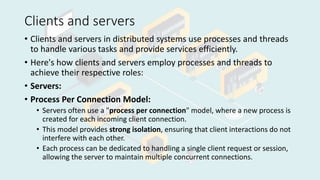
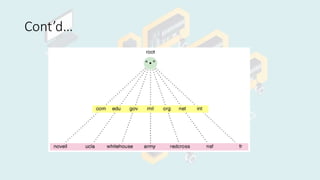
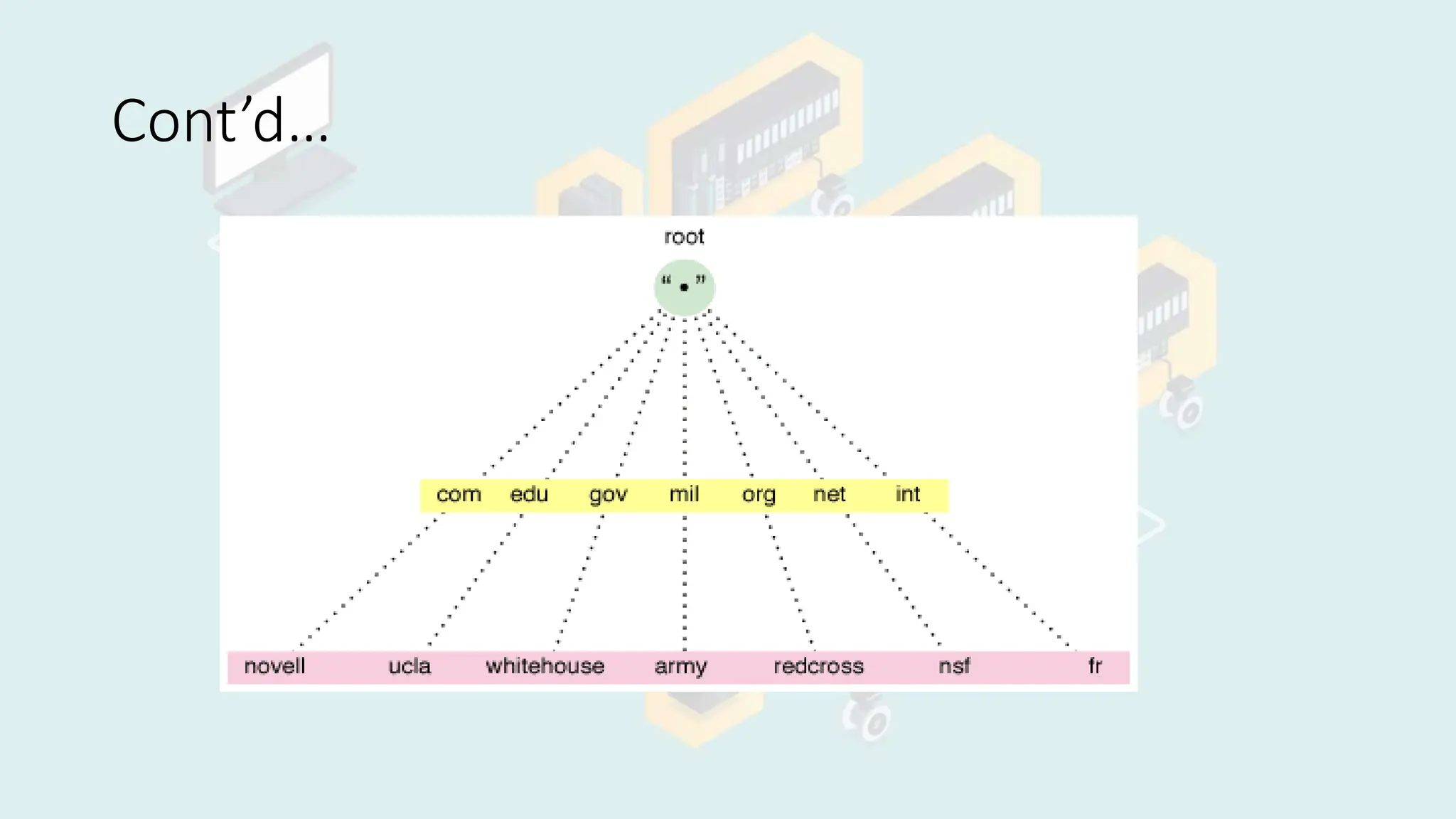
The document discusses processes and threads in distributed systems. It defines processes and threads, describing how they enable concurrency, efficient resource management, and overall system performance. Processes provide isolation between programs and dedicated resources, while threads allow for efficient sharing of resources within a process. Clients and servers employ processes and threads to handle tasks concurrently and distribute load. The document then covers naming, name resolution, name services, namespaces, and different naming schemes used in distributed systems, such as flat, hierarchical, and semantic naming. Namespaces organize naming to prevent conflicts, and name resolution maps names to network addresses.