Download as PDF, PPTX

![Motivative Data Structures behind Hazelcast development
[ Java Behind Hazelcast]
● HashMap
● ConcurrentHashMap
● Multicast Discovery Mechanisms
2](https://image.slidesharecdn.com/hazelcastintroduction-180326045250/85/Hazelcast-Introduction-2-320.jpg)







![13
Data Partitioning
13
● Hazelcast stores data in partitions
● Default partition number is 271
● Backups partitions for redundancy
● Partition table
● Repartition
○ When member joins the cluster
○ When member leaves the cluster
● Partition can be increased, if data size
per partition is bigger than 100 Mb.
● pid = hash(convert key to byte []) % pc
(271) *pid: partitionId pc: partitionCount](https://image.slidesharecdn.com/hazelcastintroduction-180326045250/85/Hazelcast-Introduction-13-320.jpg)






![Motivative Data Structures behind Hazelcast development
[ Java Behind Hazelcast]
● HashMap
● ConcurrentHashMap
● Multicast Discovery Mechanisms
2](https://image.slidesharecdn.com/hazelcastintroduction-180326045250/75/Hazelcast-Introduction-2-2048.jpg)







![13
Data Partitioning
13
● Hazelcast stores data in partitions
● Default partition number is 271
● Backups partitions for redundancy
● Partition table
● Repartition
○ When member joins the cluster
○ When member leaves the cluster
● Partition can be increased, if data size
per partition is bigger than 100 Mb.
● pid = hash(convert key to byte []) % pc
(271) *pid: partitionId pc: partitionCount](https://image.slidesharecdn.com/hazelcastintroduction-180326045250/75/Hazelcast-Introduction-13-2048.jpg)
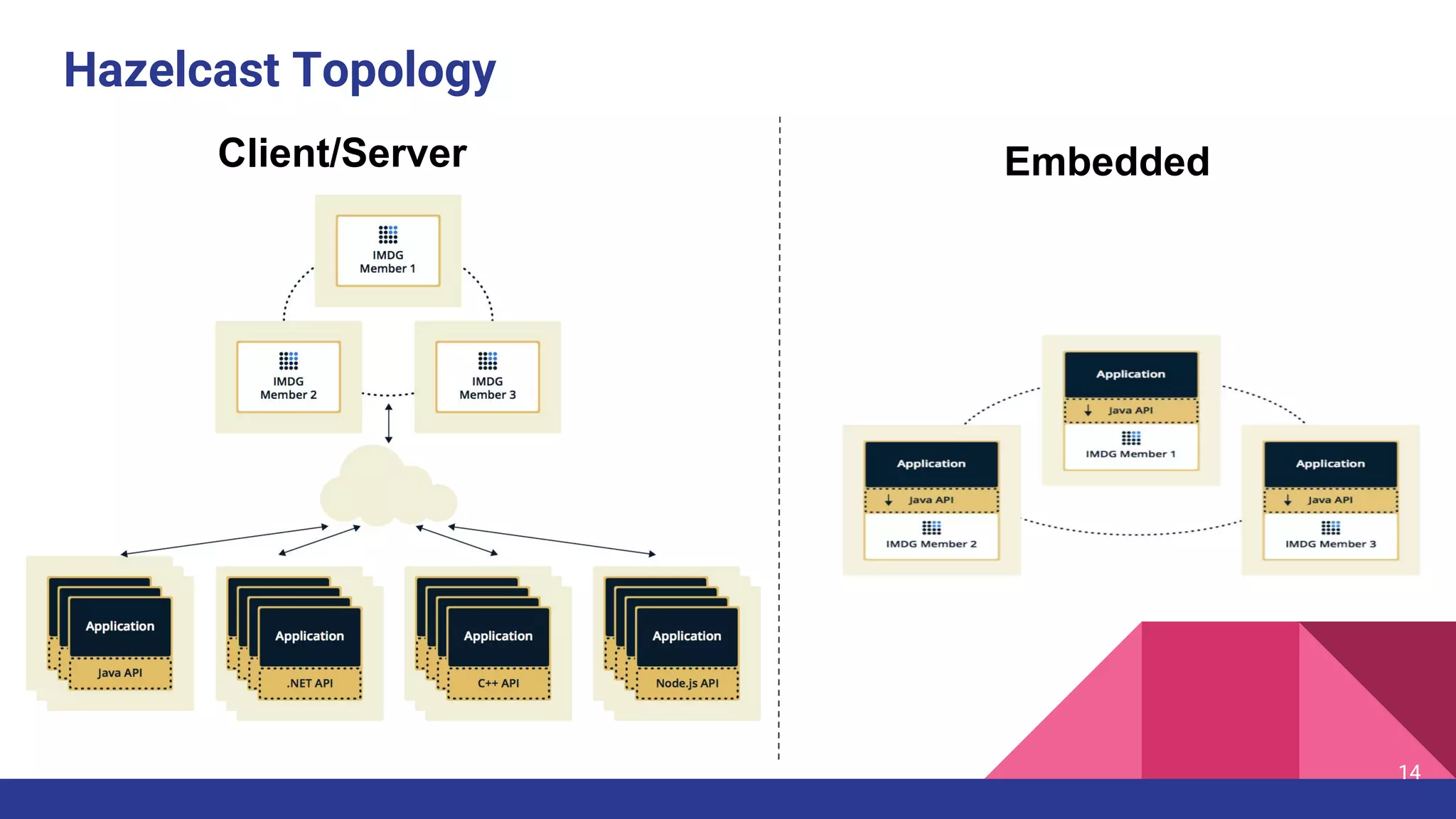
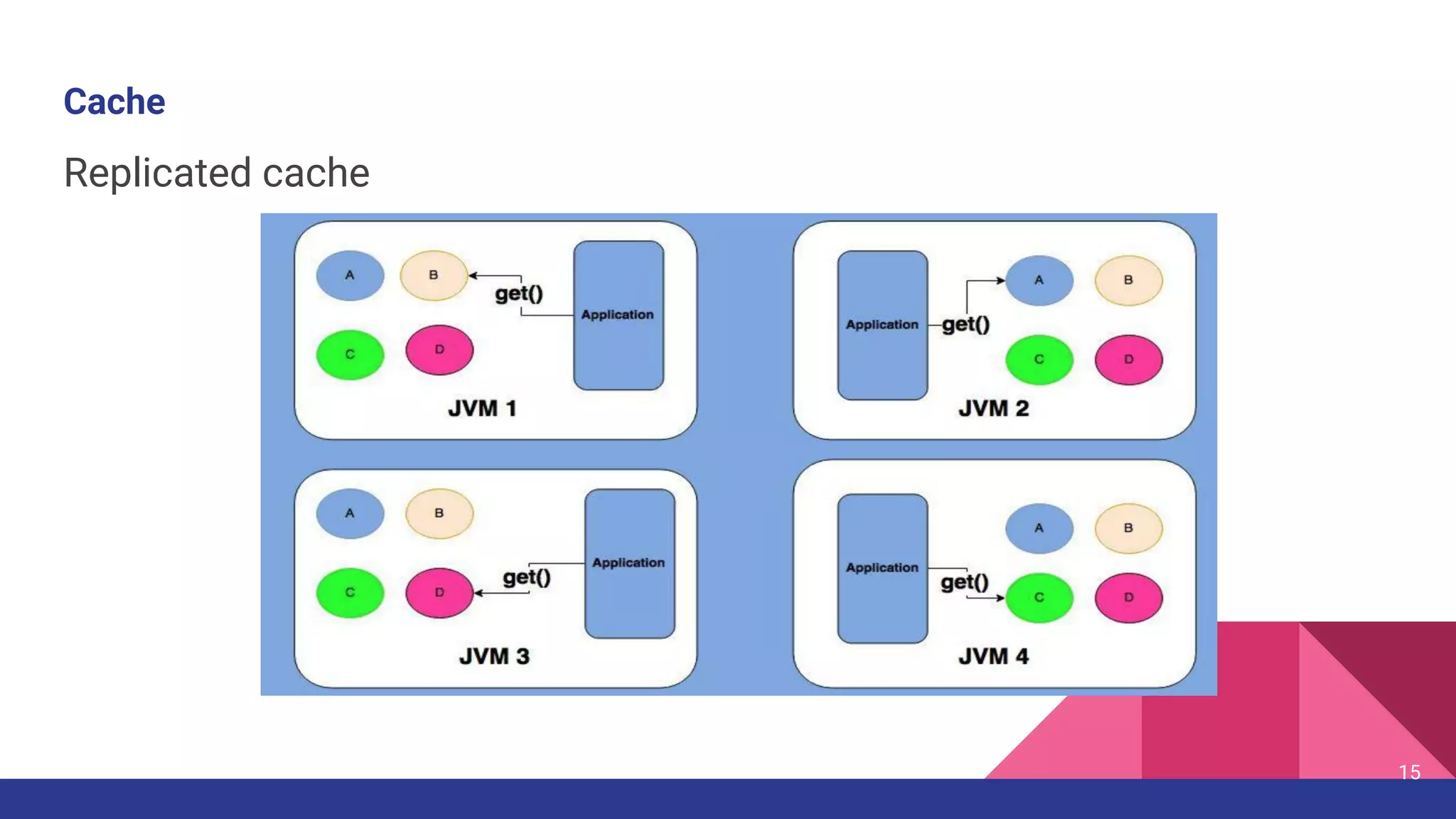
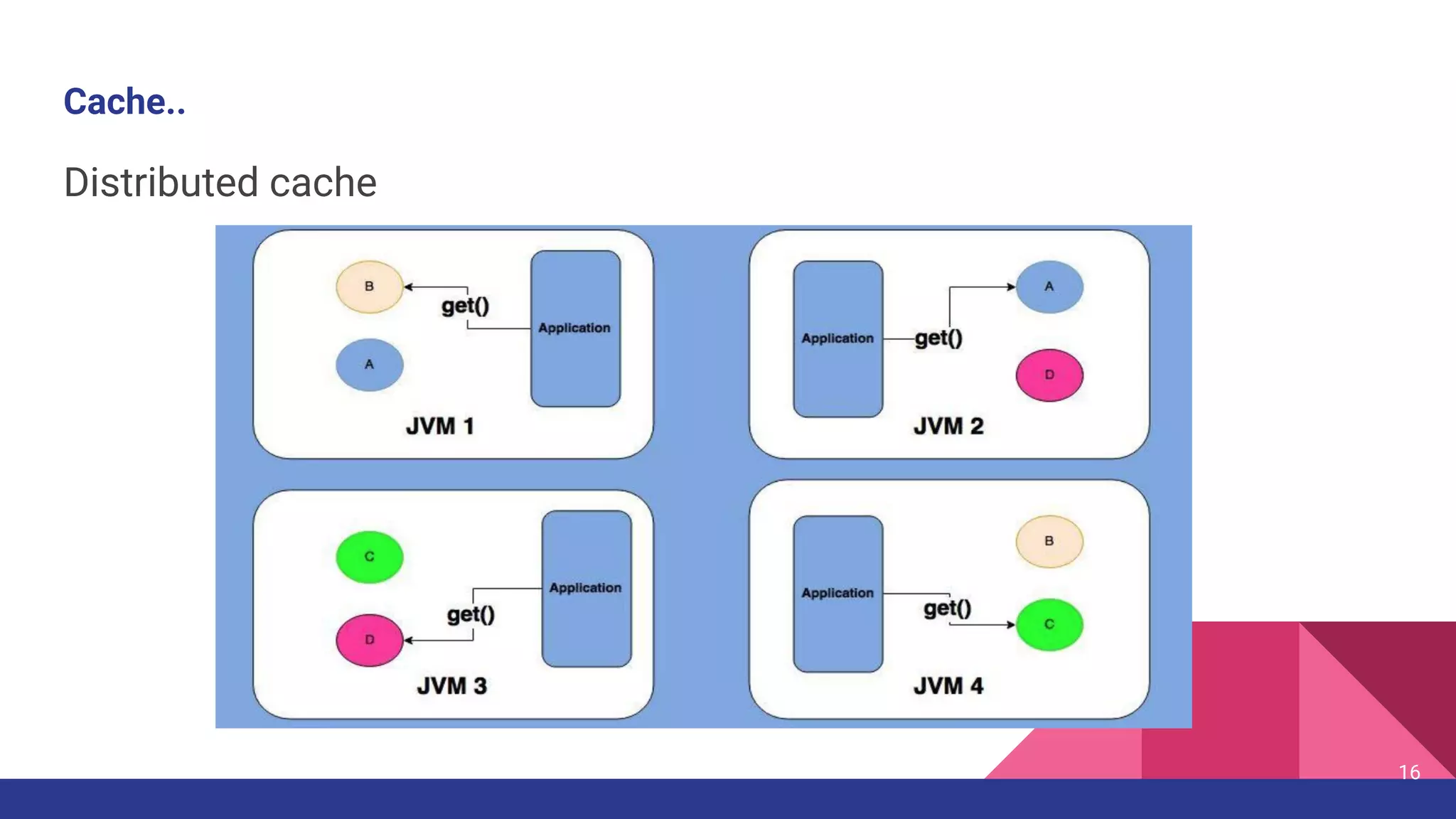






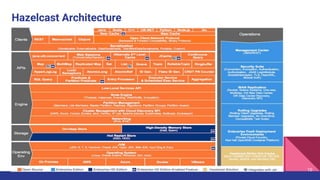
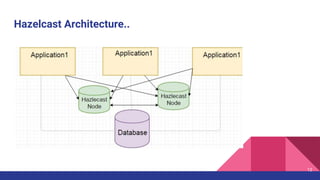
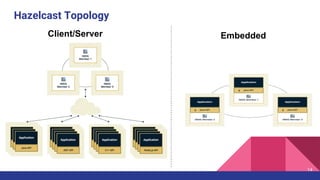
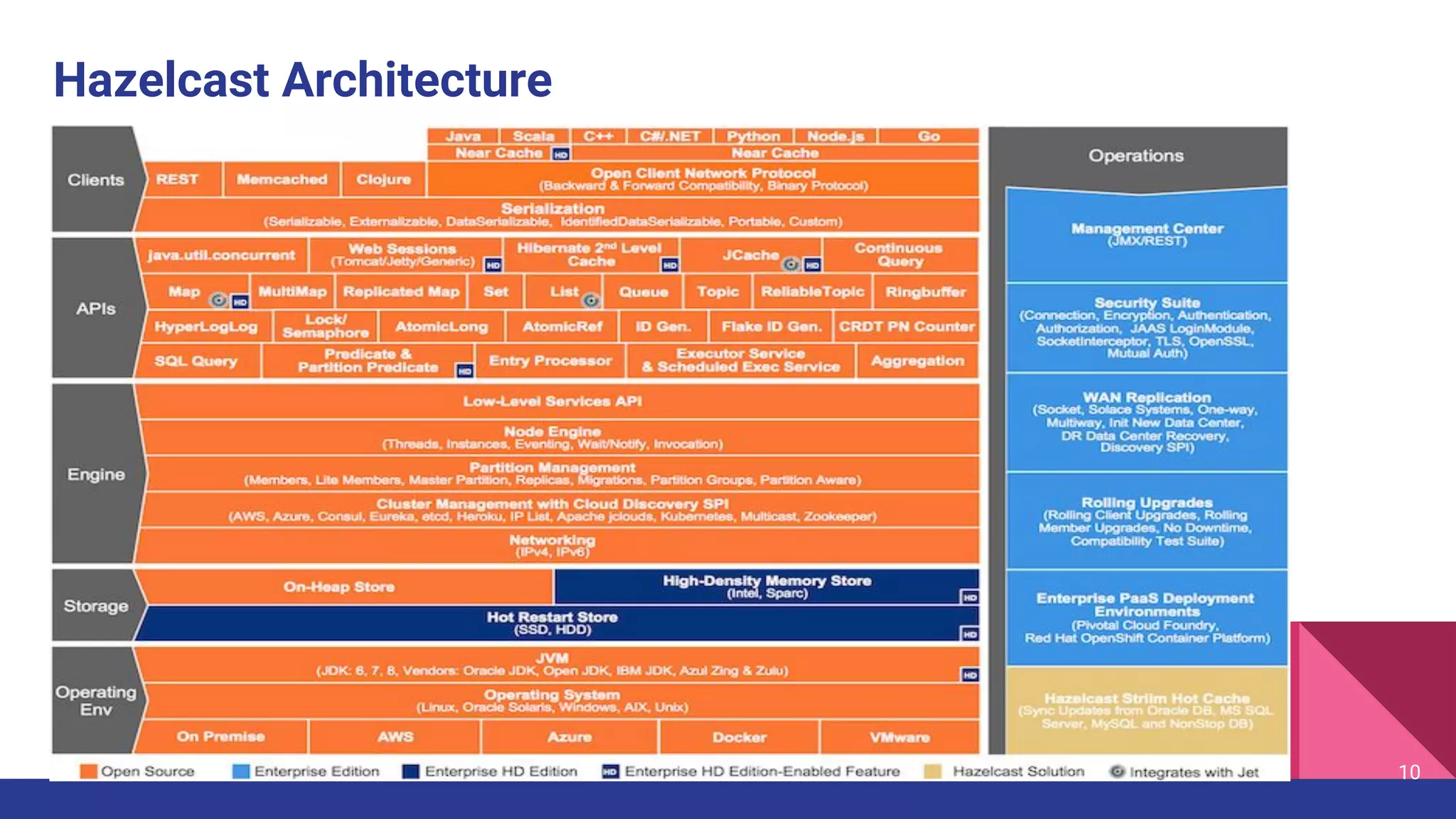
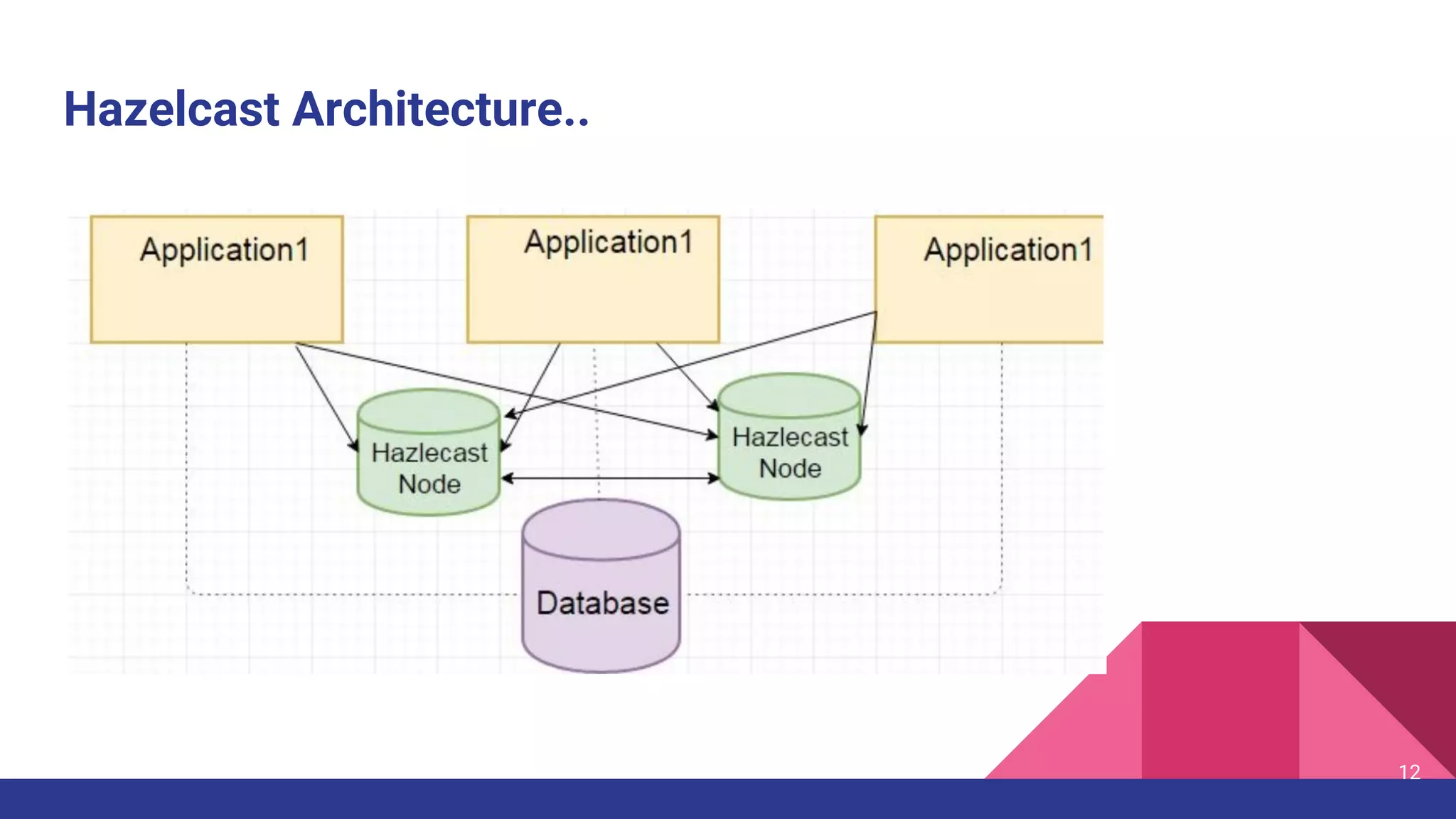
The document introduces Hazelcast, a distributed data grid built on a concurrent hashmap foundation, which offers scalable caching and data partitioning with thread safety. It discusses hashmap functionality, concurrent hashmap improvements for multi-thread environments, and discovery mechanisms for cluster connections. Hazelcast's architecture supports in-memory storage and redundancy, making it suitable for applications requiring high availability and efficient data processing.









![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




































































