KEMBAR78
Daftar
Login
Apache Hadoopを改めて知る | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
日本ヒューレット・パッカード株式会社
PDF, PPTX
442 views
Apache Hadoopを改めて知る
Get to know Apache Hadoop. Why can US companies quickly decide to deploy big data infrastructure?
Data & Analytics
◦
Related topics:
Data Center Overview
•
Read more
0
Save
Share
Embed
Download
Download as PDF, PPTX
1
/ 48
2
/ 48
3
/ 48
4
/ 48
5
/ 48
6
/ 48
7
/ 48
8
/ 48
9
/ 48
10
/ 48
11
/ 48
12
/ 48
13
/ 48
14
/ 48
15
/ 48
16
/ 48
17
/ 48
18
/ 48
19
/ 48
20
/ 48
21
/ 48
22
/ 48
23
/ 48
24
/ 48
25
/ 48
26
/ 48
27
/ 48
28
/ 48
29
/ 48
30
/ 48
31
/ 48
32
/ 48
33
/ 48
34
/ 48
35
/ 48
36
/ 48
37
/ 48
38
/ 48
39
/ 48
40
/ 48
41
/ 48
42
/ 48
43
/ 48
44
/ 48
45
/ 48
46
/ 48
47
/ 48
48
/ 48
More Related Content
PDF
コンテナーによるIT基盤変革 - IT infrastructure transformation -
by
日本ヒューレット・パッカード株式会社
PDF
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
PDF
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
PDF
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
PDF
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
PDF
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
PDF
Hadoop基盤を知る
by
日本ヒューレット・パッカード株式会社
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
コンテナーによるIT基盤変革 - IT infrastructure transformation -
by
日本ヒューレット・パッカード株式会社
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
Hadoop基盤を知る
by
日本ヒューレット・パッカード株式会社
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
What's hot
PDF
HPE×SUSE協業ソリューション
by
日本ヒューレット・パッカード株式会社
PDF
Hadoopを用いた大規模ログ解析
by
shuichi iida
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PPTX
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
PDF
CDH4.1オーバービュー
by
Cloudera Japan
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PDF
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
by
YusukeKuramata
PDF
[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...
by
Insight Technology, Inc.
PPTX
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PPTX
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
PDF
[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...
by
Insight Technology, Inc.
PPTX
Hadoop -ResourceManager HAの仕組み-
by
Yuki Gonda
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
[Postgre sql9.4新機能]レプリケーション・スロットの活用
by
Kosuke Kida
HPE×SUSE協業ソリューション
by
日本ヒューレット・パッカード株式会社
Hadoopを用いた大規模ログ解析
by
shuichi iida
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
CDH4.1オーバービュー
by
Cloudera Japan
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
by
YusukeKuramata
[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏
by
Insight Technology, Inc.
[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...
by
Insight Technology, Inc.
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...
by
Insight Technology, Inc.
Hadoop -ResourceManager HAの仕組み-
by
Yuki Gonda
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
[Postgre sql9.4新機能]レプリケーション・スロットの活用
by
Kosuke Kida
Similar to Apache Hadoopを改めて知る
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PDF
第1回Hadoop関西勉強会参加レポート
by
You&I
PPTX
お見合いで趣味を聞かれたときに 「IoTとビッグデータを少々」と答えたいSEが読む資料
by
Monta Yashi
PDF
Hadoop operation chaper 4
by
Yukinori Suda
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
PPT
Hadoop~Yahoo!Japanの活用について
by
kaminashi
PDF
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
by
The Hive
PDF
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
by
Akira Shimosako
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PPT
Hadoopの紹介
by
bigt23
PDF
Hadoopの概念と基本的知識
by
Ken SASAKI
PDF
ヤフーにおけるHadoop Operations #tdtech
by
Yahoo!デベロッパーネットワーク
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
第1回Hadoop関西勉強会参加レポート
by
You&I
お見合いで趣味を聞かれたときに 「IoTとビッグデータを少々」と答えたいSEが読む資料
by
Monta Yashi
Hadoop operation chaper 4
by
Yukinori Suda
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
Hadoop~Yahoo!Japanの活用について
by
kaminashi
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
by
The Hive
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
by
Akira Shimosako
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
Hadoopの紹介
by
bigt23
Hadoopの概念と基本的知識
by
Ken SASAKI
ヤフーにおけるHadoop Operations #tdtech
by
Yahoo!デベロッパーネットワーク
Apache Hadoopを改めて知る
1.
1 Apache Hadoopを改めて知る ~ なぜ、米国企業は、ビッグデータ分析にいち早く取り掛かれたのか
~ 日本ヒューレットパッカード株式会社 HPE認定オープンソース・Linuxテクノロジーエバンジェリスト/Hadoop(CCAH)認定技術者 古賀政純 @masazumi_koga 2020年10月 1 Hadoopクラスター構築実践ガイド著者が語る
2.
2 古賀政純の実践ガイドシリーズ 最先端オープンソース書籍出版の取り組み コンテナや OSSの 自動配備 IT資源管理 の自動化 クラウド 構築手順 ステップバ イステップで 徹底解説 OS部門1位 AmazonJP ランキング OS部門1位 AmazonJP 新着 ランキング OS部門2位 AmazonJP ランキング 機械学習 ビッグデータ 基盤構築 具体例満載 AmazonJP 新着 ランキング OS部門2位 2
3.
3 •HPEグローバルでHadoop/AI基盤の情報交換 •市場動向等をタイムリーにお届け 古賀政純の「ビッグデータ・AI最前線」シリーズ HPEにおけるビッグデータ・AI on HPE
Apollo情報提供の取り組み Hadoop認定技術者 MapRイベント登壇 CIO/IT部門長向け 満員御礼! Clouderaイベント登壇 最新情報提供 満員御礼! 日経記事登場 最先端AI/GPU コンピューティング 人工知能学会 登壇 人工知能学会登壇 2020年6月10日12:30‐13:20 ビッグデータ・AI・HPCコンテナ
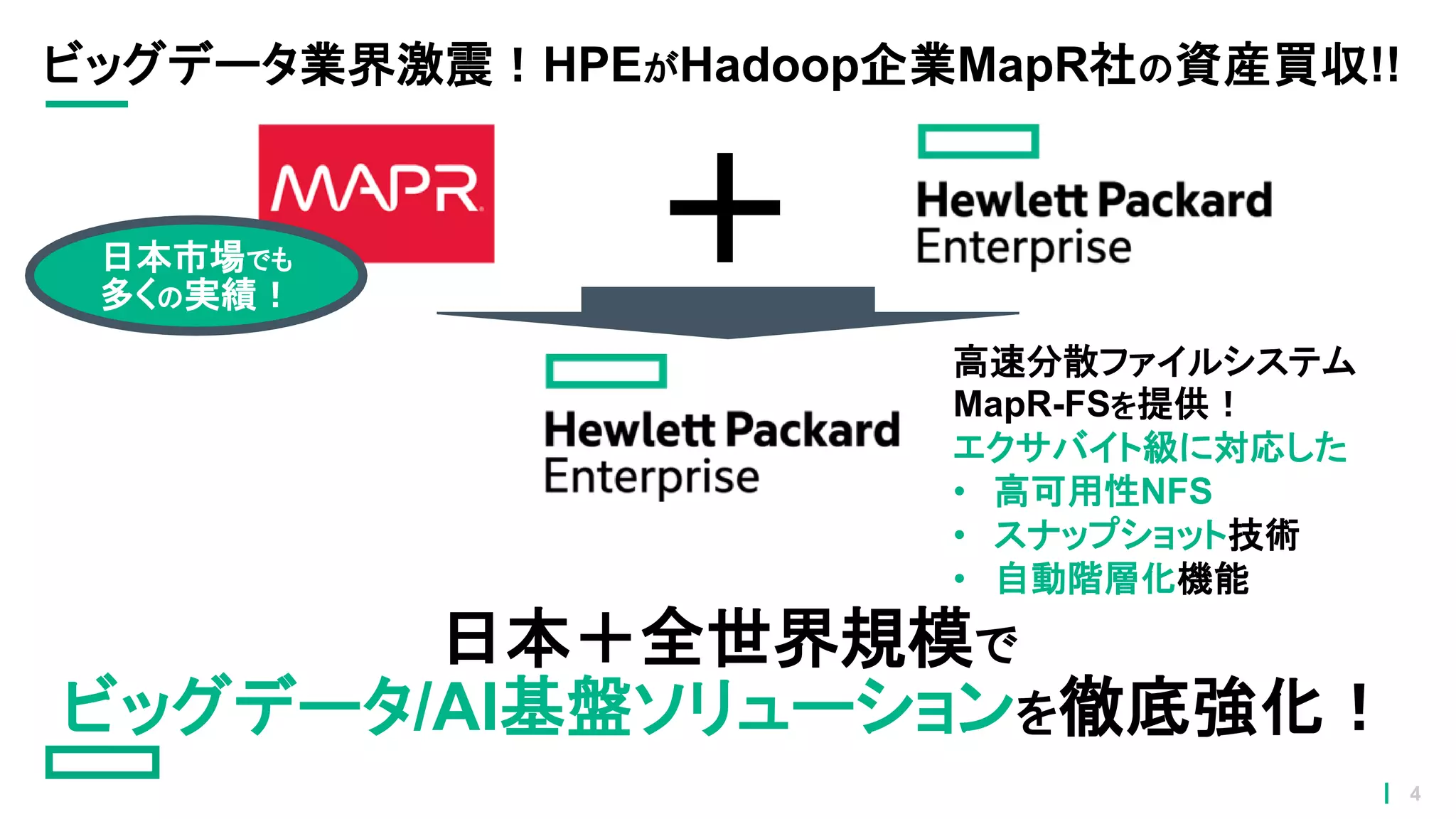
4.
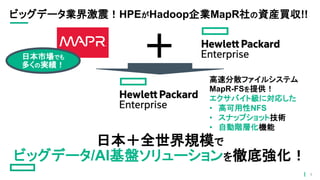
ビッグデータ業界激震!HPEがHadoop企業MapR社の資産買収!! +日本市場でも 多くの実績! 日本+全世界規模で ビッグデータ/AI基盤ソリューションを徹底強化! 高速分散ファイルシステム MapR-FSを提供! エクサバイト級に対応した • 高可用性NFS • スナップショット技術 •
自動階層化機能 4
5.
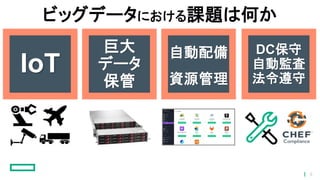
ビッグデータにおける課題は何か 自動配備 資源管理 巨大 データ 保管 DC保守 自動監査 法令遵守 IoT 5
6.
ビッグデータにおけるITの課題と解決策 大切なデータがどんどん増える コンピューター増設で容量拡大
データから知見を得たい 映像 文書 IoT 会話 記録 Hadoop 分散ストレージ 6
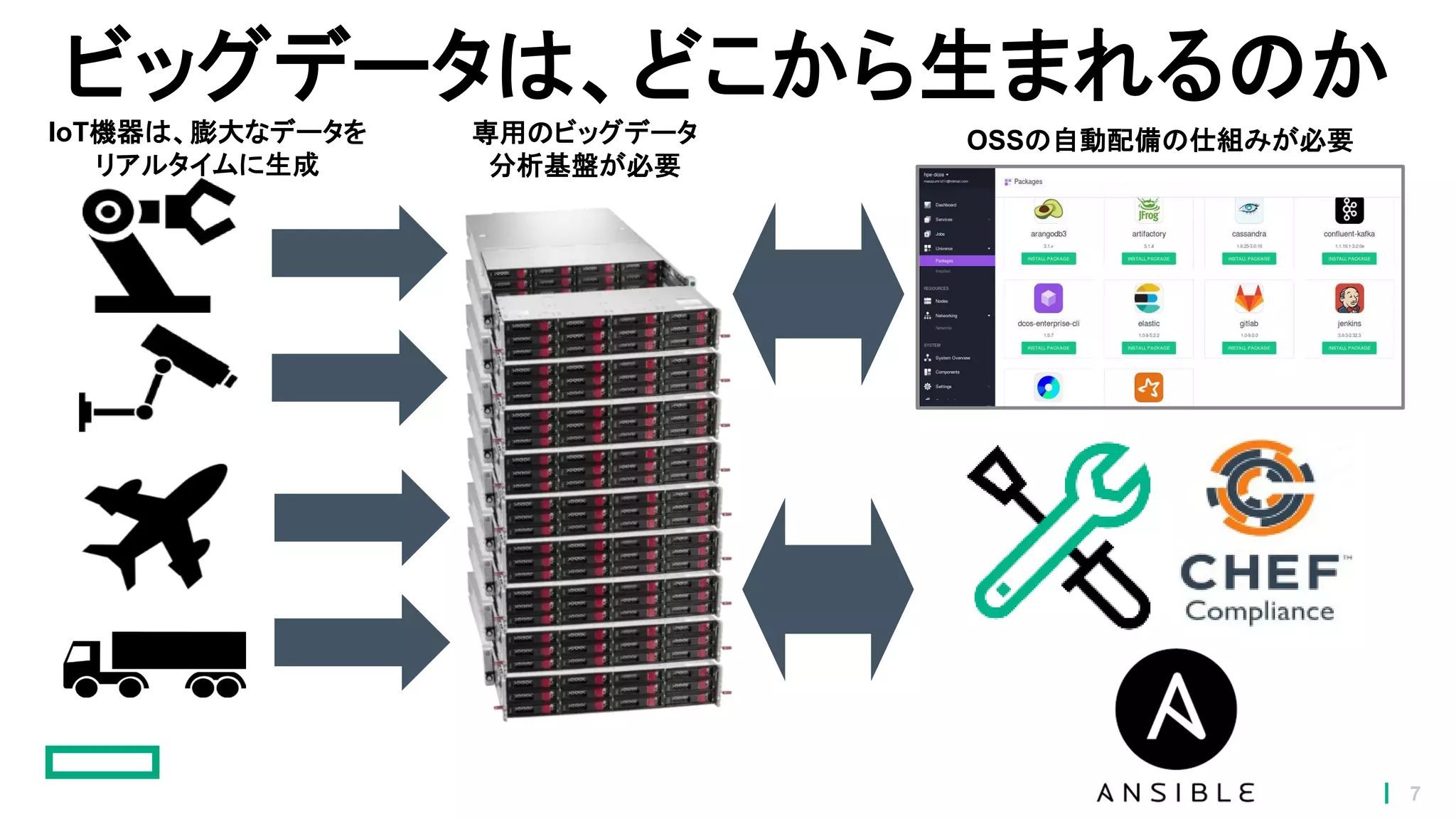
7.
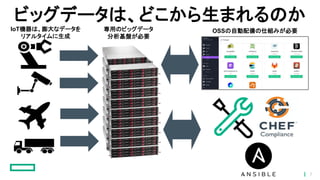
ビッグデータは、どこから生まれるのか IoT機器は、膨大なデータを リアルタイムに生成 専用のビッグデータ 分析基盤が必要 OSSの自動配備の仕組みが必要 7
8.
AI時代: データ処理のニーズが変化 定型処理 非定型処理 •
人間が介在しない完全な自動化が可能 • 厳密さが求められる • トランザクション管理 • データ量は多くてもGbytesオーダー • 給与計算、売上集計、伝票処理など • 人間の介在が必要 • 厳密さよりカバレッジ重視(データ量が重要) • データ量:ペタバイト級、エクサバイト級へ • スケールアウトによる性能向上 • 統計データ作成、検索、データ・マイニングなど RDBMSが得意とする領域 RDBMSが苦手とする領域 従来の定型処理に加え、非定形処理が必要不可欠になってきた! 8
9.
RDBMS Hadoop • トランザクション処理 •
インデックス検索 • リアルタイム処理 • 定型処理 • スケールアウトによる性能向上 • バッチ処理 • 非定型処理 Hadoop適用範囲:RDBMS比較 得 意 不 得 意 • スケールアウトによる性能向上 • リアルタイム処理 • データ更新処理 相互に補完! 9
10.
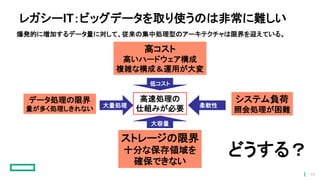
レガシーIT:ビッグデータを取り使うのは非常に難しい 爆発的に増加するデータ量に対して、従来の集中処理型のアーキテクチャは限界を迎えている。 データ処理の限界 量が多く処理しきれない システム負荷 照会処理が困難 大量処理 柔軟性 ストレージの限界 十分な保存領域を 確保できない 低コスト 高コスト 高いハードウェア構成 複雑な構成&運用が大変 高速処理の 仕組みが必要 大容量 どうする? 10
11.
Hadoopとは何か 11
12.
Hadoop開発の歴史的経緯を見ると、何がどう重要かが見えてくる Google FileSystemやMapReduceと呼ばれる分散処理技術を独自に開 発。ソースコードではなく、その仕組みを論文として発表(2004年) 膨大なデータに対する検索処理で課題を抱えていたYahoo Inc.は、著名 なエンジニアであるDoug
Cutting氏を中心に上記論文を元にHadoopを 開発。Apache Hadoopプロジェクトとして公開され、オープンソースソフト ウェアとして開発が進む 米国を中心に利用が進み、Hadoop自体も様々な改良が加えられる Google社は、なぜ ファイルシステムに 着目したのでしょうか? 12
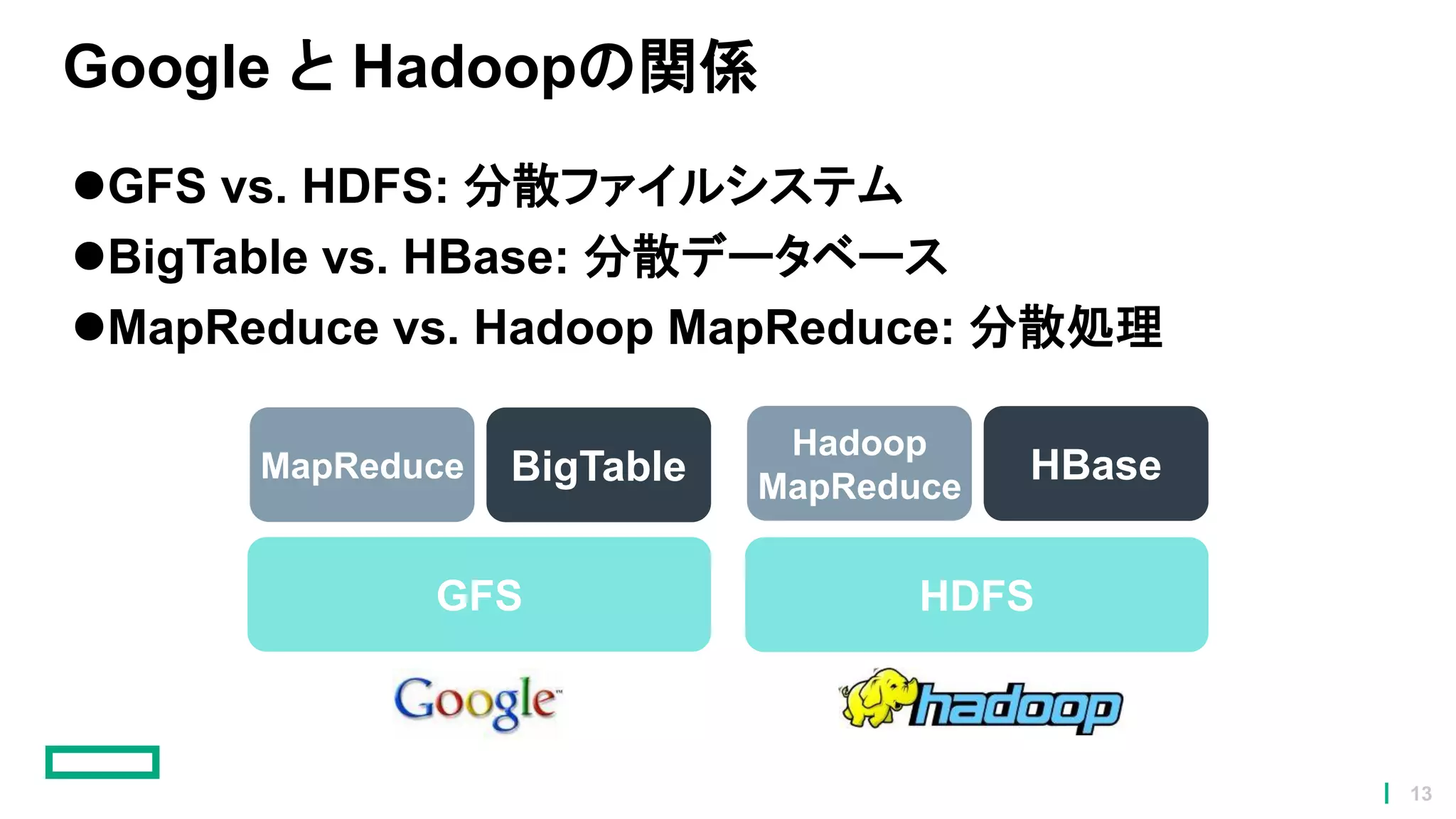
13.
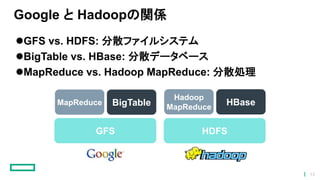
Google と Hadoopの関係 GFS
vs. HDFS: 分散ファイルシステム BigTable vs. HBase: 分散データベース MapReduce vs. Hadoop MapReduce: 分散処理 GFS HDFS MapReduce BigTable Hadoop MapReduce HBase 13
14.
分散並列処理エンジンが何の役に立つのか? –Hadoop: 大規模データ処理のための並列分散処理基盤ソフトウェア –1つの処理を複数のサーバで同時に処理できるプラットホーム –Yahoo!、Facebook、VISA、JP MORGAN、Baidu等 –ログ解析、レコメンデーションエンジン、検索エンジン –データウェアハウス、ビジネスインテリジェンス –2009年時点で1PBのデータソートを約16時間で処理! –
http://sortbenchmark.org 米国の先進企業は、 なぜ、Hadoopを採用 したのでしょうか? まだAIが本格化して いない時代に、彼らは、 なぜ、Hadoopに着目 したのか? 14
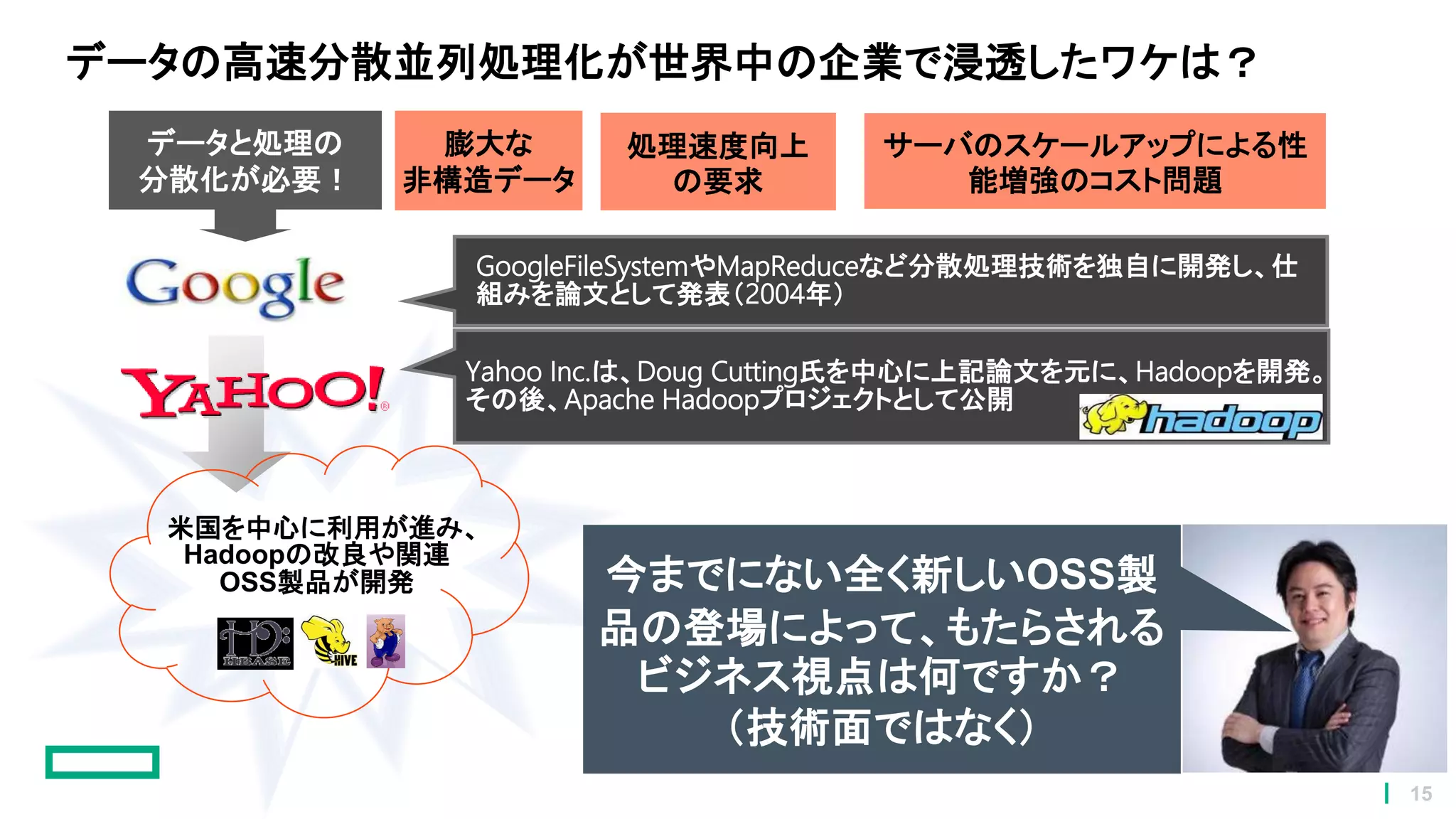
15.
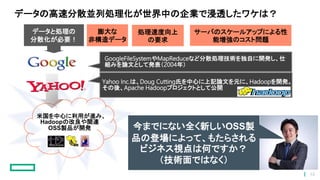
データと処理の 分散化が必要! データの高速分散並列処理化が世界中の企業で浸透したワケは? GoogleFileSystemやMapReduceなど分散処理技術を独自に開発し、仕 組みを論文として発表(2004年) Yahoo Inc.は、Doug Cutting氏を中心に上記論文を元に、Hadoopを開発。 その後、Apache
Hadoopプロジェクトとして公開 米国を中心に利用が進み、 Hadoopの改良や関連 OSS製品が開発 サーバのスケールアップによる性 能増強のコスト問題 膨大な 非構造データ 処理速度向上 の要求 今までにない全く新しいOSS製 品の登場によって、もたらされる ビジネス視点は何ですか? (技術面ではなく) 15
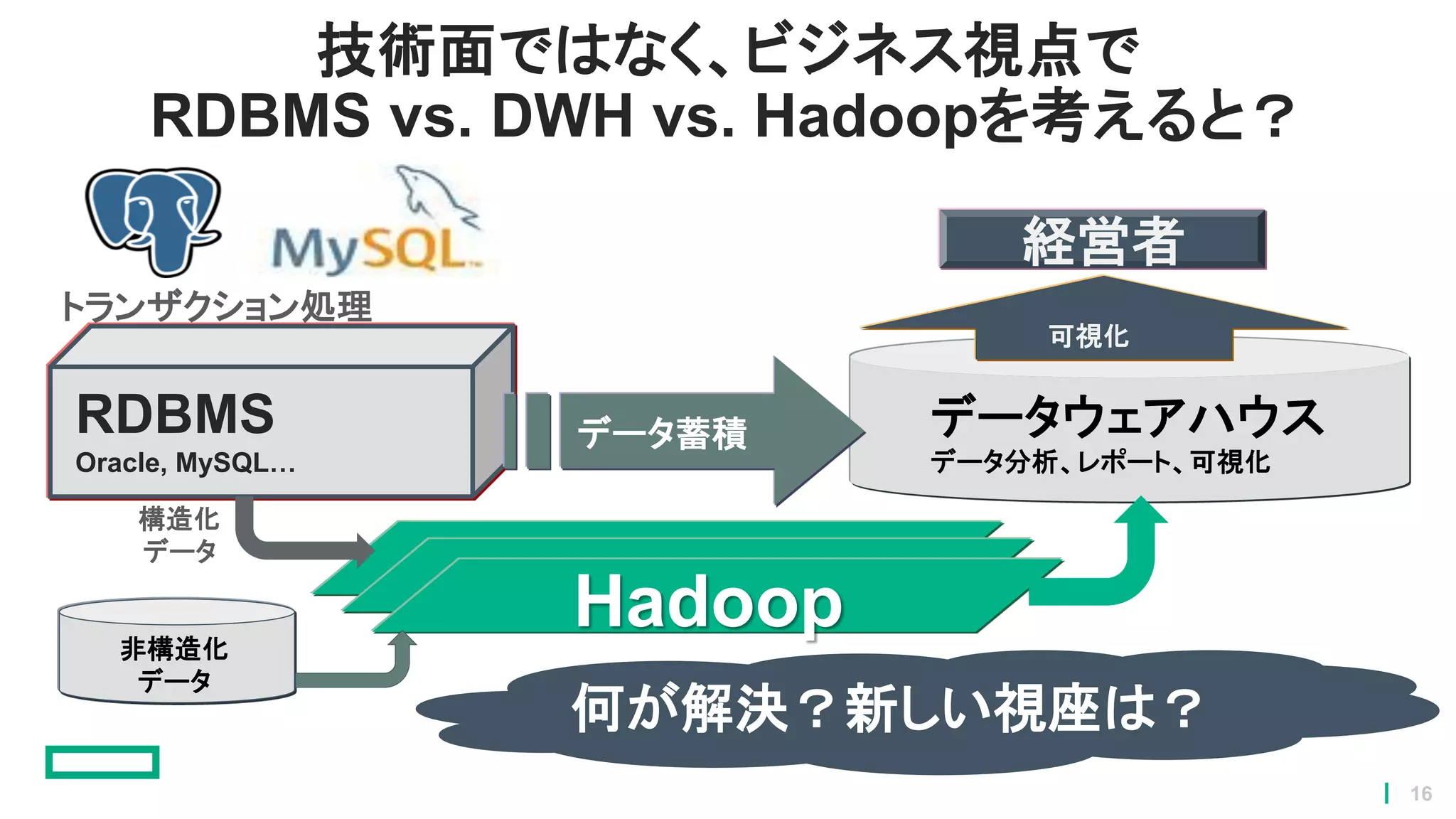
16.
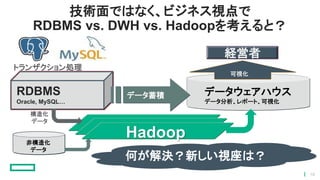
技術面ではなく、ビジネス視点で RDBMS vs. DWH
vs. Hadoopを考えると? RDBMS Oracle, MySQL… データウェアハウス データ分析、レポート、可視化 トランザクション処理 Hadoop 可視化 経営者 データ蓄積 構造化 データ 非構造化 データ 何が解決?新しい視座は? 16
17.
Hadoopの種類 ~ MapR vs.
Apache Hadoop ~ 17
18.
MapR版と vs. Apache
Hadoopベース版 CDHMapR Apache Hadoop ファイルシステム性能の違いは? 18
19.
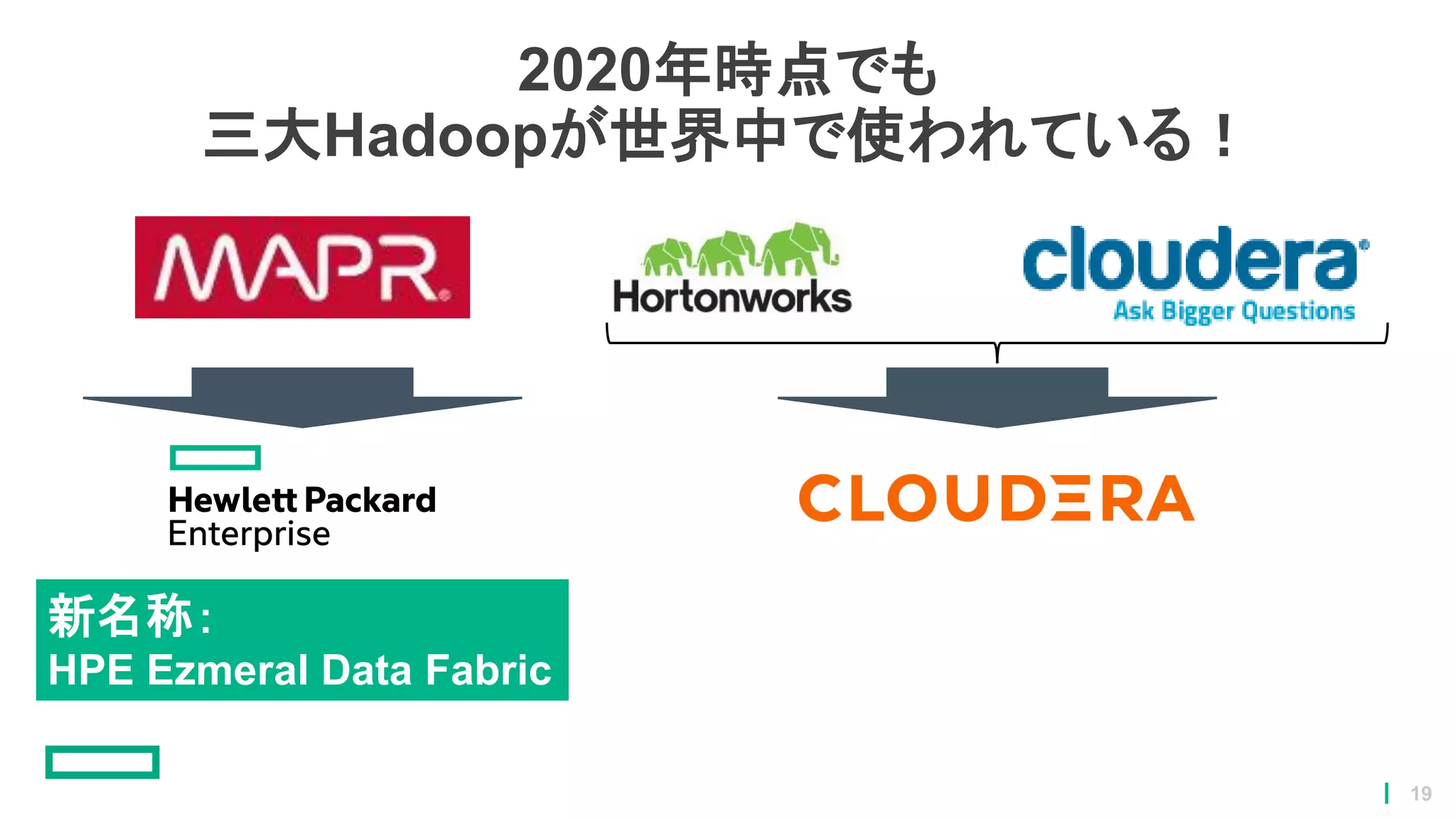
2020年時点でも 三大Hadoopが世界中で使われている! 新名称: HPE Ezmeral Data
Fabric 19
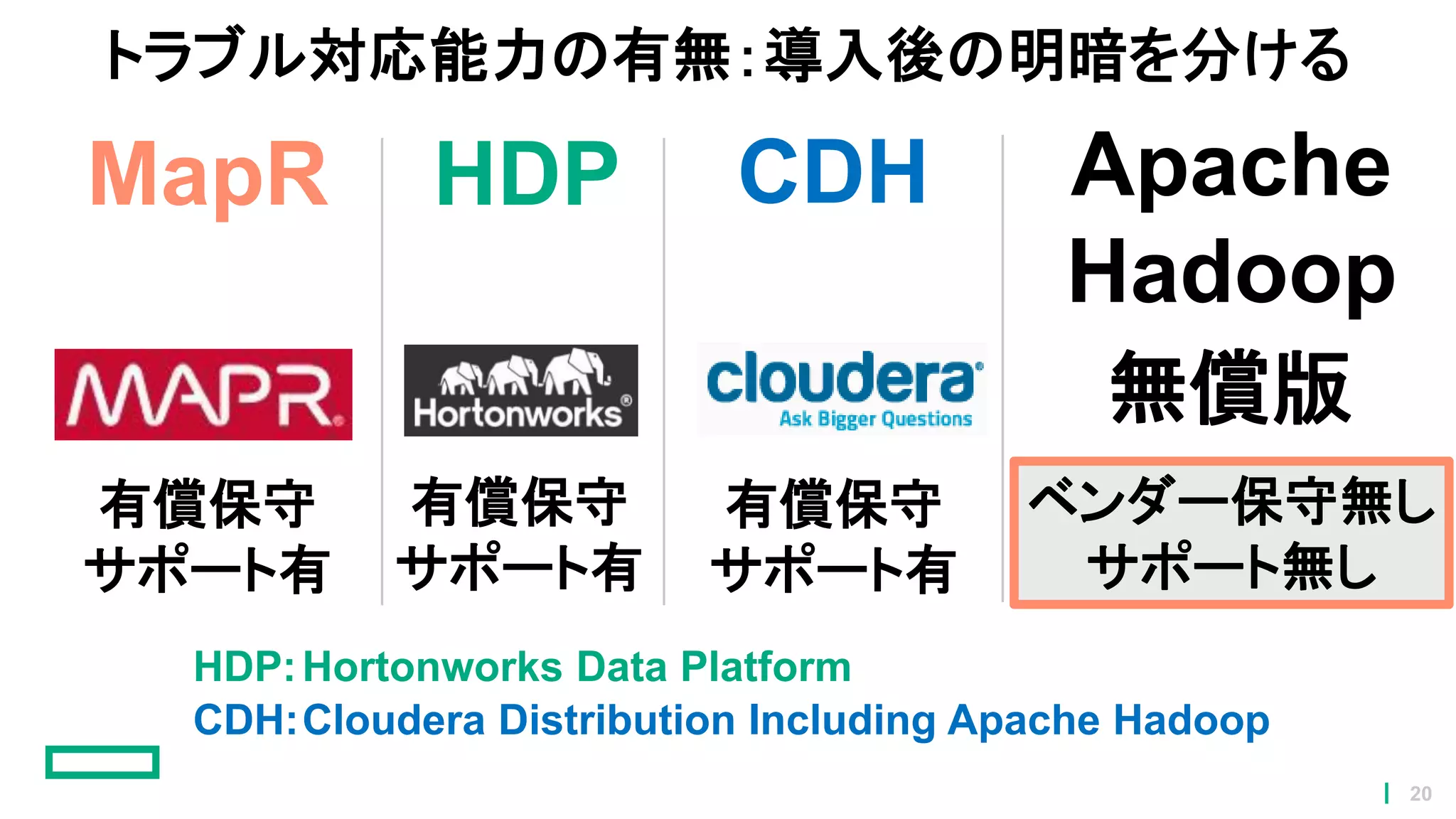
20.
トラブル対応能力の有無:導入後の明暗を分ける Apache Hadoop HDP 有償保守 サポート有 MapR 有償保守 サポート有 CDH 有償保守 サポート有 ベンダー保守無し サポート無し 無償版 CDH:Cloudera Distribution Including
Apache Hadoop HDP:Hortonworks Data Platform 20
21.
なにが違うのか? •Javaで実装 •Cloudera Managerで管理 •マスターノードをHA化 •Hadoopの生みの親が在籍 • エンタープライズ向け •
C/C++で実装(超高速) • MapR Control Systemで管理 • マスターとスレーブの区別なく、 メタデータを分散し、性能がス ケール • 高可用性が前提 • NFSサーバーとしても利用可能 •Javaで実装 •管理ツールAmbari •100%オープンソース •HPE研究所と一緒にインメモリ 処理ソフトSparkに取り組む 複数の現場部門でバラバラに 使われると面倒... 21
22.
22 新ブランドで全世界展開! HPE Ezmeral Data
Fabric (HPE EDF) エズメラルデータファブリック
23.
2020年の米国最新Hadoop事情 すべてコンテナでカンタン配備! HPE Ezmeral Container
Platform 23
24.
Bigdata in 2020 24 HPE
Ezmeral Data Fabric HPE Ezmeral Container Platform – 圧倒的性能のMapR File System継続提供! – OSS集「MapR Ecosystem Pack」継続提供! – MapRプロフェッショナルサービスによるHadoop導入コンサ ル – 米国HPEも認める日本での豊富な導入実績! – 旧BlueData EPICとOSS版Kubernetesを搭載! – 三大HadoopディストリビューションやOSS-DBをコンテナで カンタン配備! – AI環境準備・AIワークフロー管理を徹底的に簡素化する 「ML Ops」 – 複数部門同時利用:マルチテナント対応で共通基盤化!
25.
Hadoopの仕組み 25
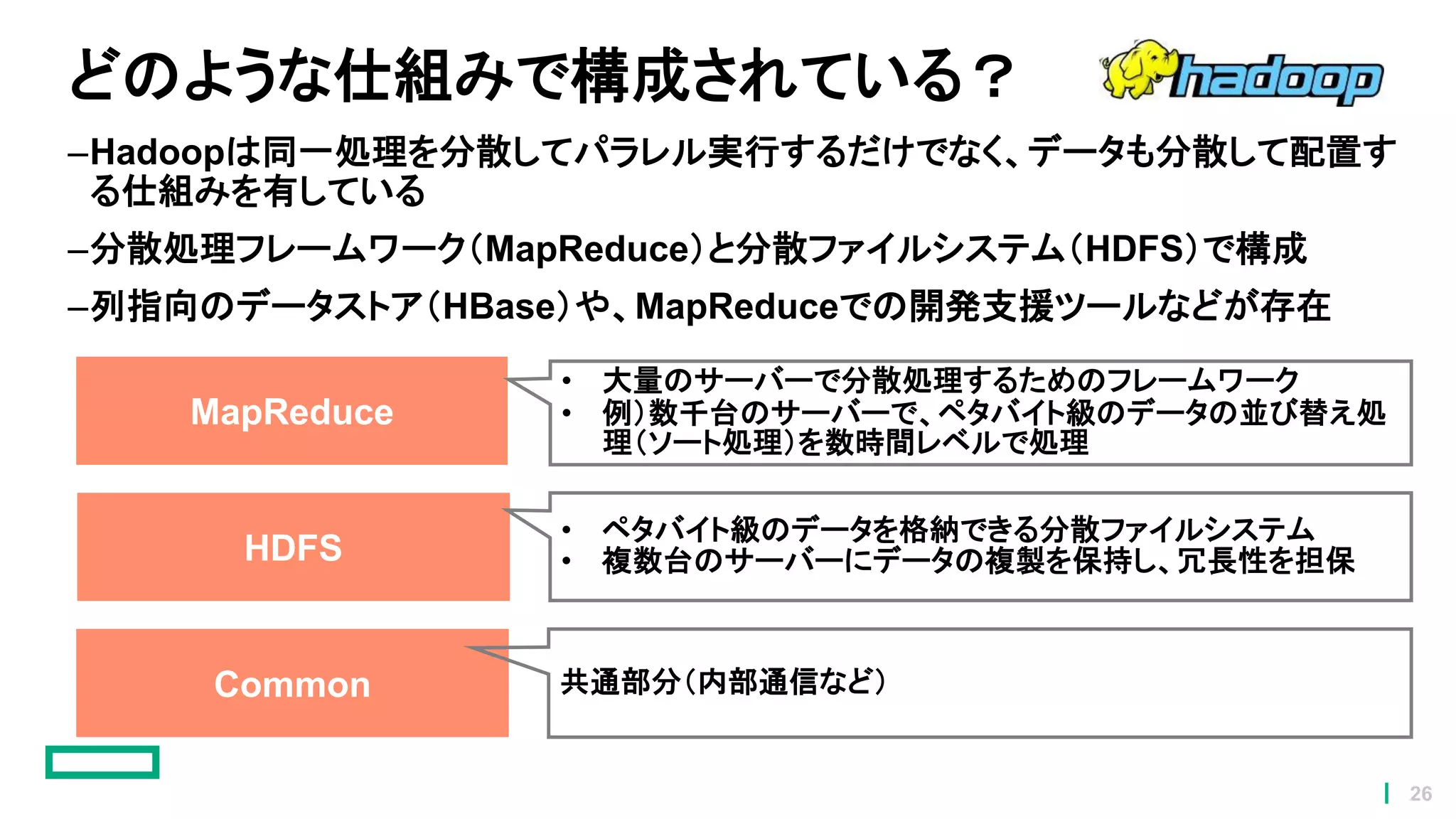
26.
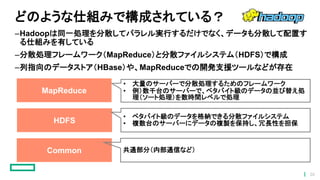
どのような仕組みで構成されている? –Hadoopは同一処理を分散してパラレル実行するだけでなく、データも分散して配置す る仕組みを有している –分散処理フレームワーク(MapReduce)と分散ファイルシステム(HDFS)で構成 –列指向のデータストア(HBase)や、MapReduceでの開発支援ツールなどが存在 HDFS Common MapReduce • 大量のサーバーで分散処理するためのフレームワーク • 例)数千台のサーバーで、ペタバイト級のデータの並び替え処 理(ソート処理)を数時間レベルで処理 共通部分(内部通信など) •
ペタバイト級のデータを格納できる分散ファイルシステム • 複数台のサーバーにデータの複製を保持し、冗長性を担保 26
27.
Hadoopの主な構成要素 –「Hadoop」とは、そもそも分散並列処理の「プロジエクト」 –分散並列処理のエンジンそのもの –システム構成 –Linuxのファイルシステムの上に分散ファイルシステム 「HDFS」が存在 –並列分散処理フレームワーク 「MapReduce」用のアプリをユーザーが書く –エコシステムソフトウェアが充実 –SQLインタフェ-ス
「Hive」 –ETL処理で利用されるスクリプトインタフェース 「Pig」 –巨大なテーブル操作が可能な「HBase」(キーバリューストア) –分散環境のためのアプリケーション管理 「ZooKeeper」 – RDBMSとHadoop間のデータのインポートやエクスポートを行う「Sqoop」等 従来のRDBMSによる分析 基盤と比較して、メリットと デメリットは何でしょうか? 27
28.
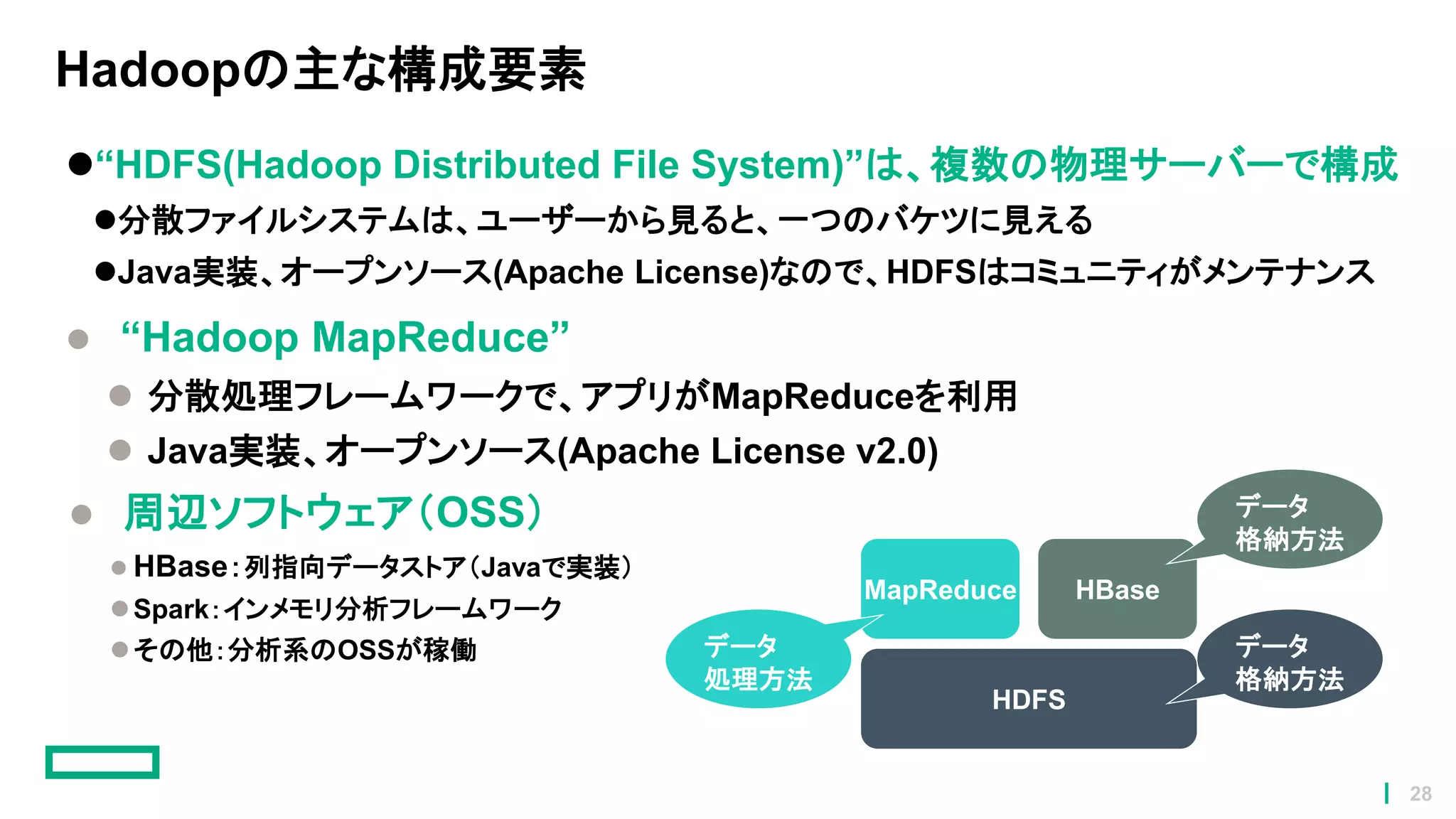
Hadoopの主な構成要素 “HDFS(Hadoop Distributed File
System)”は、複数の物理サーバーで構成 分散ファイルシステムは、ユーザーから見ると、一つのバケツに見える Java実装、オープンソース(Apache License)なので、HDFSはコミュニティがメンテナンス “Hadoop MapReduce” 分散処理フレームワークで、アプリがMapReduceを利用 Java実装、オープンソース(Apache License v2.0) 周辺ソフトウェア(OSS) HBase:列指向データストア(Javaで実装) Spark:インメモリ分析フレームワーク その他:分析系のOSSが稼働 HDFS MapReduce HBase データ 格納方法 データ 処理方法 データ 格納方法 28
29.
Apache HadoopやHBaseの注意点 –HDFSはPOSIXファイルシステムではない –HDFSは、多数の小さなファイルへの低レイテンシアクセス用に設計されていない –Hadoop MapReduceはインタラクティブアプリケーション用に設計されていない –HBaseはリレーショナルデータベースではない –HDFSとHBaseは、セキュリティ、暗号化、マルチテナンシーに重点を置いていない HPE
Ezmeral Data Fabric(旧MapR) は、これらのHadoopやHBaseの欠点を どのように克服しているのでしょうか? 29
30.
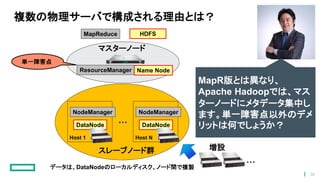
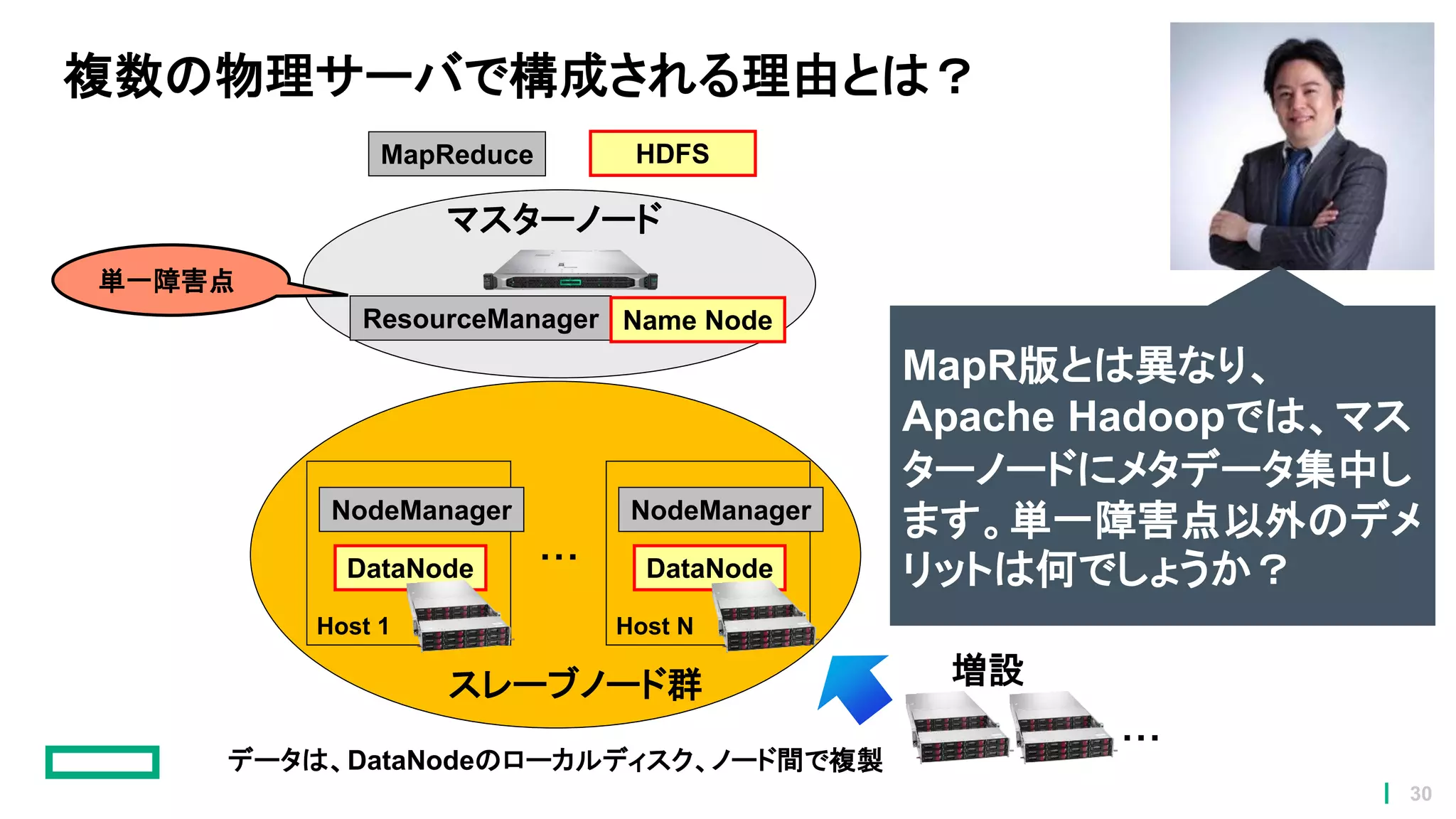
複数の物理サーバで構成される理由とは? マスターノード ResourceManager Name Node NodeManager DataNode Host
1 スレーブノード群 NodeManager DataNode Host N ・・・ 増設 HDFSMapReduce データは、DataNodeのローカルディスク、ノード間で複製 単一障害点 MapR版とは異なり、 Apache Hadoopでは、マス ターノードにメタデータ集中し ます。単一障害点以外のデメ リットは何でしょうか? ・・・ 30
31.
Hadoop導入イメージを掴む 31
32.
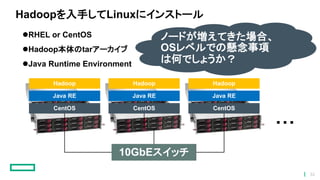
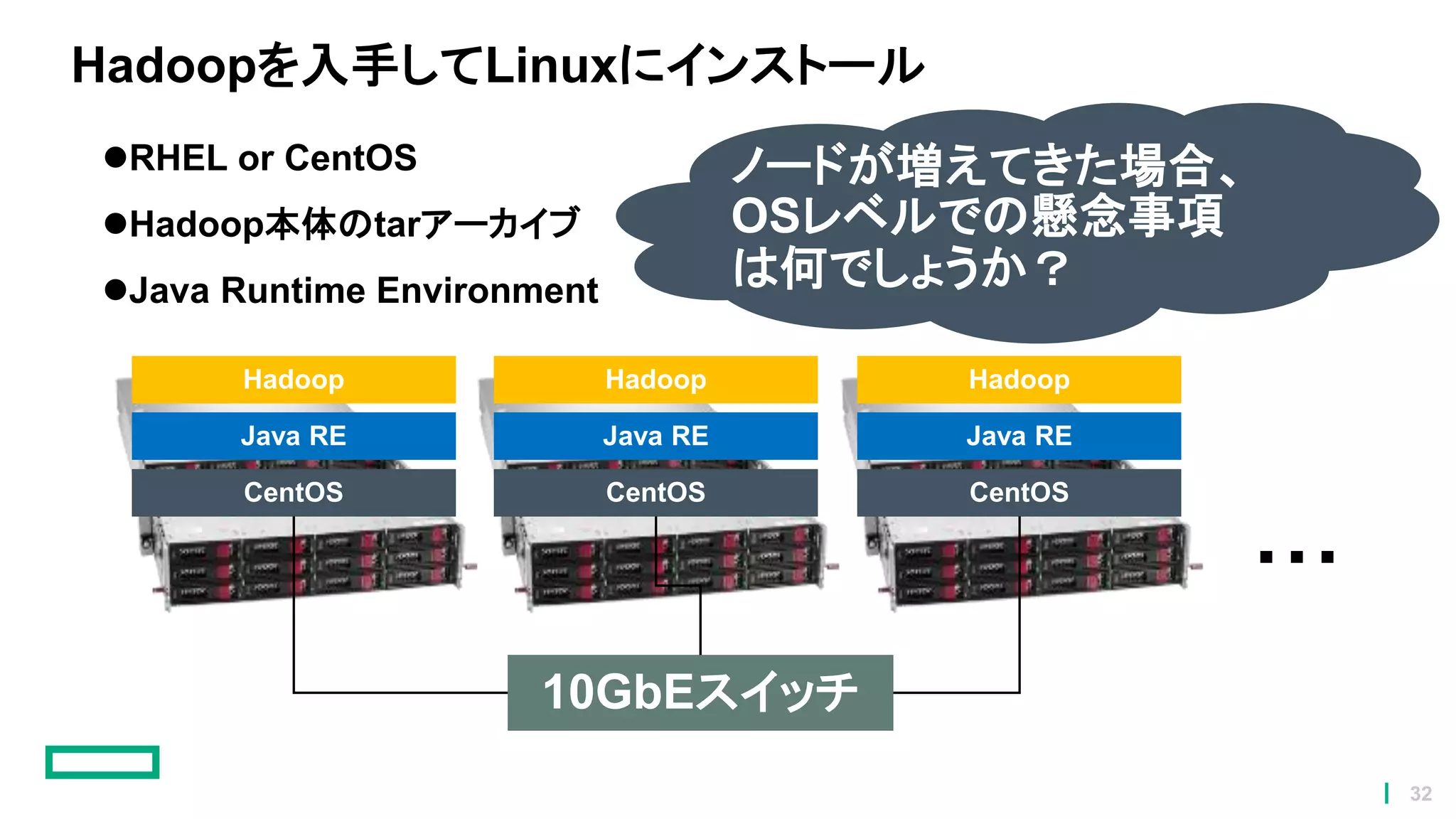
Hadoopを入手してLinuxにインストール RHEL or CentOS Hadoop本体のtarアーカイブ Java
Runtime Environment CentOS Java RE Hadoop CentOS Java RE Hadoop CentOS Java RE Hadoop ・・・ 10GbEスイッチ ノードが増えてきた場合、 OSレベルでの懸念事項 は何でしょうか? 32
33.
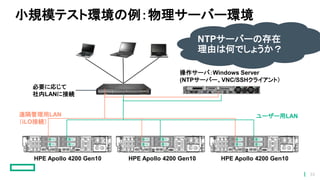
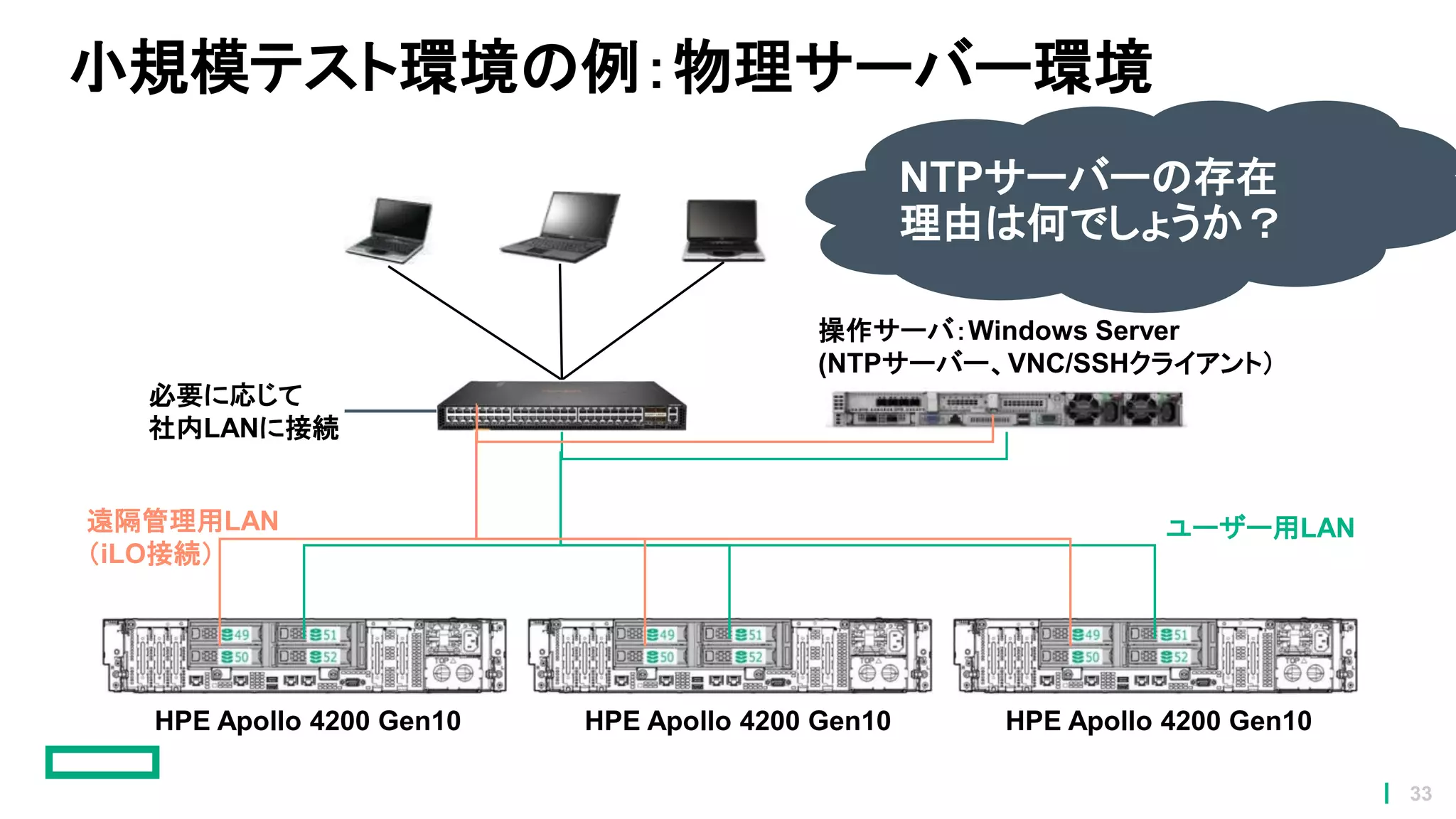
小規模テスト環境の例:物理サーバー環境 必要に応じて 社内LANに接続 操作サーバ:Windows Server (NTPサーバー、VNC/SSHクライアント) HPE Apollo
4200 Gen10 HPE Apollo 4200 Gen10 HPE Apollo 4200 Gen10 ユーザー用LAN遠隔管理用LAN (iLO接続) NTPサーバーの存在 理由は何でしょうか? 33
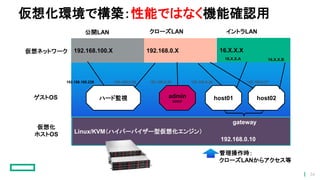
34.
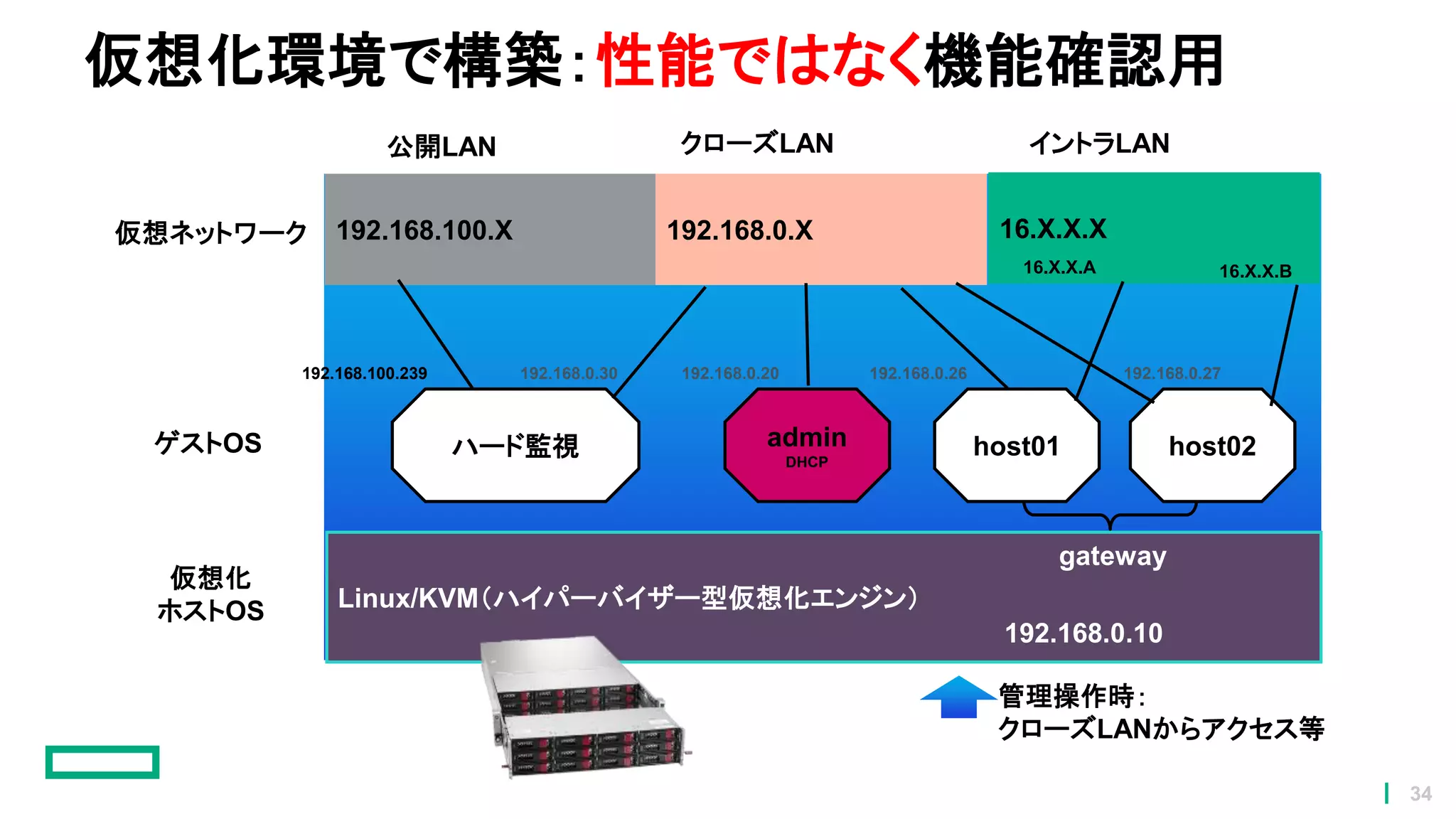
仮想化環境で構築:性能ではなく機能確認用 管理操作時: クローズLANからアクセス等 Linux/KVM(ハイパーバイザー型仮想化エンジン) 192.168.100.X 16.X.X.X192.168.0.X ハード監視 admin DHCP host01
host02 192.168.0.10 ゲストOS 仮想ネットワーク 仮想化 ホストOS 公開LAN クローズLAN イントラLAN 192.168.0.30 192.168.0.20192.168.100.239 16.X.X.A 16.X.X.B 192.168.0.26 192.168.0.27 gateway 34
35.
Hadoop導入の課題 35
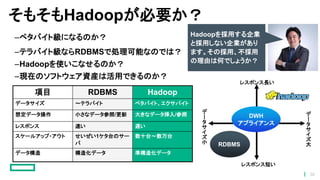
36.
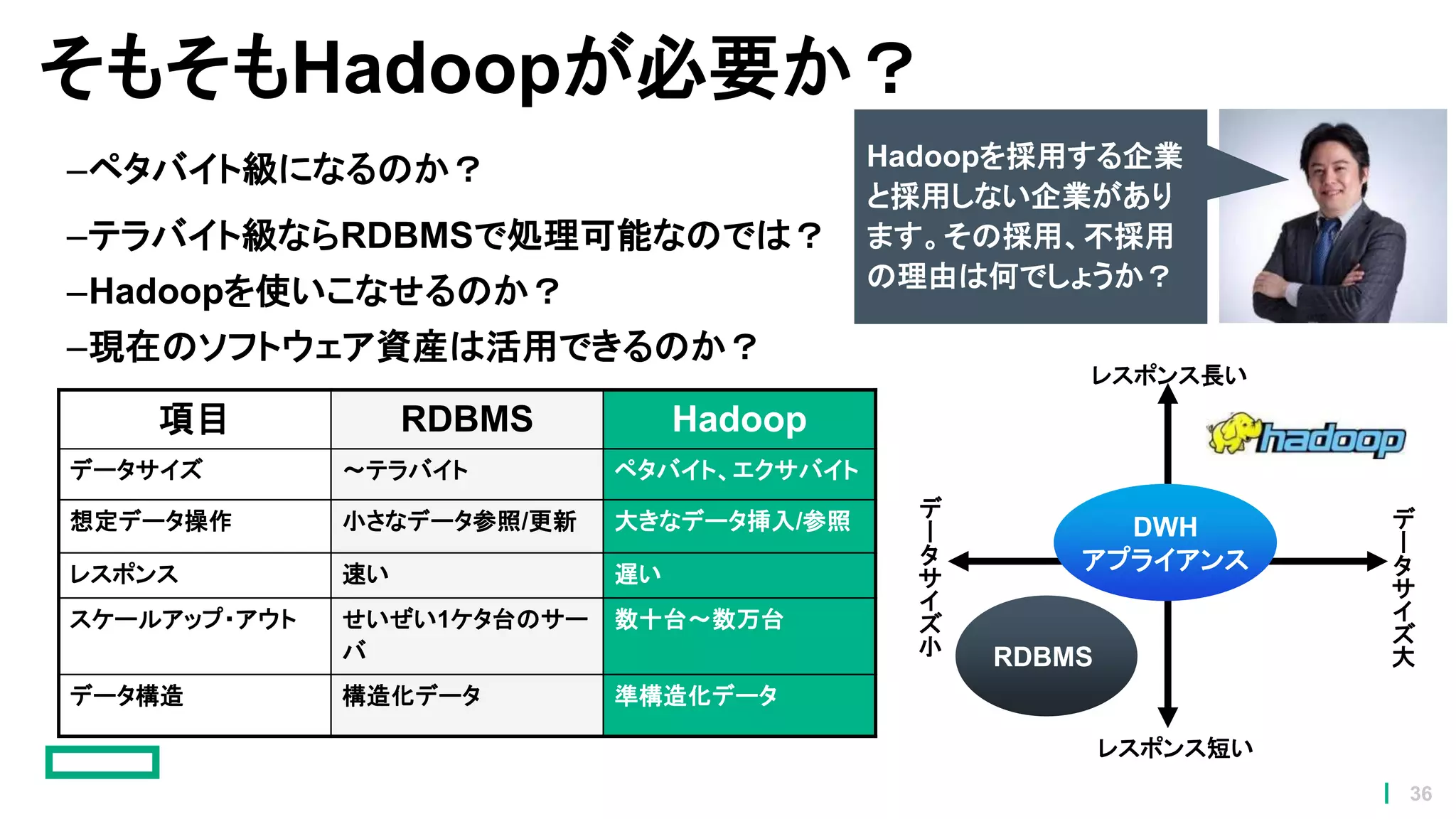
そもそもHadoopが必要か? –ペタバイト級になるのか? –テラバイト級ならRDBMSで処理可能なのでは? –Hadoopを使いこなせるのか? –現在のソフトウェア資産は活用できるのか? 項目 RDBMS Hadoop データサイズ
~テラバイト ペタバイト、エクサバイト 想定データ操作 小さなデータ参照/更新 大きなデータ挿入/参照 レスポンス 速い 遅い スケールアップ・アウト せいぜい1ケタ台のサー バ 数十台~数万台 データ構造 構造化データ 準構造化データ デ ー タ サ イ ズ 大 デ ー タ サ イ ズ 小 レスポンス長い レスポンス短い DWH アプライアンス RDBMS Hadoopを採用する企業 と採用しない企業があり ます。その採用、不採用 の理由は何でしょうか? 36
37.
HadoopとRDBMSの得意分野を混同してはいけない –データの更新処理 – 大量のデータを1度だけ格納し、参照する – 格納されたデータに対する更新処理概念 (RDBMSでは当然の機能) –リアルタイム処理 –
前準備や後処理など基本はバッチ処理(NFS) – セミリアルタイム処理(ストリーミング) –可用性 –RDBMS(HAクラスター)の可用性とHadoopの可用性 –SPOFに対する考え方 銀行、証券会社、大手 通信事業者などが導入 するNonStop OS+ NonStop SQLと、 Linux OS+Hadoopを 使ったSQL処理基盤の 決定的な違いは? 37
38.
Hadoopはあくまでエンジン:うまく使いこなせるのか? –MapReduceで開発が大変 –分析アプリをKeyValueモデルで設計できるか –Javaがベース、開発言語の選択 –アプリケーションのデバック –ワークロードの負荷のかけ方 –クラスターの用途分割 –ネットワークリソースの割当て –サーバスペックが必要 –コア数、ローカルディスク性能、メモリ容量に依存 –ネットワークが遅いと全体性能に影響 HDDが48本も入る サーバーが開発される 背景は何でしょうか? HPE Apollo 4200
Gen10 38
39.
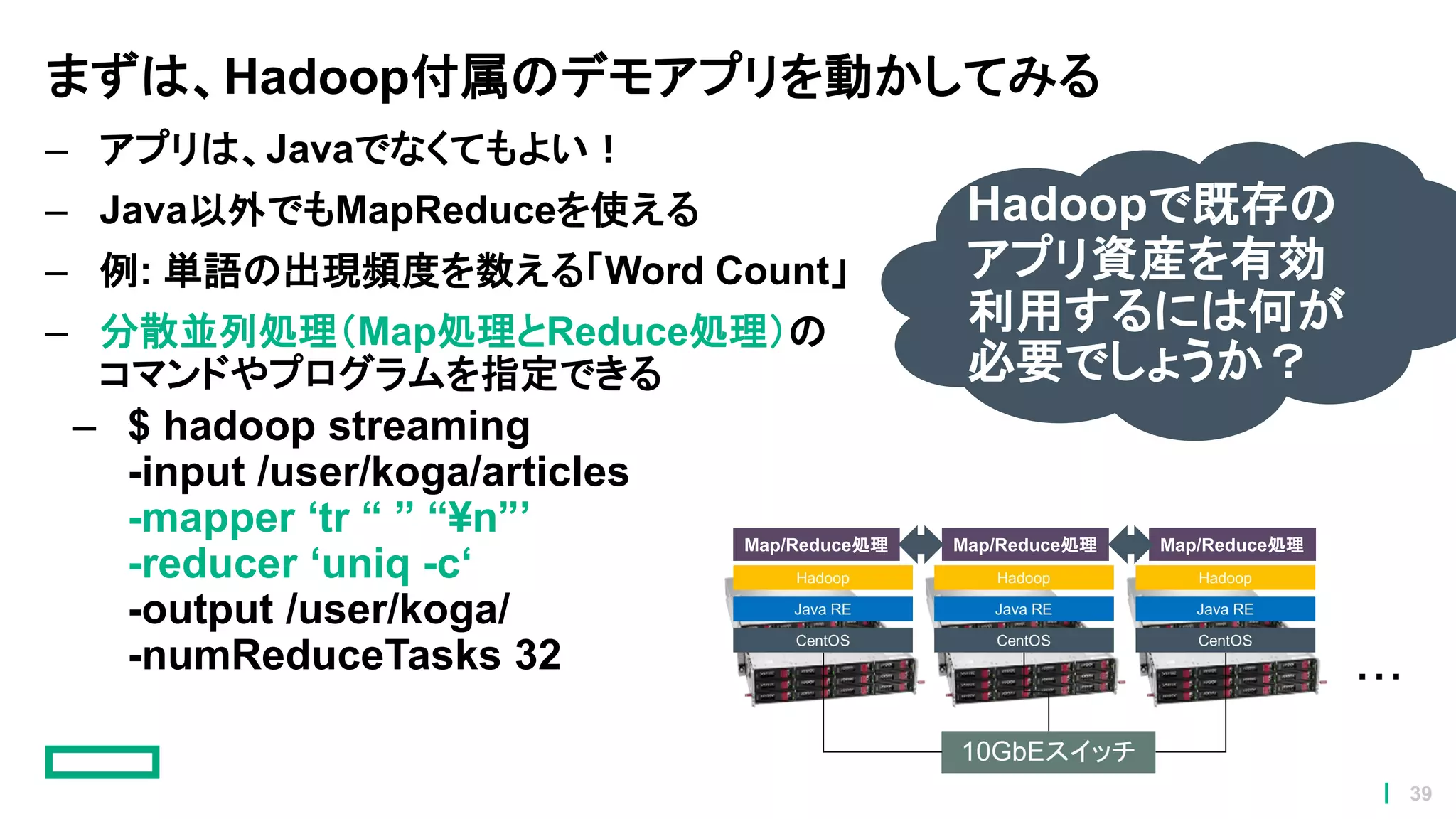
まずは、Hadoop付属のデモアプリを動かしてみる – アプリは、Javaでなくてもよい! – Java以外でもMapReduceを使える –
例: 単語の出現頻度を数える「Word Count」 – 分散並列処理(Map処理とReduce処理)の コマンドやプログラムを指定できる – $ hadoop streaming -input /user/koga/articles -mapper ‘tr “ ” “¥n”’ -reducer ‘uniq -c‘ -output /user/koga/ -numReduceTasks 32 Map/Reduce処理 Map/Reduce処理 Map/Reduce処理 Hadoopで既存の アプリ資産を有効 利用するには何が 必要でしょうか? 39
40.
Hadoop基盤でビジネス成果が得られるか? –従来のスケールアップ型RBDMSとは異なるスケールアウト型設計 –アプリ開発は必須 – 分析アプリ、AIアプリの開発コスト – その後のアプリ保守コスト –速くなるメリット –
従来のデータ規模:従来手法(RDBMS等) vs. 非構造化データ – 応答性、スケールアウトの恩恵 –全社IT基盤における位置づけ – 共通基盤化構想:複数ユーザーへのリソース配分 – 個別システム化構想:誰がどのような目的で利用するのか?専用機、個人の開発マシン等 データ分析で成長 している企業は、 どのような分野で、 何を「覚悟」してい るのでしょうか? 40
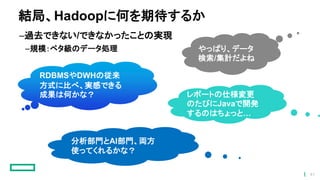
41.
結局、Hadoopに何を期待するか –過去できない/できなかったことの実現 –規模:ペタ級のデータ処理 RDBMSやDWHの従来 方式に比べ、実感できる 成果は何かな? やっぱり、データ 検索/集計だよね レポートの仕様変更 のたびにJavaで開発 するのはちょっと… 分析部門とAI部門、両方 使ってくれるかな? 41
42.
Hadoopのユースケース、事例 42
43.
Hadoopの事例はたくさんある 43
44.
リスクのモデル化 [金融(銀行・保険)] 顧客チャーン(解約)分析 [通信・金融] レコメンデーション
[eコマース・製造・小売] 広告のターゲッティング [広告] POS分析 [小売] 故障予測 [公共・通信・データセンター] 脅威分析 [セキュリティ・金融] 取引の監視 [金融・検査当局] 検索の品質 [eコマース・Web] データのサンドボックス [全業種] 様々な苦難を乗り越え、Hadoopを業務に適用している 集計・抽出・分析・ 時系列解析・変換 などの処理に採用 44
45.
2010年 –Facebookユーザー –4億人で(半分以上が毎日ログイン) –月に250億のコンテンツを共有 – 月に5000億ページが見られている –36ペタバイト(PB)の非圧縮データを保存 – Hadoopマシン:2200台以上 –
CPUコア:23000 – 1台当たりのメモリ:32GB – 1日当たり80~90TB処理 – クラスタ当たり、月に300-400のユーザー – 1日に25000のジョブを発行 2020年 –市場価値は約4,750億ドル –Facebookユーザー –毎月20億人以上のアクティブユーザー –月に250億のコンテントを共有 – 136,000枚/分の写真投稿 – 510,000件/分のコメント投稿 – 293,000件/分のステータス更新 –300ペタバイトのデータ分析 –Hadoopに強く依存したIT https://www.simplilearn.com/how-facebook-is-using-big-data-article 45
46.
導入事例:検索サイト • Hadoopの用途: • Webページテキスト分析、利用者の閲覧分析 •
地図情報検索 • 検索サービス • Webページのお勧め情報の表示 等 • OSS-DB • 処理に数日 • スケールアップ型の大規模化で対処 • サーバーとソフトウェアの初期投資増 • 商用RBDMSも併用 Before After • Hadoop • 数日かかっていた処理が数分に短縮 • スケールアウト型サーバー構成 • サーバーの初期投資低減 • SQLクエリも可能 この企業は、なぜ、 Hadoopに踏み切った のでしょうか? 46
47.
47 ご清聴ありがとう ございました @masazumi_koga
48.
48 機械学習+Hadoop基盤を知る 最先端オープンソース書籍出版への取り組み AI時代に必携の一冊! 導入前の検討、構築、設定、使用法、応用例 等 Apache
Hadoop 3と商用版MapR 6クラスター構築、使用法 機械学習, ニューラルネットワークの具体例 データベースとの連携, ETLツール RDBMS, ログ, Twitterデータの取得 等 • Bigdata分析基盤の概要 • Hadoopの種類、沿革、システム構成 • Apache Hadoop 3の特徴 • Hadoopシステム構成、導入前検討項目 • ハードウェアコンポーネントの検討 • Hadoop 3, MapR 6クラスターのハードウェア構成例 • Hadoopクラウド • ハードウェアの設定 • Hadoop 3, MapR 6クラスターのインストール • Hadoop 3, MapR 6クラスターの運用管理 • Spark SQL, Spark Streaming, Spark GraphX, Spark R, Spark MLlib • ニューラルネットワーク • Hive, Impala, HBase, Pig • Sqoop, Flume • Mahout Amazon インプレス フライトデータ分析、 迷惑メール分類、 おすすめ映画タイトル の表示など、機械学習 の具体例を掲載! Hadoop 3と MapR 6を 解説した世界初の本!
Download




























![リスクのモデル化 [金融(銀行・保険)]
顧客チャーン(解約)分析 [通信・金融]
レコメンデーション [eコマース・製造・小売]
広告のターゲッティング [広告]
POS分析 [小売]
故障予測 [公共・通信・データセンター]
脅威分析 [セキュリティ・金融]
取引の監視 [金融・検査当局]
検索の品質 [eコマース・Web]
データのサンドボックス [全業種]
様々な苦難を乗り越え、Hadoopを業務に適用している
集計・抽出・分析・
時系列解析・変換
などの処理に採用
44](https://image.slidesharecdn.com/apachehadoopmasazumikogahpe202010-201001050548/85/Apache-Hadoop-44-320.jpg)































![リスクのモデル化 [金融(銀行・保険)]
顧客チャーン(解約)分析 [通信・金融]
レコメンデーション [eコマース・製造・小売]
広告のターゲッティング [広告]
POS分析 [小売]
故障予測 [公共・通信・データセンター]
脅威分析 [セキュリティ・金融]
取引の監視 [金融・検査当局]
検索の品質 [eコマース・Web]
データのサンドボックス [全業種]
様々な苦難を乗り越え、Hadoopを業務に適用している
集計・抽出・分析・
時系列解析・変換
などの処理に採用
44](https://image.slidesharecdn.com/apachehadoopmasazumikogahpe202010-201001050548/75/Apache-Hadoop-44-2048.jpg)























![[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l34hp5-141120233511-conversion-gate02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d21hppostgresplusadvancedserverv9-141120232610-conversion-gate02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c25hpfacebook-141120232027-conversion-gate02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![[Postgre sql9.4新機能]レプリケーション・スロットの活用](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql9-140909012453-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














![[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29](https://cdn.slidesharecdn.com/ss_thumbnails/lanceriedelappserver-thehiveaug29-130920154018-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




