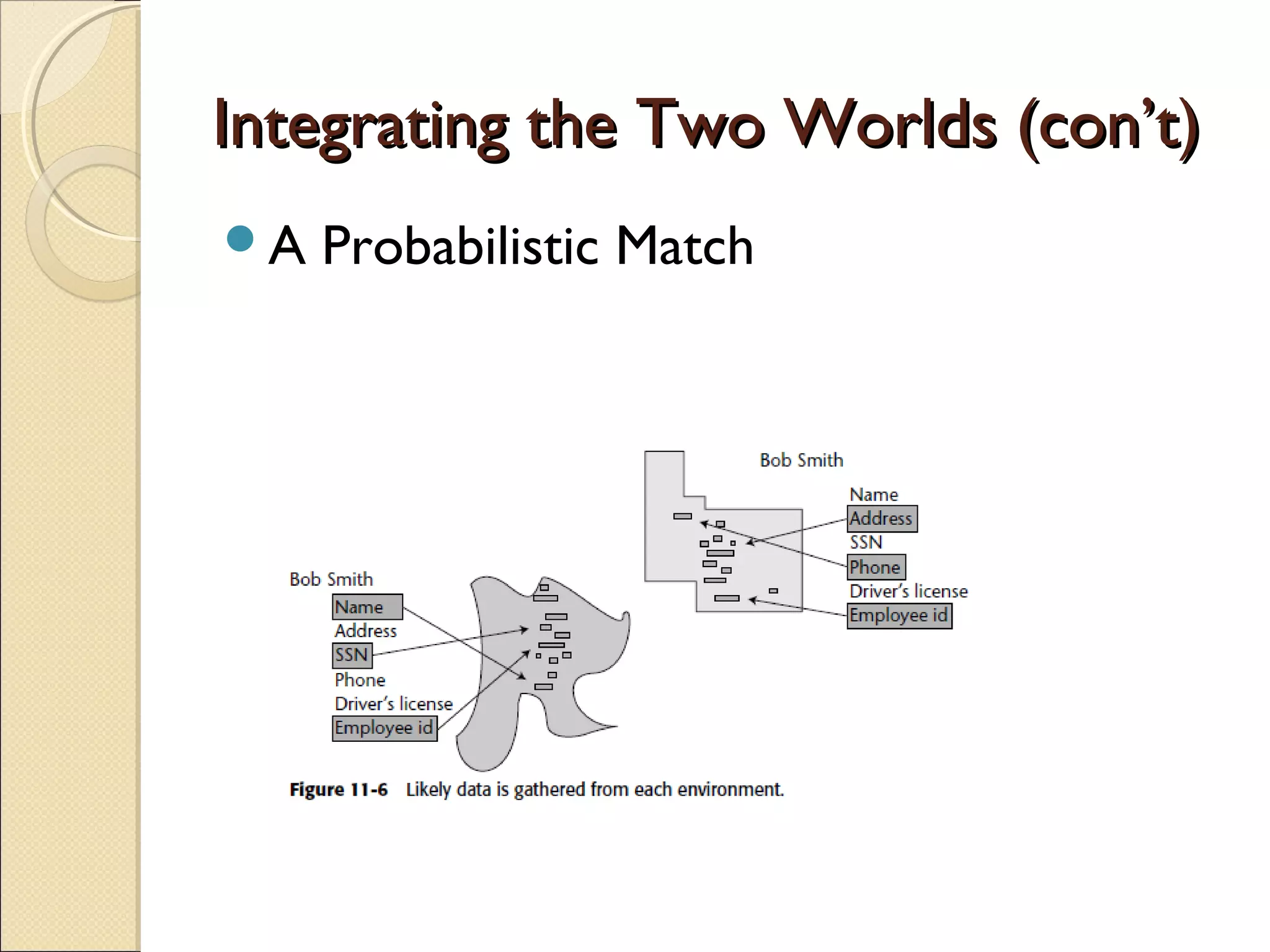
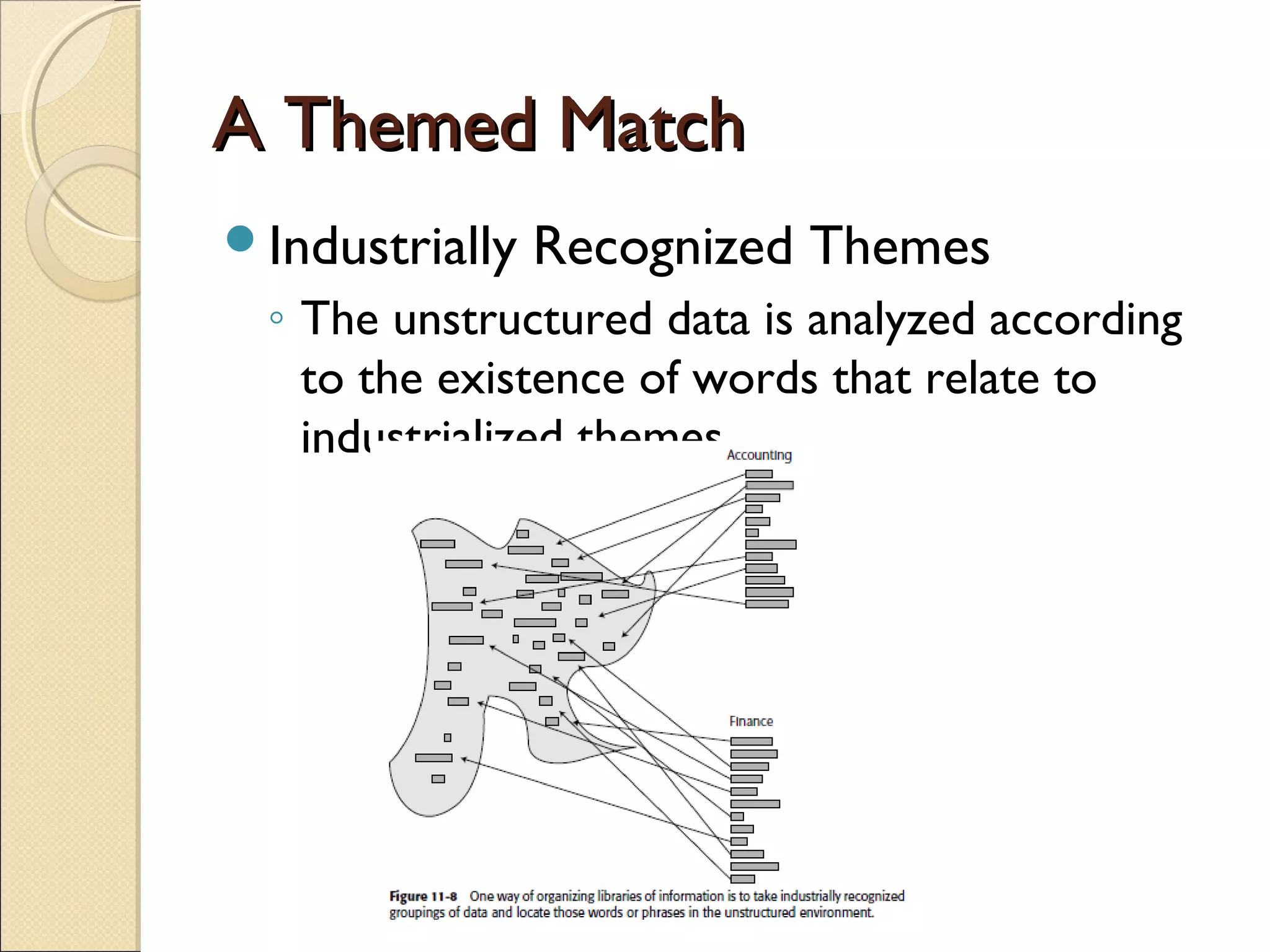
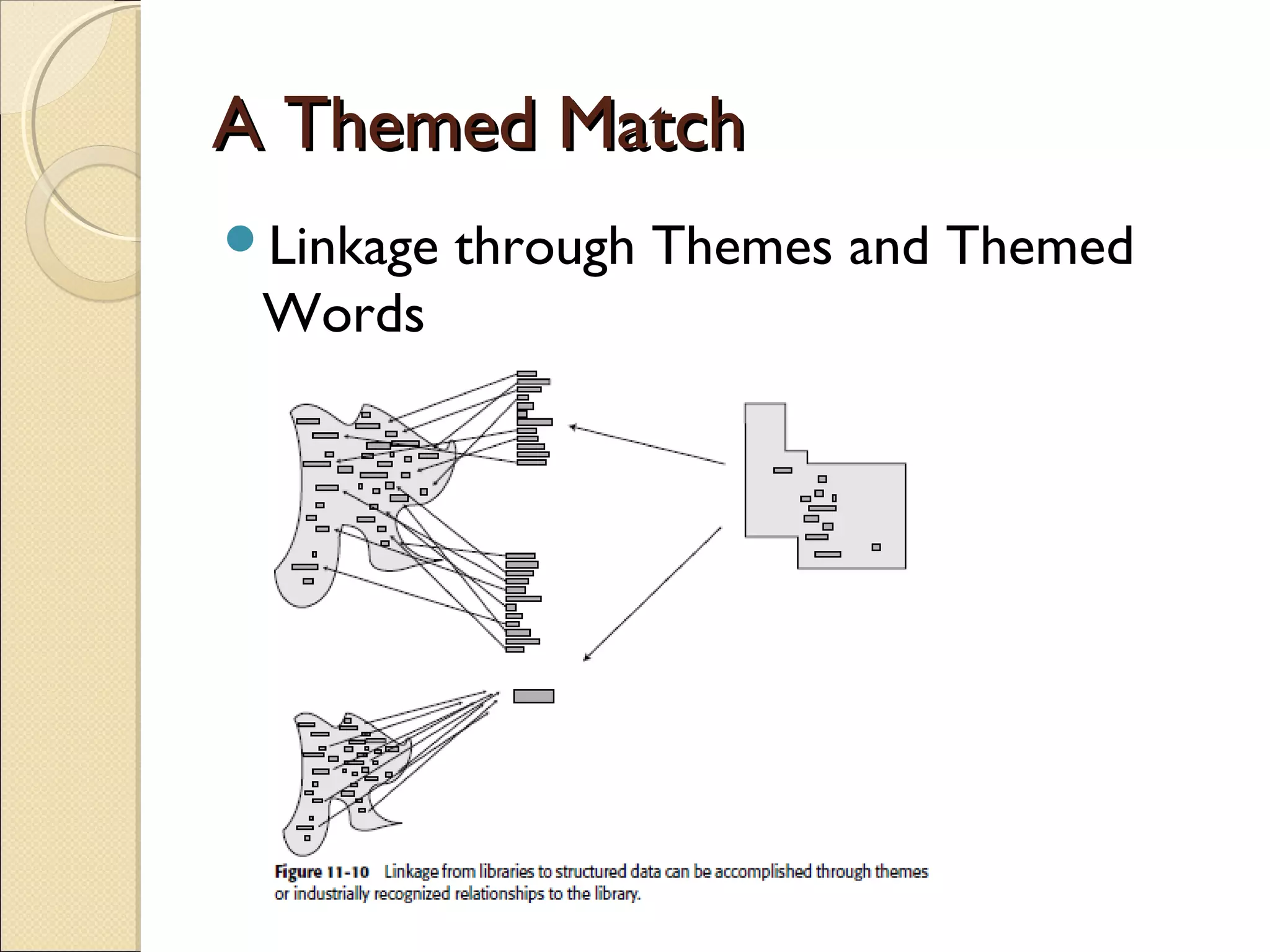
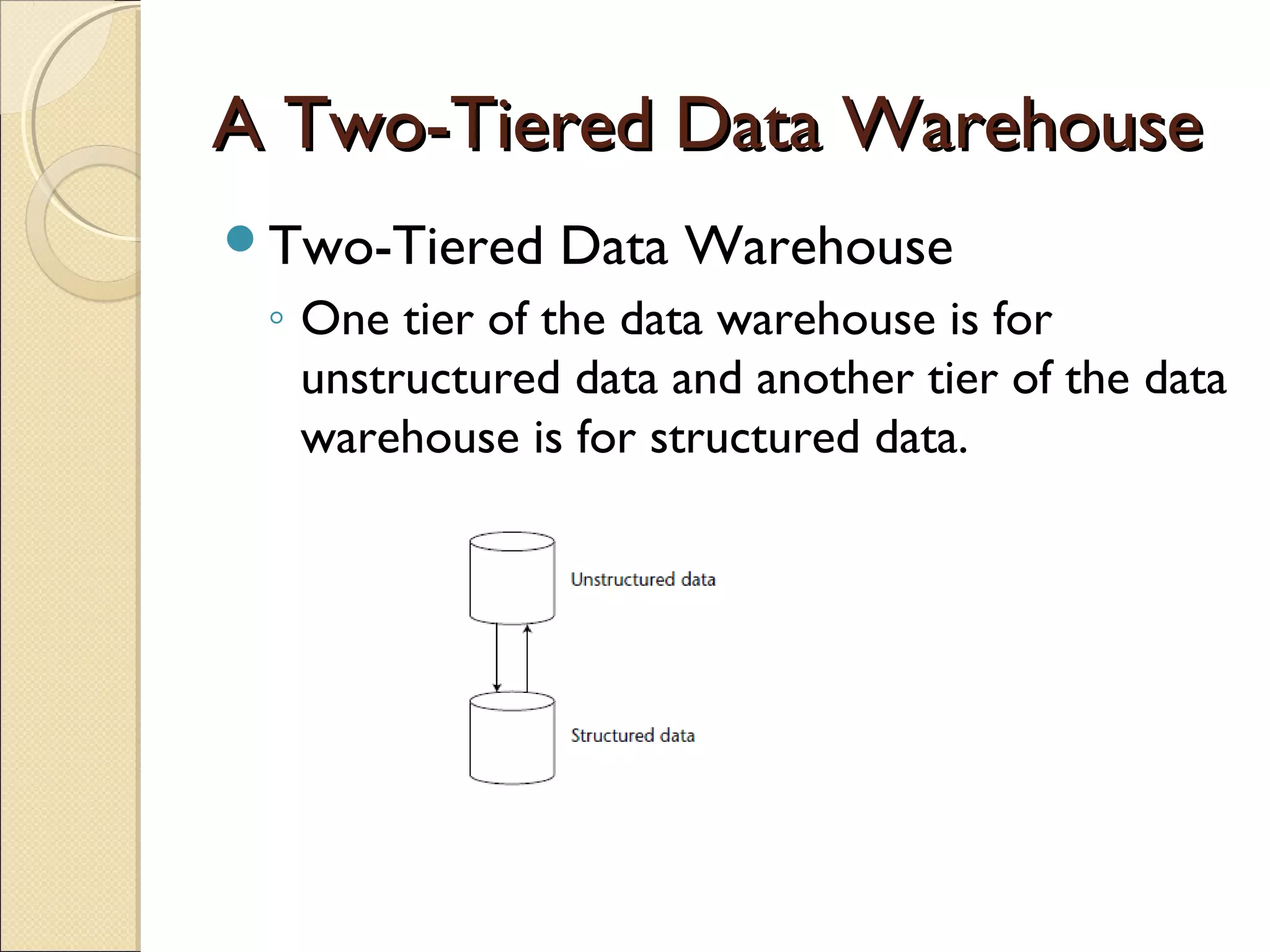
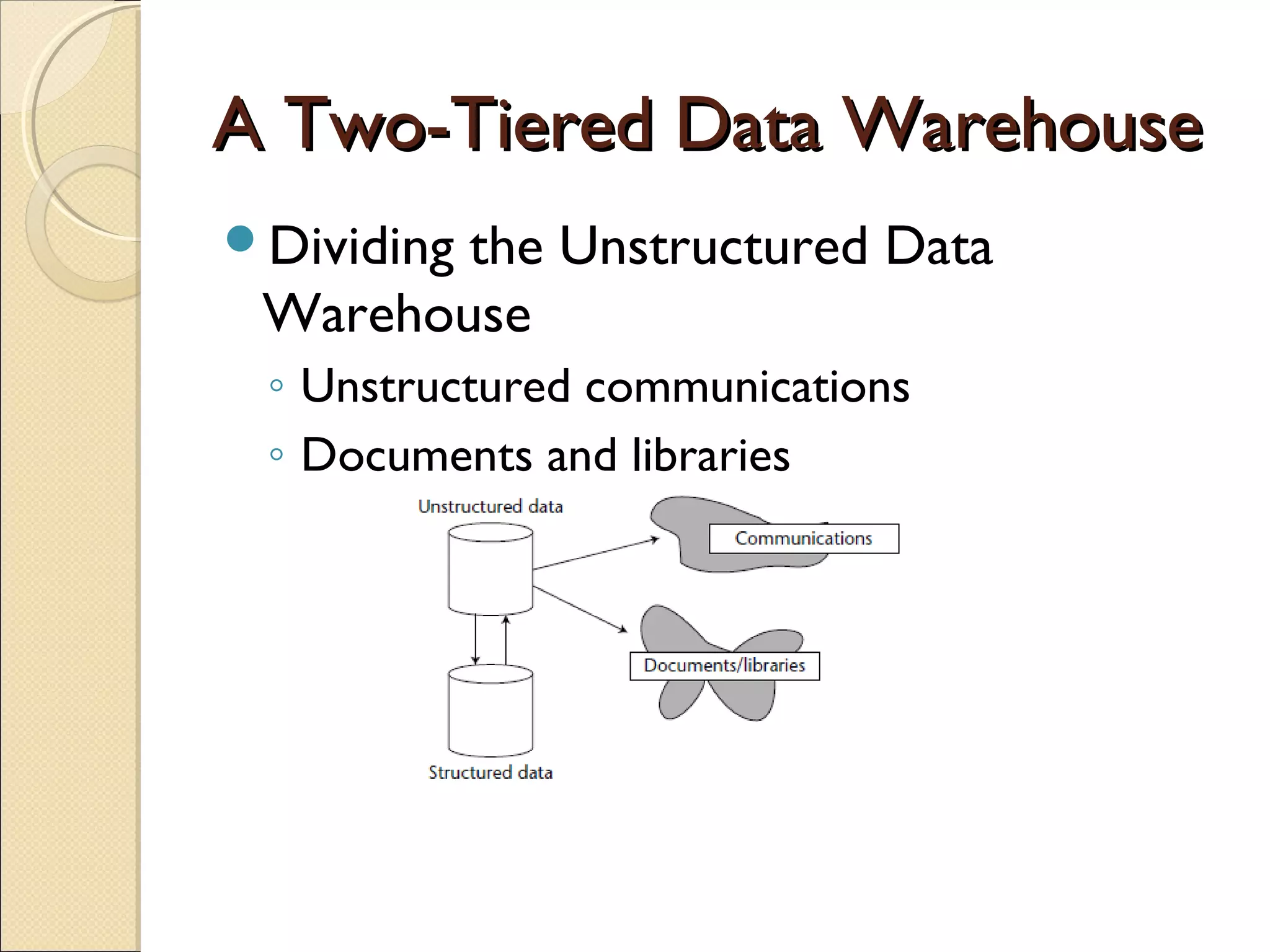
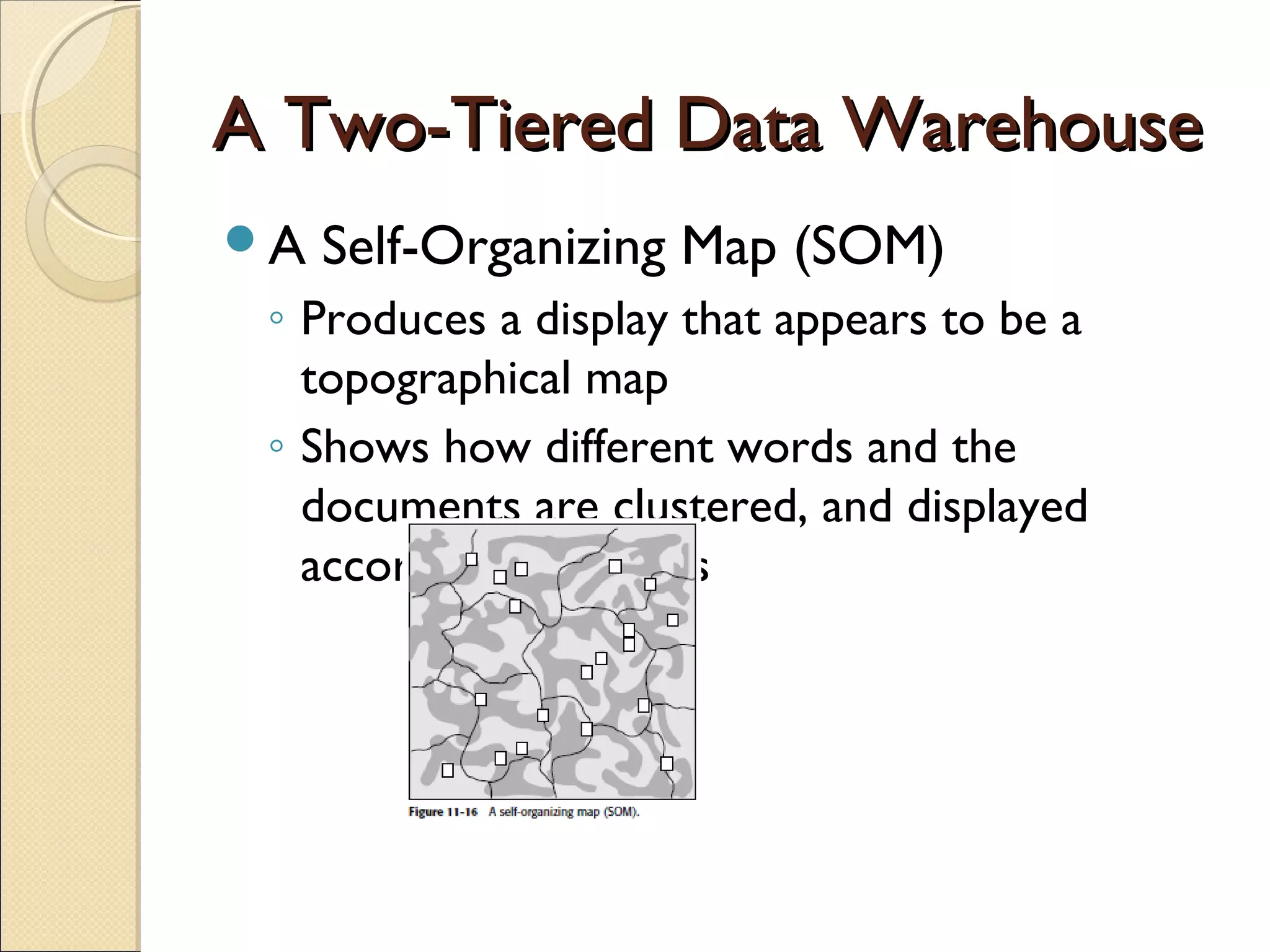
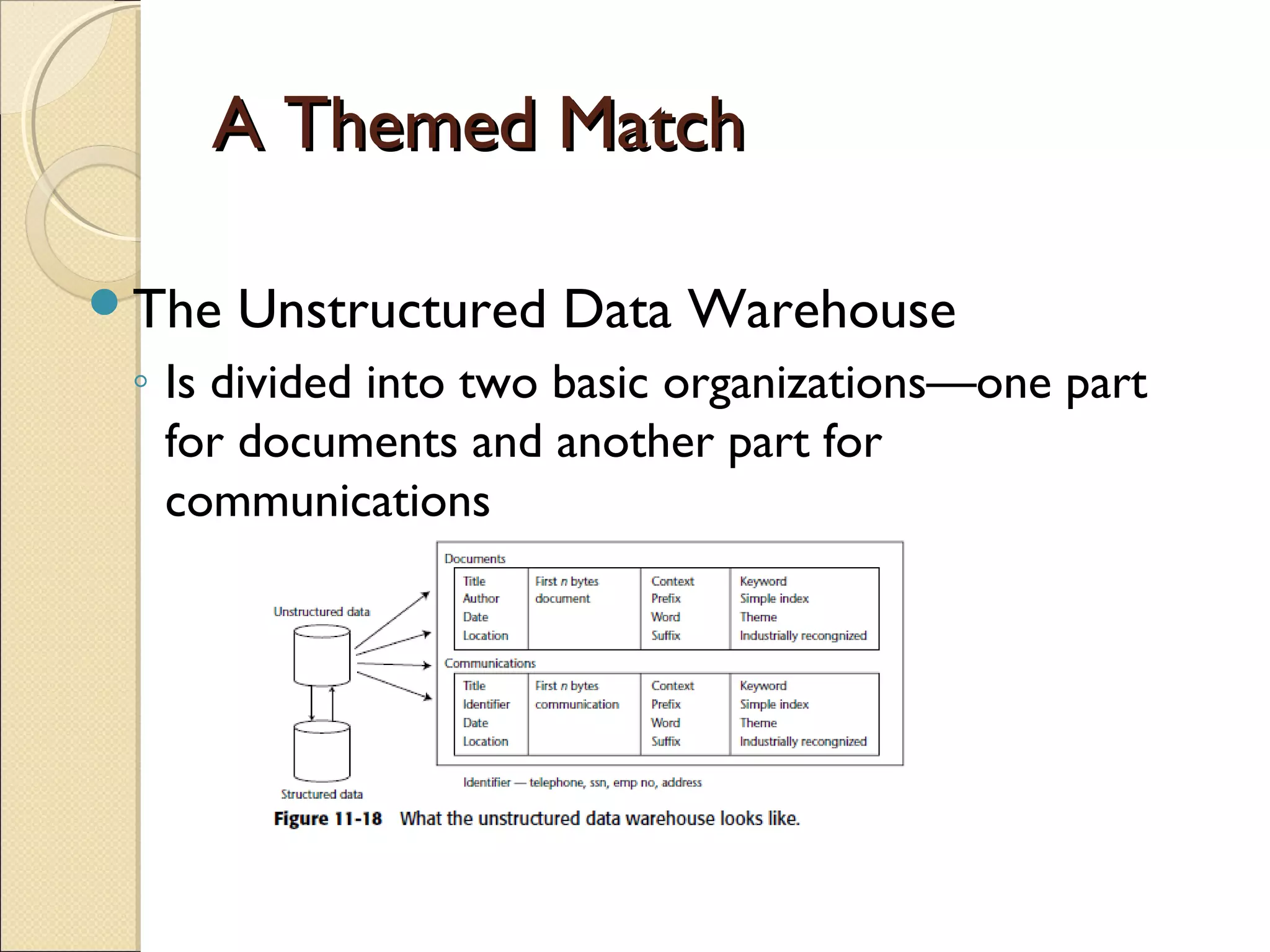
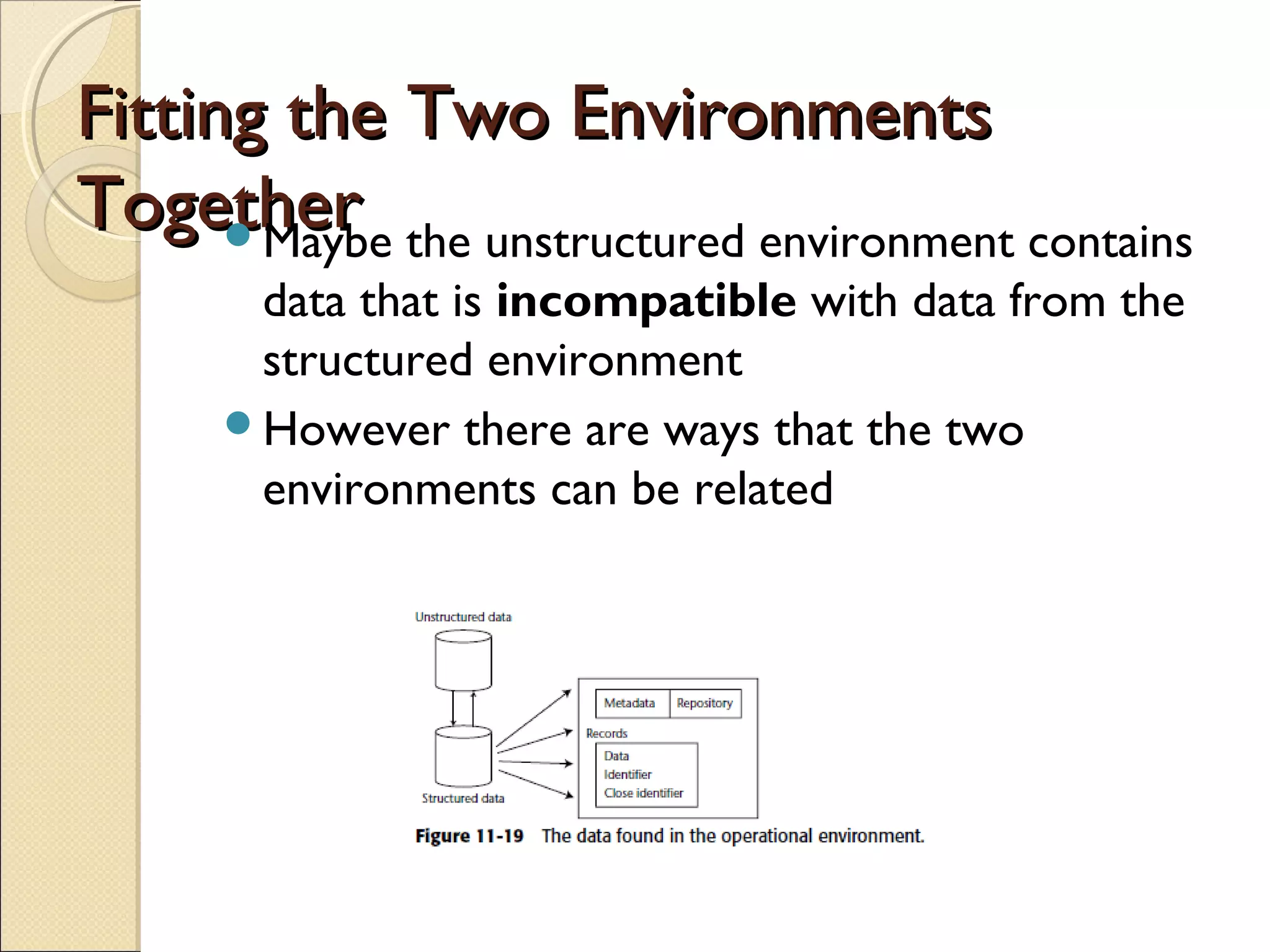
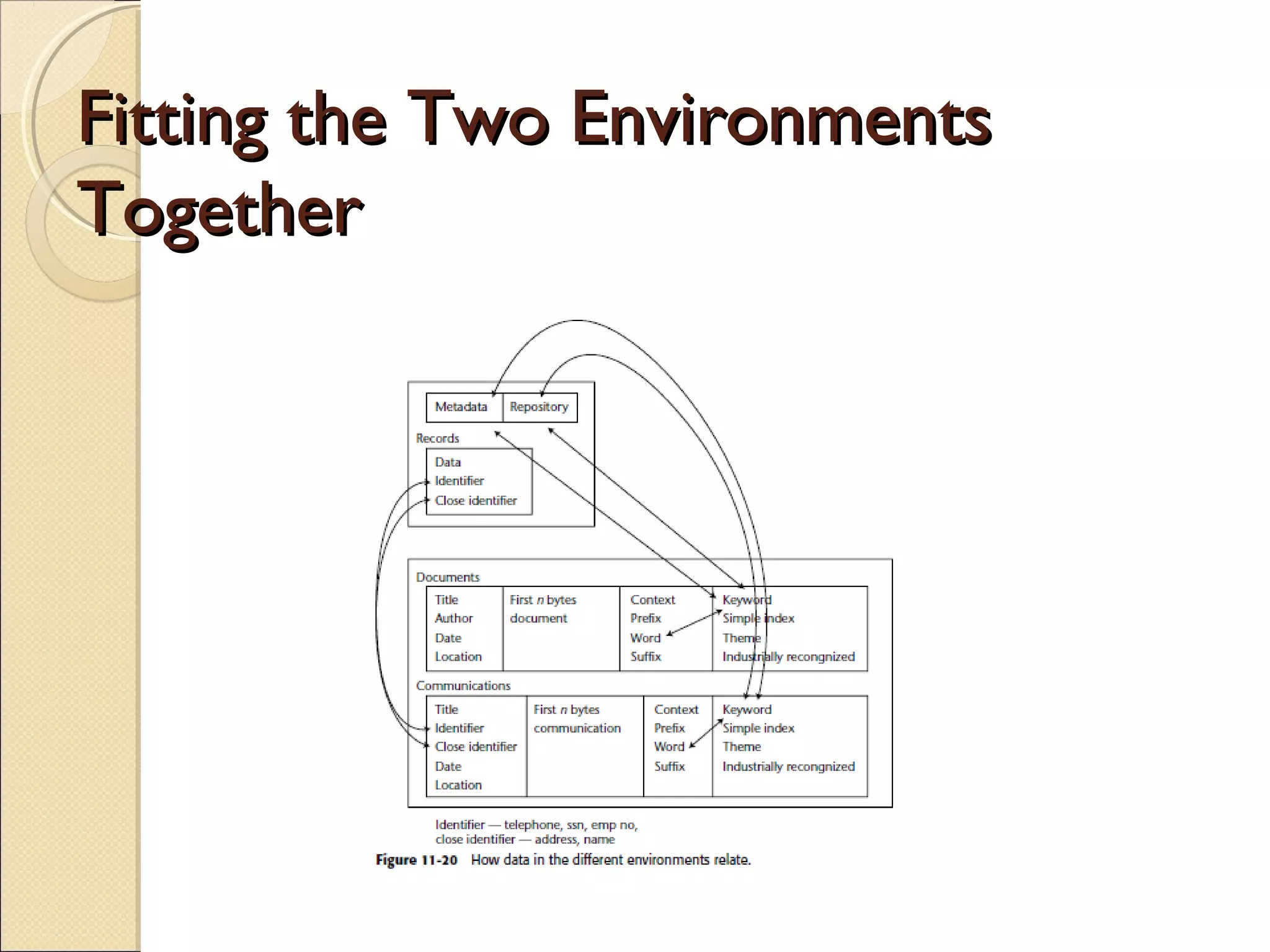
This chapter discusses integrating structured and unstructured data in a data warehouse. It presents methods like using common text to link the two environments, employing a two-tiered structure with separate warehouses for structured and unstructured data, and using techniques like self-organizing maps to visualize unstructured data. The goal is to find ways to relate the different data types while addressing issues like incompatible formats and large unstructured data volumes.