Download to read offline





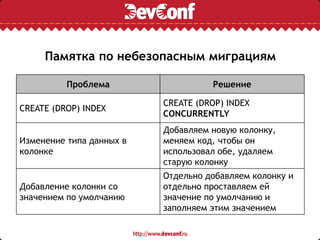







![Простое решение: N+1 запросов
for category in categories: latest_articles_by_category[category] =
( Article.objects .filter(category=category) .order_by('-
date_published')[:N])
Придется сделать по одному запросу к БД на каждую группу, сработает
относительно быстро для небольшого количества групп.
Проблем у Django ORM с таким решением не возникает.](https://image.slidesharecdn.com/c14da2e8-2b18-4be2-82e6-bdfaed10aa07-160802213805/85/django-and-postgresql-16-320.jpg)

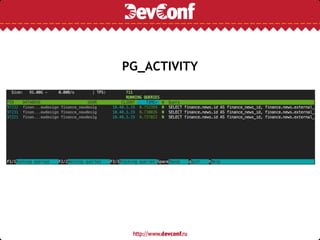
![В Django-ORM нет поддержки оконных
функций и явных подзапросов
articles_subquery = ( Article.objects .filter(category_id__in=(1, 2, 3, 4))
.annotate(row=RawSQL( 'ROW_NUMBER() OVER (PARTITION BY %s ORDER BY %s
DESC)', [Article._meta.get_field('category').column,
Article._meta.get_field('date_published').column] )) )
articles = Article.objects.raw(
'SELECT * FROM ({}) AS s WHERE s.row <= %s'
.format(articles_subquery.query), [5])](https://image.slidesharecdn.com/c14da2e8-2b18-4be2-82e6-bdfaed10aa07-160802213805/85/django-and-postgresql-18-320.jpg)
























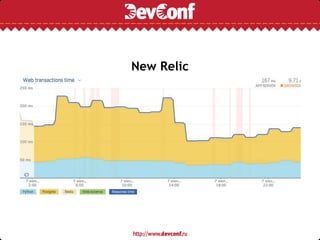
![Простое решение: N+1 запросов
for category in categories: latest_articles_by_category[category] =
( Article.objects .filter(category=category) .order_by('-
date_published')[:N])
Придется сделать по одному запросу к БД на каждую группу, сработает
относительно быстро для небольшого количества групп.
Проблем у Django ORM с таким решением не возникает.](https://image.slidesharecdn.com/c14da2e8-2b18-4be2-82e6-bdfaed10aa07-160802213805/75/django-and-postgresql-16-2048.jpg)

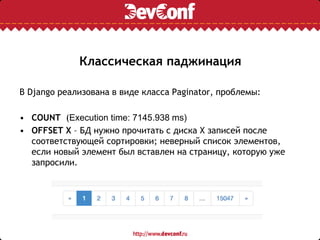
![В Django-ORM нет поддержки оконных
функций и явных подзапросов
articles_subquery = ( Article.objects .filter(category_id__in=(1, 2, 3, 4))
.annotate(row=RawSQL( 'ROW_NUMBER() OVER (PARTITION BY %s ORDER BY %s
DESC)', [Article._meta.get_field('category').column,
Article._meta.get_field('date_published').column] )) )
articles = Article.objects.raw(
'SELECT * FROM ({}) AS s WHERE s.row <= %s'
.format(articles_subquery.query), [5])](https://image.slidesharecdn.com/c14da2e8-2b18-4be2-82e6-bdfaed10aa07-160802213805/75/django-and-postgresql-18-2048.jpg)




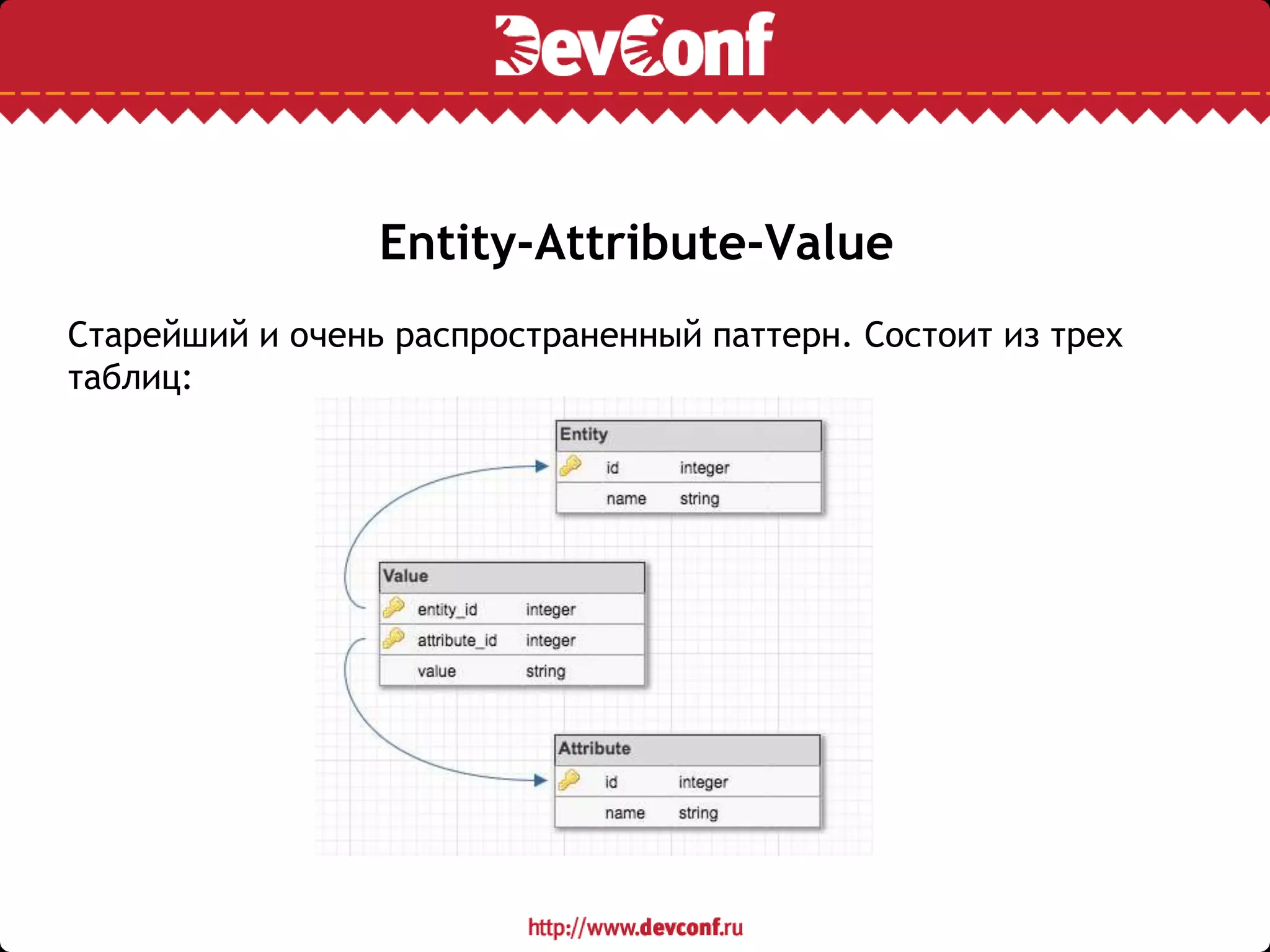







Документ обсуждает интеграцию Django ORM с PostgreSQL, подчеркивая важные моменты для разработчиков, такие как управление схемой данных и ограничения. В нем рассматриваются проблемы, возникающие при миграции схем, а также способы оптимизации запросов и манипуляций с данными для повышения производительности. Также поднимаются вопросы работы с jsonb и EAV, отмечая плюсы и минусы каждого подхода.



































































