Downloaded 864 times












![Aggregate Model
• Aggregate is a term coming from Domain-Driven
Design [Evans03]
– An aggregate is a collection of related objects that we wish
to treat as a unit for data manipulation, management a
consistency.
• We like to update aggregates with atomic operation
• We like to communicate with our data storage in
terms of aggregates
13http://pbdmng.datatoknowledge.it/readingMaterial/Evans03.pdf](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/85/5-Data-Modeling-for-NoSQL-1-2-13-320.jpg)

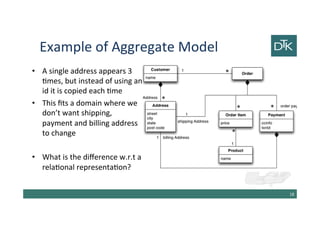
![Example of Aggregate Model
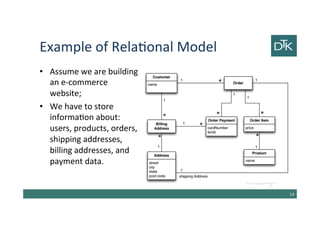
• The link between customer and the order is a relationship
between aggregates
20
//Customer
{
"id": 1,
"name": "Fabio",
"billingAddress": [
{
"city": "Bari"
}
]
}
//Orders
{
"id": 99,
"customerId": 1,
"orderItems": [
{
"productId": 27,
"price": 34,
"productName": "Scala in Action”
} ],
"shippingAddress": [ {"city": "Bari”} ],
"orderPayment": [
{ "ccinfo": "100-432423-545-134",
"txnId": "afdfsdfsd",
"billingAddress": [ {"city": "Bari” }]
} ]
}](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/85/5-Data-Modeling-for-NoSQL-1-2-20-320.jpg)
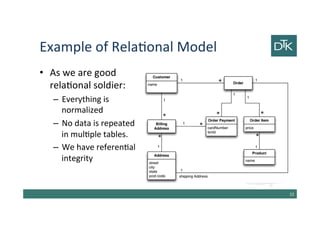
![Orders Details
•There is the customer id
•The product name is a part of the
ordered Items
•The product id is part of the
ordered items
•The address is stored several
times
21
//Orders
{
"id": 99,
"customerId": 1,
"orderItems": [
{
"productId": 27,
"price": 34,
"productName": "Scala in Action”
} ],
"shippingAddress": [ {"city": "Bari”} ],
"orderPayment": [
{ "ccinfo": "100-432423-545-134",
"txnId": "afdfsdfsd",
"billingAddress": [ {"city": "Bari” }]
} ]
}](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/85/5-Data-Modeling-for-NoSQL-1-2-21-320.jpg)




















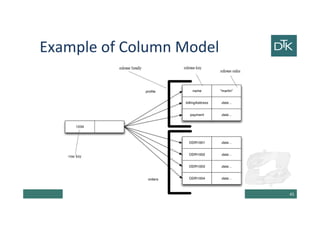
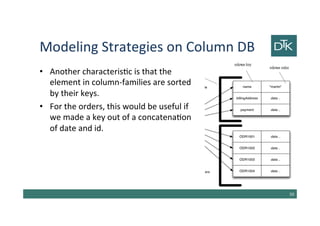
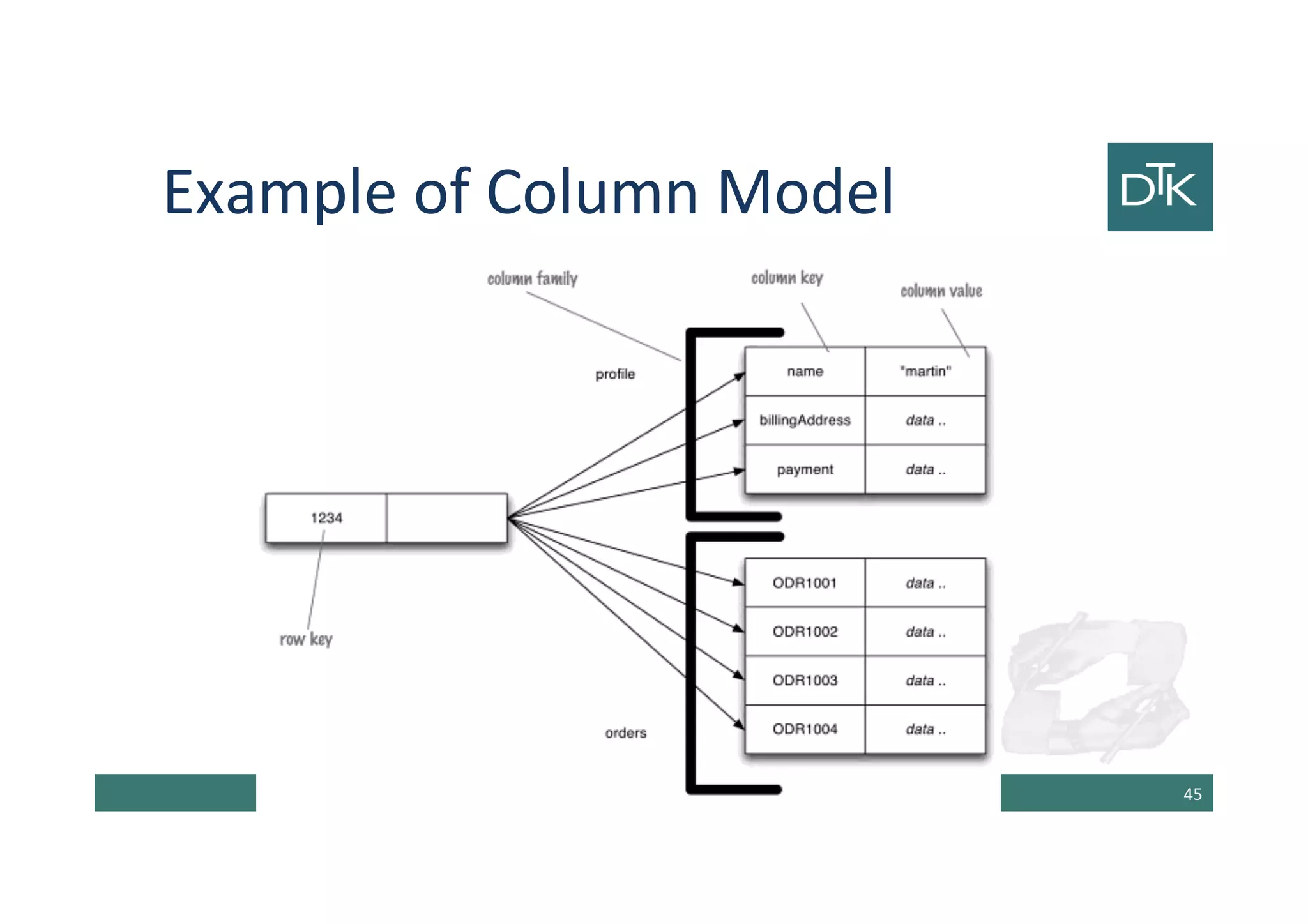
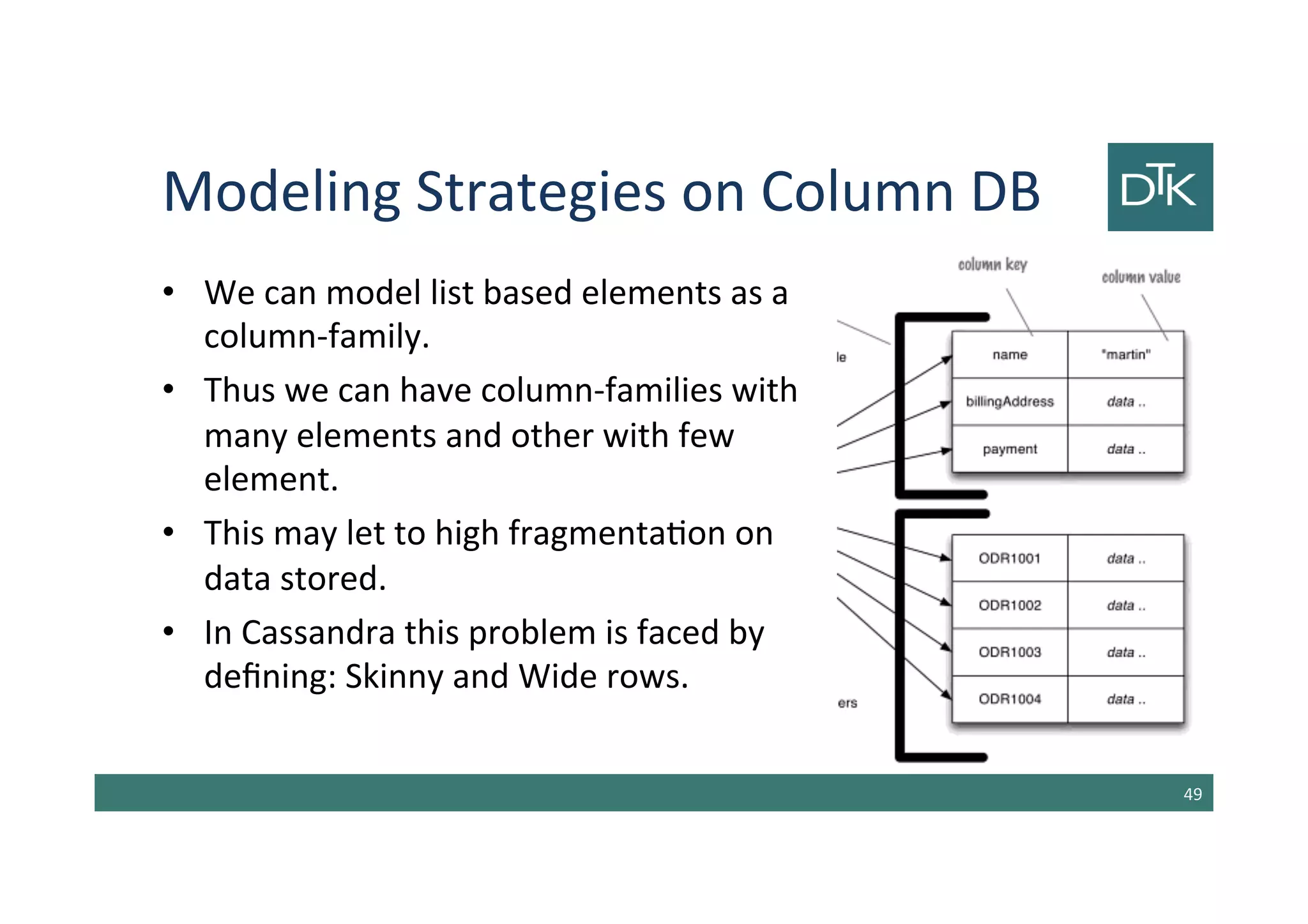
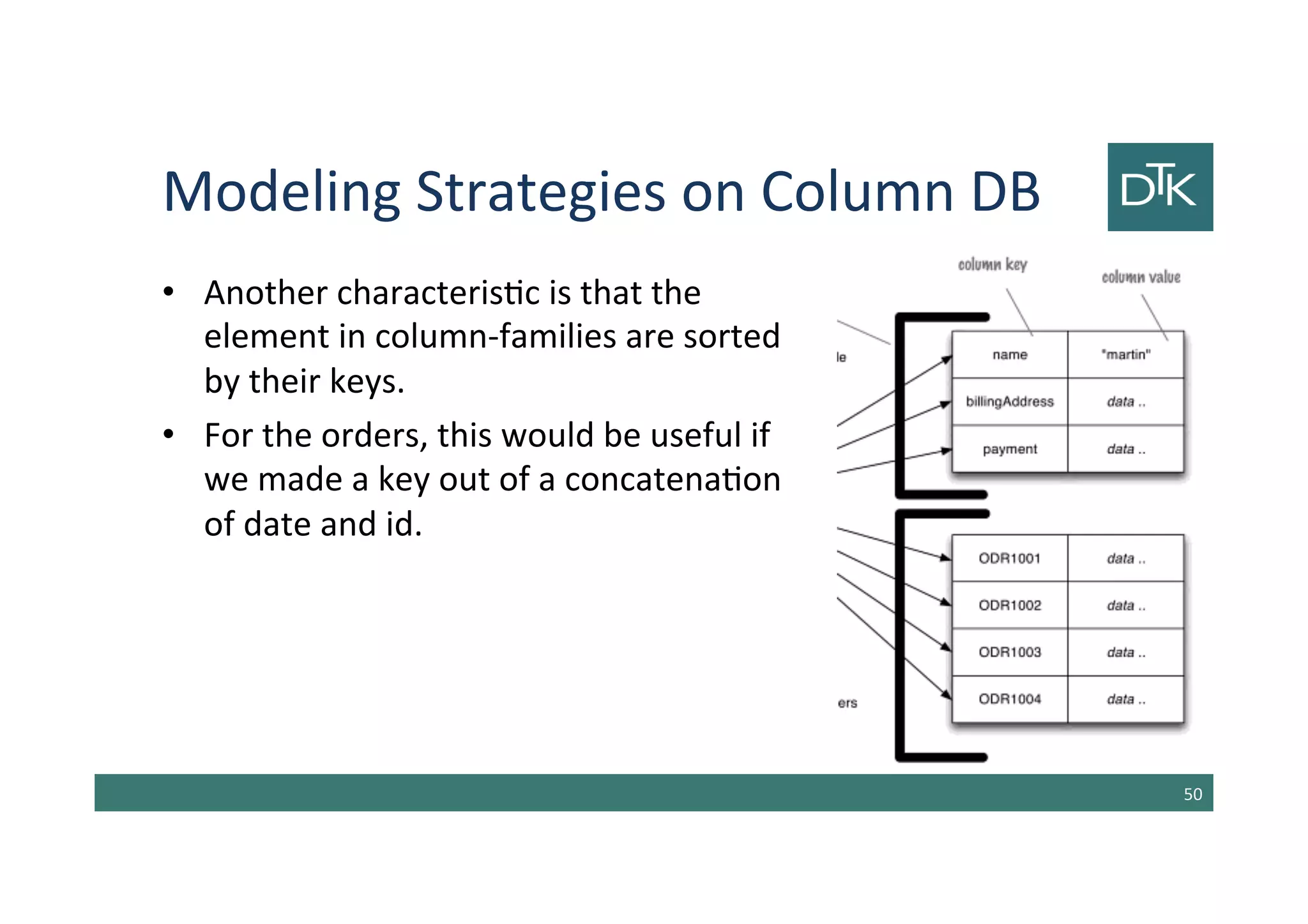
![Column-Family Stores
• One of the most influential NoSQL databases was
Google’s BigTable [Chang et al.]
• Its name derives from its structure composed by
sparse columns and no schema.
• We don’t have to think to this structure as a table,
but to a two-level map.
• BigTable models influenced the design the open
source HBase and Cassandra.
42](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/85/5-Data-Modeling-for-NoSQL-1-2-42-320.jpg)






















![Aggregate Model
• Aggregate is a term coming from Domain-Driven
Design [Evans03]
– An aggregate is a collection of related objects that we wish
to treat as a unit for data manipulation, management a
consistency.
• We like to update aggregates with atomic operation
• We like to communicate with our data storage in
terms of aggregates
13http://pbdmng.datatoknowledge.it/readingMaterial/Evans03.pdf](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/75/5-Data-Modeling-for-NoSQL-1-2-13-2048.jpg)

![Example of Aggregate Model
• The link between customer and the order is a relationship
between aggregates
20
//Customer
{
"id": 1,
"name": "Fabio",
"billingAddress": [
{
"city": "Bari"
}
]
}
//Orders
{
"id": 99,
"customerId": 1,
"orderItems": [
{
"productId": 27,
"price": 34,
"productName": "Scala in Action”
} ],
"shippingAddress": [ {"city": "Bari”} ],
"orderPayment": [
{ "ccinfo": "100-432423-545-134",
"txnId": "afdfsdfsd",
"billingAddress": [ {"city": "Bari” }]
} ]
}](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/75/5-Data-Modeling-for-NoSQL-1-2-20-2048.jpg)
![Orders Details
•There is the customer id
•The product name is a part of the
ordered Items
•The product id is part of the
ordered items
•The address is stored several
times
21
//Orders
{
"id": 99,
"customerId": 1,
"orderItems": [
{
"productId": 27,
"price": 34,
"productName": "Scala in Action”
} ],
"shippingAddress": [ {"city": "Bari”} ],
"orderPayment": [
{ "ccinfo": "100-432423-545-134",
"txnId": "afdfsdfsd",
"billingAddress": [ {"city": "Bari” }]
} ]
}](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/75/5-Data-Modeling-for-NoSQL-1-2-21-2048.jpg)




















![Column-Family Stores
• One of the most influential NoSQL databases was
Google’s BigTable [Chang et al.]
• Its name derives from its structure composed by
sparse columns and no schema.
• We don’t have to think to this structure as a table,
but to a two-level map.
• BigTable models influenced the design the open
source HBase and Cassandra.
42](https://image.slidesharecdn.com/5-150325142411-conversion-gate01/75/5-Data-Modeling-for-NoSQL-1-2-42-2048.jpg)










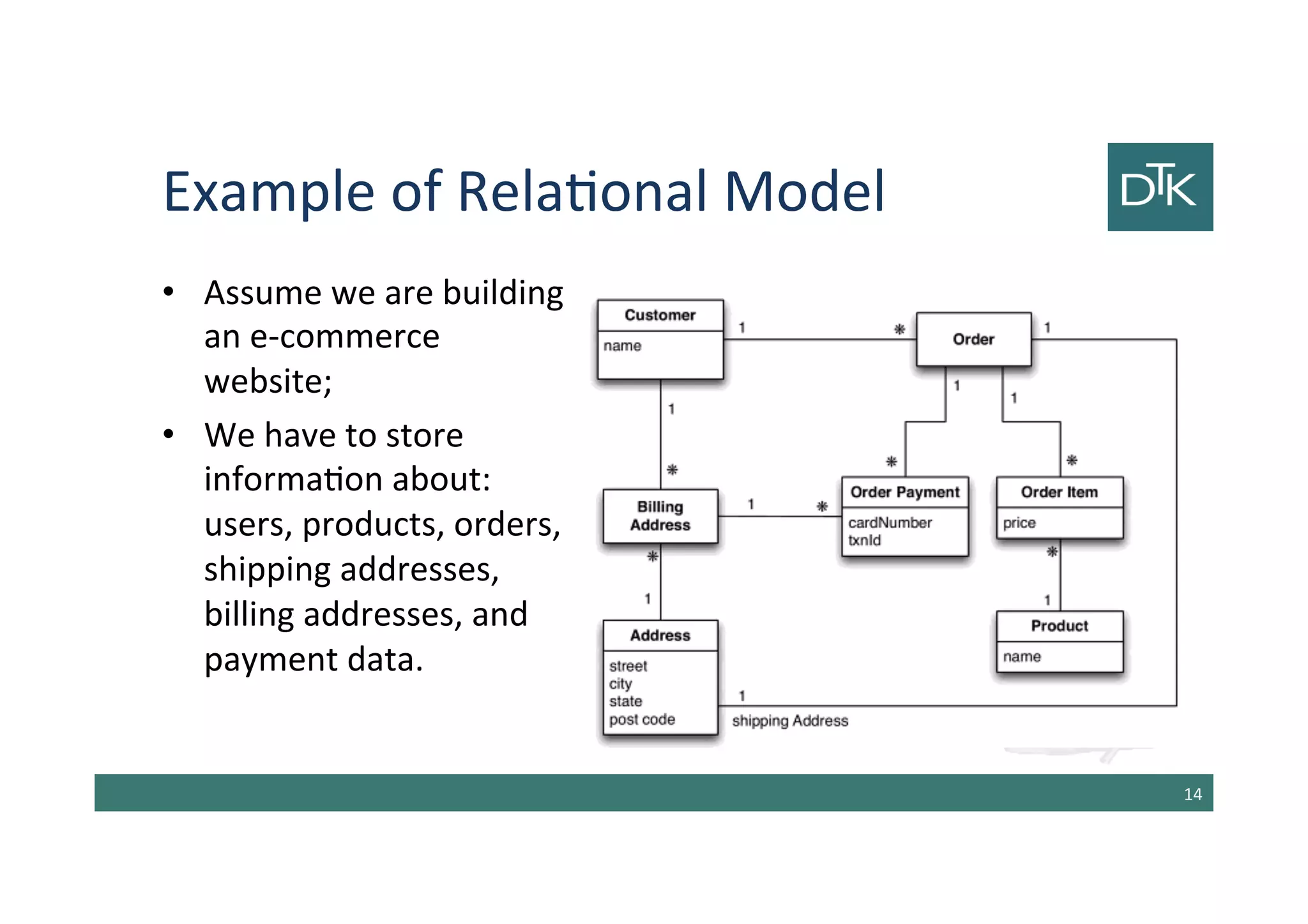
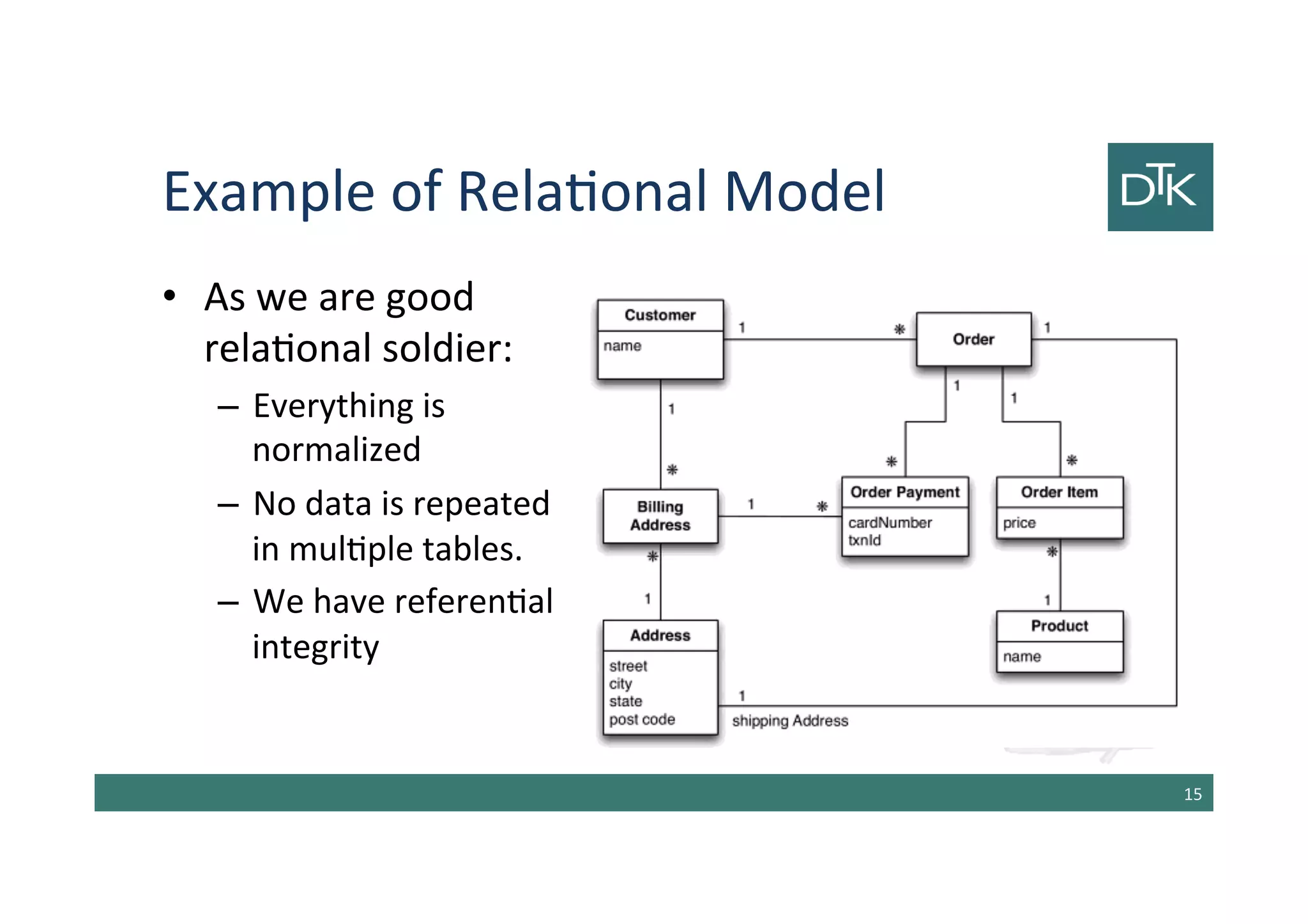
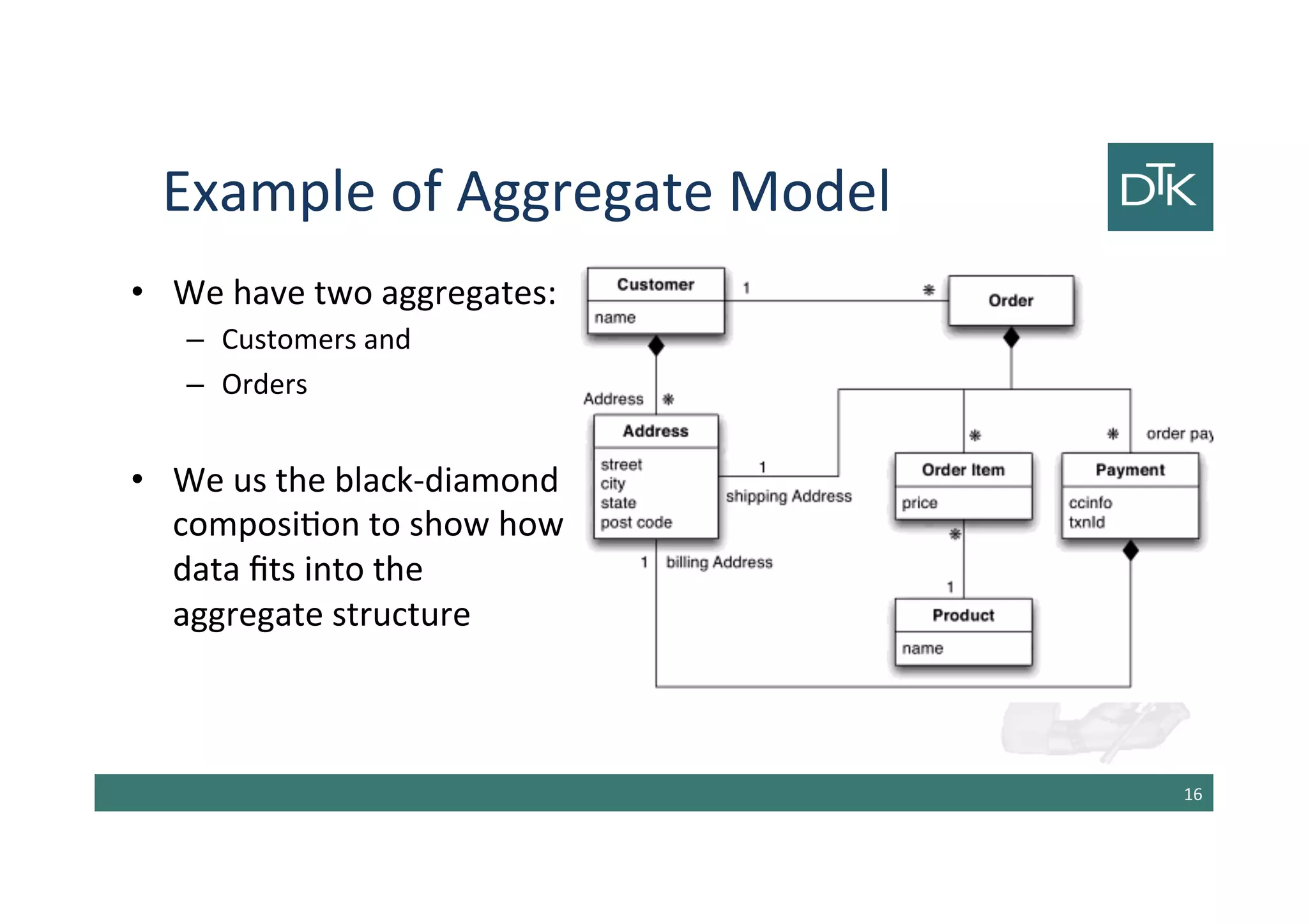
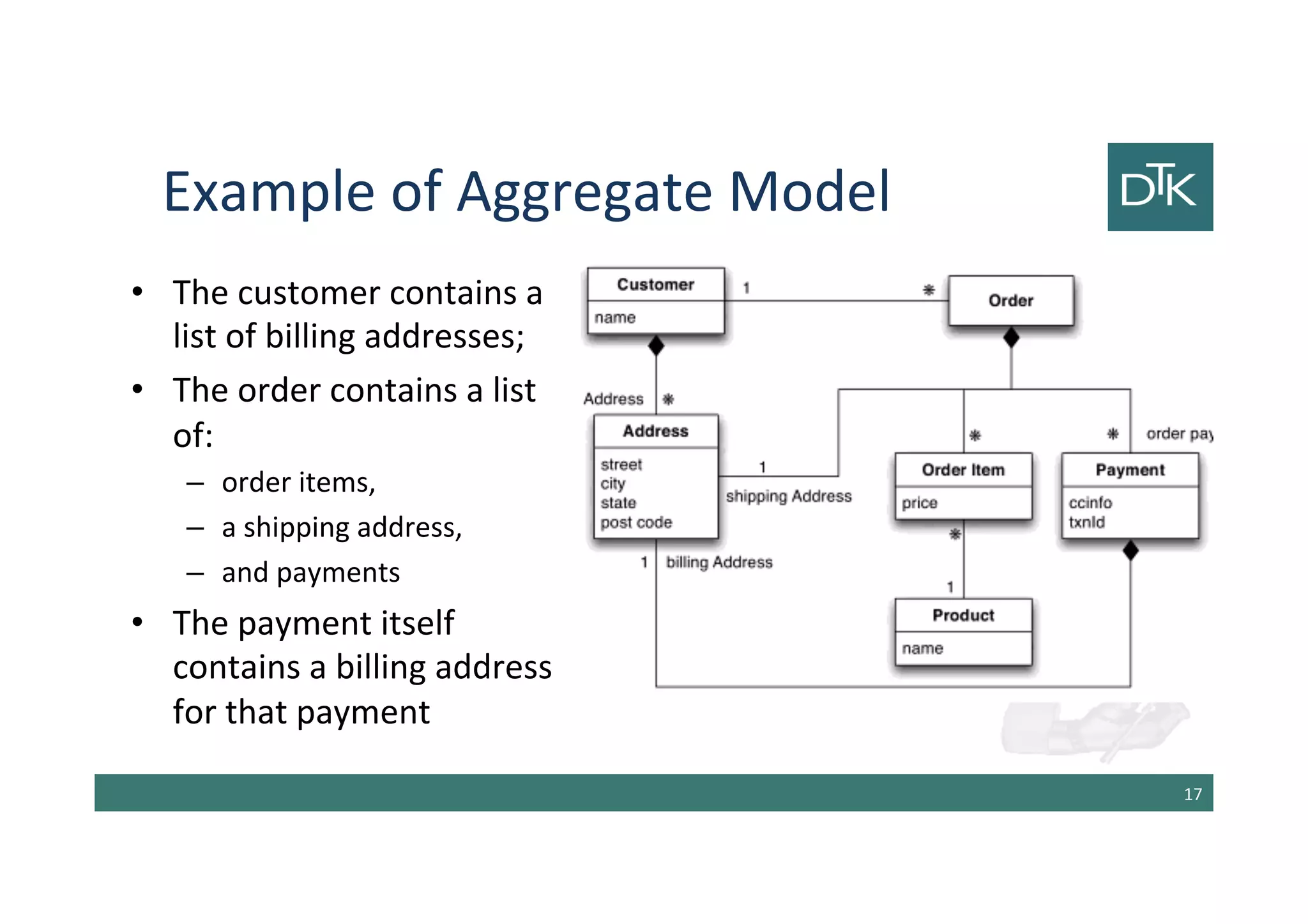
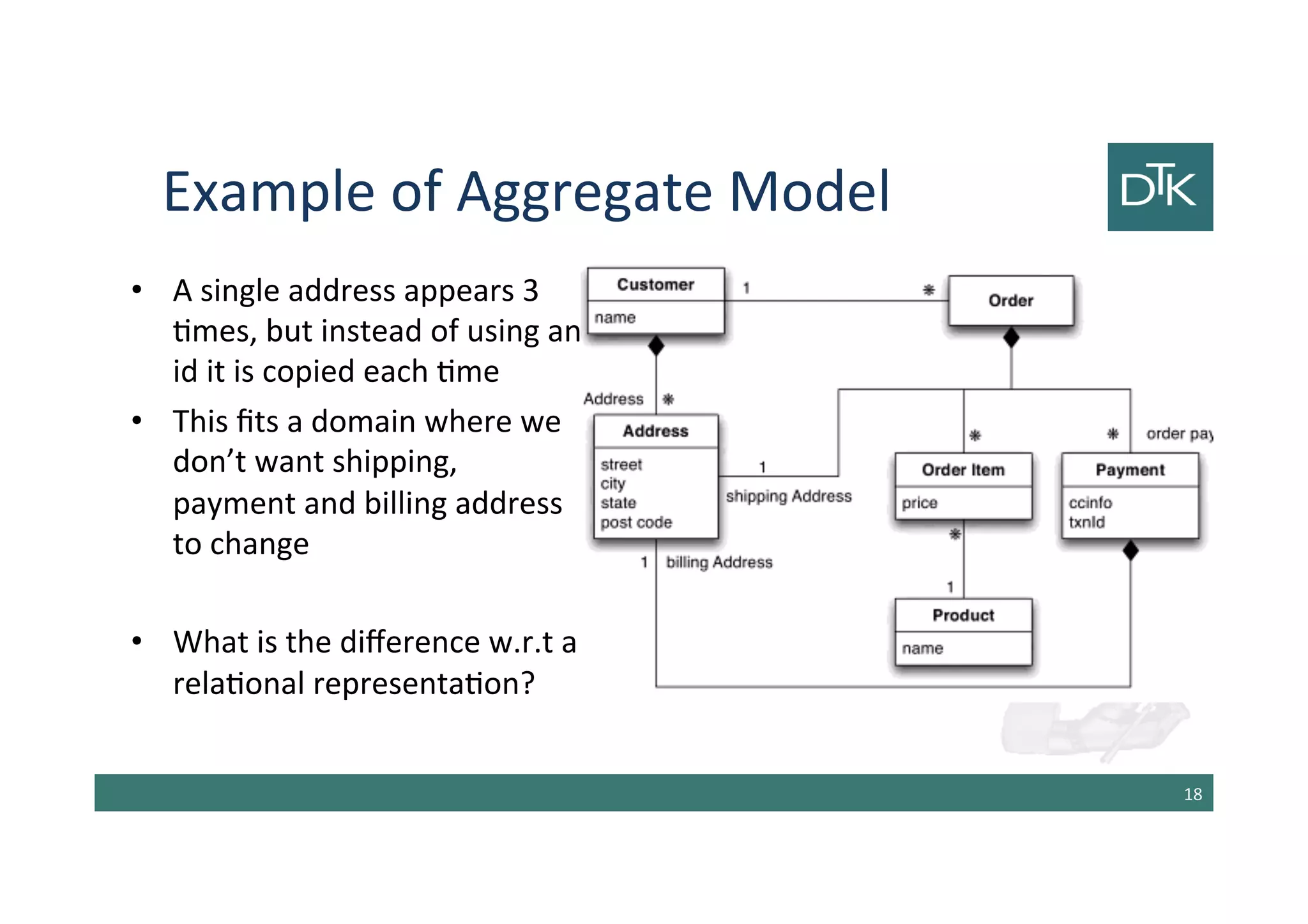
The document discusses the evolution and comparison between relational and aggregate data models, particularly in the context of NoSQL databases. It explains how aggregate models, which allow for more complex data structures and relationships, can enhance performance in certain scenarios, while also touching on the limitations of relational databases in handling aggregation. Additionally, various NoSQL database types such as key-value, document, and column-family stores are examined, highlighting their unique characteristics and use cases.








































































![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




