UNIT II :HDFS(Hadoop Distributed File System)
The Design of HDFS, HDFS Concepts, Command Line
Interface, Hadoop file system interfaces, Data flow,
Data Ingest with Flume and Scoop and Hadoop archives,
Hadoop I/O: Compression, Serialization, Avro and File-
Based Data structures.
2.
Hadoop - HDFS(Hadoop Distributed File System)
Before head over to learn about the HDFS(Hadoop Distributed File System), we
should know what actually the file system is.
The file system is a kind of Data structure or method which we use in an operating
system to manage file on disk space.
This means it allows the user to keep maintain and retrieve data from the local disk.
3.
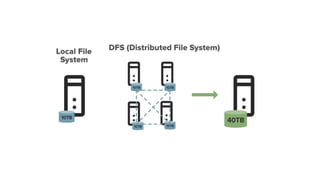
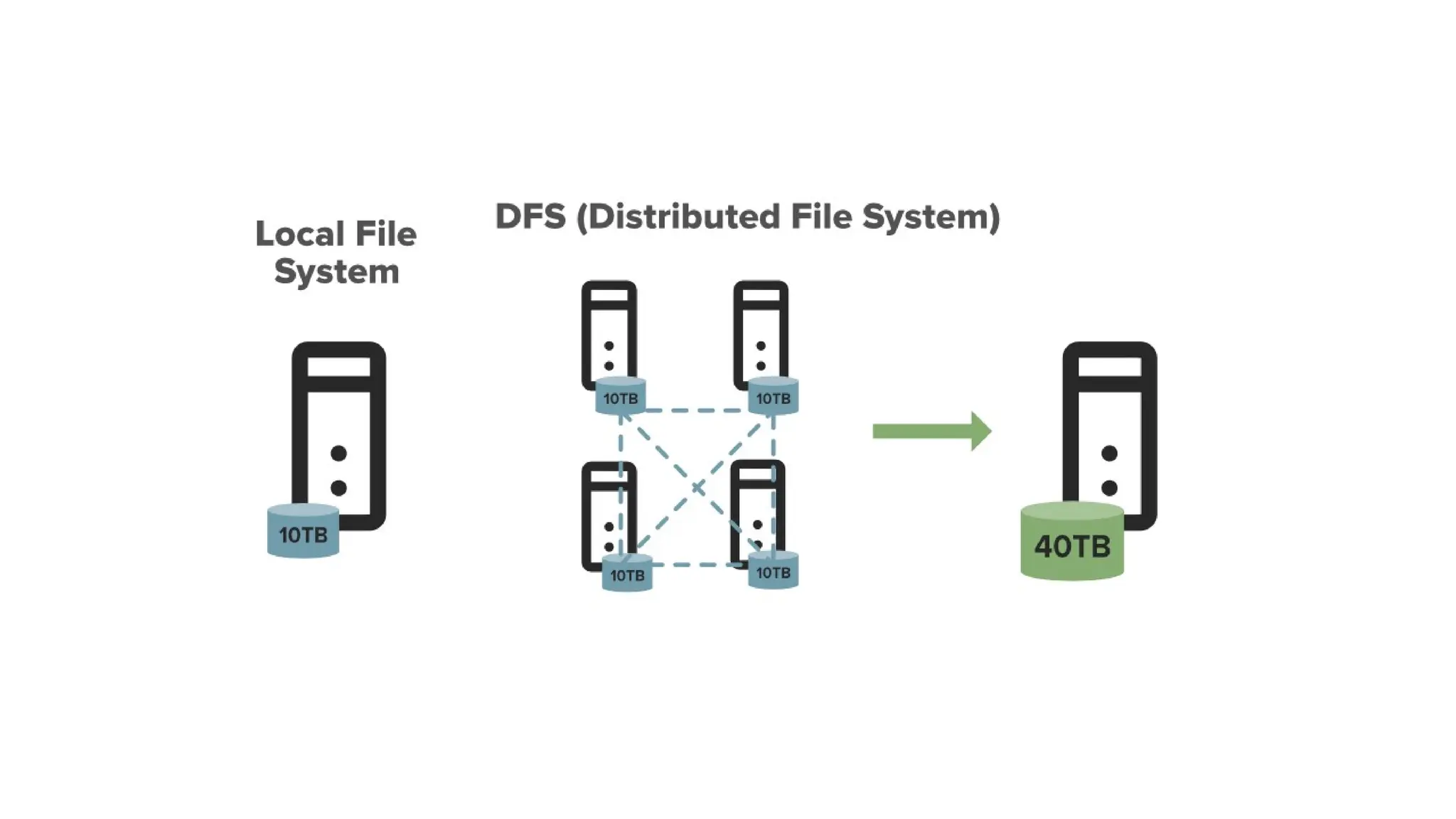
What is DFS?
DFS stands for the distributed file system, it is a concept of storing the file in multiple
nodes in a distributed manner.
DFS actually provides the Abstraction for a single large system whose storage is equal
to the sum of storage of other nodes in a cluster.
Let's understand this with an example. Suppose you have a DFS comprises of 4 different
machines each of size 10TB in that case you can store let say 30TB across this DFS as it
provides you a combined Machine of size 40TB.
The 30TB data is distributed among these Nodes in form of Blocks.
5.
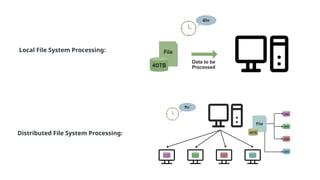
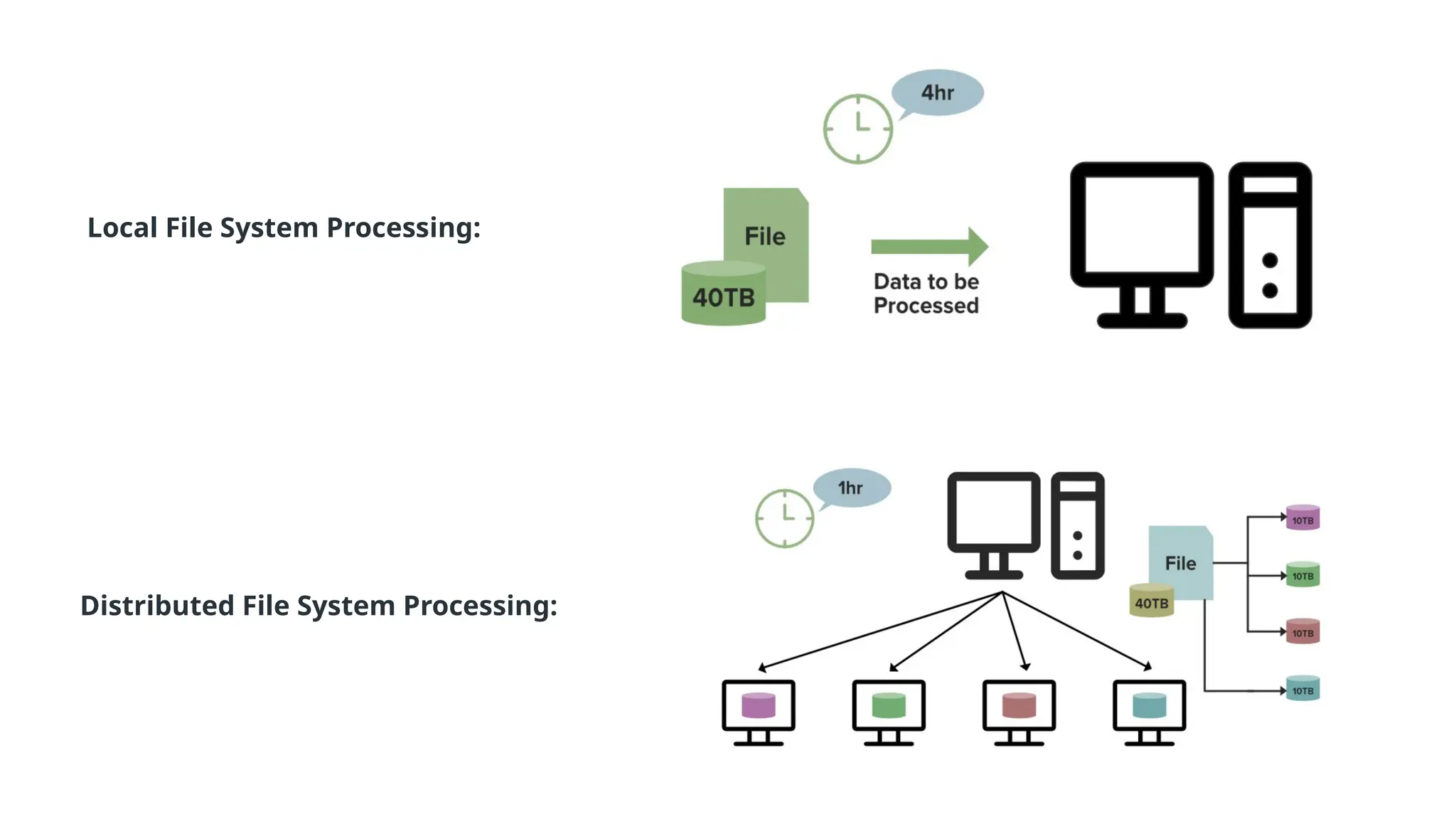
Why We NeedDFS?
You might be thinking that we can store a file of size 30TB in a single system then why
we need this DFS.
This is because the disk capacity of a system can only increase up to an extent.
If somehow you manage the data on a single system then you'll face the processing
problem, processing large datasets on a single machine is not efficient.
Let's understand this with an example. Suppose you have a file of size 40TB to process. On a
single machine, it will take suppose 4hrs to process it completely but what if you use a
DFS(Distributed File System). In that case, as you can see in the below image the File of
size 40TB is distributed among the 4 nodes in a cluster each node stores the 10TB of file. As
all these nodes are working simultaneously it will take the only 1 Hour to completely
HDFS
HDFS(Hadoop DistributedFile System) is utilized for storage permission is a Hadoop
cluster.
HDFS (Hadoop Distributed File System) is optimized for handling and storing large
files. Instead of breaking data into many small blocks, HDFS breaks data into fewer,
larger blocks (typically 128 MB or 256 MB per block).
8.
This designhelps: Reduce the overhead of managing a large number of small blocks.
Improve performance when processing big datasets, since large sequential reads are
more efficient.
Support big data applications, which usually deal with massive files like log files,
videos, or datasets—not small individual records.
HDFS in Hadoop provides Fault-tolerance and High availability to the storage layer and
the other devices present in that Hadoop cluster.
9.
With growingdata velocity the data size easily outgrows the storage limit of a machine.
A solution would be to store the data across a network of machines.
Such filesystems are called distributed filesystems.
Since data is stored across a network all the complications of a network come in.
This is where Hadoop comes in.
It provides one of the most reliable file systems.
HDFS (Hadoop Distributed File System) is a unique design that provides storage
for extremely large files with streaming data access pattern, and it runs on commodity
hardware.
10.
Let's elaborate onthe terms:
•Extremely large files: Here, we are talking about the data in a range of petabytes (1000
TB).
•Streaming Data Access Pattern: HDFS is designed on principle of write-once and read-
many-times. Once data is written large portions of dataset can be processed any number
times.
•Commodity hardware: Hardware that is inexpensive and easily available in the market.
This is one of the features that especially distinguishes HDFS from other file systems.
11.
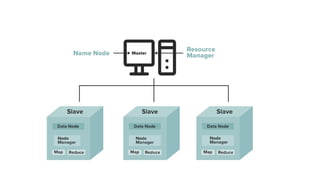
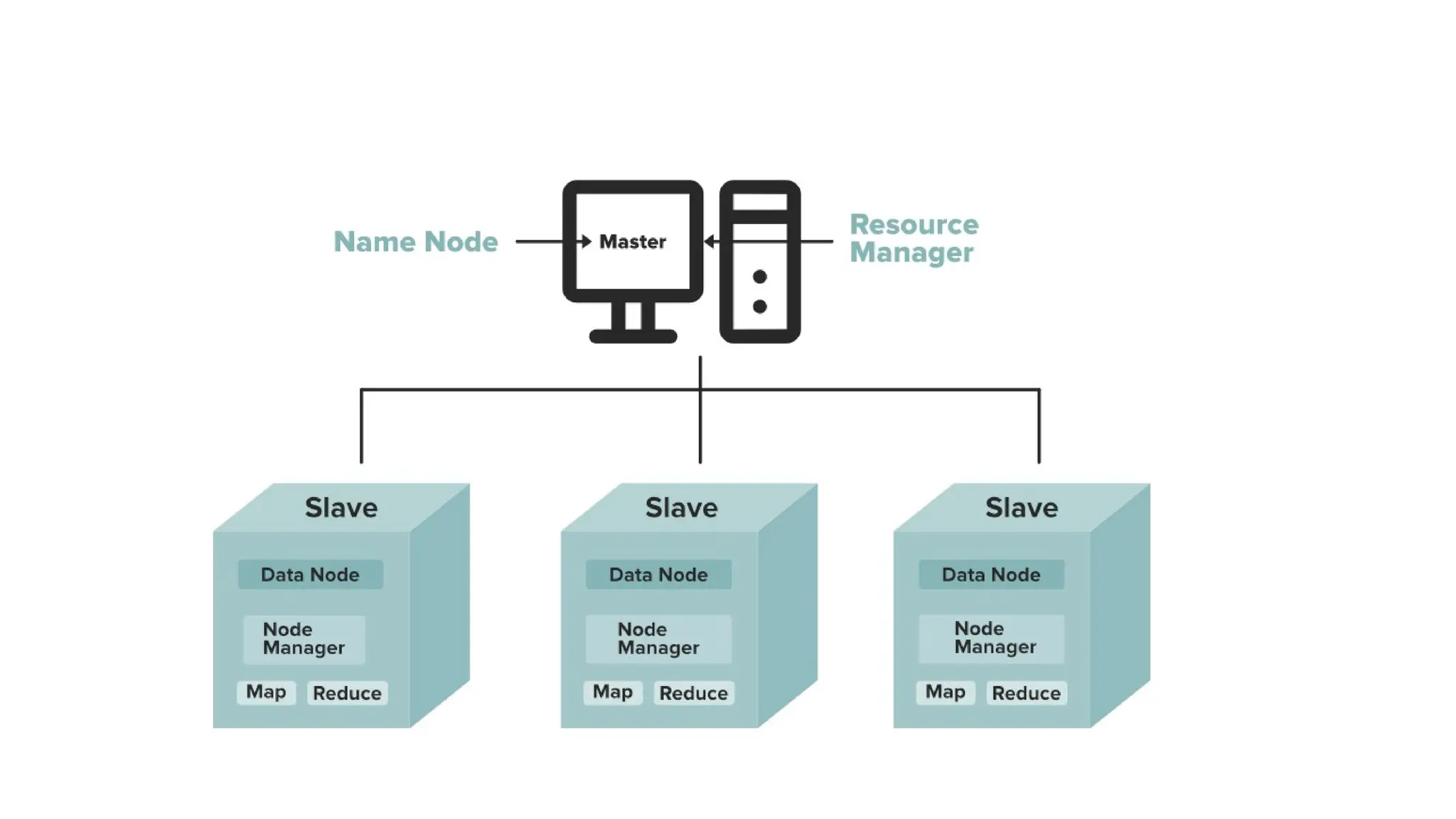
Nodes: Master-slave nodestypically form the HDFS cluster.
NameNode(MasterNode):
Manages all the slave nodes and assigns work to them.
It executes file system namespace operations like opening, closing, and renaming files
and directories.
It should be deployed on reliable hardware that has a high configuration. not on
commodity hardware.
DataNode(SlaveNode):
Actual worker nodes do the actual work like reading, writing, processing, etc.
They also perform creation, deletion, and replication upon instruction from the master.
They can be deployed on commodity hardware.
13.
HDFS daemons: Daemonsare the processes running in the background.
Namenodes:
Run on the master node.
Store metadata (data about data) like file path, the number of blocks, block Ids. etc.
Requires a high amount of RAM.
Store meta-data in RAM for fast retrieval i.e to reduce seek time. Though a persistent
copy of it is kept on disk.
DataNodes:
Run on slave nodes.
Require high memory as data is actually stored here.
14.
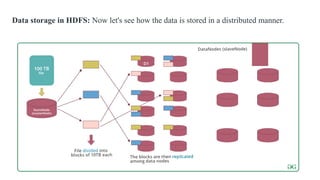
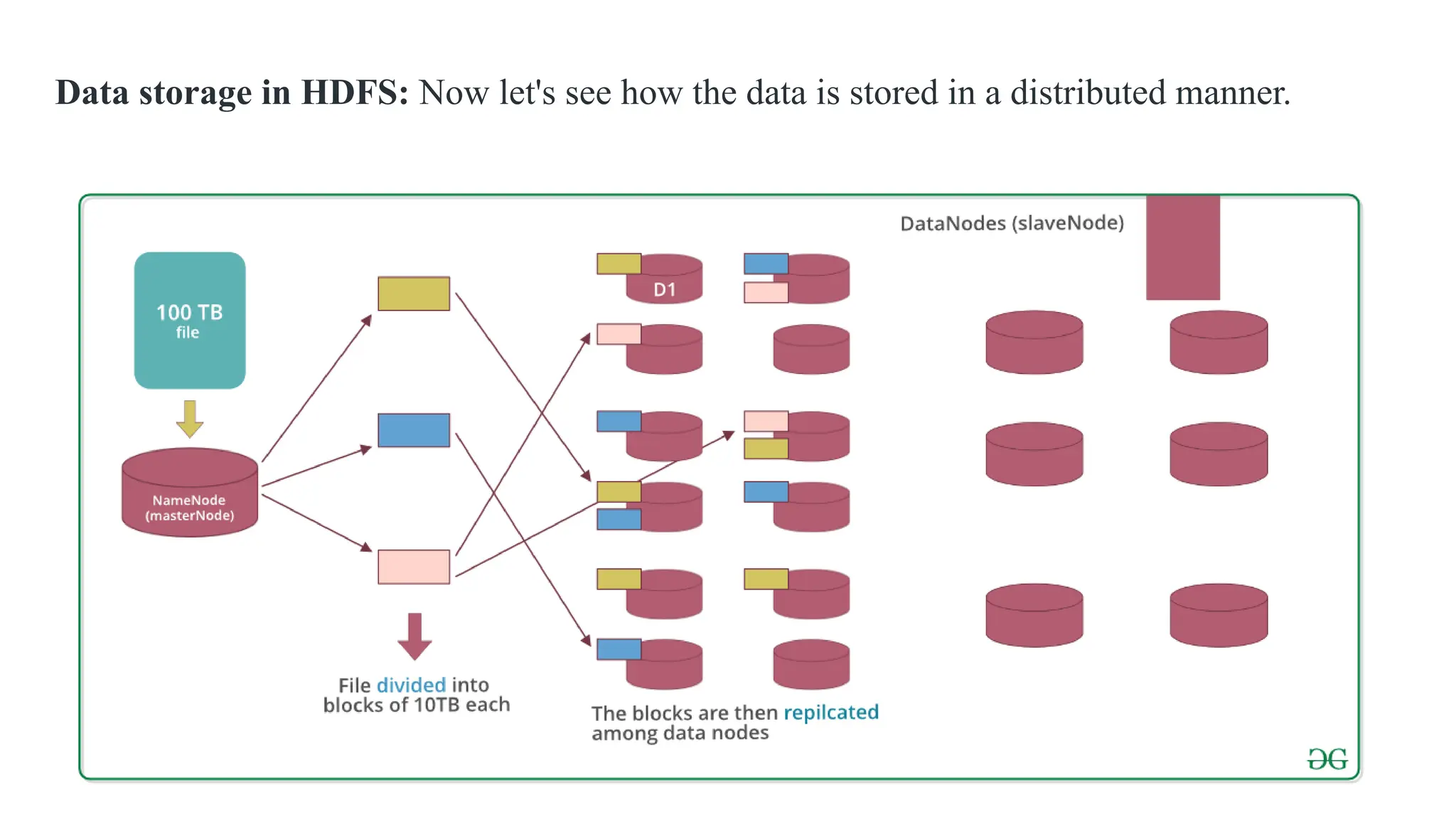
Data storage inHDFS: Now let's see how the data is stored in a distributed manner.
15.
MasterNode has therecord of everything, it knows the location and info of each and every
single data nodes and the blocks they contain, i.e. nothing is done without the permission
of masternode.
16.
Why divide thefile into blocks?
Let's assume that we don't divide, now it's very difficult to store a 100 TB file on a
single machine.
Even if we store, then each read and write operation on that whole file is going to take
very high seek time.
But if we have multiple blocks of size 128MB then its become easy to perform various
read and write operations on it compared to doing it on a whole file at once.
So we divide the file to have faster data access i.e. reduce seek time.
17.
Why replicate theblocks in data nodes while storing?
Let's assume we don't replicate and only one yellow block is present on datanode D1.
Now if the data node D1 crashes we will lose the block and which will make the overall
data inconsistent and faulty.
So we replicate the blocks to achieve fault-tolerance.
18.
Terms related toHDFS:
•HeartBeat : It is the signal that datanode continuously sends to namenode. If namenode
doesn't receive heartbeat from a datanode then it will consider it dead.
•Balancing : If a datanode is crashed the blocks present on it will be gone too and the
blocks will be under-replicated compared to the remaining blocks. Here master
node(namenode) will give a signal to datanodes containing replicas of those lost blocks
to replicate so that overall distribution of blocks is balanced.
•Replication:: It is done by datanode.
19.
HDFS Command LineInterface (CLI)
The HDFS Command Line Interface (CLI) is a set of shell commands provided by
Apache Hadoop to interact with the Hadoop Distributed File System (HDFS).
These commands are used to perform file operations such as copying, moving,
deleting, creating directories, and checking file status within HDFS.
Common HDFS CLICommands
Command Description Example
-ls
Lists files and directories in a given
HDFS directory
hdfs dfs -ls /user/hadoop
-mkdir Creates a new directory in HDFS hdfs dfs -mkdir /user/data
-put Uploads a local file to HDFS hdfs dfs -put localfile.txt /user/data/
-
copyFrom
Local
Same as -put
hdfs dfs -copyFromLocal
localfile.txt /user/data/
22.
-get
Downloads an HDFSfile to local
filesystem
hdfs dfs -get /user/data/file.txt ./
-
copyToLoc
al
Same as -get
hdfs dfs -copyToLocal
/user/data/file.txt ./
-cat
Displays the contents of a file in
HDFS
hdfs dfs -cat /user/data/file.txt
-rm Deletes a file in HDFS hdfs dfs -rm /user/data/file.txt
-rm -r Deletes a directory and its contents hdfs dfs -rm -r /user/data/
-du Shows the size of a file or directory hdfs dfs -du /user/data/
23.
-df Shows availablespace in HDFS hdfs dfs -df -h /
-stat Shows the status of a file hdfs dfs -stat /user/data/file.txt
-
moveFrom
Local
Moves a local file into HDFS
(removes from local)
hdfs dfs -moveFromLocal file.txt
/user/data/
-tail Shows the last kilobyte of the file hdfs dfs -tail /user/data/log.txt
24.
Hadoop File SystemInterfaces
In the world of Big Data, storing and accessing huge amounts of data is a major
challenge for businesses.
Traditional file systems used on regular computers (like Windows File Explorer)
cannot manage the scale and complexity of modern data.
That’s where Hadoop Distributed File System (HDFS) comes in — it’s the
backbone of the Hadoop ecosystem and allows companies to store, access, and
process large-scale data across multiple servers.
25.
To interactwith this powerful file system, Hadoop provides multiple interfaces —
that is, different ways in which users or applications can communicate with HDFS.
These interfaces are like gateways or access points to work with data stored inside
the Hadoop environment.
26.
1. Command LineInterface (CLI)
This is the most basic and widely used interface.
It allows users to perform file system operations using text-based commands — very
similar to how you use commands in Windows Command Prompt or Linux Terminal.
For example, users can:
• Upload or download files
• View directories
• Delete or move files in HDFS
Why it matters for business:
Even non-programmers in operations or support teams can use CLI scripts to automate
file transfers and manage data storage efficiently.
27.
2. Web Interface(HDFS Web UI)
HDFS also offers a browser-based interface that provides a visual way to explore and
manage the file system.
Users can log in through a URL and see the entire structure of HDFS, including files,
directories, and block locations.
28.
3. Java API(Application Programming Interface)
For software developers, Hadoop provides a Java-based API.
This interface allows programs and applications to interact directly with HDFS — for
example, reading a file, writing new data, or checking directory structures
programmatically.
29.
4. HDFS ShellInterface
This is a specialized set of commands designed specifically for interacting with HDFS.
It includes commands like:
•hdfs dfs -ls → list files
•hdfs dfs -put → upload files
•hdfs dfs -get → download files
30.
4. Web Interface(HDFS Web UI)
The NameNode Web UI provides a graphical interface accessible via a web browser
(usually on port 9870). It displays:
•Directory structure of HDFS
•File block details and replication
•DataNode status and health
•Capacity utilization
31.
5. HTTP andREST-based Interface (WebHDFS)
WebHDFS allows remote access to HDFS via HTTP using RESTful web service calls.
This is language-agnostic and can be used with tools like Python, JavaScript, or even
CURL.
Example Request:
http
GET http://namenode:50070/webhdfs/v1/user/hadoop/file.txt?op=OPEN
Use Case: WebHDFS is essential for integrating Hadoop with web applications, APIs, or
remote clients without needing Java or CLI.
32.
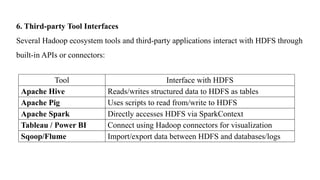
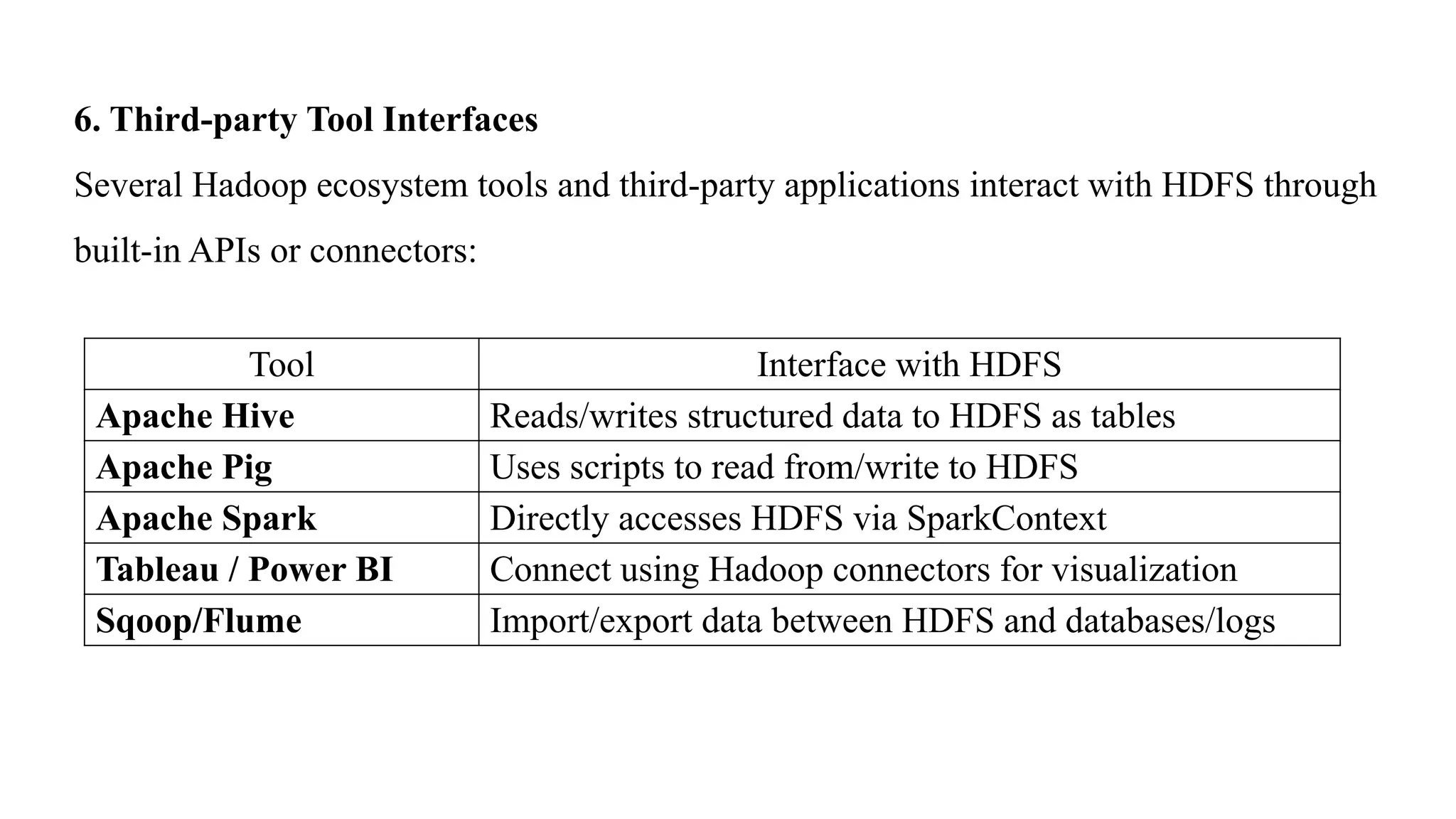
Tool Interface withHDFS
Apache Hive Reads/writes structured data to HDFS as tables
Apache Pig Uses scripts to read from/write to HDFS
Apache Spark Directly accesses HDFS via SparkContext
Tableau / Power BI Connect using Hadoop connectors for visualization
Sqoop/Flume Import/export data between HDFS and databases/logs
6. Third-party Tool Interfaces
Several Hadoop ecosystem tools and third-party applications interact with HDFS through
built-in APIs or connectors:
33.
HDFS Data Flow
TheHadoop Distributed File System (HDFS) is the backbone of data storage in
Hadoop. It is designed for reliable, fault-tolerant, and distributed storage of large-
scale datasets. To fully understand how HDFS operates, it’s important to study the
data flow — that is, how data moves into, within, and out of the system.
There are two main types of data flow in HDFS:
1.Write Data Flow – how data is written/uploaded into HDFS
2.Read Data Flow – how data is retrieved from HDFS
34.
HDFS Write DataFlow (Uploading Data)
When a client uploads a file to HDFS (e.g., using hdfs dfs -put), the process involves
multiple components working together: the client, the NameNode, and multiple DataNodes.
🔸 Step-by-Step Flow:
1.Client Requests to Upload:
The HDFS client requests the NameNode to upload a file. The NameNode is the master that
manages metadata — file names, block locations, permissions, etc.
2.NameNode Checks and Responds:
The NameNode checks if the file already exists, calculates how many blocks are needed, and
chooses the best DataNodes for storing those blocks (usually 3 replicas per block).
35.
3.Data is Splitinto Blocks:
The file is divided into blocks (default size = 128 MB or 256 MB). These blocks are not stored in one place
but distributed across different DataNodes.
4.Pipelined Writing Begins:
The client starts sending data to the first DataNode. This DataNode forwards the data to the second, and so
on, forming a pipeline of DataNodes.
5.Replication Happens in the Pipeline:
As one DataNode receives a block, it forwards a copy to the next one until all replicas are created.
5. Acknowledgement:
Once all DataNodes confirm they’ve stored the block, an acknowledgement is sent back to the client,
36.
2. HDFS ReadData Flow (Downloading Data)
When a client wants to read/download a file from HDFS, the process is optimized for speed
and fault-tolerance.
🔸 Step-by-Step Flow:
1.Client Requests File from NameNode:
The client asks the NameNode for the location of the file it wants to read.
2.NameNode Responds with Metadata:
The NameNode doesn’t send the file — it only replies with the locations of the blocks and
the list of DataNodes that hold those blocks.
37.
3. Client Connectsto DataNodes:
The client directly contacts the nearest or least-loaded DataNode to retrieve each block.
4. Blocks are Fetched and Reassembled:
As each block is downloaded, the client reassembles them into the original file.
5. Automatic Failover:
If a DataNode is down, the client will switch to another replica of the same block without
interrupting the process.
38.
3. Security andAccess Control in Data Flow
•Authentication (e.g., via Kerberos) ensures only authorized users access data
•Permissions control file access (like Linux: read, write, execute)
•Data is encrypted in transit and optionally at rest (for security-sensitive applications)
39.
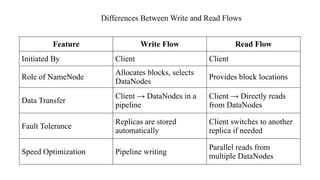
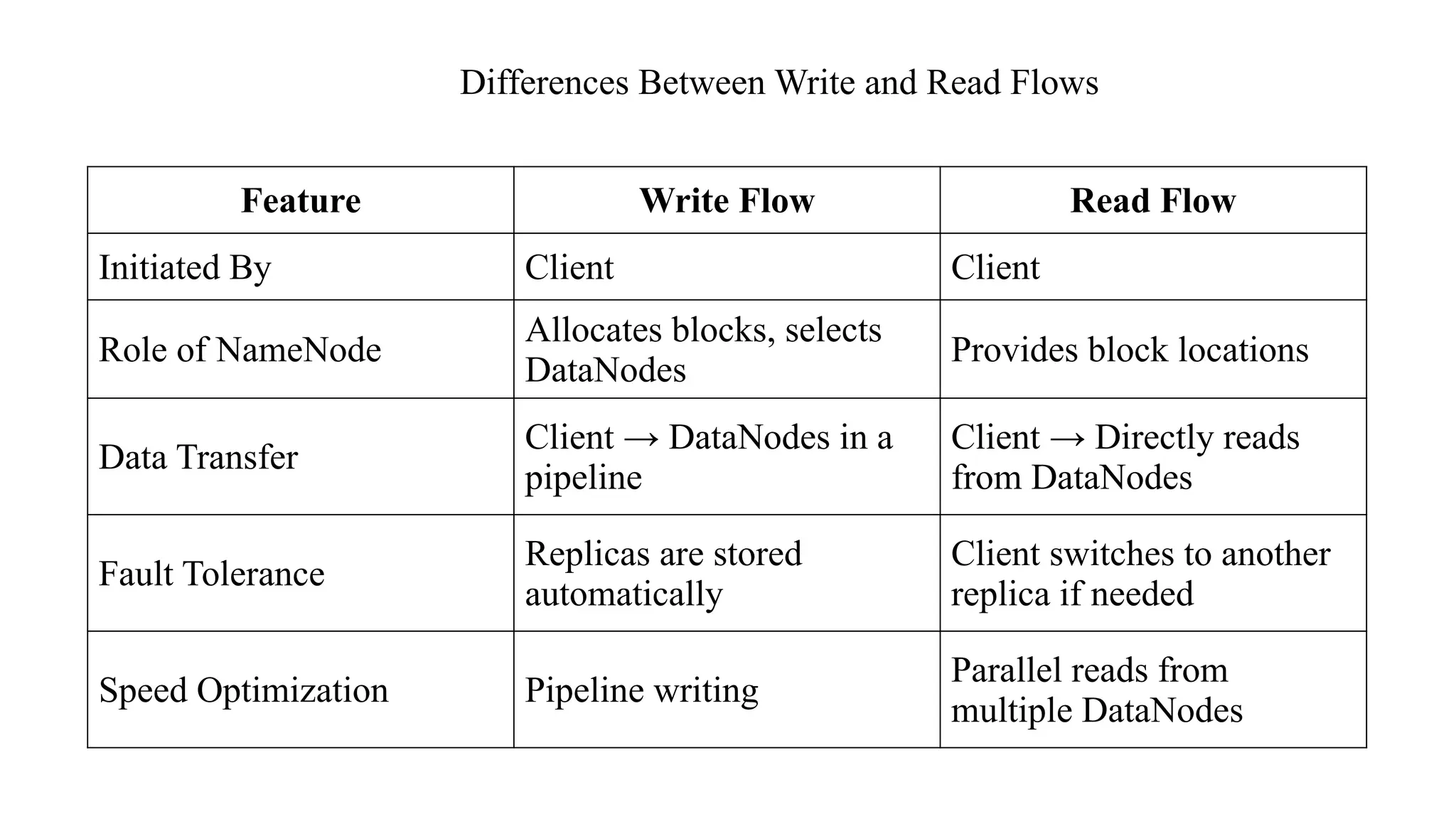
Differences Between Writeand Read Flows
Feature Write Flow Read Flow
Initiated By Client Client
Role of NameNode
Allocates blocks, selects
DataNodes
Provides block locations
Data Transfer
Client → DataNodes in a
pipeline
Client → Directly reads
from DataNodes
Fault Tolerance
Replicas are stored
automatically
Client switches to another
replica if needed
Speed Optimization Pipeline writing
Parallel reads from
multiple DataNodes
40.
What is DataIngestion
Data Ingestion is the process of collecting and importing data from various
sources into a centralized system, such as a data lake, data warehouse, or Hadoop
Distributed File System (HDFS), for storage, analysis, and further processing.
It is the first step in any Big Data pipeline — before data can be cleaned, processed,
analyzed, or visualized, it must be ingested into the system.
41.
Types of DataIngestion
1.Batch Ingestion
1. Data is collected and imported at regular intervals (hourly, daily).
2. Example: Importing yesterday’s sales data every morning.
3. Tools: Apache Sqoop, Kafka, ETL tools
2.Real-Time (Streaming) Ingestion
1. Data is collected continuously as it is generated.
2. Example: Streaming live tweets, website clicks, or sensor data.
3. Tools: Apache Flume, Apache Kafka, NiFi
42.
Why Data Ingestionis Important in Big Data
•Centralizes Data from different systems (RDBMS, logs, cloud storage)
•Enables faster decision-making using real-time insights
•Supports machine learning models, dashboards, and reports
•Powers ETL pipelines (Extract, Transform, Load)
•Helps organizations create a unified data platform
43.
Data Ingestion withApache Flume
What is Apache Flume?
Apache Flume is a distributed, reliable, and scalable data ingestion service designed
for collecting, aggregating, and transporting large volumes of log or event data
from multiple sources into destinations such as the Hadoop Distributed File System
(HDFS) or HBase.
Flume is best suited for:
• Streaming data
• Real-time log files
• Event-based data (from sensors, web servers, social platforms, etc.)
44.
Purpose of Flumein Big Data
Big Data systems need to collect raw data continuously from sources like:
• Application logs (e.g., from web or mobile servers)
• Social media feeds (e.g., Twitter)
• IoT sensor data
• Email or system logs
Apache Flume acts as a pipeline that moves this real-time or semi-structured data into
Hadoop so it can be stored and analyzed.
45.
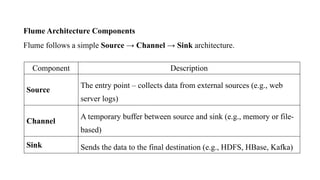
Flume Architecture Components
Flumefollows a simple Source → Channel → Sink architecture.
Component Description
Source
The entry point – collects data from external sources (e.g., web
server logs)
Channel
A temporary buffer between source and sink (e.g., memory or file-
based)
Sink Sends the data to the final destination (e.g., HDFS, HBase, Kafka)
47.
1. Flume Source(Data Inlet)
Definition:
The Source is the entry point of data into a Flume agent. It collects data from
an external source and transforms it into a Flume Event.
How it Works:
• It listens to a data stream from an external source like log files, applications, or
network services.
• The received data is converted into Flume events (with headers and body).
• These events are then passed into the Channel.
48.
Flume Channel (Bufferor Data Holding Area)
Definition:
The Channel is a temporary storage layer (like a buffer) that connects the
Source to the Sink. It holds the events until the Sink is ready to process them.
How it Works:
• After the source pushes data, it is stored in the channel.
• The channel acts like a queue.
• The Sink reads events from the channel asynchronously.
49.
Flume Sink (DataOutlet)
Definition:
The Sink delivers events from the Channel to the final destination — such as
HDFS, HBase, Elasticsearch, another Flume agent, or a custom store.
How it Works:s
• The sink continuously polls the channel for new events.
• Once events are fetched, they are batched and sent to the target system.
50.
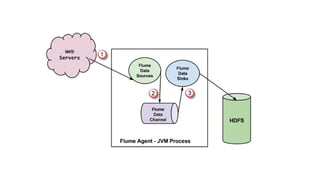
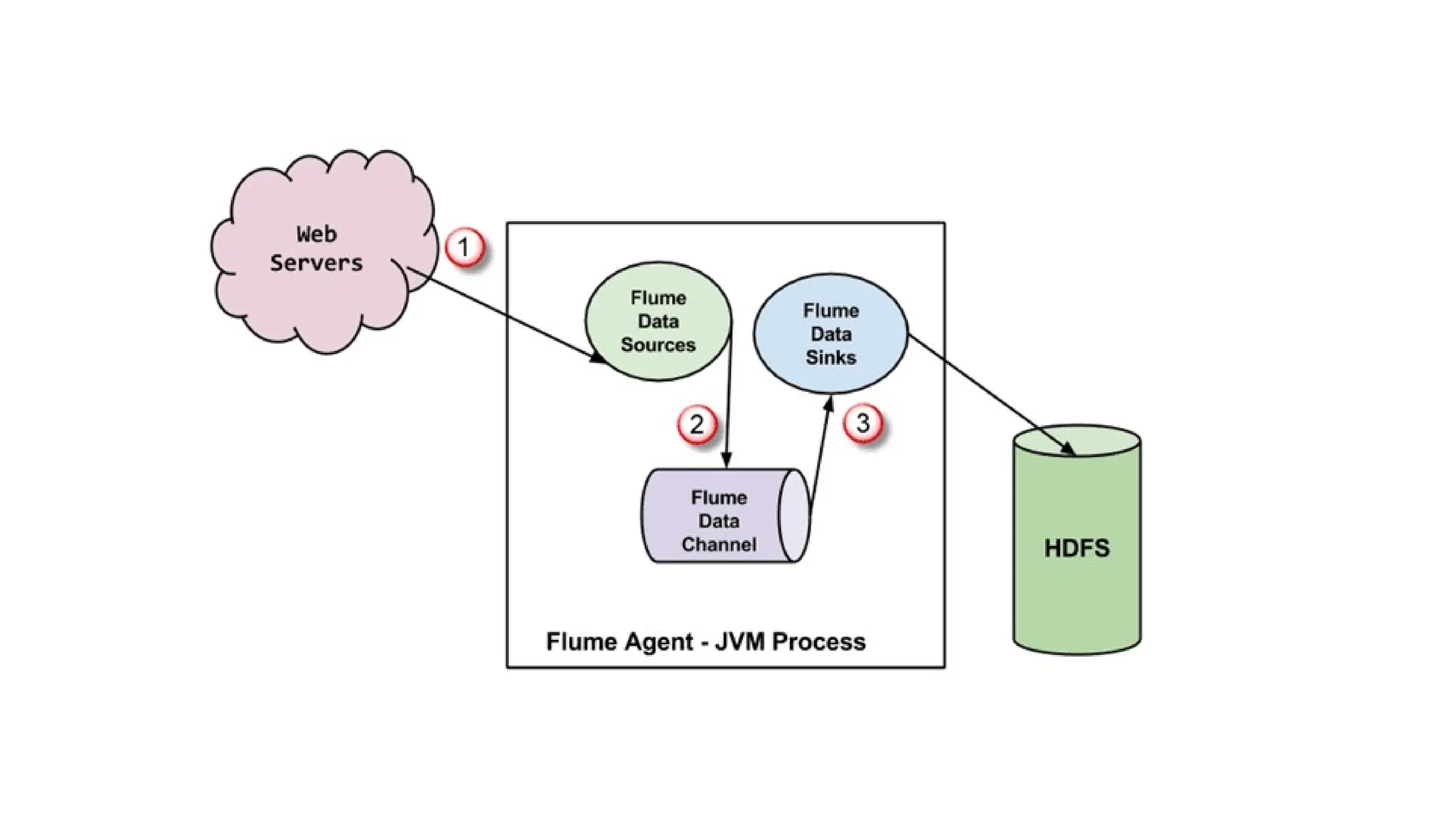
Data Flow inFlume
Let’s consider an example:
An e-commerce website collects user activity logs and wants to analyze them
in Hadoop.
Data Flow:
Web Server Logs (Source)
↓
Flume Agent → Memory Channel
↓
Sink → HDFS
So, every log entry from the web server is:
1.Captured by Flume’s Source (e.g., tailing a log file)
2.Temporarily stored in the Channel
3.Sent to HDFS via the Sink
This happens in real-time and continuously, without manual intervention.
51.
Data Ingest withScoop
What is Apache Sqoop?
Apache Sqoop is a tool that helps transfer data from traditional databases (like
MySQL, Oracle, SQL Server) into Hadoop systems like HDFS, Hive, or HBase — and
vice versa.
Think of Sqoop as a bridge that connects structured data stored in databases with
the Big Data world.
52.
Why is SqoopImportant in Big Data?
Most companies already have valuable business data (like customer records,
orders, employee data) stored in relational databases. But to analyze large volumes of
this data, they use Big Data platforms like Hadoop.
Sqoop helps to:
• Import this data from databases into Hadoop systems for analysis.
• Export processed data back to the original database for business use.
53.
How Sqoop Works(Conceptually):
1.Connects to the Database
Sqoop connects to the business database where structured data like sales or customer
info is stored.
2.Brings Data into Hadoop
It copies the required data from the database and stores it in HDFS or Hive (Hadoop
components used for storage and analysis).
54.
3.Analysis Happens inHadoop
1.Data analysts or data scientists run Big Data tools to process this imported data — like
finding trends, patterns, or making forecasts.
4.Sends Results Back (if needed)
Sqoop can also send the analyzed data back into the original database so that business
systems (like dashboards or CRMs) can use it.
55.
Business Use CaseExample:
•A retail company wants to analyze customer purchase history.
•All the purchase data is stored in a MySQL database.
•Using Sqoop, the company imports this data into Hadoop.
•Hadoop performs complex analysis like predicting buying behavior.
•Final reports or scored customer lists are sent back to the database for use in sales or
marketing tools.
56.
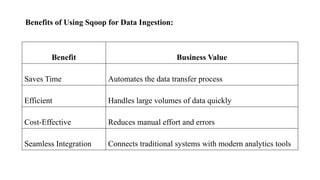
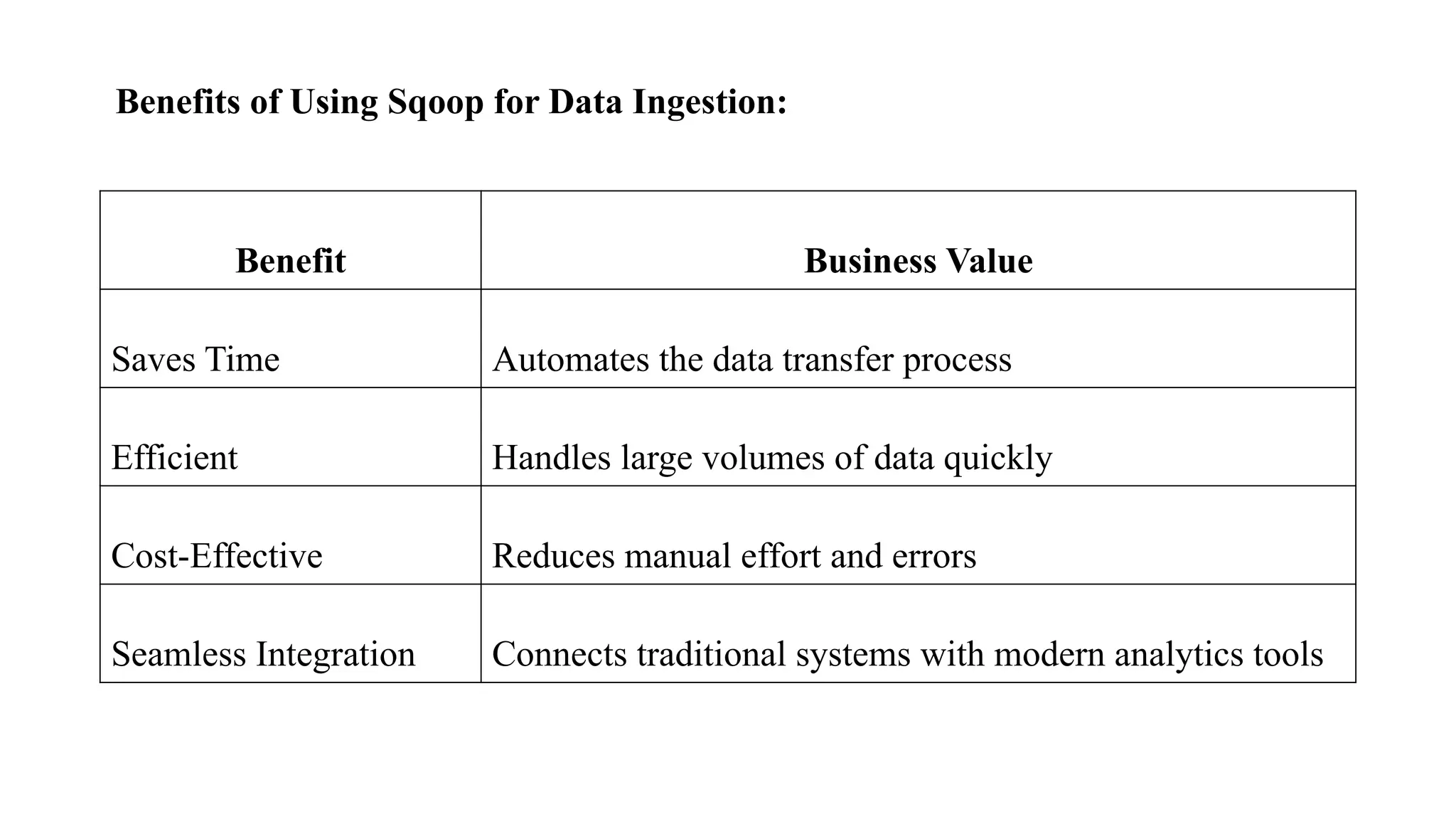
Benefits of UsingSqoop for Data Ingestion:
Benefit Business Value
Saves Time Automates the data transfer process
Efficient Handles large volumes of data quickly
Cost-Effective Reduces manual effort and errors
Seamless Integration Connects traditional systems with modern analytics tools
57.
Data Ingest withHadoop Archives
What is a Hadoop Archive (HAR)?
In big data systems like Hadoop, data is usually stored in large blocks in the
HDFS (Hadoop Distributed File System). But when there are a lot of small files, it
can reduce efficiency and waste storage.
Hadoop Archives (HAR) is a storage format used to combine many small
files into one large archive file, making storage more efficient and easier to manage.
58.
Why is itneeded?
HDFS is designed to work best with large files, not many small ones. When there
are thousands of small files, it creates problems:
• High memory usage in the NameNode (which manages file metadata).
• Slower performance during file access.
• Poor storage efficiency.
What does HAR do?
A HAR file groups many small files into a single large archive — like a zip file
— but it still lets you access each individual file without extracting the archive.
So instead of having 10,000 separate files, HDFS sees just one HAR file,
reducing the system's overhead.
59.
Why Use HARin Data Ingestion?
When data is being ingested (i.e., brought into Hadoop), especially from external systems,
we might end up with thousands of tiny files — for example:
• Transaction logs
• Sensor readings
• Daily reports
Storing each small file separately in HDFS is not efficient. This is where HAR comes in:
• Combining many small files into a single archive.
• Reducing the load on the NameNode (which manages file metadata in Hadoop).
• Improving storage efficiency.
• Simplifying data management.
60.
How HAR Helpsin the Ingestion Process:
1.Data Collection:
1. Data is collected from various sources such as websites, IoT devices, or logs.
2. This data may be stored as many small files.
2.Archiving with HAR:
1. These small files are grouped together into a Hadoop Archive (HAR file).
2. It looks like one big file to Hadoop, but still allows access to the original files inside.
3.Storing in HDFS:
1. The HAR file is then stored in HDFS as part of the ingestion process.
2. This improves performance, especially during data analysis.
61.
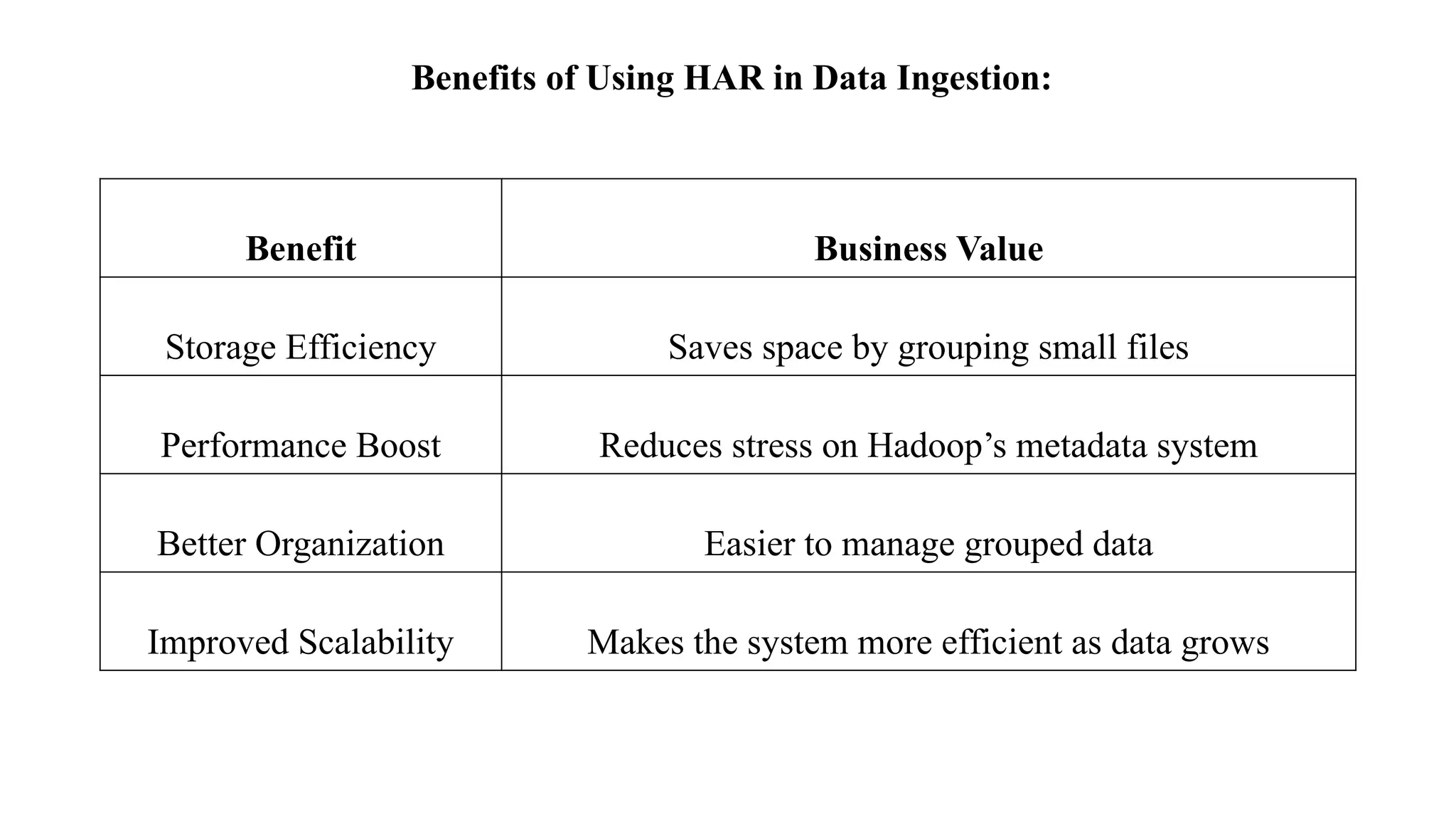
Benefits of UsingHAR in Data Ingestion:
Benefit Business Value
Storage Efficiency Saves space by grouping small files
Performance Boost Reduces stress on Hadoop’s metadata system
Better Organization Easier to manage grouped data
Improved Scalability Makes the system more efficient as data grows
62.
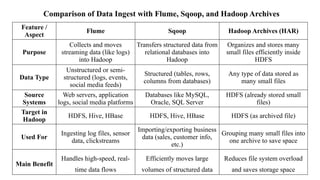
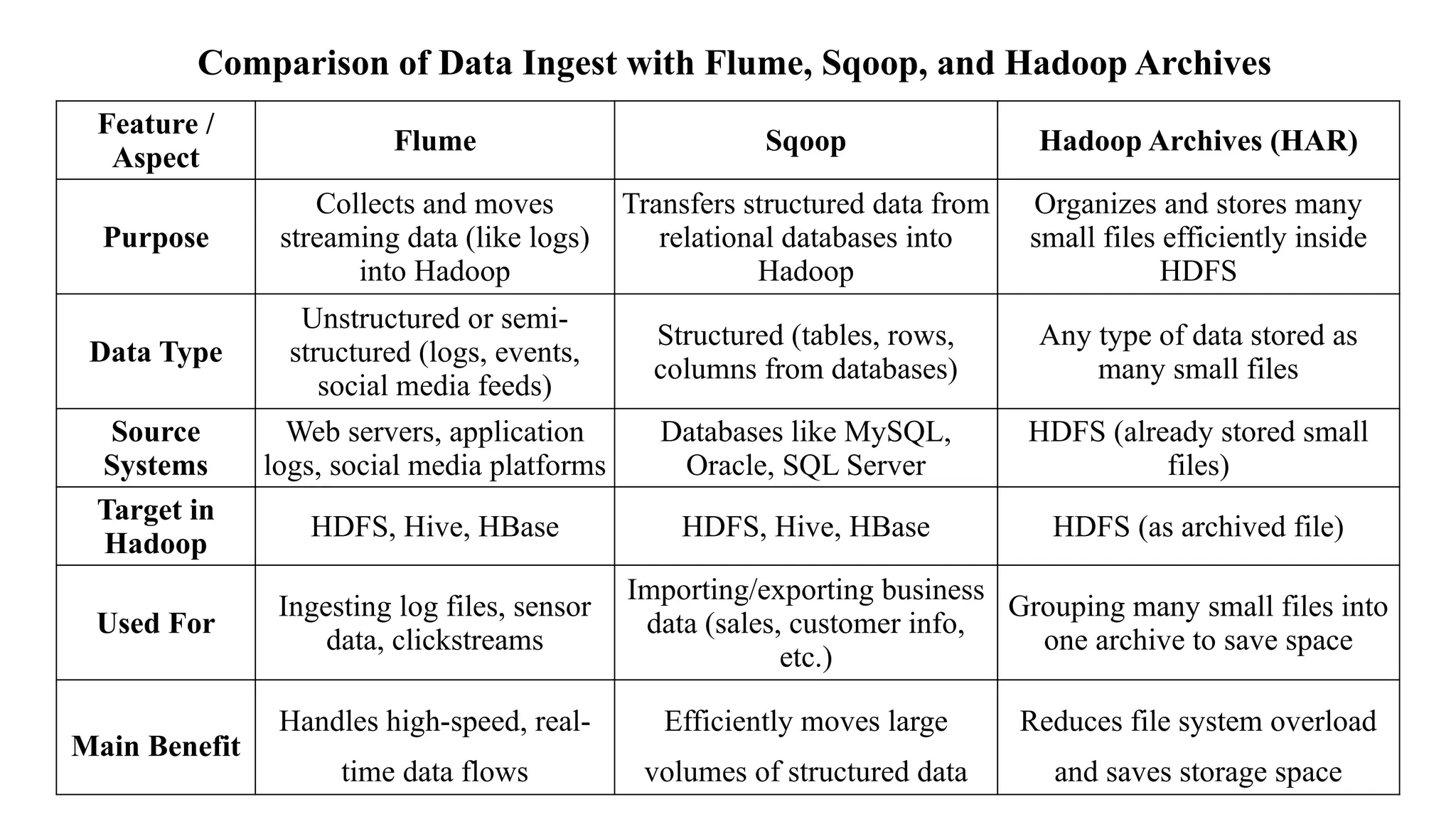
Comparison of DataIngest with Flume, Sqoop, and Hadoop Archives
Feature /
Aspect
Flume Sqoop Hadoop Archives (HAR)
Purpose
Collects and moves
streaming data (like logs)
into Hadoop
Transfers structured data from
relational databases into
Hadoop
Organizes and stores many
small files efficiently inside
HDFS
Data Type
Unstructured or semi-
structured (logs, events,
social media feeds)
Structured (tables, rows,
columns from databases)
Any type of data stored as
many small files
Source
Systems
Web servers, application
logs, social media platforms
Databases like MySQL,
Oracle, SQL Server
HDFS (already stored small
files)
Target in
Hadoop
HDFS, Hive, HBase HDFS, Hive, HBase HDFS (as archived file)
Used For
Ingesting log files, sensor
data, clickstreams
Importing/exporting business
data (sales, customer info,
etc.)
Grouping many small files into
one archive to save space
Main Benefit
Handles high-speed, real-
time data flows
Efficiently moves large
volumes of structured data
Reduces file system overload
and saves storage space
63.
Summary
Tool Best UsedFor
Flume Real-time ingestion of logs, social media feeds, or sensor data
Sqoop Importing/exporting structured data from traditional databases
HAR Organizing many small files into large archives to improve efficiency
64.
Data Compression Techniquesin Hadoop Framework
There are many challenges like Input/Output(I/O) which will frequently appear when
working with the Hadoop framework to process massive data.
This topic is to understanding of different data compression techniques available in the
Hadoop framework to solve this problem.
65.
What is HadoopI/O?
Hadoop I/O refers to the input and output operations involved in reading data
into the Hadoop system and writing data out of it — especially during MapReduce
processing.
In simple terms, it manages how Hadoop reads data from storage, processes it,
and then writes results back.
66.
Why is HadoopI/O Important?
• Hadoop works with huge volumes of data stored in the HDFS.
• For processing to happen efficiently, data must be read (input) and written (output) in a
way that Hadoop can handle — this is where Hadoop I/O comes in.
• It ensures efficient data access, compression, and serialization (converting data to/from
a format that Hadoop can understand).
67.
Key Concepts inHadoop I/O:
1. Input Format
• Defines how data is read from HDFS.
• Splits large files into blocks and assigns them to different tasks.
• Example: Reading lines from a text file or reading records from a database.
2. Output Format
• Defines how results are written back to storage after processing.
• It could be plain text, key-value pairs, or custom formats.
3. Serialization
• Converts data into a format that can be stored or transmitted.
• Hadoop uses Writable (a lightweight format) to handle this efficiently.
68.
4. Compression
•Reduces thesize of the data while storing or transferring.
•Helps save space and time, especially during big data jobs.
5. Data Types
•Hadoop I/O uses its own custom data types (like IntWritable, Text, etc.) for
performance and compatibility across nodes in the cluster.
69.
Compression in Hadoop
Whatis it?
Compression means reducing the size of data files to save storage space and
speed up data transfer.
Why is it important?
• Big Data files can be huge. Without compression, Hadoop jobs take longer to run and
require more disk space.
• Compressed files are faster to read/write during processing.
70.
There are twotypes of compression techniques: lossless compression
and lossy compression.
Lossless Compression
In lossless compression, the compressed data can be fully recovered to its original form
without any loss of information.
It achieves this by identifying and removing redundant or repetitive patterns within the
data. Common lossless compression algorithms include Gzip and Deflate.
Lossless compression is used when it is crucial to retain the accuracy and integrity of the
data.
71.
Lossy Compression
Lossycompression, on the other hand, sacrifices some degree of data accuracy for more
significant compression ratios.
It achieves higher compression by discarding less essential or perceptually insignificant
data.
Lossy compression techniques are widely used in multimedia applications, such as image
and video compression.
Popular algorithms like JPEG and MP3 employ lossy compression to achieve significant
file size reductions
72.
Importance of DataCompression in Hadoop
In the context of Apache Hadoop, data compression plays a vital role in several
aspects, including
Storage cost optimization
Network bandwidth efficiency
Query and processing performance.
Storage Cost Optimization
By compressing data before storing it in the Hadoop Distributed File System (HDFS),
organizations can optimize their storage infrastructure.
Compressed data occupies less disk space, leading to reduced storage costs.
Efficient data compression can significantly impact large-scale data processing
scenarios, as data volumes are often immense in Hadoop environments.
73.
Network Bandwidth Efficiency
When transmitting data across a network, especially on distributed Hadoop
clusters, compression reduces the amount of data that needs to be transferred.
This results in reduced network bandwidth requirements, allowing
organizations to achieve faster and more efficient data transfer between nodes.
Query and Processing Performance
Compressed data requires less I/O (input/output) and disk read operations,
leading to faster query and processing times.
Compression speeds up data retrieval and processing as it reduces the amount
of data that needs to be read from disk, minimizing disk I/O bottlenecks.
74.
Hadoop compression formats
Thereare many different compression formats available in Hadoop framework. You
will have to use one that suits your requirement.
Parameters that you need to look for are-
Time it takes to compress.
Space saving.
Compression format is splittable or not.
Deflate– It is the compression algorithm whose implementation is zlib. Defalte compression
algorithm is also used by gzip compression tool. Filename extension is .deflate.
gzip- gzip compression is based on Deflate compression algorithm. Gzip compression is not as
fast as LZO or snappy but compresses better so space saving is more.
Filename extension is .gz.
75.
bzip2- Using bzip2for compression will provide higher compression ratio but the
compressing and decompressing speed is slow. Filename extension is .bz2.
Snappy– The Snappy compressor from Google provides fast compression and
decompression but compression ratio is less.
Filename extension is .snappy.
LZO– LZO, just like snappy is optimized for speed so compresses and decompresses
faster but compression ratio is less.
Filename extension is .lzo.
76.
LZ4– Has fastcompression and decompression speed but compression ratio is less. LZ4 is
not splittable.
Filename extension is .lz4.
Zstandard– Zstandard is a real-time compression algorithm, providing high compression
ratios. It offers a very wide range of compression / speed trade-off.
77.
Serialization in Hadoop
Serialization is the process of converting in-memory data structures or
objects into a format suitable for storage or transmission.
In Apache Hadoop, serialization is essential for efficiently transferring data
between the Map and Reduce tasks and for persisting data in HDFS.
Hadoop provides various serialization frameworks like Apache
Avro, Apache Thrift, and Apache Parquet, which offer compact binary
serialization formats suitable for storing and processing big data efficiently.
These frameworks allow developers to define schemas and automatically
generate code to serialize and deserialize data, eliminating the overhead of manual
serialization implementations.
78.
Why Data Serializationfor Storage Formats?
•To process records faster (Time-bound).
•When proper data formats need to maintain and transmit over data without schema
support on another end.
•Now when in the future, data without structure or format needs to process, complex Errors
may occur.
•Serialization offers data validation over transmission.
79.
Avro
Apache Avro isa language-neutral data serialization system.
It was developed by Doug Cutting, the father of Hadoop.
Since Hadoop writable classes lack language portability, Avro becomes quite helpful, as it
deals with data formats that can be processed by multiple languages.
Avro is a preferred tool to serialize data in Hadoop.
Avro has a schema-based system.
80.
A language-independentschema is associated with its read and write operations.
Avro serializes the data which has a built-in schema.
Avro serializes the data into a compact binary format, which can be deserialized by any
application.
Avro uses JSON format to declare the data structures.
Presently, it supports languages such as Java, C, C++, C#, Python, and Ruby.
81.
Avro Schemas
Avrodepends heavily on its schema.
It allows every data to be written with no prior knowledge of the schema.
It serializes fast and the resulting serialized data is lesser in size.
Schema is stored along with the Avro data in a file for any further processing.
The client and the server exchange schemas during the connection.
This exchange helps in the communication between same named fields, missing fields,
extra fields, etc.
Avro schemas are defined with JSON that simplifies its implementation in languages
with JSON libraries.
82.
Key Features ofAvro:
Schema-based: Every Avro data file contains the schema (in JSON format) that
defines the data structure.
Row-oriented: Data is stored in rows, making it efficient for write-heavy
applications.
Compact & Efficient: Binary format minimizes space and improves processing
speed.
Dynamic Typing: Data and schema are tightly coupled—no need for pre-generated
code.
Interoperability: Supports multiple languages like Java, Python, C++, Ruby, etc.
83.
General Working ofAvro
To use Avro, you need to follow the given workflow −
•Step 1 − Create schemas. Here you need to design Avro schema according to your data.
•Step 2 − Read the schemas into your program. It is done in two ways −
•Step 3 − Serialize the data using the serialization API provided for Avro, which is found in
the package org.apache.avro.specific.
•Step 4 − Deserialize the data using deserialization API provided for Avro, which is found in
the package org.apache.avro.specific.
84.
Avro in Hadoop
ApacheAvro is a popular row-oriented data serialization framework used in
Hadoop for data exchange and persistence.
What is Avro?
Avro is a data serialization system developed by Apache to support data-
intensive applications.
It provides a compact, fast, binary data format with rich data structures.
Avro is often used in Hadoop MapReduce for storing and exchanging large
volumes of data across nodes.
85.
Avro File Structure:
AnAvro file contains:
• Header: Contains file metadata and schema in JSON.
• Data Blocks: Compressed binary data serialized using the schema.
Example Avro Schema (JSON Format):
{
"type": "record",
"name": "Employee",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "salary", "type": "float"}
]
}
86.
Advantages of Avroin Hadoop:
• Self-describing: Schema stored with data.
• Splittable and compressible: Suitable for large data files.
• Used with Hive, Pig, and MapReduce.
87.
File-Based Data Structuresin Hadoop
In Hadoop, file-based data structures refer to how data is stored and formatted on
disk within the Hadoop Distributed File System (HDFS).
These data structures are file formats that influence how data is read, written,
serialized, compressed, and split across nodes for processing.
88.
Why File-Based DataStructures Matter
•Performance: Determines the speed of reading/writing data.
•Compression: Affects storage space and I/O bandwidth.
•Splittability: Impacts parallel processing in MapReduce and Spark.
•Compatibility: Some formats are optimized for specific tools (e.g., Hive, Pig, Spark).
89.
Types of File-BasedData Structures
Text Files (Plain Text, CSV, TSV)
•Description: Stores data in human-readable text format, line by line.
•Format: Rows with fields separated by commas or tabs.
•Pros:
• Simple and readable
• Easy to create and use
•Cons:
• Inefficient in space and speed
• No schema, so data parsing is difficult
•Use Case: Logging, initial data load
90.
SequenceFile
•Description: A binaryformat to store key-value pairs, mainly used in MapReduce.
•Components:
• Key and value class names
• Record data
•Pros:
• Binary, thus compact
• Splittable and compressible
• Optimized for MapReduce input/output
•Cons:
• Not human-readable
•Use Case: Intermediate output of MapReduce
91.
Avro
•Description: Row-based binaryformat that includes a JSON schema.
•Pros:
• Supports schema evolution
• Compact and fast
• Language-independent
• Suitable for serializing structured data
•Cons:
• Schema processing overhead
•Use Case: Data exchange between services, storage with schema










































































![Avro File Structure:
An Avro file contains:
• Header: Contains file metadata and schema in JSON.
• Data Blocks: Compressed binary data serialized using the schema.
Example Avro Schema (JSON Format):
{
"type": "record",
"name": "Employee",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "salary", "type": "float"}
]
}](https://image.slidesharecdn.com/mb4332-unit2-250929110810-82b76bc9/85/HDFS-Hadoop-Distributed-File-System-Unit-2-pptx-85-320.jpg)
















































































![Avro File Structure:
An Avro file contains:
• Header: Contains file metadata and schema in JSON.
• Data Blocks: Compressed binary data serialized using the schema.
Example Avro Schema (JSON Format):
{
"type": "record",
"name": "Employee",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "salary", "type": "float"}
]
}](https://image.slidesharecdn.com/mb4332-unit2-250929110810-82b76bc9/75/HDFS-Hadoop-Distributed-File-System-Unit-2-pptx-85-2048.jpg)





























































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
