Download to read offline



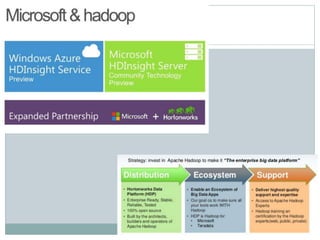
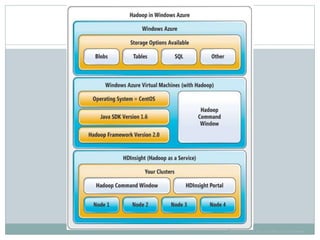

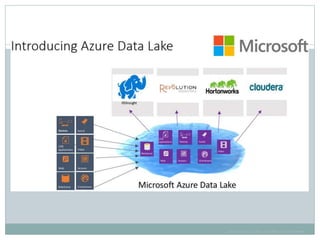

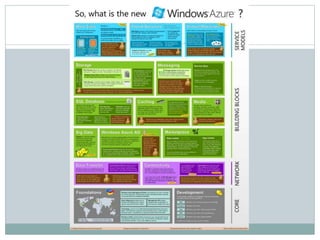
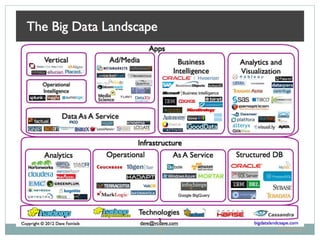


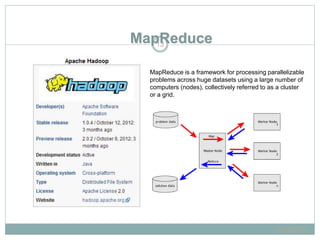


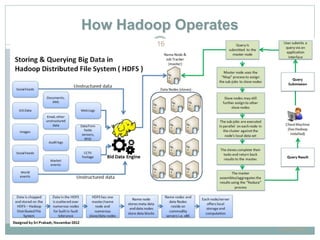













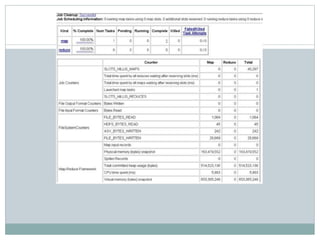
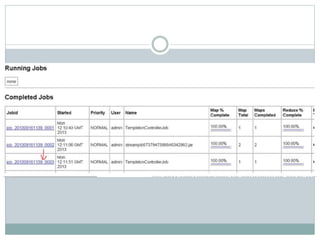
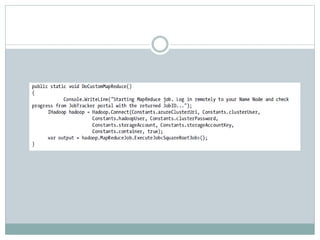
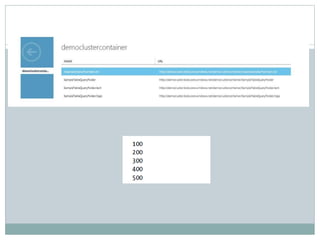

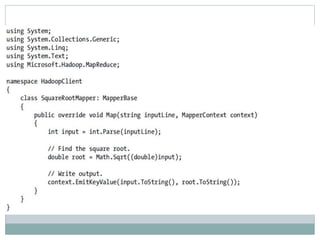
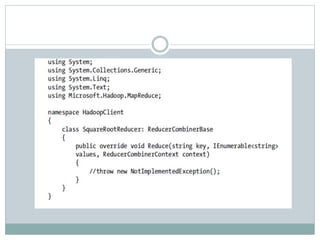






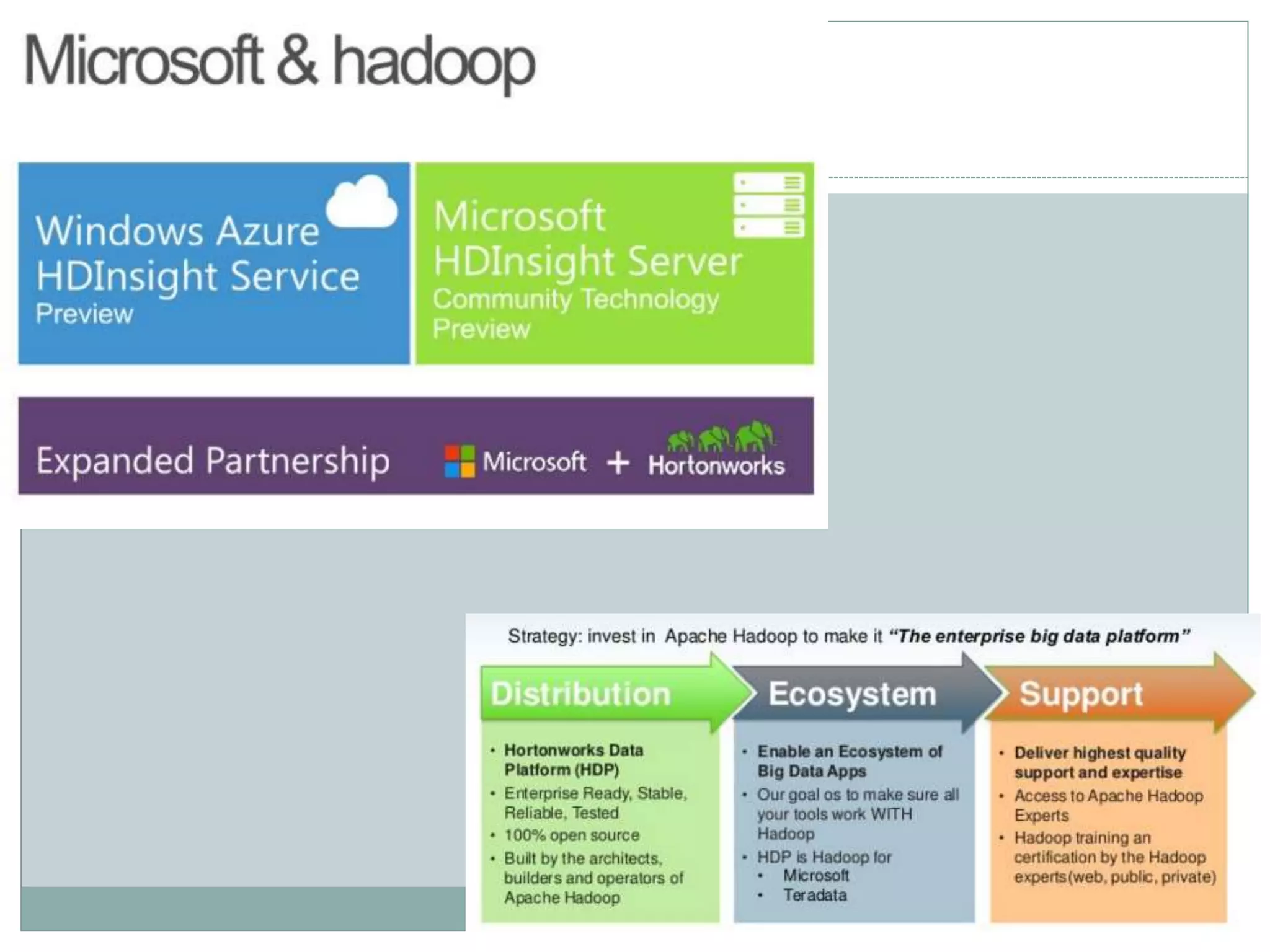
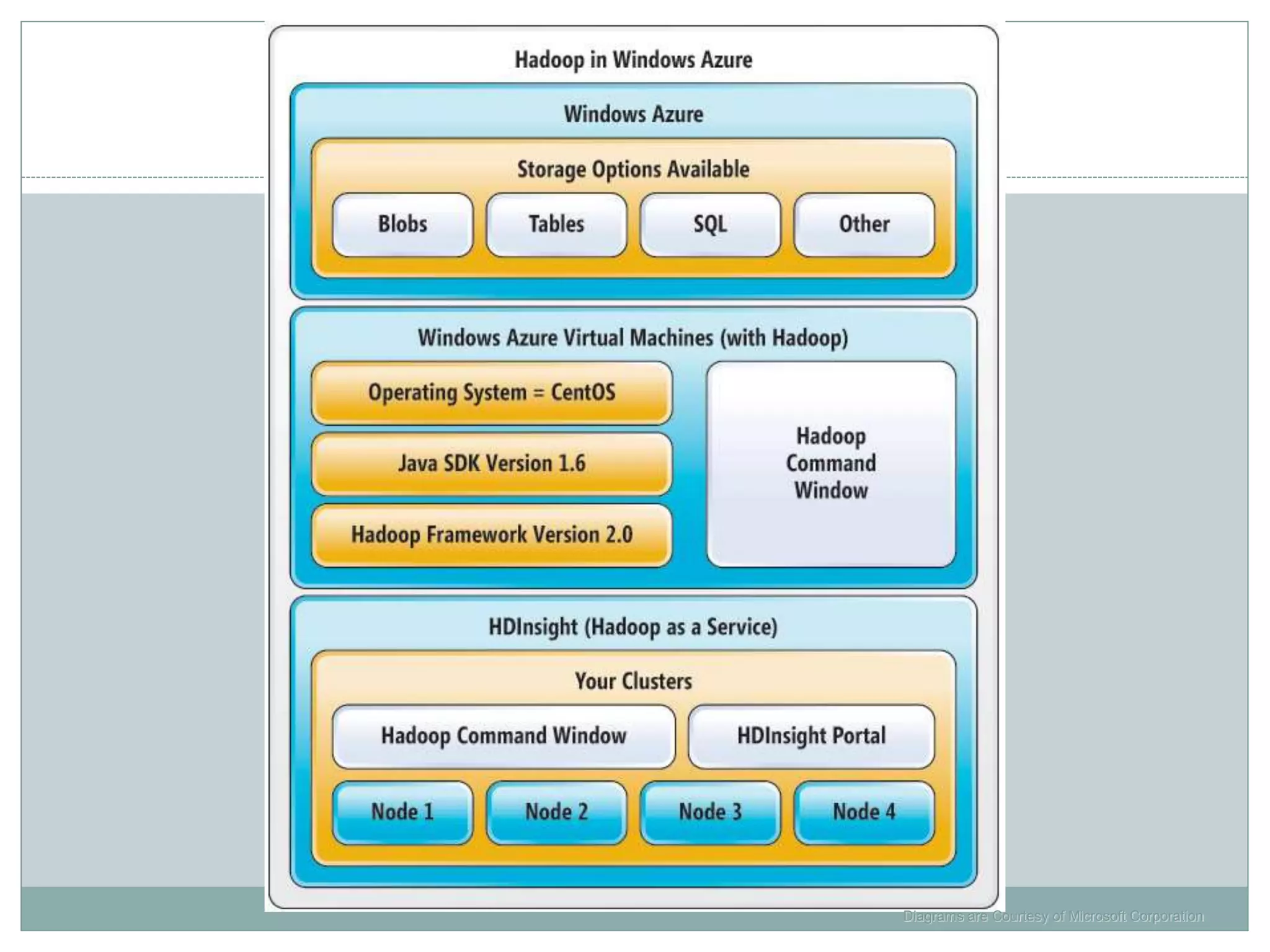

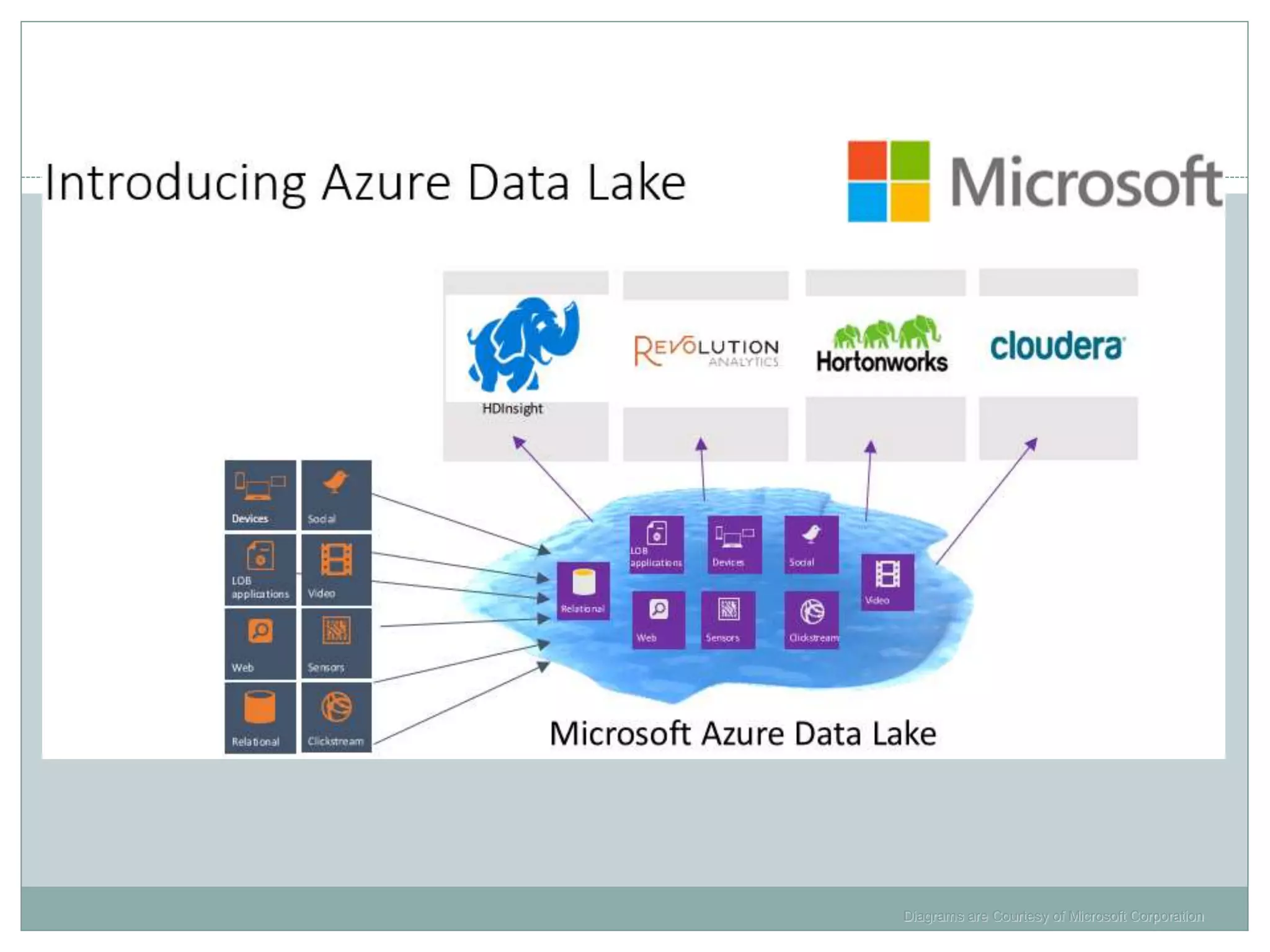
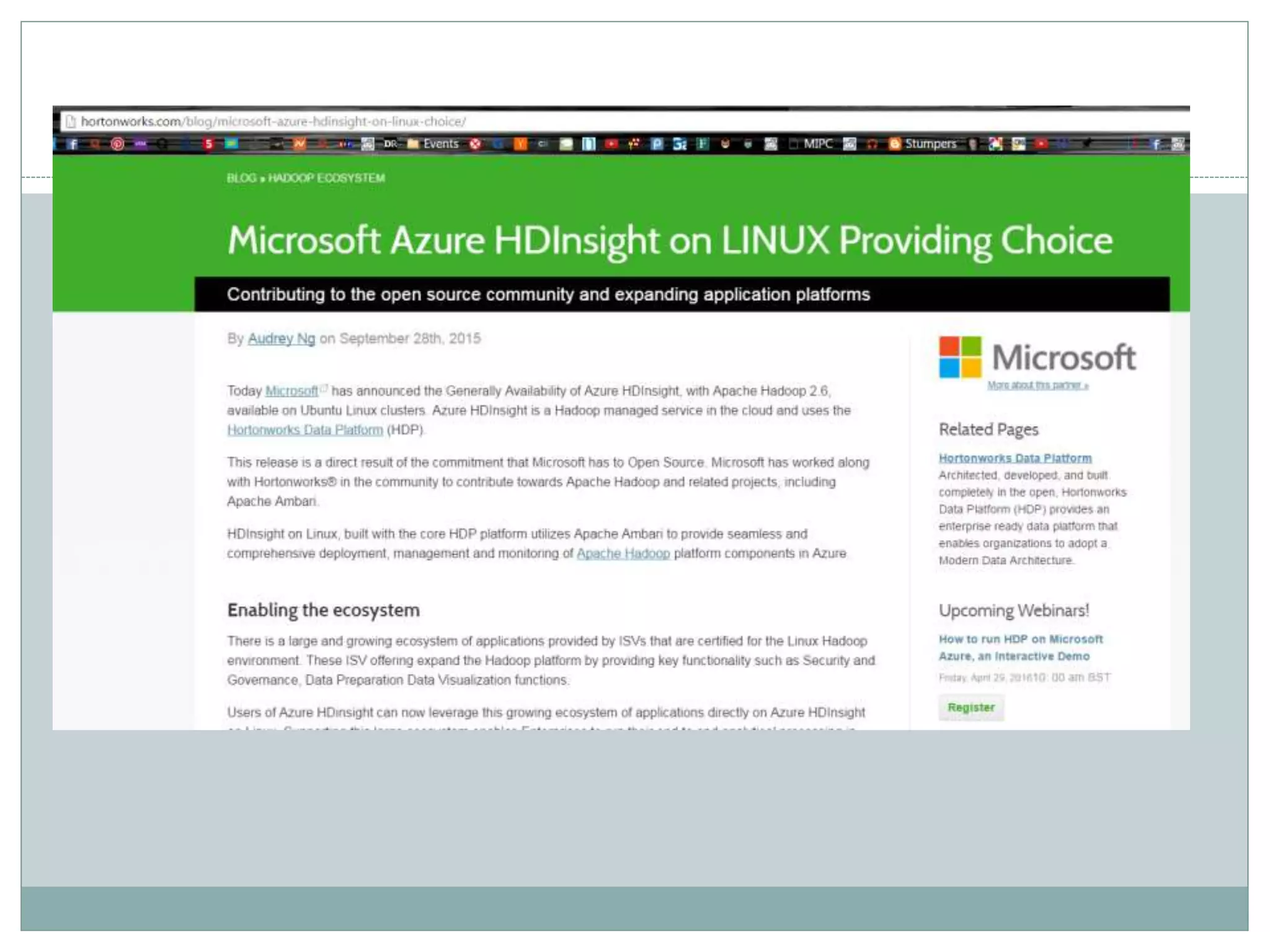
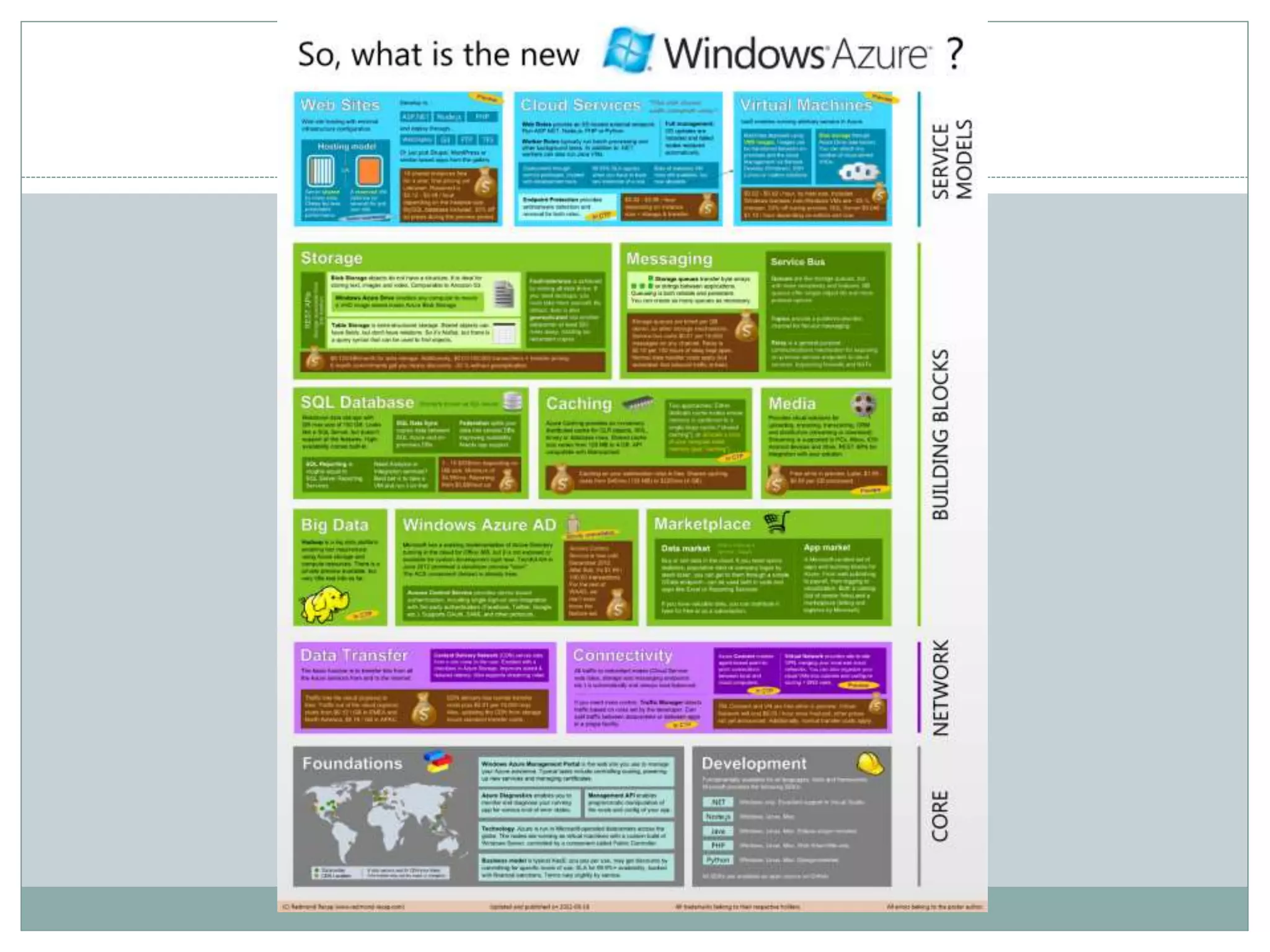
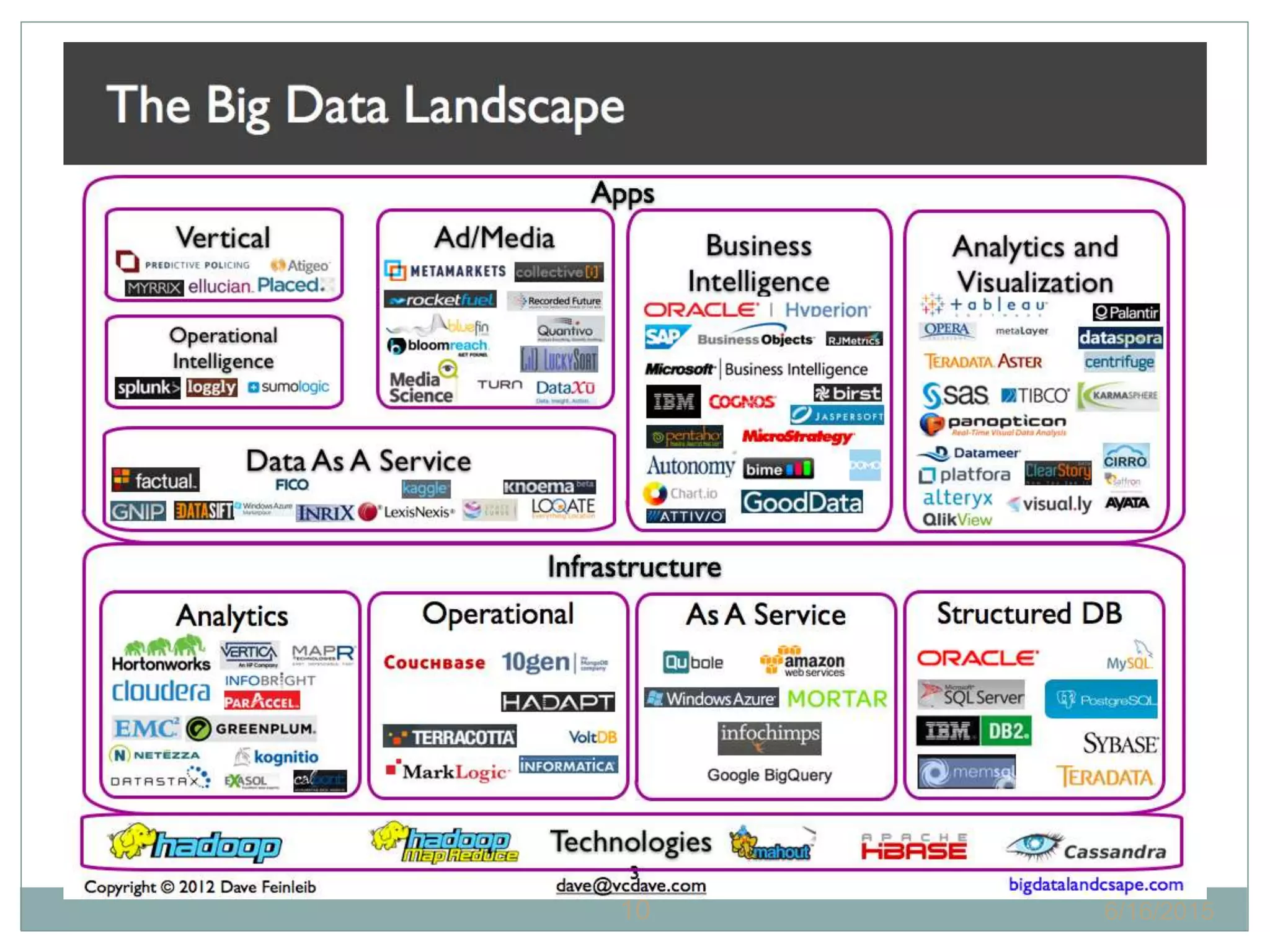


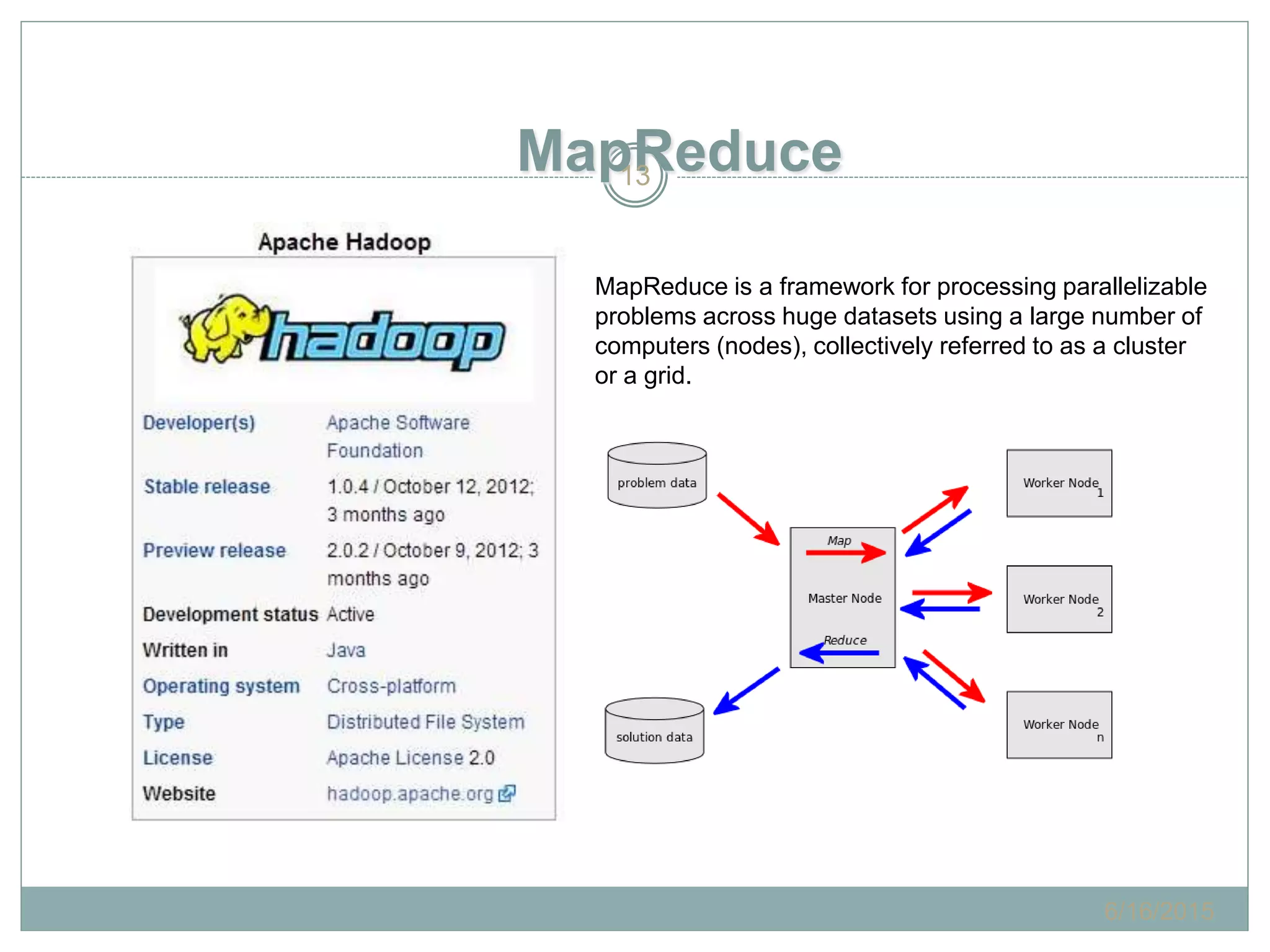


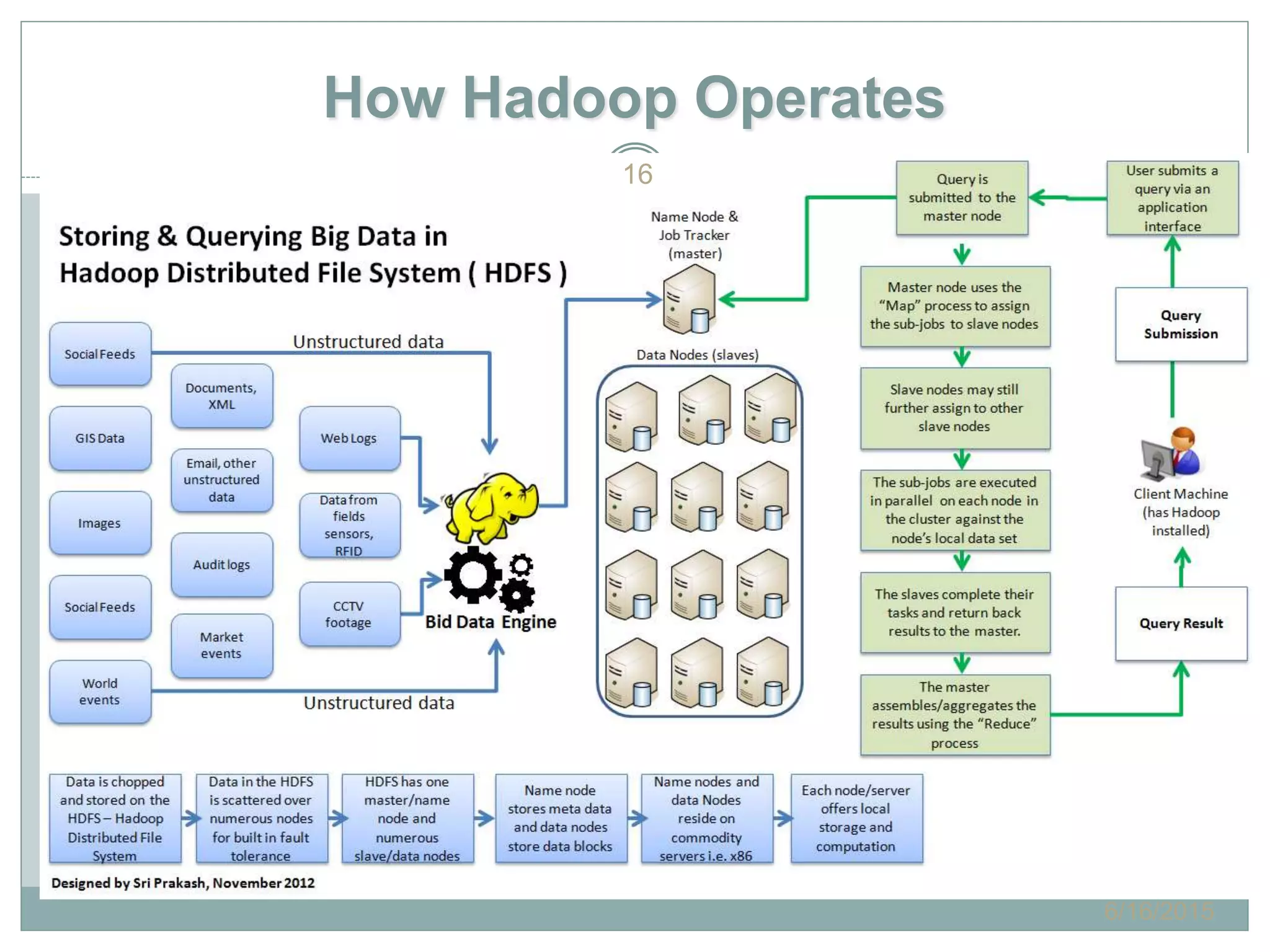













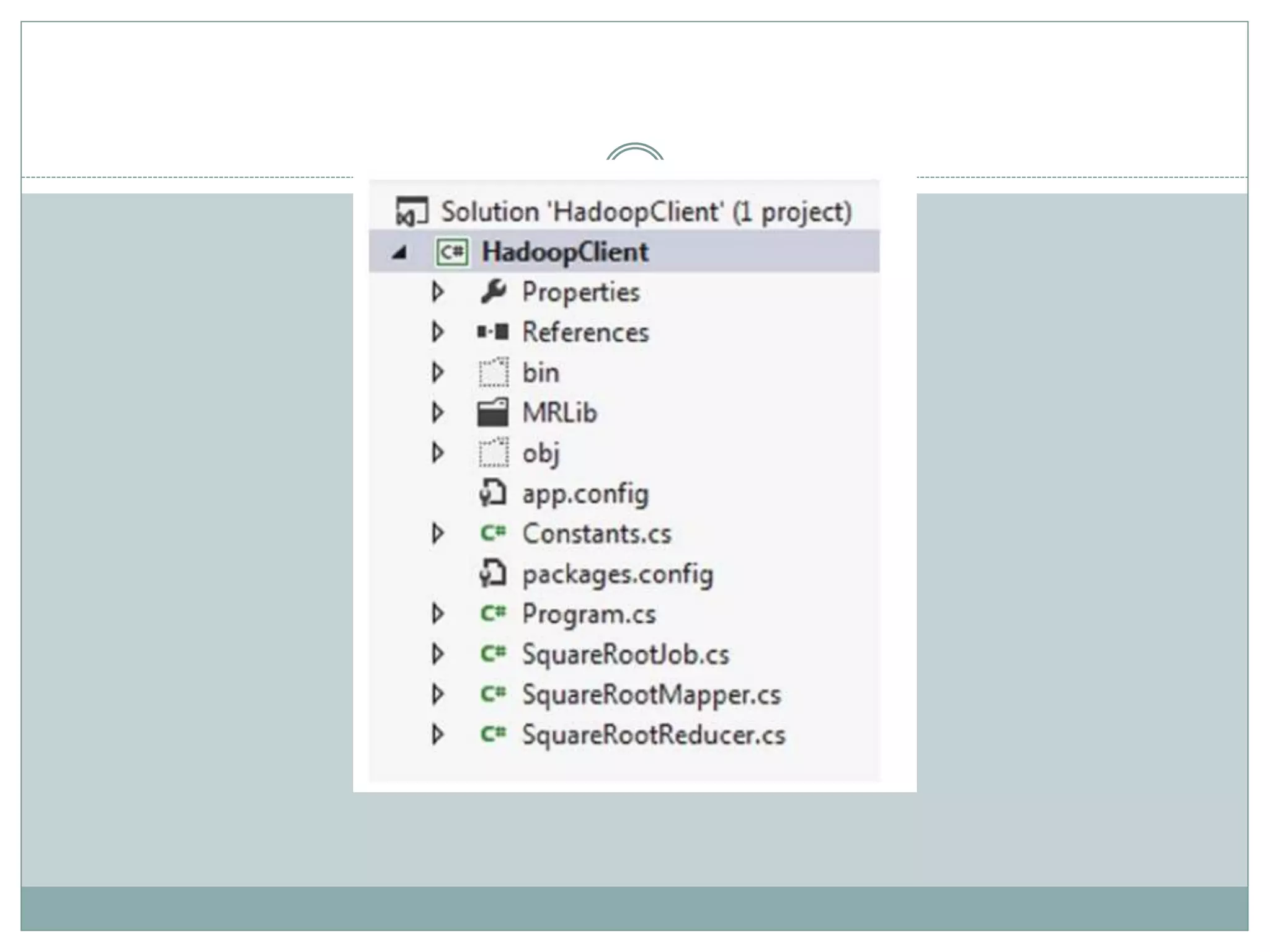
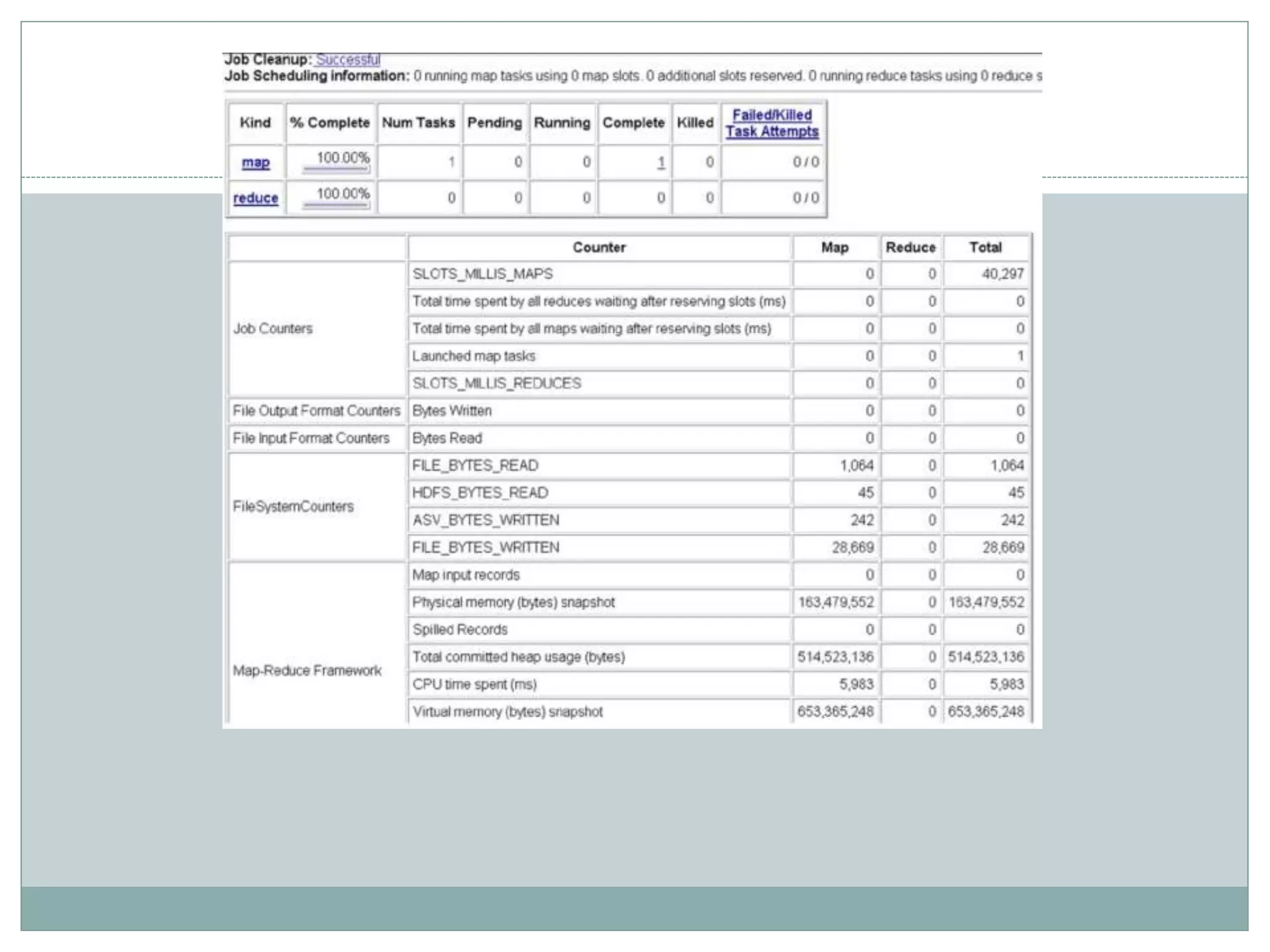
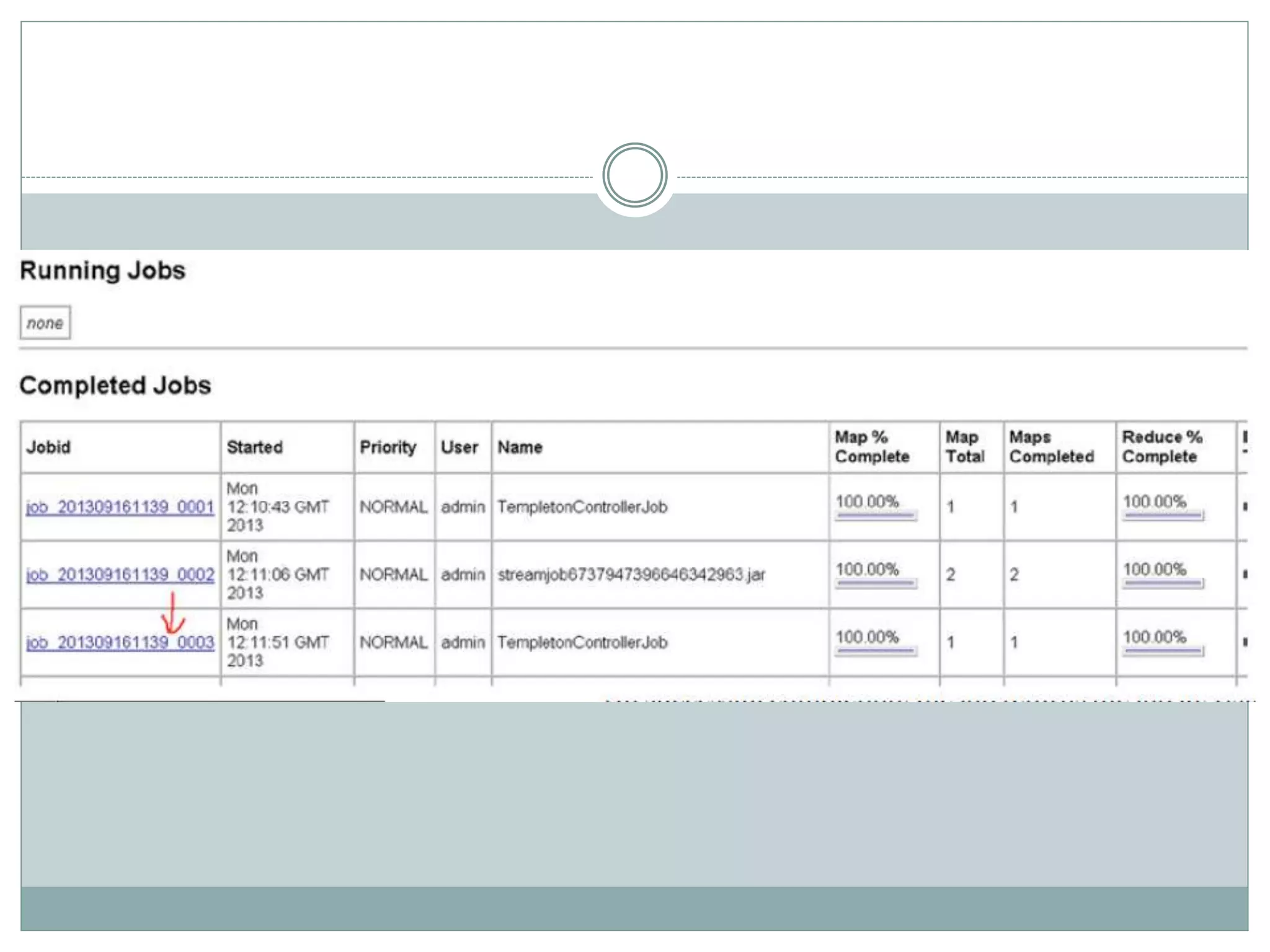
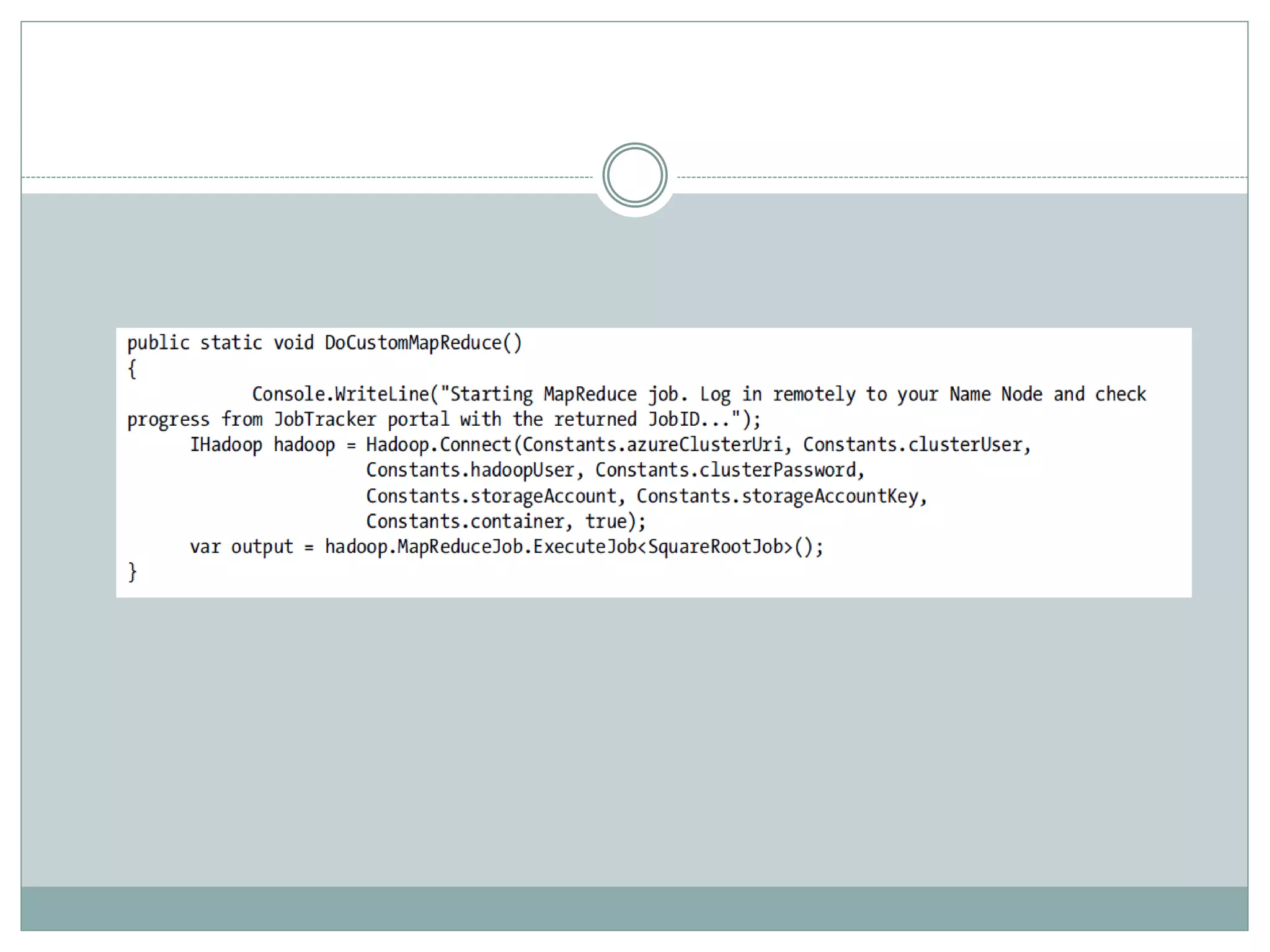
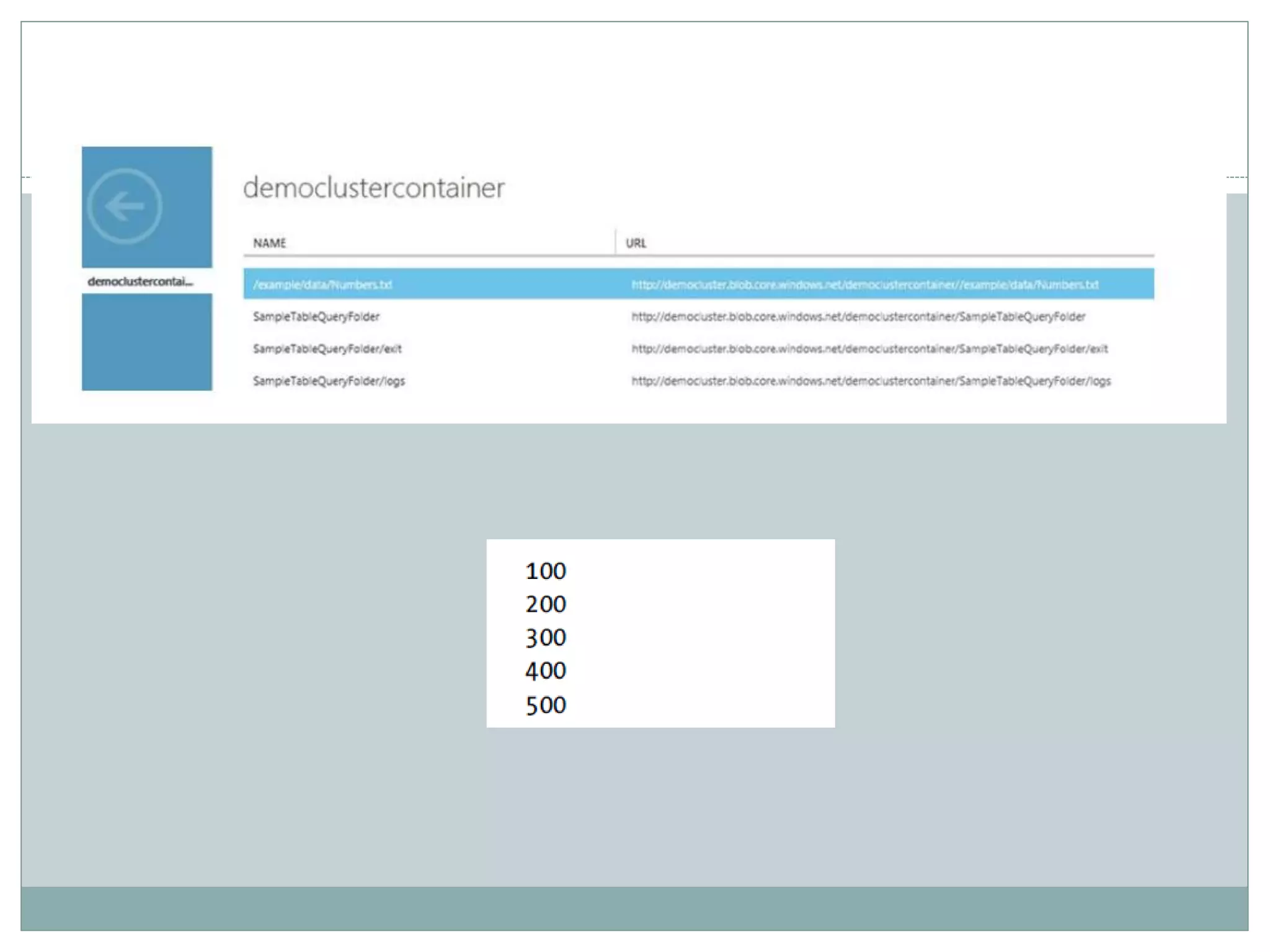
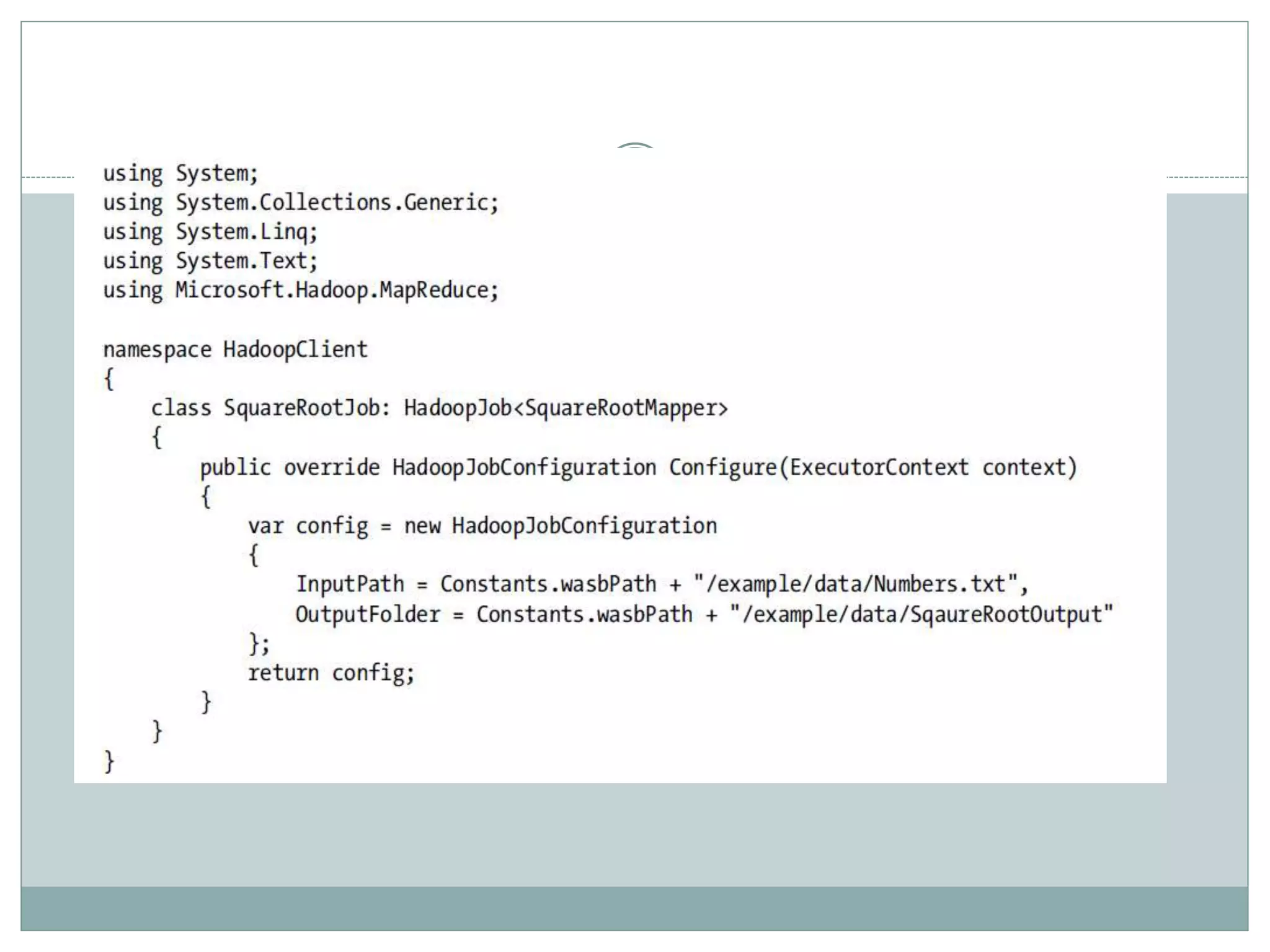
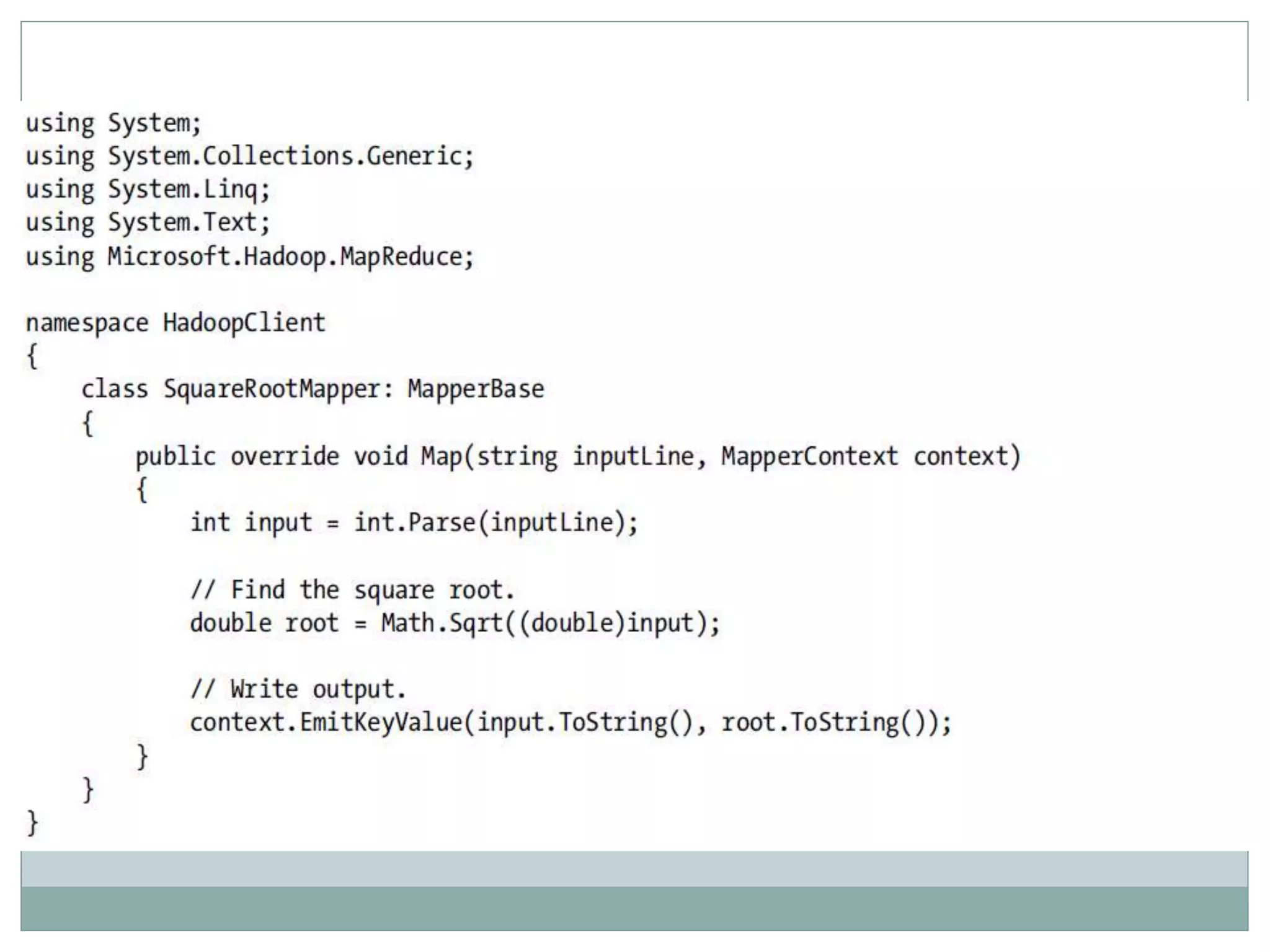
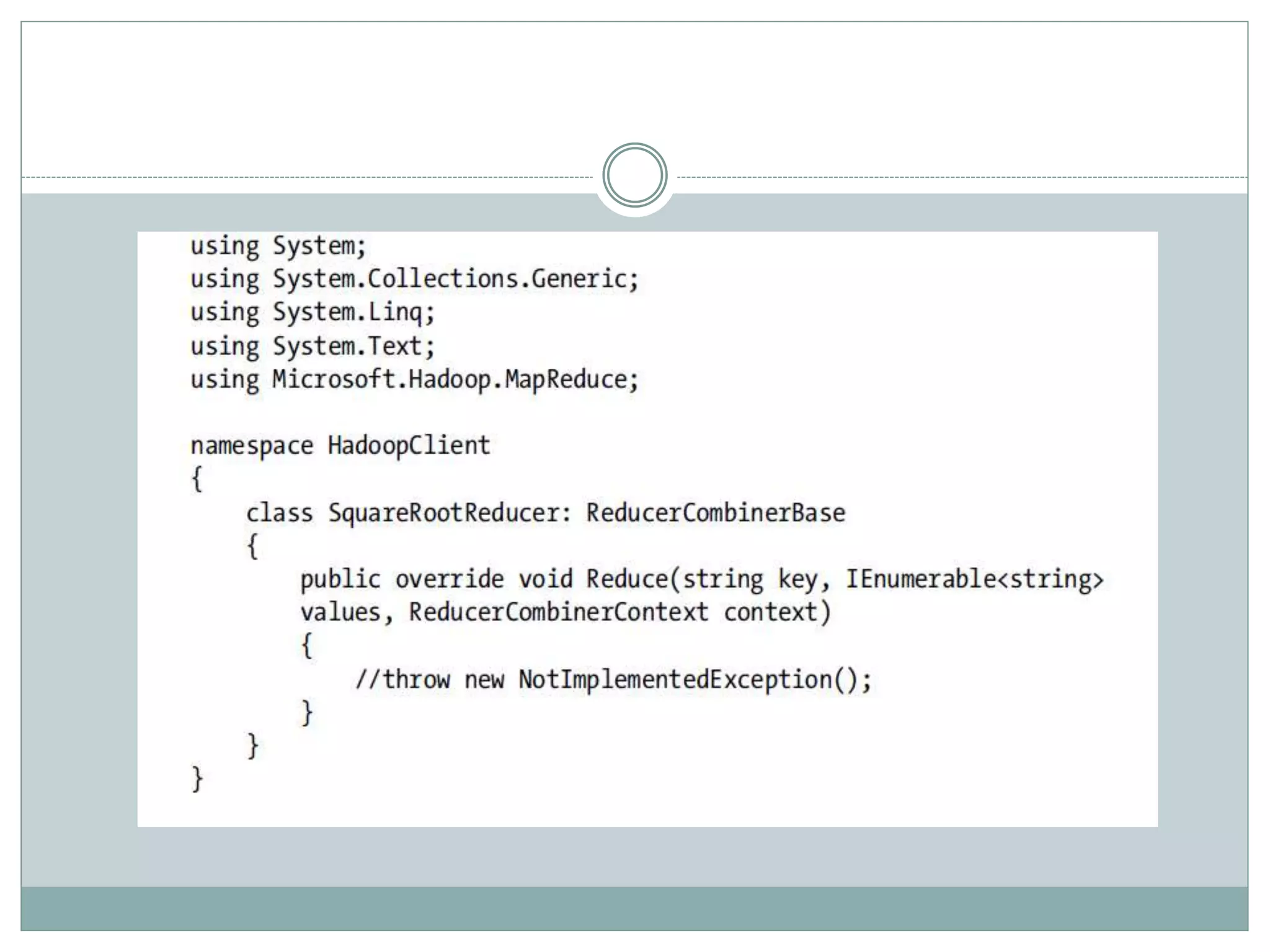




The document presents insights from a talk by Adnan Masood, Ph.D., on data science using Microsoft Azure, focusing on machine learning and Hadoop frameworks. It explains the architecture and functionality of Hadoop and MapReduce, highlighting their applications in various fields, and introduces Apache Spark as a high-performance computing solution. Key players in the Hadoop ecosystem, including Hortonworks and Cloudera, are discussed, alongside the role of cloud service providers like AWS and Google in delivering Hadoop-as-a-Service.































































































