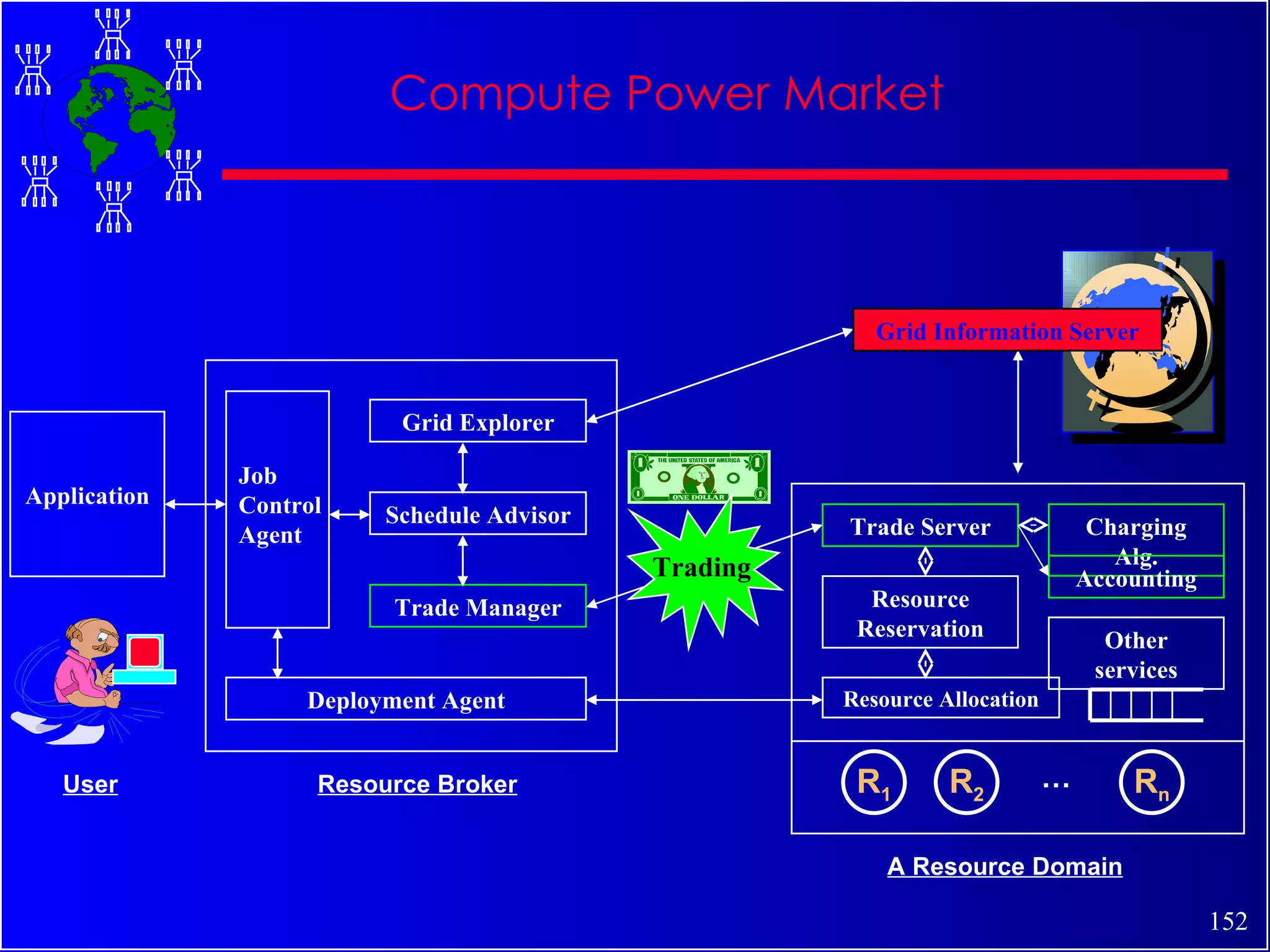
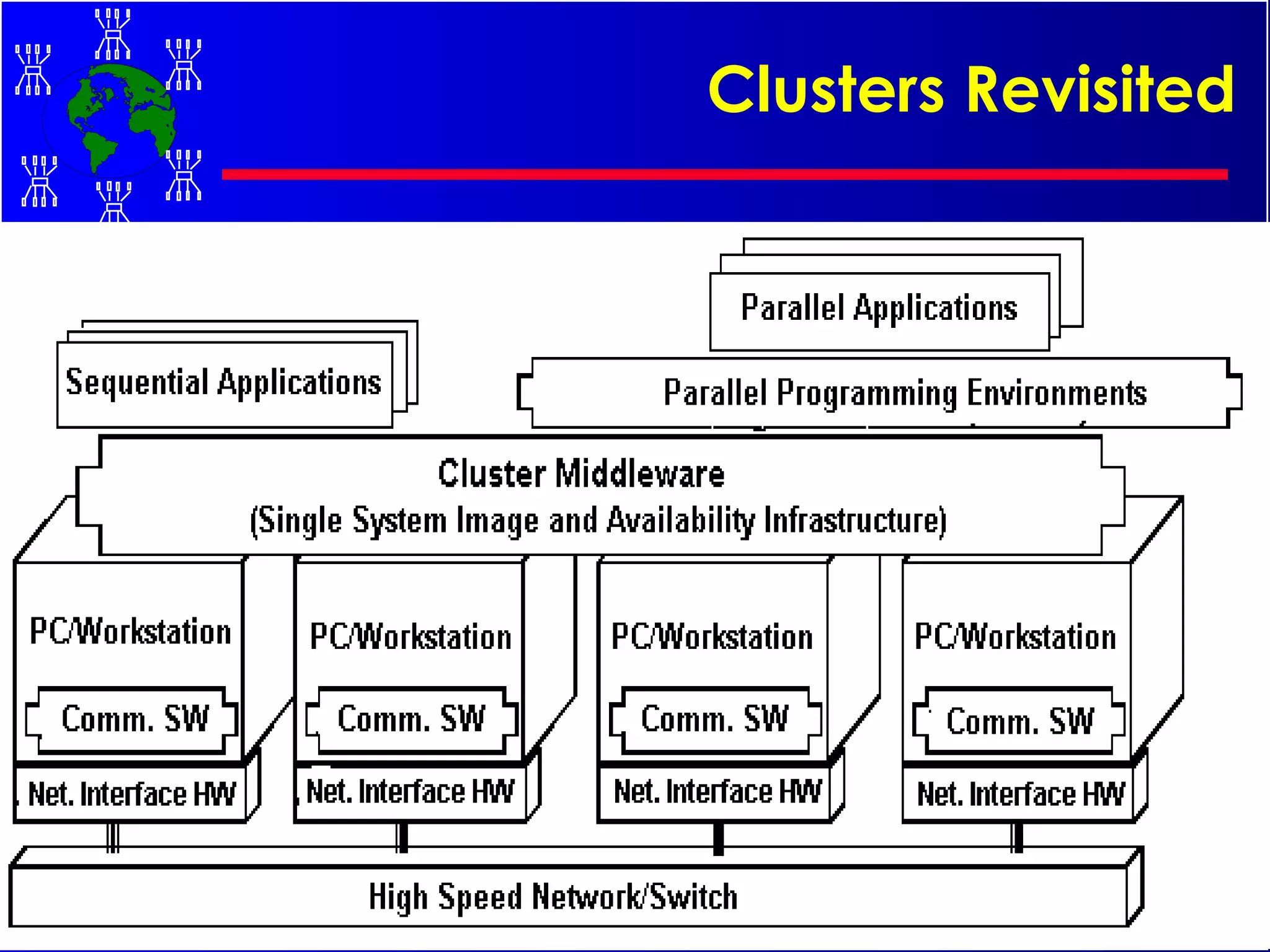
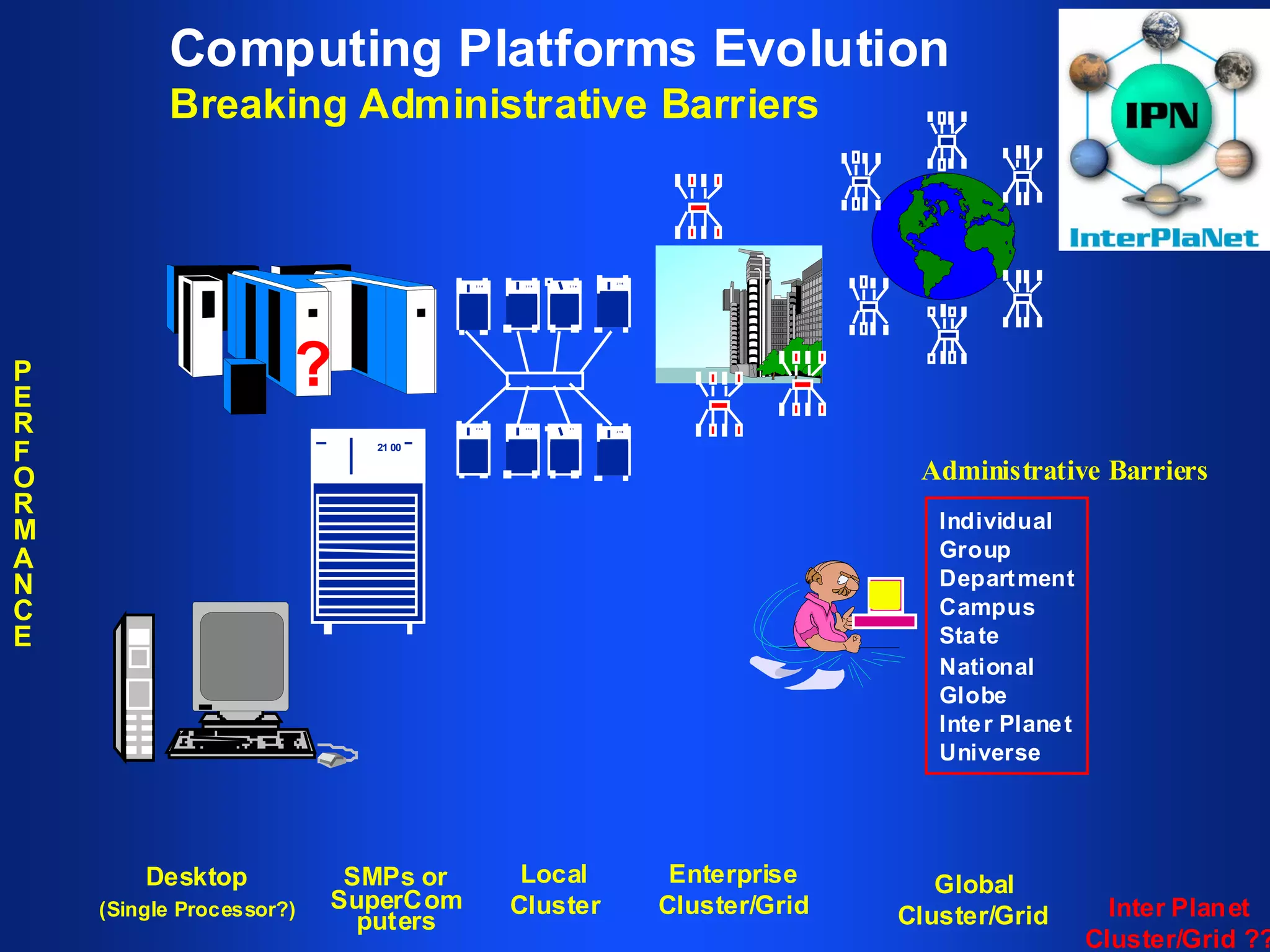
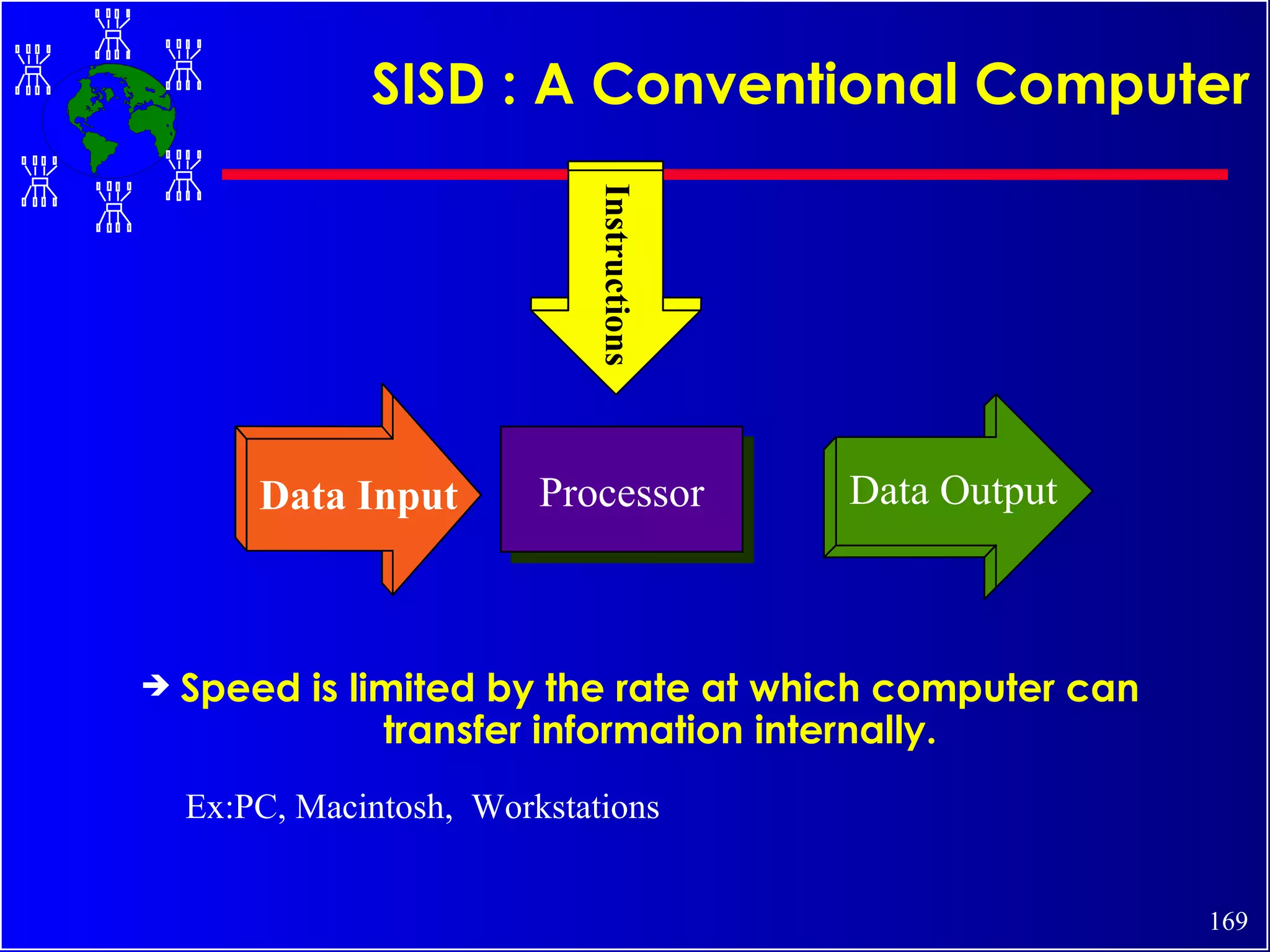
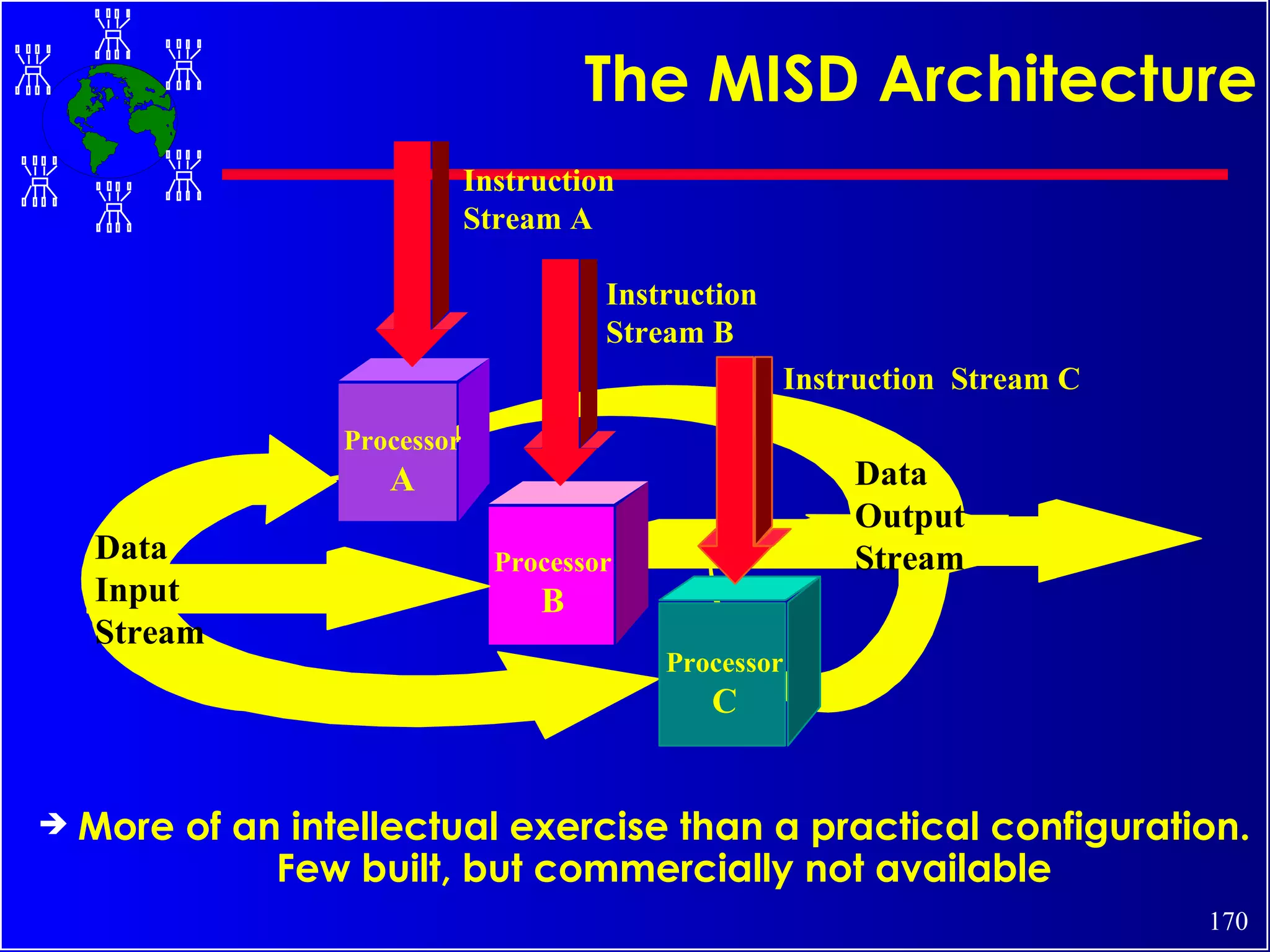
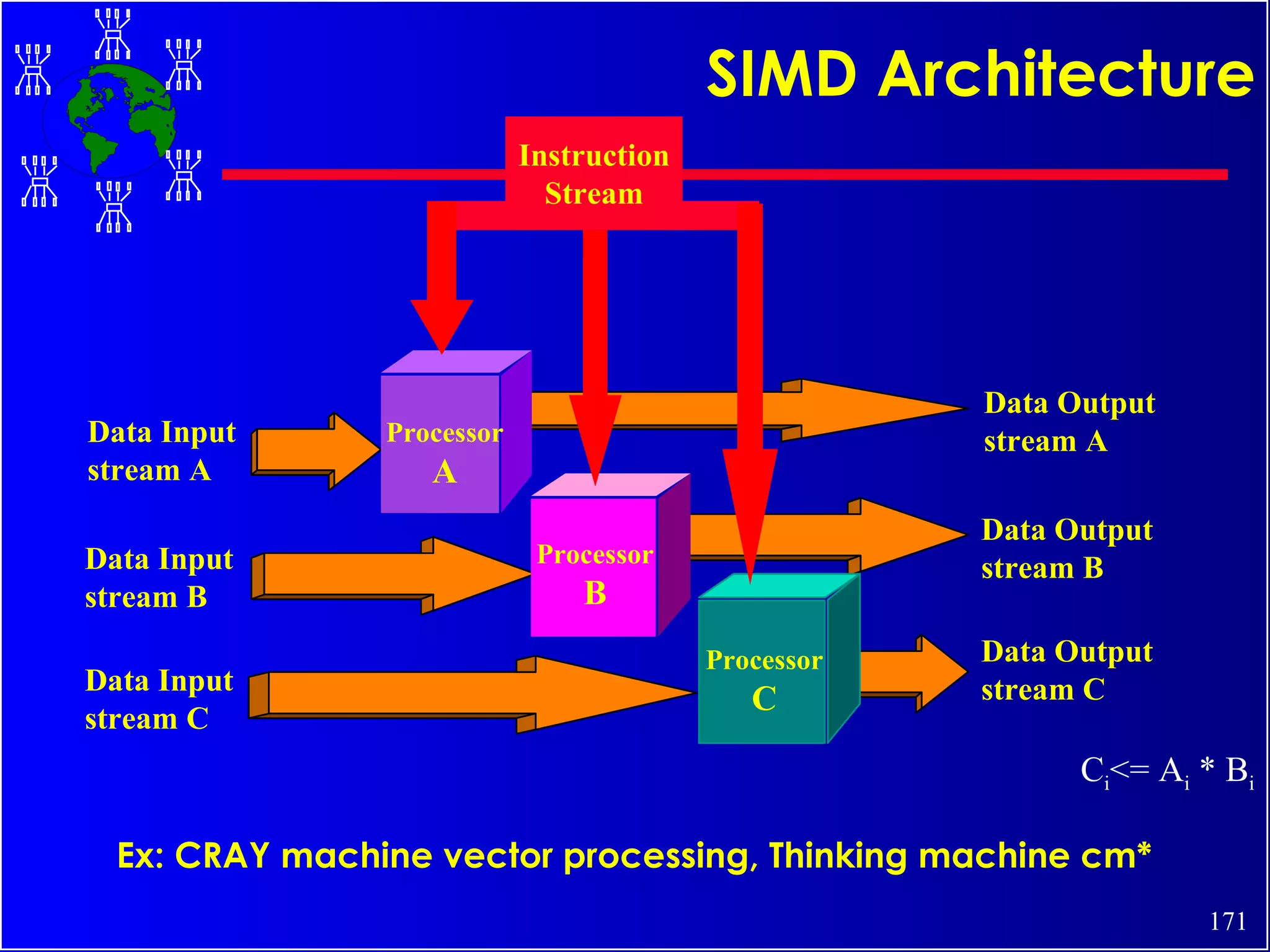
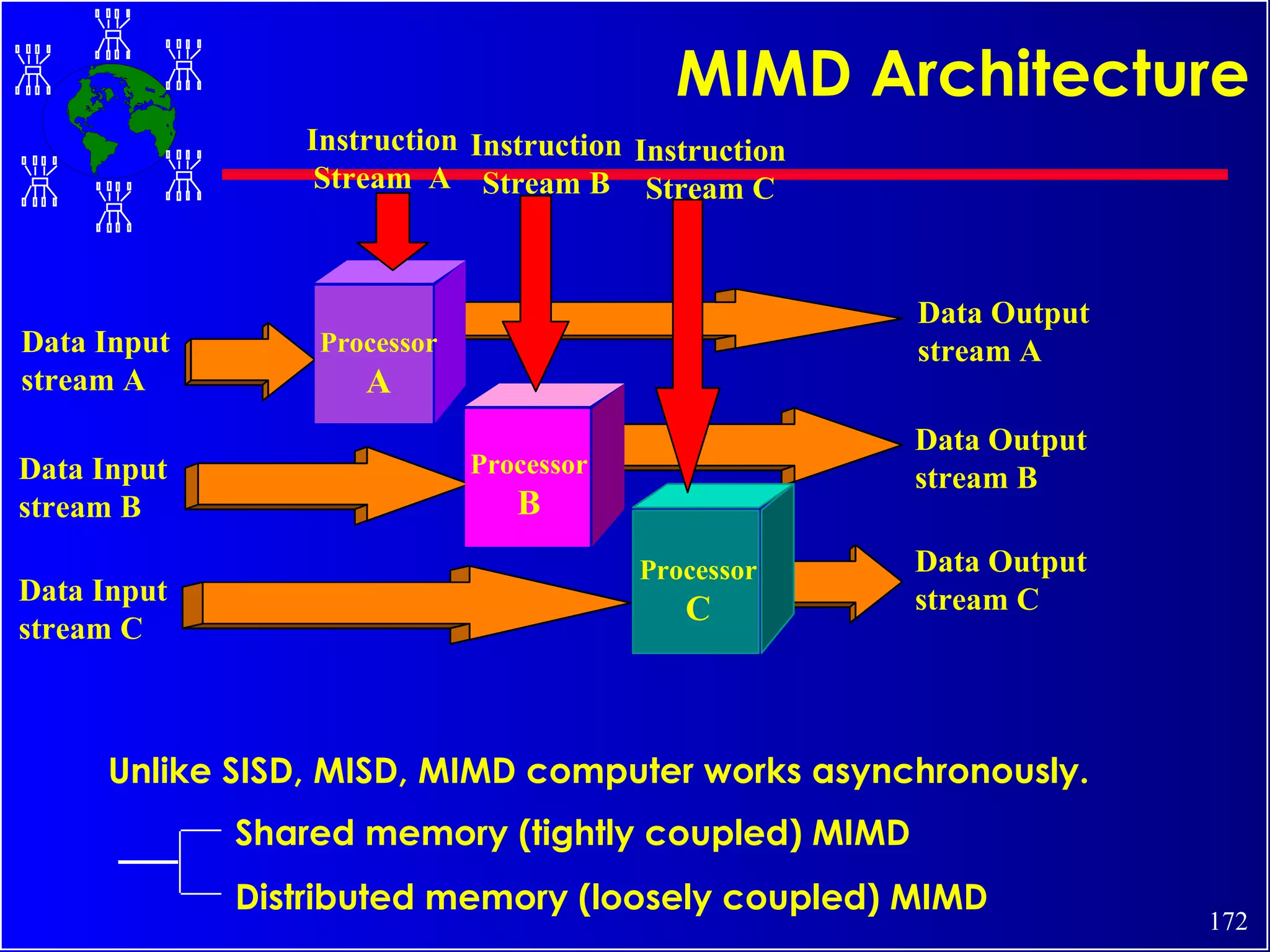
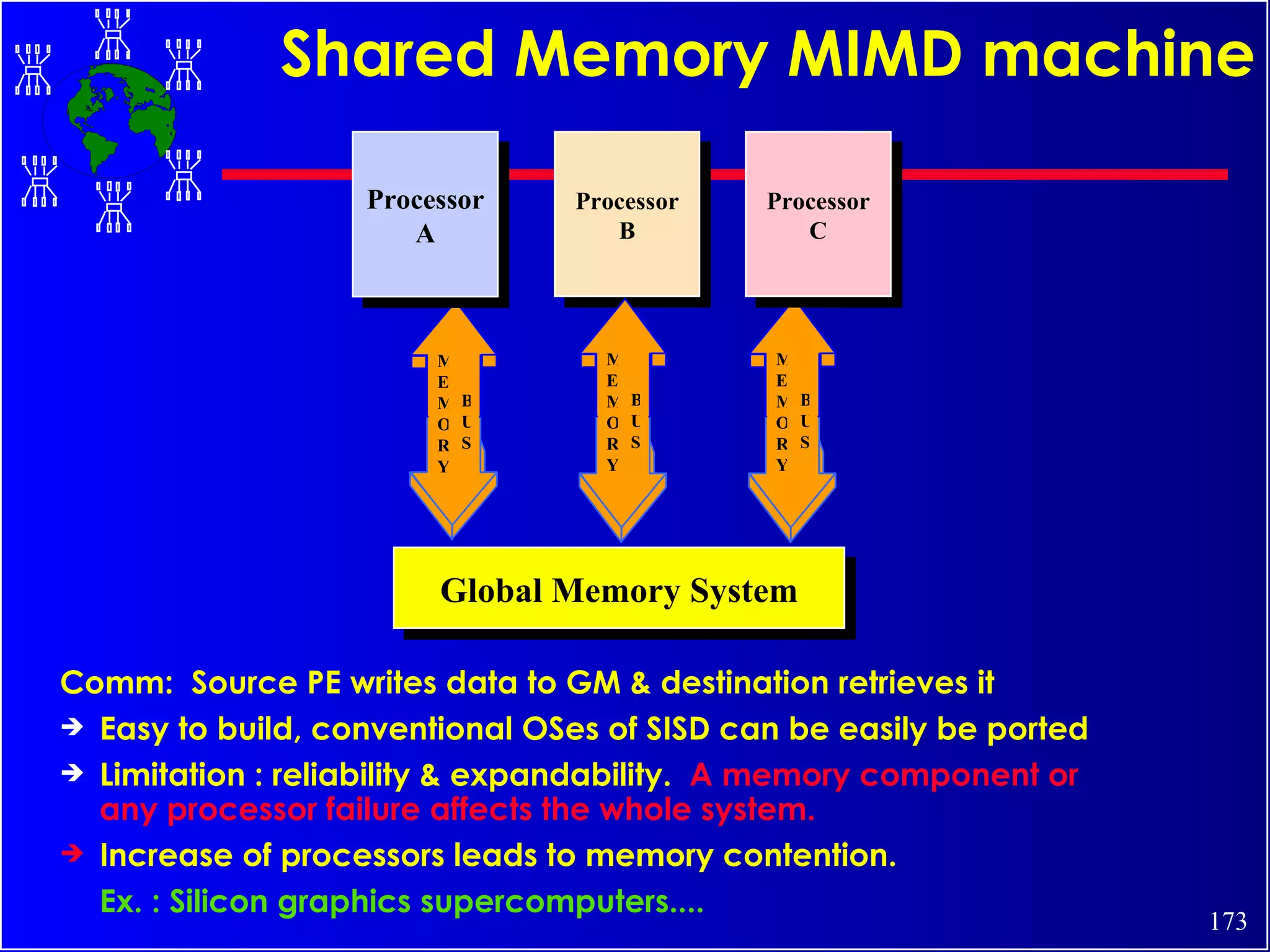
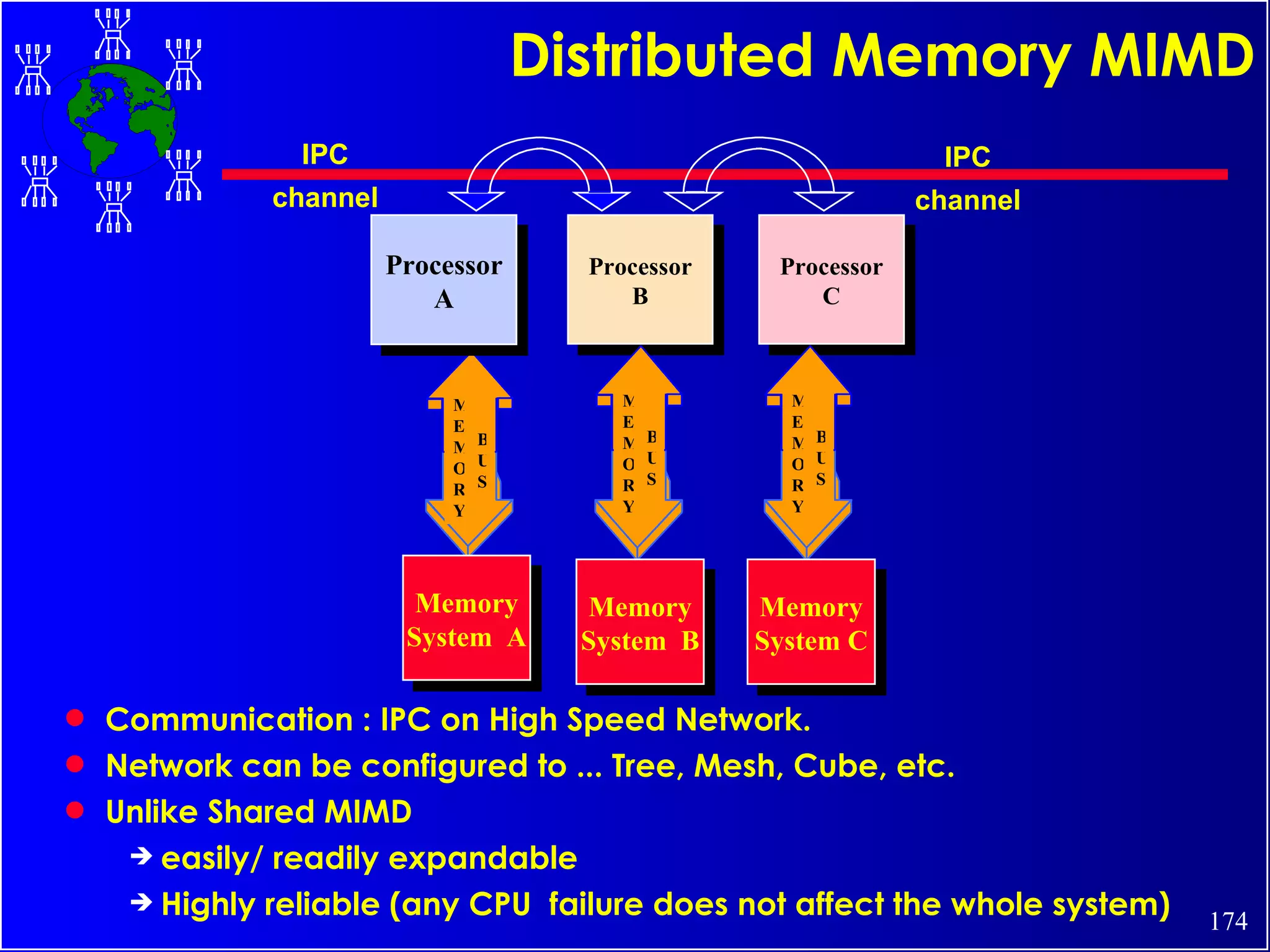
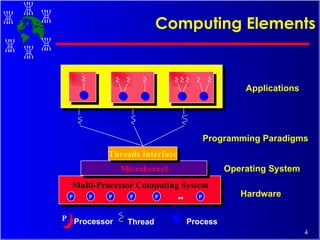
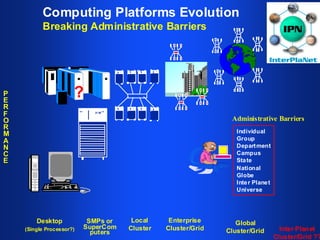
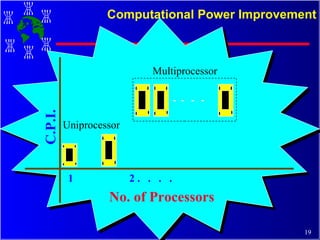
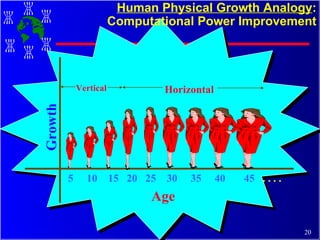
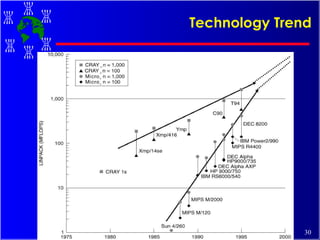
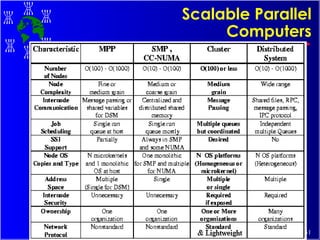
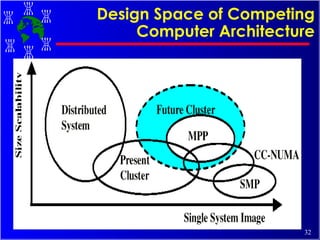
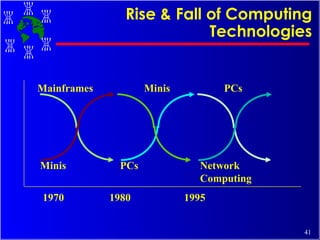
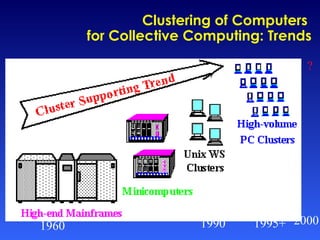
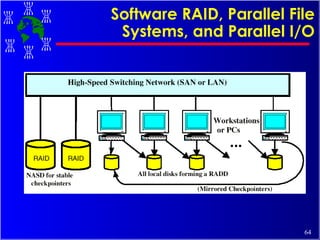
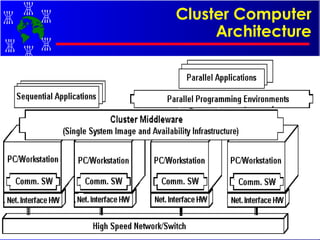
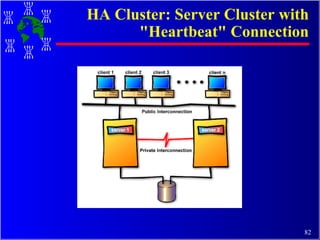
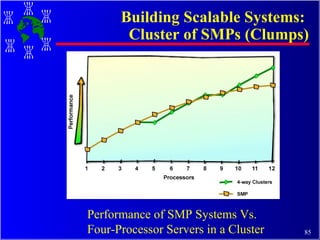
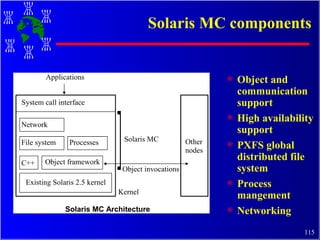
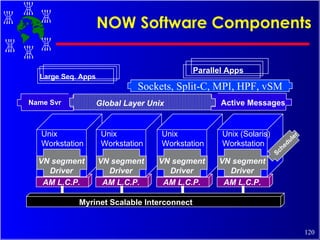
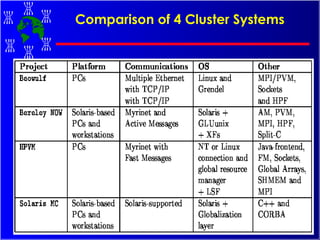
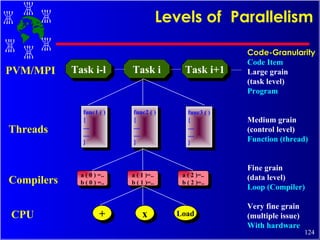
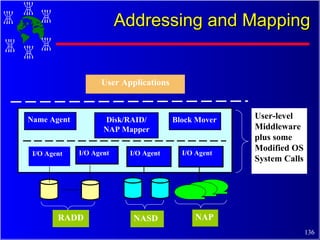
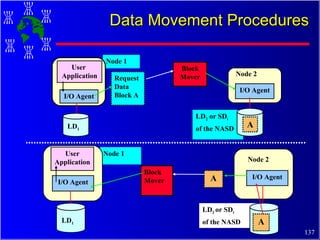
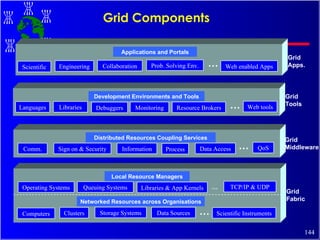
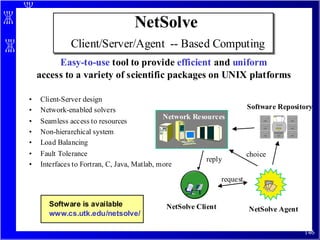
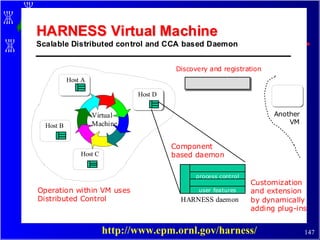
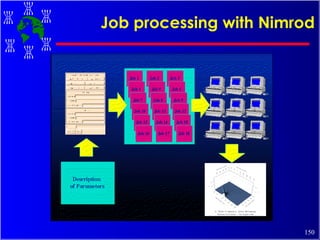
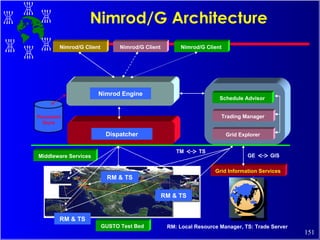
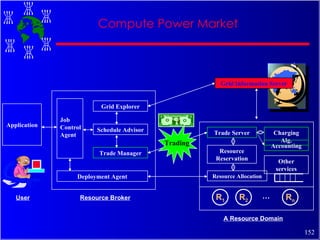
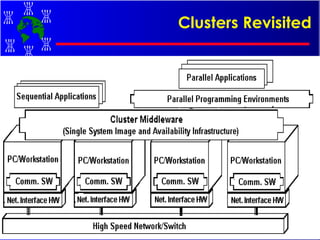
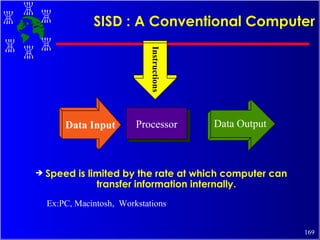
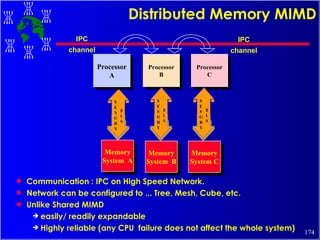
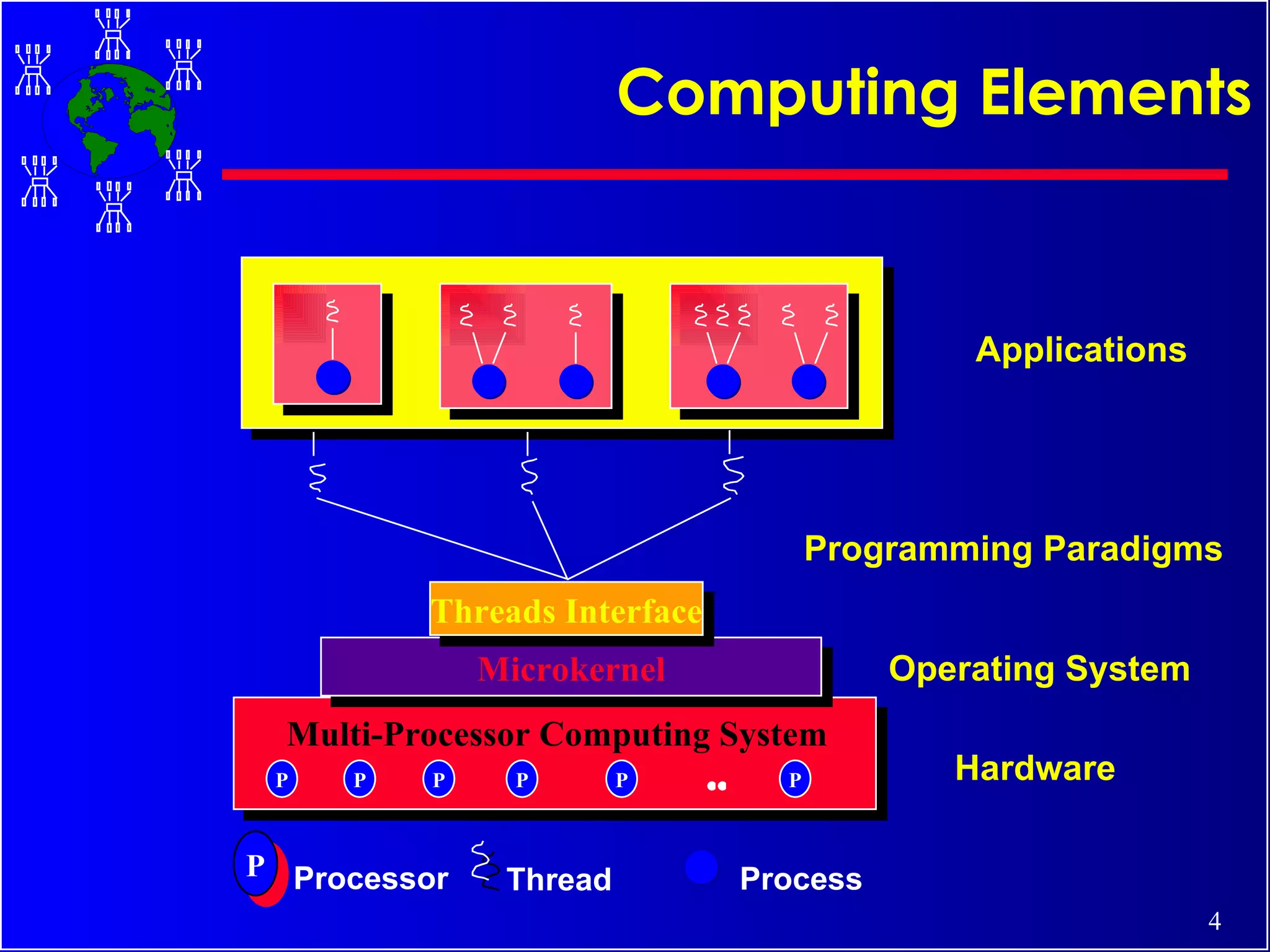
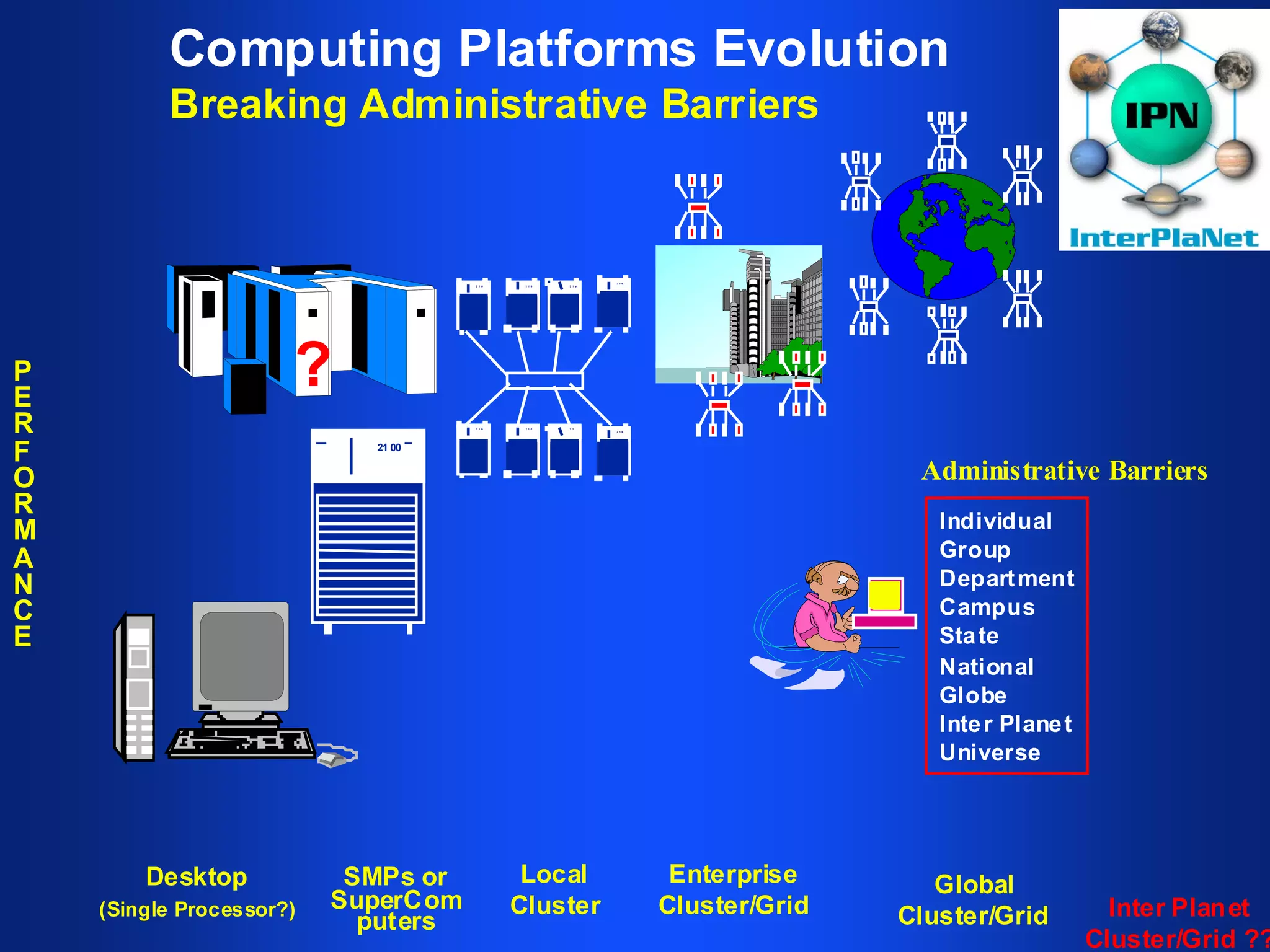
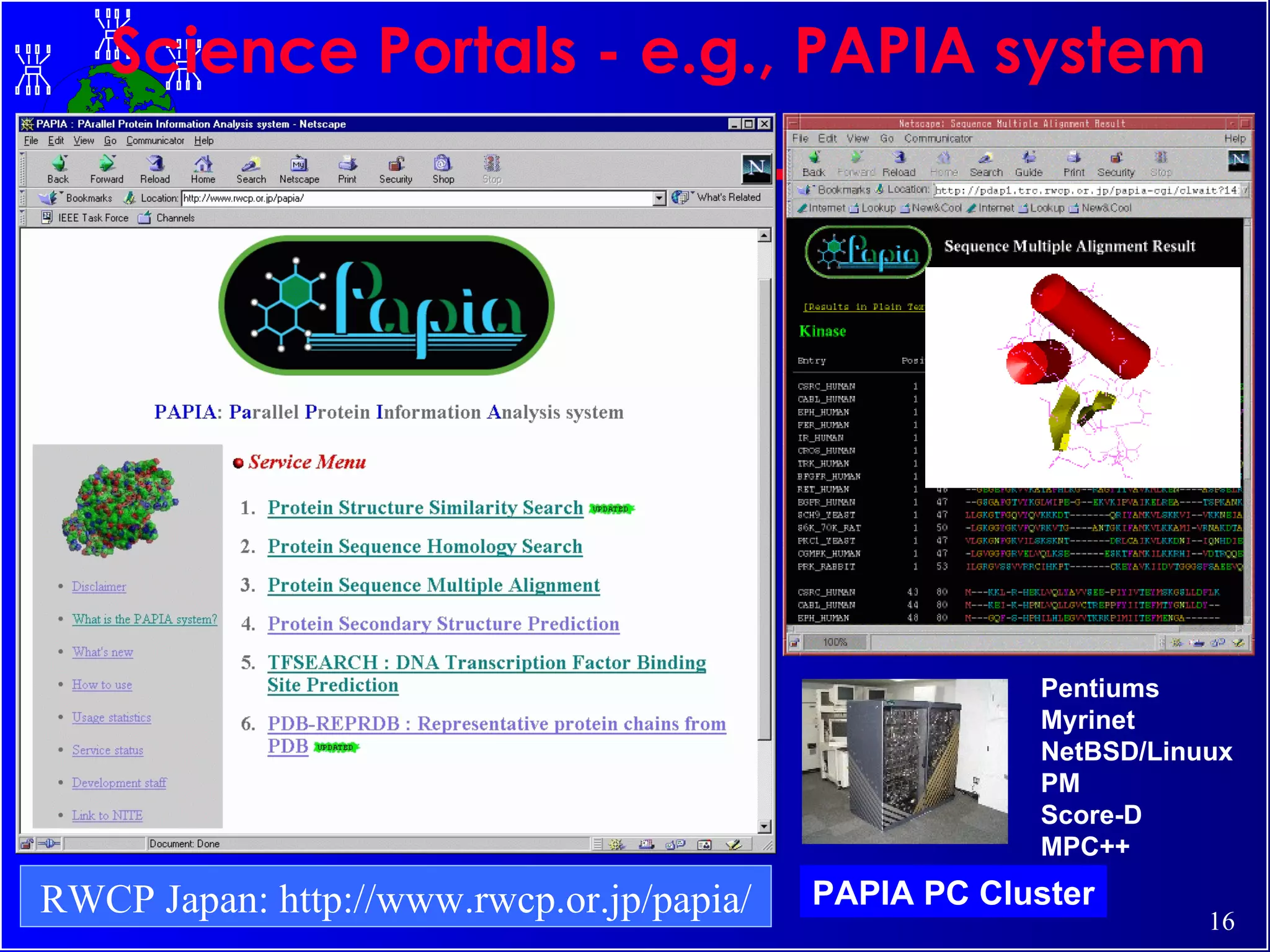
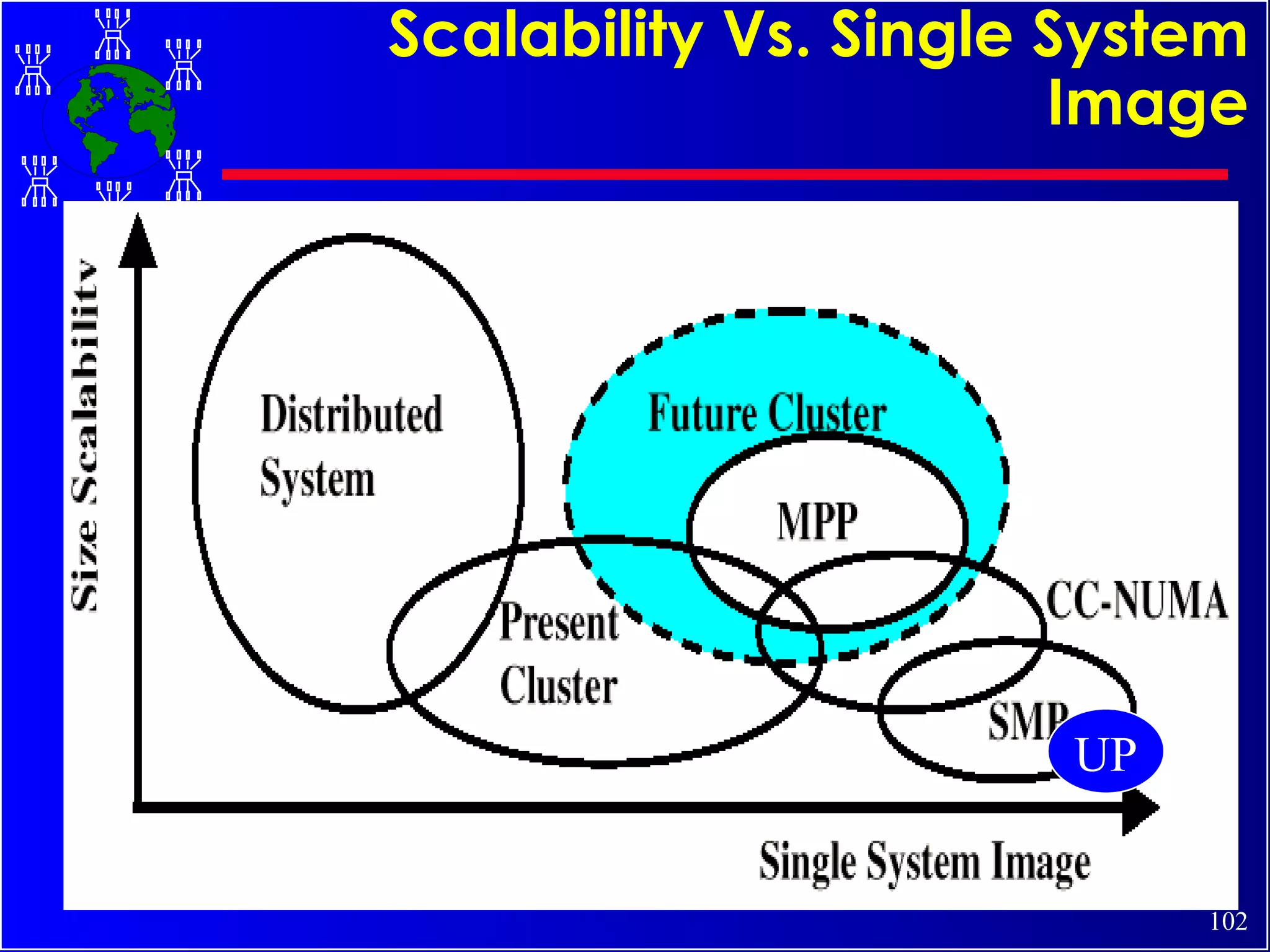
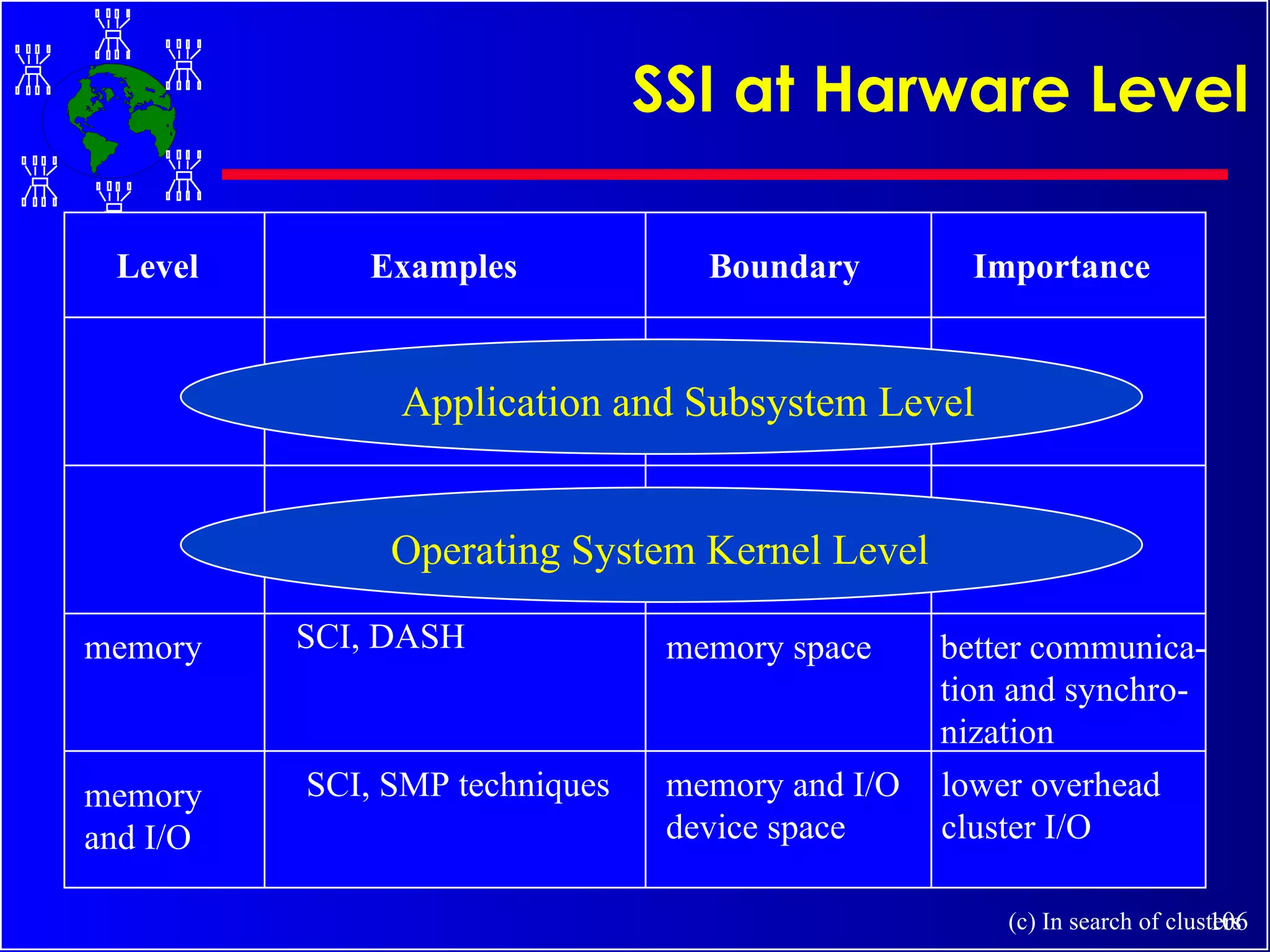
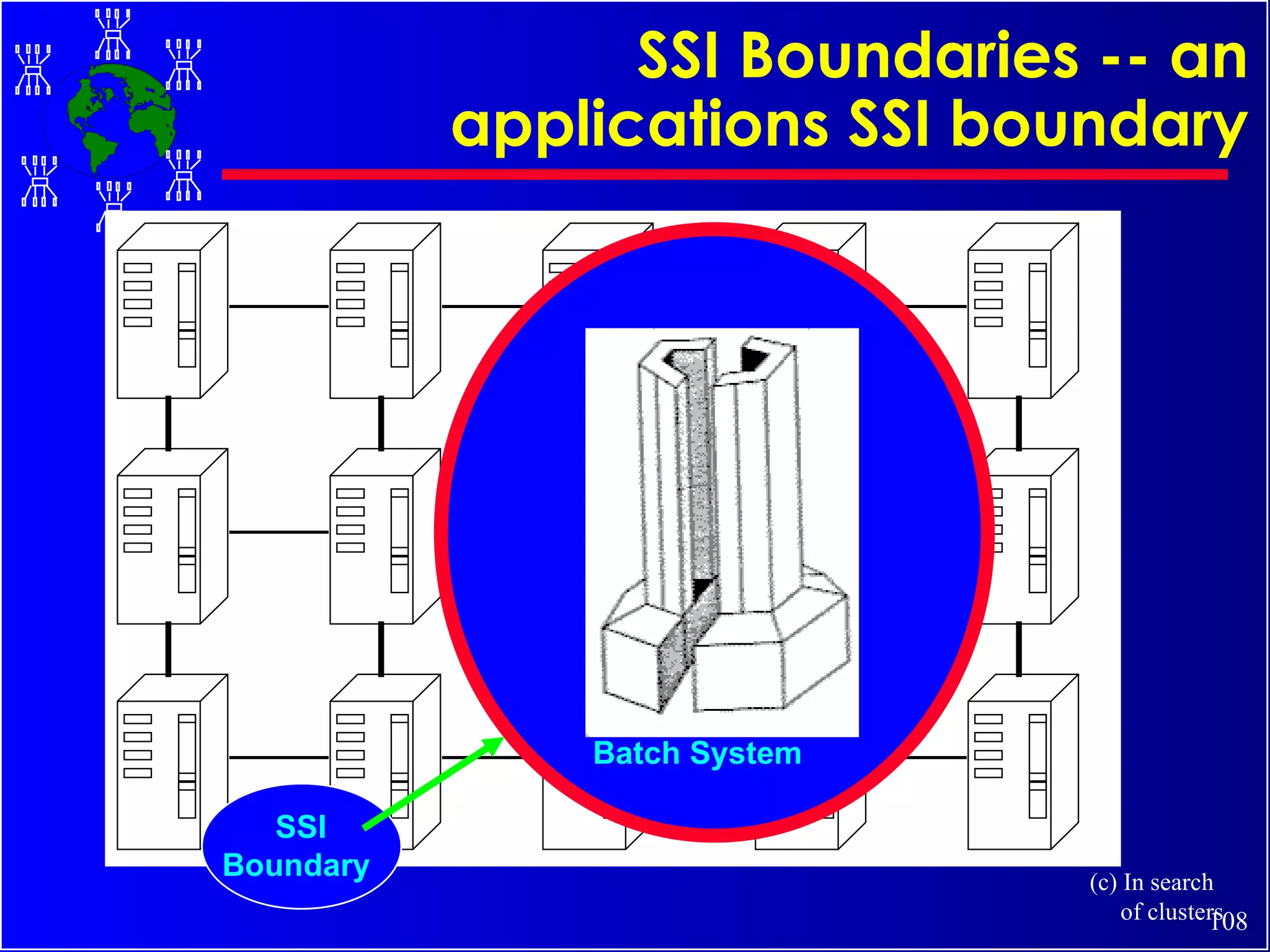
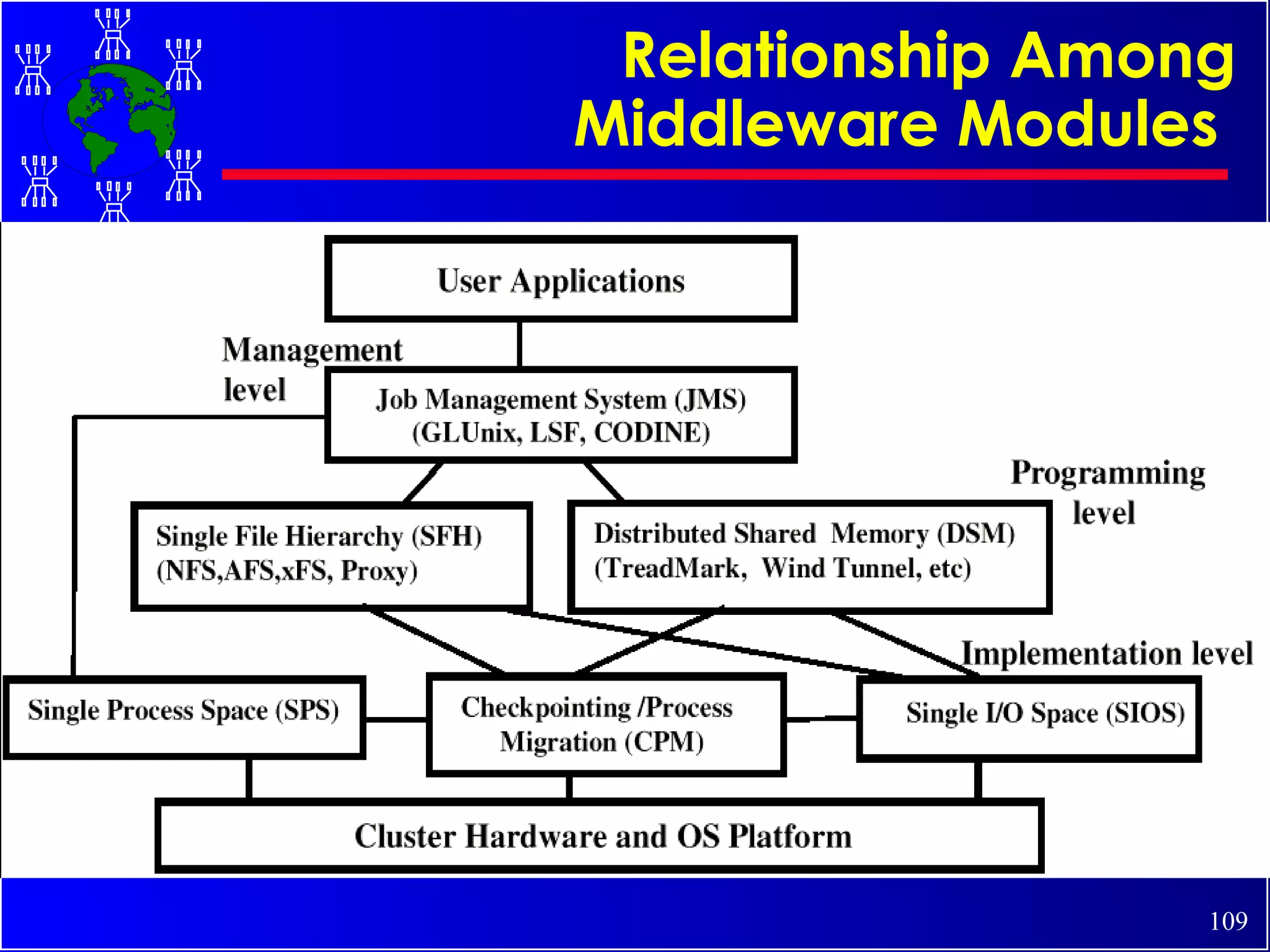
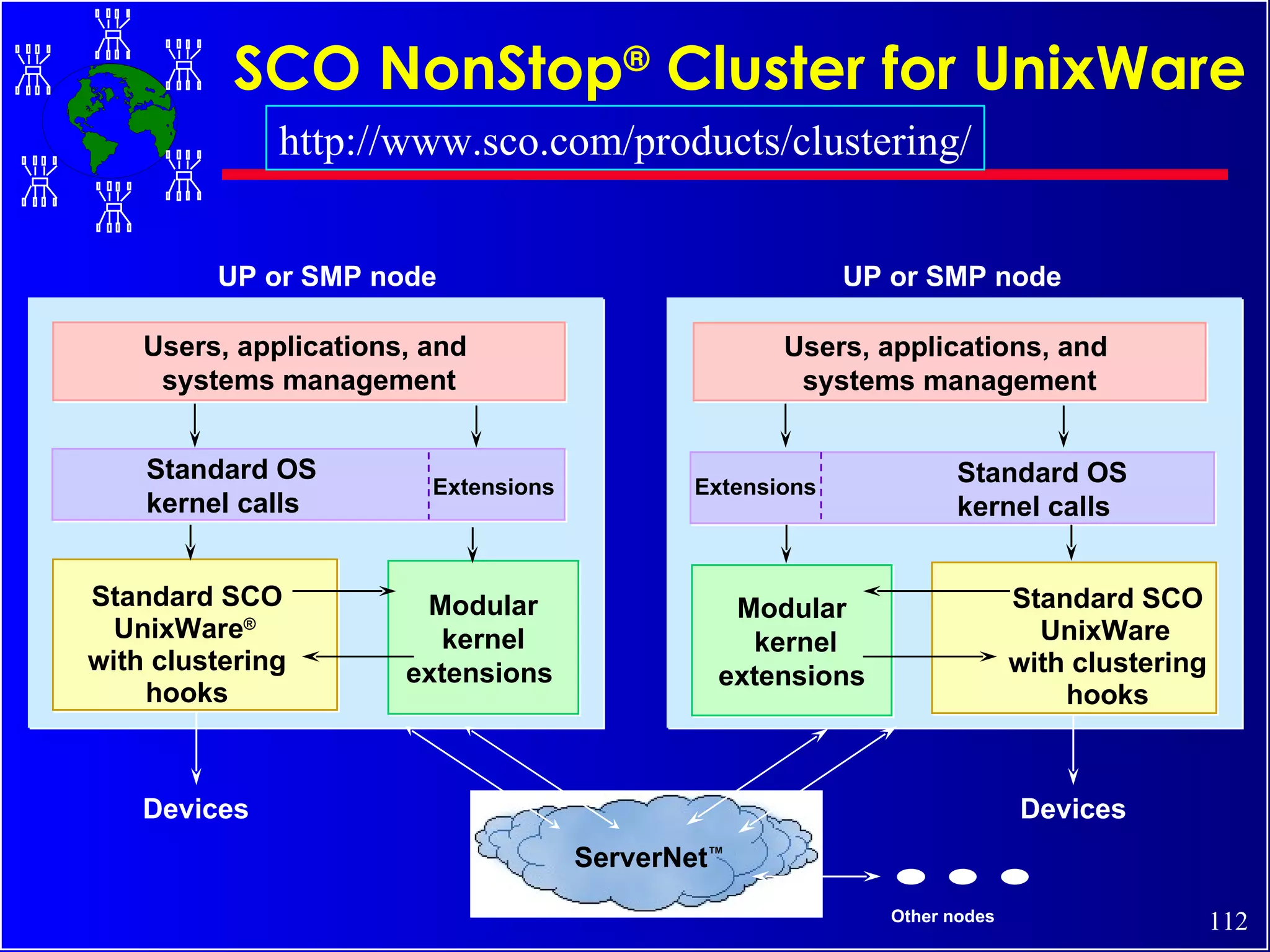
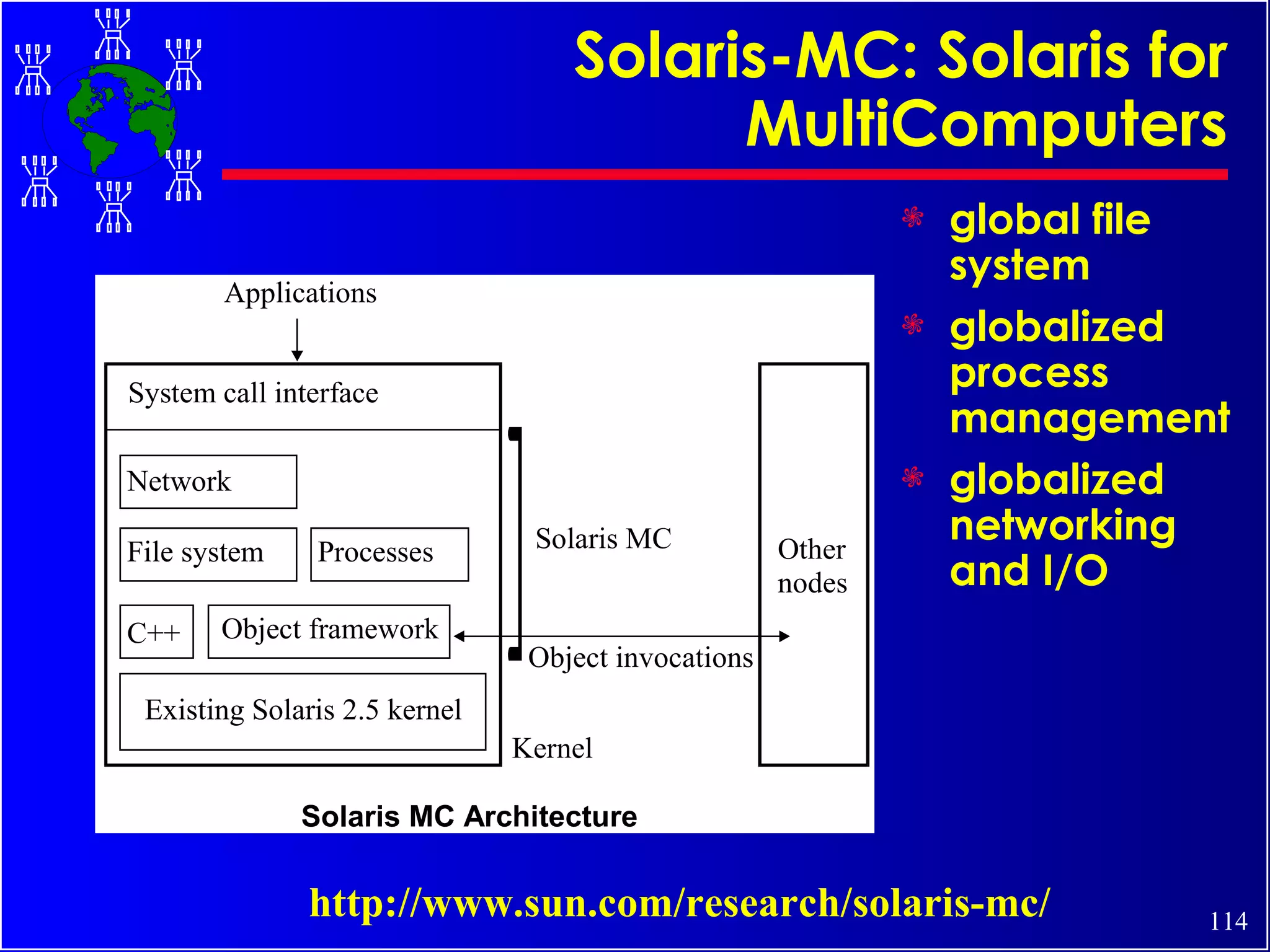
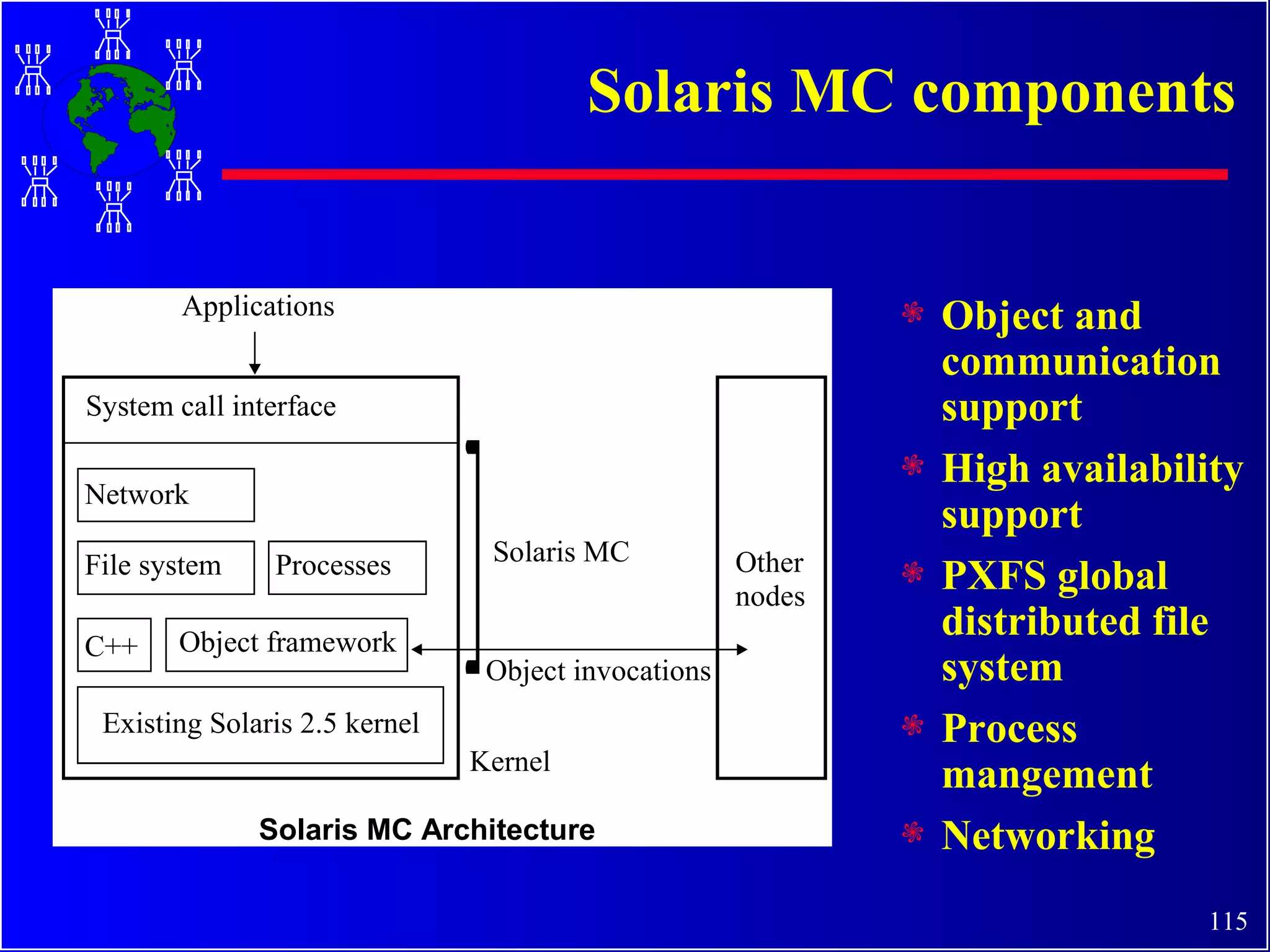
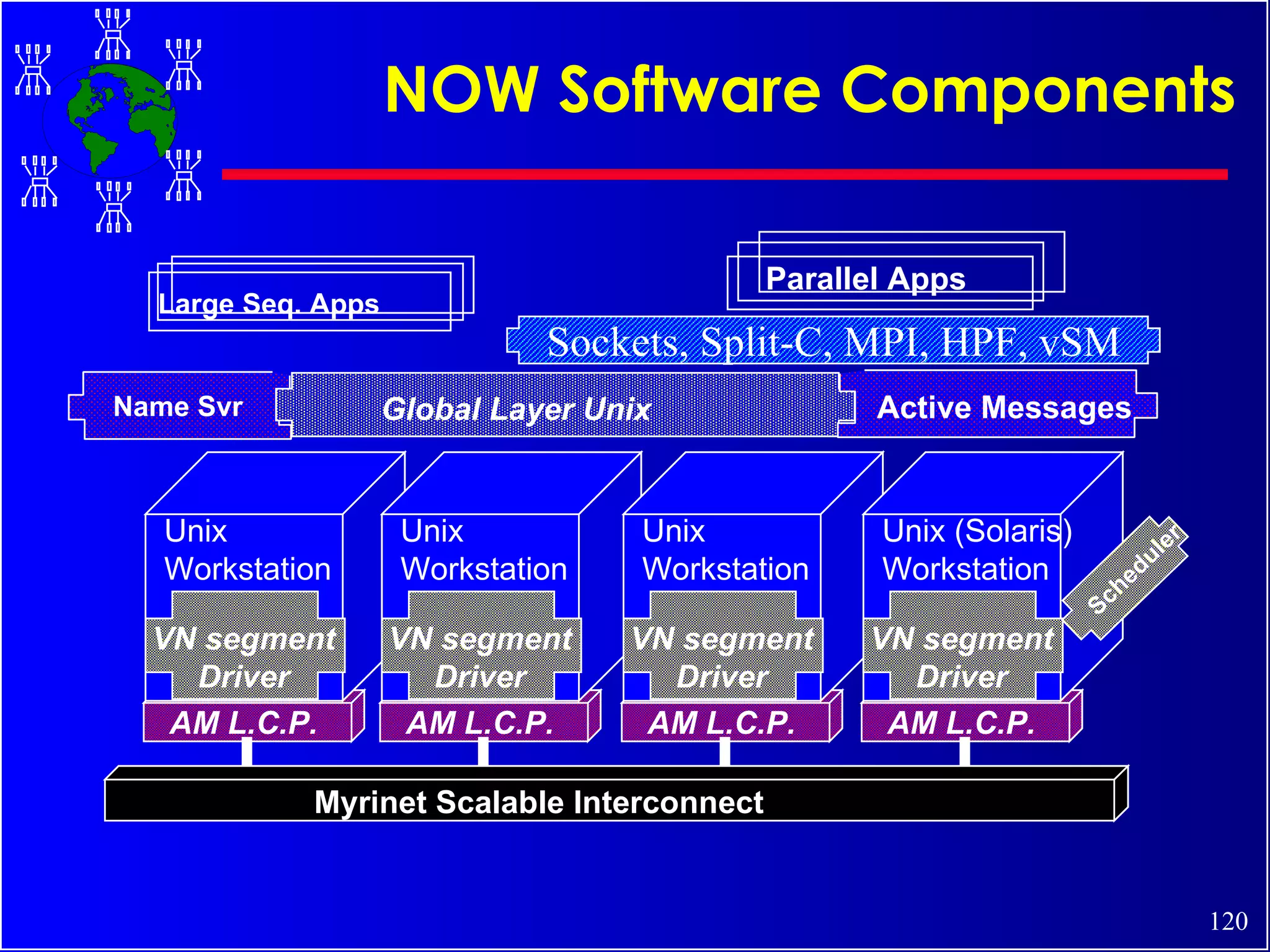
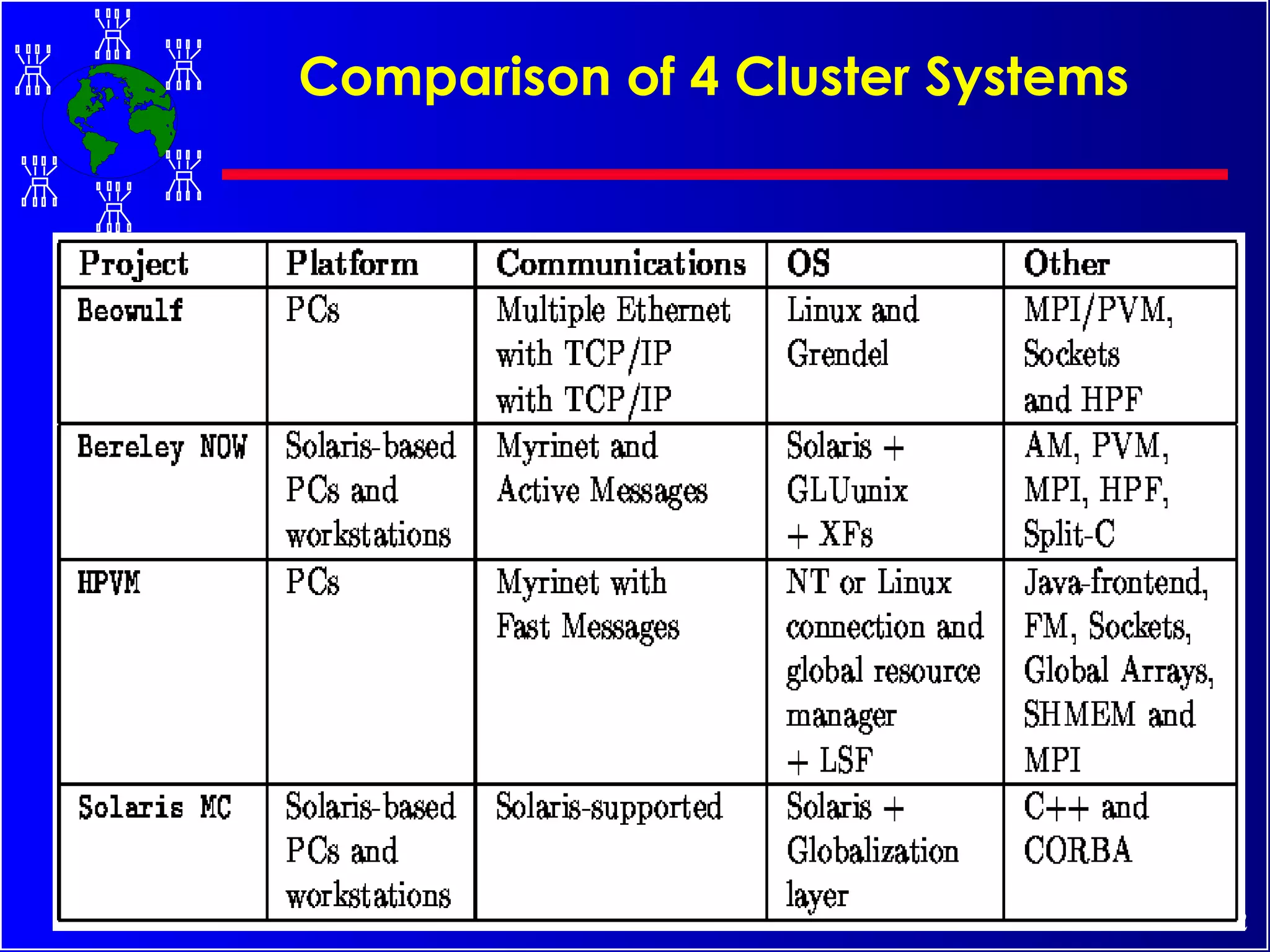
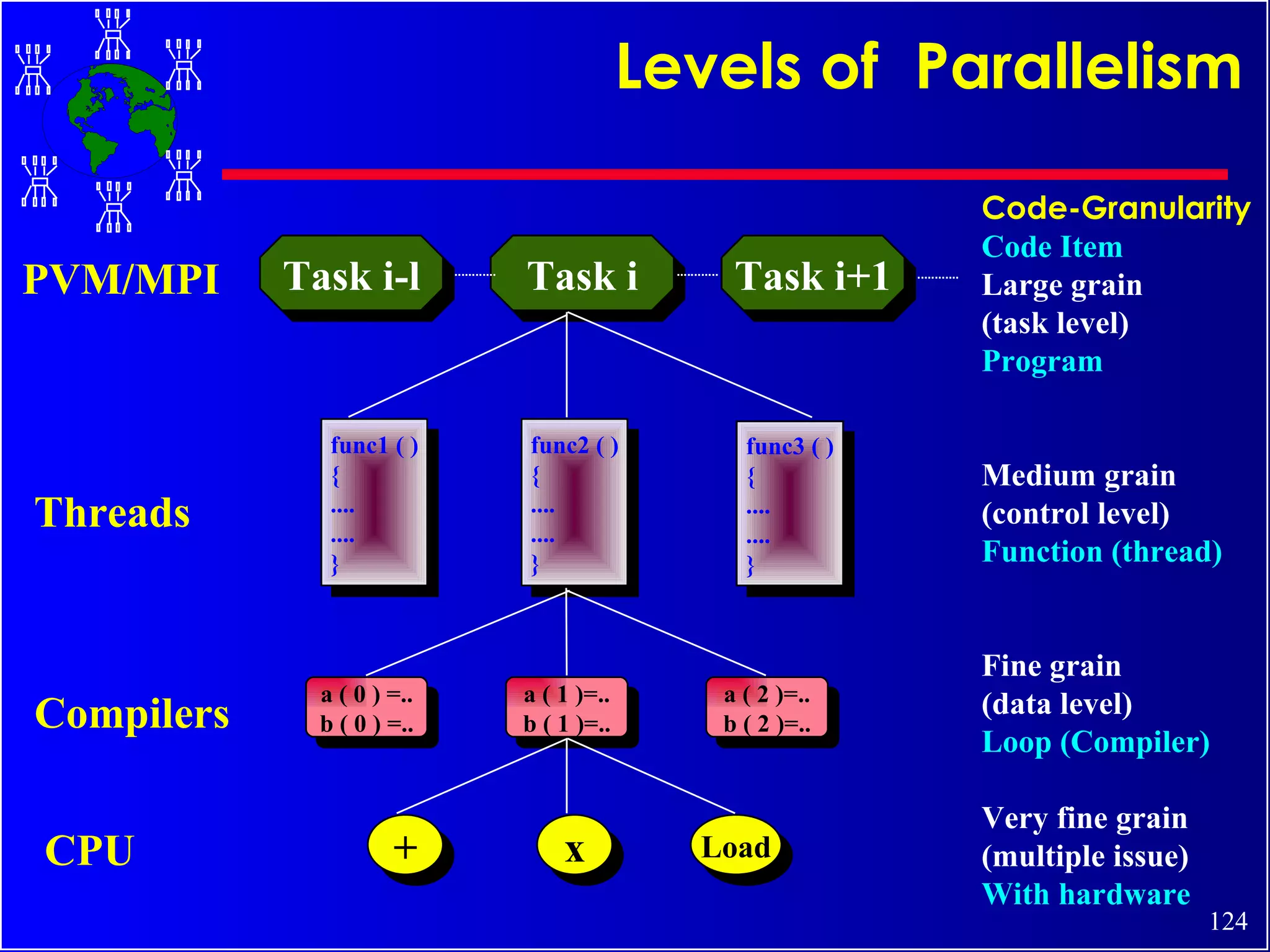
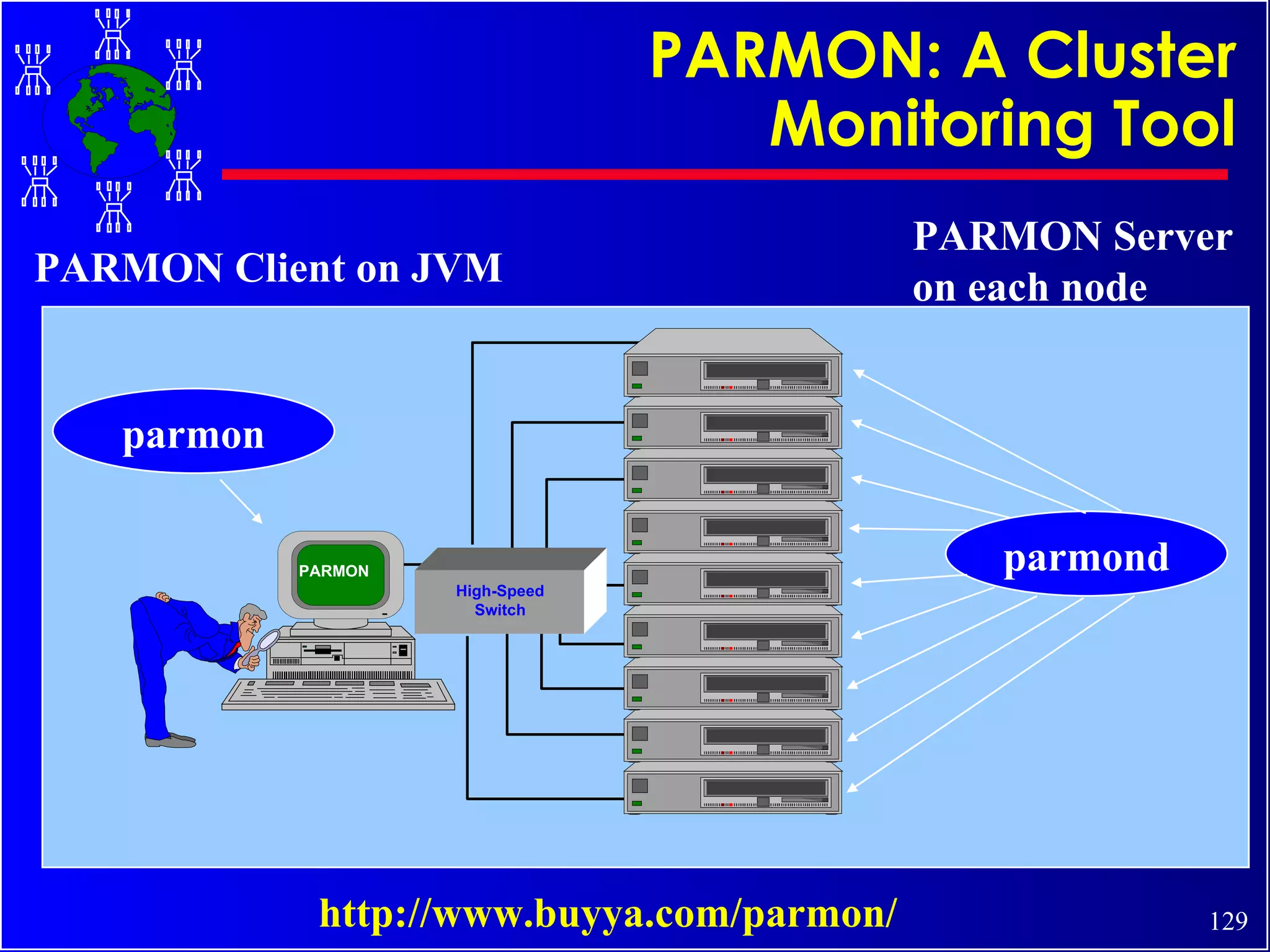
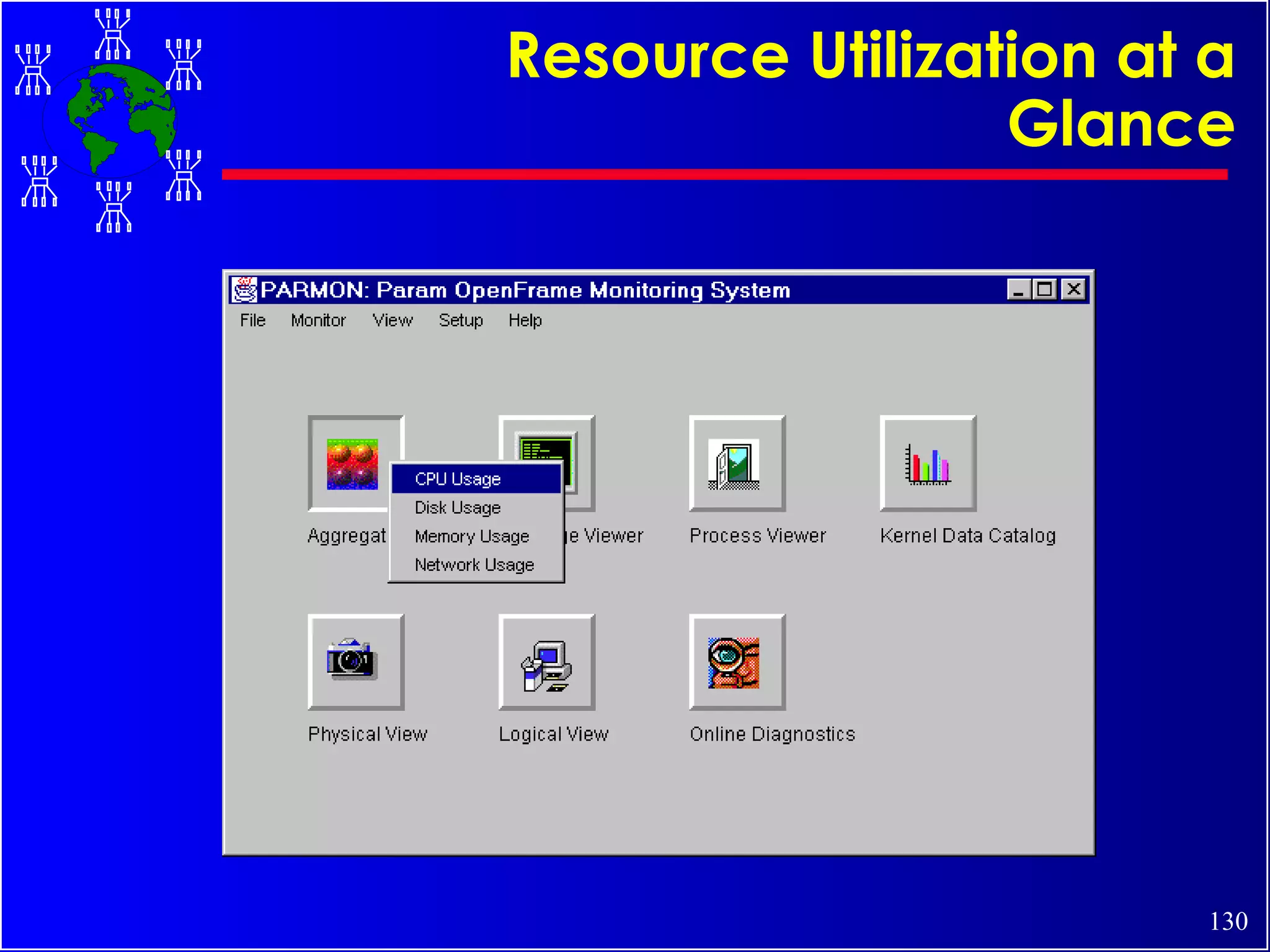
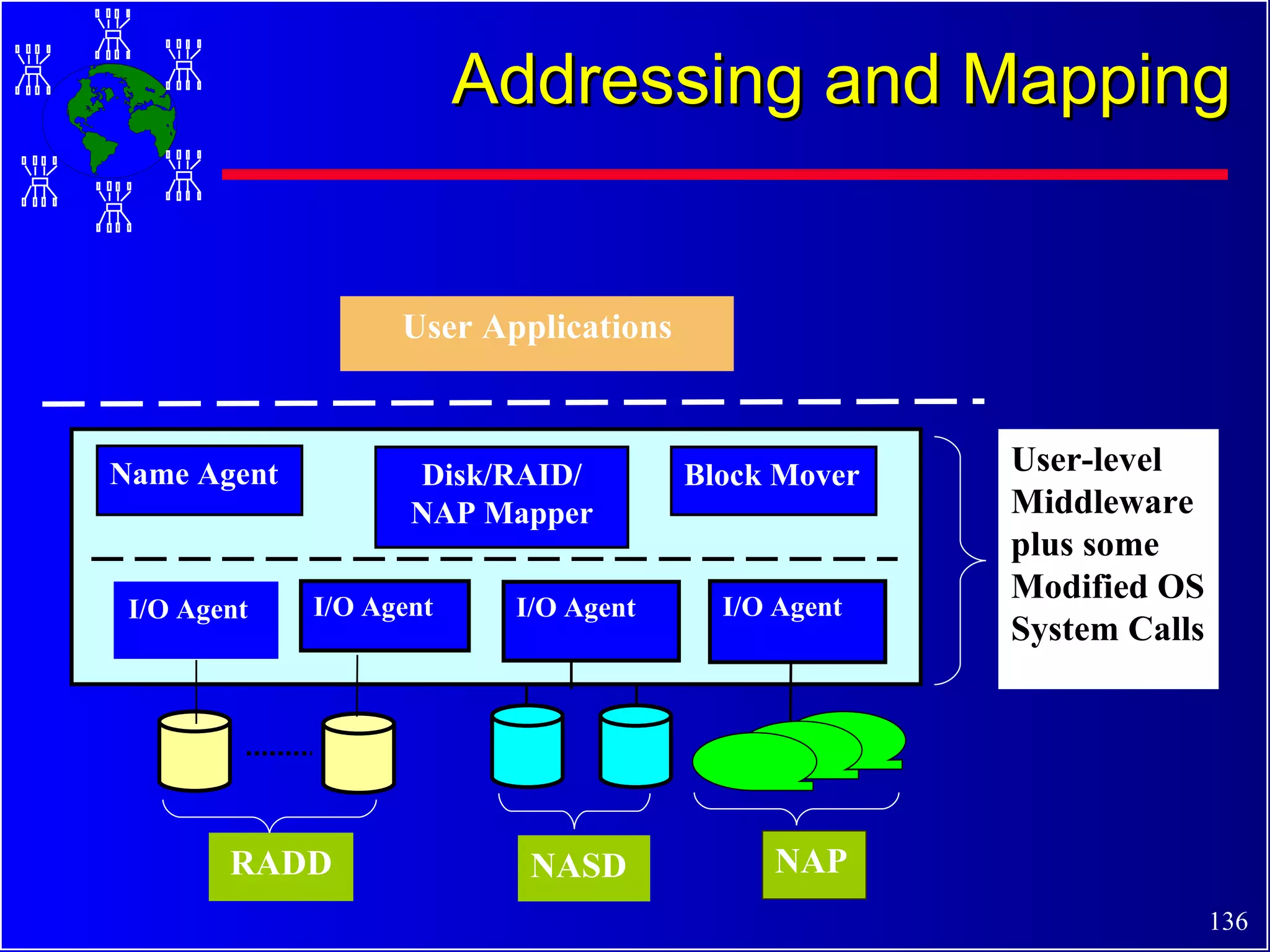
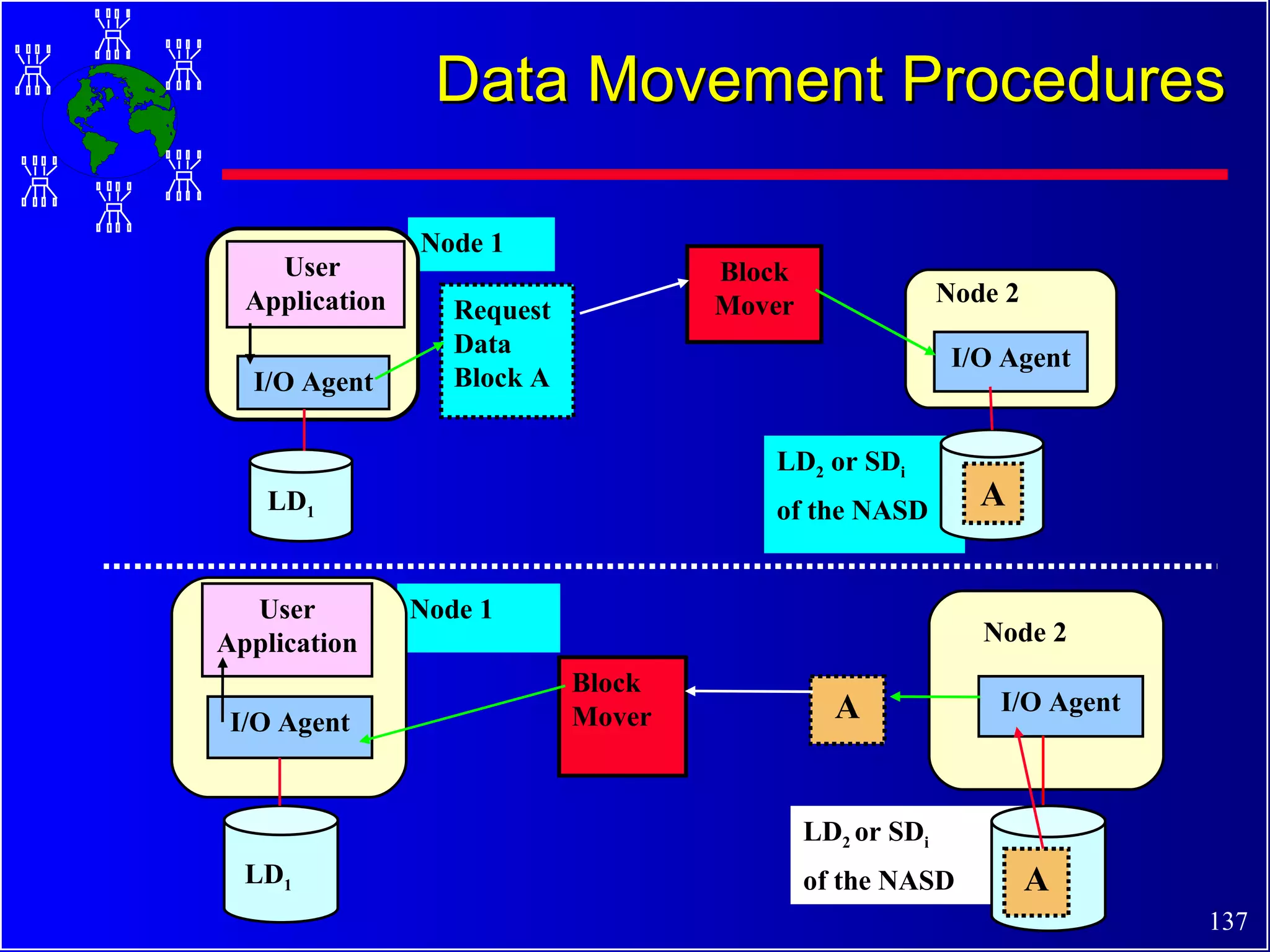
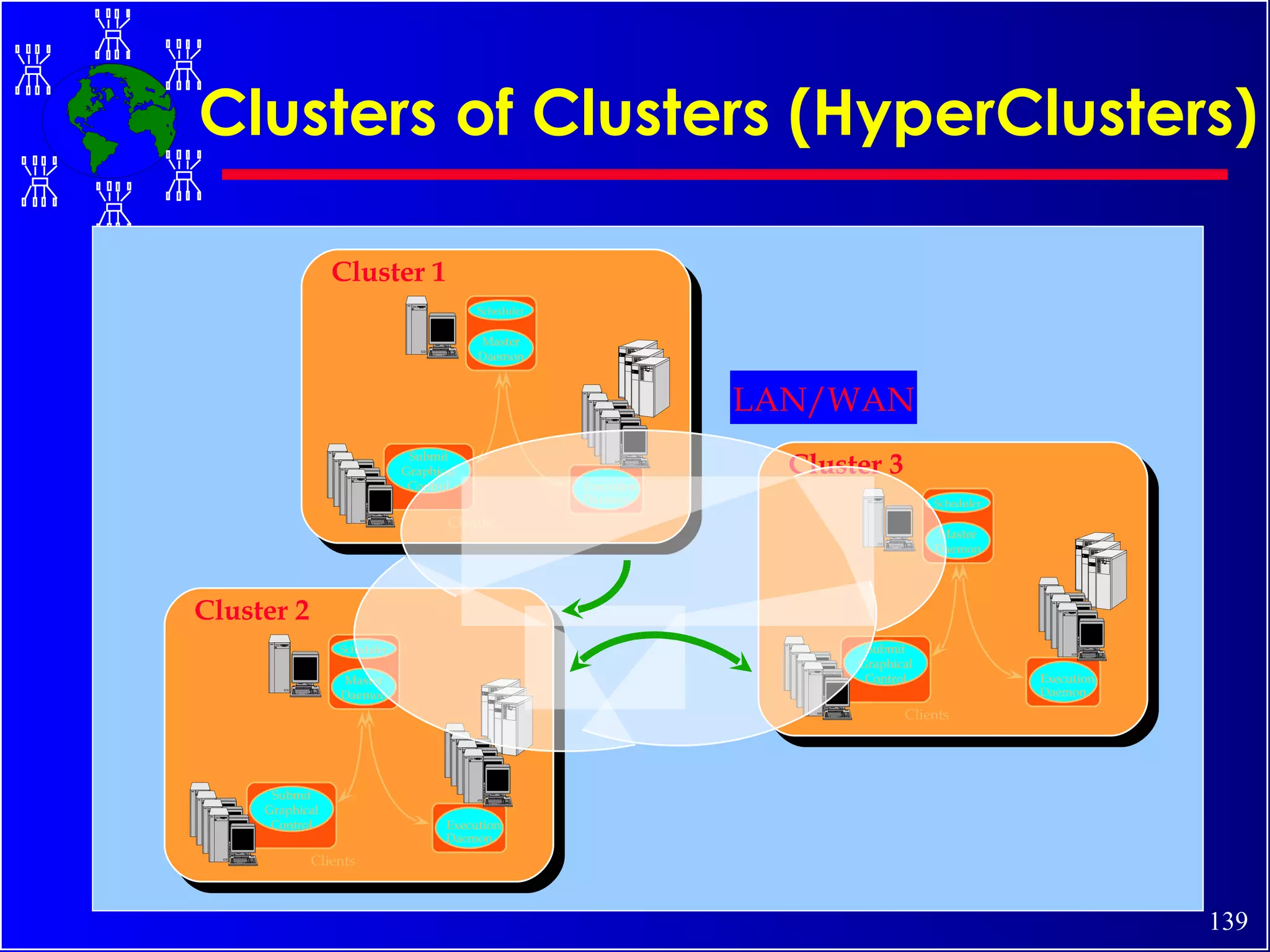
The document discusses high performance cluster computing, including its architecture, systems, applications, and enabling technologies. It provides an overview of cluster computing and classifications of cluster systems. Key components of cluster architecture are discussed, along with representative cluster systems and conclusions. Cluster middleware, resources, and applications are also mentioned.


































































































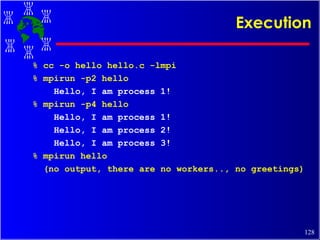
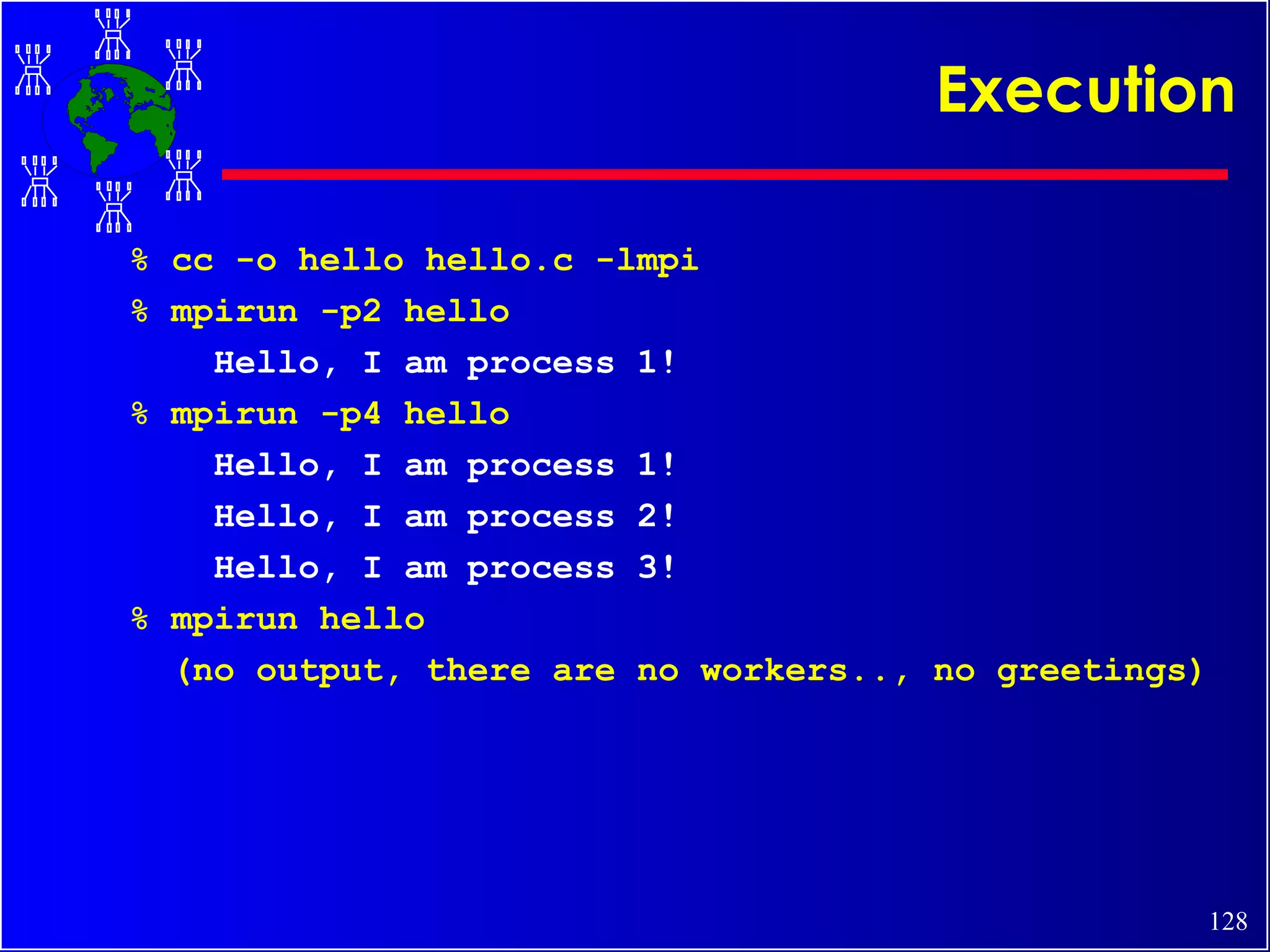
![A Sample MPI Program... # include <stdio.h> # include <string.h> #include “mpi.h” main( int argc, char *argv[ ]) { int my_rank; /* process rank */ int p; /*no. of processes*/ int source; /* rank of sender */ int dest; /* rank of receiver */ int tag = 0; /* message tag, like “email subject” */ char message[100]; /* buffer */ MPI_Status status; /* function return status */ /* Start up MPI */ MPI_Init( &argc, &argv ); /* Find our process rank/id */ MPI_Comm_rank( MPI_COM_WORLD, &my_rank); /*Find out how many processes/tasks part of this run */ MPI_Comm_size( MPI_COM_WORLD, &p); … (master) (workers) Hello,...](https://image.slidesharecdn.com/cluster-tutorial-090302090527-phpapp01/85/Cluster-Tutorial-126-320.jpg)

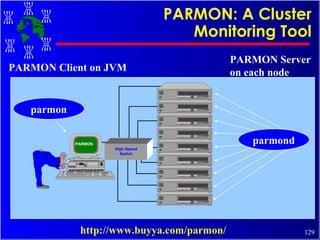









![Many GRID Projects and Initiatives PUBLIC FORUMS Computing Portals Grid Forum European Grid Forum IEEE TFCC! GRID’2000 and more. Australia Nimrod/G EcoGrid and GRACE DISCWorld Europe UNICORE MOL METODIS Globe Poznan Metacomputing CERN Data Grid MetaMPI DAS JaWS and many more... Public Grid Initiatives Distributed.net [email_address] Compute Power Grid USA Globus Legion JAVELIN AppLes NASA IPG Condor Harness NetSolve NCSA Workbench WebFlow EveryWhere and many more... Japan Ninf Bricks and many more... http://www.gridcomputing.com/](https://image.slidesharecdn.com/cluster-tutorial-090302090527-phpapp01/85/Cluster-Tutorial-145-320.jpg)
















































































































![A Sample MPI Program... # include <stdio.h> # include <string.h> #include “mpi.h” main( int argc, char *argv[ ]) { int my_rank; /* process rank */ int p; /*no. of processes*/ int source; /* rank of sender */ int dest; /* rank of receiver */ int tag = 0; /* message tag, like “email subject” */ char message[100]; /* buffer */ MPI_Status status; /* function return status */ /* Start up MPI */ MPI_Init( &argc, &argv ); /* Find our process rank/id */ MPI_Comm_rank( MPI_COM_WORLD, &my_rank); /*Find out how many processes/tasks part of this run */ MPI_Comm_size( MPI_COM_WORLD, &p); … (master) (workers) Hello,...](https://image.slidesharecdn.com/cluster-tutorial-090302090527-phpapp01/75/Cluster-Tutorial-126-2048.jpg)











![Many GRID Projects and Initiatives PUBLIC FORUMS Computing Portals Grid Forum European Grid Forum IEEE TFCC! GRID’2000 and more. Australia Nimrod/G EcoGrid and GRACE DISCWorld Europe UNICORE MOL METODIS Globe Poznan Metacomputing CERN Data Grid MetaMPI DAS JaWS and many more... Public Grid Initiatives Distributed.net [email_address] Compute Power Grid USA Globus Legion JAVELIN AppLes NASA IPG Condor Harness NetSolve NCSA Workbench WebFlow EveryWhere and many more... Japan Ninf Bricks and many more... http://www.gridcomputing.com/](https://image.slidesharecdn.com/cluster-tutorial-090302090527-phpapp01/75/Cluster-Tutorial-145-2048.jpg)