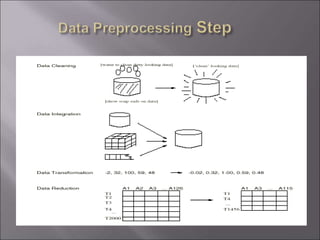
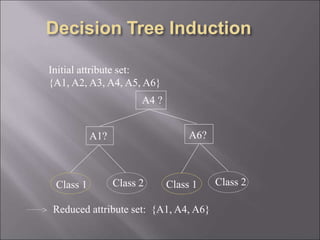
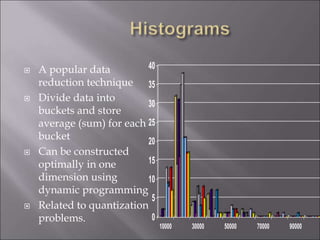
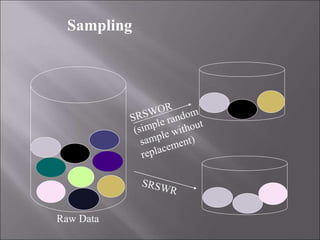
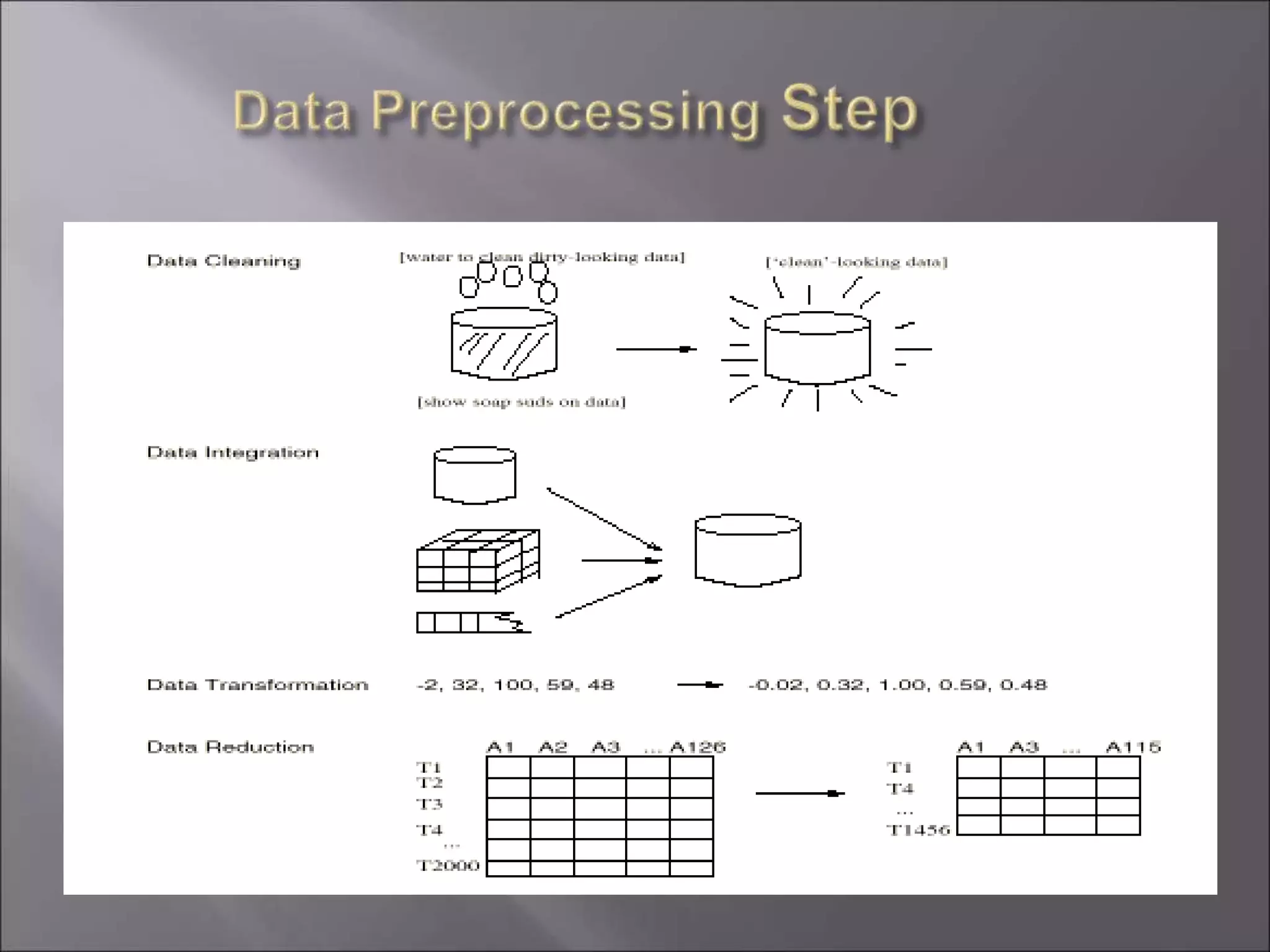
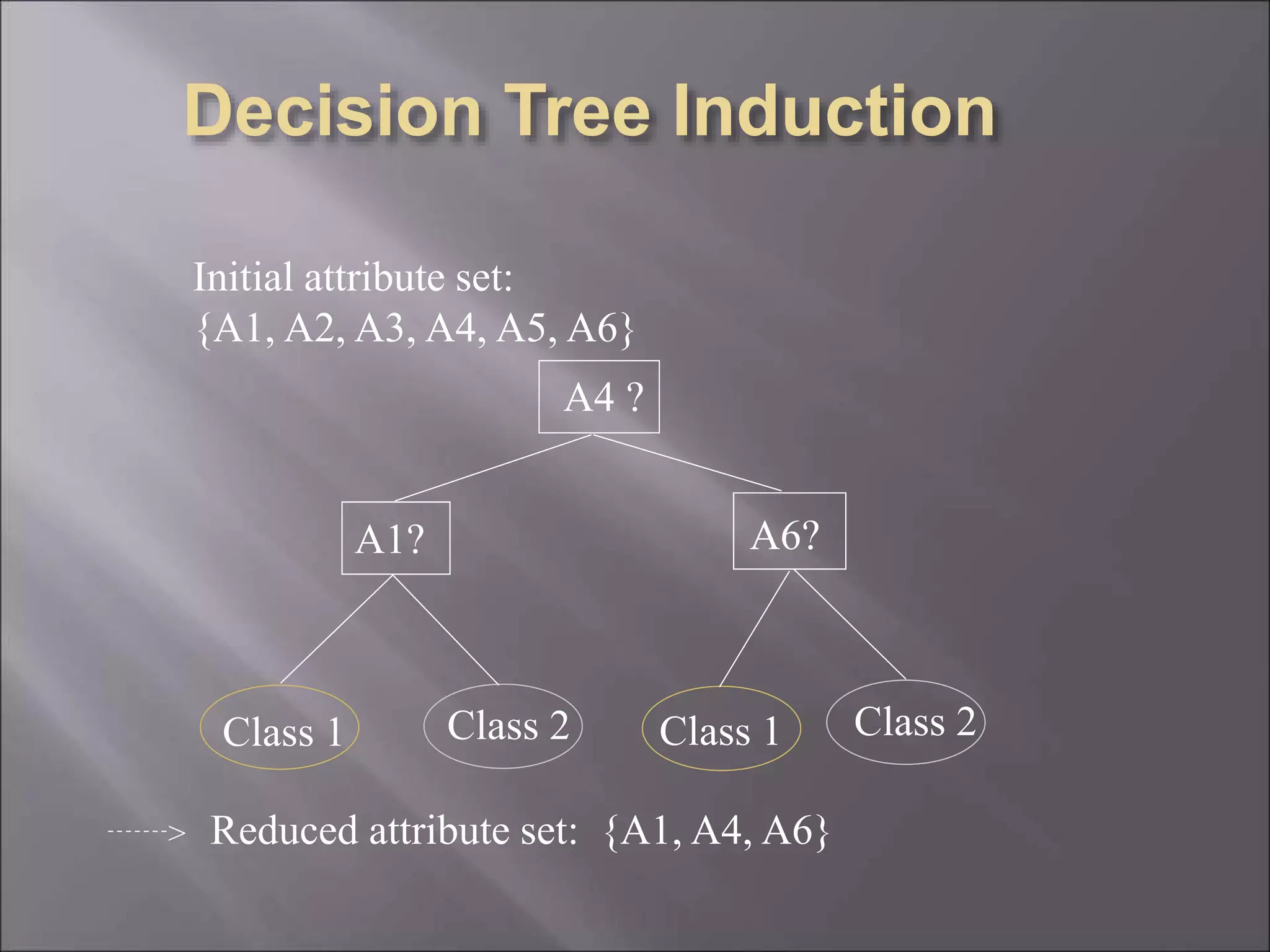
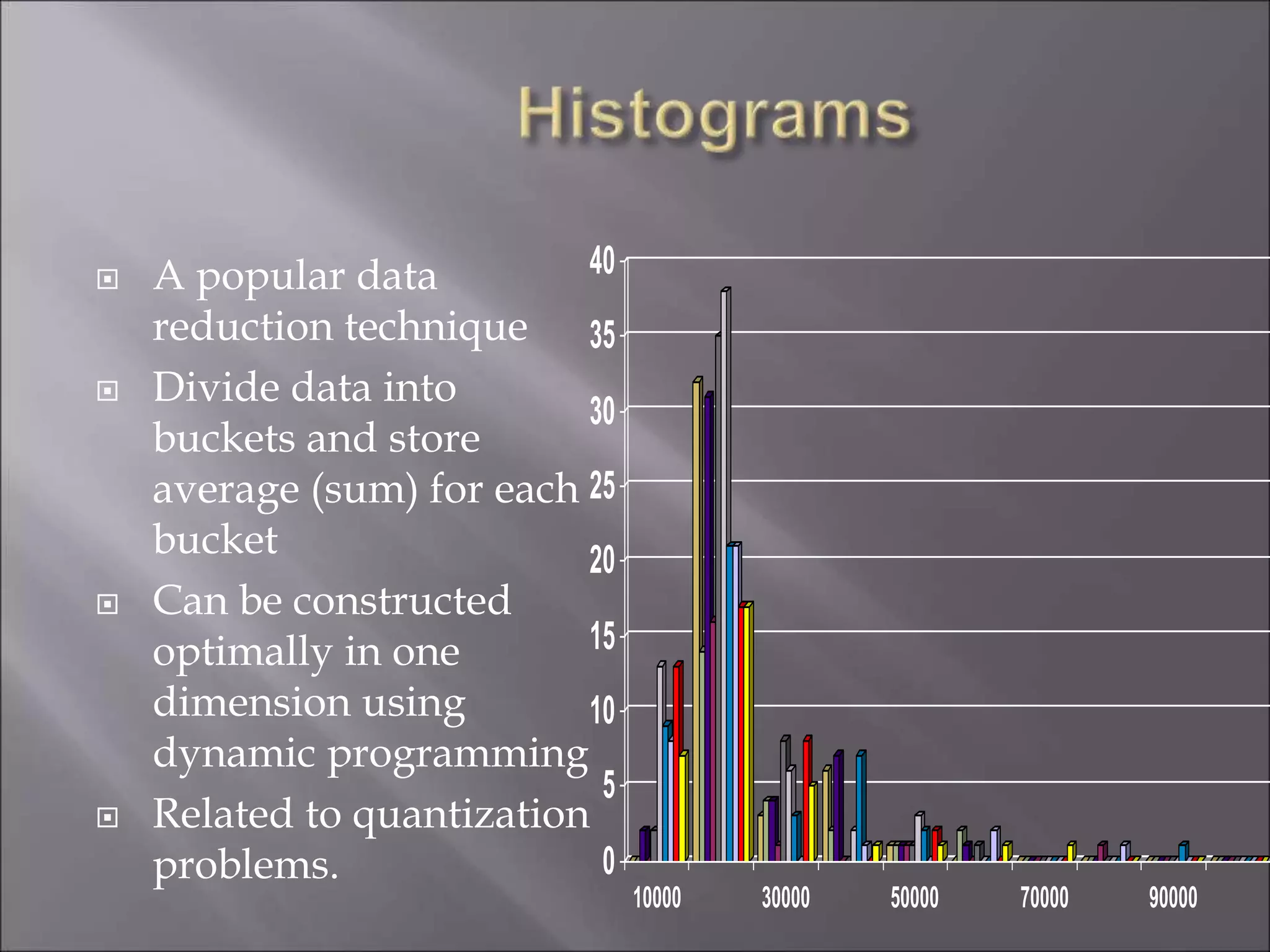
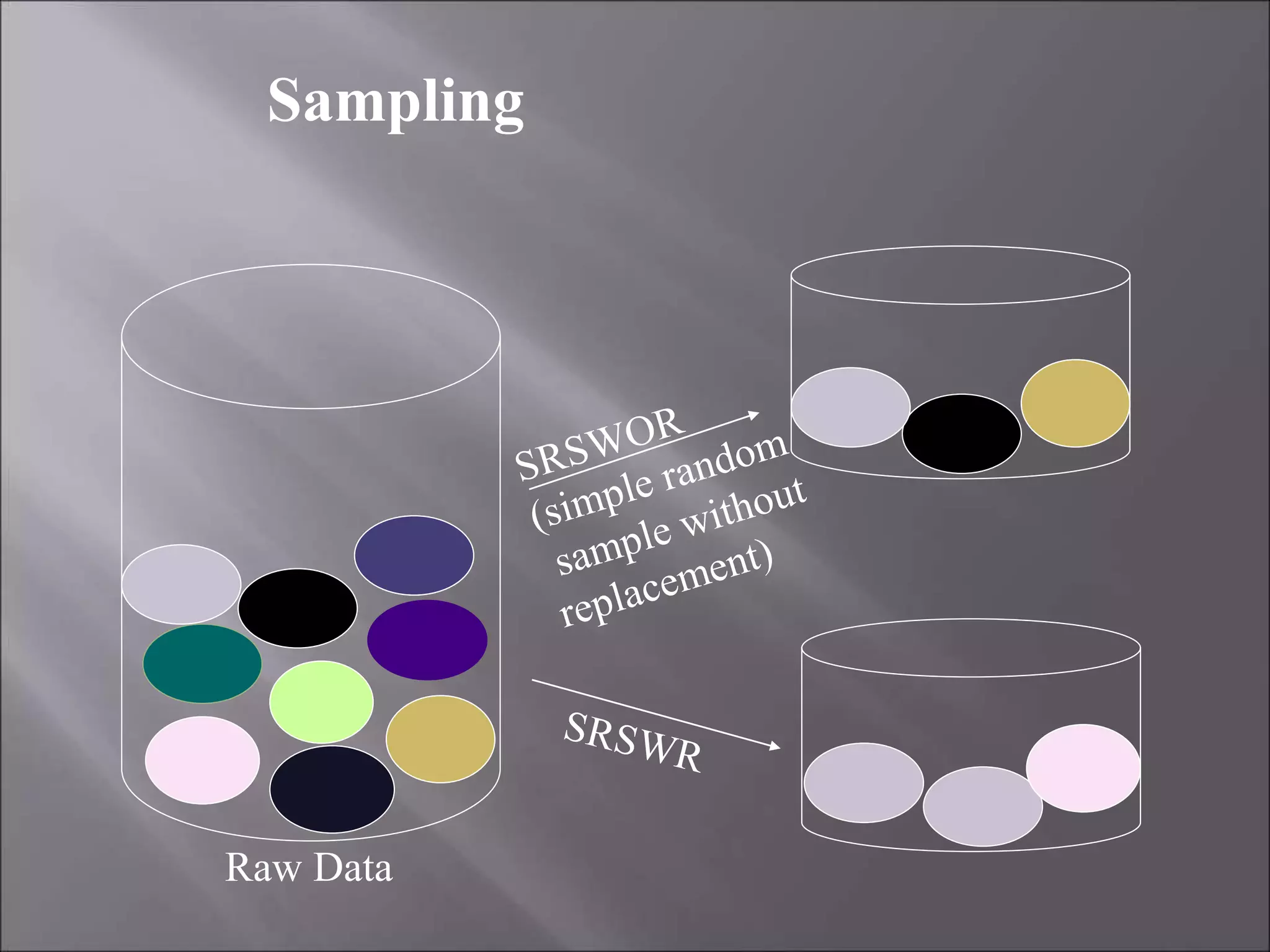
Data is often incomplete, noisy, and inconsistent which can negatively impact mining results. Effective data cleaning is needed to fill in missing values, identify and remove outliers, and resolve inconsistencies. Other important tasks include data integration, transformation, reduction, and discretization to prepare the data for mining and obtain reduced representation that produces similar analytical results. Proper data preparation is essential for high quality knowledge discovery.