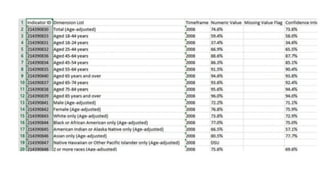
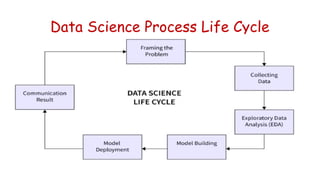
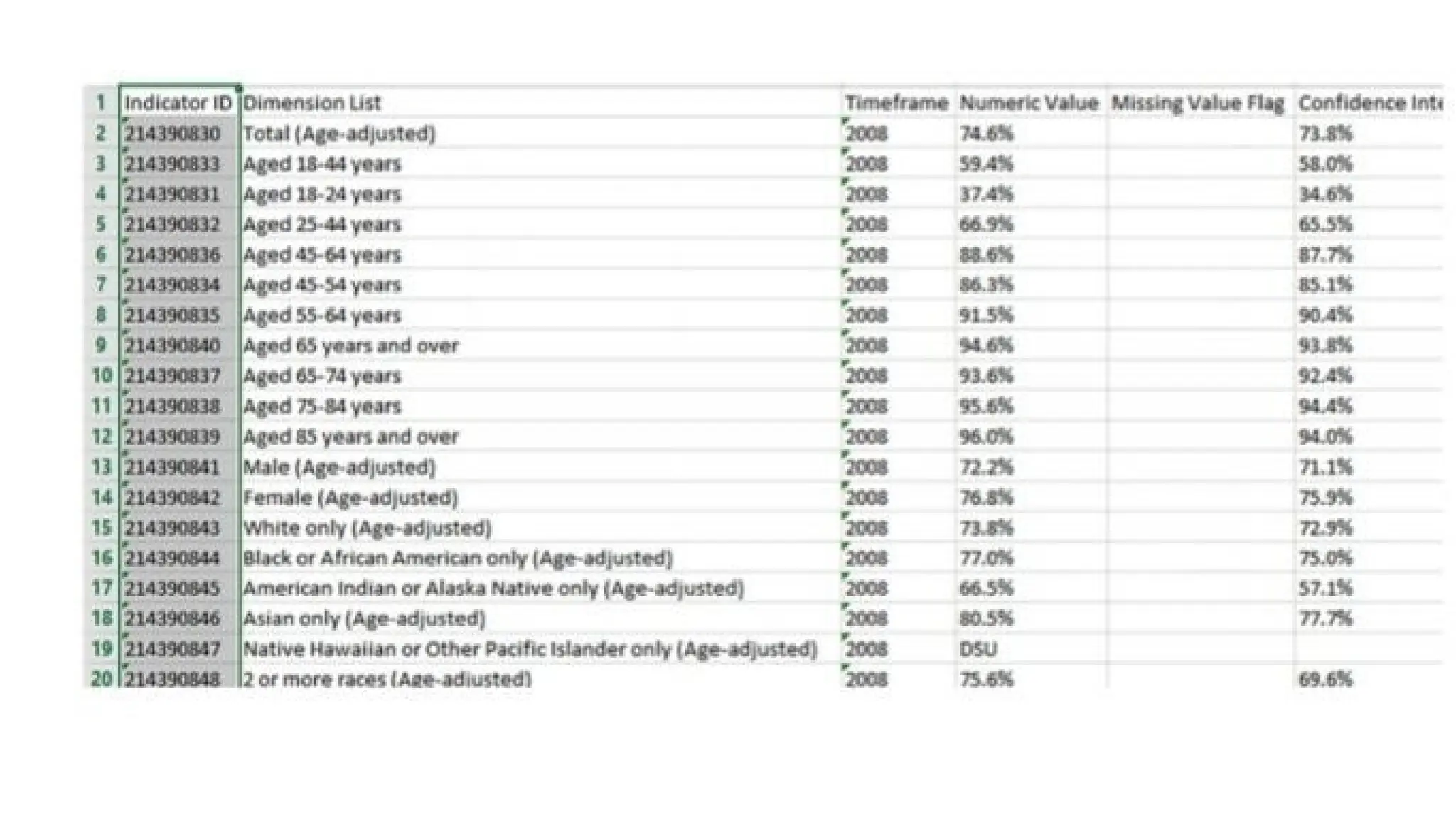
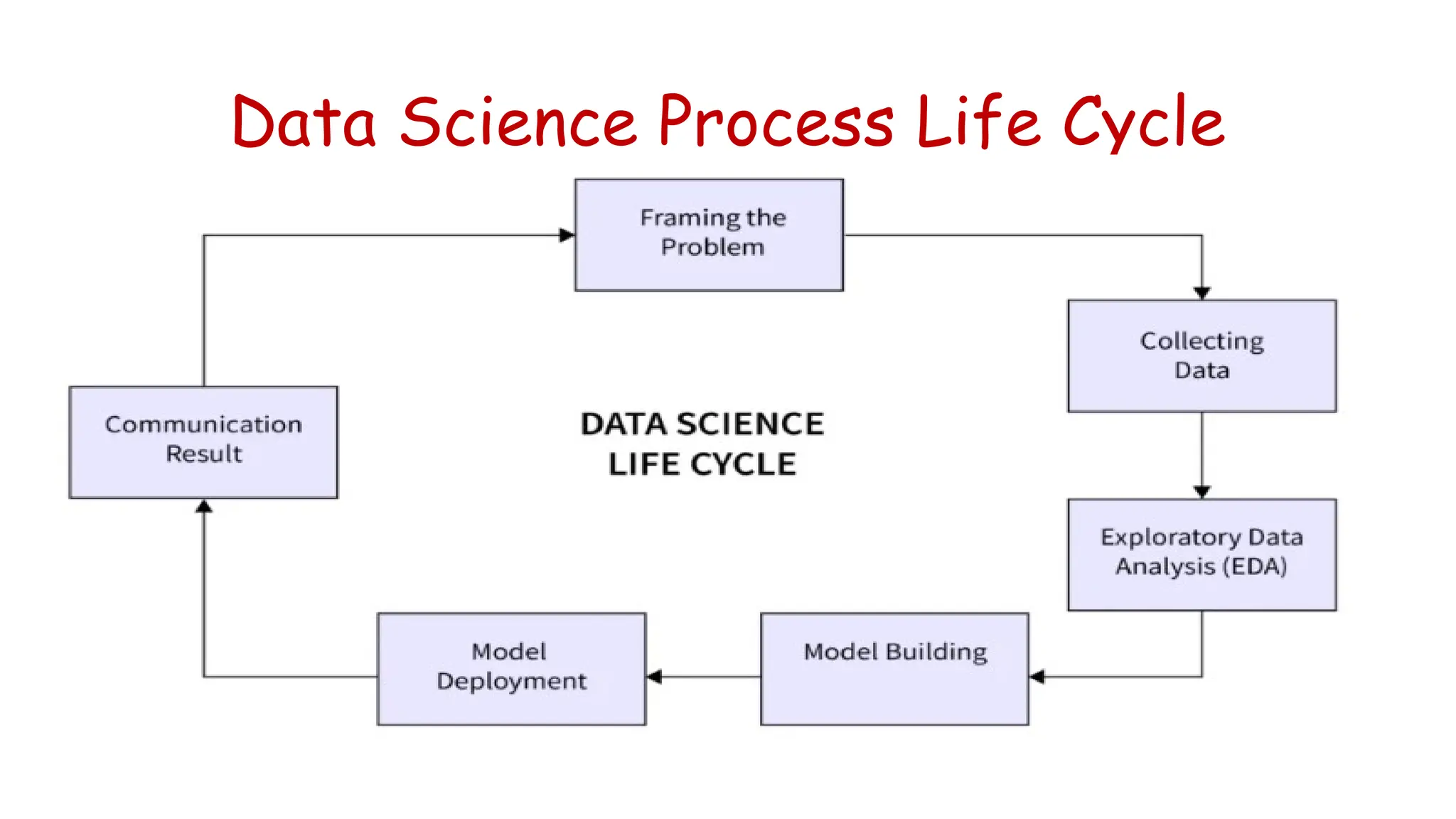
The document provides an introduction to data science, defining it as a multidisciplinary field involving statistics, data analysis, and machine learning to extract insights from data. It outlines the data science process, which includes problem framing, data collection, cleaning, exploratory analysis, model building, deployment, and communicating results, as well as the types of data (structured, unstructured, and natural language). Additionally, it briefly touches upon applications of data science across various industries and introduces NumPy, a fundamental Python library for numerical operations on arrays.