Downloaded 15 times








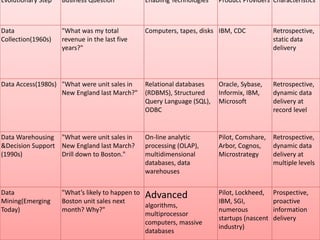






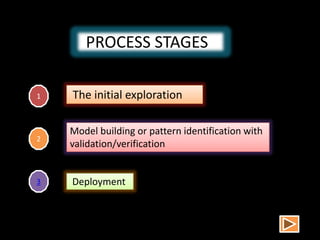


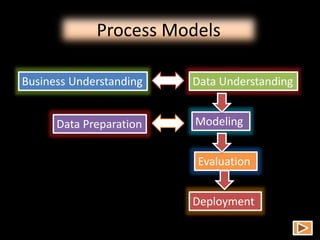
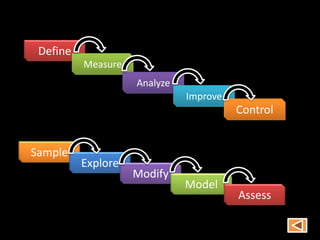













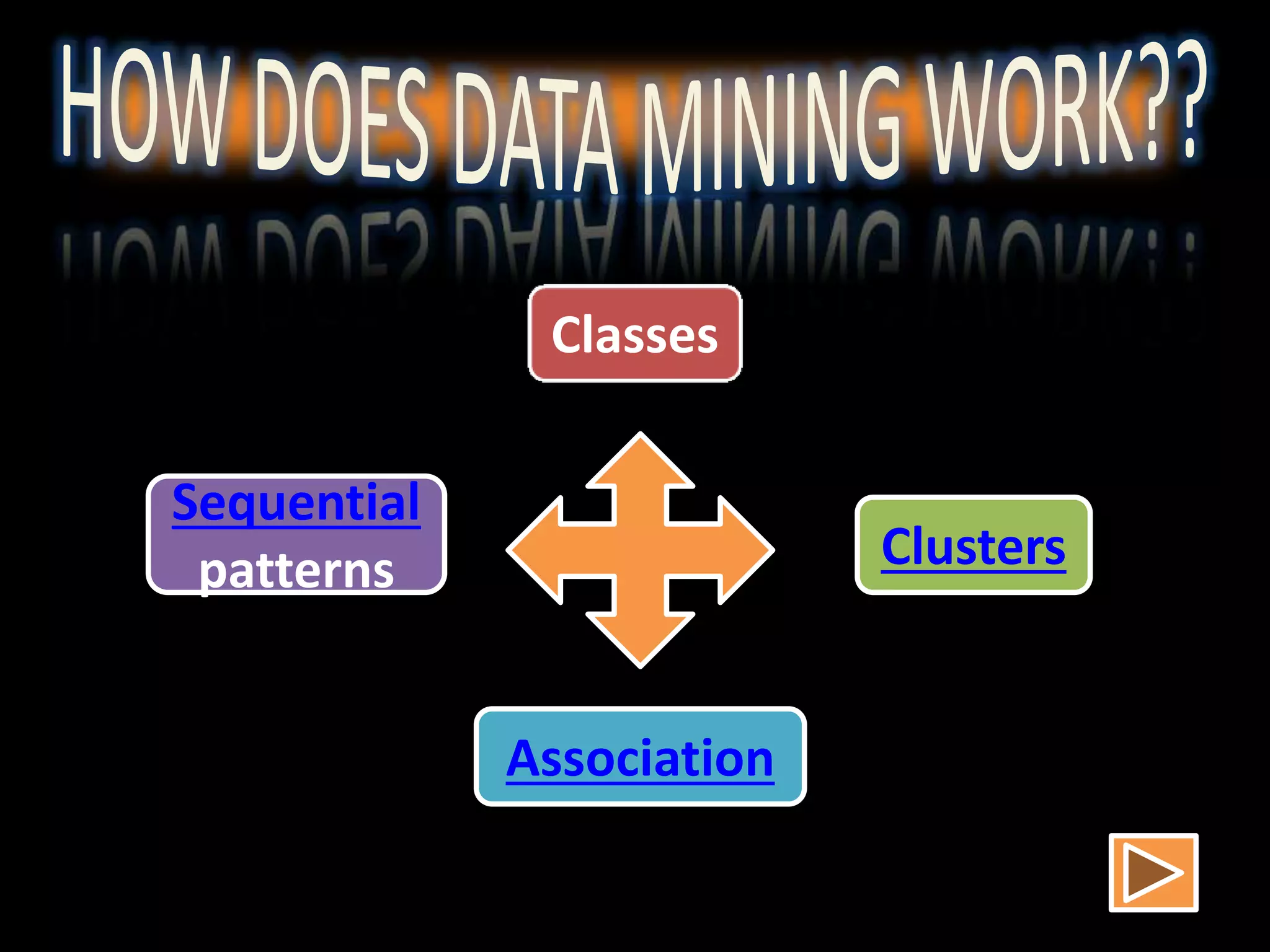




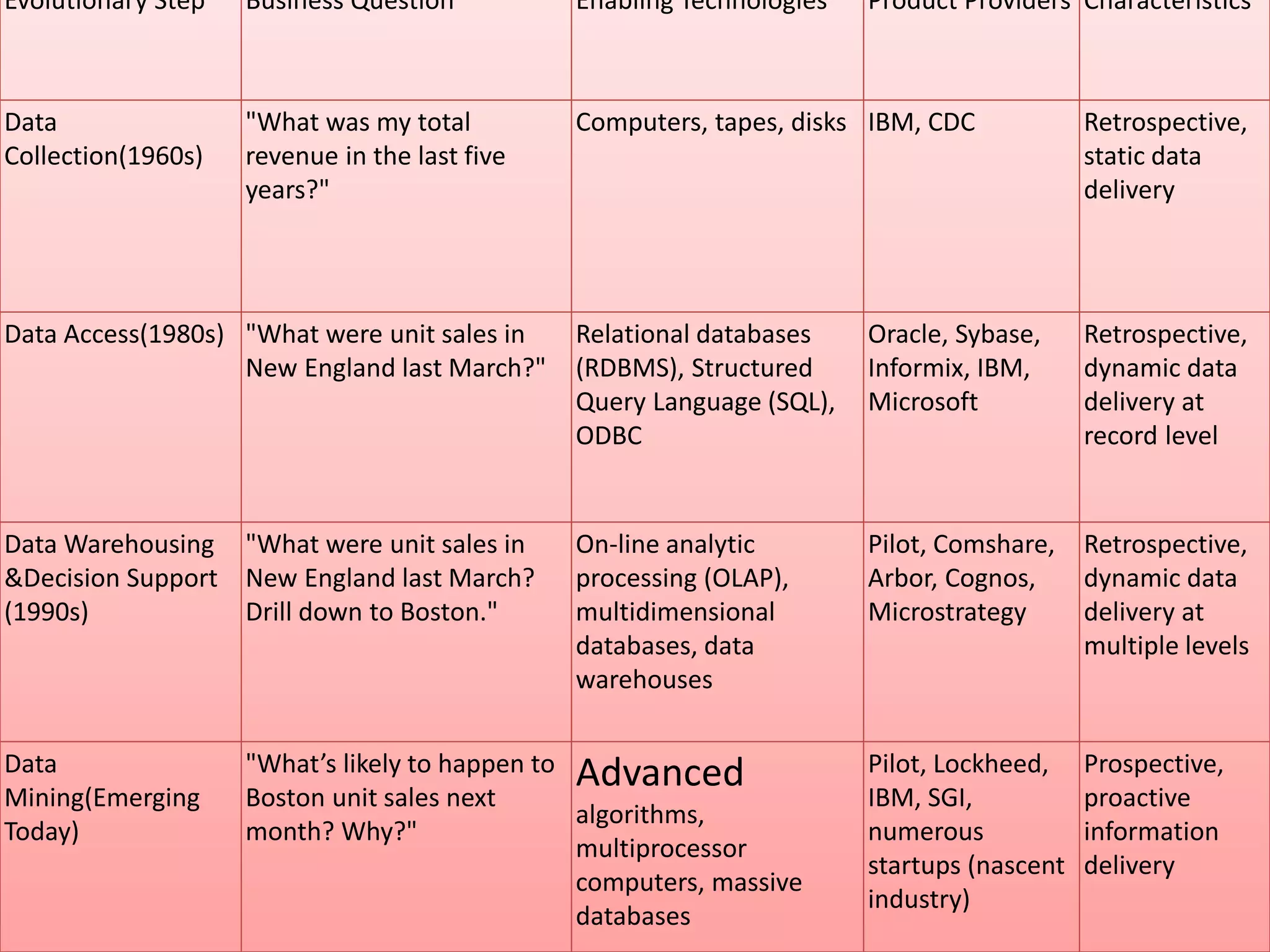


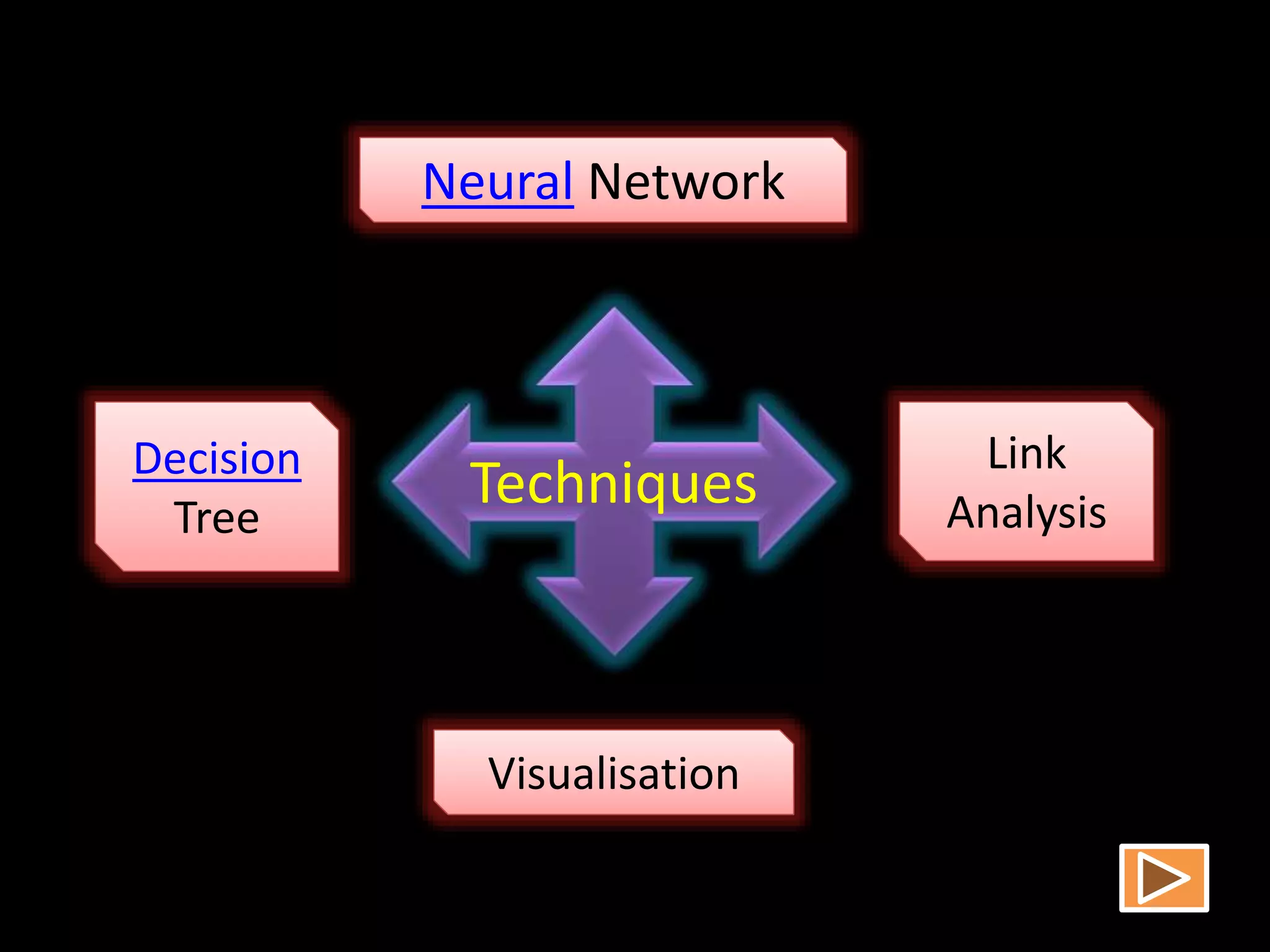




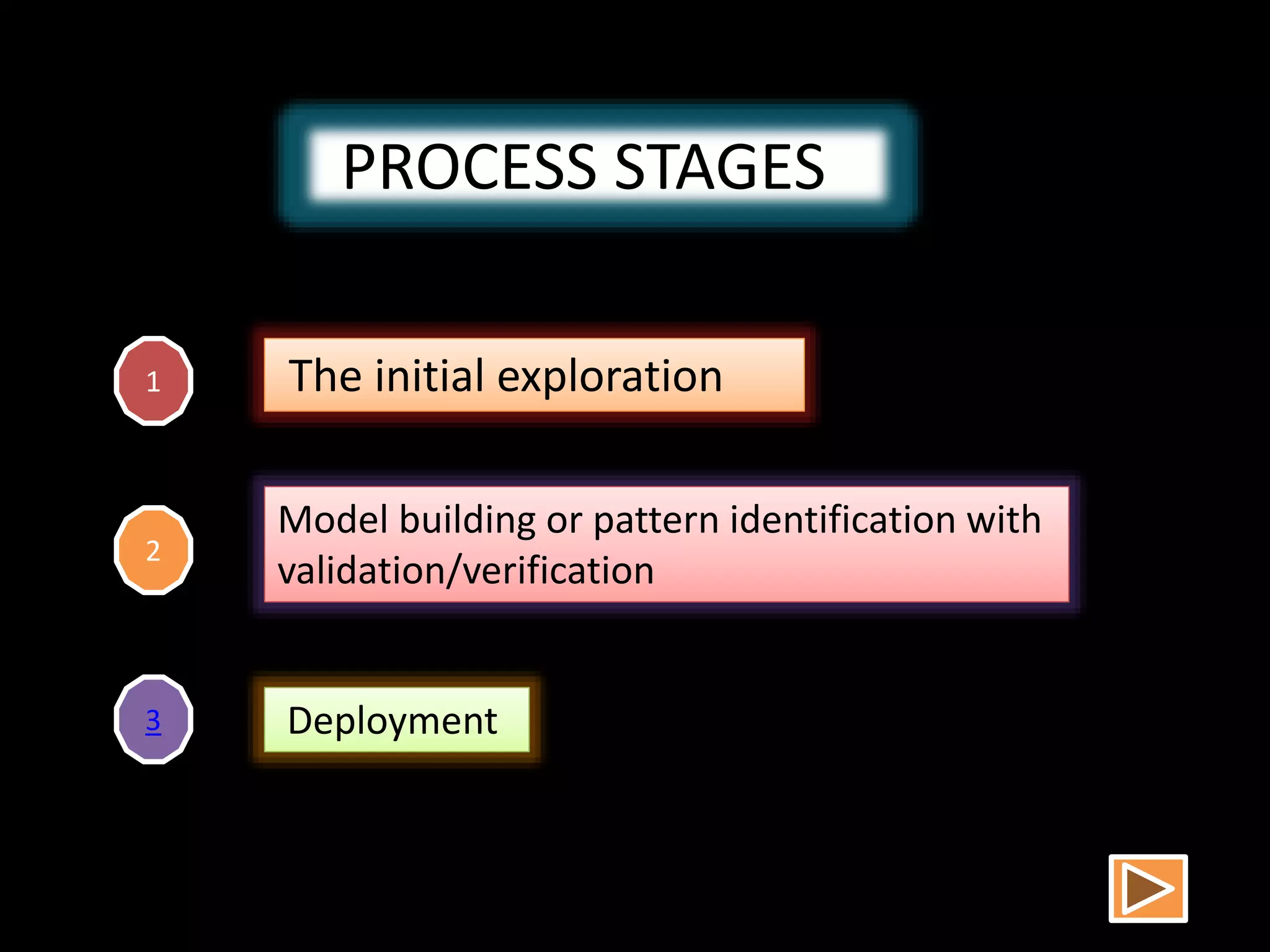


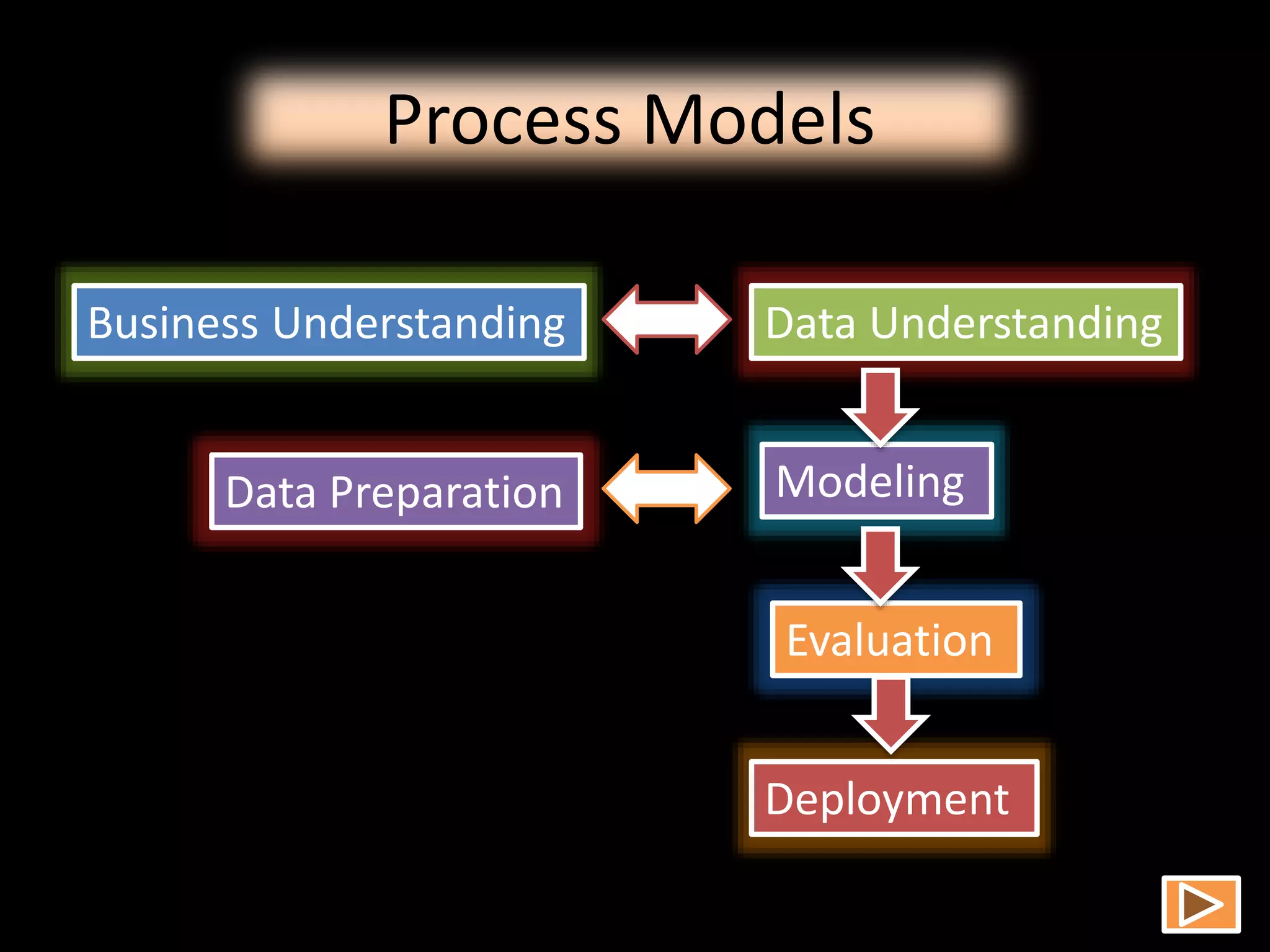
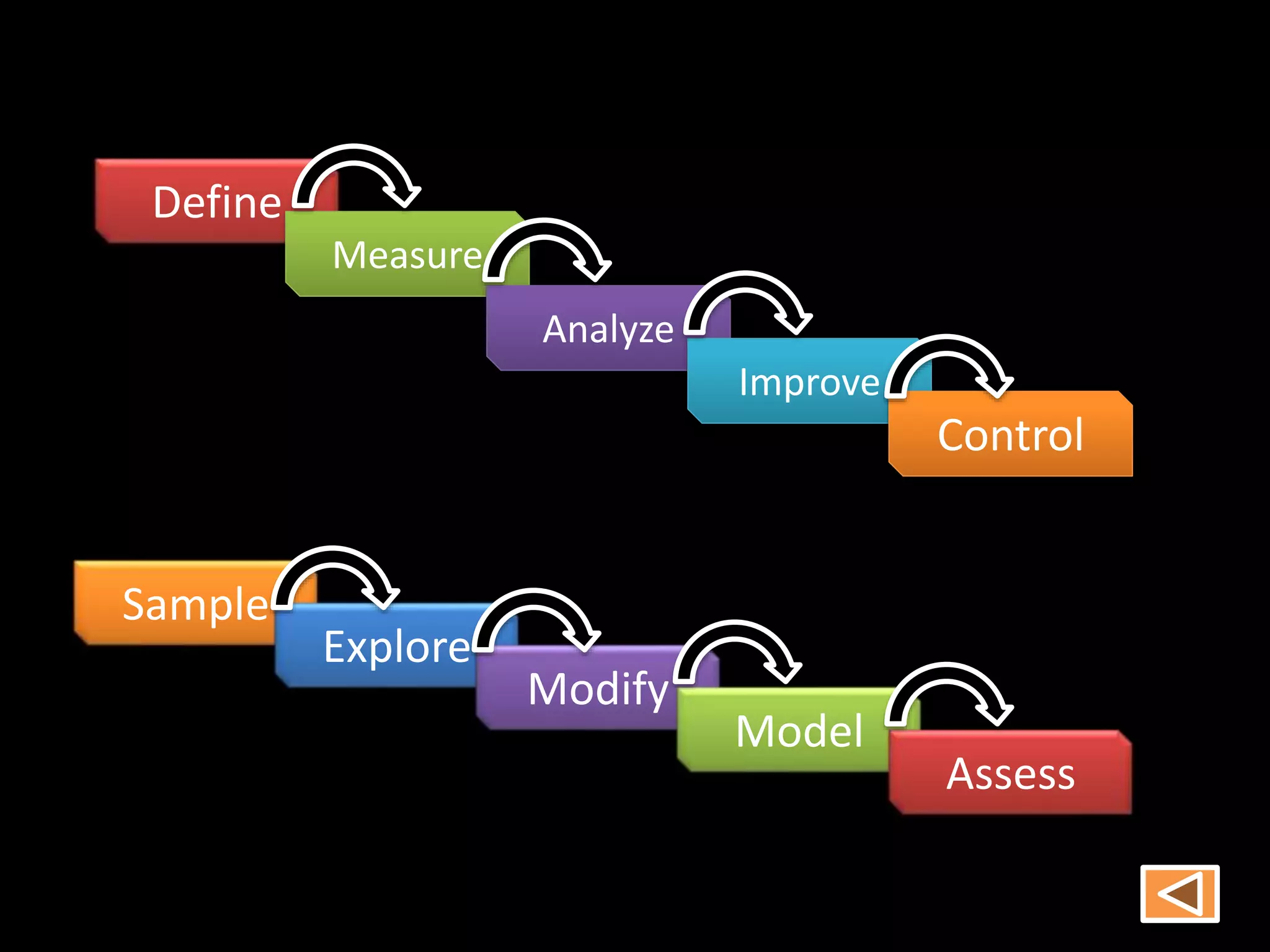

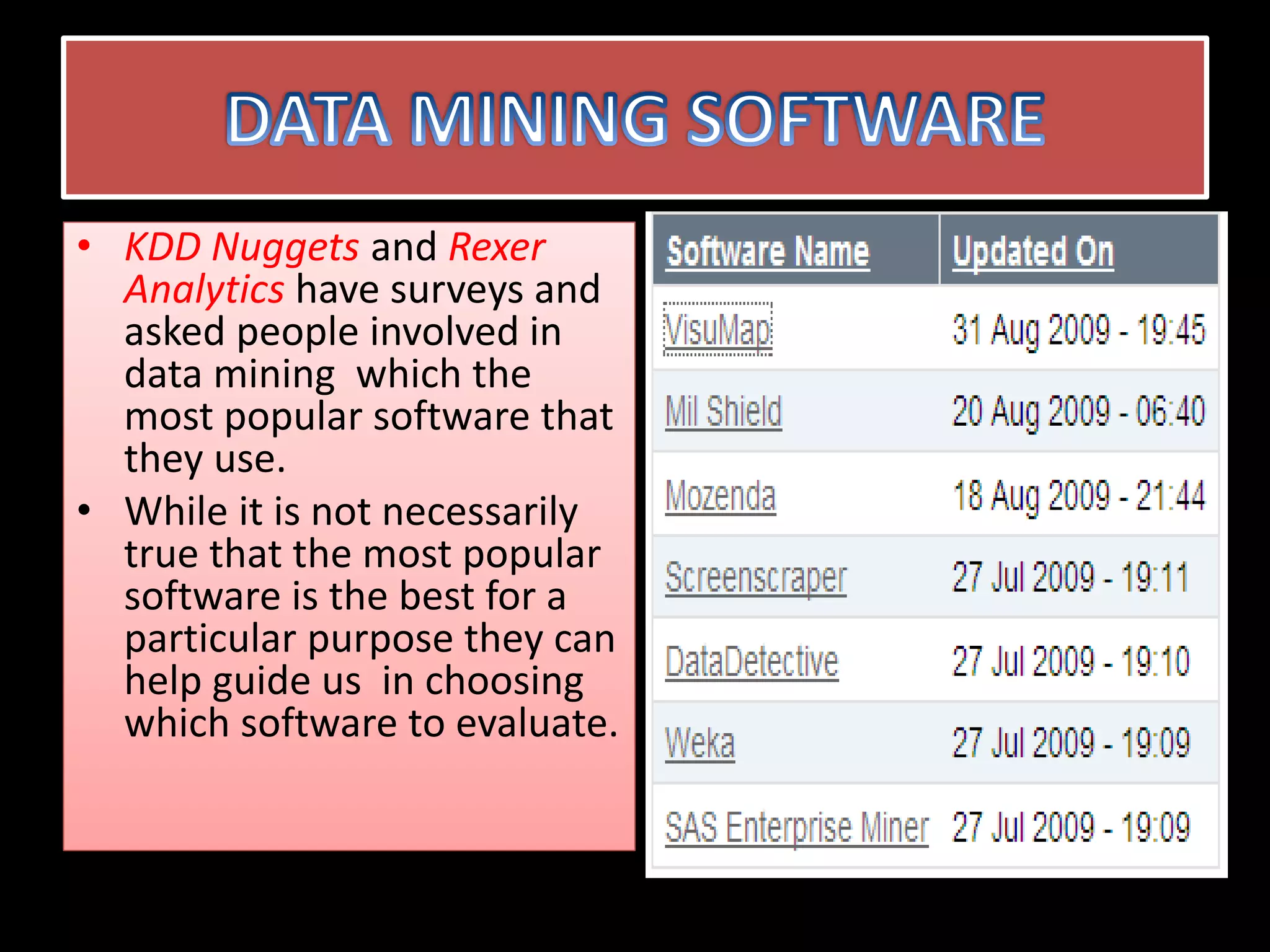



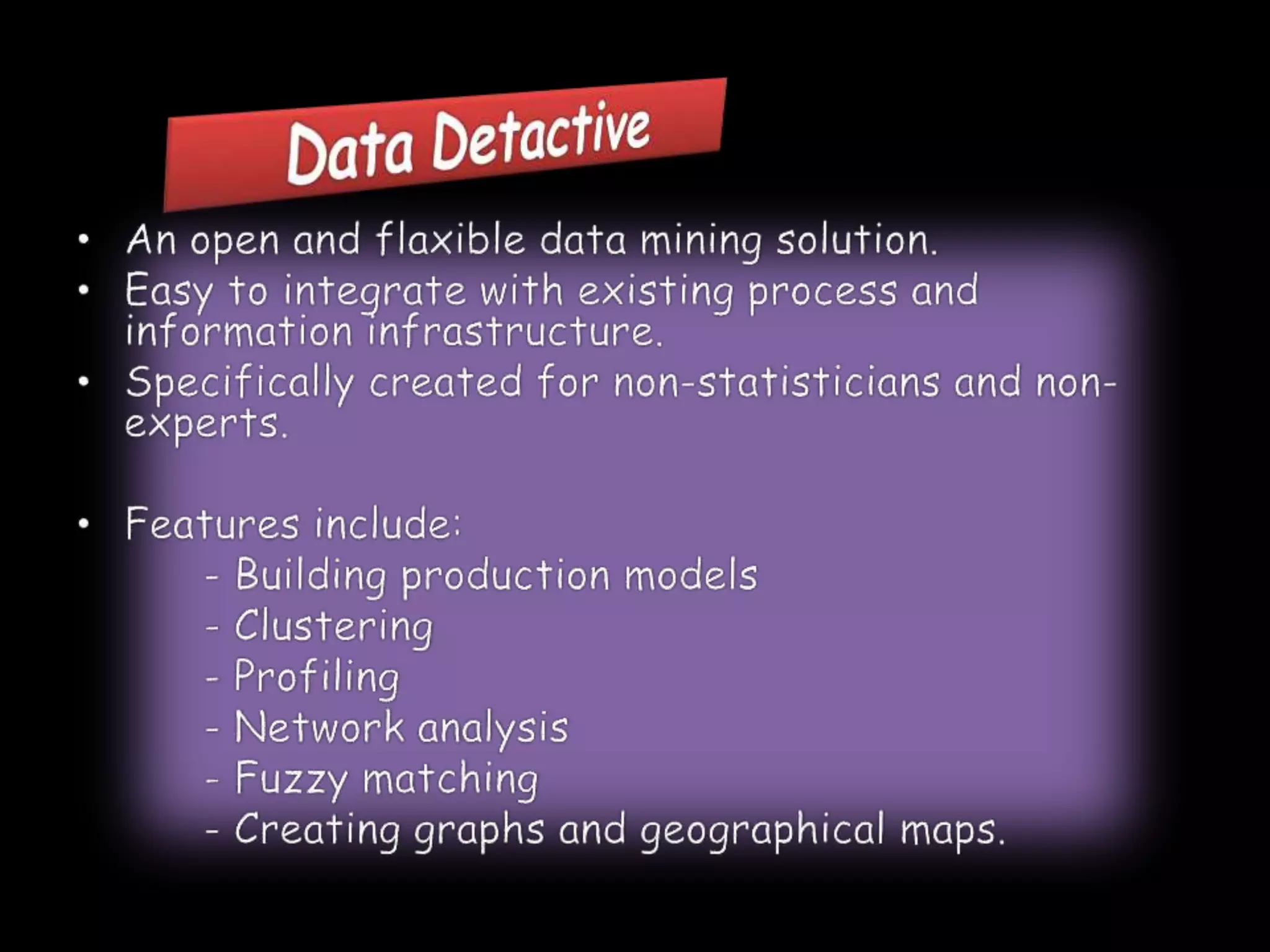




Data mining involves extracting hidden predictive information from large databases. It uses techniques like neural networks, decision trees, visualization, and link analysis. The data mining process involves exploration of the data, building and validating models, and deploying the results. Popular data mining software packages include R, which is open source and flexible, and SAS Enterprise Miner, which has an easy to use interface and supports a variety of techniques.












































































