Downloaded 117 times


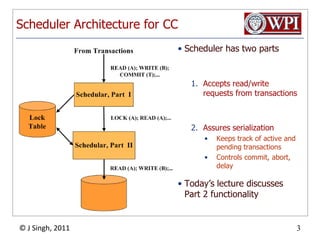
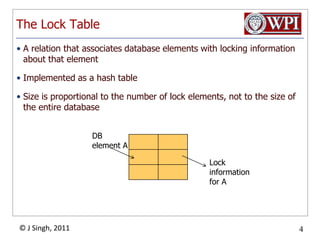




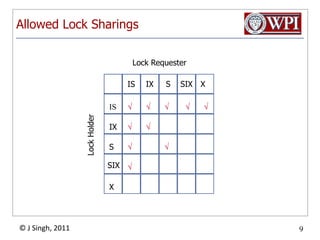

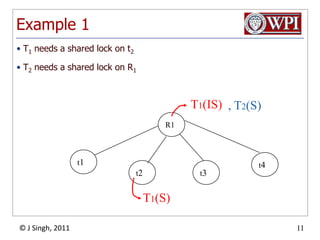
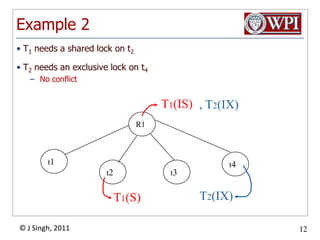

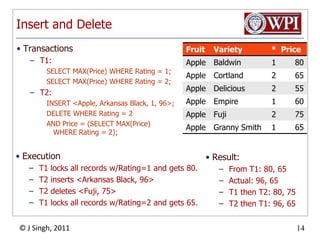





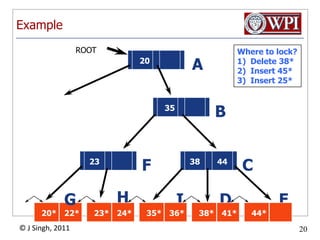


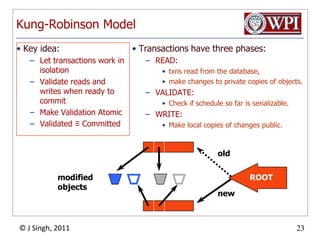









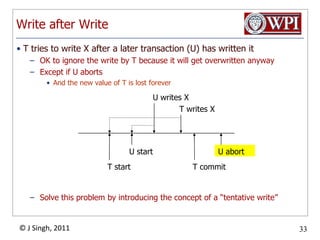






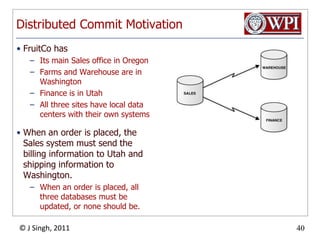


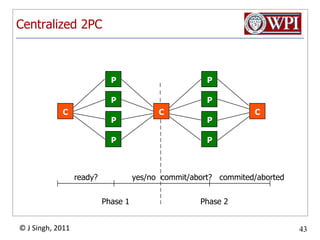
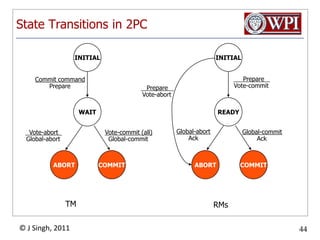
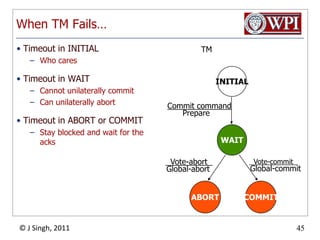
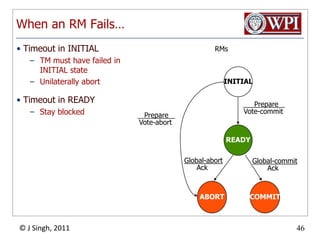
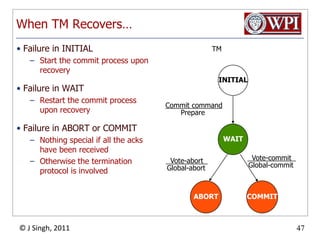
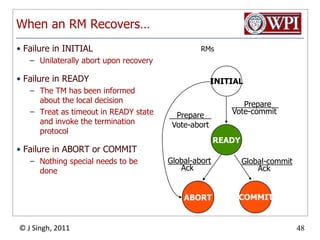
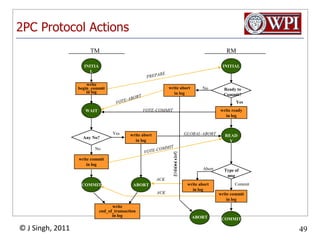


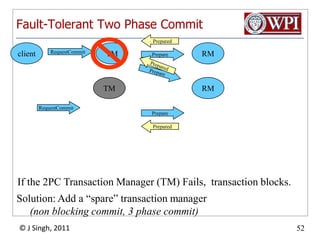
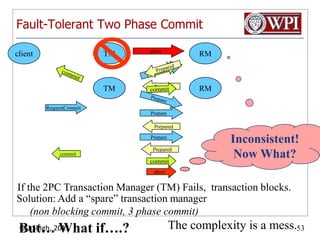

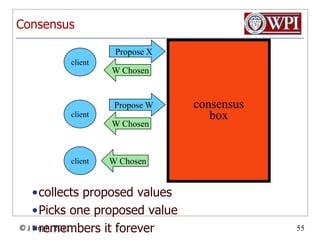
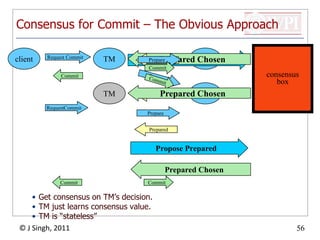
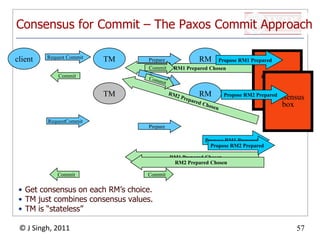
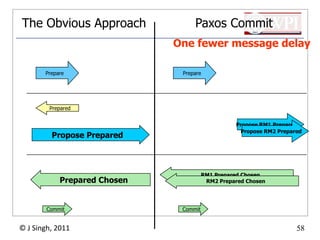
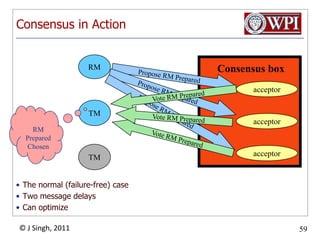





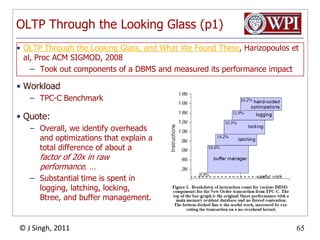







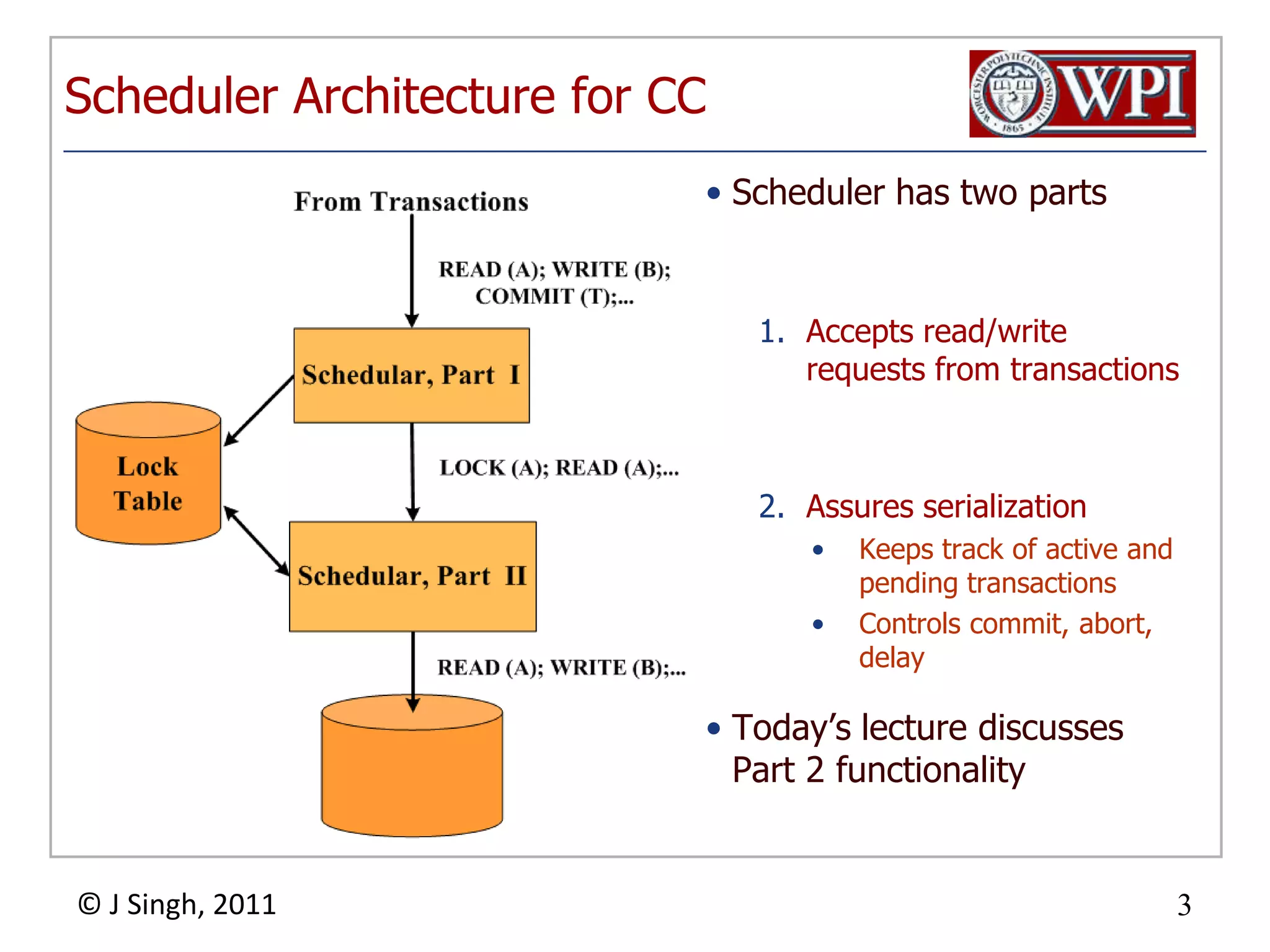
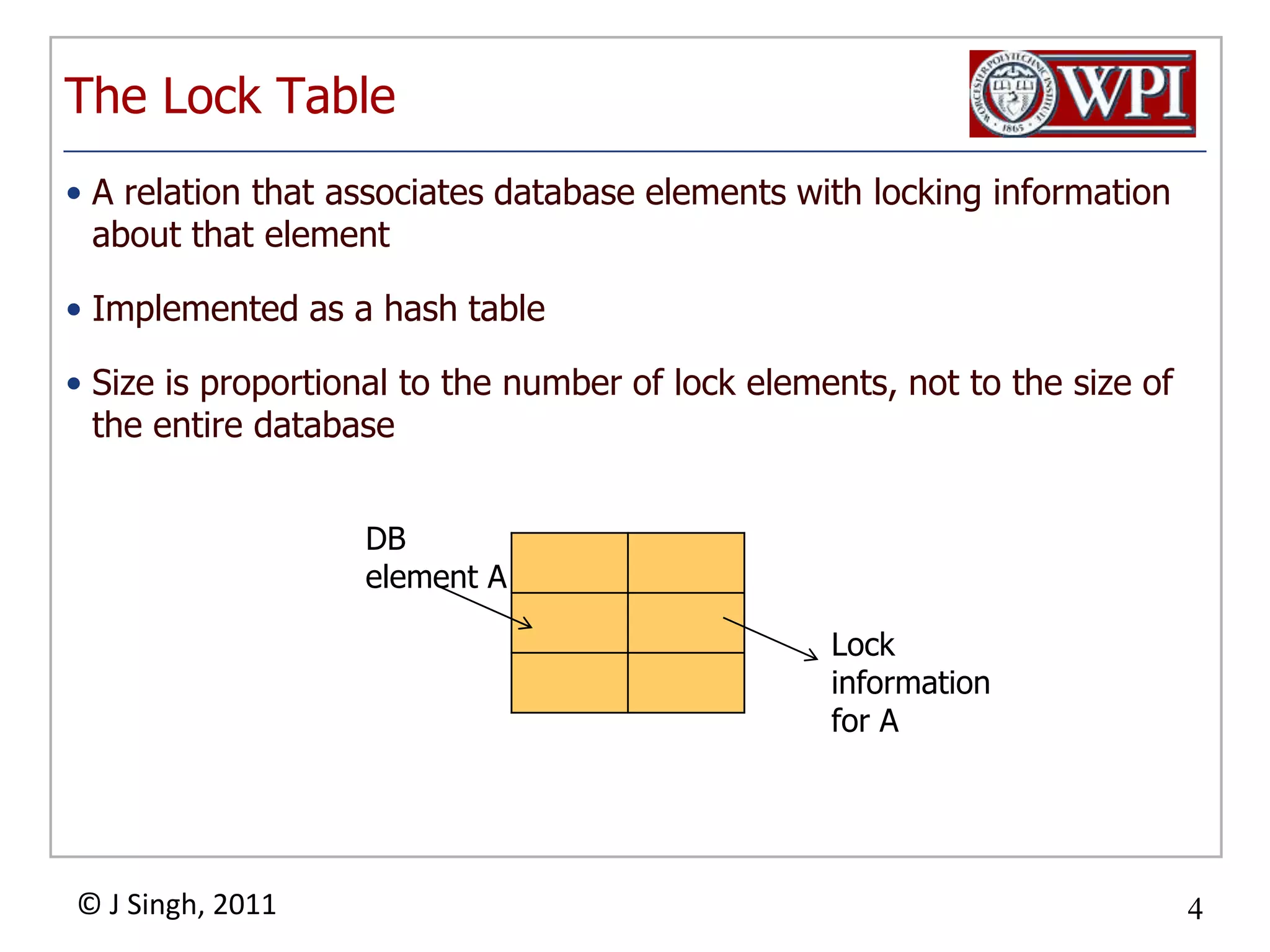




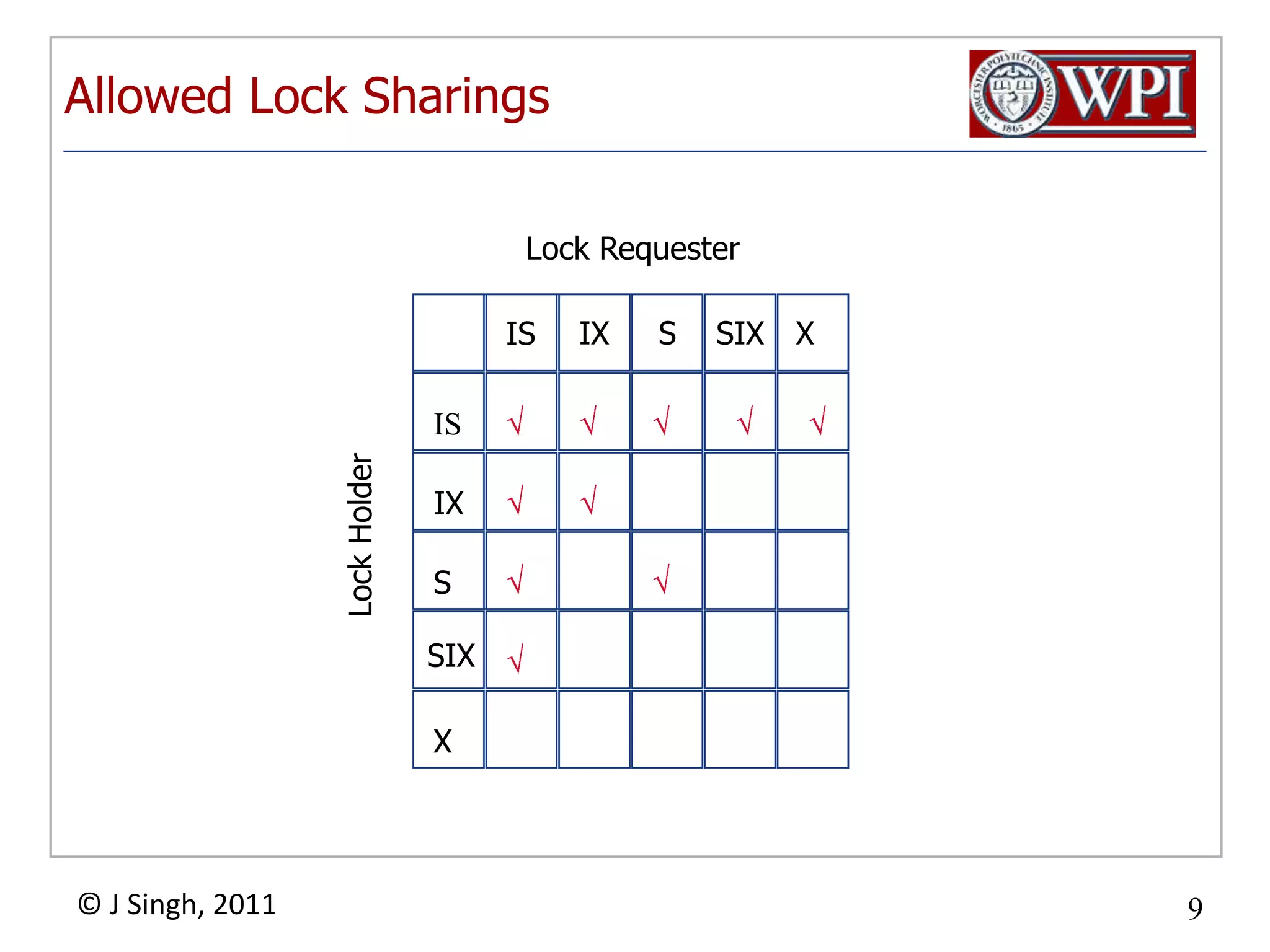

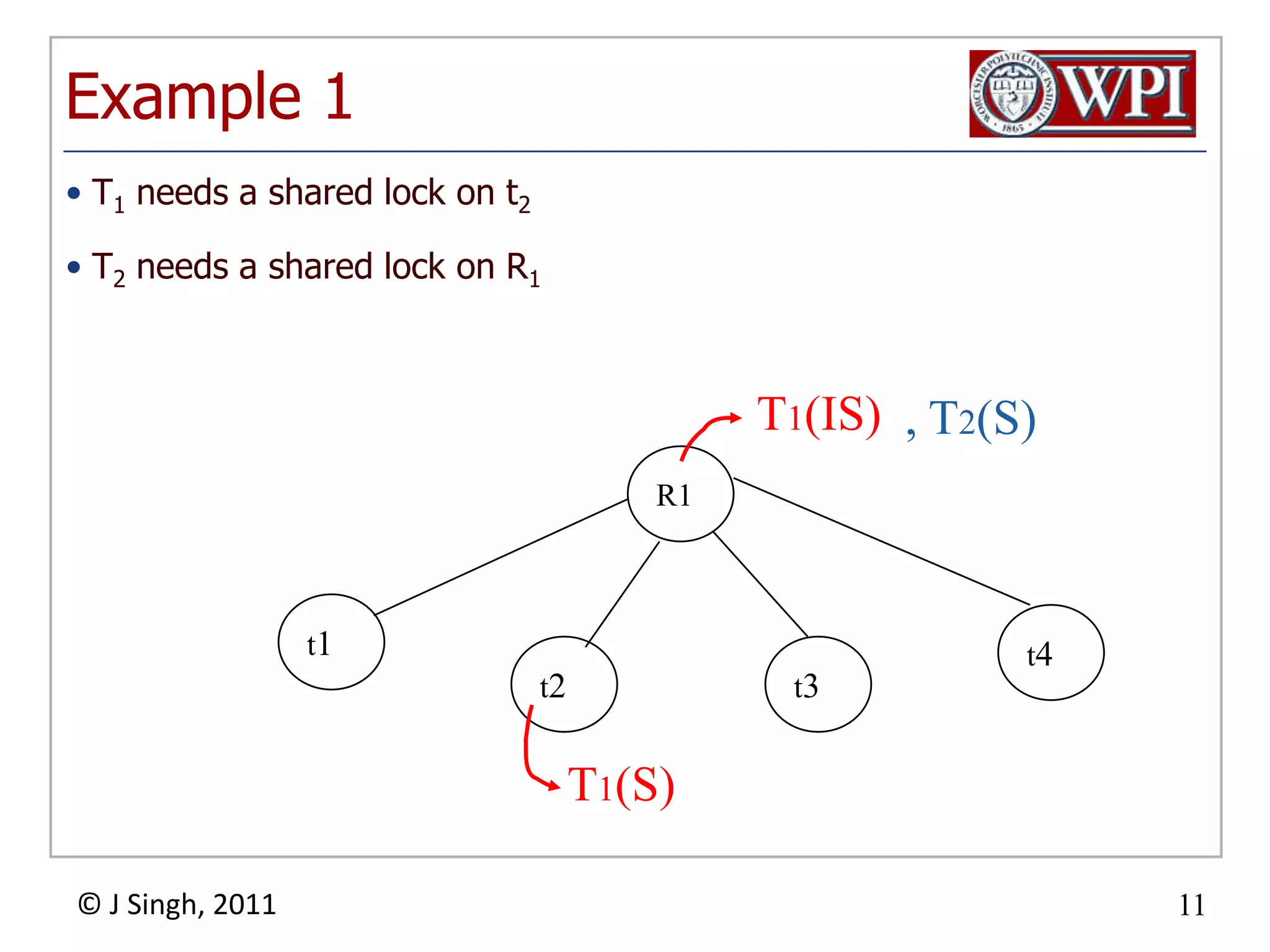
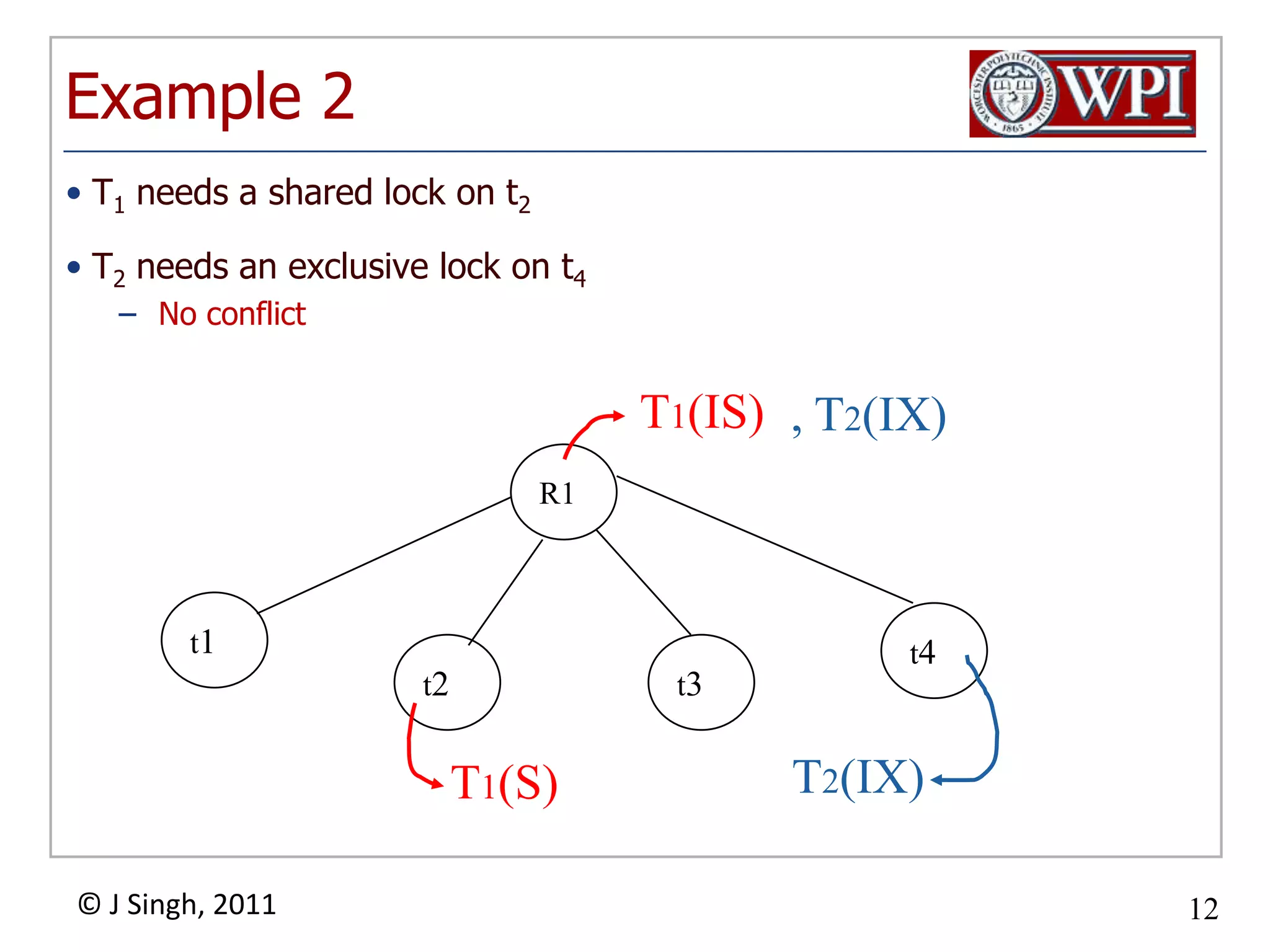

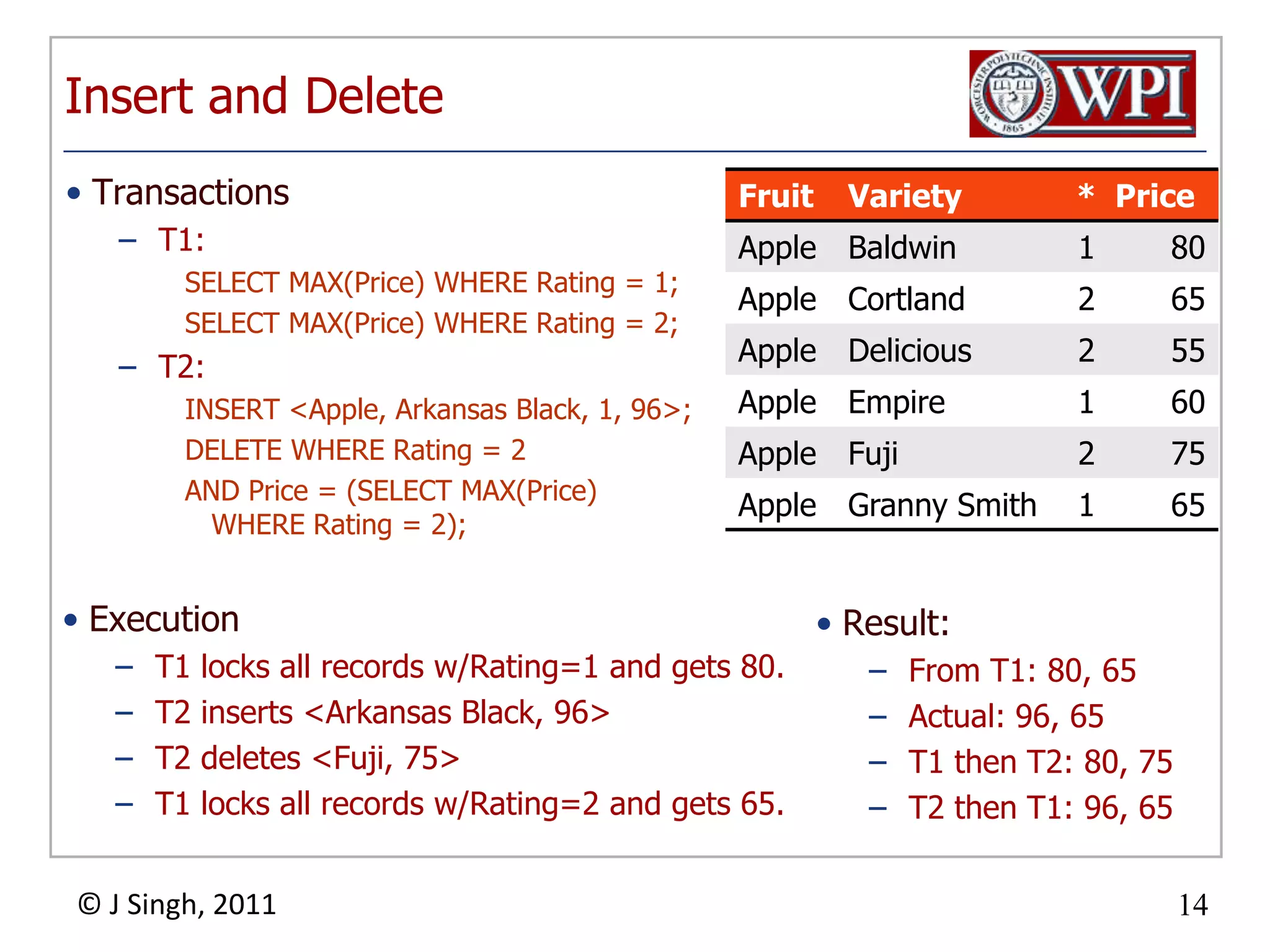





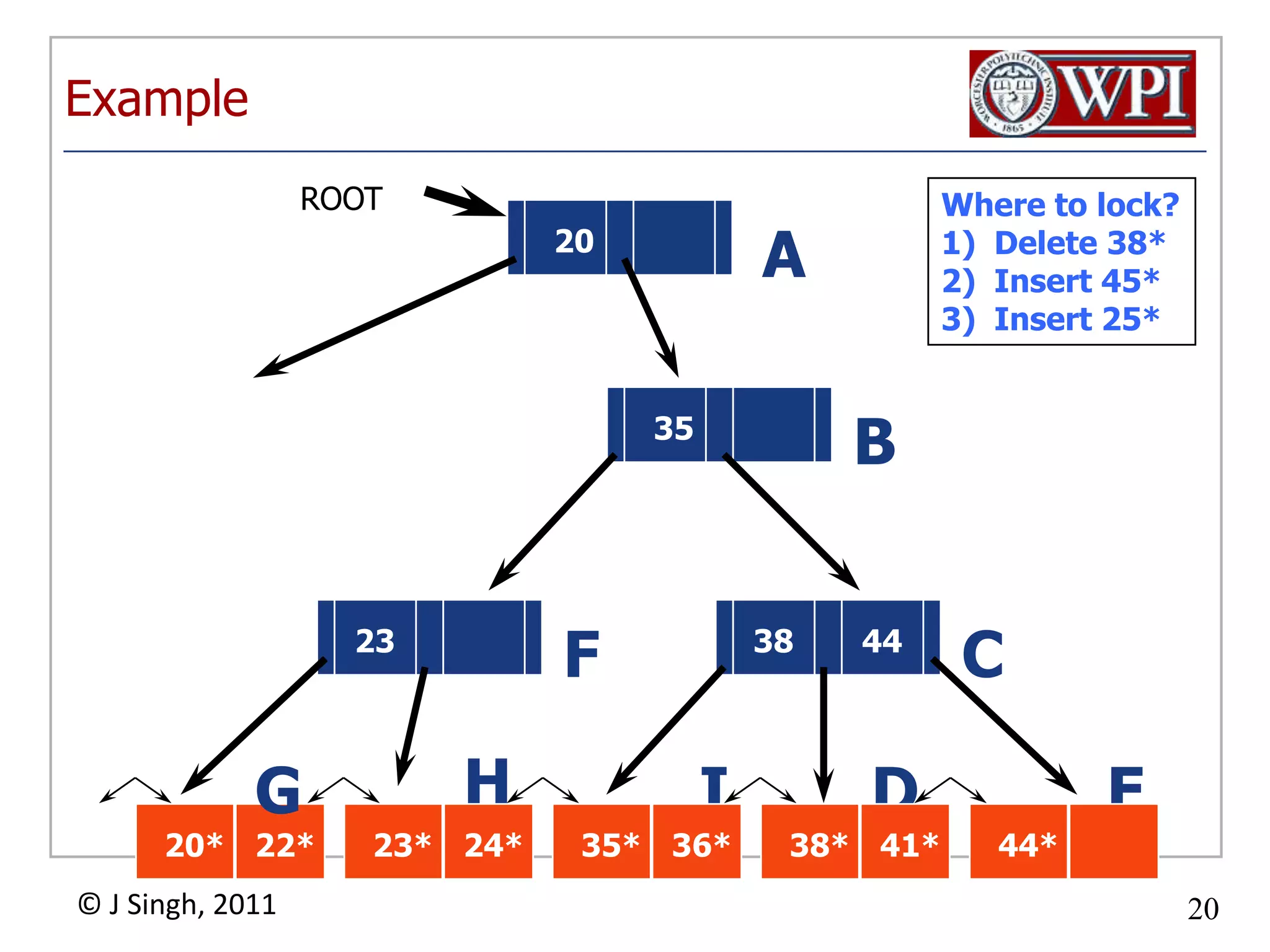


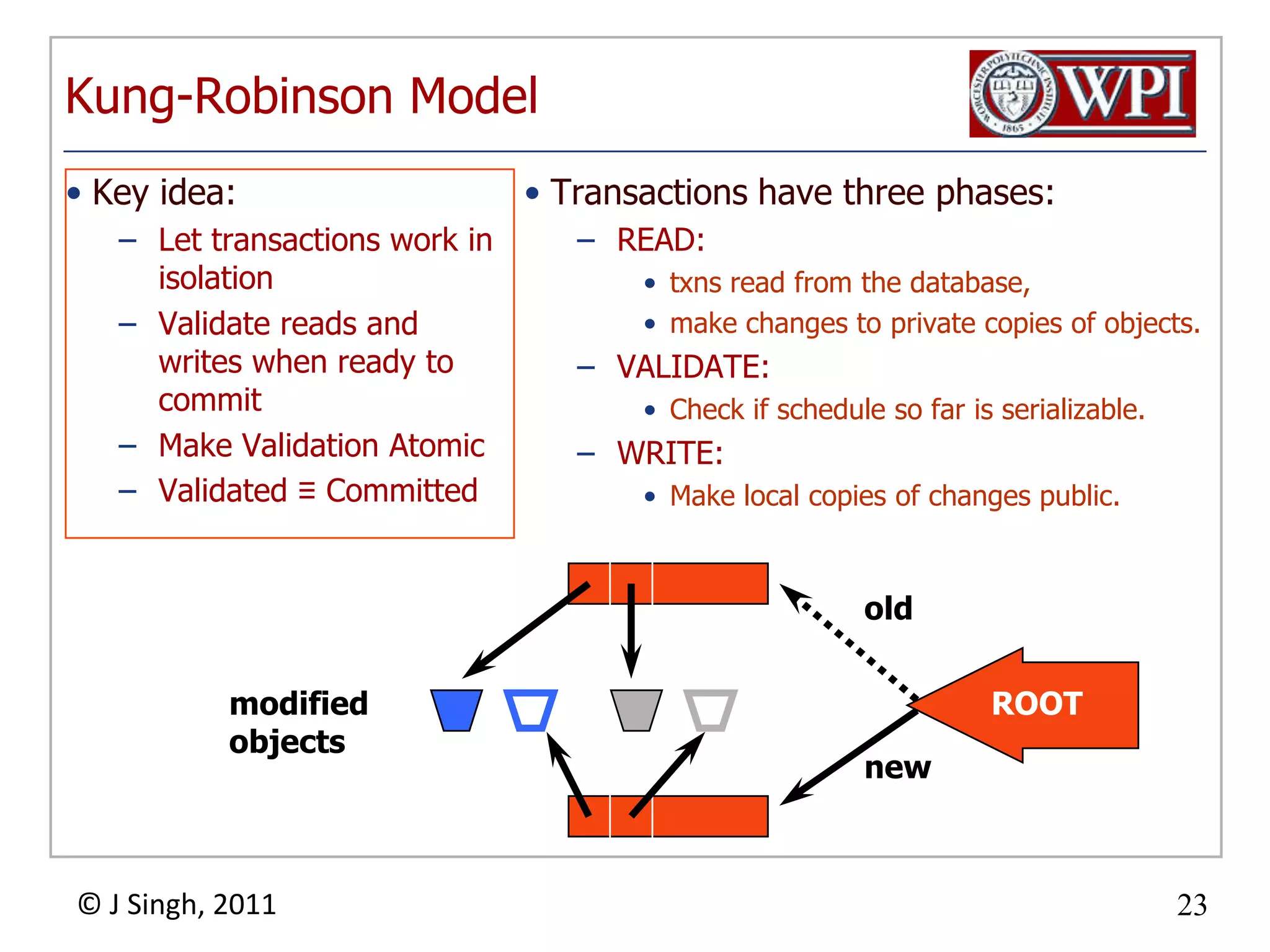









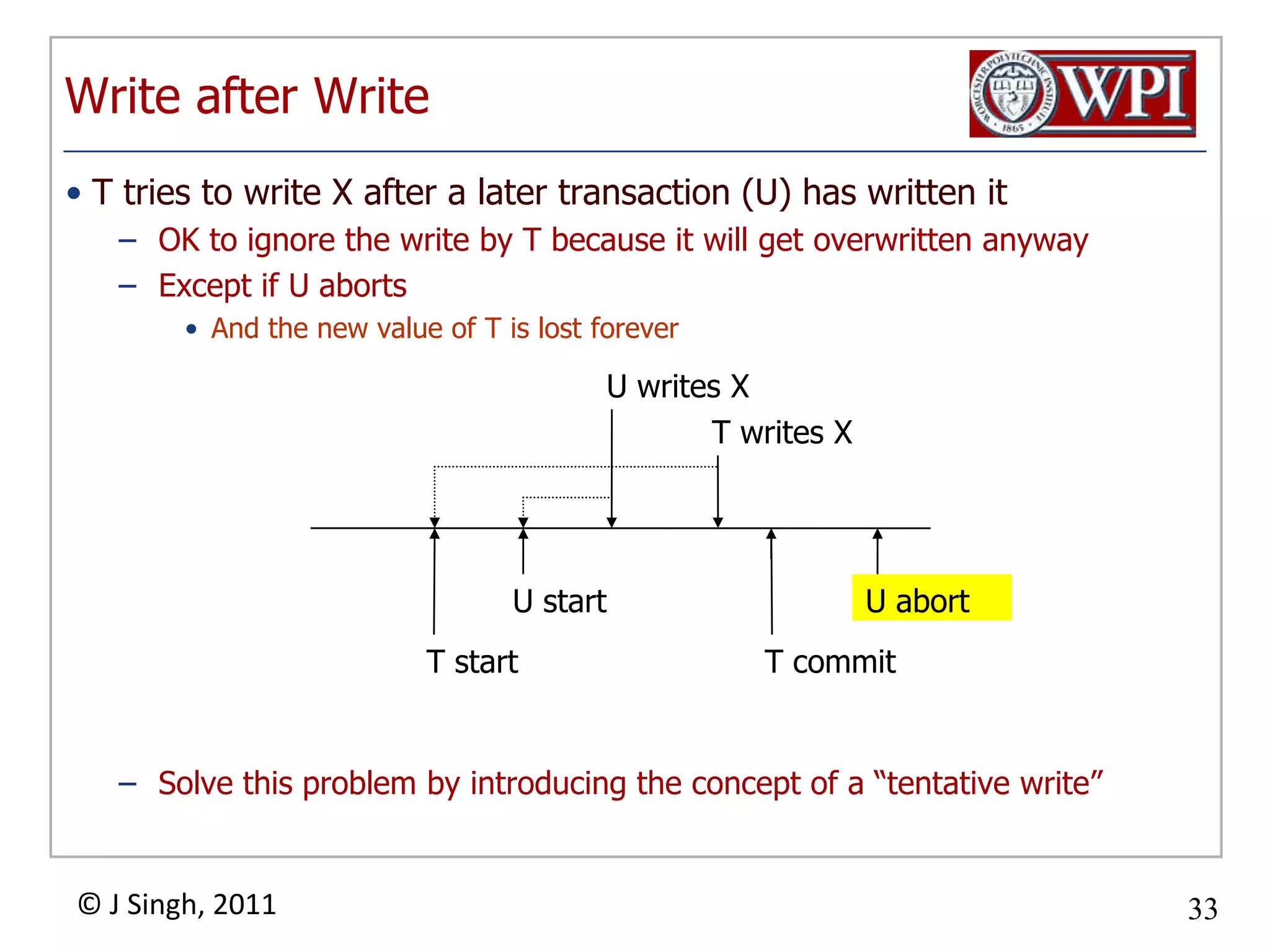






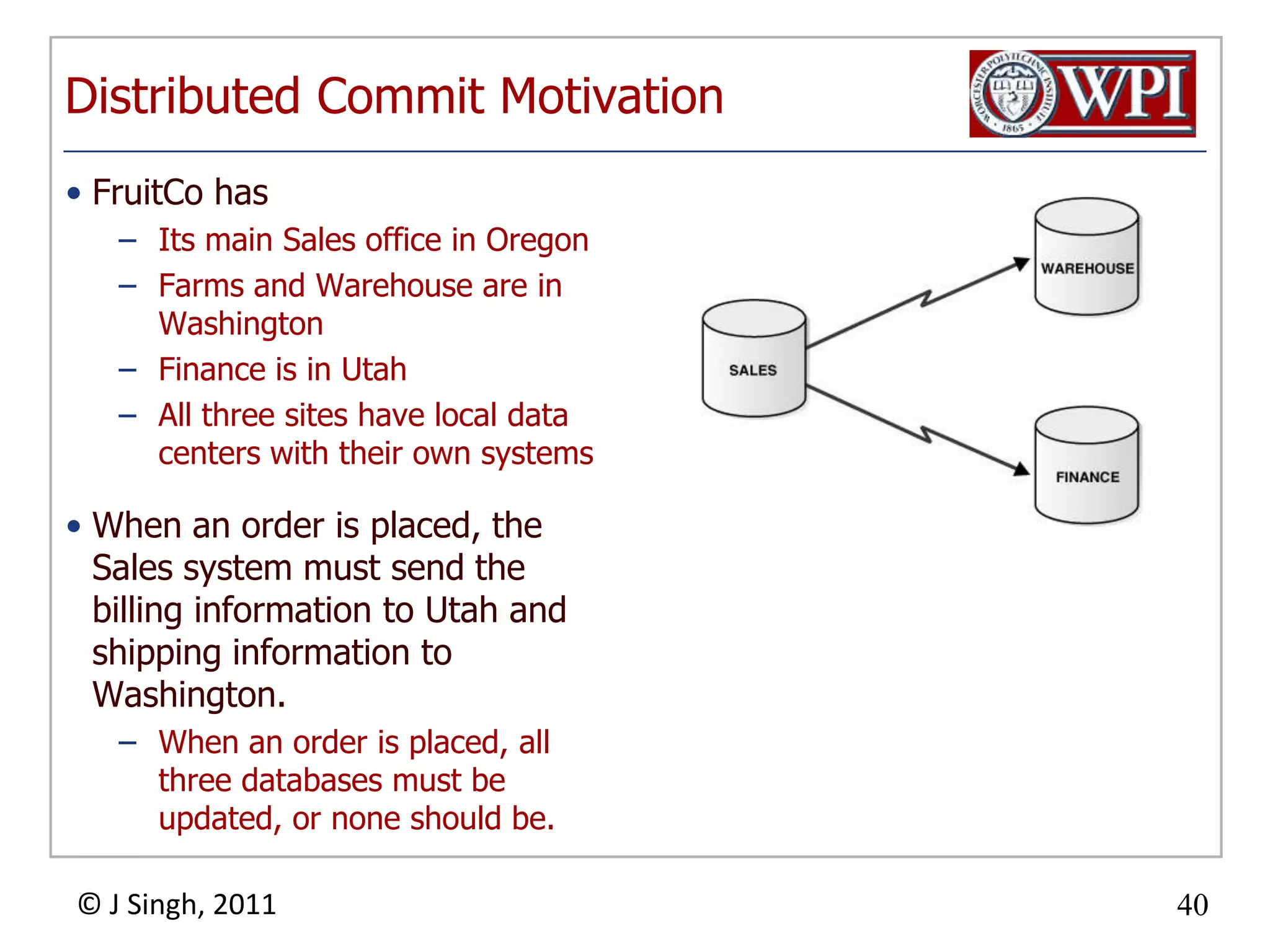


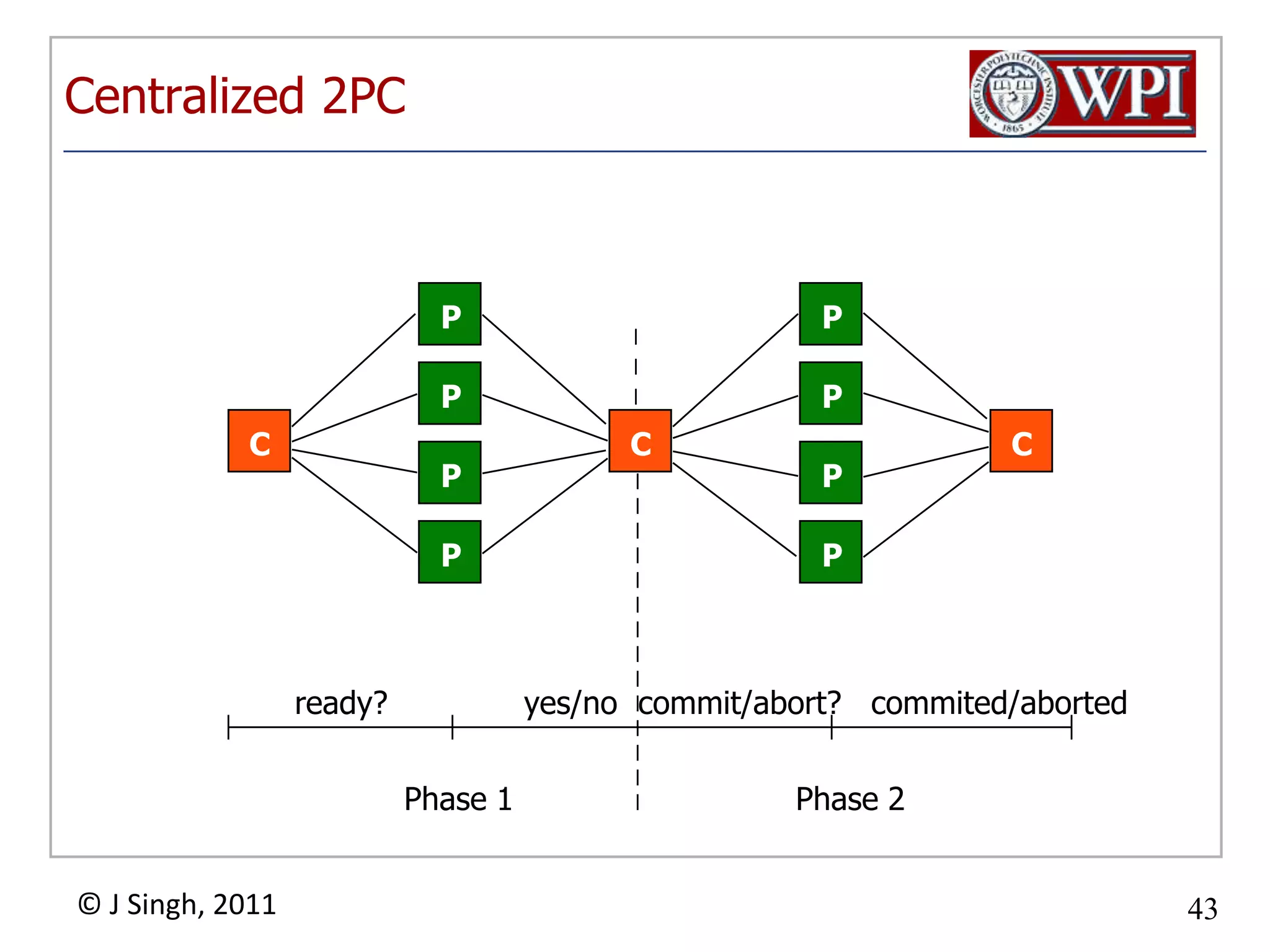
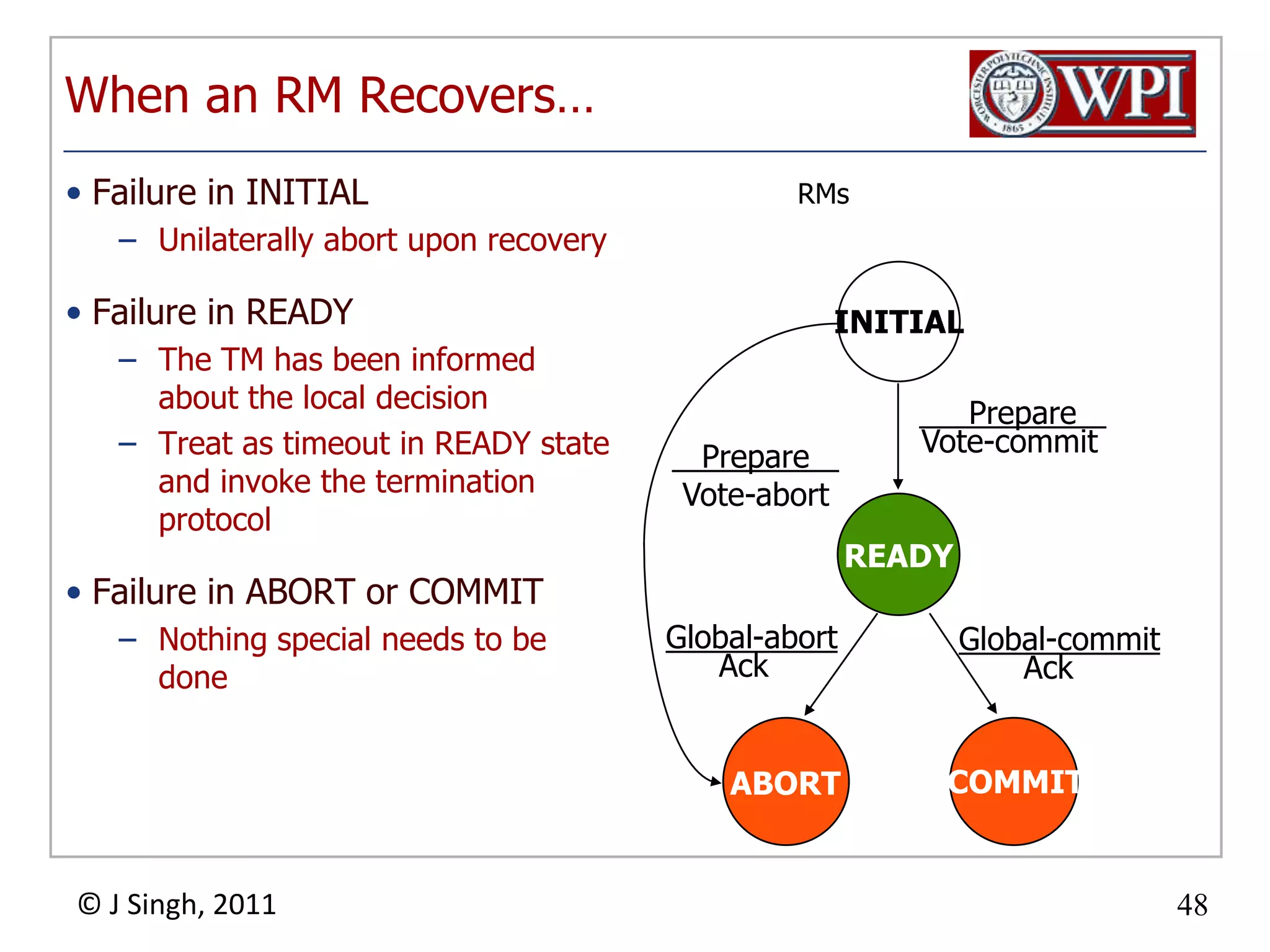
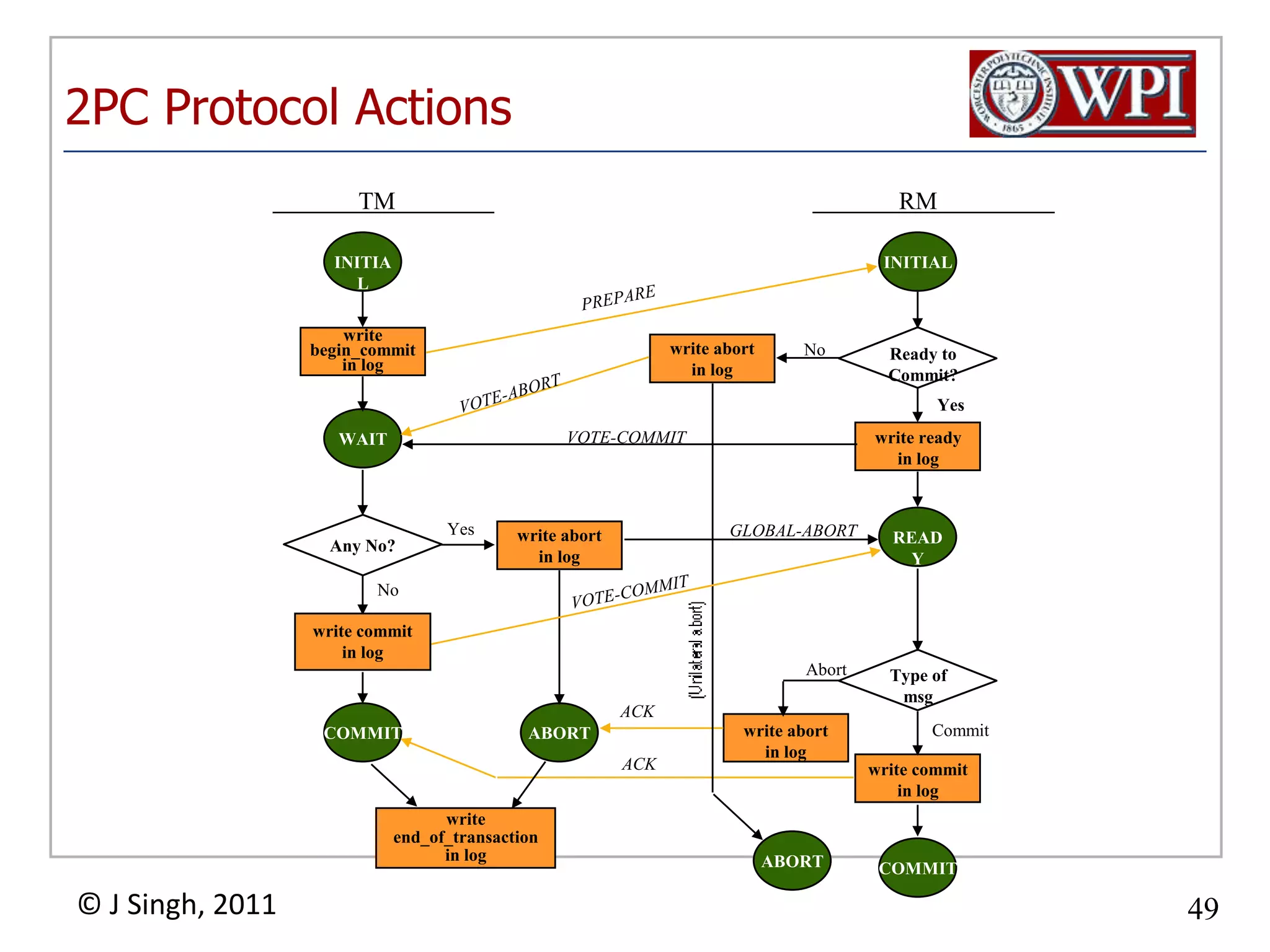


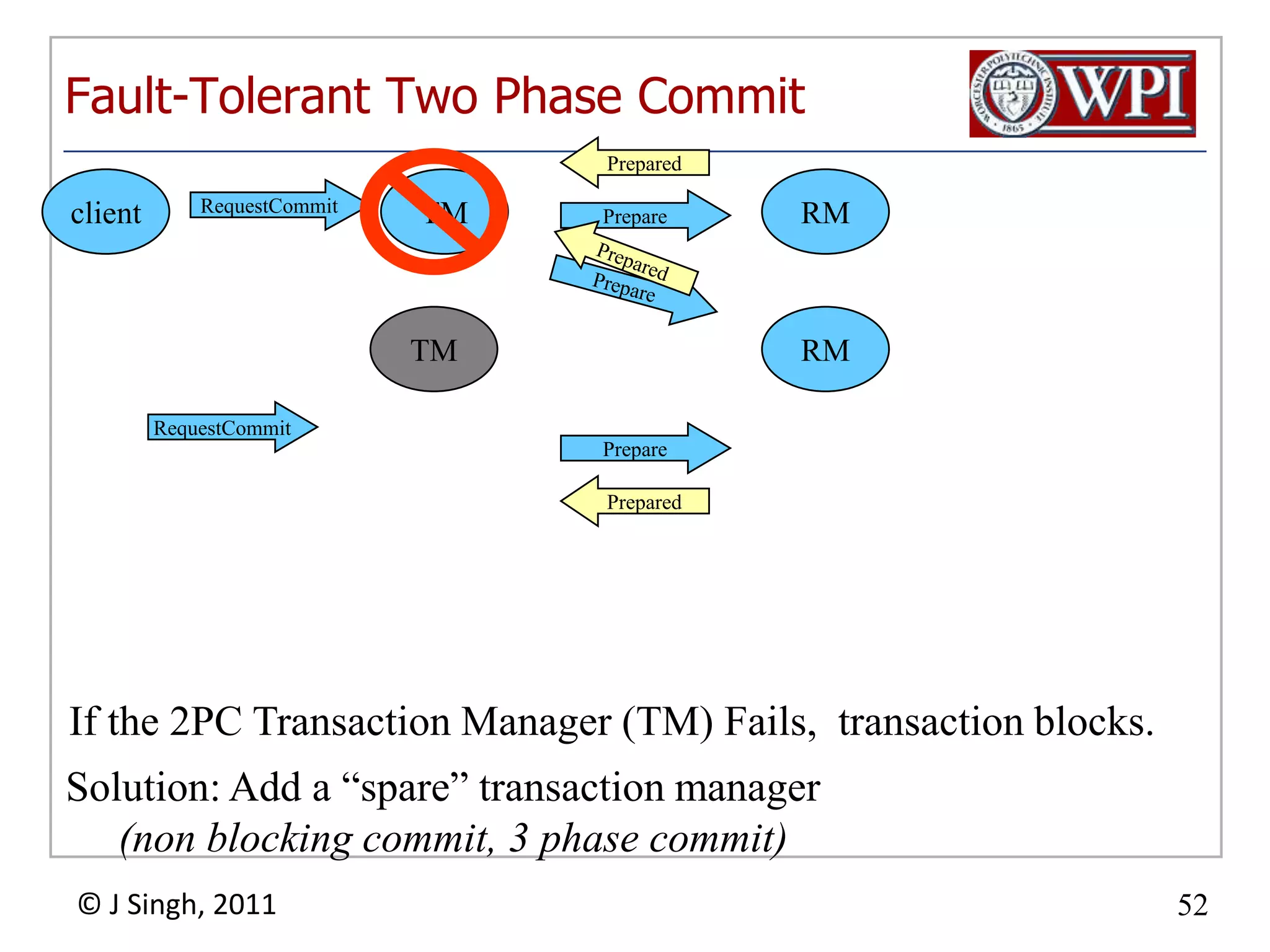
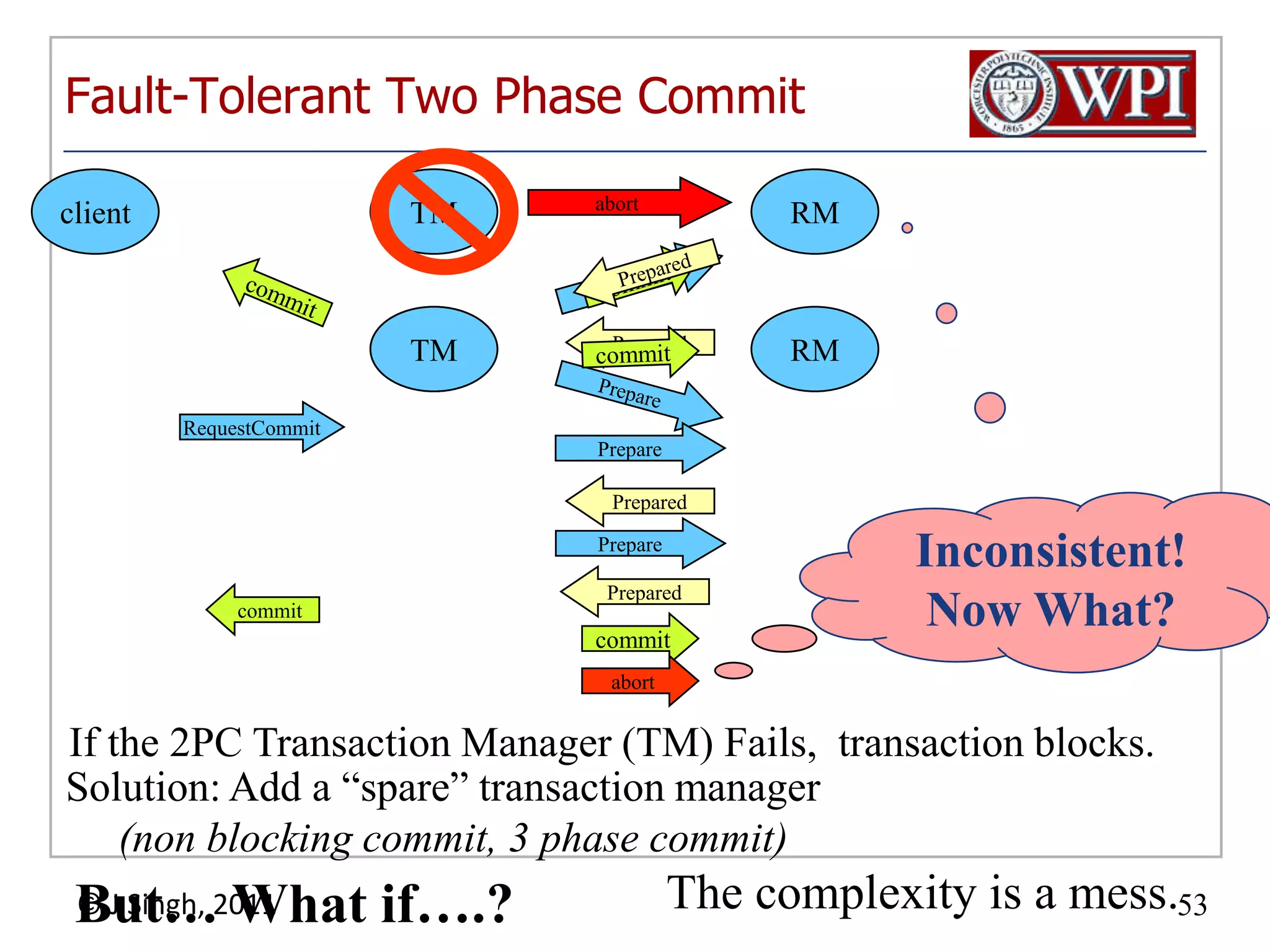

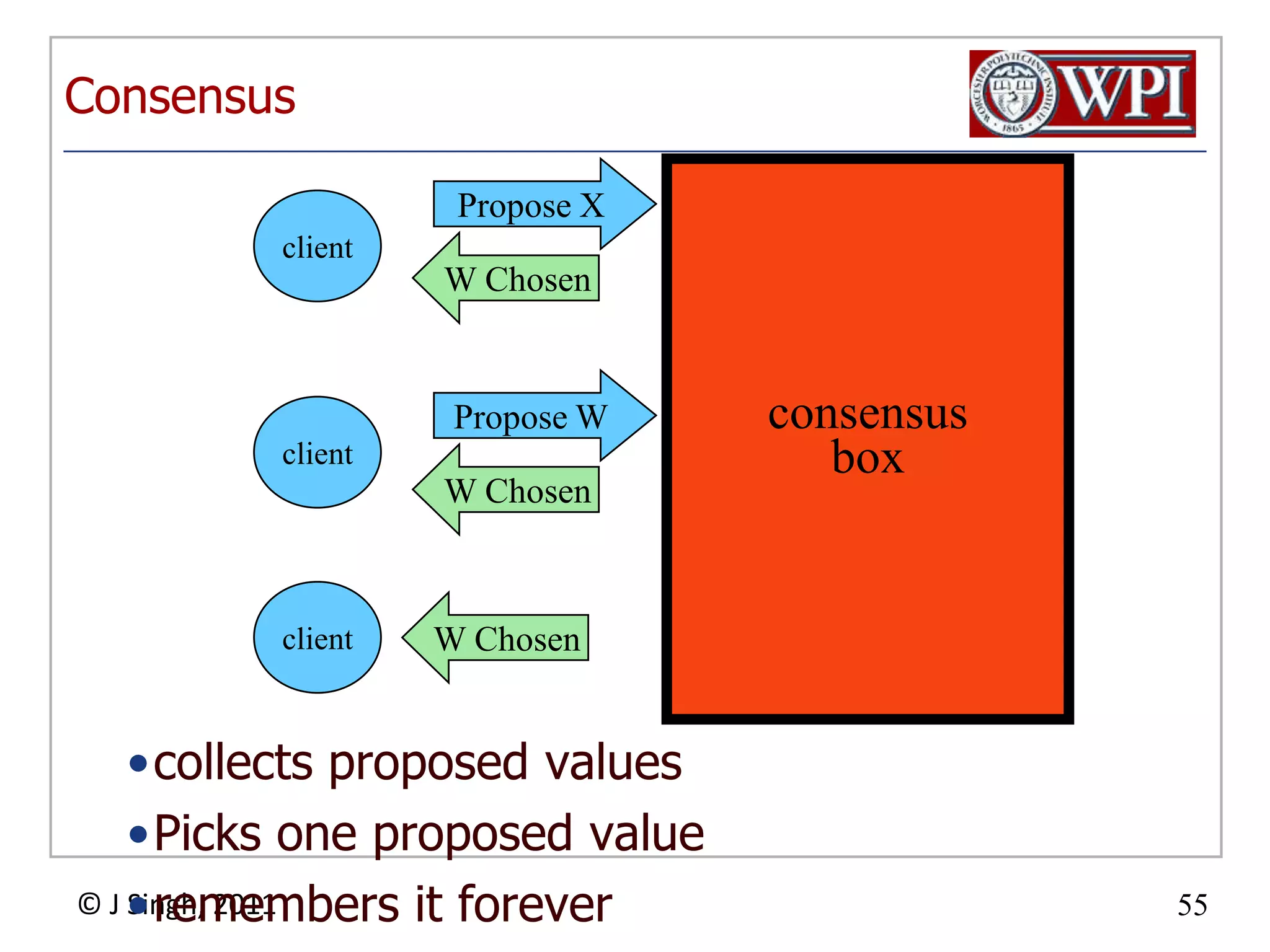
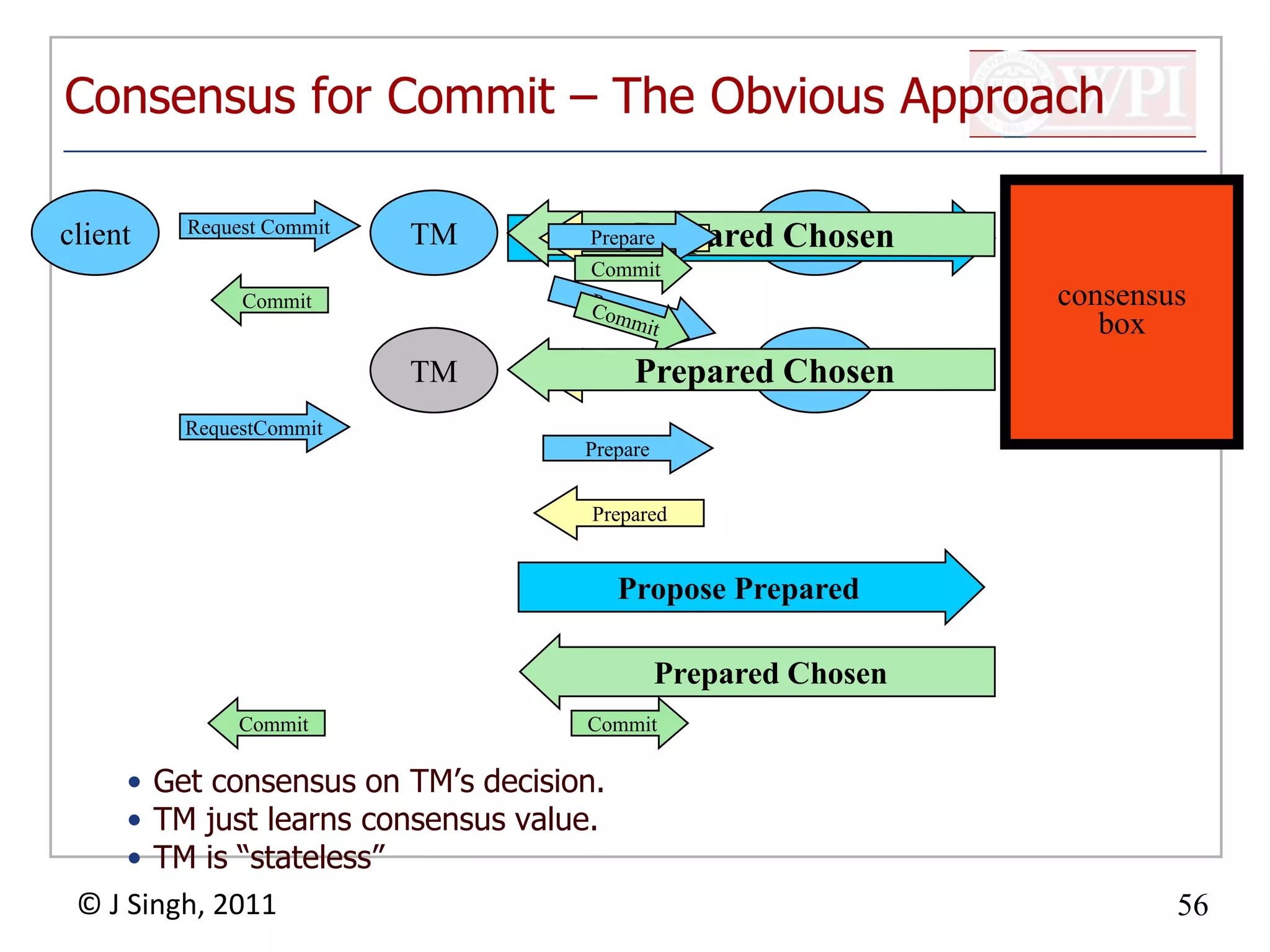
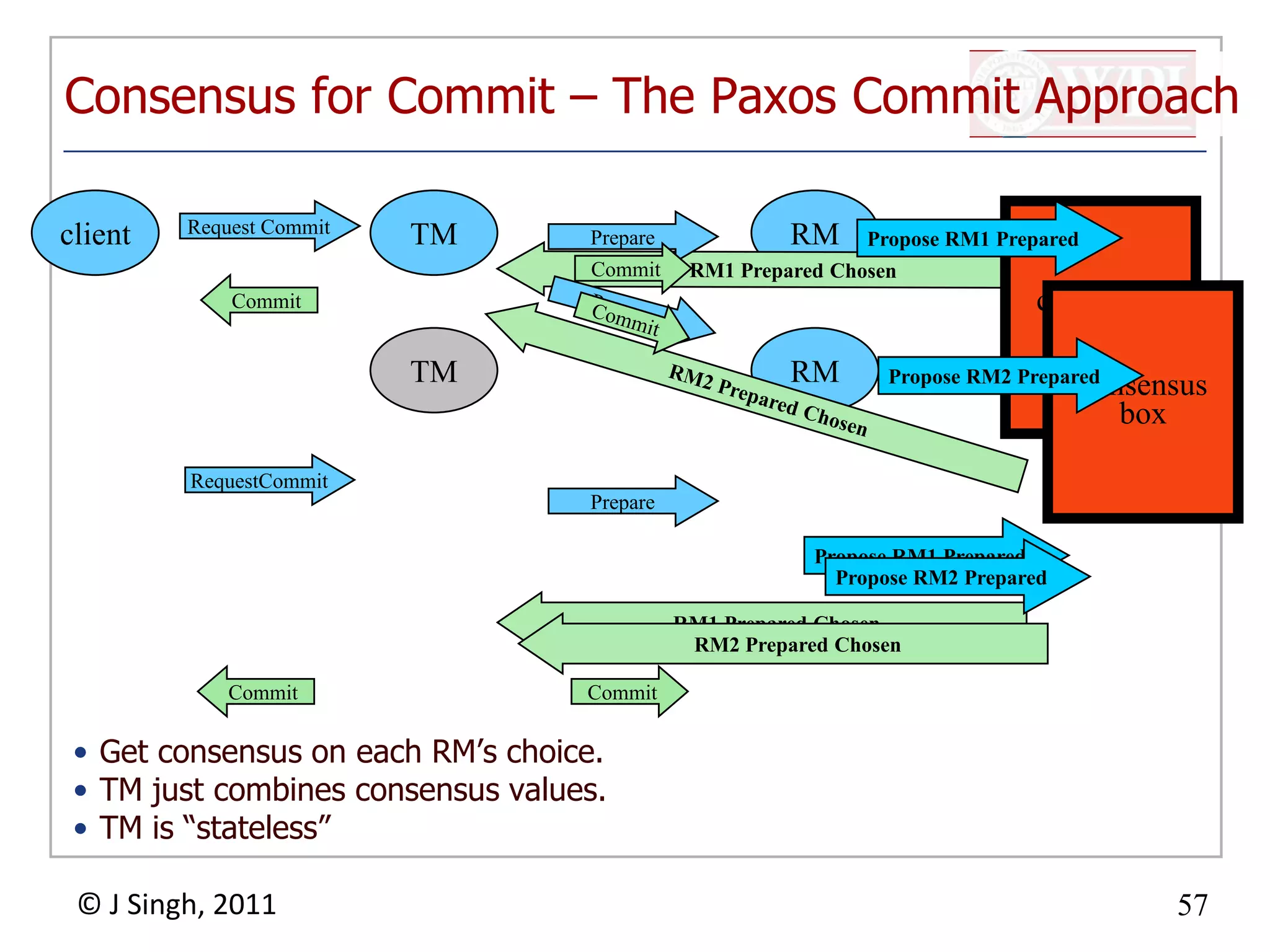
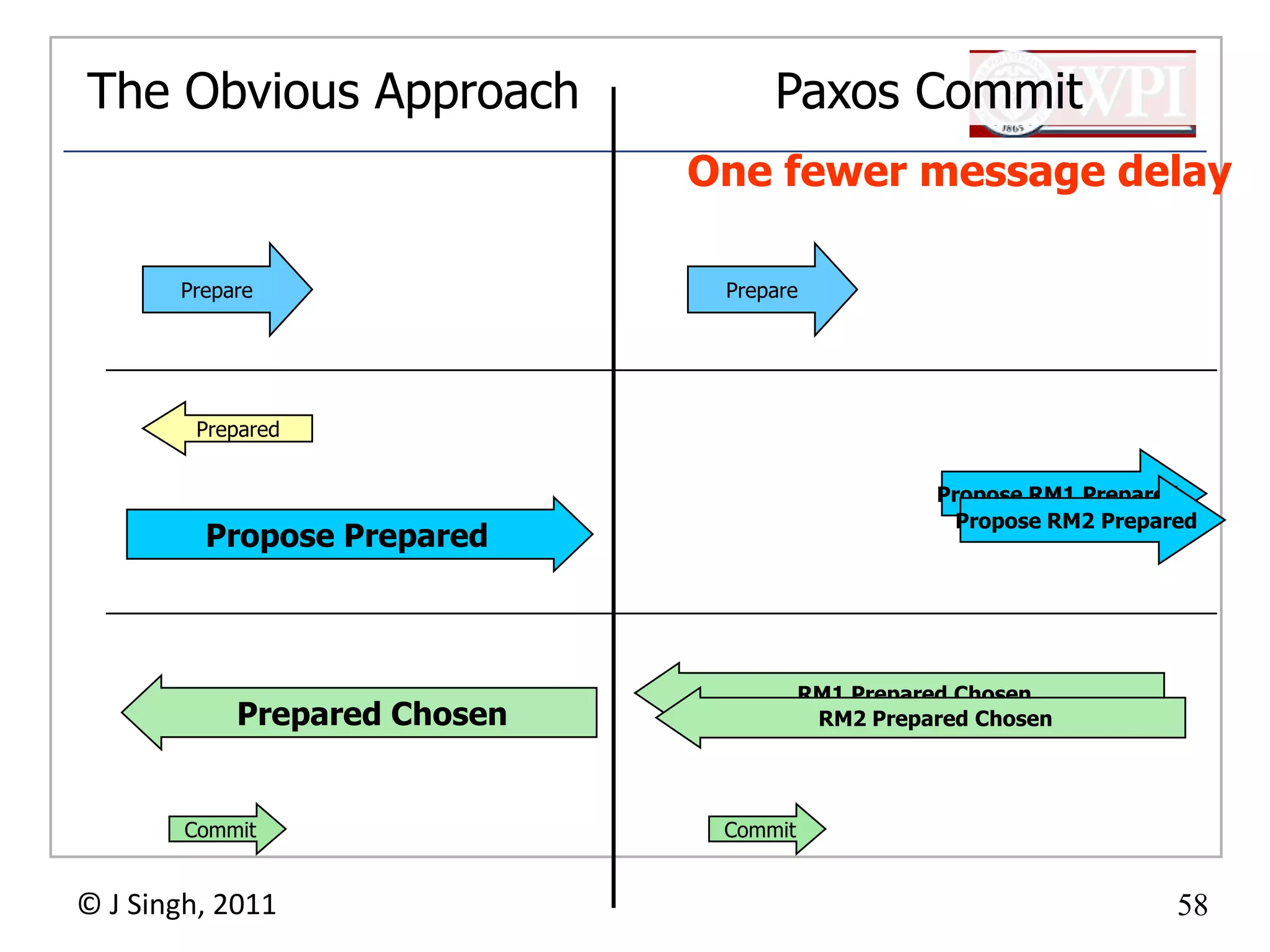
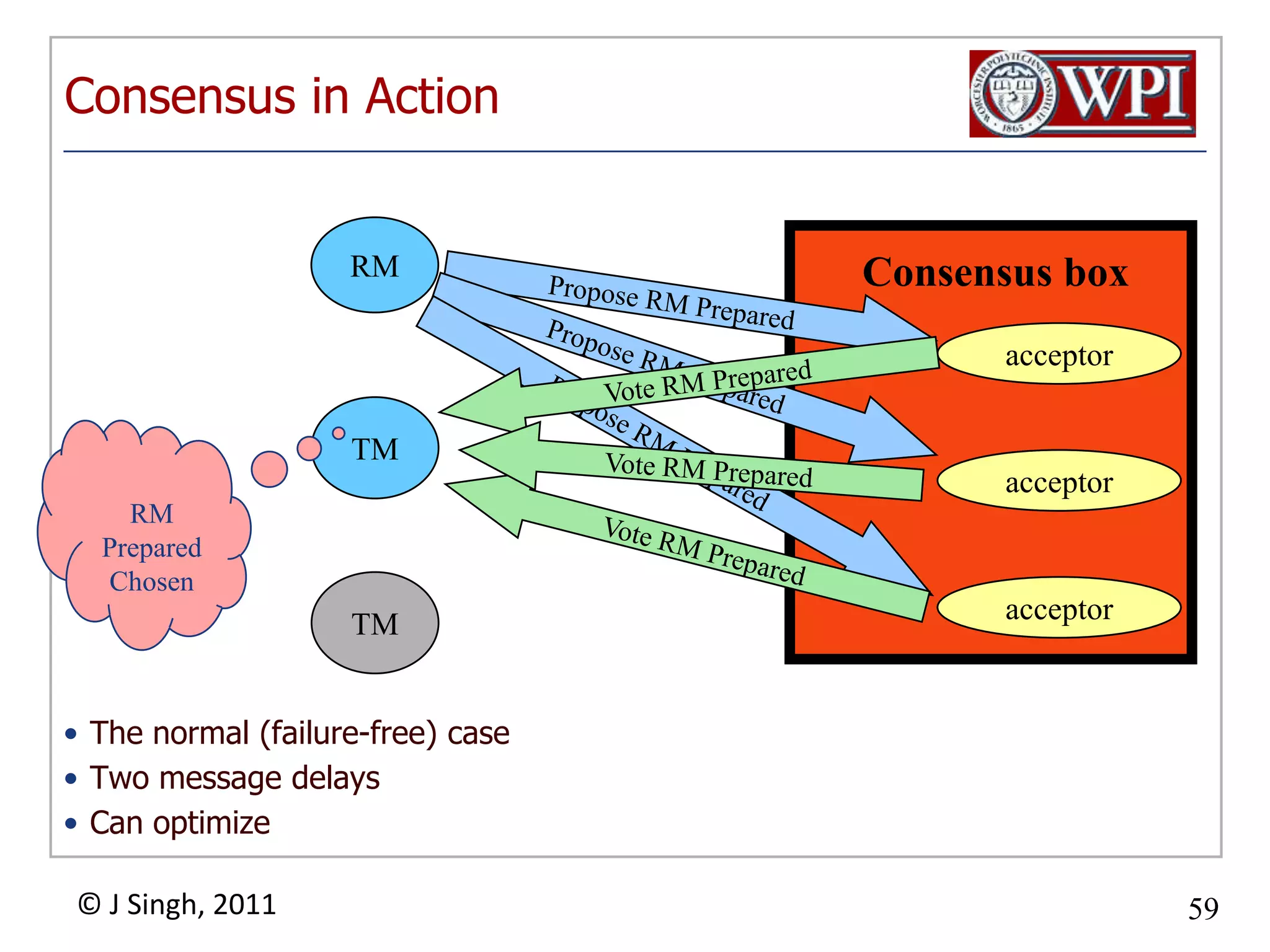





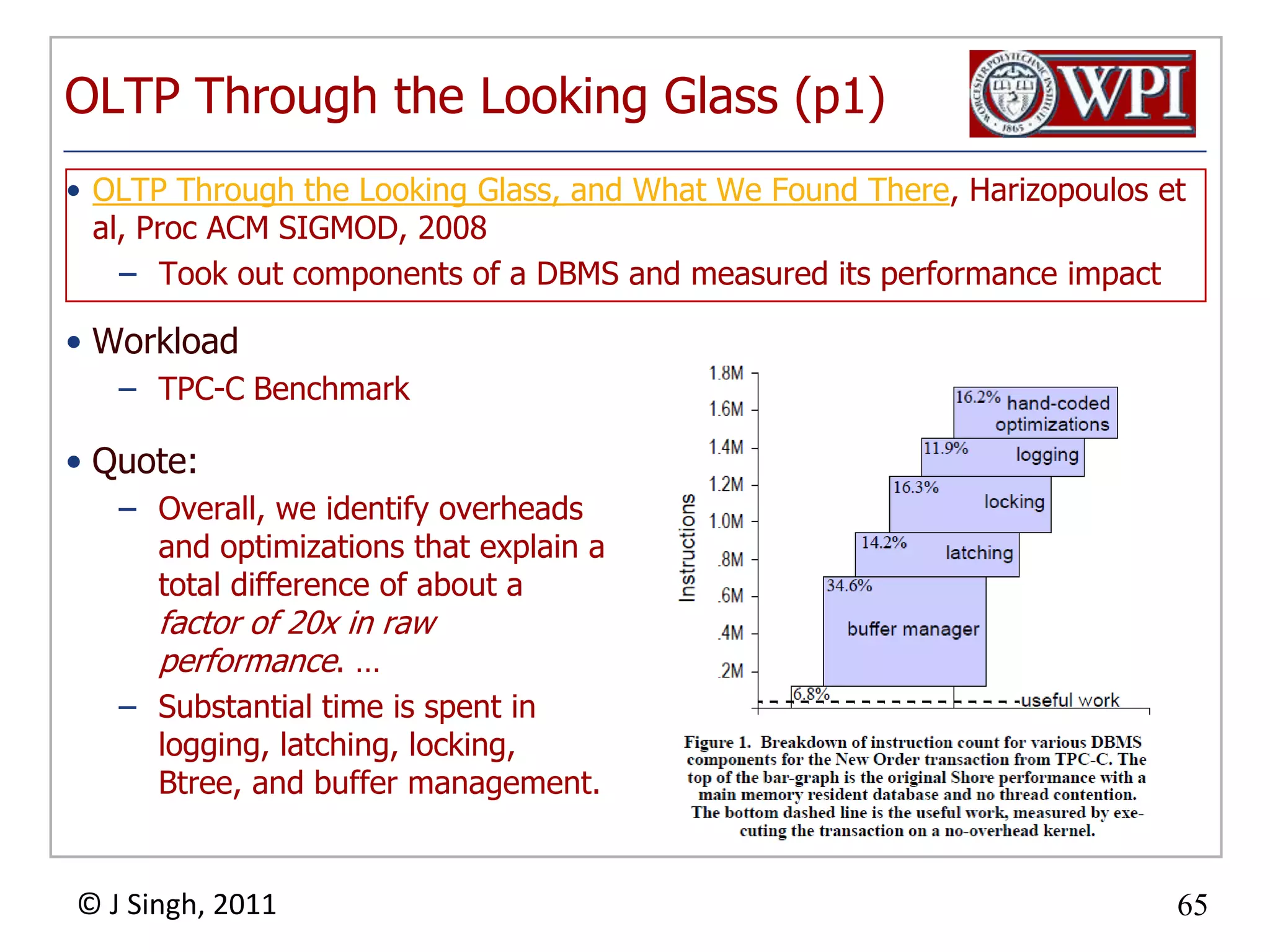






The document summarizes topics discussed in a database management systems lecture, including concurrency control techniques like intention locks, index locking, optimistic concurrency control using validation, and timestamp ordering algorithms. It also discusses multi-version concurrency control and challenges with commit in distributed databases using two phase commit and the Paxos algorithm. The lecture covers lock-based and optimistic approaches to concurrency control and managing concurrent transactions in a database system.

































































































