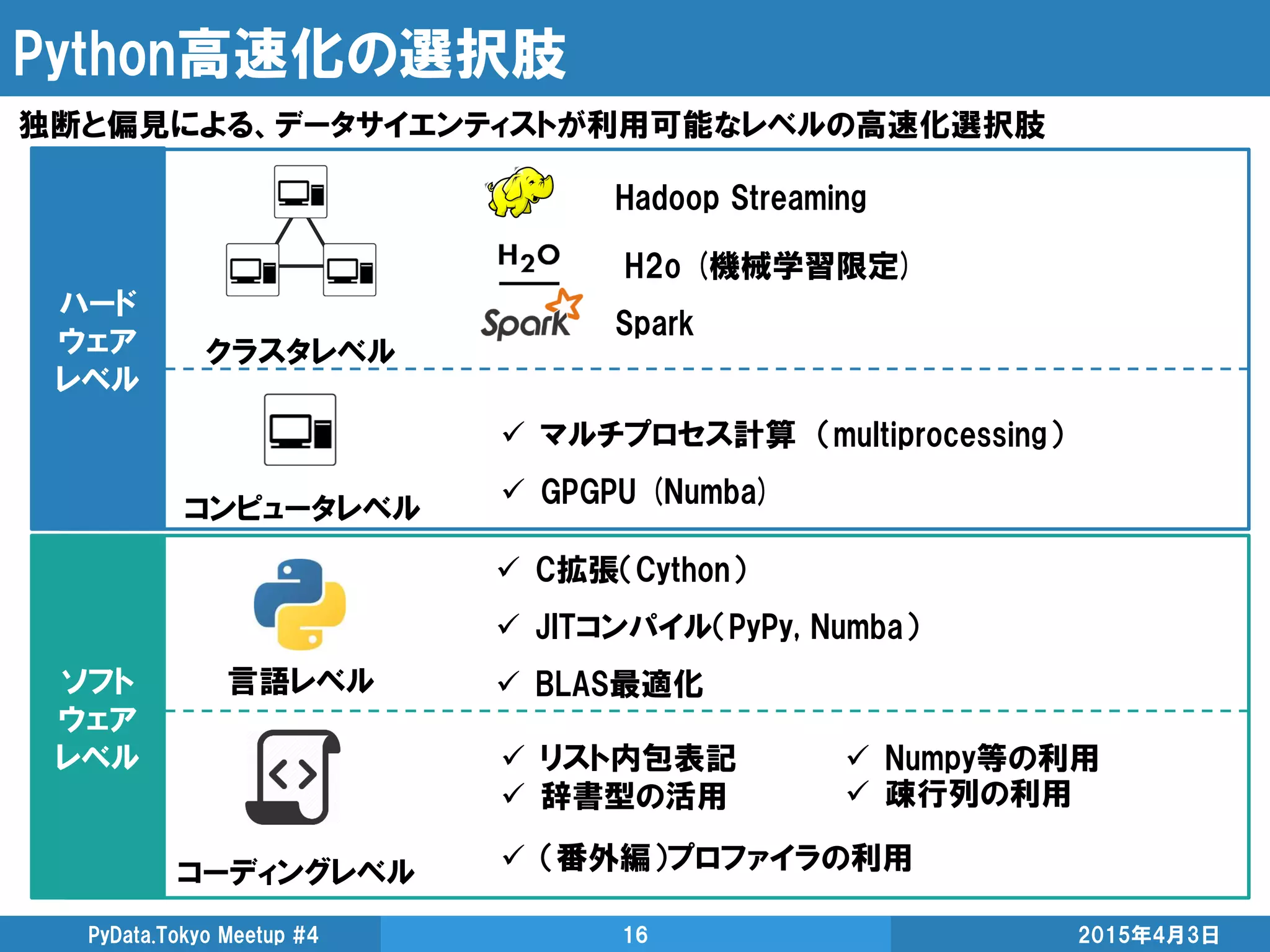
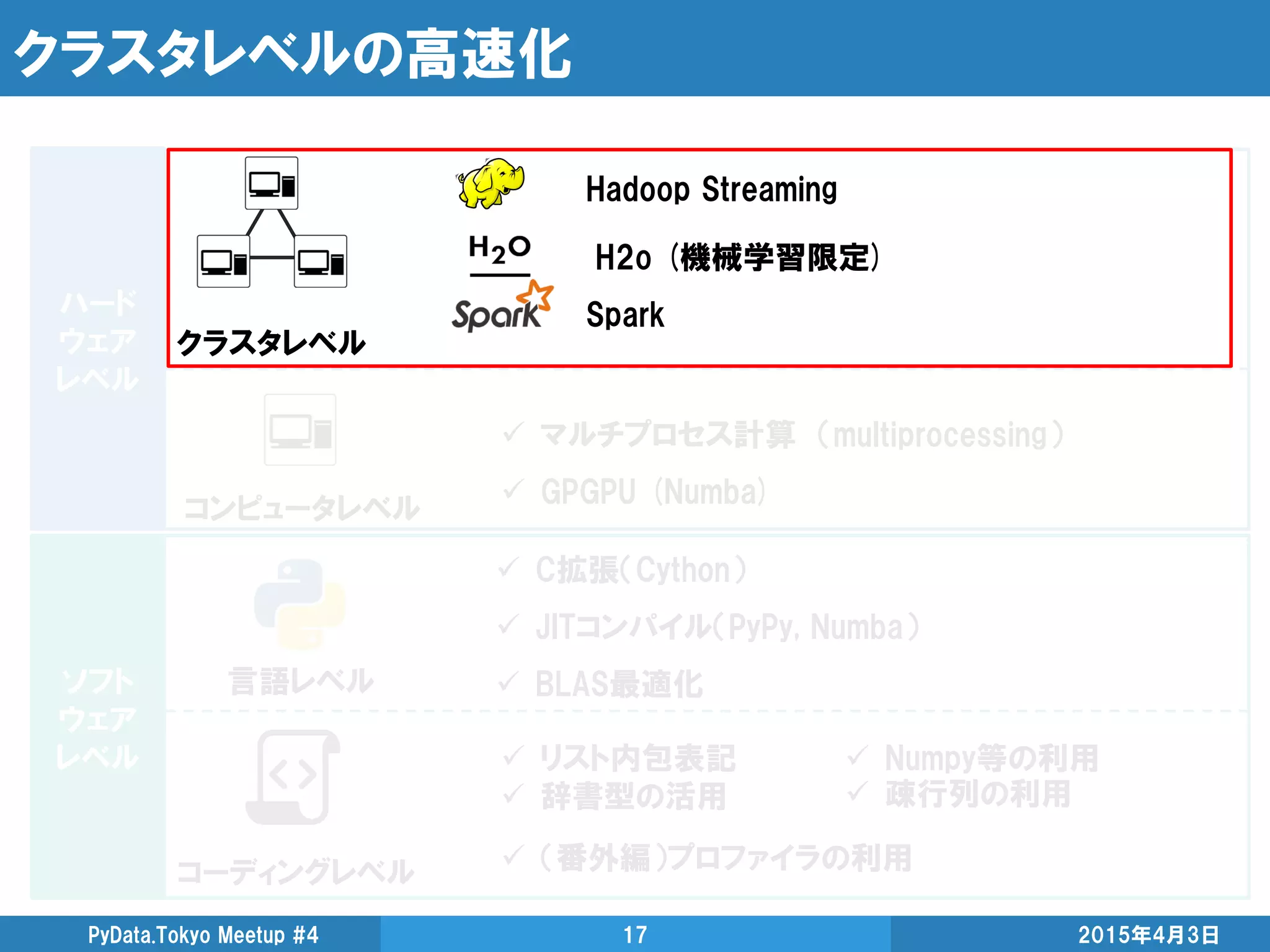
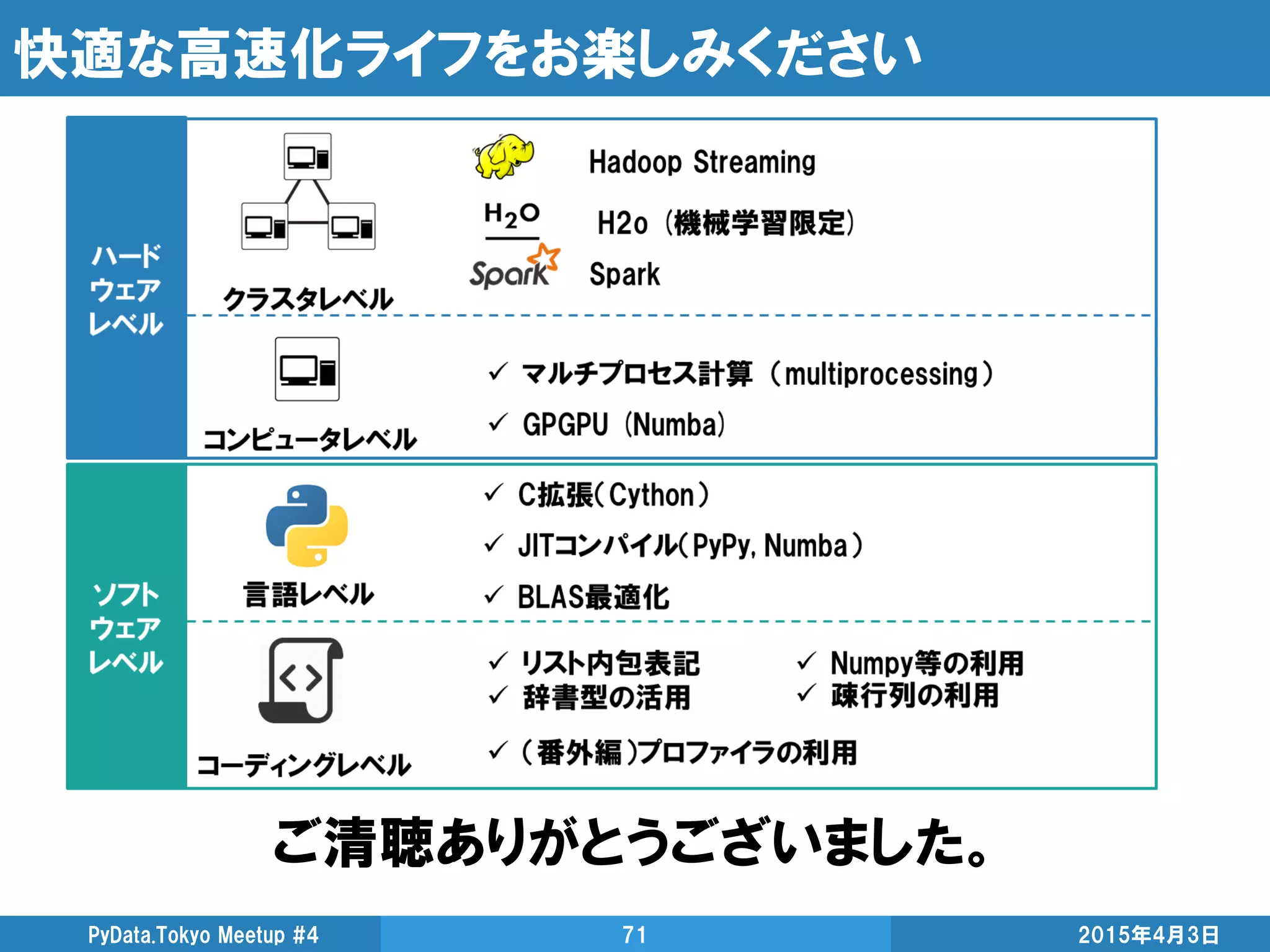
GPGPU(General-purpose computing ongraphics processing units)
基本的にGPGPUはCUDAでプログラミング
2015年4月3日PyData.Tokyo Meetup #4 35
GPUの演算資源を画像処理以外の目的に応用する技術
by wikipedia
GPGPU
CUDA NVIDIAが提供するGPU向けのC言語の統合開発環境
by wikipedia
注意:データサイエンティストには障壁が高いかも・・・
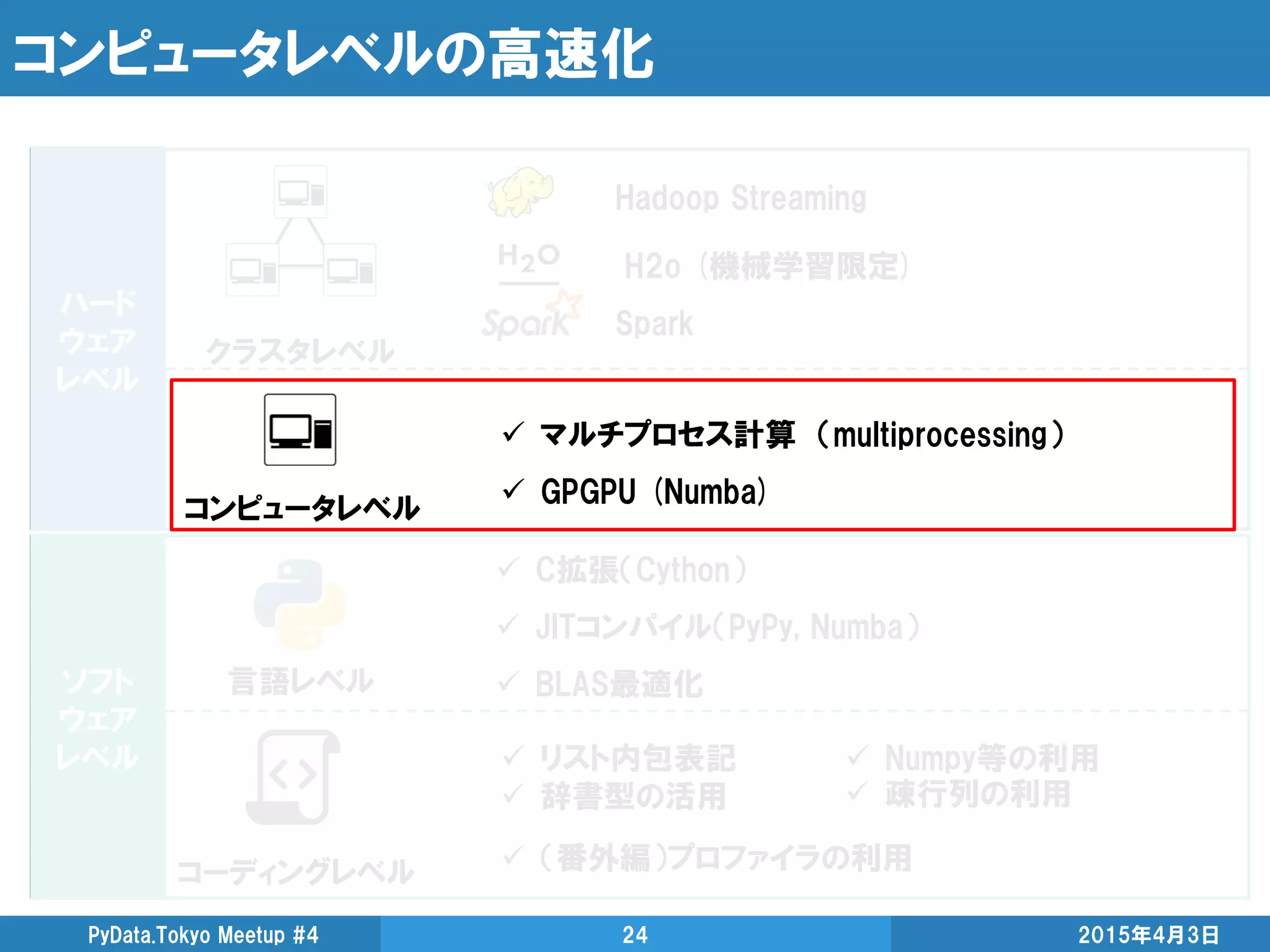
Numba(CPU)
基本的にはデコレータ一発
サポート外のpythonオブジェクトが無ければnopython=Trueでさらに高速化
2015年4月3日PyData.Tokyo Meetup #443
@jit('f8[:, :](f8[:, :], f8[:, :])', nopython=True)
def pairwise_distance(X, D):
M = X.shape[0]
N = X.shape[1]
for i in range(M):
for j in range(M):
d = 0.0
for k in range(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
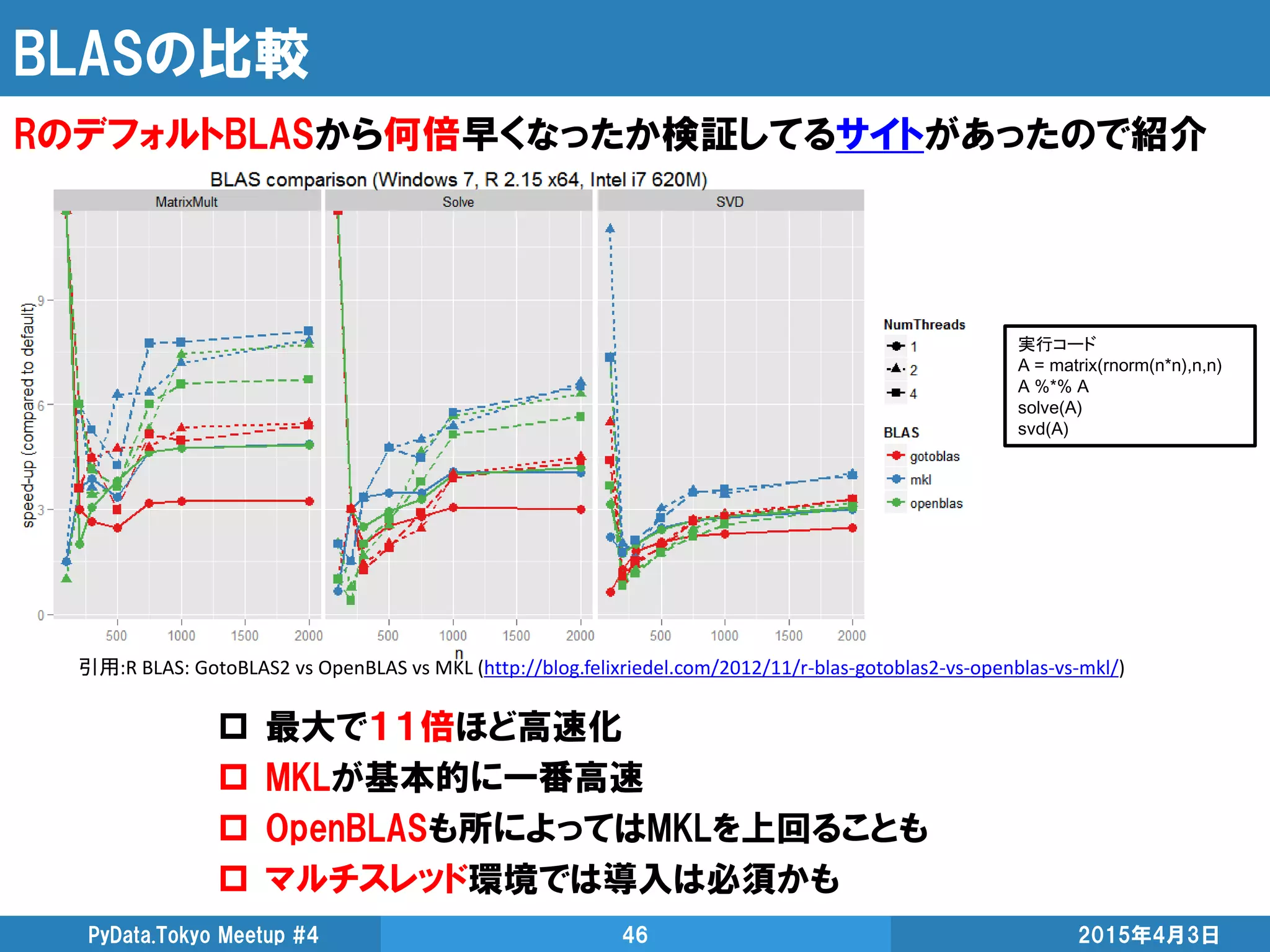
普通のPython 4.69秒
Numba 0.015秒
scipyのpdist 0.007秒
3次元座標の1,000地点間の距離計算時間はこちら
上の実装は、対称行列分の半分はサボれるので納得の結果
44.
Cython
3倍速いけど、あんまり速くない。不味いところあったら教えて下さい
2015年4月3日PyData.Tokyo Meetup #444
import numpy
cimport numpy
def pairwise_distance(numpy.ndarray[double, ndim=2] X,
numpy.ndarray[double, ndim=2] D):
cdef int i, j, k, M, N
cdef double d, tmp
M = X.shape[0]
N = X.shape[1]
for i in xrange(M):
for j in xrange(M):
d = 0.0
for k in xrange(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
C言語っぽく型を、ひたすら固定 Numbaよりは若干面倒
*.pyxで保存して、import pyximport; pyximport.install()で使う
普通のPython 4.69秒
Cython 1.22秒
3次元座標の1,000地点間の距離計算時間はこちら
リスト内包表記
多くの方がご存知の通り、リスト内包表記は早いです
2015年4月3日PyData.Tokyo Meetup #449
list_results = []
for i in xrange(1000000):
list_results.append(str(i))
list_results = []
for i in xrange(1000000):
list_results += [str(i)]
list_results = [str(i) for i in xrange(100000)]
リストの足し算するよりも、
appendしたほうが速く
さらに、リスト内包表記の方が速いです
リスト内包表記は『内部的にはappendをせずに、直接リストにぶち込めるから』速いのだそうです。
『リスト内包表記はなぜ速い?』 http://dsas.blog.klab.org/archives/51742727.html
0.42秒
0.35秒
0.26秒
list_results = []
list_results_append = list_results.append
for i in xrange(1000000):
list_results_append(str(i))
さらに、appendのdotを外したほうが速く
0.32秒
list_results = map(str, xrange(100000))
実は、今回の場合はmapが一番速いです。(mapはlambda式とか使うと遅い)
0.13秒
50.
辞書型の活用
データがあるかどうかの探索は、計算時間にかなり効果的
配列を全て走査する線形探索O(n)を理由なくやるのはご法度
2015年4月3日PyData.Tokyo Meetup #450
list_elements = [i for i in xrange(10000)]
for i in xrange(10000):
if i in list_elements:
pass
0.87秒
リストに対するin演算は線形探索だが、
辞書に対するin演算はハッシュ探索なのでO(1)で動作
map_elements = {i: None for i in xrange(10000)}
for i in xrange(10000):
if i in map_elements:
pass
0.001秒
気を抜くと、やりがちなので注意が必要
※状況に応じて二分木探索も


























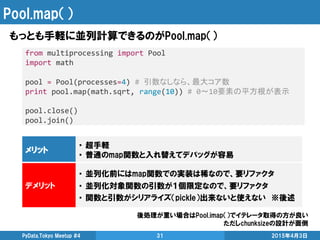
![Pool.apply_async()
2015年4月3日PyData.Tokyo Meetup #4 32
for文を簡単に並列化したいときにオススメ
from multiprocessing import Pool
import math
pool = Pool(processes=4) # 引数なしなら、最大コア数
list_processes = []
for i in range(10):
# math.pow(x, y)はxのy乗を返す関数
list_processes.append(pool.apply_async(math.pow, (i, 0.5))) # 引数を複数設定可能
list_results = [process.get() for process in list_processes]
print list_results
pool.close()
pool.join()
メリット • 並列化前のfor文をそのまま残せる
デメリット
• map関数よりは記述量が多い
• 関数と引数がシリアライズ(pickle)出来ないと使えない ※後述](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-32-320.jpg)
![Process()
2015年4月3日PyData.Tokyo Meetup #4 33
関数と引数がシリアライズ出来ない時にはコレ、結果は共有メモリで取得
from multiprocessing import Process, Manager
def sqrt(x, map_results):
map_results[x] = x**0.5
if __name__ == '__main__':
list_processes = []
manager = Manager()
map_results = manager.dict()
for i in range(10):
process = Process(target=sqrt,
args=(i, map_results,))
process.start()
list_processes.append(process)
[process.join() for process in list_processes]
print map_results.values()
メリット • シリアライズ出来なくても使える
デメリット
• 前の2つよりは面倒
• 例外処理が面倒](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-33-320.jpg)



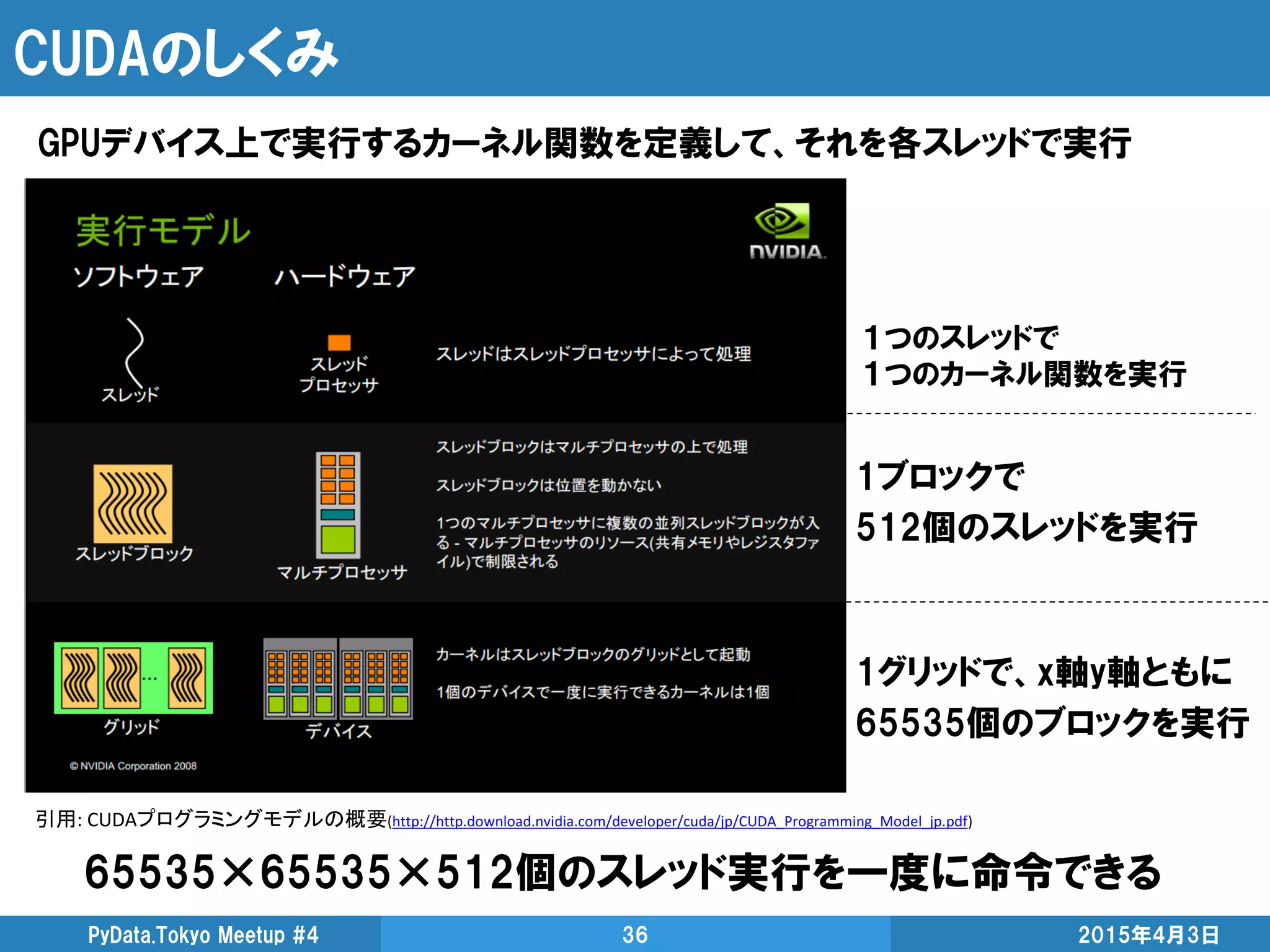
![Numbaでのカーネル関数記述
2015年4月3日PyData.Tokyo Meetup #4 37
PythonにJITコンパイラを導入して高速化するモジュール ※後述
GPUも扱える。Numba
from numba import cuda
import numpy
@cuda.jit('void(f8[:, :], f8[:, :])')
def pairwise_distance(X, D):
'''距離行列計算関数
'''
M = X.shape[0]
N = X.shape[1]
#スレッドとブロックのインデックスを使って
#このスレッドで計算する地点ペアを特定
i, j = cuda.grid(2)
if i < M and j < M:
d = 0.0
for k in range(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = math.sqrt(d)
if __name__ == '__main__':
X = numpy.random.random((1000, 3)) # 3次元座標
D = numpy.empty((1000, 1000)) # 出力される距離行列
griddim = 100, 100 # 100*100にブロックを配置
blockdim = 16, 16 # ブロック内で16*16にスレッドを配置
pairwise_distance[griddim, blockdim](X, D)
STEP2
1600×1600のスレッドの場所で
どの2地点間の計算するか決定
※この設計だと1600以上の地点間は計算出来ない
STEP1
1600×1600のスレッドを用意
C言語での記述とほぼ同様のフォーマット](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-37-320.jpg)




', nopython=True)
def pairwise_distance(X, D):
M = X.shape[0]
N = X.shape[1]
for i in range(M):
for j in range(M):
d = 0.0
for k in range(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
普通のPython 4.69秒
Numba 0.015秒
scipyのpdist 0.007秒
3次元座標の1,000地点間の距離計算時間はこちら
上の実装は、対称行列分の半分はサボれるので納得の結果](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-43-320.jpg)
![Cython
3倍速いけど、あんまり速くない。不味いところあったら教えて下さい
2015年4月3日PyData.Tokyo Meetup #4 44
import numpy
cimport numpy
def pairwise_distance(numpy.ndarray[double, ndim=2] X,
numpy.ndarray[double, ndim=2] D):
cdef int i, j, k, M, N
cdef double d, tmp
M = X.shape[0]
N = X.shape[1]
for i in xrange(M):
for j in xrange(M):
d = 0.0
for k in xrange(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
C言語っぽく型を、ひたすら固定 Numbaよりは若干面倒
*.pyxで保存して、import pyximport; pyximport.install()で使う
普通のPython 4.69秒
Cython 1.22秒
3次元座標の1,000地点間の距離計算時間はこちら](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-44-320.jpg)



![リスト内包表記
多くの方がご存知の通り、リスト内包表記は早いです
2015年4月3日PyData.Tokyo Meetup #4 49
list_results = []
for i in xrange(1000000):
list_results.append(str(i))
list_results = []
for i in xrange(1000000):
list_results += [str(i)]
list_results = [str(i) for i in xrange(100000)]
リストの足し算するよりも、
appendしたほうが速く
さらに、リスト内包表記の方が速いです
リスト内包表記は『内部的にはappendをせずに、直接リストにぶち込めるから』速いのだそうです。
『リスト内包表記はなぜ速い?』 http://dsas.blog.klab.org/archives/51742727.html
0.42秒
0.35秒
0.26秒
list_results = []
list_results_append = list_results.append
for i in xrange(1000000):
list_results_append(str(i))
さらに、appendのdotを外したほうが速く
0.32秒
list_results = map(str, xrange(100000))
実は、今回の場合はmapが一番速いです。(mapはlambda式とか使うと遅い)
0.13秒](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-49-320.jpg)
![辞書型の活用
データがあるかどうかの探索は、計算時間にかなり効果的
配列を全て走査する線形探索O(n)を理由なくやるのはご法度
2015年4月3日PyData.Tokyo Meetup #4 50
list_elements = [i for i in xrange(10000)]
for i in xrange(10000):
if i in list_elements:
pass
0.87秒
リストに対するin演算は線形探索だが、
辞書に対するin演算はハッシュ探索なのでO(1)で動作
map_elements = {i: None for i in xrange(10000)}
for i in xrange(10000):
if i in map_elements:
pass
0.001秒
気を抜くと、やりがちなので注意が必要
※状況に応じて二分木探索も](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-50-320.jpg)




![Numpy等の利用
行列積とか今更比べても仕様がないので、私の失敗例
2015年4月3日PyData.Tokyo Meetup #4 55
pandasのデータフレームに対して多対一の距離計算を考えていて
user_all_vecs = numpy.random.random((100000, 100)) # ユーザ毎のベクトル(多)
some_user_vec = numpy.random.random(100) # あるユーザのベクトル(一)
pd_user_all_vecs = pandas.DataFrame(user_all_vecs) ) # pandas準備
インデックスを保持したいので行ごとにapplyで計算すると超遅く
scipyのcdistと再インデックス付与の方が断然速い
pd_user_all_vecs.apply(lambda vec: euclidean(vec, some_user_vec),
axis=1)
pandas.Series(cdist(pd_user_all_vecs,[some_user_vec])[:, 0],
index=pd_user_all_vecs.index)
3.9秒
0.06秒
BLASパワーはマジで偉大](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-55-320.jpg)



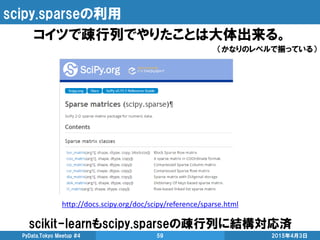
![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 60
色々提案されているので、主要な疎行列表現のみ紹介
COO表現
(COOdinate format)
行番号、列番号、要素の3配列で行列を表現
>>> row = numpy.array([0, 3, 1, 0])
>>> col = numpy.array([0, 3, 1, 2])
>>> data = numpy.array([4, 5, 7, 9])
>>> coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
メリット • 超簡単
デメリット
• 要素のアクセスが線形探索のみ(ソート済みなら二分木探索)
• 要素の追加が難しい
• この表現のまま行列演算は基本難しい
使用例
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.coo_matrix](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-60-320.jpg)
![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 61
CSR表現
(Compressed Sparse Row format)
列番号、行の境目、要素の3配列で行列を表現
>>> indptr = numpy.array([0, 2, 3, 6])
>>> indices = numpy.array([0, 2, 2, 0, 1, 2])
>>> data = numpy.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
使用例
メリット
• 行列演算がしやすい
• 行要素が定数個と仮定するならO(1)で要素アクセス可能
デメリット
• 作るのが面倒くさい
• 要素アクセスはO(1)だとしても面倒
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.csr_matrix](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-61-320.jpg)
![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 62
CSC表現
(Compressed Sparse Column format)
行番号、列の境目、要素の3配列で行列を表現
使用例
メリット
• 行列演算がしやすい
• 行要素が定数個ならO(1)で要素アクセス可能
デメリット
• 作るのが面倒くさい
• 要素アクセスもO(1)だとしても面倒
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.csc_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csc_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 4],
[0, 0, 5],
[2, 3, 6]])
行と列が入れ替わっただけなので、
CSR表現と同じ](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-62-320.jpg)




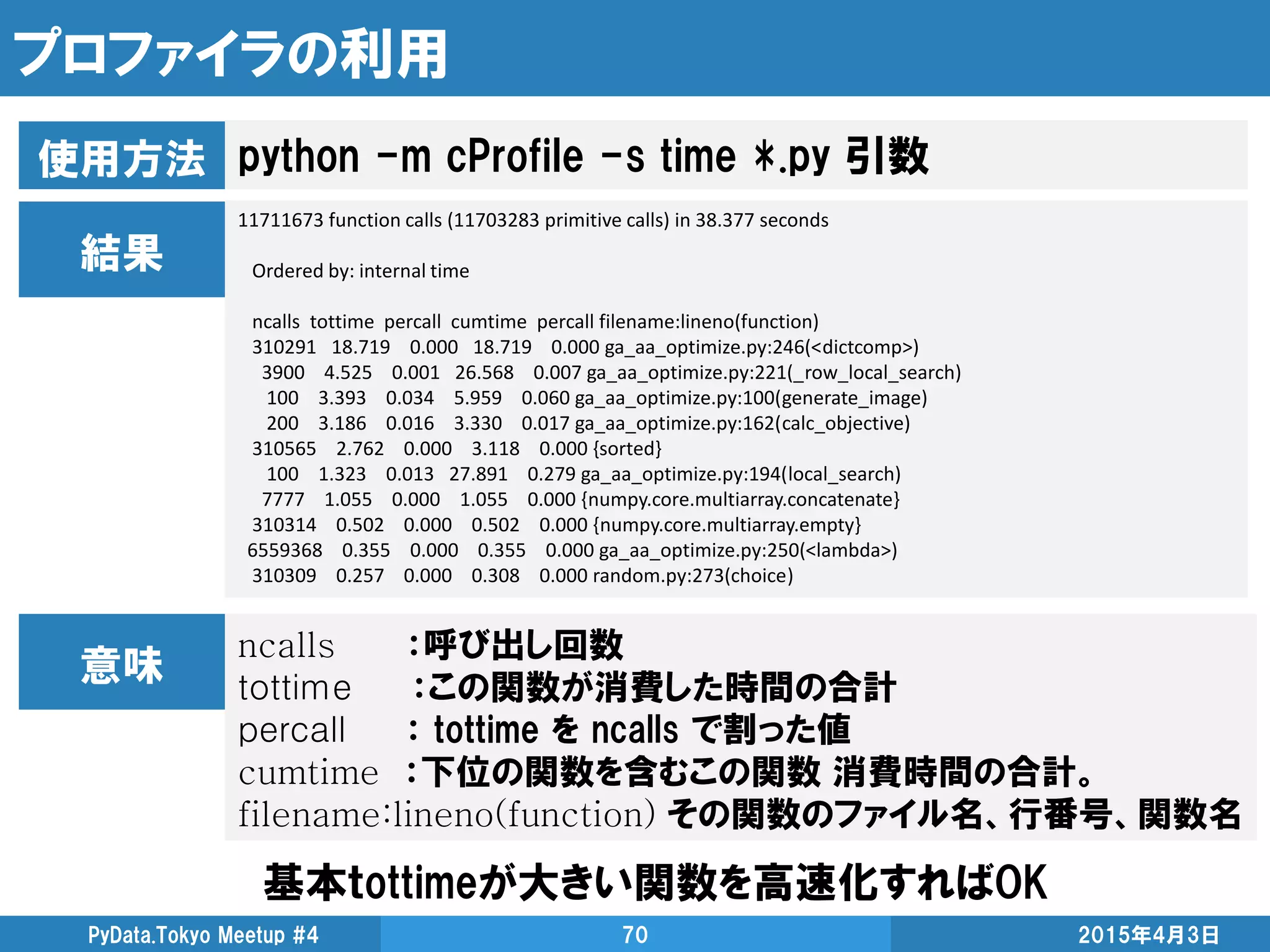
![IPythonの%timeと%timeitを使う
IPythonには時間計測に%timeと%timeitのマジックコマンドが存在
2015年4月3日PyData.Tokyo Meetup #4 67
In [5]: %time sum(i for i in xrange(10000))
Wall time: 1 ms
Out[5]: 49995000
In [6]: %timeit sum(i for i in xrange(10000))
1000 loops, best of 3: 330 us per loop
%timeitは繰り返し解いて、信頼度の高い計算時間を返してくれる](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-67-320.jpg)
![Loggingをちゃんと使う
概算でよいなら、loggingでログを吐くのがオススメ
メソッド前と後ろでログ吐けば大体の時間はわかる
2015年4月3日PyData.Tokyo Meetup #4 68
2015-03-23 00:32:53,385 ga_aa_optimize.optimize 50 [INFO]start optimize with image_num=20, max_iter=50
2015-03-23 00:32:53,387 ga_aa_optimize.optimize 51 [INFO]start to make initial solutions.
2015-03-23 00:32:55,530 ga_aa_optimize.optimize 81 [INFO]row_shift is 0.
2015-03-23 00:32:55,530 ga_aa_optimize.optimize 82 [INFO]end making initial solutions in 2.14299988747 seconds.
2015-03-23 00:32:57,713 ga_aa_optimize.optimize 135 [INFO]1: 58517.0 | 2.17900013924
2015-03-23 00:33:00,621 ga_aa_optimize.optimize 135 [INFO]2: 57258.0 | 2.90799999237
2015-03-23 00:33:03,428 ga_aa_optimize.optimize 135 [INFO]3: 56428.0 | 2.80799984932
2015-03-23 00:33:06,232 ga_aa_optimize.optimize 135 [INFO]4: 56242.0 | 2.80300021172
2015-03-23 00:33:08,980 ga_aa_optimize.optimize 135 [INFO]5: 56173.0 | 2.74699997902
2015-03-23 00:33:11,894 ga_aa_optimize.optimize 135 [INFO]6: 56004.0 | 2.91499996185
2015-03-23 00:33:14,677 ga_aa_optimize.optimize 135 [INFO]7: 55948.0 | 2.78200006485
2015-03-23 00:33:17,608 ga_aa_optimize.optimize 135 [INFO]8: 55919.0 | 2.93099999428
2015-03-23 00:33:20,421 ga_aa_optimize.optimize 135 [INFO]9: 55919.0 | 2.81200003624
2015-03-23 00:33:23,270 ga_aa_optimize.optimize 135 [INFO]10: 55899.0 | 2.84799981117
http://qiita.com/amedama/items/b856b2f30c2f38665701
『ログってなに?printでいいだろ』って人はここを読むと良いかも](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/85/High-performance-python-computing-for-data-science-68-320.jpg)

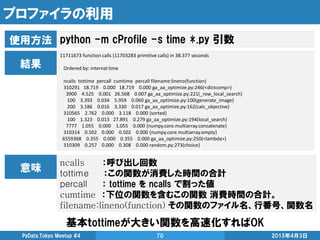
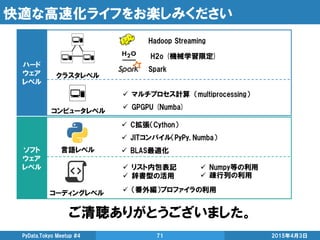



























![Pool.apply_async()
2015年4月3日PyData.Tokyo Meetup #4 32
for文を簡単に並列化したいときにオススメ
from multiprocessing import Pool
import math
pool = Pool(processes=4) # 引数なしなら、最大コア数
list_processes = []
for i in range(10):
# math.pow(x, y)はxのy乗を返す関数
list_processes.append(pool.apply_async(math.pow, (i, 0.5))) # 引数を複数設定可能
list_results = [process.get() for process in list_processes]
print list_results
pool.close()
pool.join()
メリット • 並列化前のfor文をそのまま残せる
デメリット
• map関数よりは記述量が多い
• 関数と引数がシリアライズ(pickle)出来ないと使えない ※後述](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-32-2048.jpg)
![Process()
2015年4月3日PyData.Tokyo Meetup #4 33
関数と引数がシリアライズ出来ない時にはコレ、結果は共有メモリで取得
from multiprocessing import Process, Manager
def sqrt(x, map_results):
map_results[x] = x**0.5
if __name__ == '__main__':
list_processes = []
manager = Manager()
map_results = manager.dict()
for i in range(10):
process = Process(target=sqrt,
args=(i, map_results,))
process.start()
list_processes.append(process)
[process.join() for process in list_processes]
print map_results.values()
メリット • シリアライズ出来なくても使える
デメリット
• 前の2つよりは面倒
• 例外処理が面倒](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-33-2048.jpg)


![Numbaでのカーネル関数記述
2015年4月3日PyData.Tokyo Meetup #4 37
PythonにJITコンパイラを導入して高速化するモジュール ※後述
GPUも扱える。Numba
from numba import cuda
import numpy
@cuda.jit('void(f8[:, :], f8[:, :])')
def pairwise_distance(X, D):
'''距離行列計算関数
'''
M = X.shape[0]
N = X.shape[1]
#スレッドとブロックのインデックスを使って
#このスレッドで計算する地点ペアを特定
i, j = cuda.grid(2)
if i < M and j < M:
d = 0.0
for k in range(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = math.sqrt(d)
if __name__ == '__main__':
X = numpy.random.random((1000, 3)) # 3次元座標
D = numpy.empty((1000, 1000)) # 出力される距離行列
griddim = 100, 100 # 100*100にブロックを配置
blockdim = 16, 16 # ブロック内で16*16にスレッドを配置
pairwise_distance[griddim, blockdim](X, D)
STEP2
1600×1600のスレッドの場所で
どの2地点間の計算するか決定
※この設計だと1600以上の地点間は計算出来ない
STEP1
1600×1600のスレッドを用意
C言語での記述とほぼ同様のフォーマット](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-37-2048.jpg)




', nopython=True)
def pairwise_distance(X, D):
M = X.shape[0]
N = X.shape[1]
for i in range(M):
for j in range(M):
d = 0.0
for k in range(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
普通のPython 4.69秒
Numba 0.015秒
scipyのpdist 0.007秒
3次元座標の1,000地点間の距離計算時間はこちら
上の実装は、対称行列分の半分はサボれるので納得の結果](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-43-2048.jpg)
![Cython
3倍速いけど、あんまり速くない。不味いところあったら教えて下さい
2015年4月3日PyData.Tokyo Meetup #4 44
import numpy
cimport numpy
def pairwise_distance(numpy.ndarray[double, ndim=2] X,
numpy.ndarray[double, ndim=2] D):
cdef int i, j, k, M, N
cdef double d, tmp
M = X.shape[0]
N = X.shape[1]
for i in xrange(M):
for j in xrange(M):
d = 0.0
for k in xrange(N):
tmp = X[i, k] - X[j, k]
d += tmp * tmp
D[i, j] = numpy.sqrt(d)
return D
C言語っぽく型を、ひたすら固定 Numbaよりは若干面倒
*.pyxで保存して、import pyximport; pyximport.install()で使う
普通のPython 4.69秒
Cython 1.22秒
3次元座標の1,000地点間の距離計算時間はこちら](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-44-2048.jpg)



![リスト内包表記
多くの方がご存知の通り、リスト内包表記は早いです
2015年4月3日PyData.Tokyo Meetup #4 49
list_results = []
for i in xrange(1000000):
list_results.append(str(i))
list_results = []
for i in xrange(1000000):
list_results += [str(i)]
list_results = [str(i) for i in xrange(100000)]
リストの足し算するよりも、
appendしたほうが速く
さらに、リスト内包表記の方が速いです
リスト内包表記は『内部的にはappendをせずに、直接リストにぶち込めるから』速いのだそうです。
『リスト内包表記はなぜ速い?』 http://dsas.blog.klab.org/archives/51742727.html
0.42秒
0.35秒
0.26秒
list_results = []
list_results_append = list_results.append
for i in xrange(1000000):
list_results_append(str(i))
さらに、appendのdotを外したほうが速く
0.32秒
list_results = map(str, xrange(100000))
実は、今回の場合はmapが一番速いです。(mapはlambda式とか使うと遅い)
0.13秒](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-49-2048.jpg)
![辞書型の活用
データがあるかどうかの探索は、計算時間にかなり効果的
配列を全て走査する線形探索O(n)を理由なくやるのはご法度
2015年4月3日PyData.Tokyo Meetup #4 50
list_elements = [i for i in xrange(10000)]
for i in xrange(10000):
if i in list_elements:
pass
0.87秒
リストに対するin演算は線形探索だが、
辞書に対するin演算はハッシュ探索なのでO(1)で動作
map_elements = {i: None for i in xrange(10000)}
for i in xrange(10000):
if i in map_elements:
pass
0.001秒
気を抜くと、やりがちなので注意が必要
※状況に応じて二分木探索も](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-50-2048.jpg)




![Numpy等の利用
行列積とか今更比べても仕様がないので、私の失敗例
2015年4月3日PyData.Tokyo Meetup #4 55
pandasのデータフレームに対して多対一の距離計算を考えていて
user_all_vecs = numpy.random.random((100000, 100)) # ユーザ毎のベクトル(多)
some_user_vec = numpy.random.random(100) # あるユーザのベクトル(一)
pd_user_all_vecs = pandas.DataFrame(user_all_vecs) ) # pandas準備
インデックスを保持したいので行ごとにapplyで計算すると超遅く
scipyのcdistと再インデックス付与の方が断然速い
pd_user_all_vecs.apply(lambda vec: euclidean(vec, some_user_vec),
axis=1)
pandas.Series(cdist(pd_user_all_vecs,[some_user_vec])[:, 0],
index=pd_user_all_vecs.index)
3.9秒
0.06秒
BLASパワーはマジで偉大](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-55-2048.jpg)



![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 60
色々提案されているので、主要な疎行列表現のみ紹介
COO表現
(COOdinate format)
行番号、列番号、要素の3配列で行列を表現
>>> row = numpy.array([0, 3, 1, 0])
>>> col = numpy.array([0, 3, 1, 2])
>>> data = numpy.array([4, 5, 7, 9])
>>> coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
メリット • 超簡単
デメリット
• 要素のアクセスが線形探索のみ(ソート済みなら二分木探索)
• 要素の追加が難しい
• この表現のまま行列演算は基本難しい
使用例
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.coo_matrix](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-60-2048.jpg)
![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 61
CSR表現
(Compressed Sparse Row format)
列番号、行の境目、要素の3配列で行列を表現
>>> indptr = numpy.array([0, 2, 3, 6])
>>> indices = numpy.array([0, 2, 2, 0, 1, 2])
>>> data = numpy.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
使用例
メリット
• 行列演算がしやすい
• 行要素が定数個と仮定するならO(1)で要素アクセス可能
デメリット
• 作るのが面倒くさい
• 要素アクセスはO(1)だとしても面倒
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.csr_matrix](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-61-2048.jpg)
![scipy.sparseの利用
2015年4月3日PyData.Tokyo Meetup #4 62
CSC表現
(Compressed Sparse Column format)
行番号、列の境目、要素の3配列で行列を表現
使用例
メリット
• 行列演算がしやすい
• 行要素が定数個ならO(1)で要素アクセス可能
デメリット
• 作るのが面倒くさい
• 要素アクセスもO(1)だとしても面倒
http://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.csc_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csc_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 4],
[0, 0, 5],
[2, 3, 6]])
行と列が入れ替わっただけなので、
CSR表現と同じ](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-62-2048.jpg)




![IPythonの%timeと%timeitを使う
IPythonには時間計測に%timeと%timeitのマジックコマンドが存在
2015年4月3日PyData.Tokyo Meetup #4 67
In [5]: %time sum(i for i in xrange(10000))
Wall time: 1 ms
Out[5]: 49995000
In [6]: %timeit sum(i for i in xrange(10000))
1000 loops, best of 3: 330 us per loop
%timeitは繰り返し解いて、信頼度の高い計算時間を返してくれる](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-67-2048.jpg)
![Loggingをちゃんと使う
概算でよいなら、loggingでログを吐くのがオススメ
メソッド前と後ろでログ吐けば大体の時間はわかる
2015年4月3日PyData.Tokyo Meetup #4 68
2015-03-23 00:32:53,385 ga_aa_optimize.optimize 50 [INFO]start optimize with image_num=20, max_iter=50
2015-03-23 00:32:53,387 ga_aa_optimize.optimize 51 [INFO]start to make initial solutions.
2015-03-23 00:32:55,530 ga_aa_optimize.optimize 81 [INFO]row_shift is 0.
2015-03-23 00:32:55,530 ga_aa_optimize.optimize 82 [INFO]end making initial solutions in 2.14299988747 seconds.
2015-03-23 00:32:57,713 ga_aa_optimize.optimize 135 [INFO]1: 58517.0 | 2.17900013924
2015-03-23 00:33:00,621 ga_aa_optimize.optimize 135 [INFO]2: 57258.0 | 2.90799999237
2015-03-23 00:33:03,428 ga_aa_optimize.optimize 135 [INFO]3: 56428.0 | 2.80799984932
2015-03-23 00:33:06,232 ga_aa_optimize.optimize 135 [INFO]4: 56242.0 | 2.80300021172
2015-03-23 00:33:08,980 ga_aa_optimize.optimize 135 [INFO]5: 56173.0 | 2.74699997902
2015-03-23 00:33:11,894 ga_aa_optimize.optimize 135 [INFO]6: 56004.0 | 2.91499996185
2015-03-23 00:33:14,677 ga_aa_optimize.optimize 135 [INFO]7: 55948.0 | 2.78200006485
2015-03-23 00:33:17,608 ga_aa_optimize.optimize 135 [INFO]8: 55919.0 | 2.93099999428
2015-03-23 00:33:20,421 ga_aa_optimize.optimize 135 [INFO]9: 55919.0 | 2.81200003624
2015-03-23 00:33:23,270 ga_aa_optimize.optimize 135 [INFO]10: 55899.0 | 2.84799981117
http://qiita.com/amedama/items/b856b2f30c2f38665701
『ログってなに?printでいいだろ』って人はここを読むと良いかも](https://image.slidesharecdn.com/highperformancepythoncomputingfordatascience-150403052333-conversion-gate01/75/High-performance-python-computing-for-data-science-68-2048.jpg)









![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=600ounds&width=560&fit=bounds)























![[db analytics showcase Sapporo 2017] A15: Pythonでの分散処理再入門 by 株式会社HPCソリューションズ ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase-sapporo-2017-iisaka-170707075724-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















