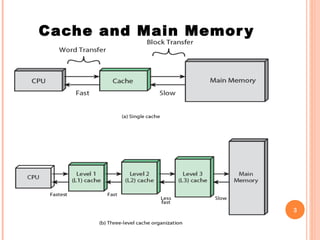
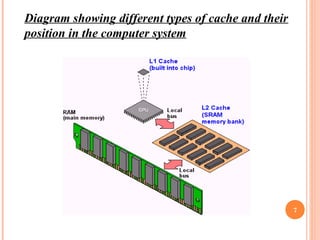
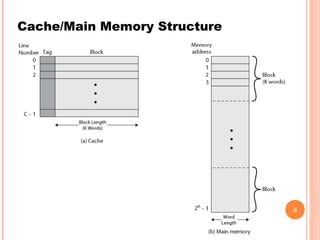
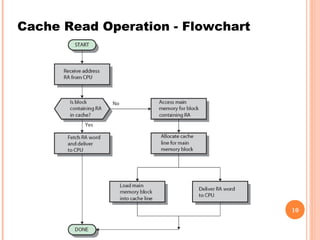
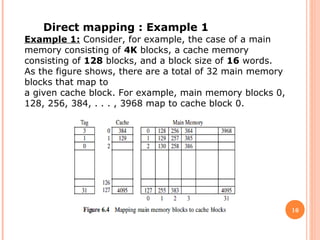
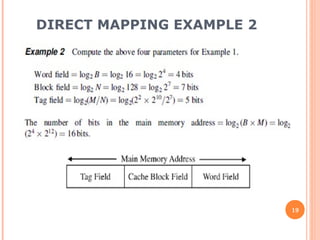
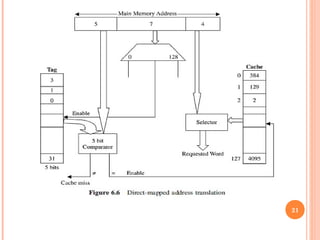
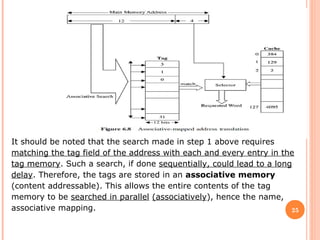
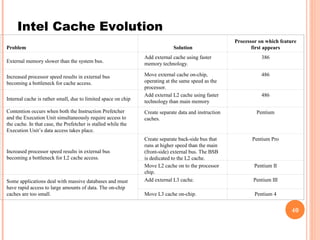
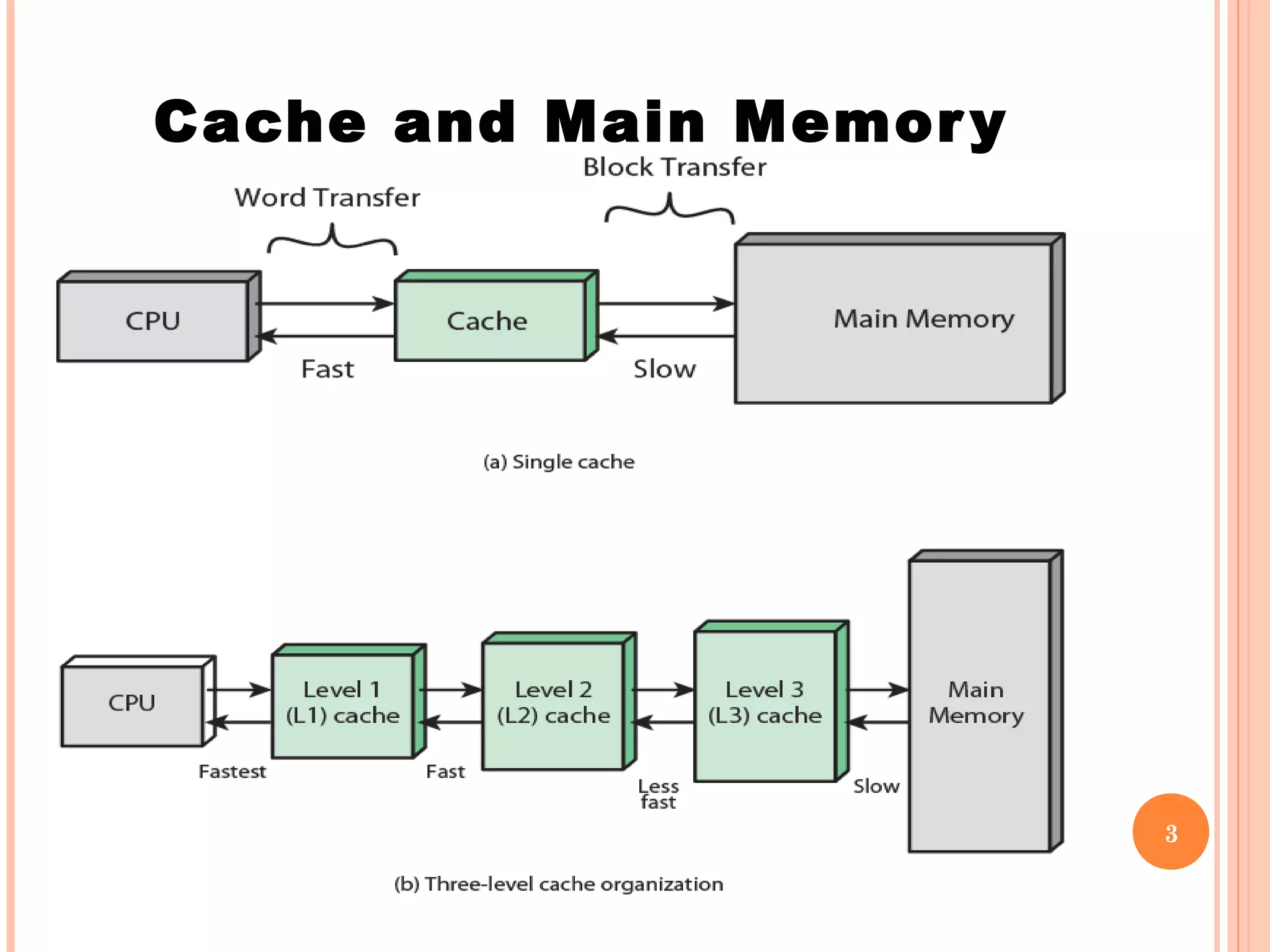
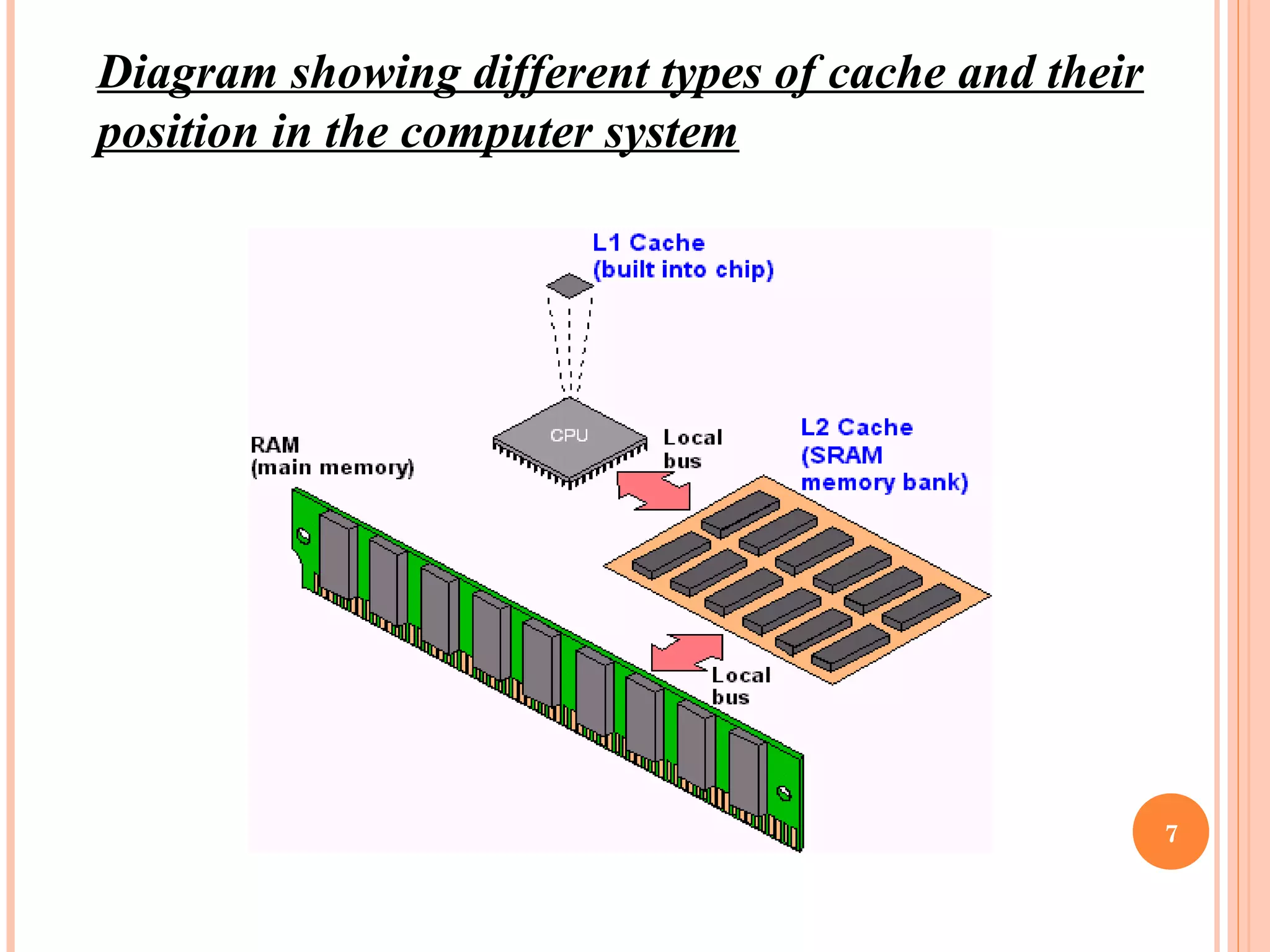
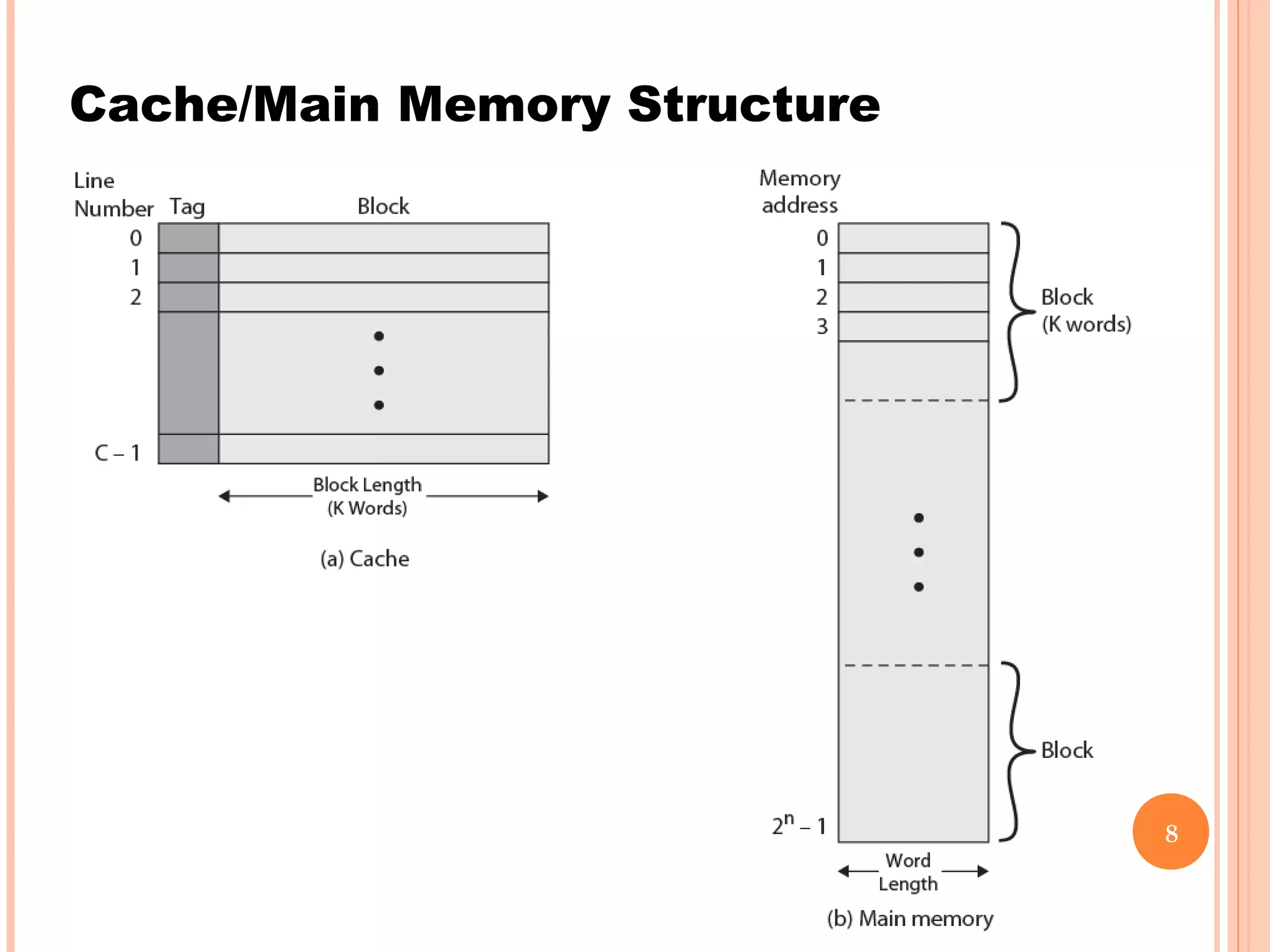
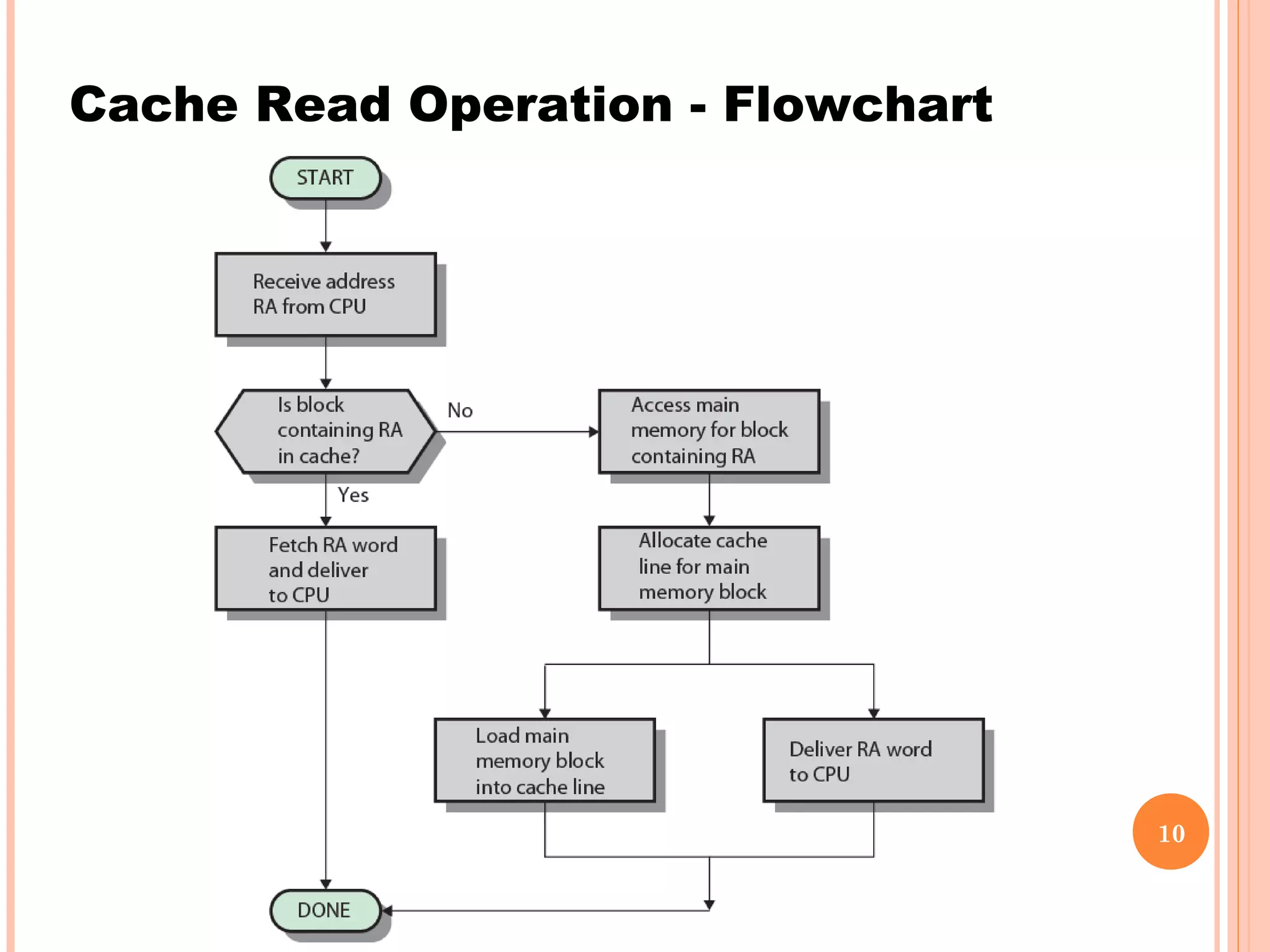
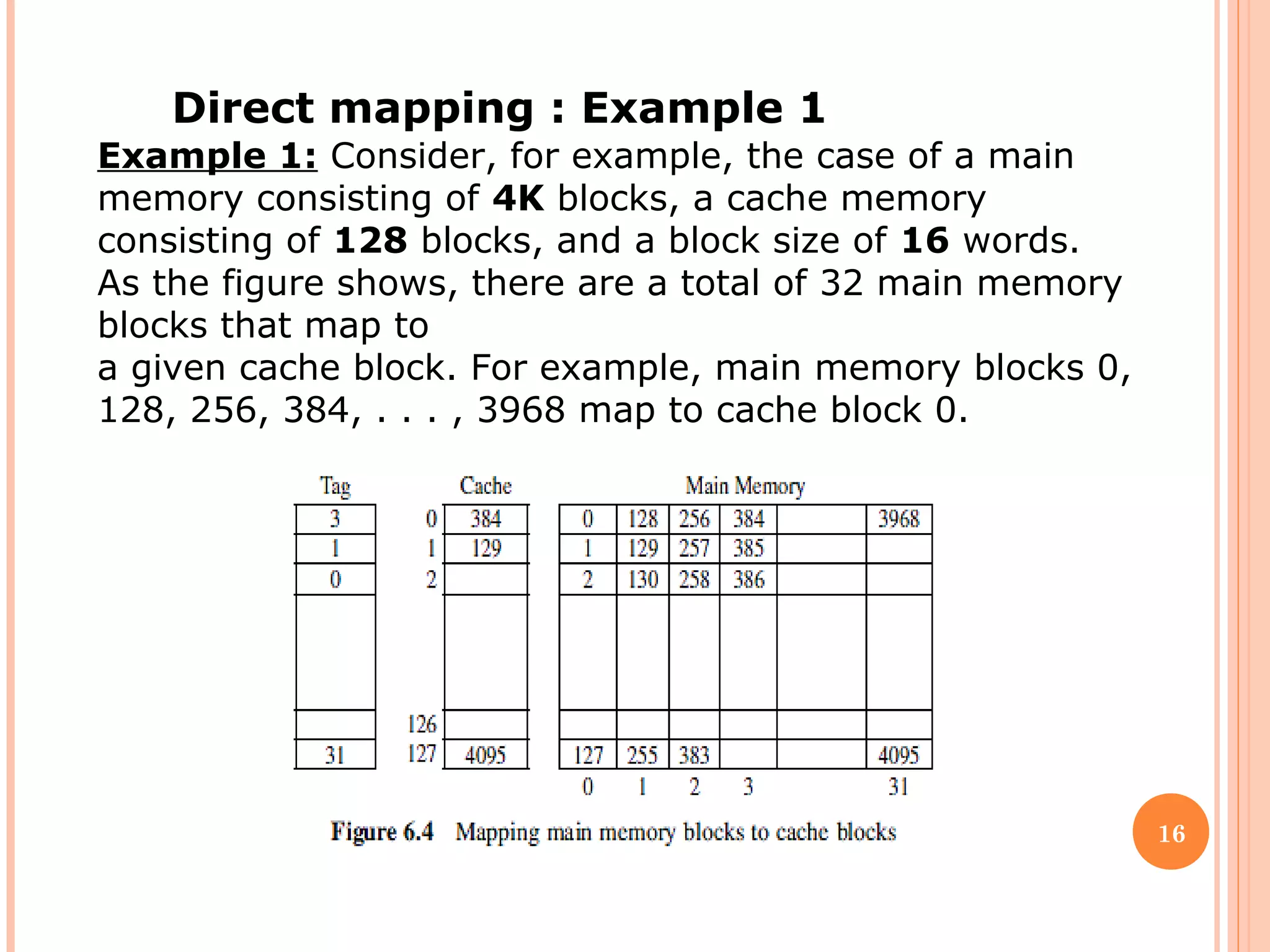
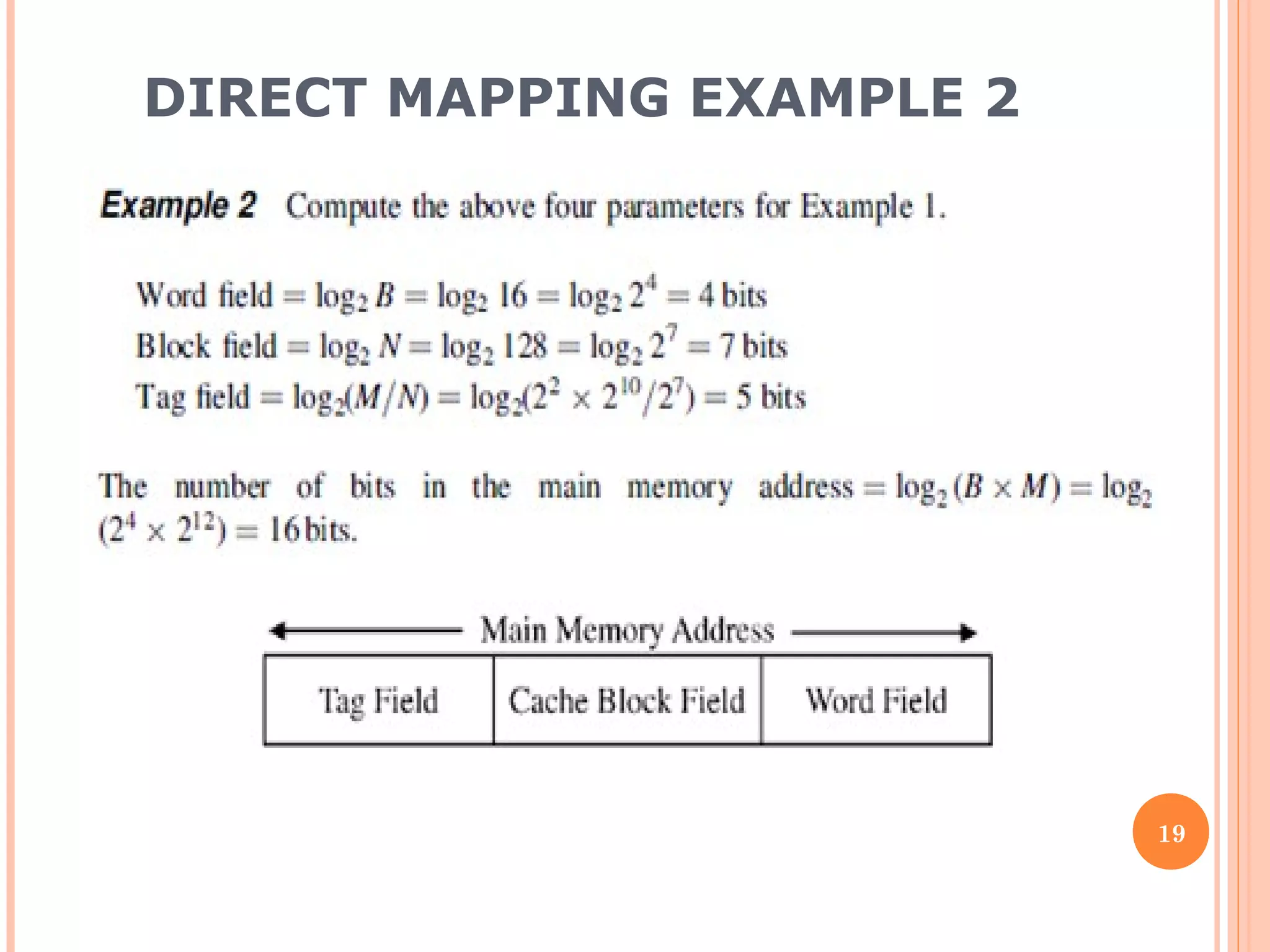
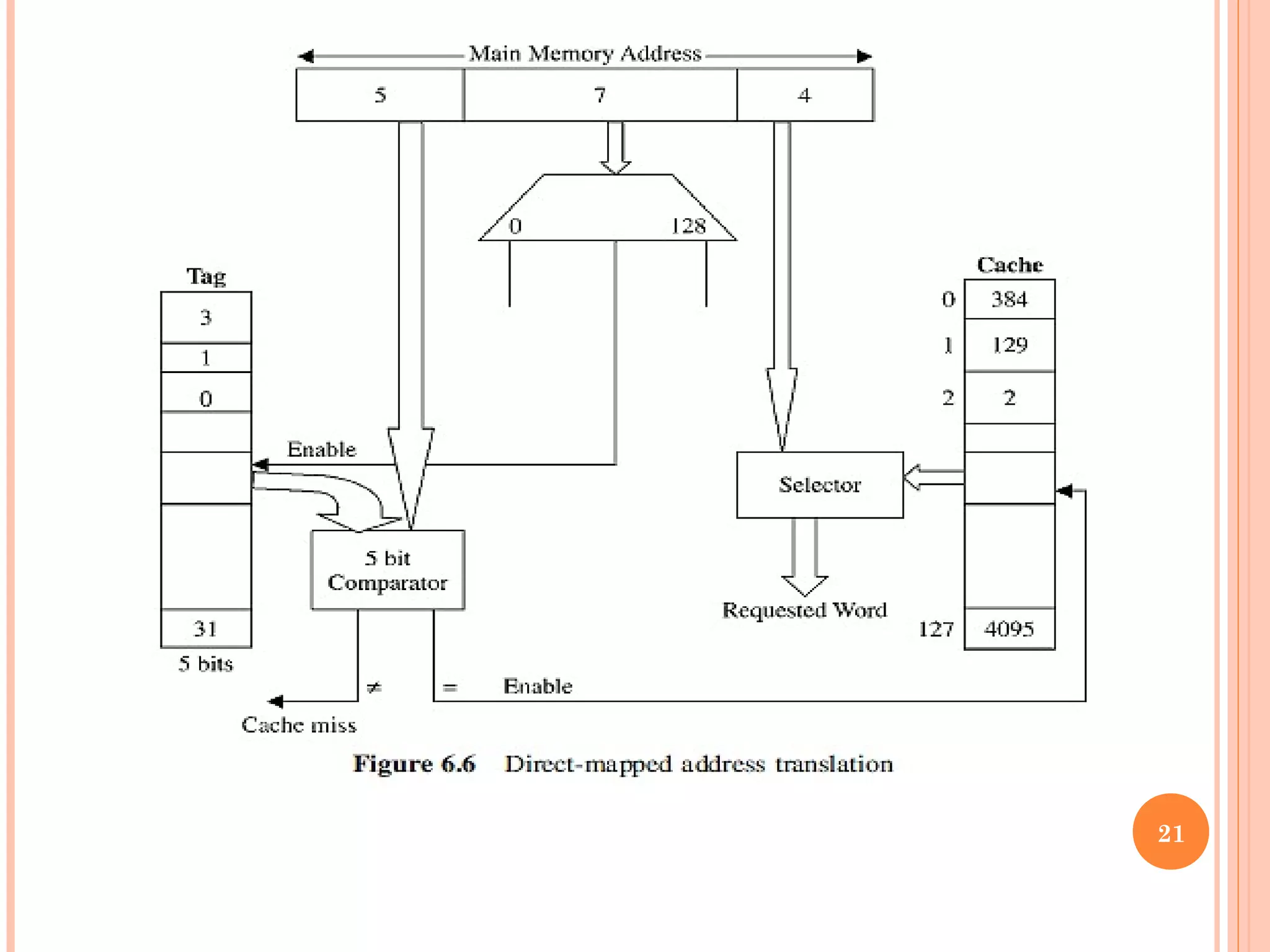
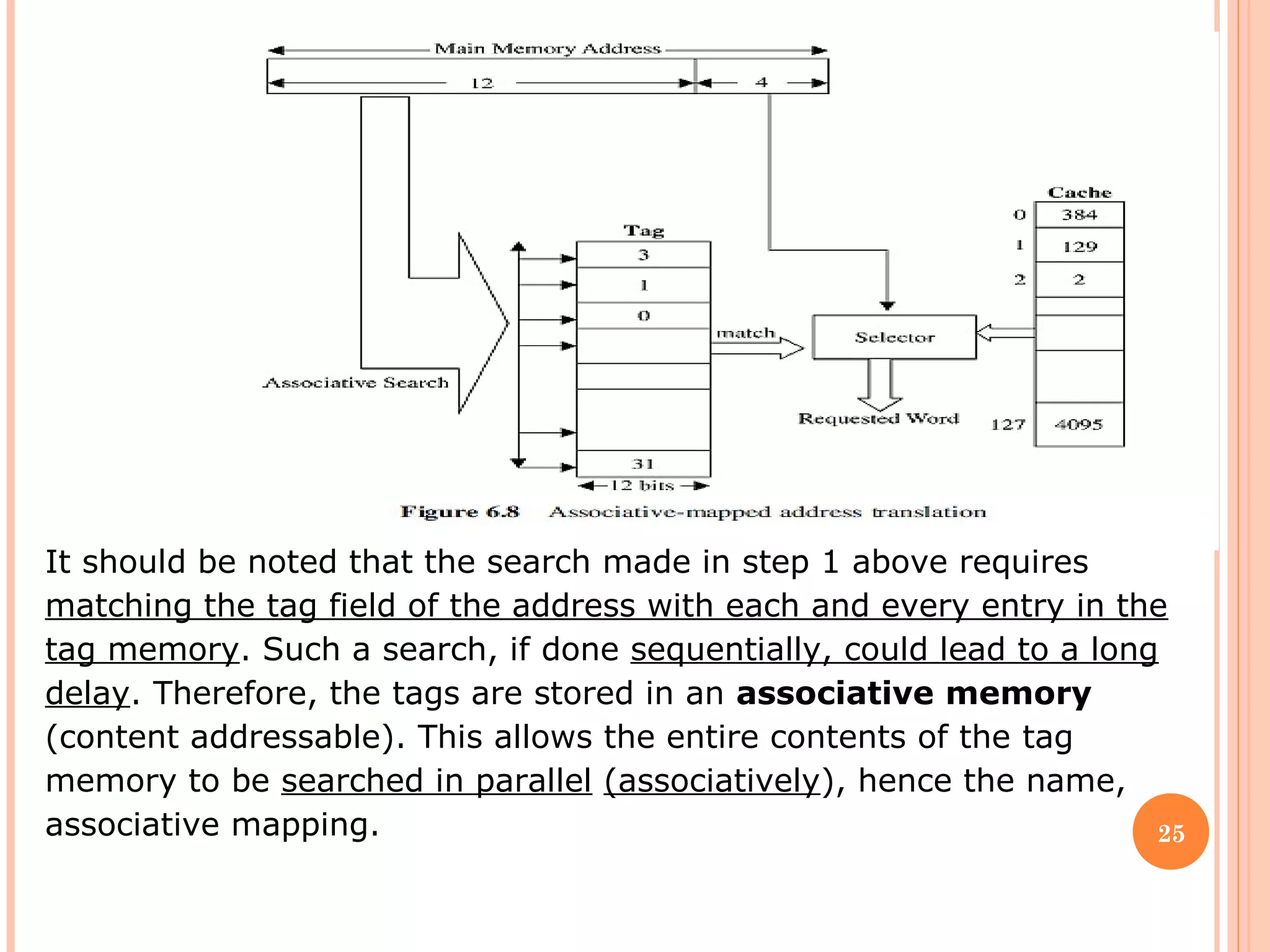
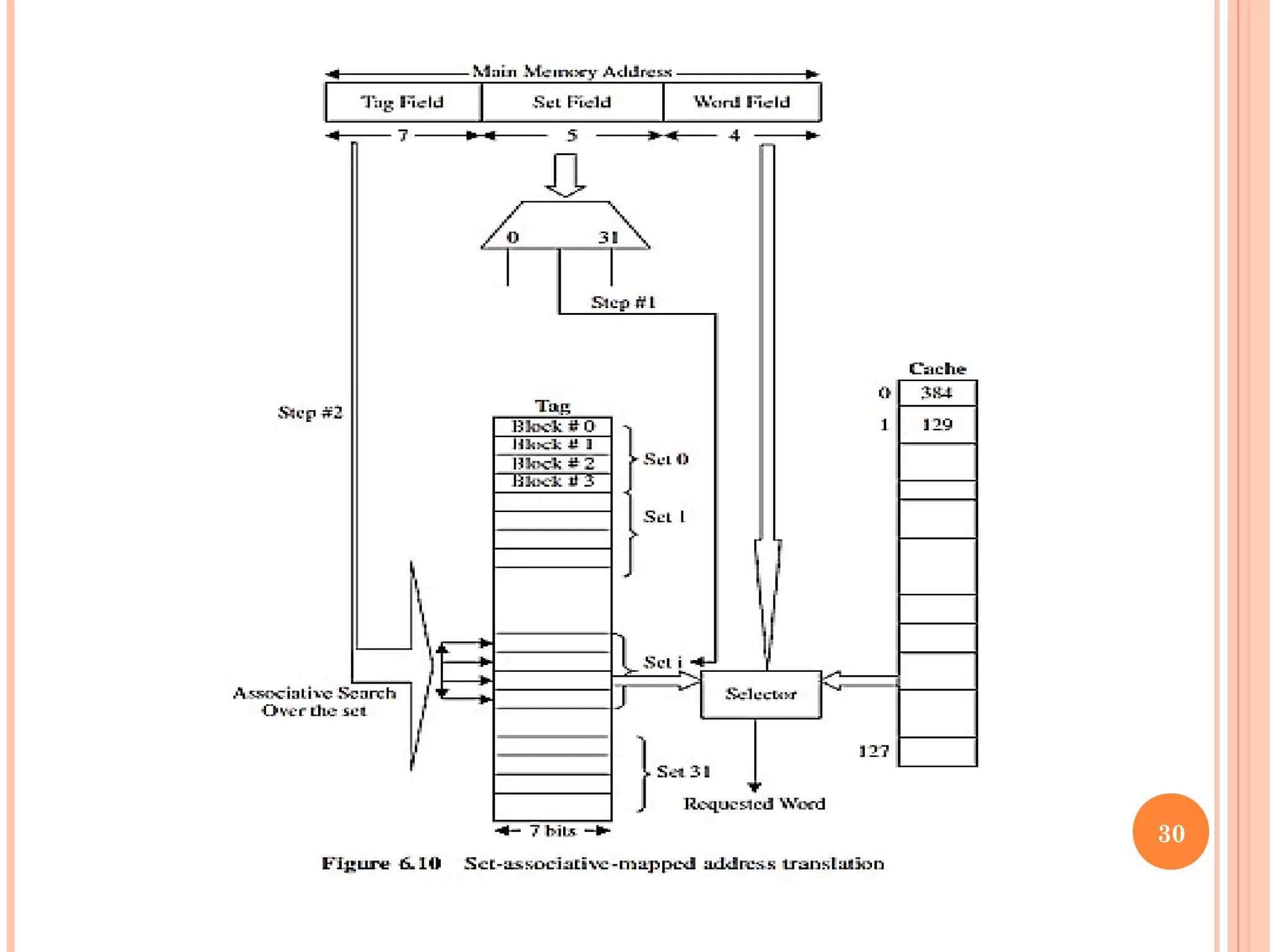
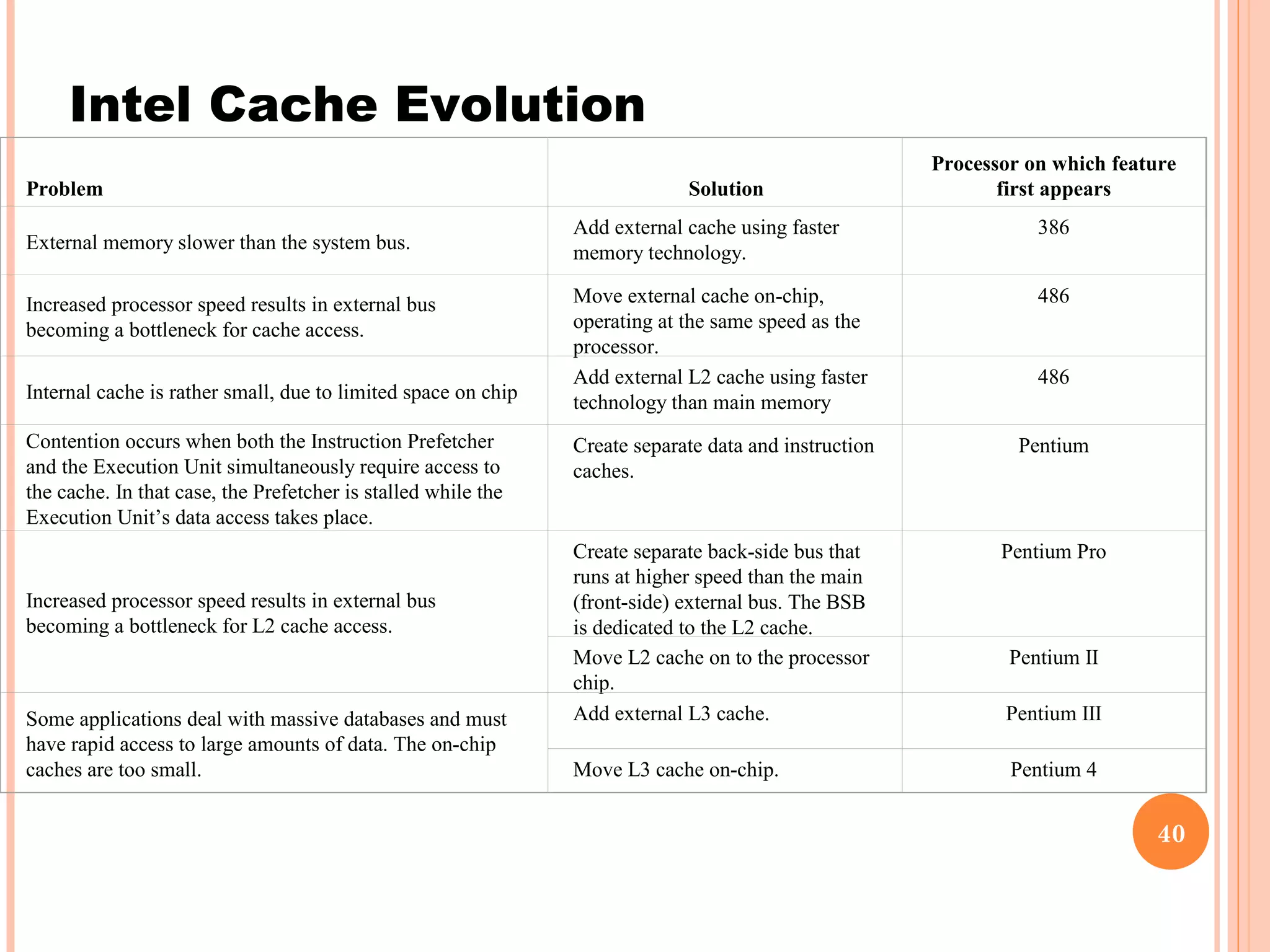
Cache memory is a small, high-speed memory located between the CPU and main memory. It stores copies of frequently used instructions and data from main memory in order to speed up processing. There are multiple levels of cache with L1 cache being the smallest and fastest located directly on the CPU chip. Larger cache levels like L2 and L3 are further from the CPU but can still provide faster access than main memory. The main purpose of cache is to accelerate processing speed while keeping computer costs low.