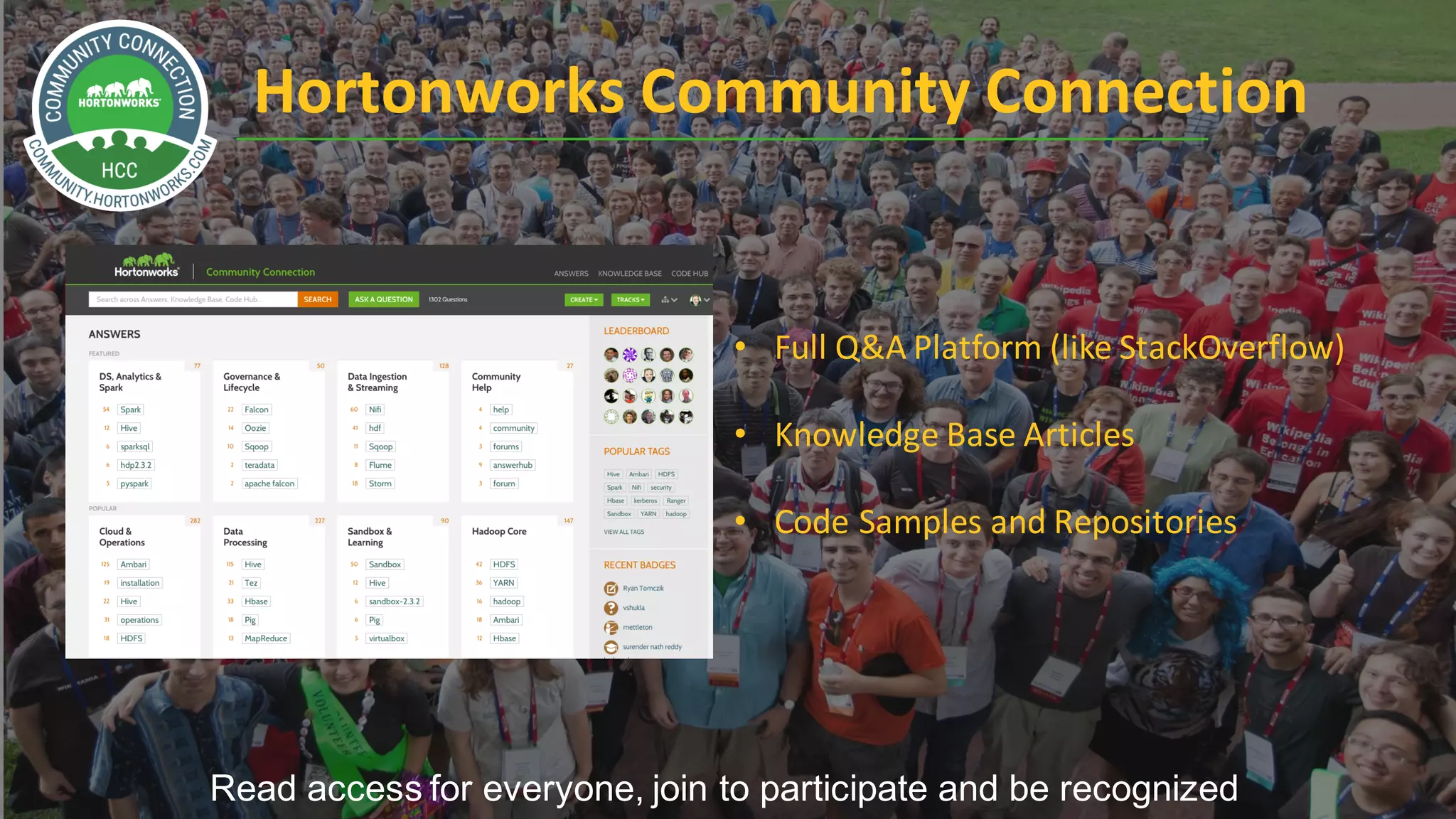
Downloaded 221 times






















![44 © Hortonworks Inc. 2011 –2016. All Rights Reserved
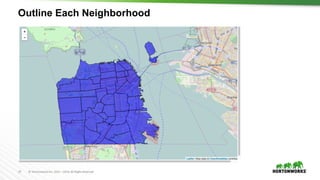
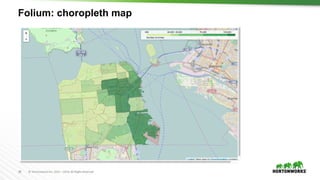
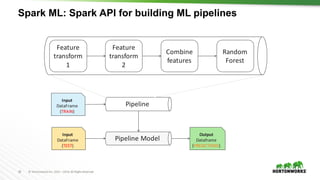
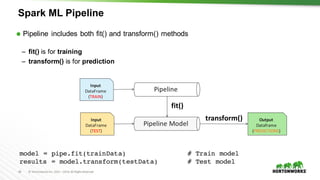
Spark ML – Simple Random Forest Example
indexer = StringIndexer(inputCol=”district", outputCol=”dis-inx")
parser = Tokenizer(inputCol=”text-field", outputCol="words")
hashingTF = HashingTF(numFeatures=50, inputCol="words", outputCol="hash-inx")
vecAssembler = VectorAssembler(
inputCols =[“dis-inx”, “hash-inx”],
outputCol="features")
rf = RandomForestClassifier(numTrees=100, labelCol="label", seed=42)
pipe = Pipeline(stages=[indexer, parser, hashingTF, vecAssembler, rf])
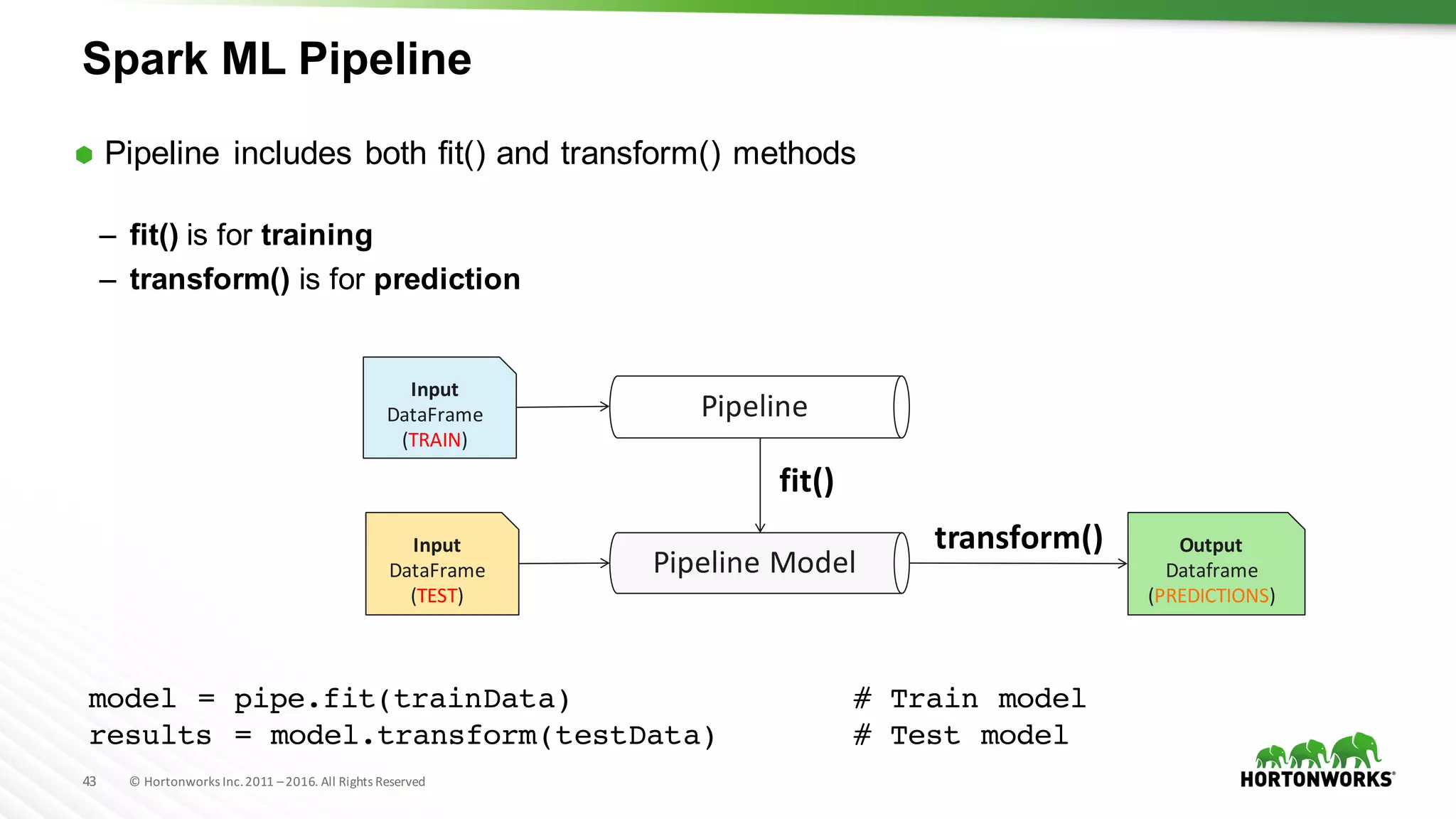
model = pipe.fit(trainData) # Train model
results = model.transform(testData) # Test model](https://image.slidesharecdn.com/datasciencecrashcoursehadoopsummitsj-160721165729/85/Data-Science-with-Apache-Spark-Crash-Course-HS16SJ-44-320.jpg)





























![44 © Hortonworks Inc. 2011 –2016. All Rights Reserved
Spark ML – Simple Random Forest Example
indexer = StringIndexer(inputCol=”district", outputCol=”dis-inx")
parser = Tokenizer(inputCol=”text-field", outputCol="words")
hashingTF = HashingTF(numFeatures=50, inputCol="words", outputCol="hash-inx")
vecAssembler = VectorAssembler(
inputCols =[“dis-inx”, “hash-inx”],
outputCol="features")
rf = RandomForestClassifier(numTrees=100, labelCol="label", seed=42)
pipe = Pipeline(stages=[indexer, parser, hashingTF, vecAssembler, rf])
model = pipe.fit(trainData) # Train model
results = model.transform(testData) # Test model](https://image.slidesharecdn.com/datasciencecrashcoursehadoopsummitsj-160721165729/75/Data-Science-with-Apache-Spark-Crash-Course-HS16SJ-44-2048.jpg)







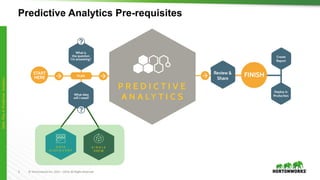
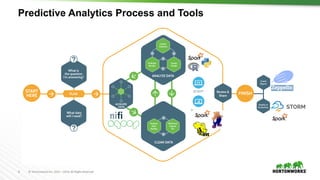
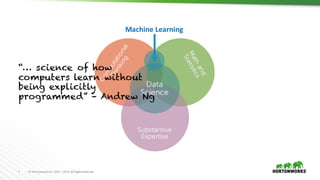
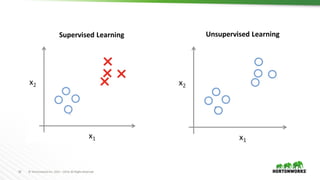
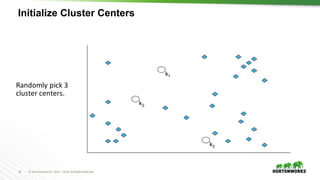
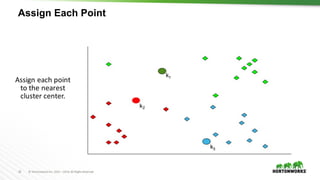
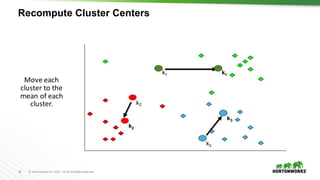
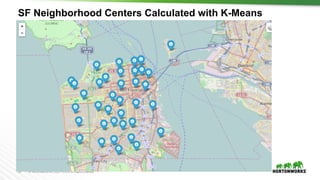
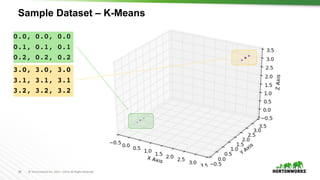
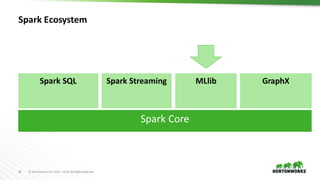
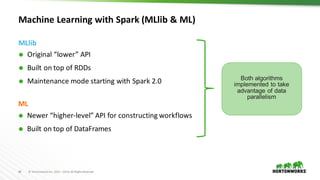
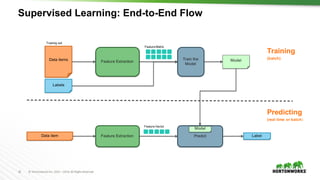
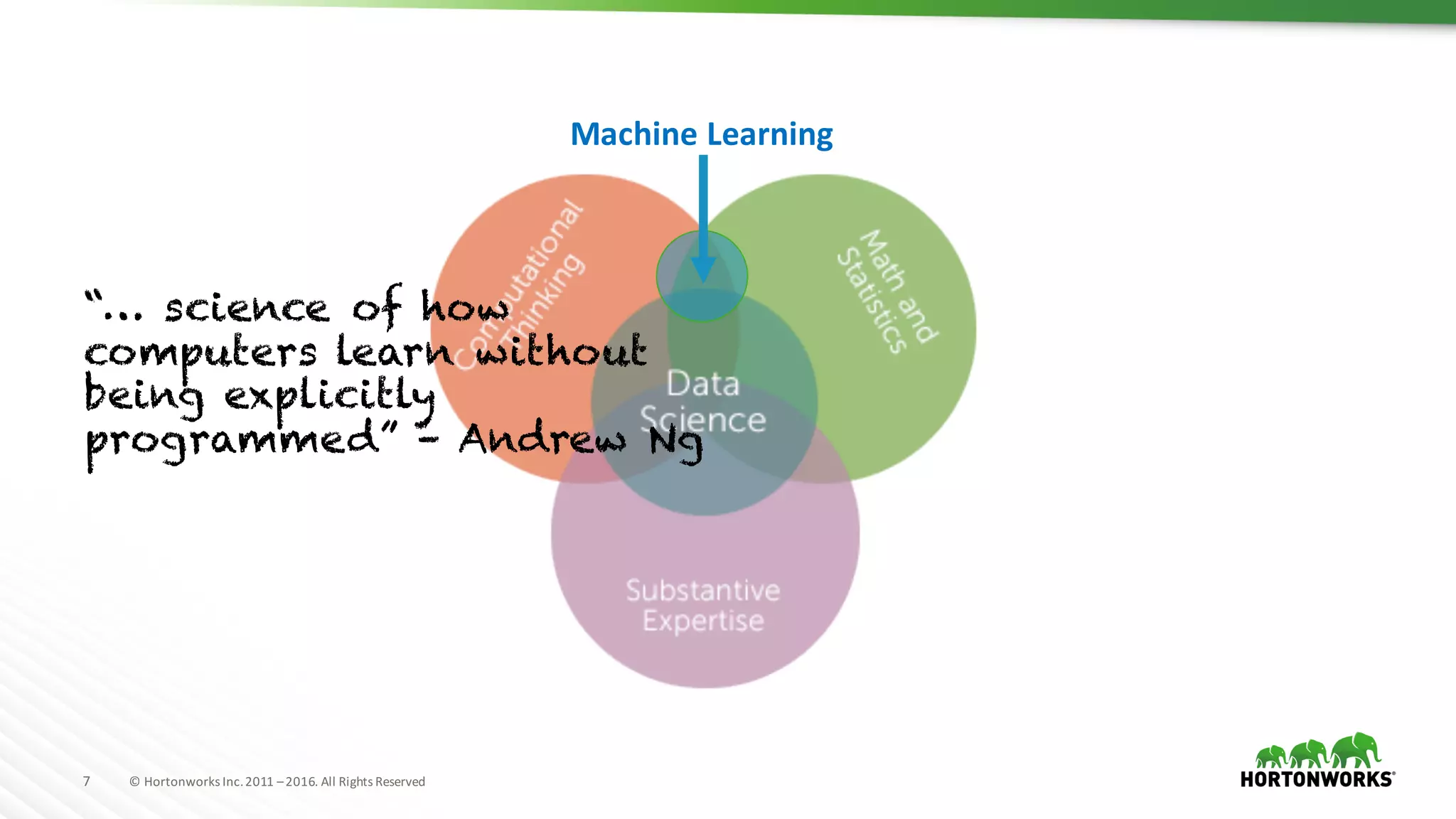
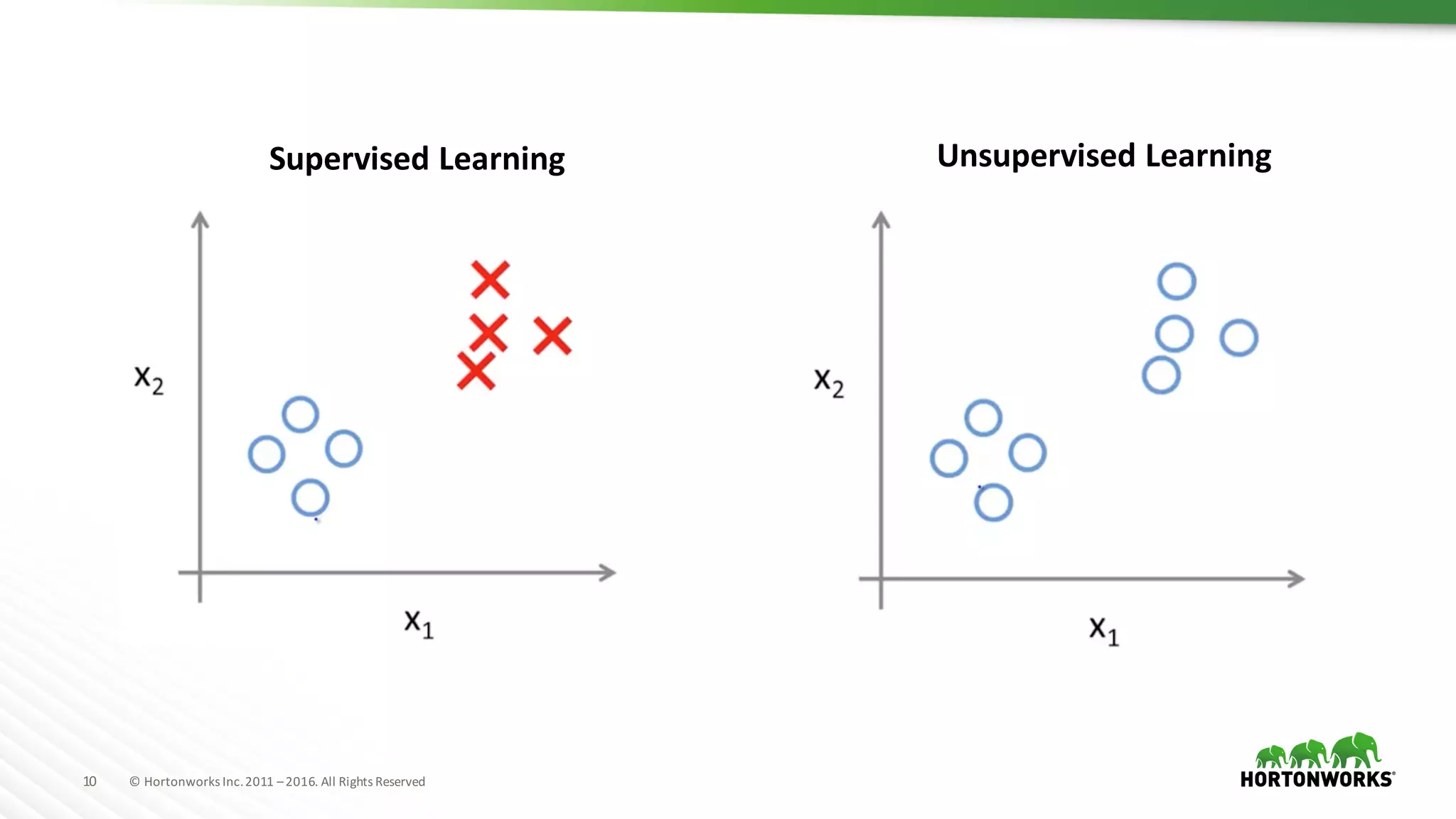
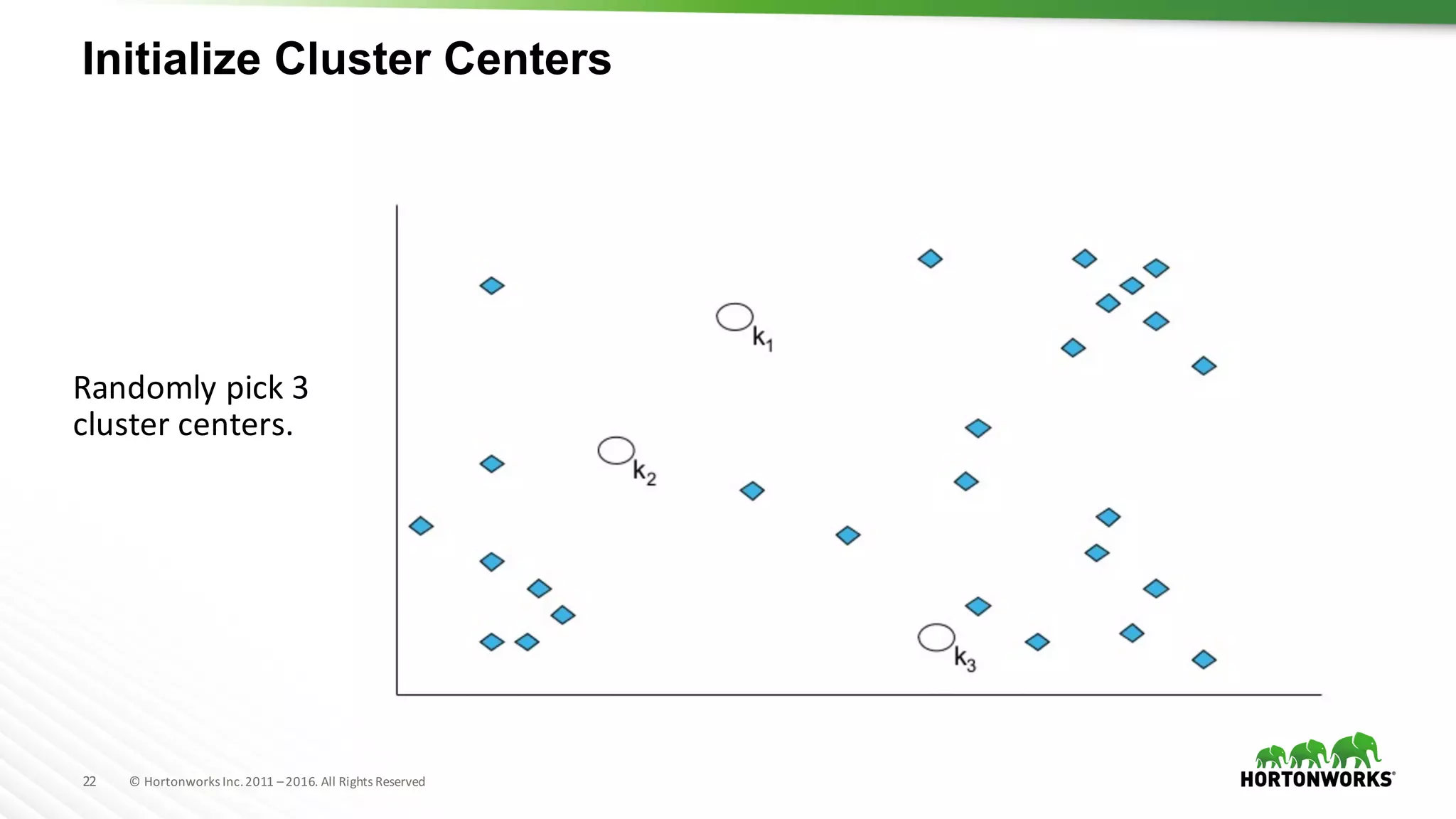
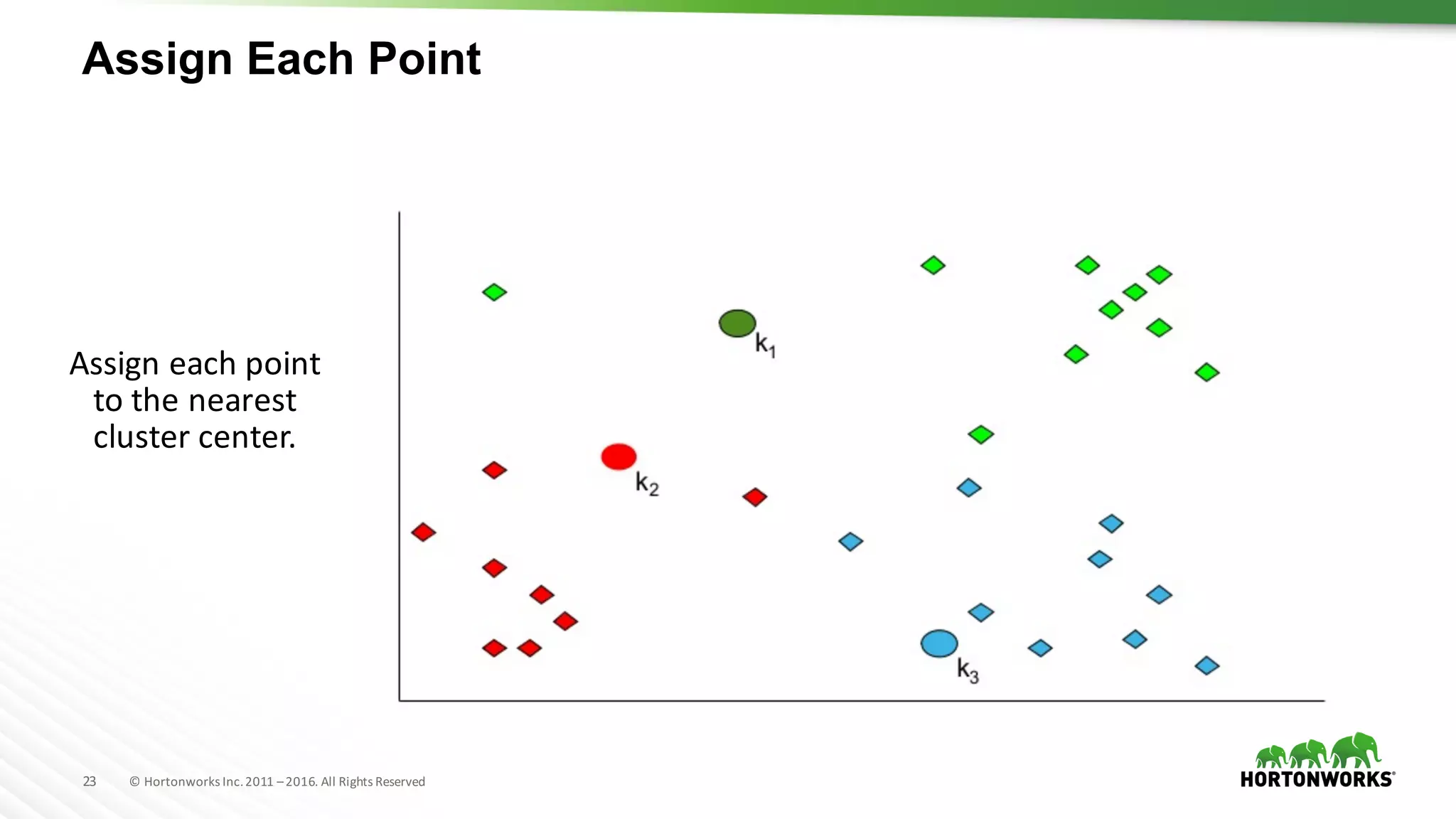
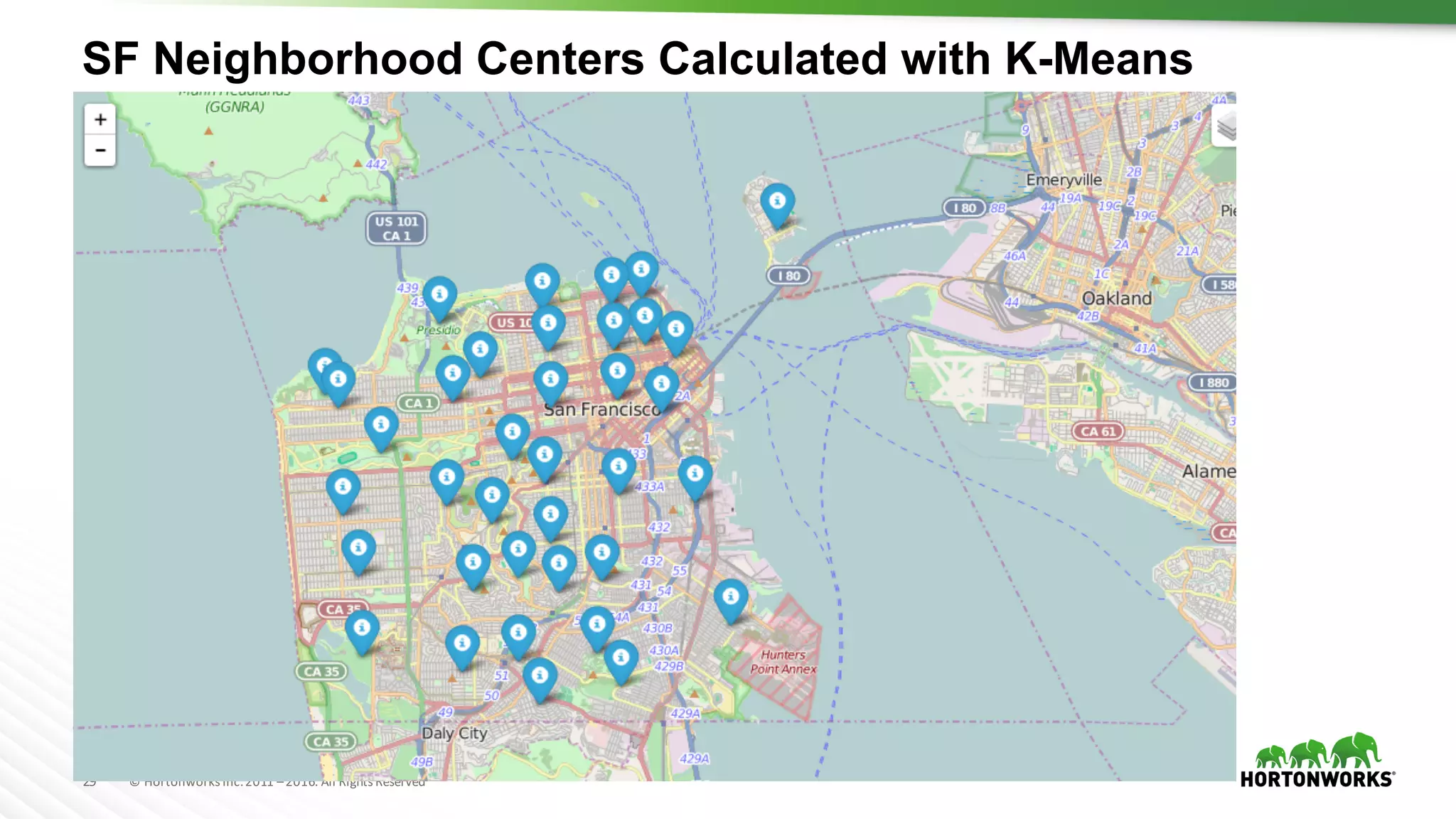
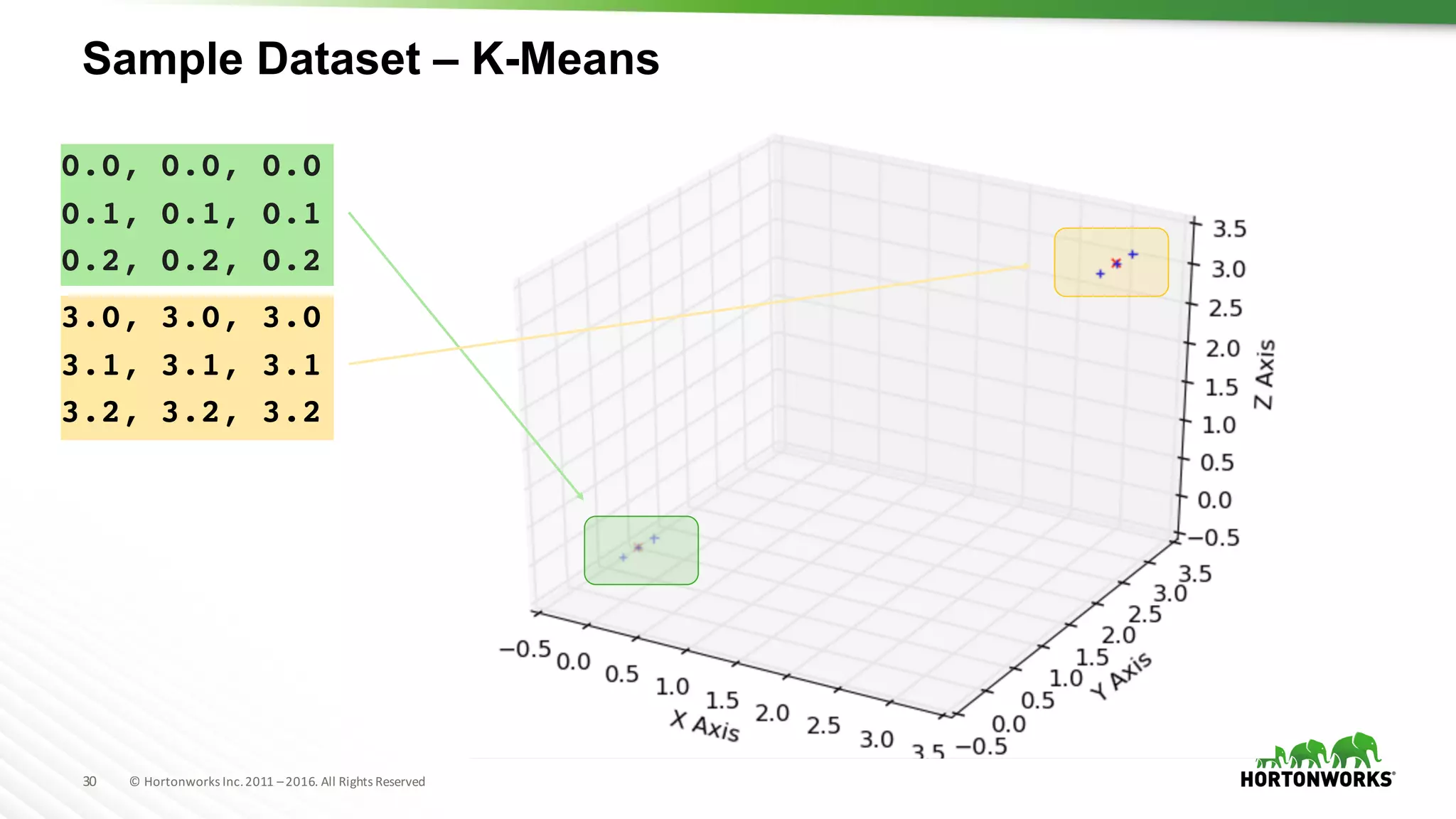
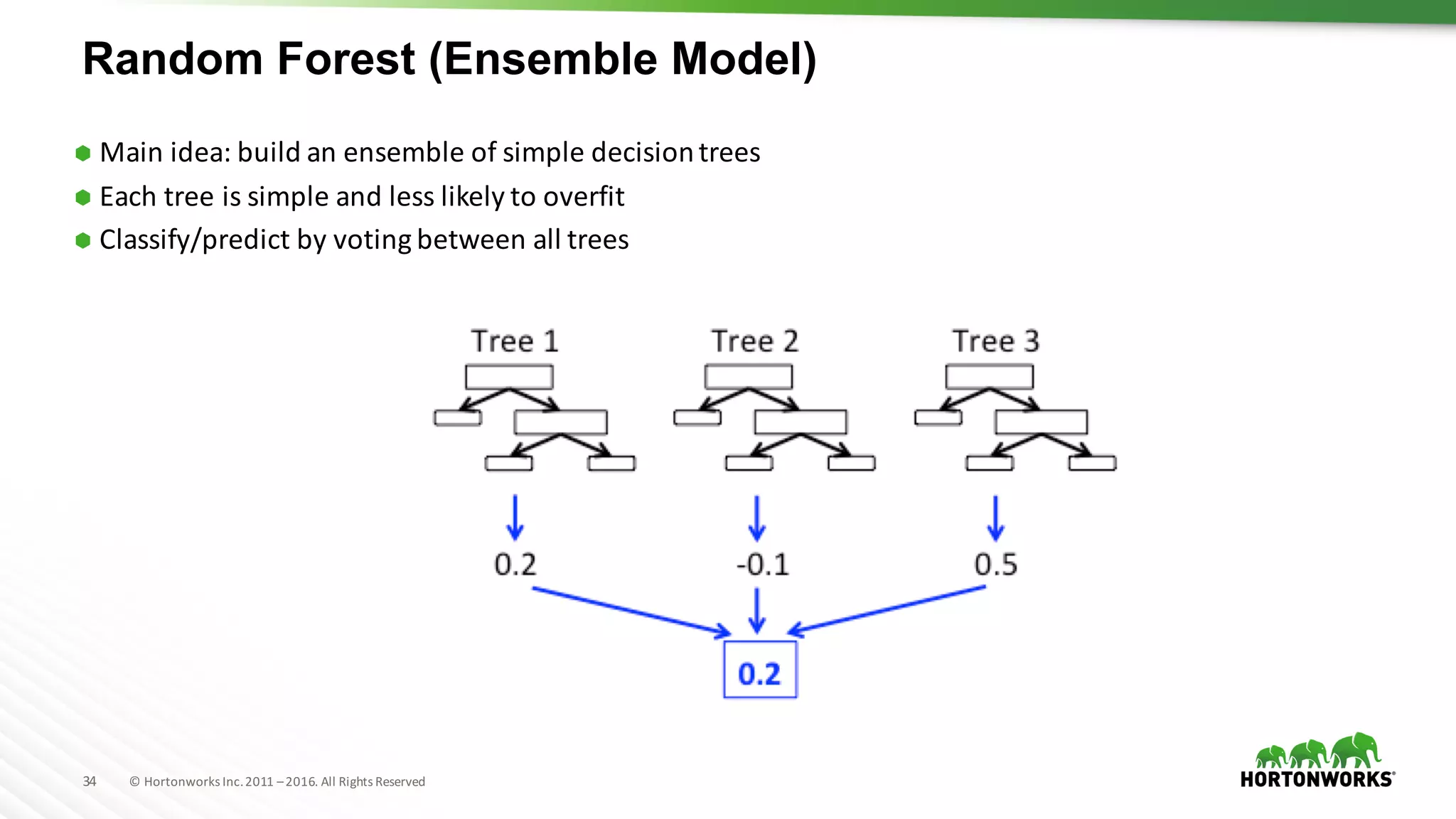
The document provides an overview of machine learning concepts and techniques using Apache Spark. It discusses supervised and unsupervised learning methods like classification, regression, clustering and collaborative filtering. Specific algorithms like k-means clustering, decision trees and random forests are explained. It also introduces Apache Spark MLlib and how to build machine learning pipelines and models with Spark ML APIs.










































































































