Downloaded 181 times













![Lock Striping
public synchronized void public void put2(int indx,
put1(int indx, String k) { String k) {
share[indx] = k; synchronized
} (locks[indx%N_LOCKS]) {
share[indx] = k;
}
}
Execution Time: 5536 Execution Time: 1857
milliseconds milliseconds
66%](https://image.slidesharecdn.com/hsjavaopenparty1-100828093729-phpapp01/85/Highly-Scalable-Java-Programming-for-Multi-Core-System-17-320.jpg)


![Example of AtomicLongArray
public synchronized void set1(int private final AtomicLongArray a;
idx, long val) {
d[idx] = val; public void set2(int idx, long val) {
} a.addAndGet(idx, val);
}
public synchronized long get1(int public long get2(int idx) {
idx) { long ret = a.get(idx); return ret;
long ret = d[idx]; }
return ret;
}
Execution Time: 23550 Execution Time: 842 milliseconds
milliseconds
96%](https://image.slidesharecdn.com/hsjavaopenparty1-100828093729-phpapp01/85/Highly-Scalable-Java-Programming-for-Multi-Core-System-21-320.jpg)





















![Lock Striping
public synchronized void public void put2(int indx,
put1(int indx, String k) { String k) {
share[indx] = k; synchronized
} (locks[indx%N_LOCKS]) {
share[indx] = k;
}
}
Execution Time: 5536 Execution Time: 1857
milliseconds milliseconds
66%](https://image.slidesharecdn.com/hsjavaopenparty1-100828093729-phpapp01/75/Highly-Scalable-Java-Programming-for-Multi-Core-System-17-2048.jpg)


![Example of AtomicLongArray
public synchronized void set1(int private final AtomicLongArray a;
idx, long val) {
d[idx] = val; public void set2(int idx, long val) {
} a.addAndGet(idx, val);
}
public synchronized long get1(int public long get2(int idx) {
idx) { long ret = a.get(idx); return ret;
long ret = d[idx]; }
return ret;
}
Execution Time: 23550 Execution Time: 842 milliseconds
milliseconds
96%](https://image.slidesharecdn.com/hsjavaopenparty1-100828093729-phpapp01/75/Highly-Scalable-Java-Programming-for-Multi-Core-System-21-2048.jpg)





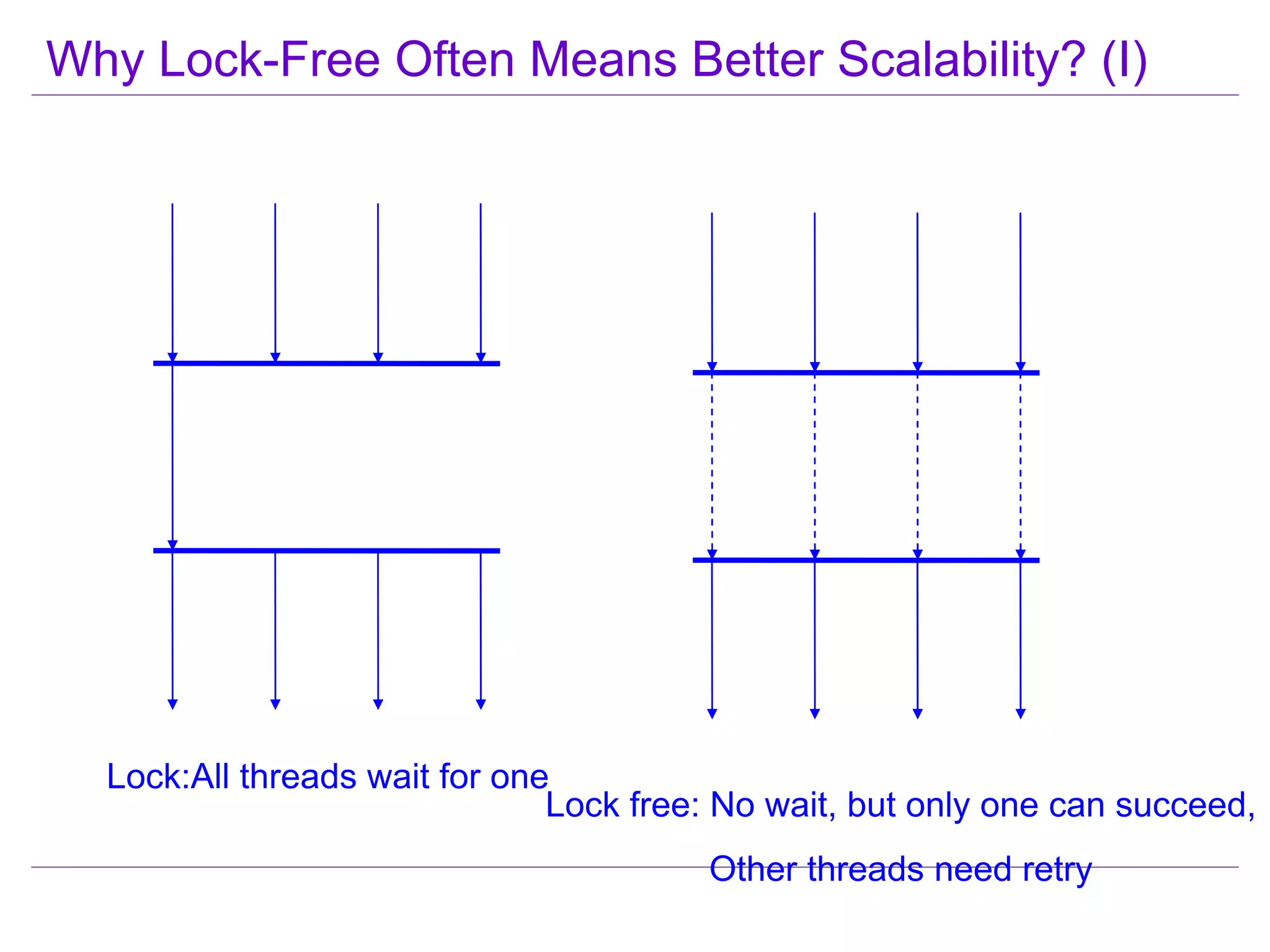
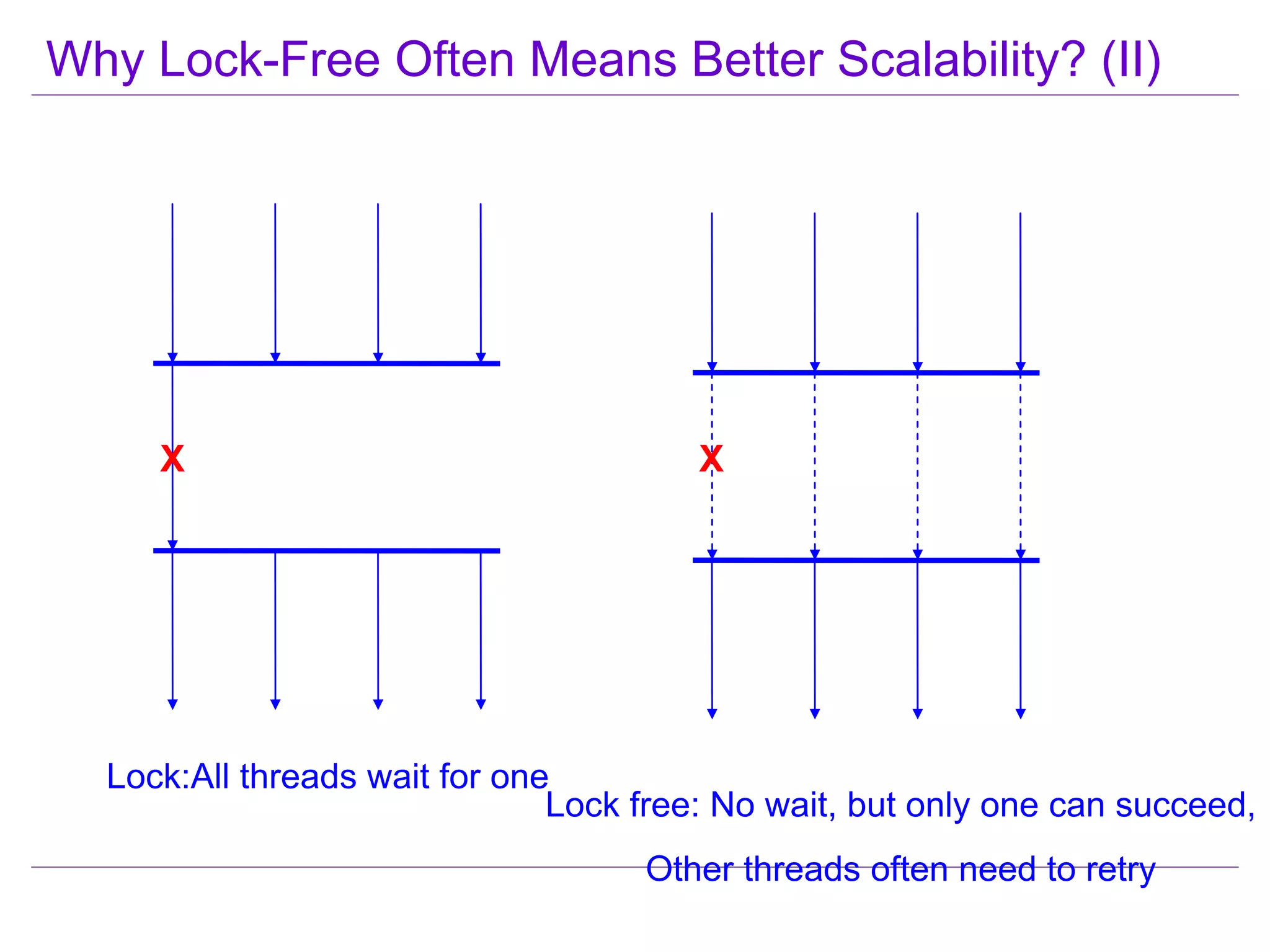
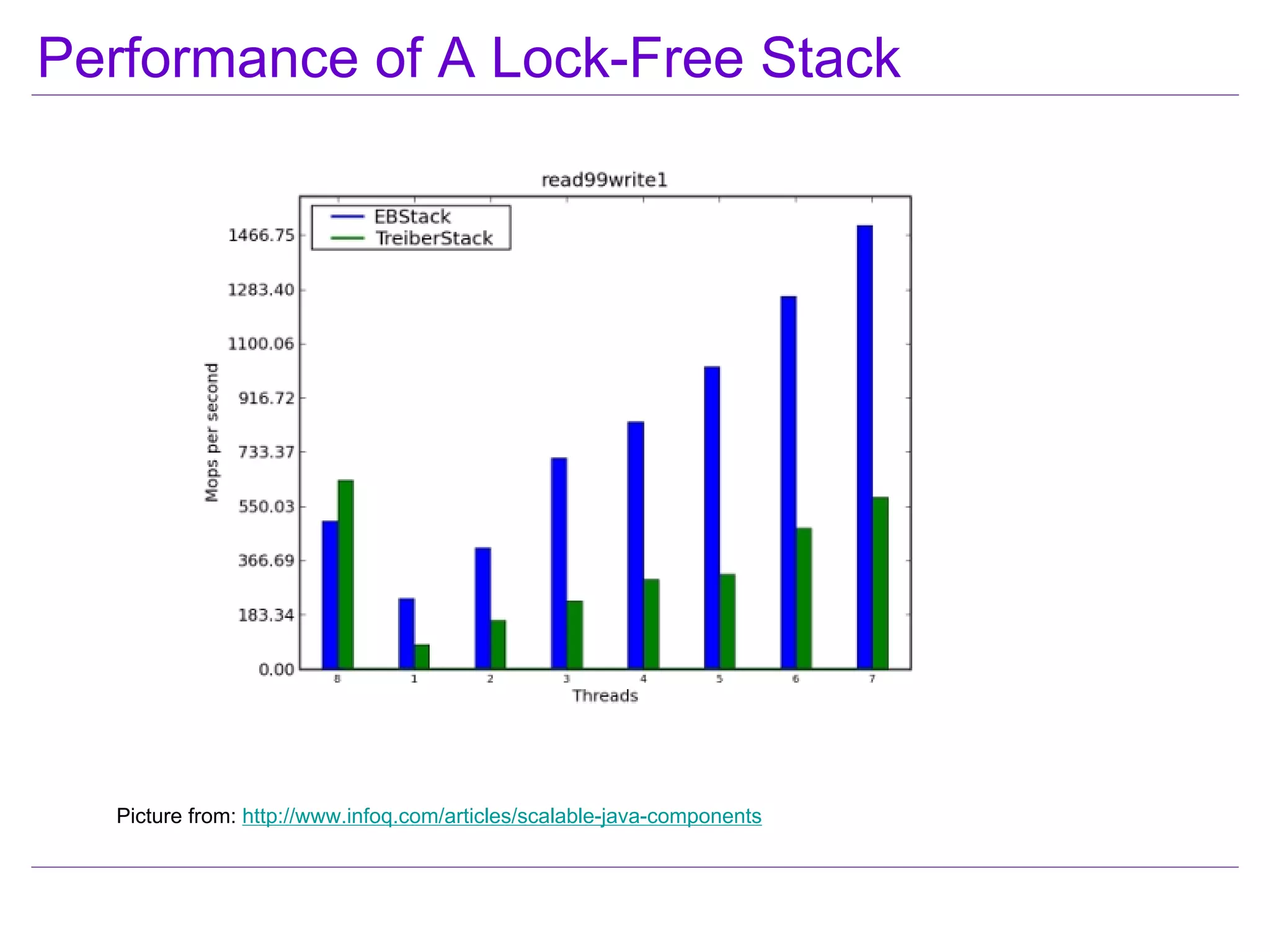



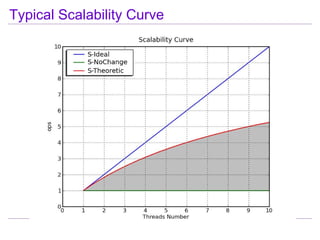
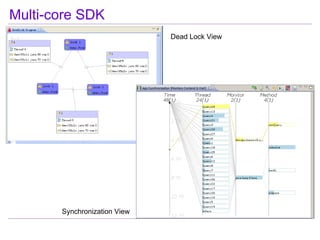
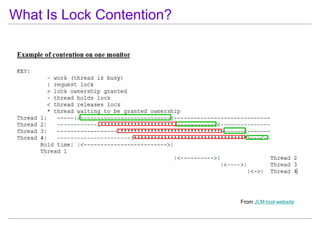
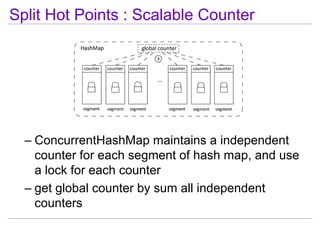
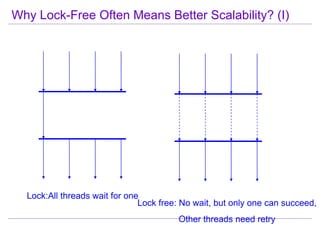
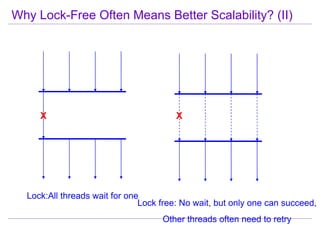
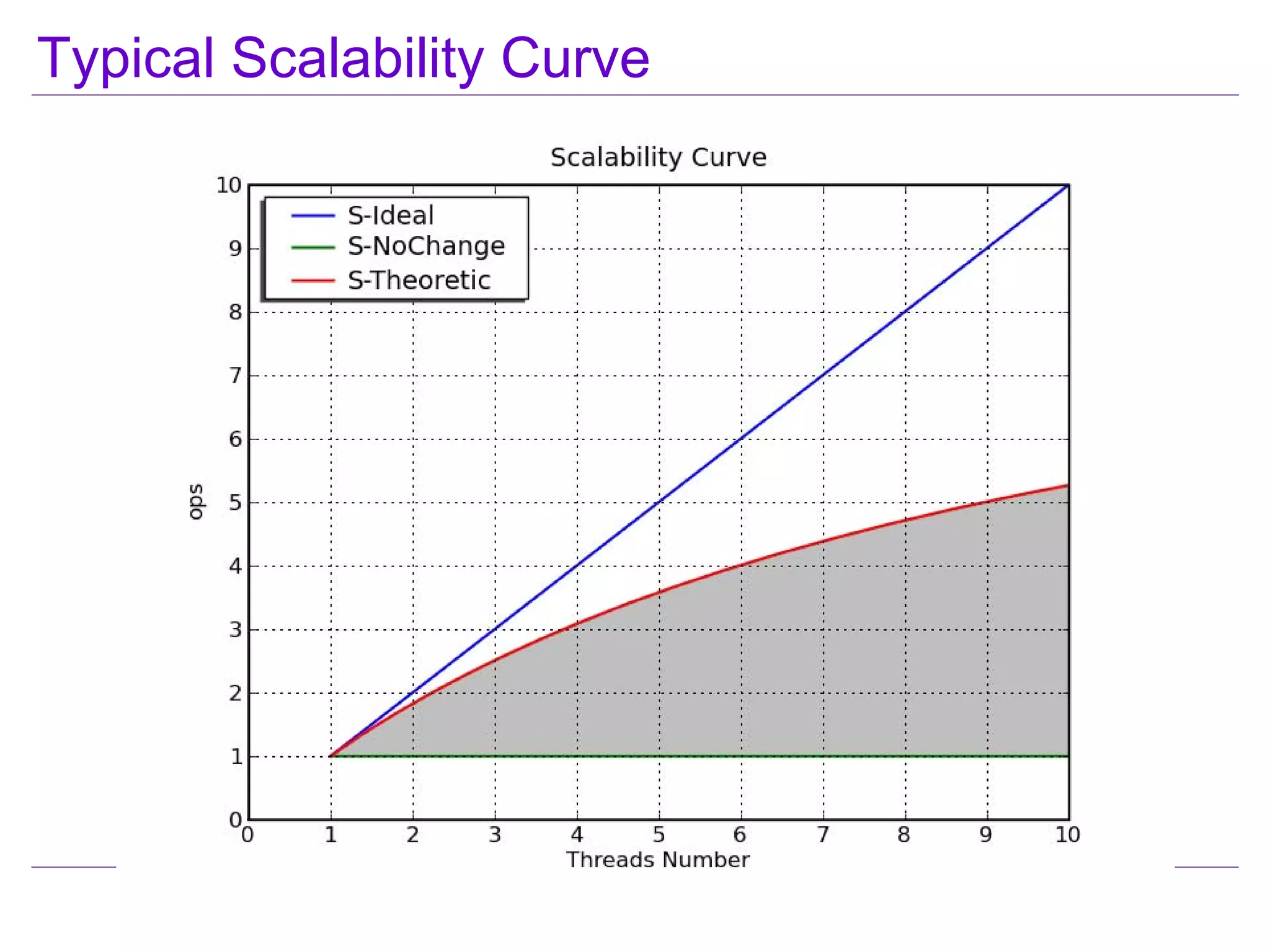
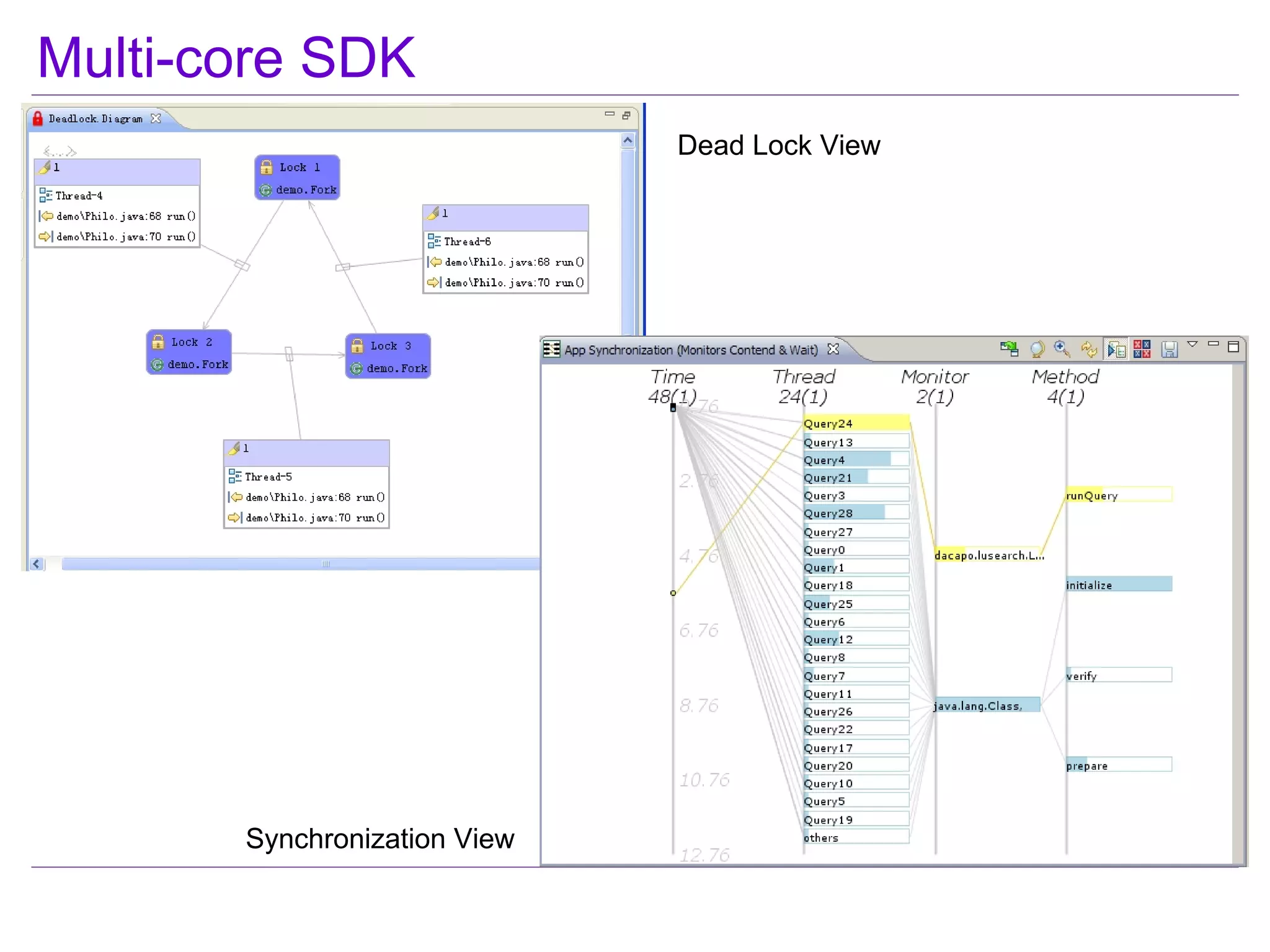
This document discusses best practices for highly scalable Java programming on multi-core systems. It begins by outlining software challenges like parallelism, memory management, and storage management. It then introduces profiling tools like the Java Lock Monitor (JLM) and Multi-core SDK (MSDK) to analyze parallel applications. The document provides techniques like reducing lock scope and granularity, using lock stripping and striping, splitting hot points, and alternatives to exclusive locks. It also recommends reducing memory allocation and using immutable/thread local data. The document concludes by discussing lock-free programming and its advantages for scalability over locking.























































































