Downloaded 315 times









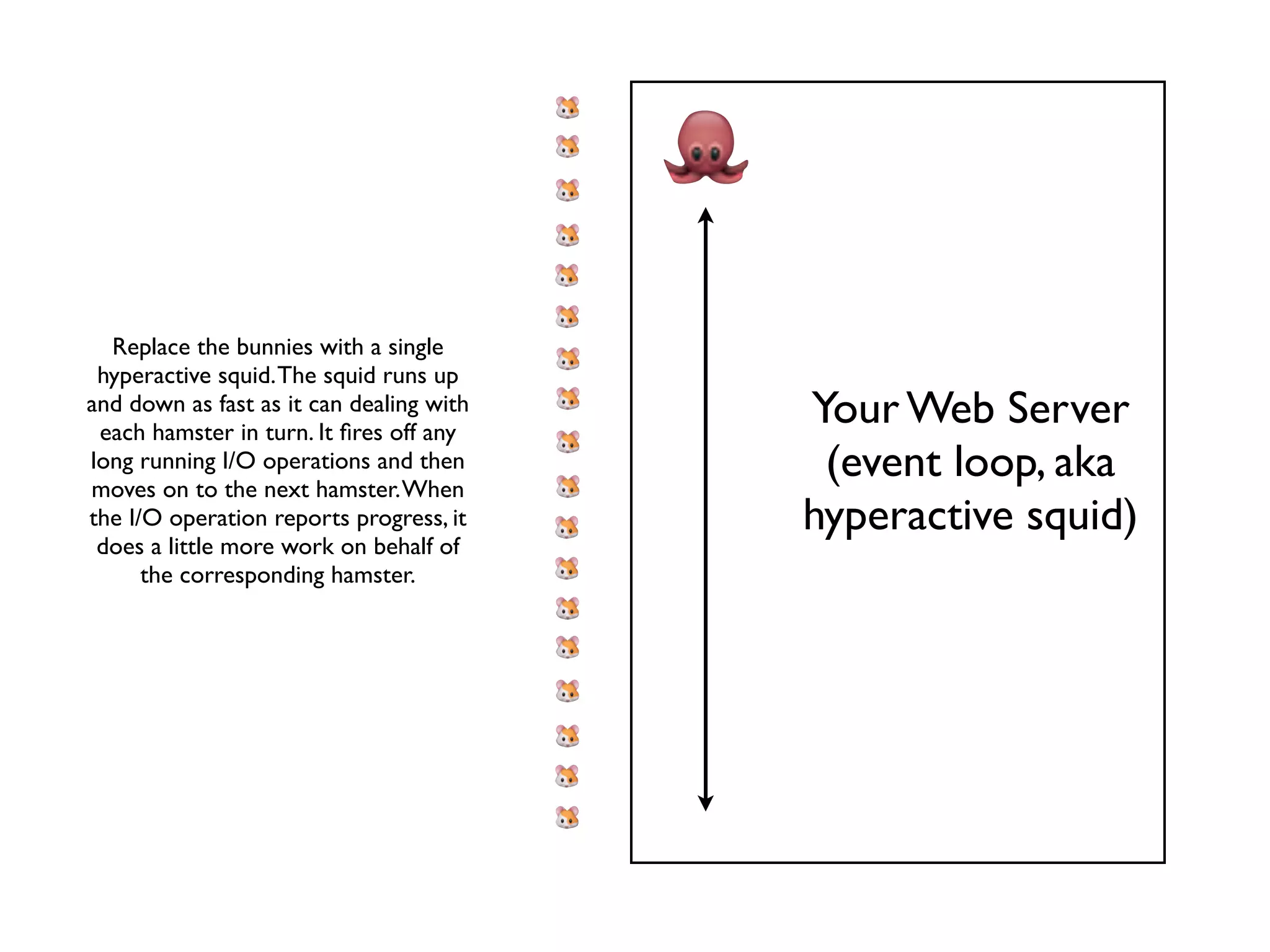



The document discusses evented I/O based web servers, illustrated through a metaphor of bunnies and hamsters handling web requests. It contrasts single-threaded and multi-threaded approaches, highlighting the blocking nature of certain operations and suggesting callback methods for non-blocking code. The use of a hyperactive squid in the metaphor represents an event loop that efficiently manages long-running I/O operations.
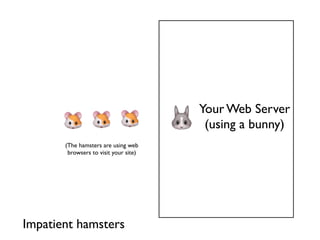
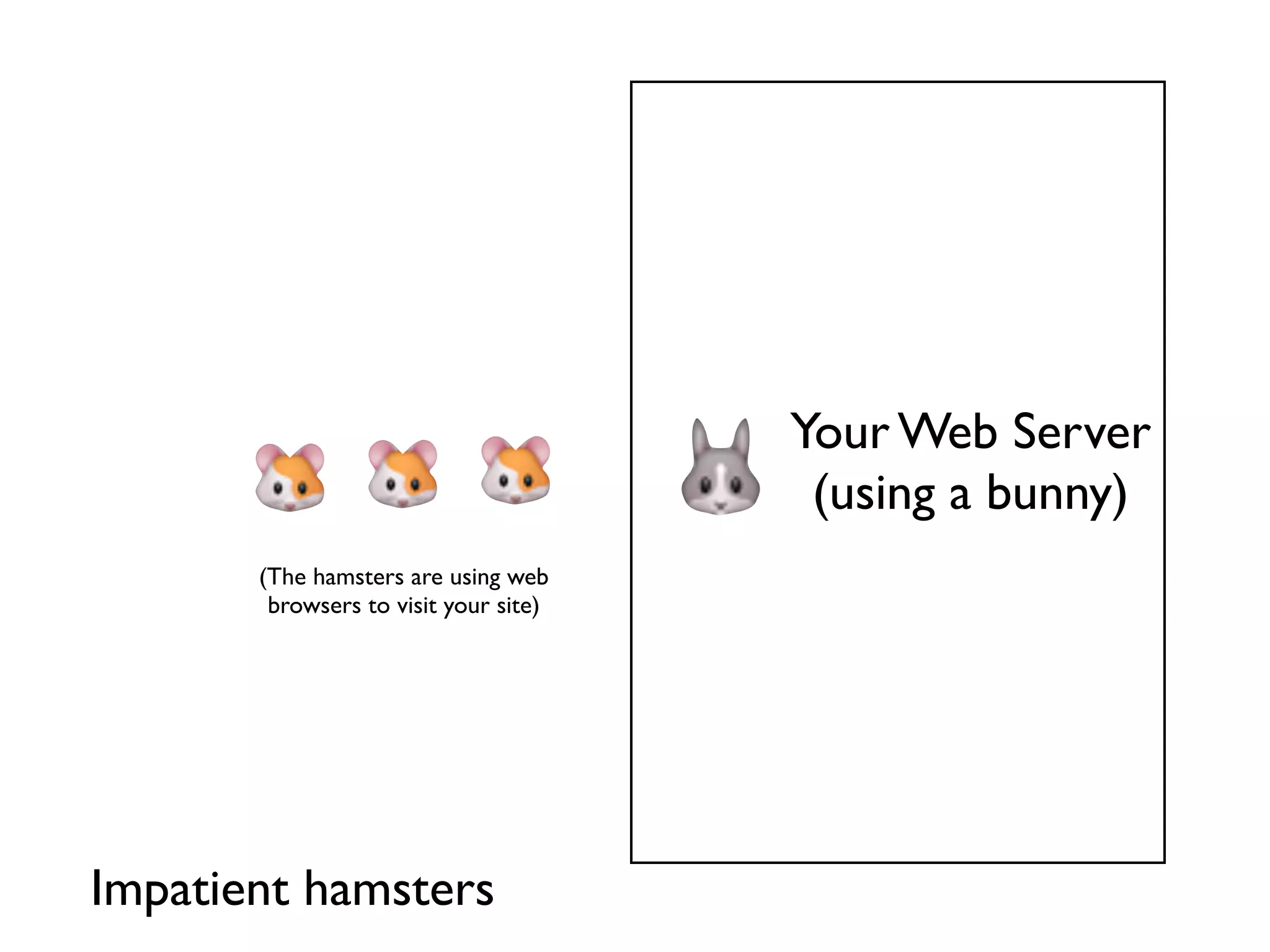
Introduction to event-driven I/O based web servers using bunnies as a metaphor.
Single-threaded server handling one request at a time, represented by a bunny with hamster users.
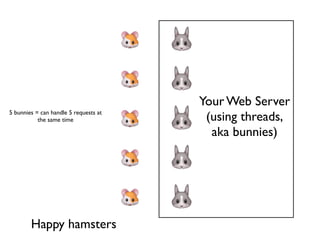
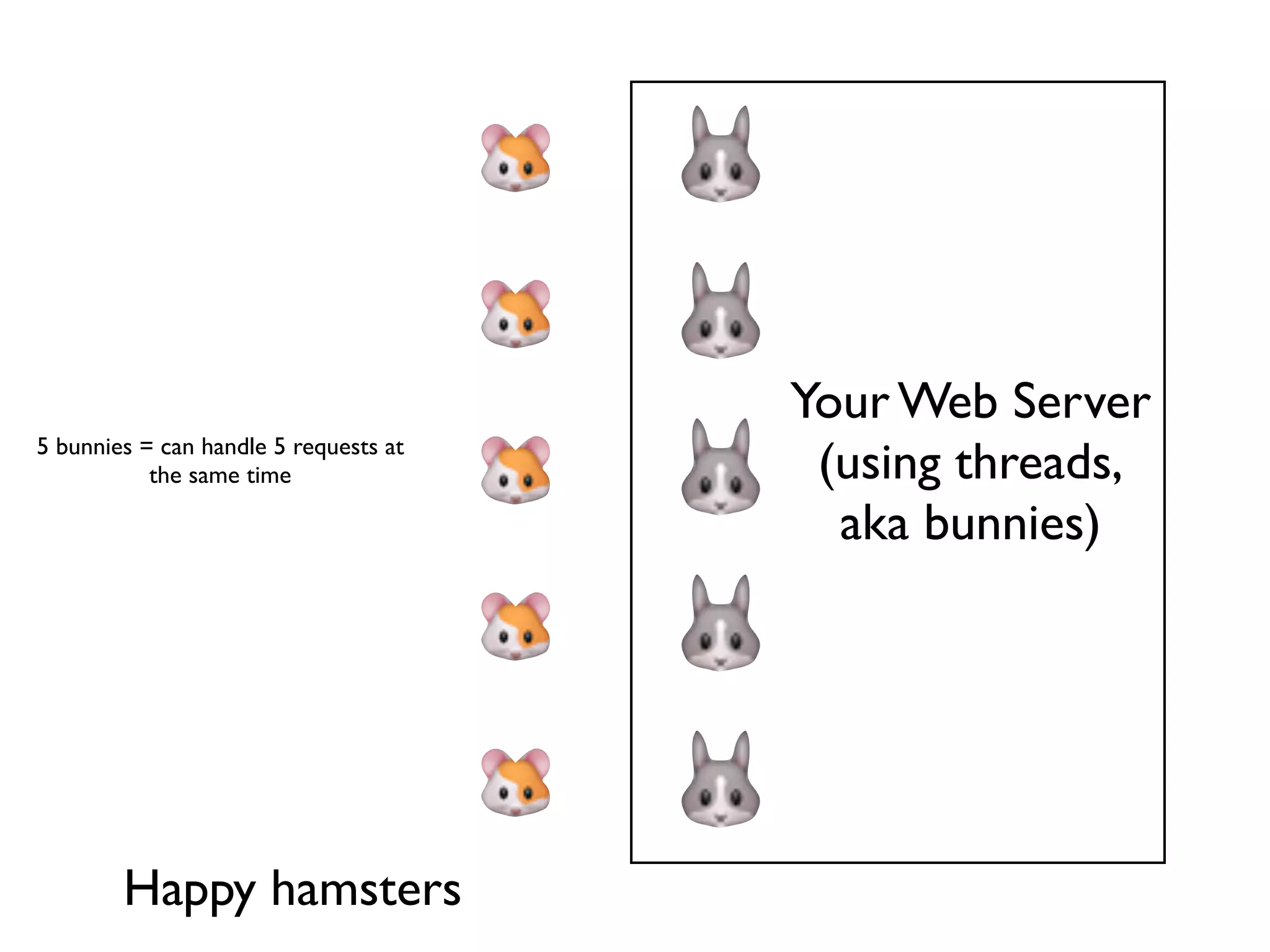
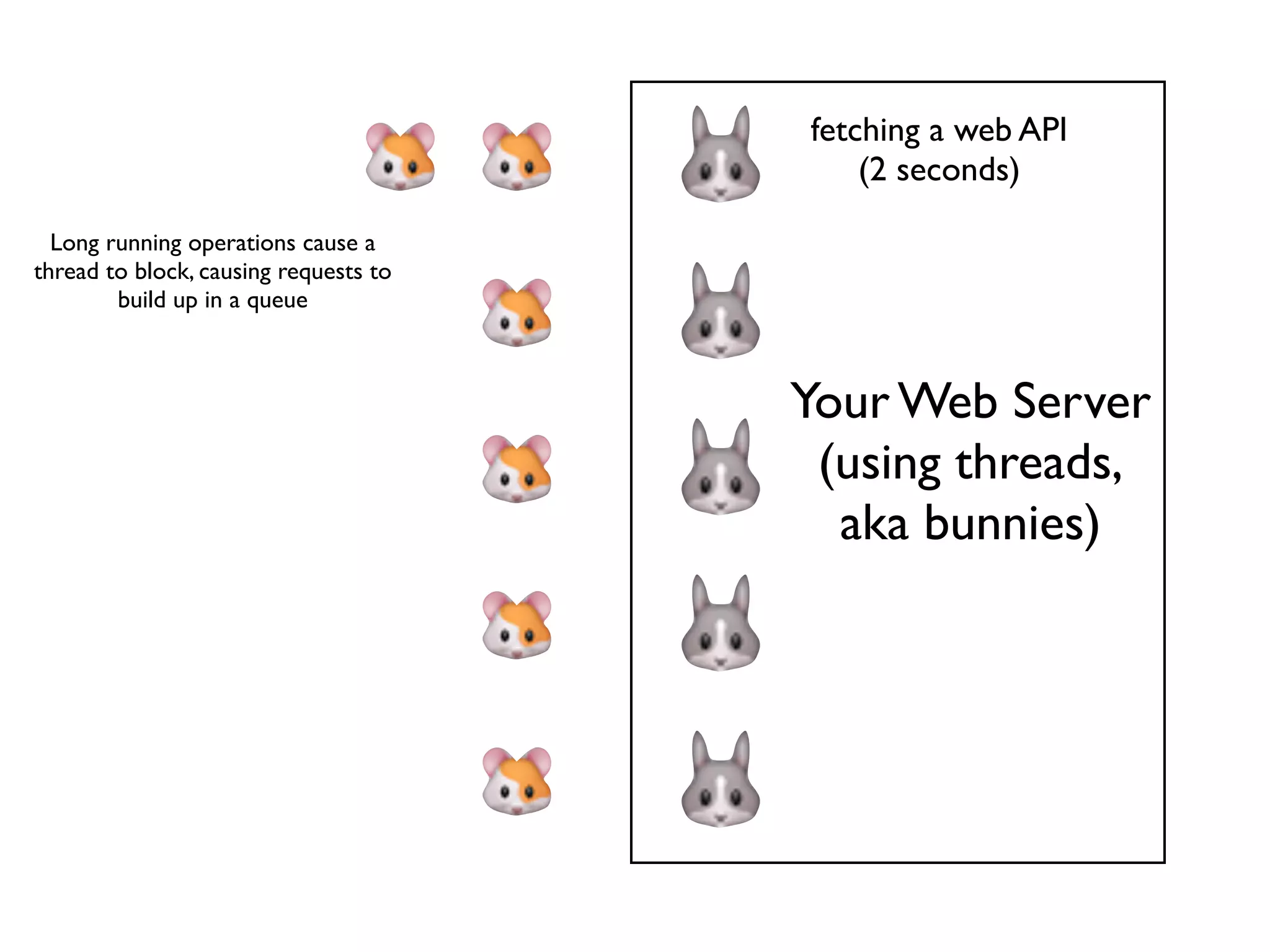
Using multiple threads (bunnies) to manage multiple requests simultaneously, but highlighting blocking issues with I/O.
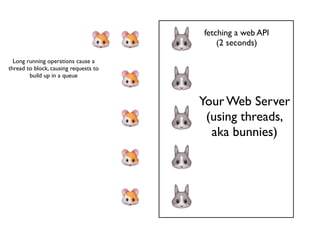
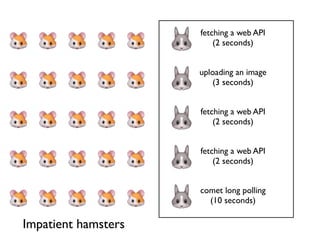
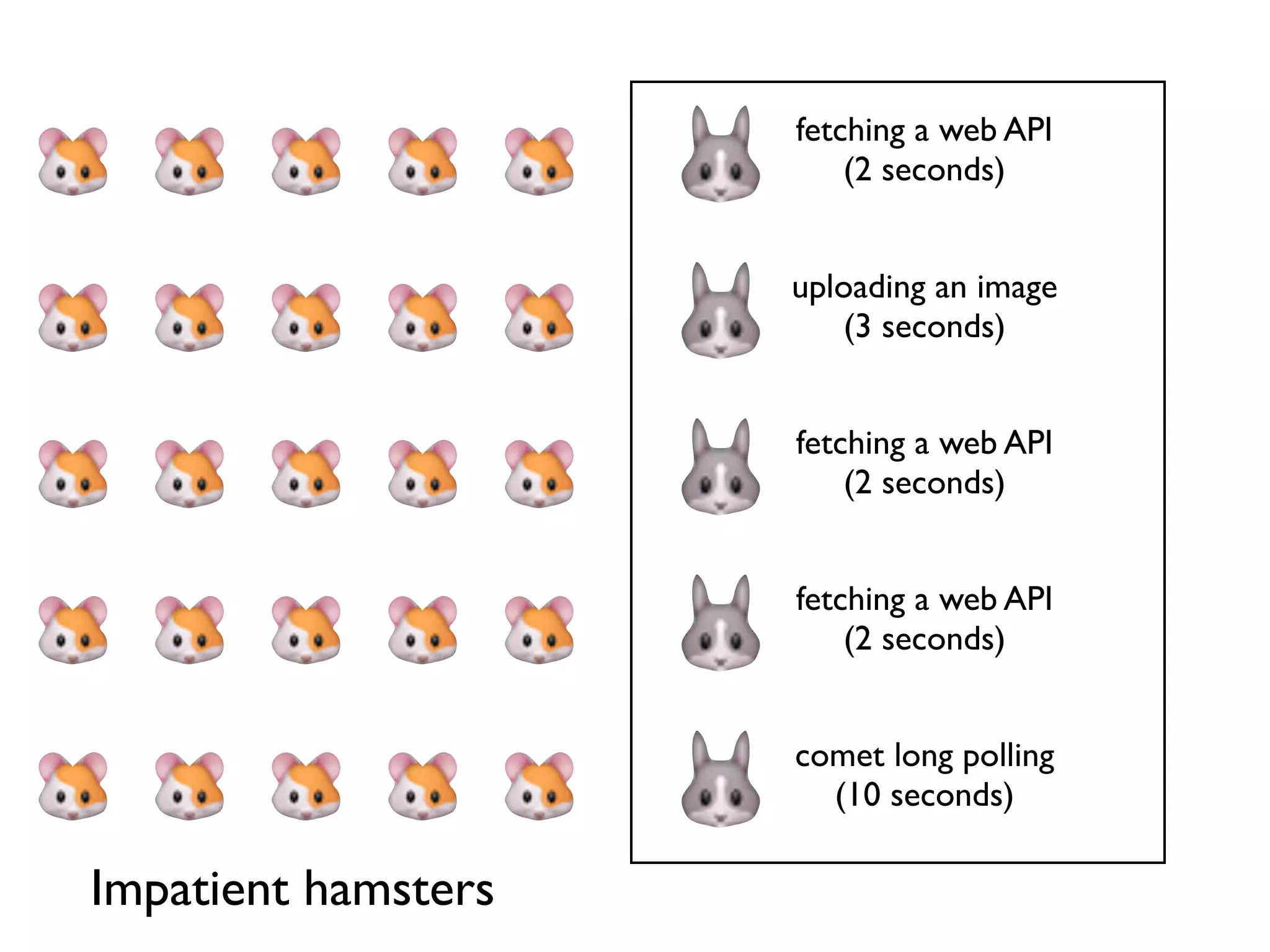
Demonstration of multiple long-running operations causing request queuing, emphasizing the impatience of hamsters.
Transition to an event loop model using a squid to handle requests asynchronously without blocking.
Illustration of bad code that blocks the event loop, causing delays in processing requests.
Illustration of good non-blocking code using callbacks to maintain responsiveness in the event loop.









































































































