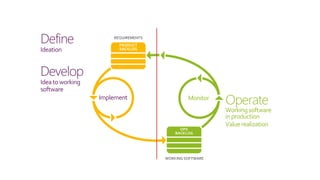
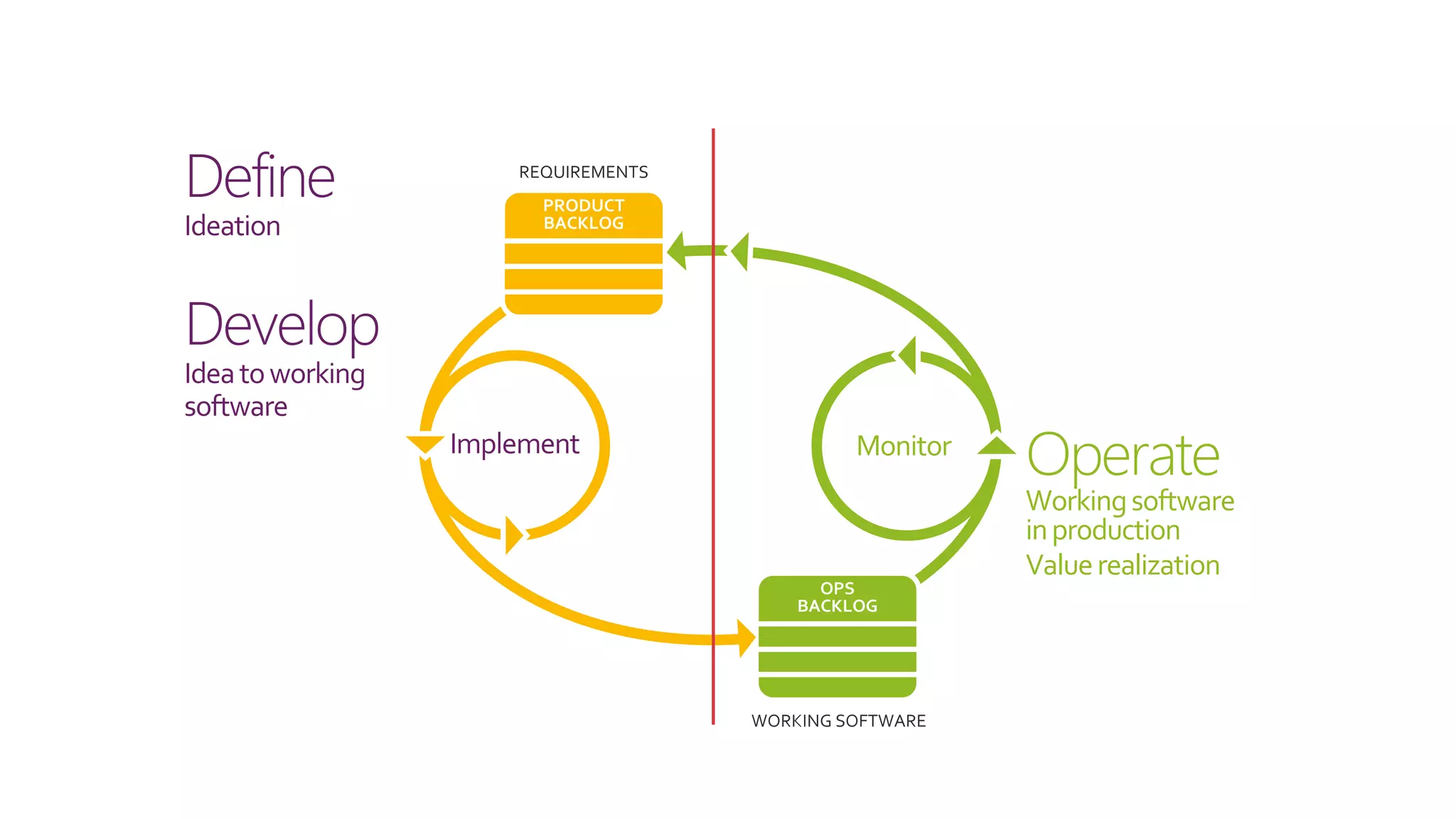
The document discusses development and QA dilemmas in DevOps. It notes that traditionally development was done separately from testing and production environments, but with DevOps there is a focus on continuous delivery through automated pipelines. It acknowledges this is a big change that makes some developers and testers uncomfortable by removing safety nets. It emphasizes that DevOps is about culture and practices, not specific technologies, and that these practices can be used on-premises. It provides examples of how to handle database schema changes and feature rollouts transparently in production. It stresses measuring outcomes through metrics and analytics to learn from users and improve products iteratively.











































































![[IBM Pulse 2014] #1579 DevOps Technical Strategy and Roadmap](https://cdn.slidesharecdn.com/ss_thumbnails/pulse1579devopstechstrategyroadmap-140303191835-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)













































































