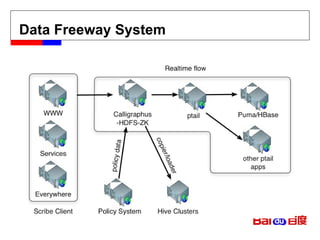
HBase 实现原理 - HBase 是什么? 分布式大规模存储引擎 针对吞吐量进行优化 不错的随机读写性能 BigTable 的开源实现 ( apache ) http://hadoop.apache.org/hbase/ Bigtable: A Distributed Storage System for Structured Data by Chang et al. http://labs.google.com/papers/bigtable.html
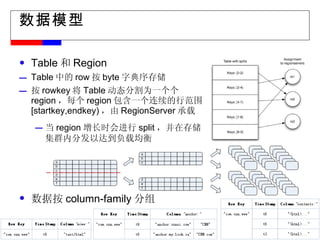
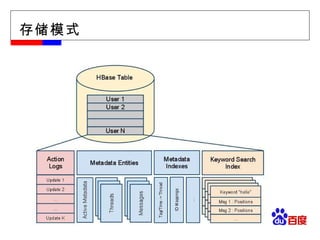
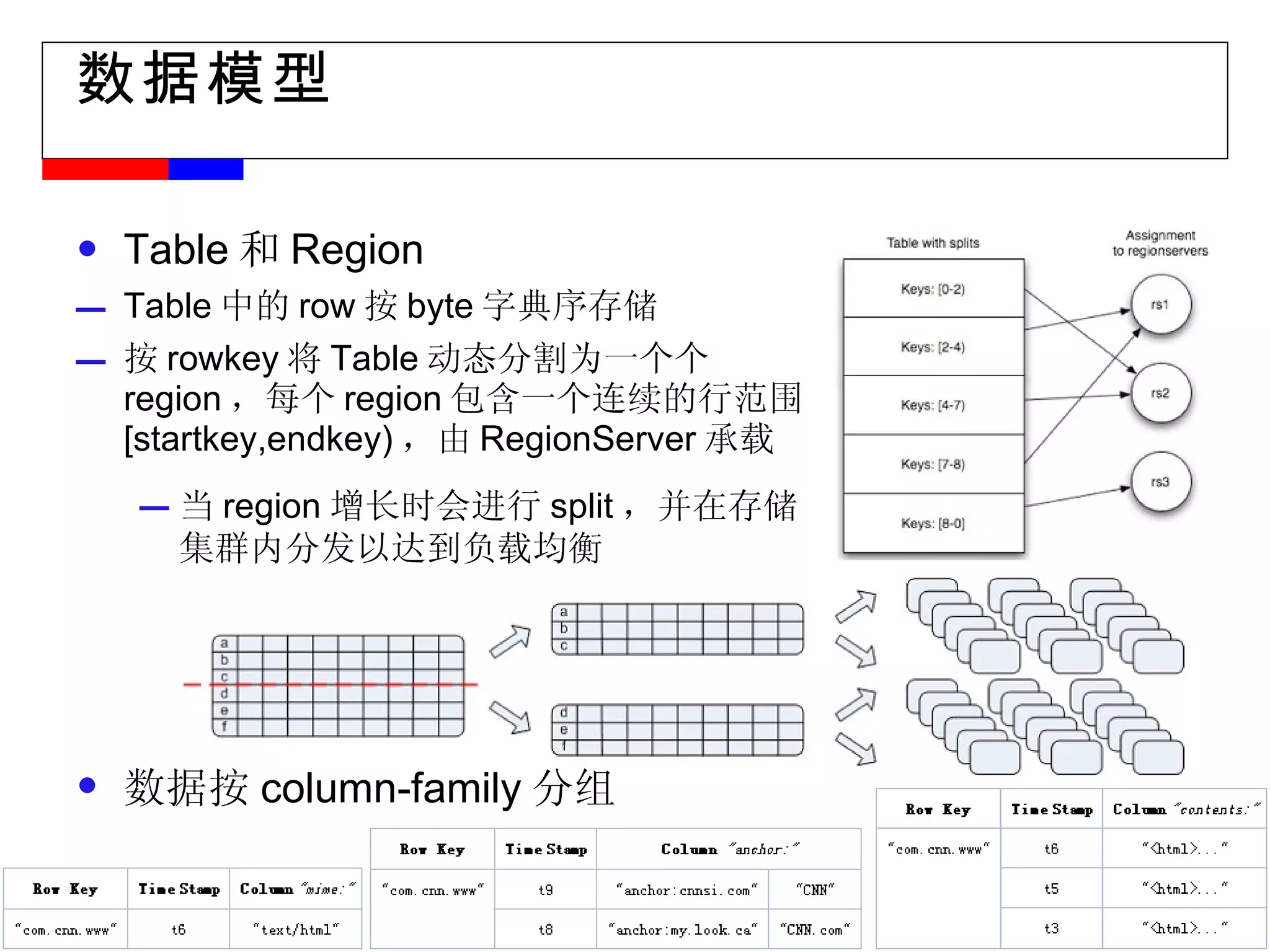
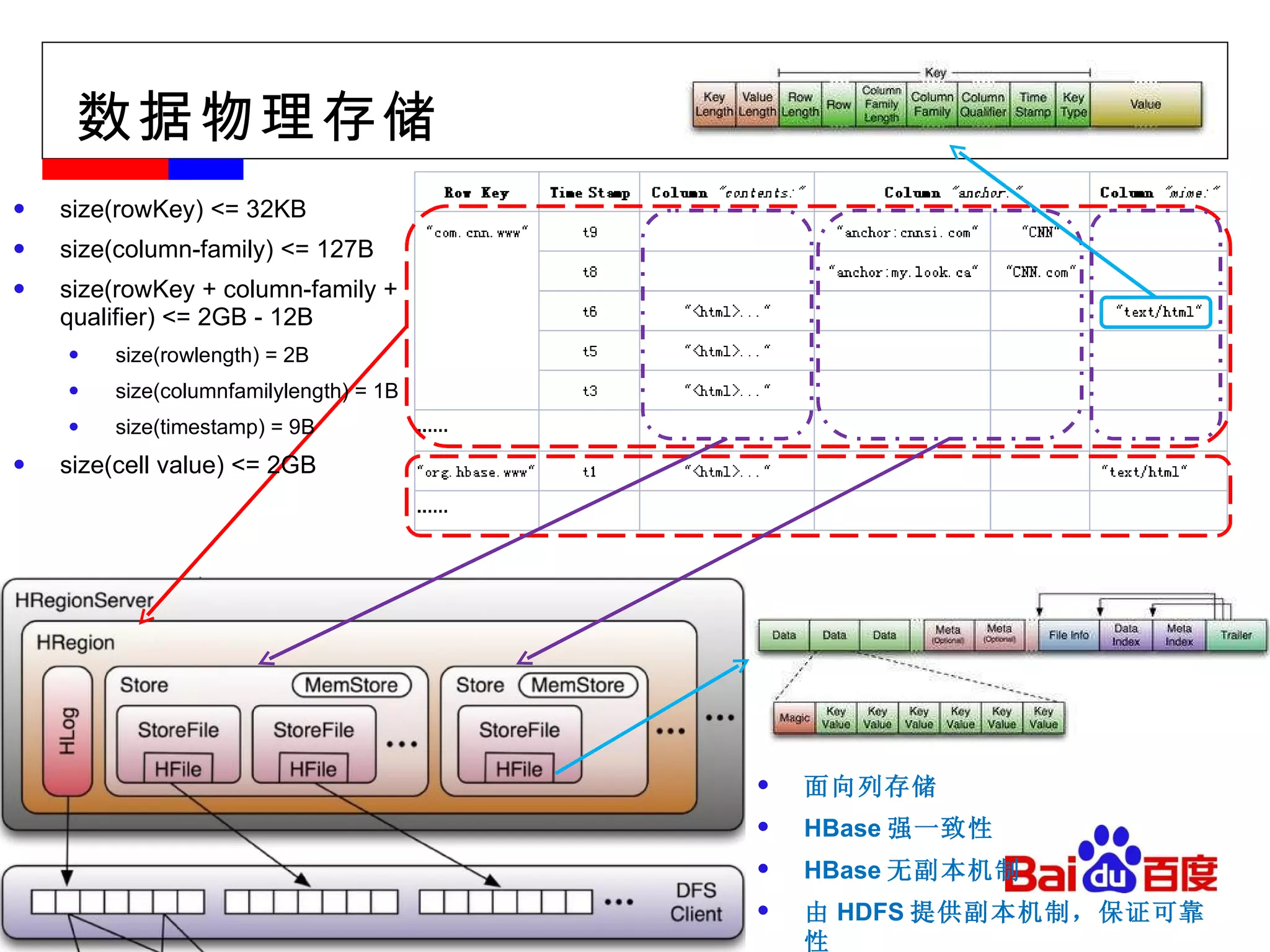
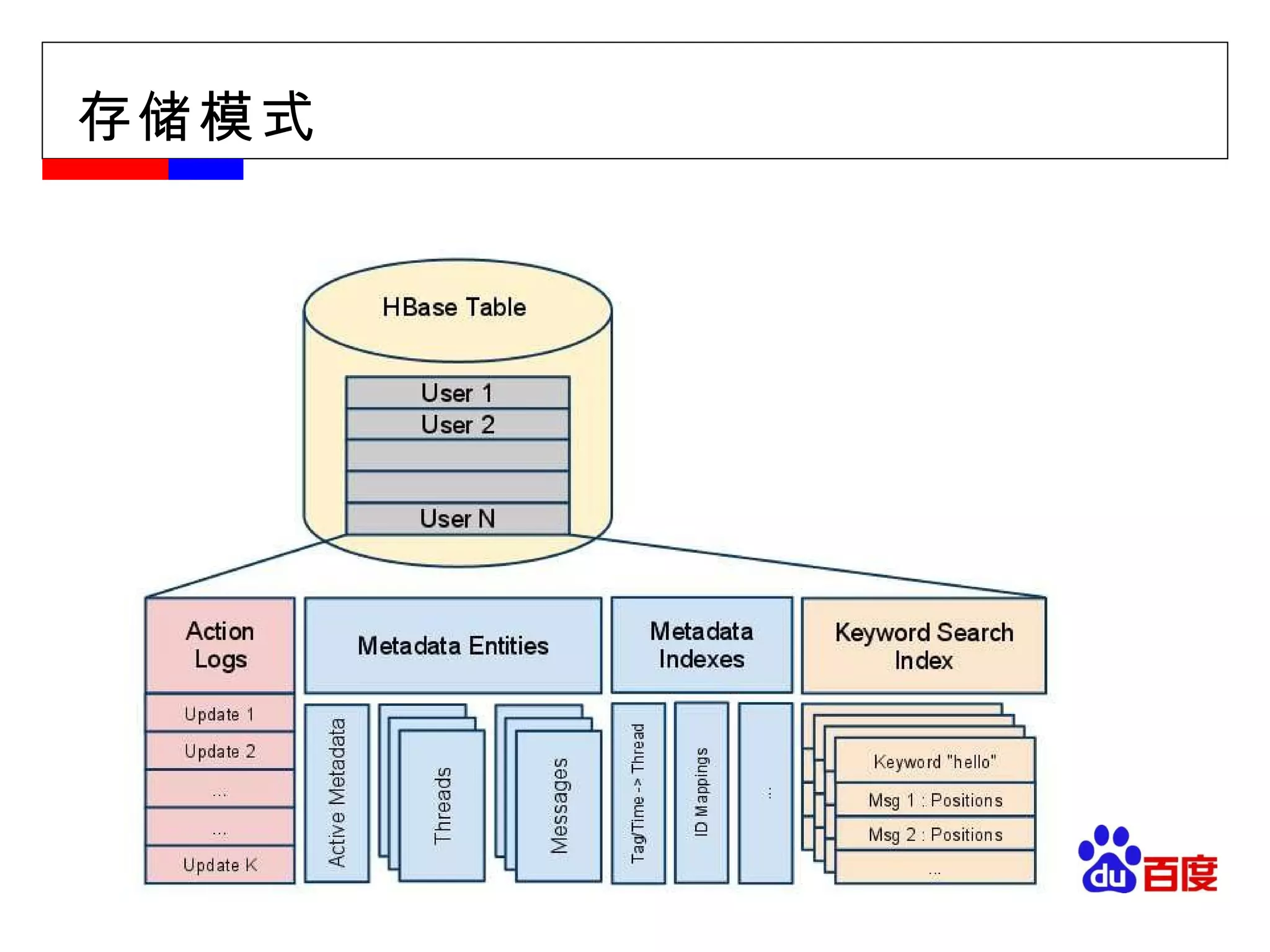
#11 物理视图: Region 、 Group by Column-family 为了实现数据存储的可扩展性, Table->Regions 数据不仅在 Table 一级进行分割,在 Region 级以 column-family 为单位进行物理分割。同一 column-family 的数据作为一组,在物理上是相近的,应用设计人员应该将这一特性作为 schema 设计的重要考虑
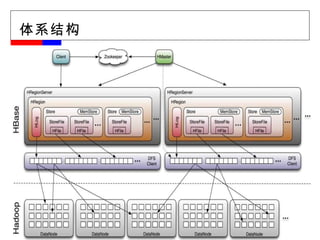
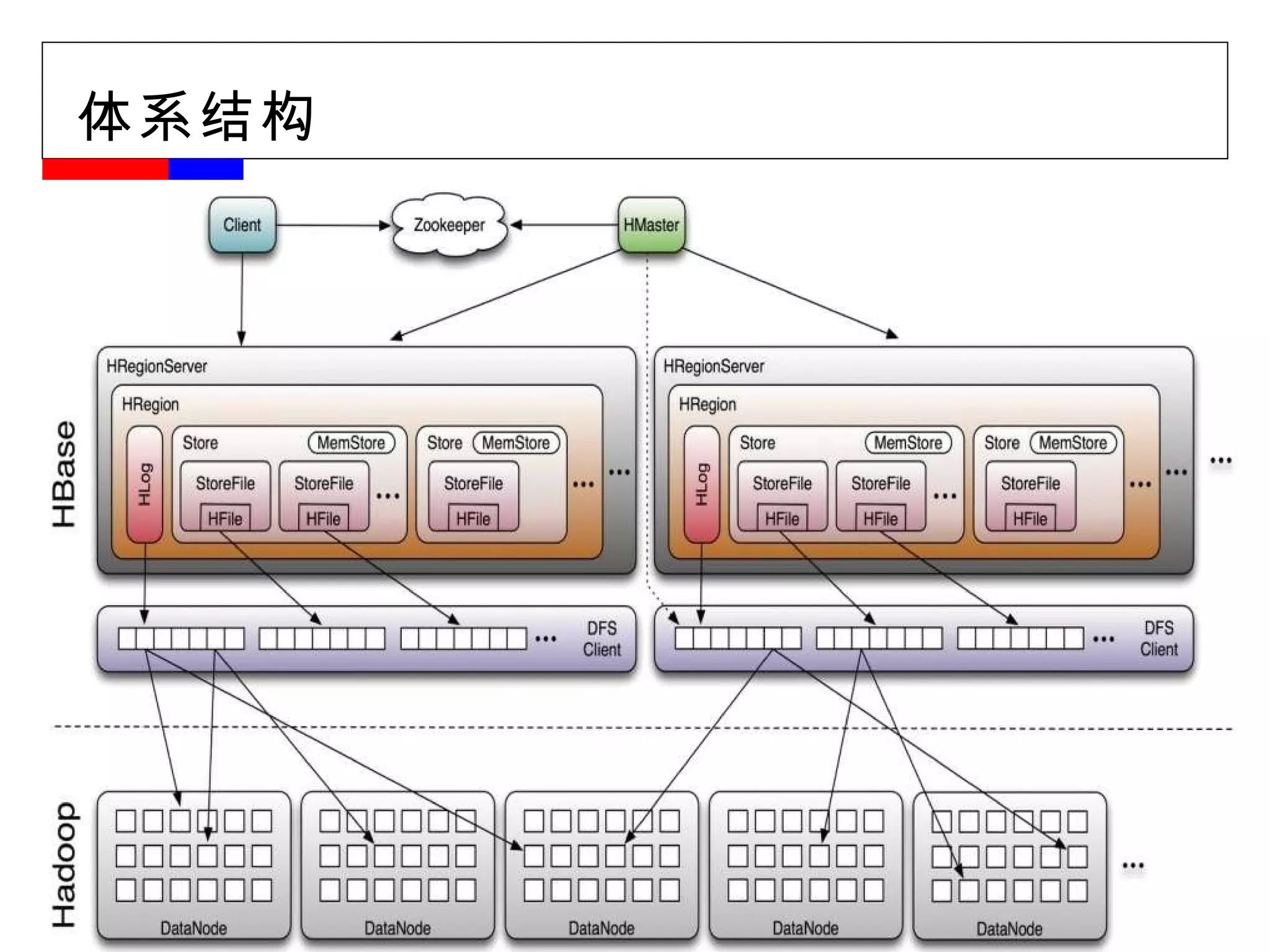
#12 HMaster 的职责: 分配 Region :在启动时分配 region ,在 region 创建、删除、增长、分裂时进行负载均衡 扫描 root/meta :确保 region 在线、删除没有引用的父 region 管理 schema 的修改、在线、离线 Admin :分发管理性的 close 、 flush 、 compact 消息 查看 ZK 中自己的 lease 和 regionserver ,以使自己清楚何时运行修复工作
#13 HMaster 的职责: 分配 Region :在启动时分配 region ,在 region 创建、删除、增长、分裂时进行负载均衡 扫描 root/meta :确保 region 在线、删除没有引用的父 region 管理 schema 的修改、在线、离线 Admin :分发管理性的 close 、 flush 、 compact 消息 查看 ZK 中自己的 lease 和 regionserver ,以使自己清楚何时运行修复工作
![HBase 原理及应用 刘景龙 [email_address] 2011-08-23](https://image.slidesharecdn.com/hbase-110823001715-phpapp02/85/Hbase-1-320.jpg)










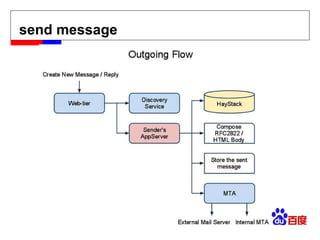
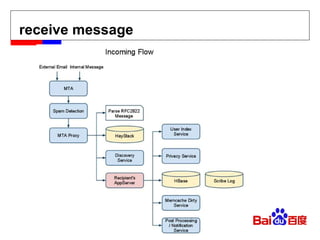
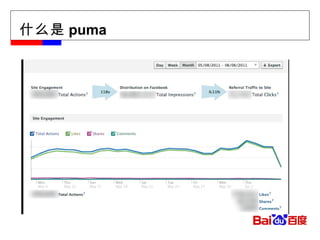
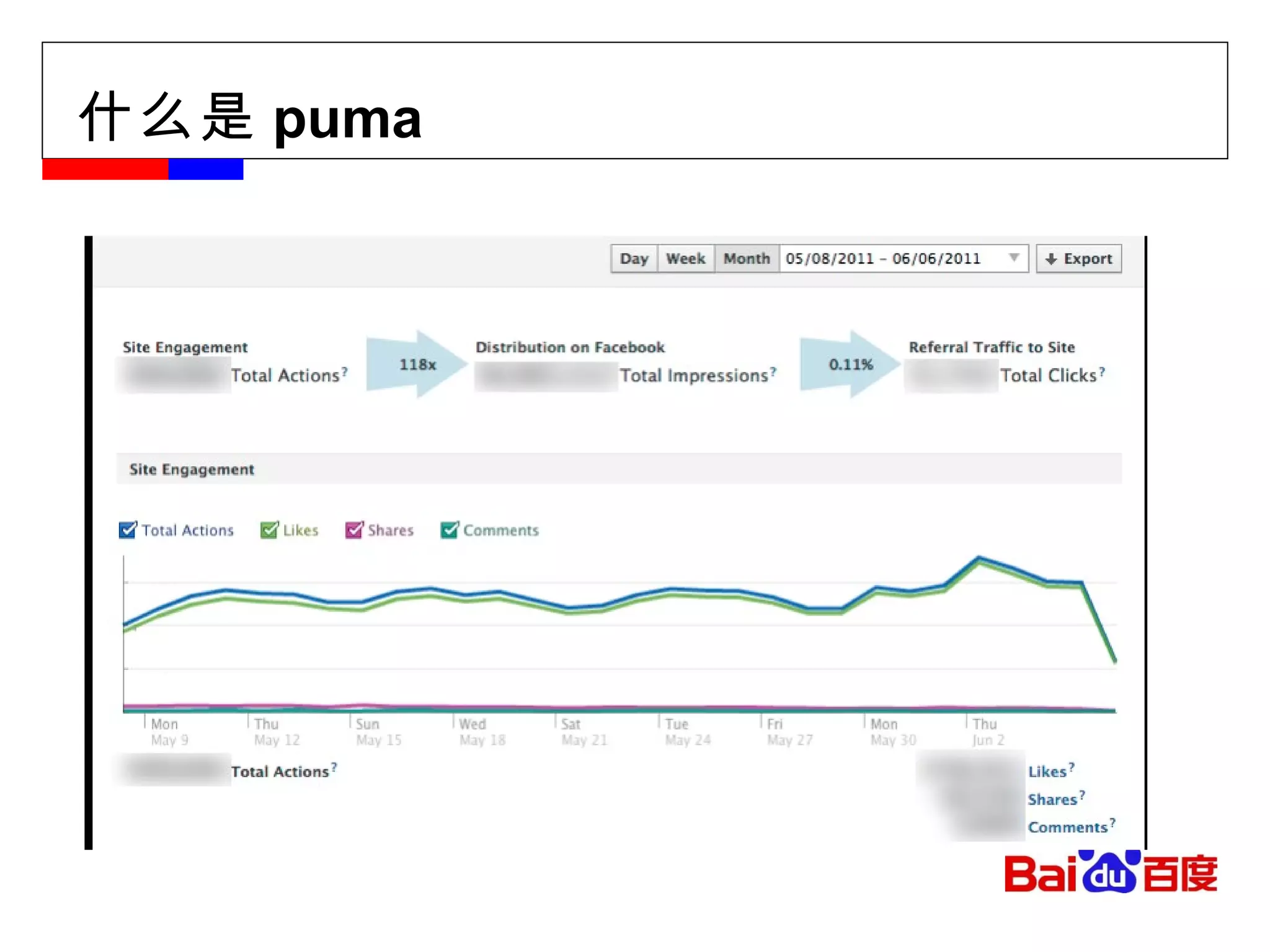
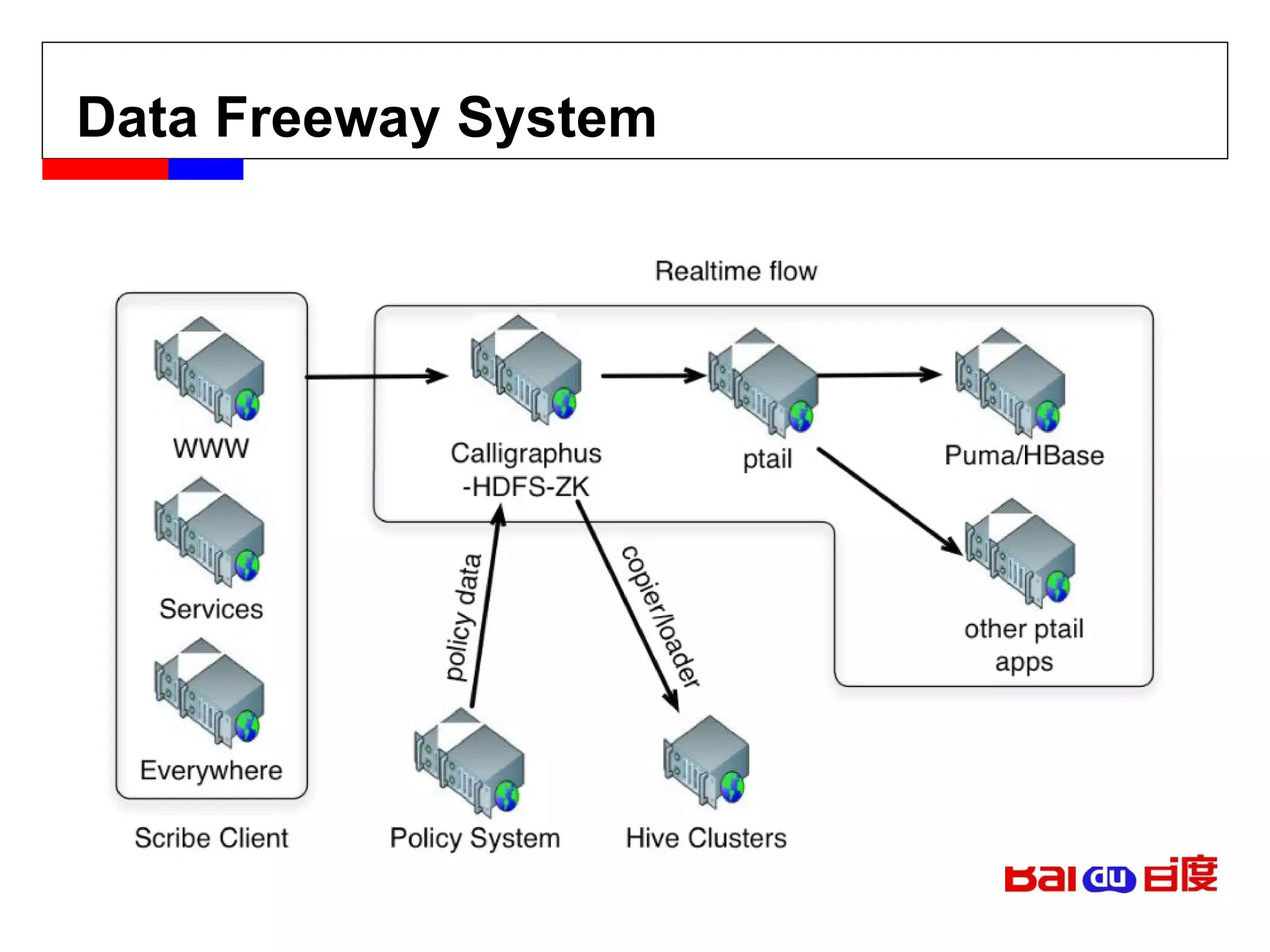
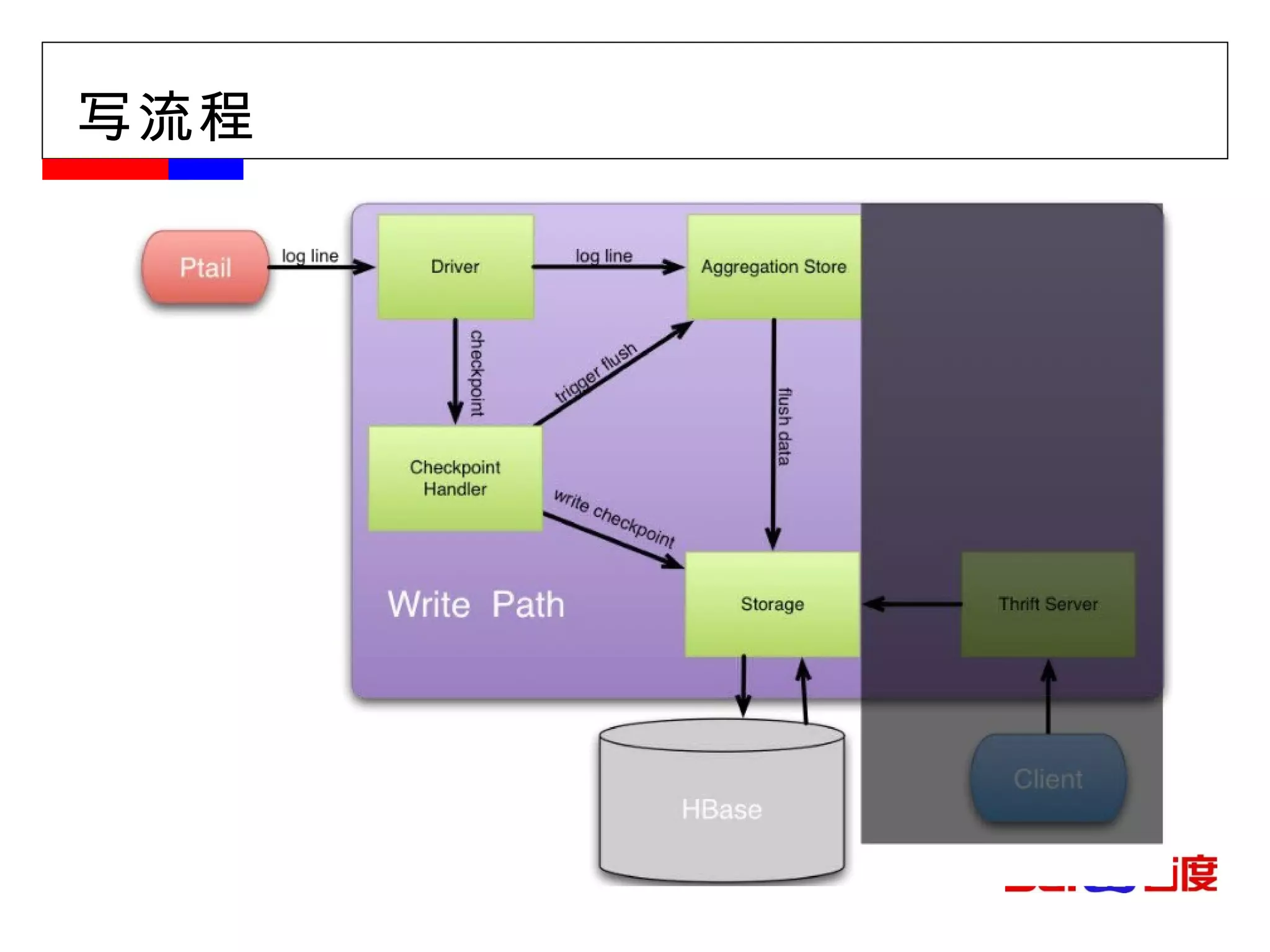
![[email_address] Facebook message (titan) Facebook insight (puma) Facebook metrics system (ODS)](https://image.slidesharecdn.com/hbase-110823001715-phpapp02/85/Hbase-18-320.jpg)









![HBase 原理及应用 刘景龙 [email_address] 2011-08-23](https://image.slidesharecdn.com/hbase-110823001715-phpapp02/75/Hbase-1-2048.jpg)









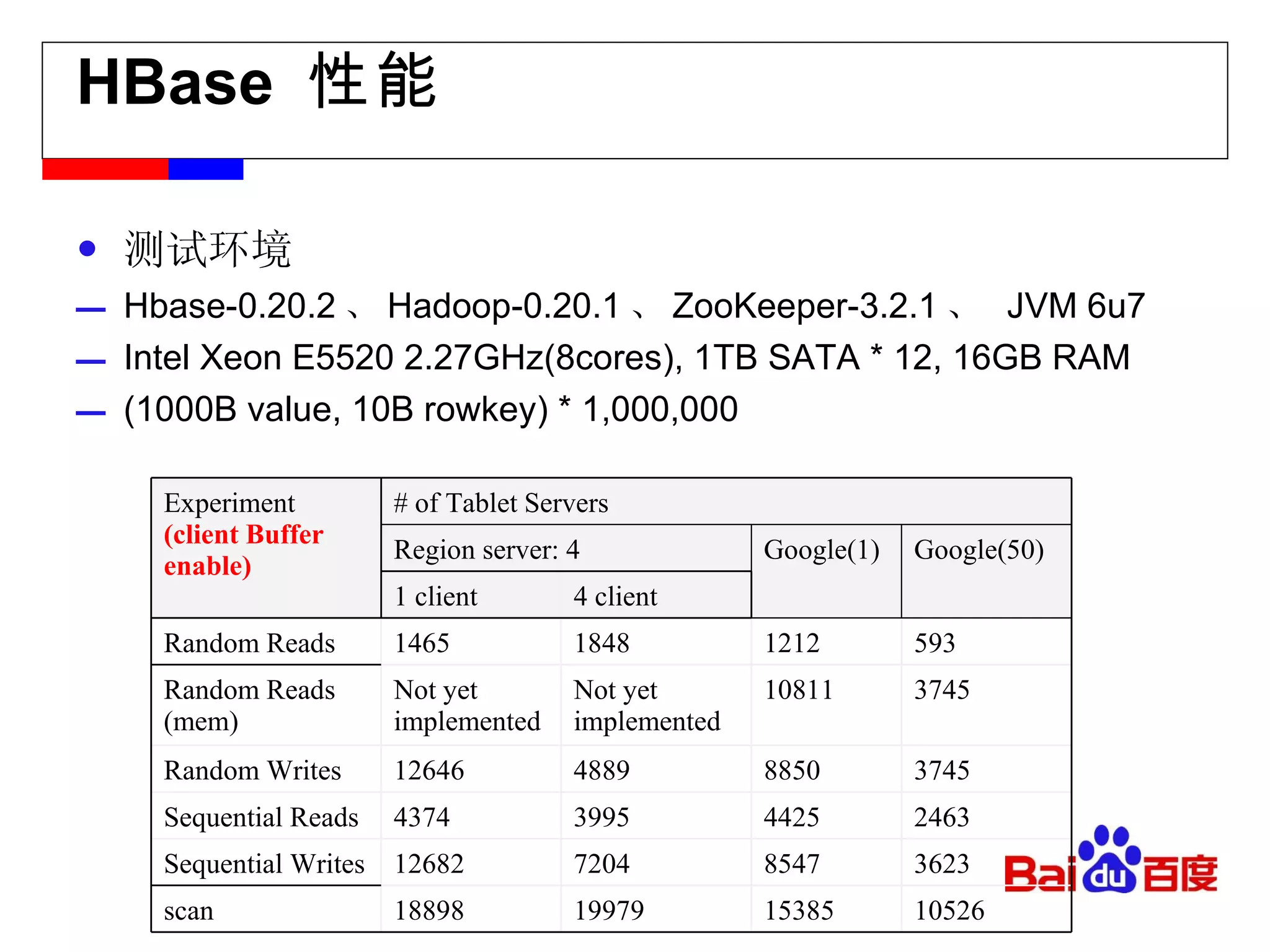
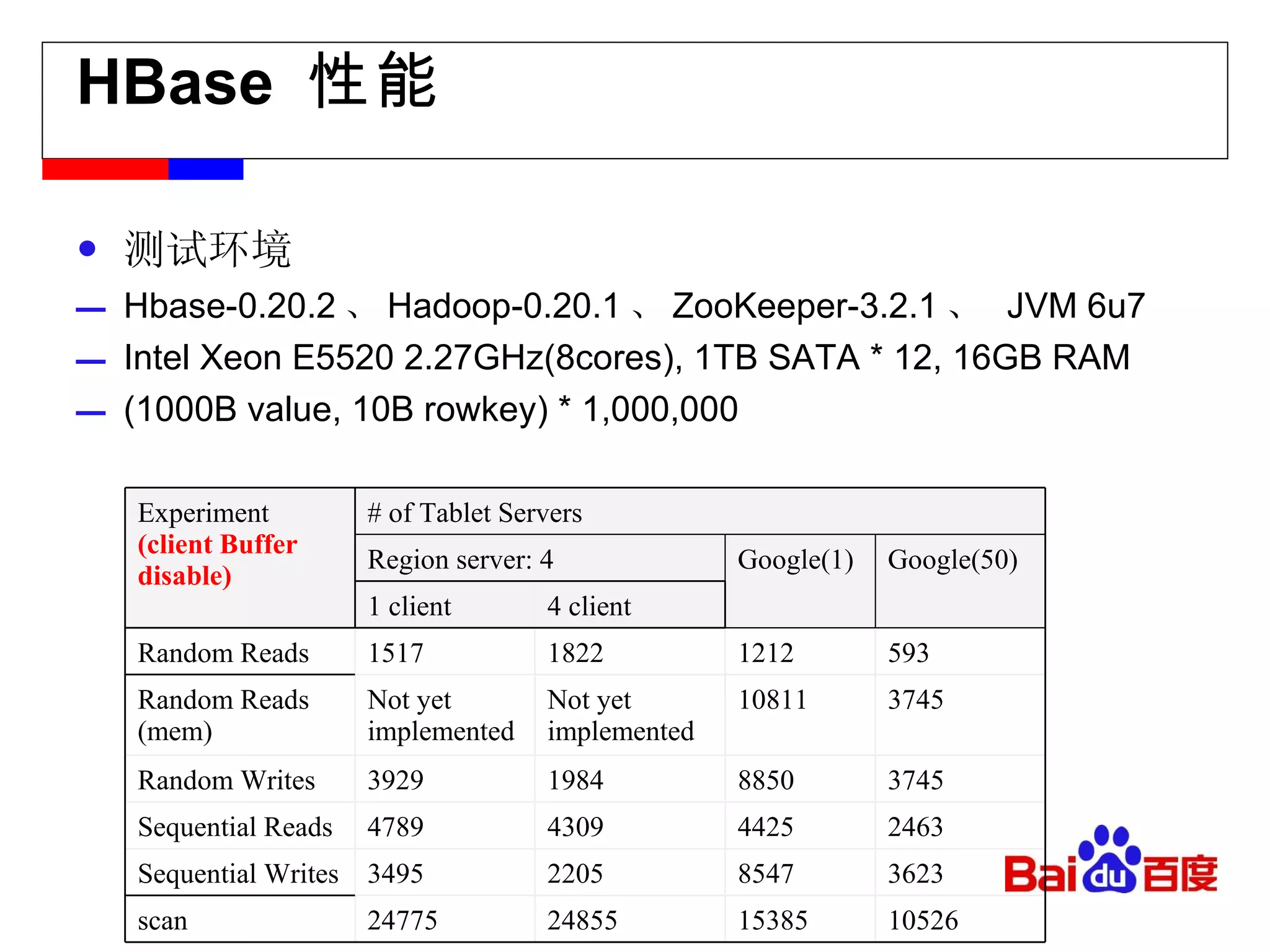

![[email_address] Facebook message (titan) Facebook insight (puma) Facebook metrics system (ODS)](https://image.slidesharecdn.com/hbase-110823001715-phpapp02/75/Hbase-18-2048.jpg)


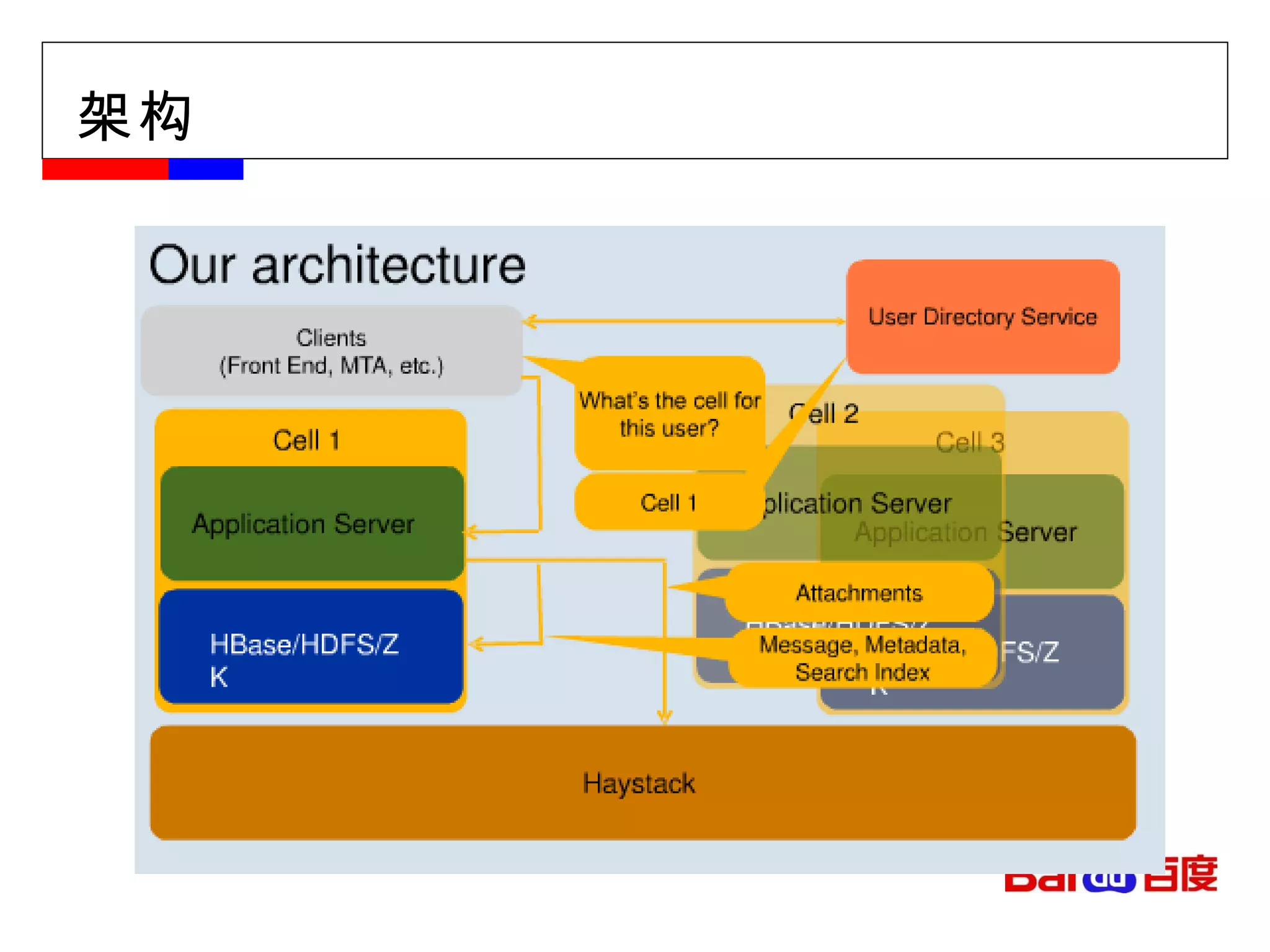
















































































![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




