Download as PDF, PPTX


![Word Count
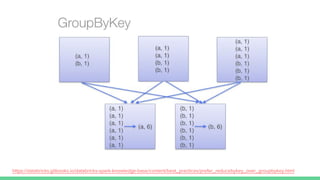
val sc: SparkContext = ...
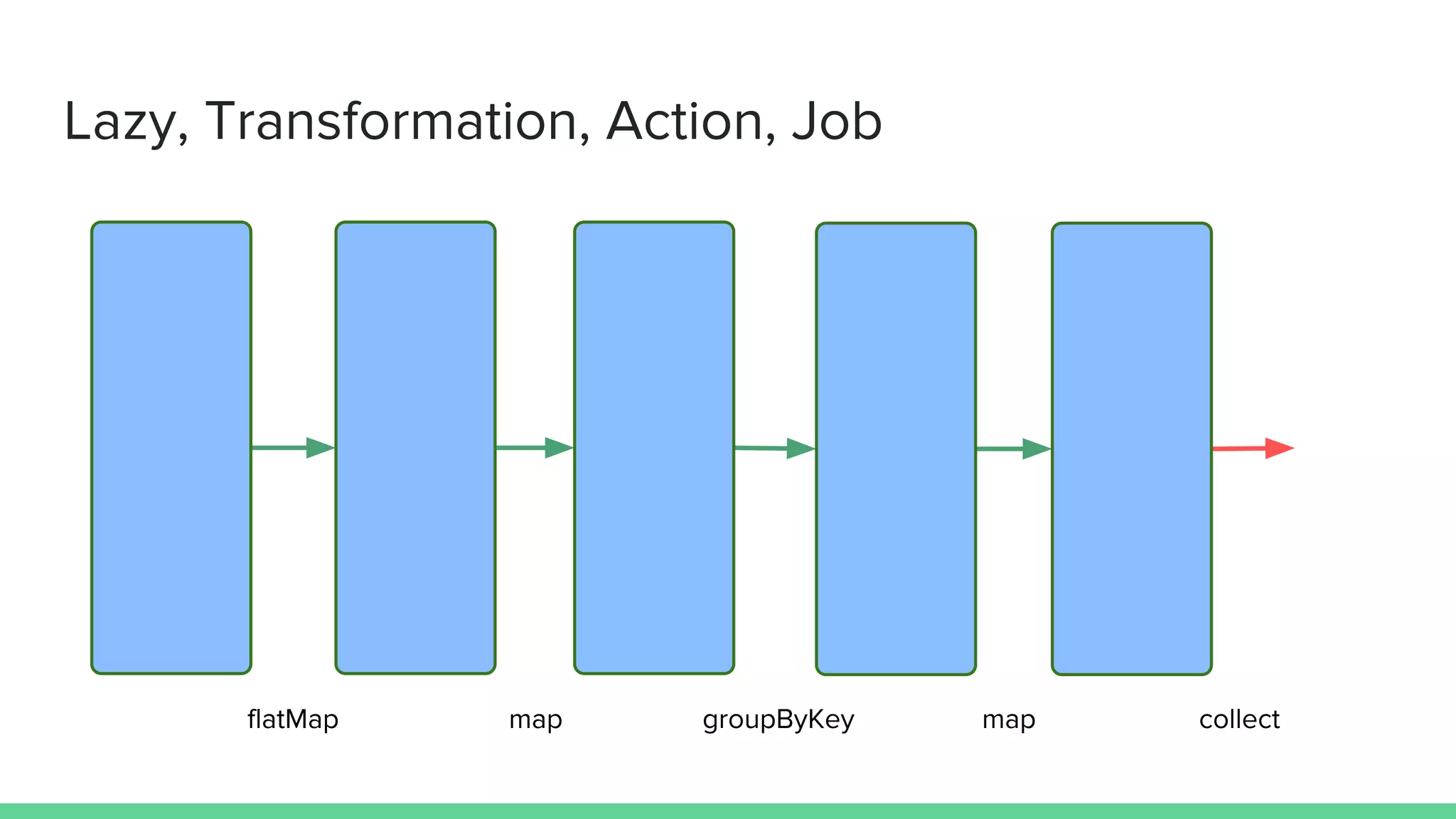
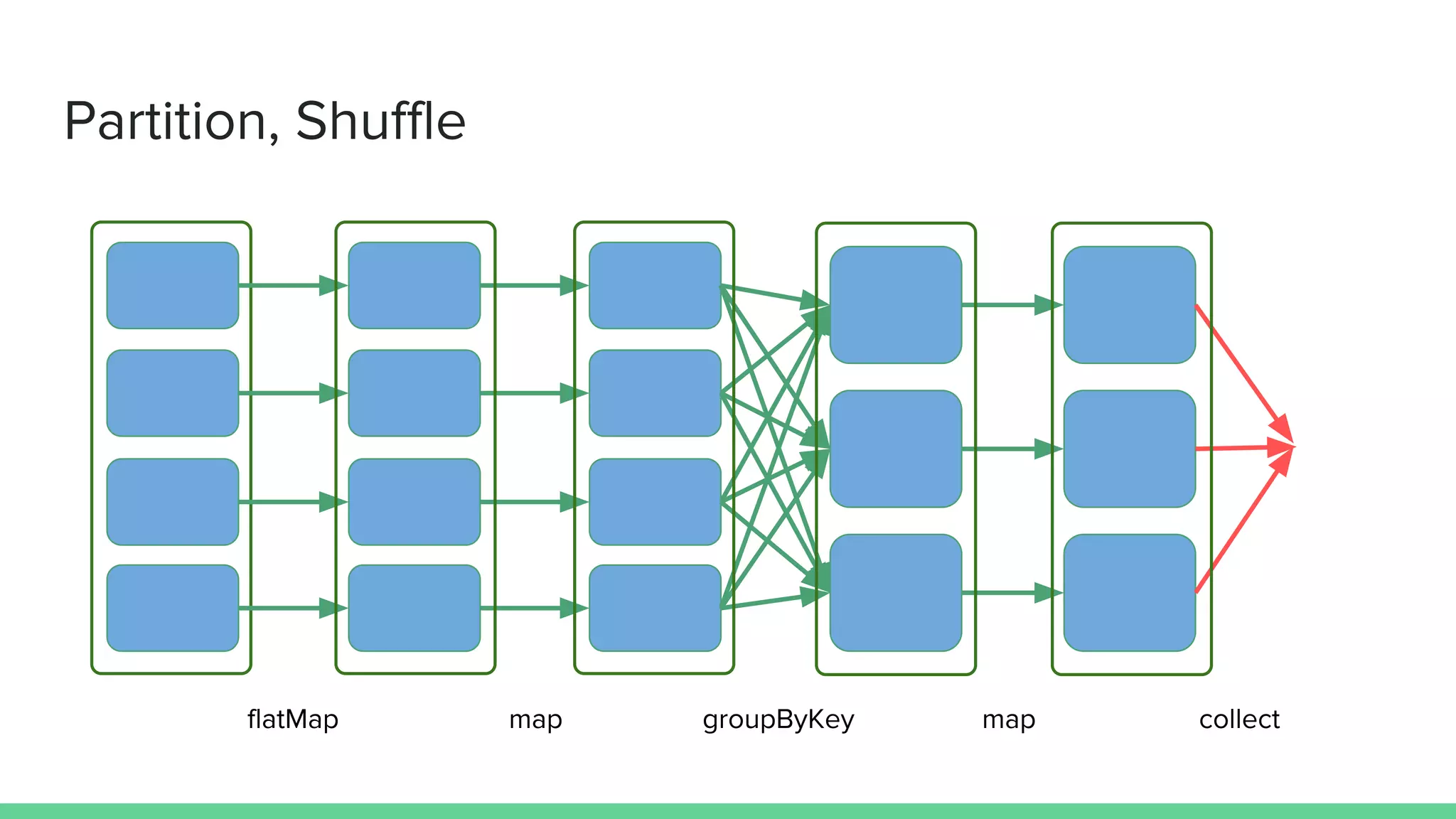
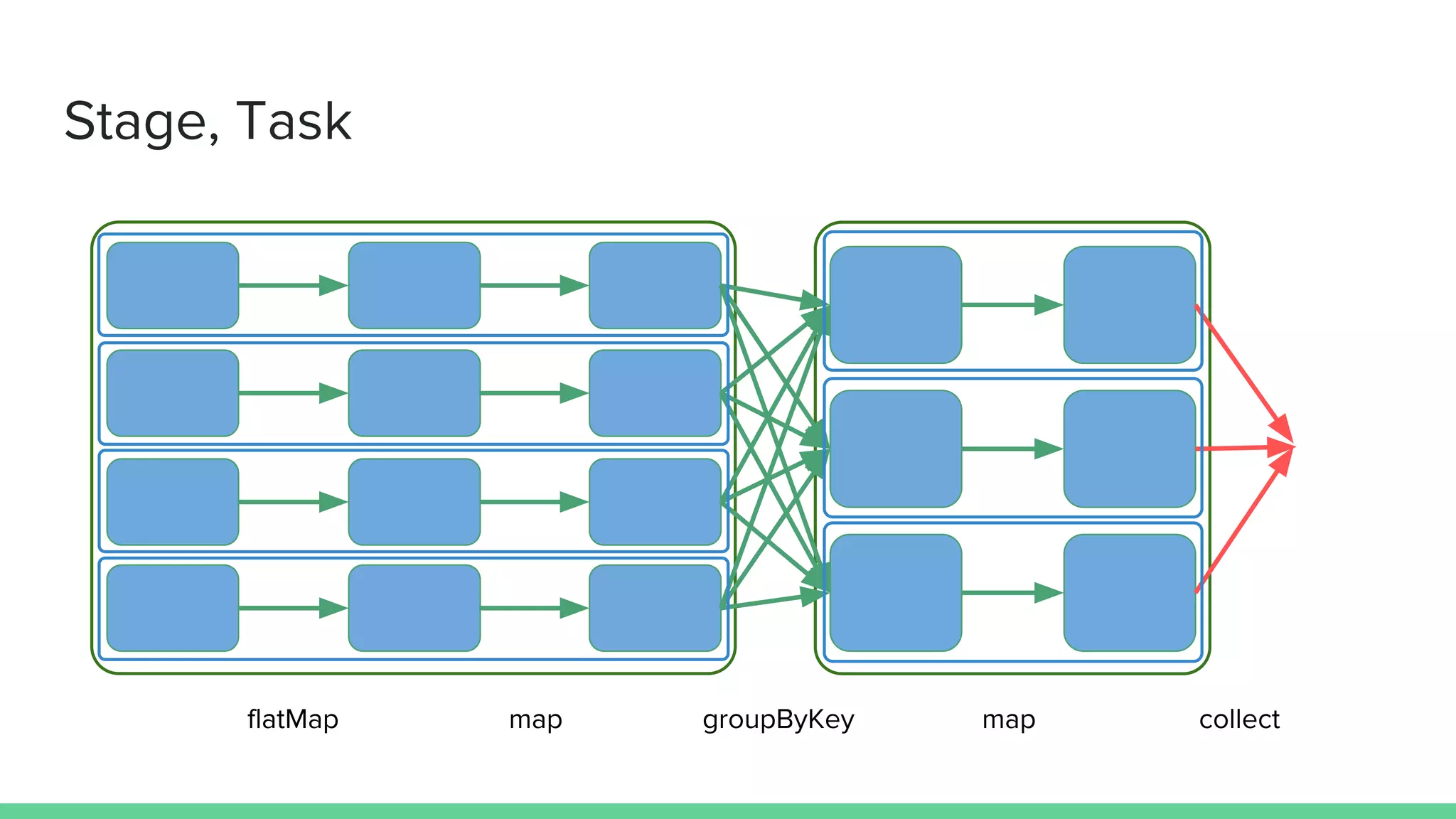
val result = sc.textFile(file) // RDD[String]
.flatMap(_.split(" ")) // RDD[String]
.map(_ -> 1) // RDD[(String, Int)]
.groupByKey() // RDD[(String, Iterable[Int])]
.map(x => (x._1, x._2.sum)) // RDD[(String, Int)]
.collect() // Array[(String, Int])](https://image.slidesharecdn.com/debuggingtuninginspark-160811150111/85/Debugging-Tuning-in-Spark-4-320.jpg)

![Correctness and Parallelizable
● Use small input
● Run locally
○ --master local
○ --master local[4]
○ --master local[*]](https://image.slidesharecdn.com/debuggingtuninginspark-160811150111/85/Debugging-Tuning-in-Spark-10-320.jpg)
















![Word Count
val sc: SparkContext = ...
val result = sc.textFile(file) // RDD[String]
.flatMap(_.split(" ")) // RDD[String]
.map(_ -> 1) // RDD[(String, Int)]
.groupByKey() // RDD[(String, Iterable[Int])]
.map(x => (x._1, x._2.sum)) // RDD[(String, Int)]
.collect() // Array[(String, Int])](https://image.slidesharecdn.com/debuggingtuninginspark-160811150111/75/Debugging-Tuning-in-Spark-4-2048.jpg)

![Correctness and Parallelizable
● Use small input
● Run locally
○ --master local
○ --master local[4]
○ --master local[*]](https://image.slidesharecdn.com/debuggingtuninginspark-160811150111/75/Debugging-Tuning-in-Spark-10-2048.jpg)
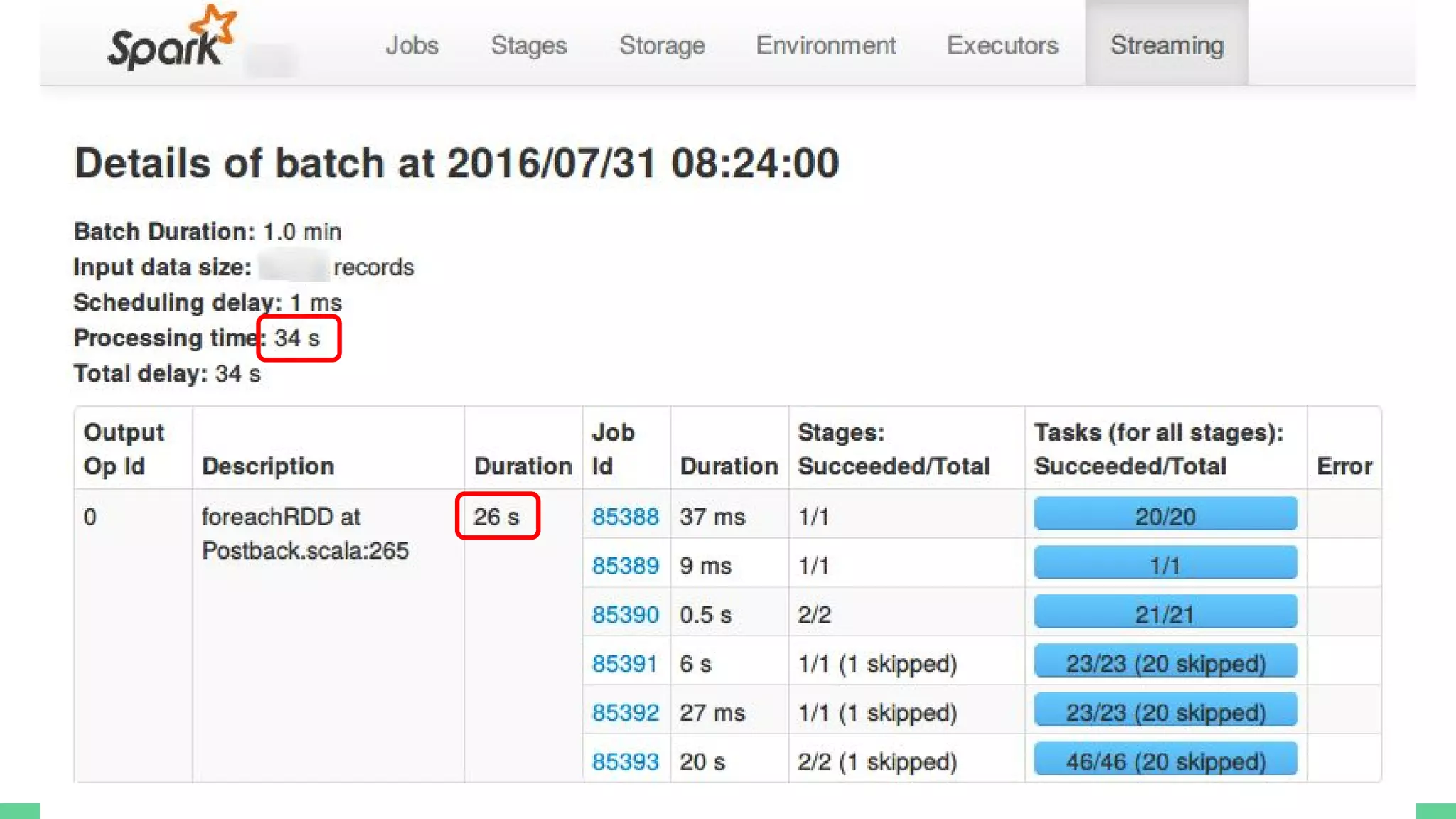
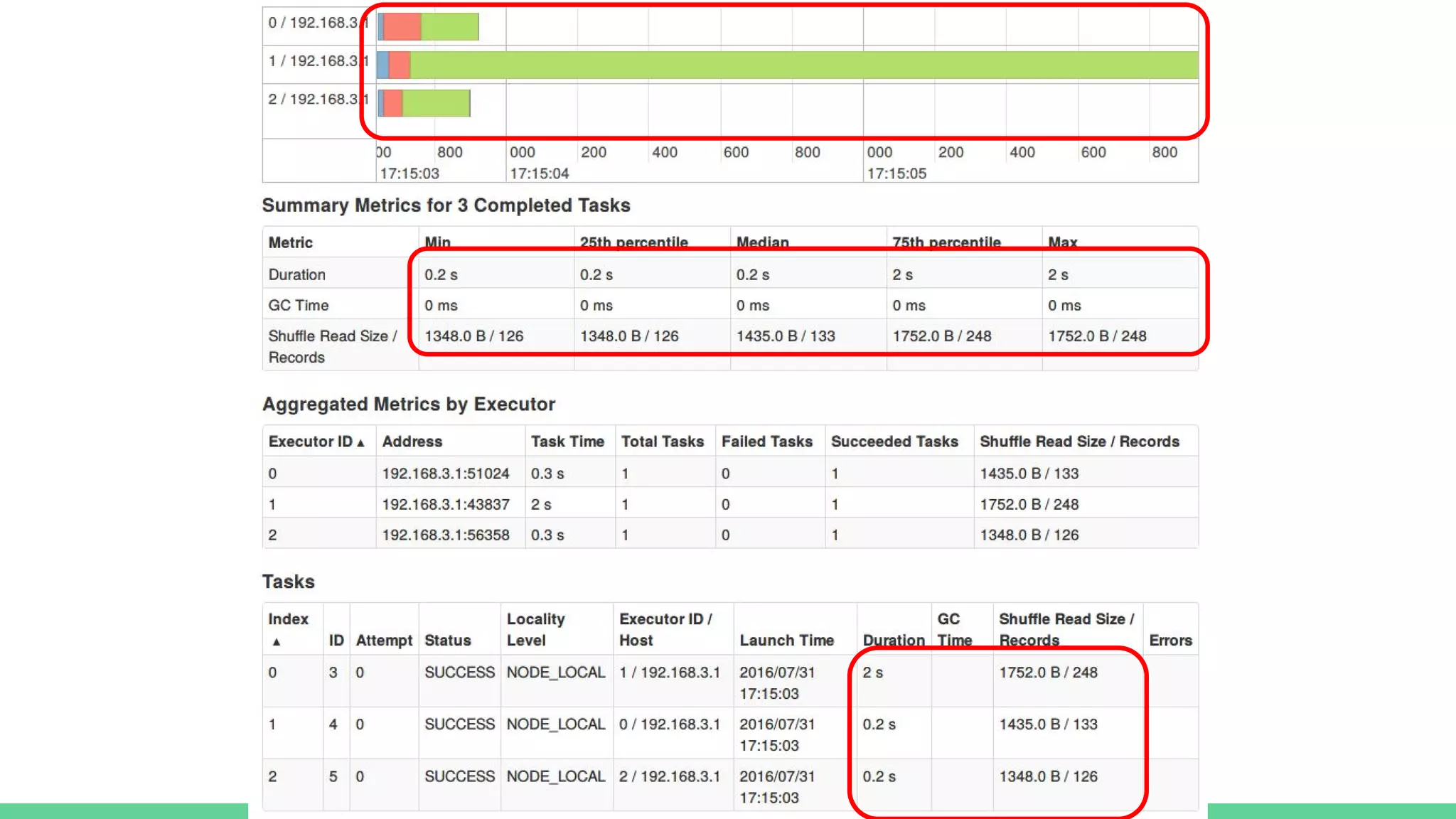

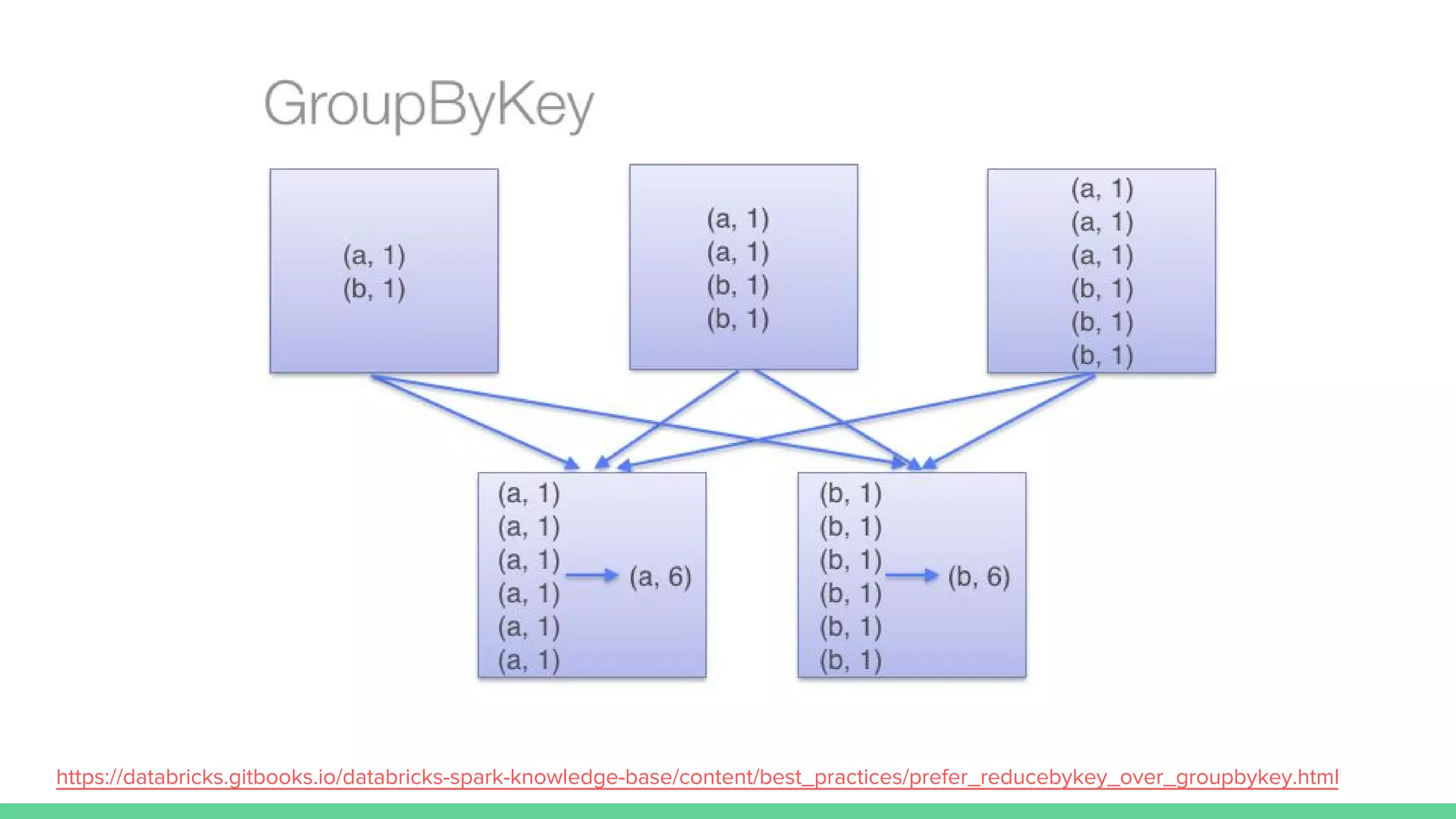
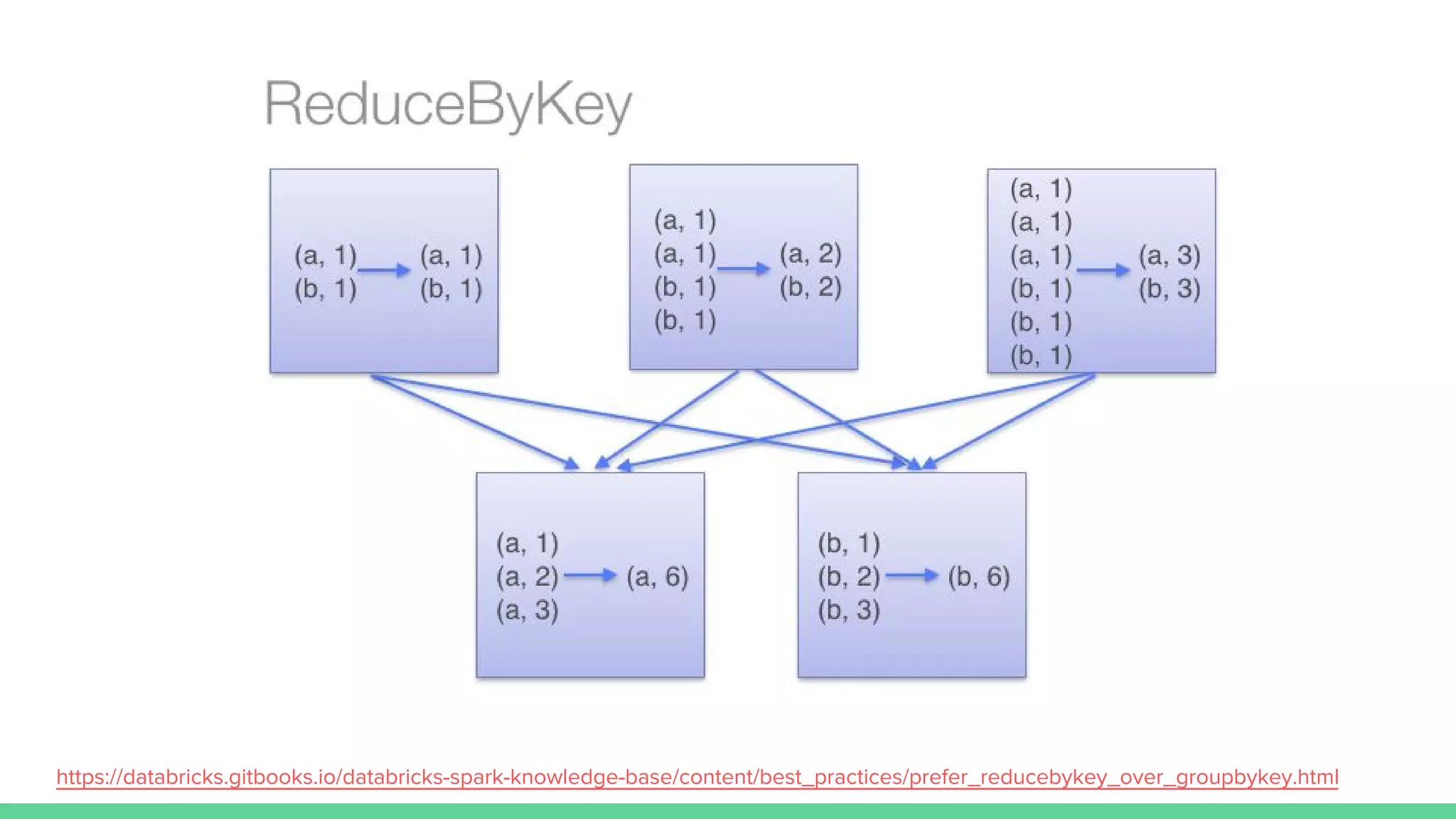
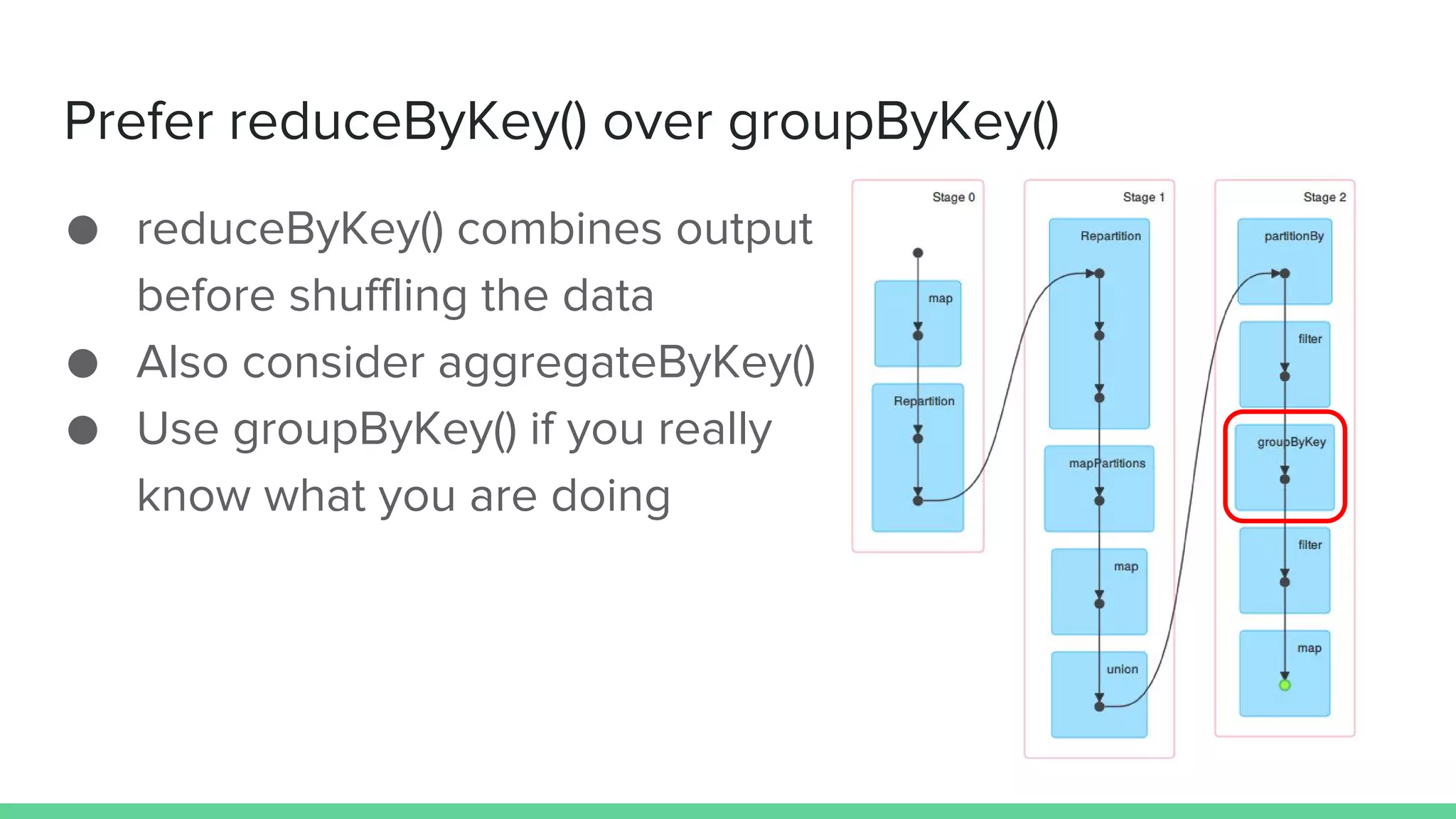
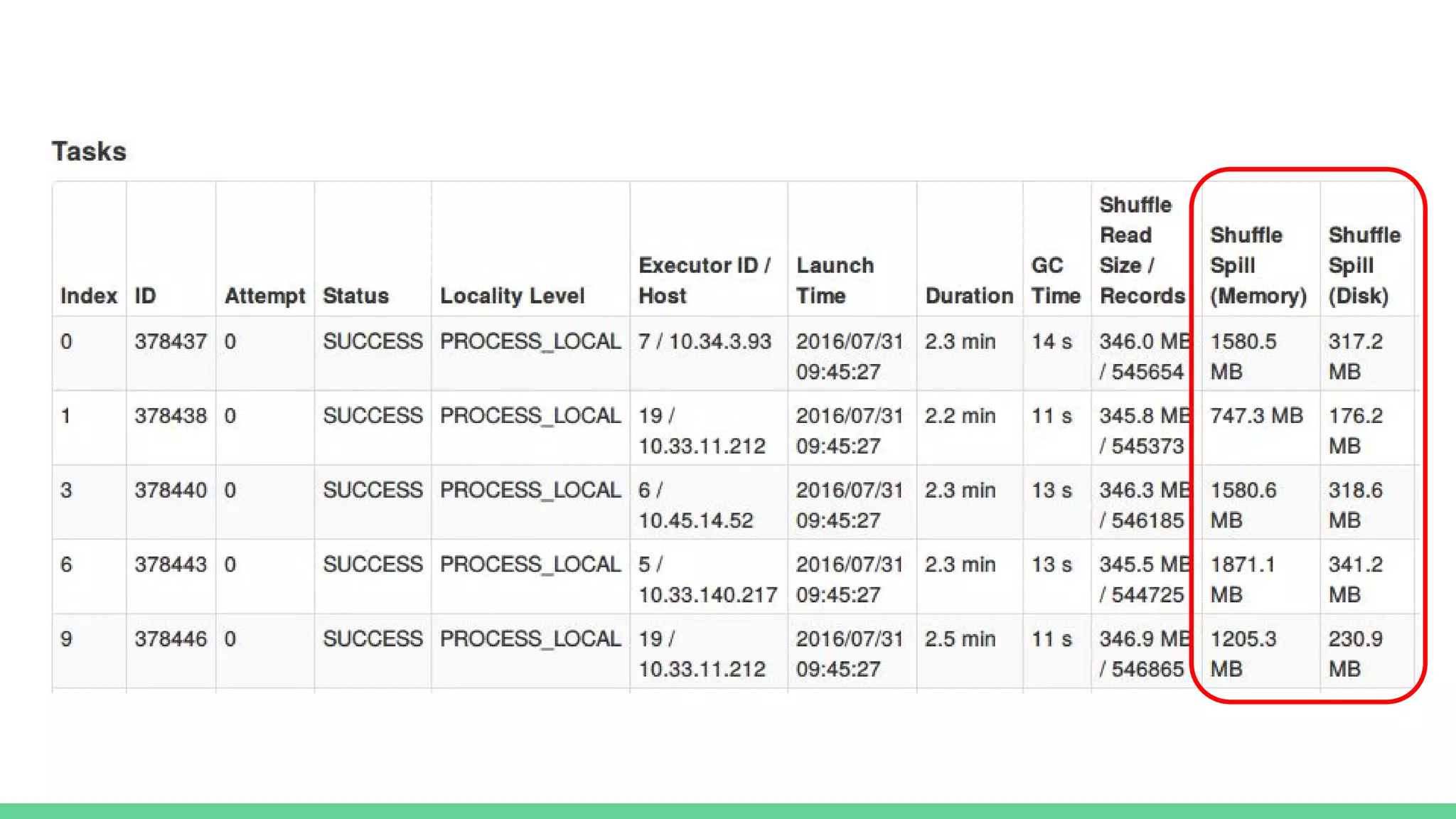

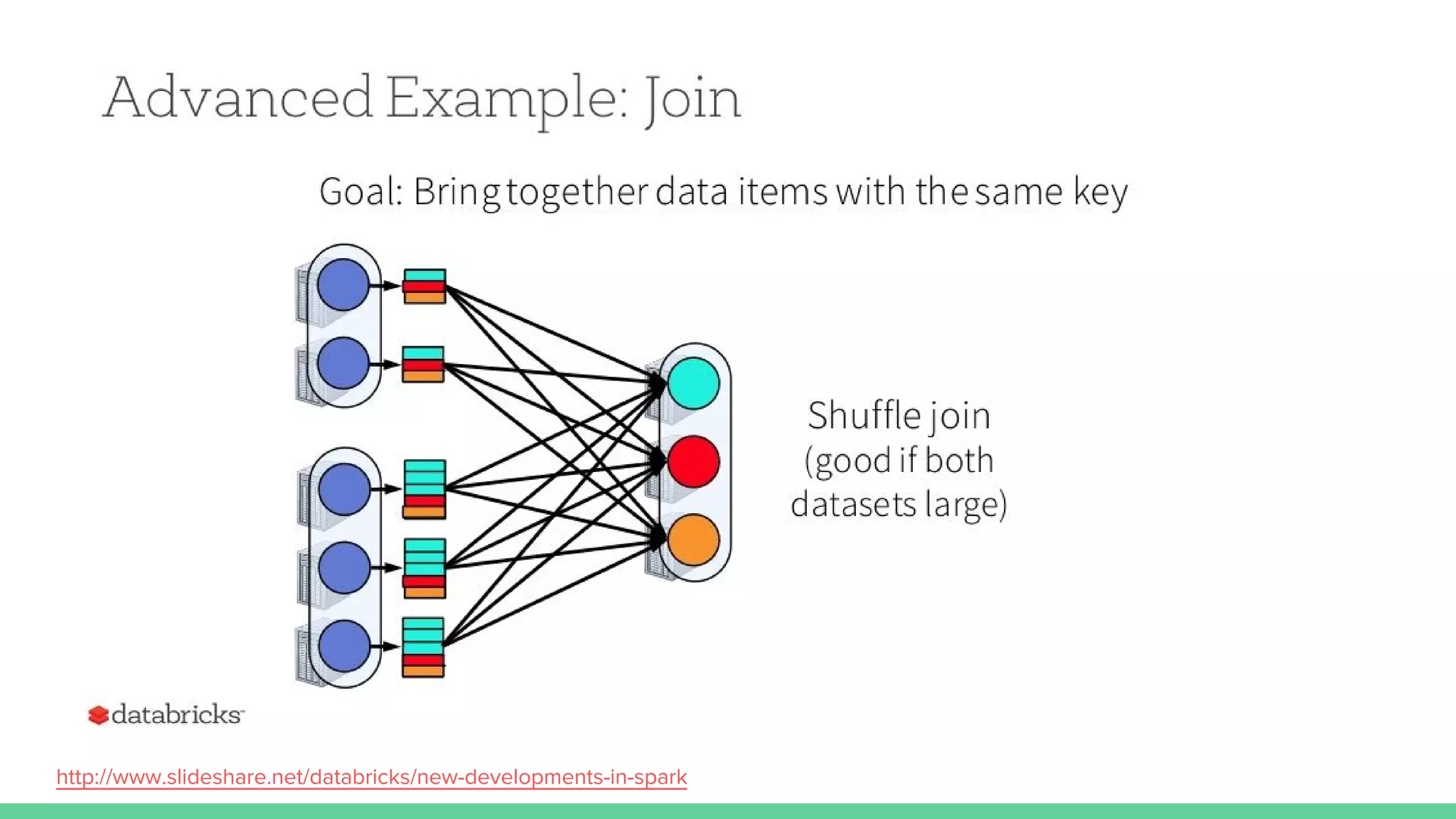



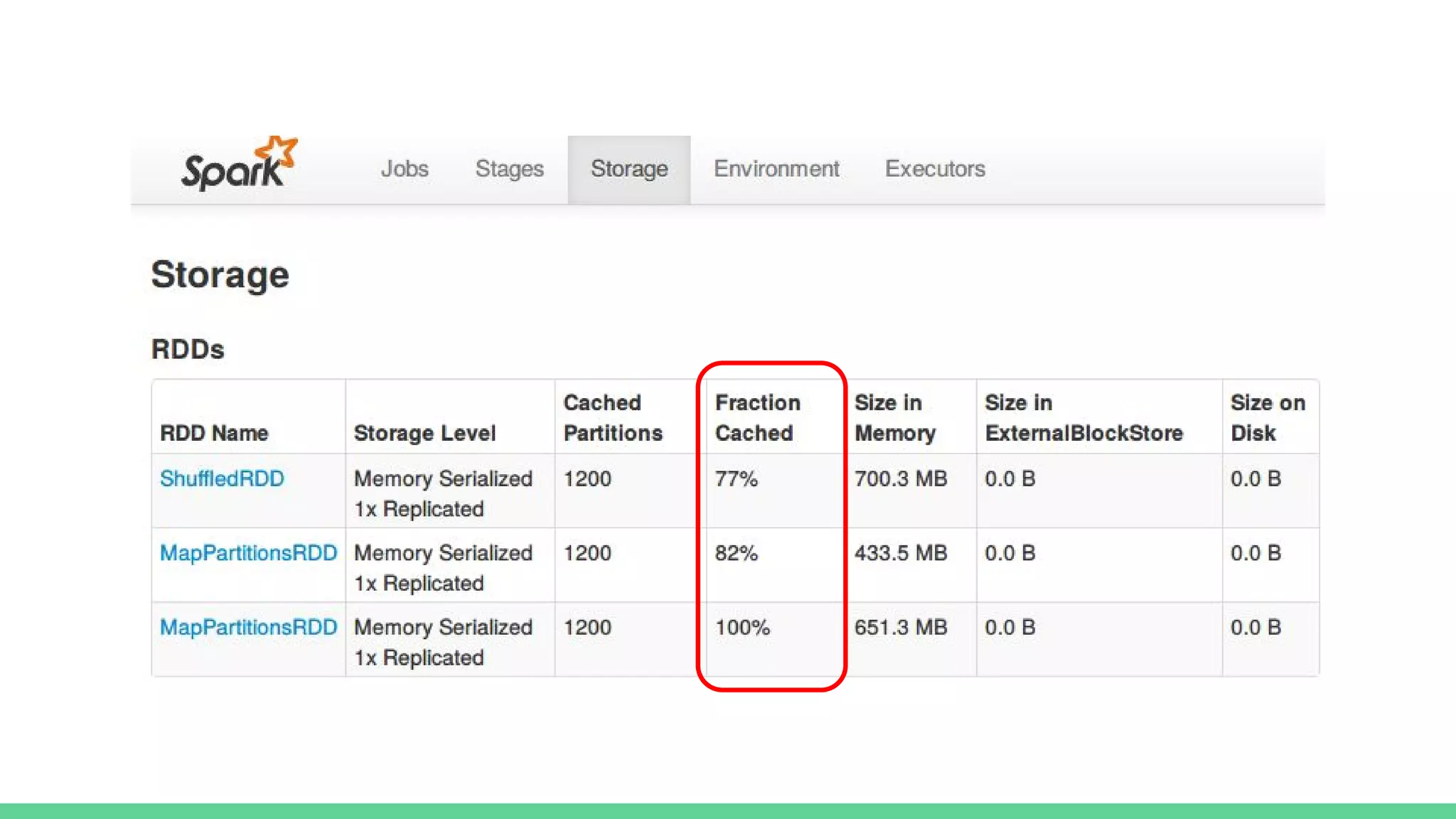



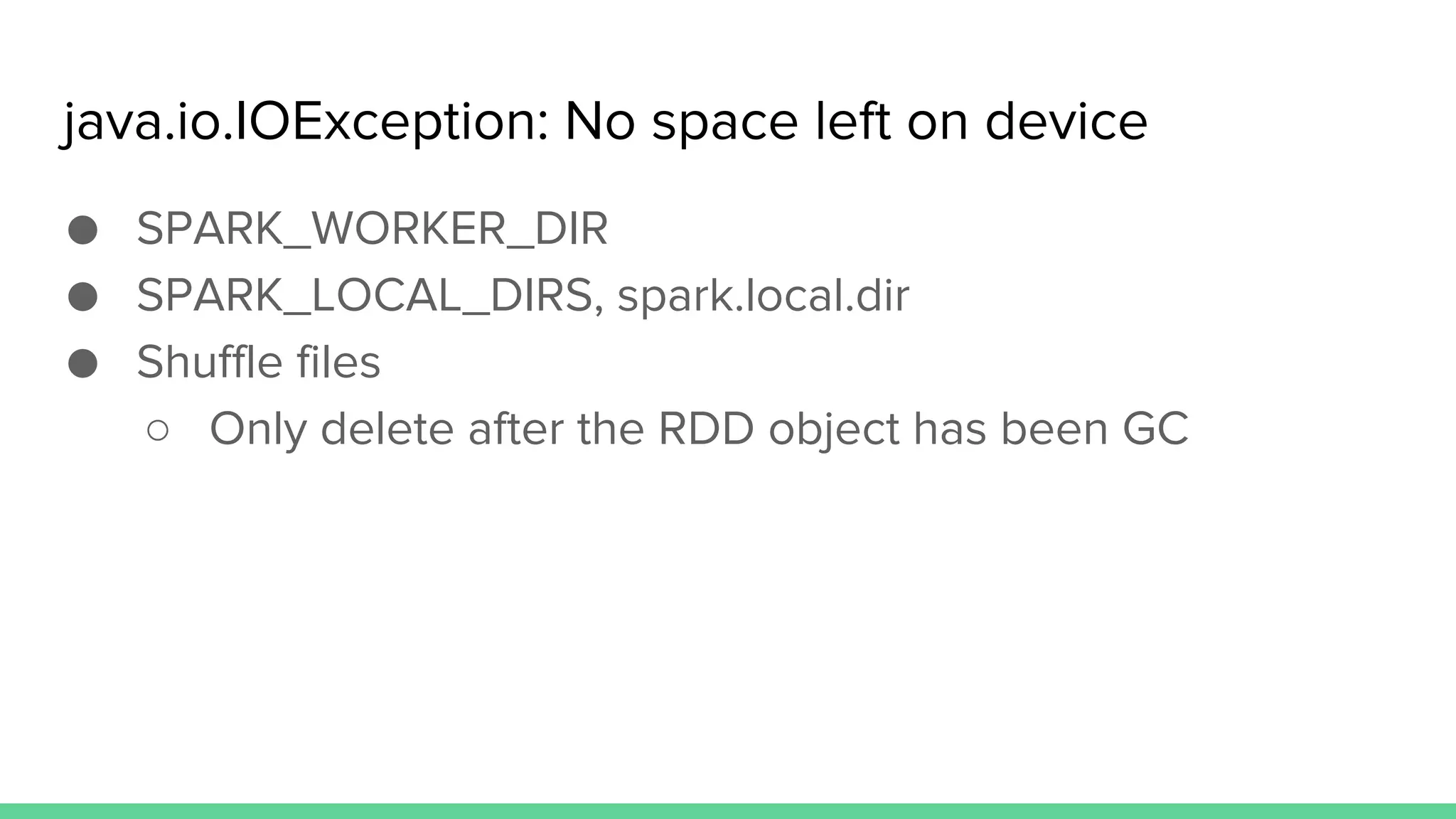







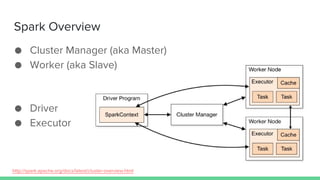
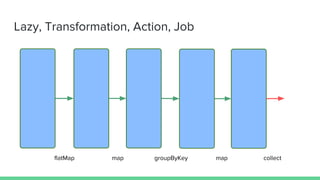
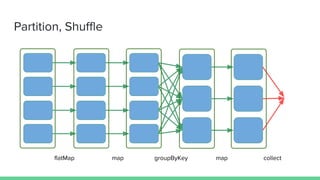
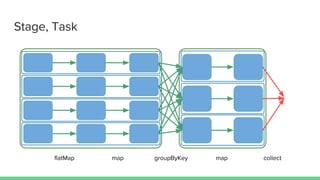
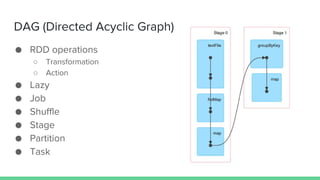
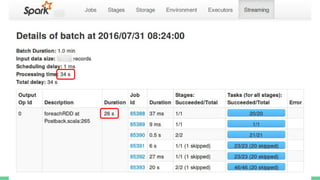
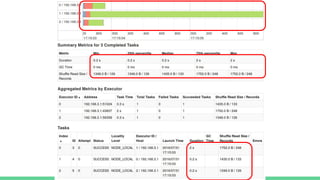
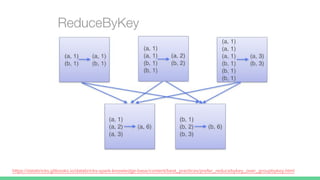
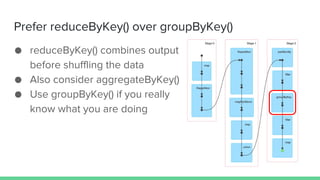
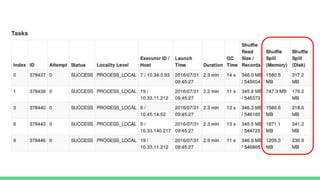
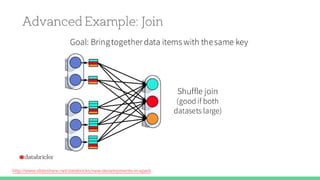
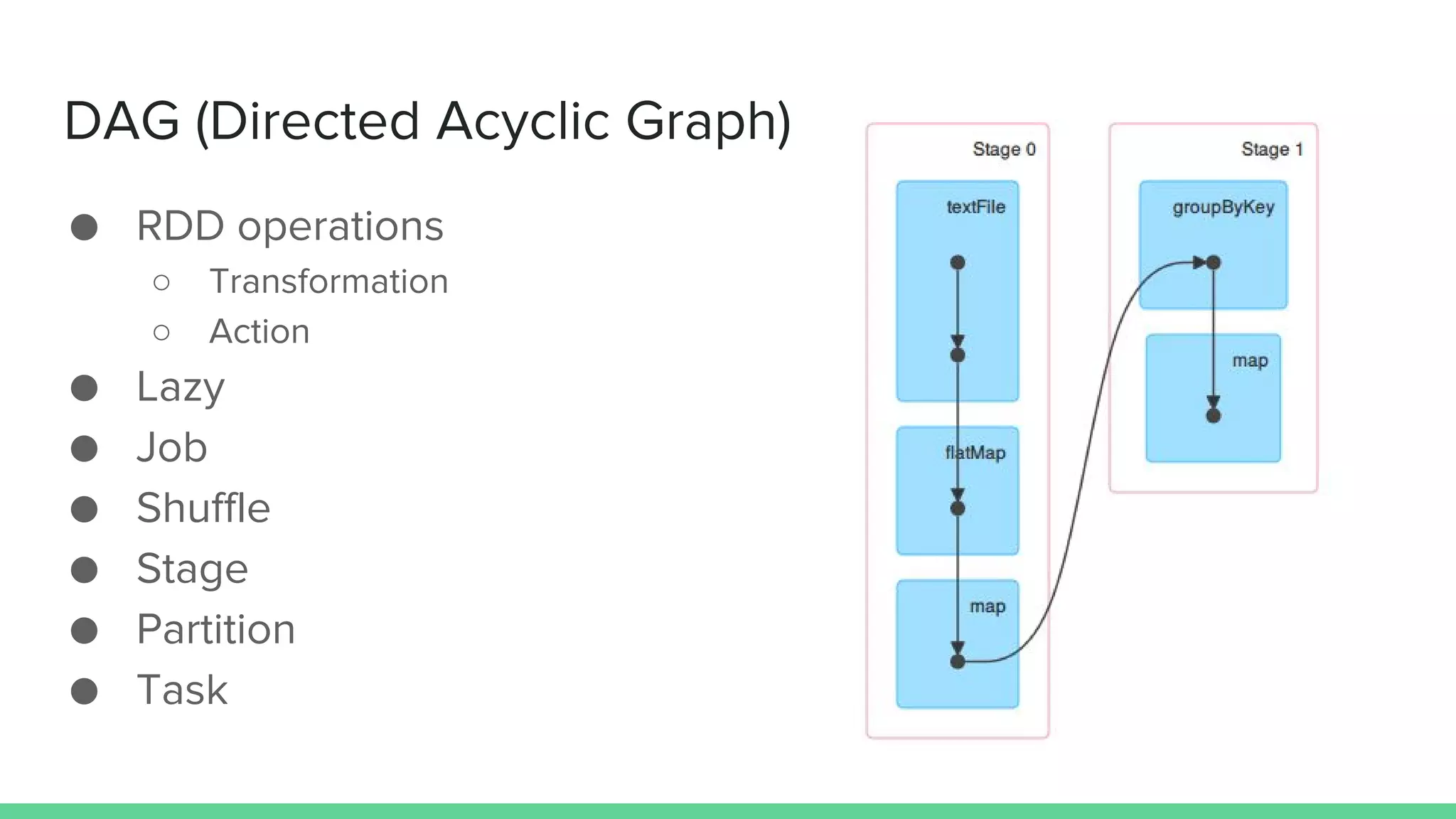
This document provides tips and best practices for debugging and tuning Spark applications. It discusses Spark concepts like RDDs, transformations, actions, and the DAG execution model. It then gives recommendations for improving correctness, reducing overhead from parallelism, avoiding data skew, and tuning configurations like storage level, number of partitions, executor resources and joins. Common failures are analyzed along with their causes and fixes. Overall it emphasizes the importance of tuning partitioning, avoiding shuffles when possible, and using the right configurations to optimize Spark jobs.



















































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







