Downloaded 1,579 times











![CS211 17
Pipeline Performance: Speedup & Efficiency
k-stage pipeline processes n tasks in k + (n-1) clock
cycles:
k cycles for the first task and n-1 cycles
for the remaining n-1 tasks
Total time to process n tasks
Tk = [ k + (n-1)]
For the non-pipelined processor
T1 = n k
Speedup factor
Sk =
T1
Tk
=
n k
[ k + (n-1)]
=
n k
k + (n-1)
7](https://image.slidesharecdn.com/caopresentationpipelining-161213185856/85/Instruction-pipeline-Computer-Architecture-17-320.jpg)















![CS211 17
Pipeline Performance: Speedup & Efficiency
k-stage pipeline processes n tasks in k + (n-1) clock
cycles:
k cycles for the first task and n-1 cycles
for the remaining n-1 tasks
Total time to process n tasks
Tk = [ k + (n-1)]
For the non-pipelined processor
T1 = n k
Speedup factor
Sk =
T1
Tk
=
n k
[ k + (n-1)]
=
n k
k + (n-1)
7](https://image.slidesharecdn.com/caopresentationpipelining-161213185856/75/Instruction-pipeline-Computer-Architecture-17-2048.jpg)





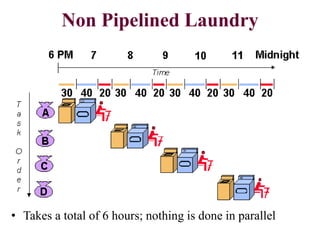
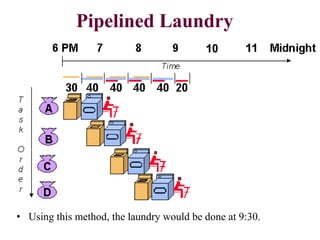
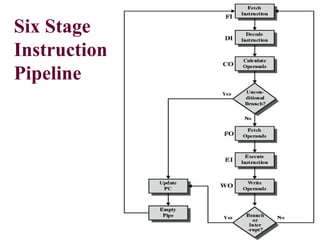
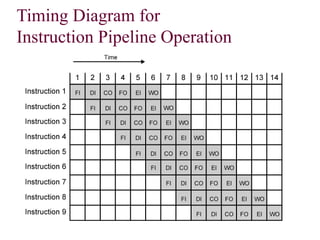
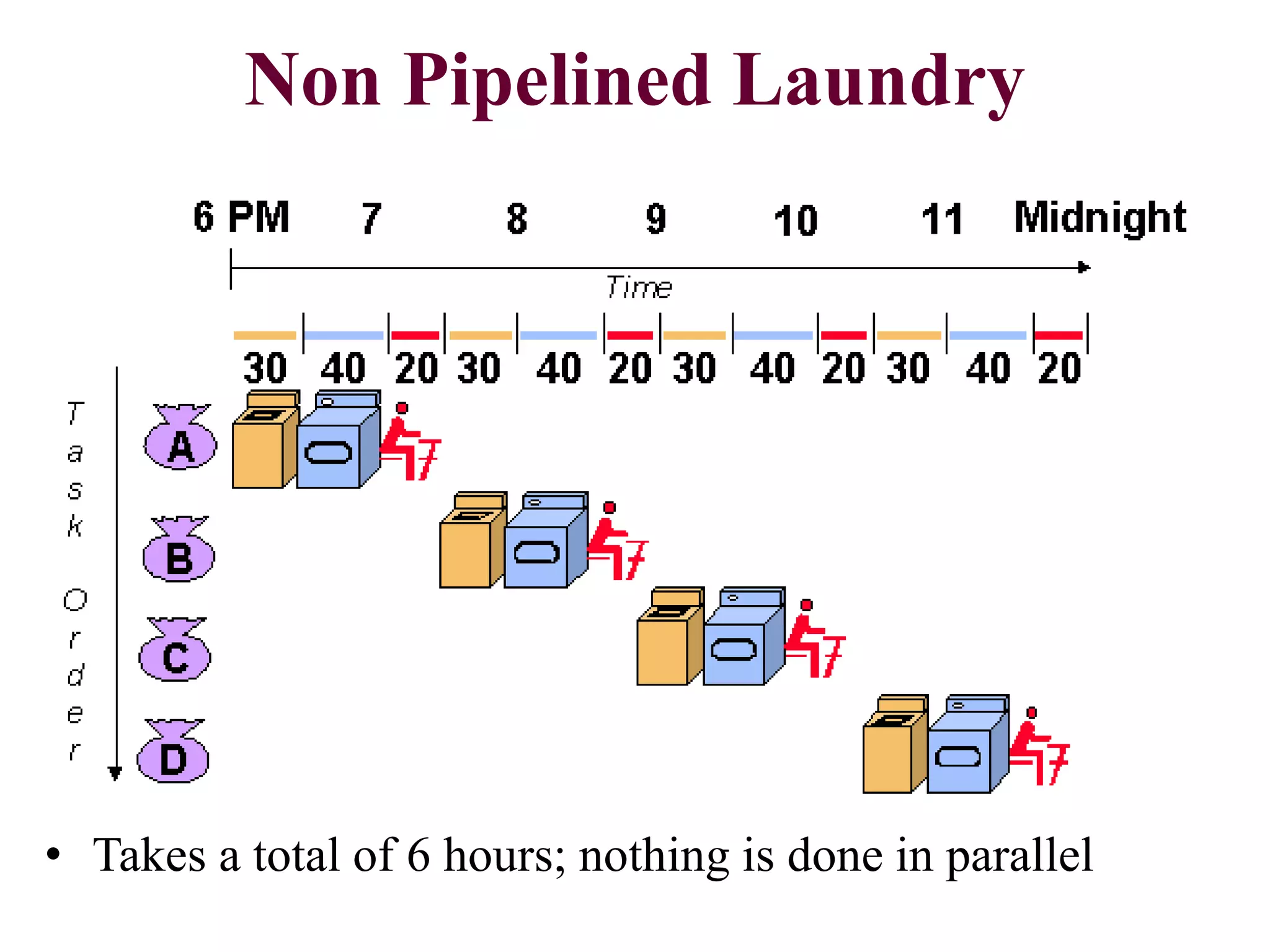
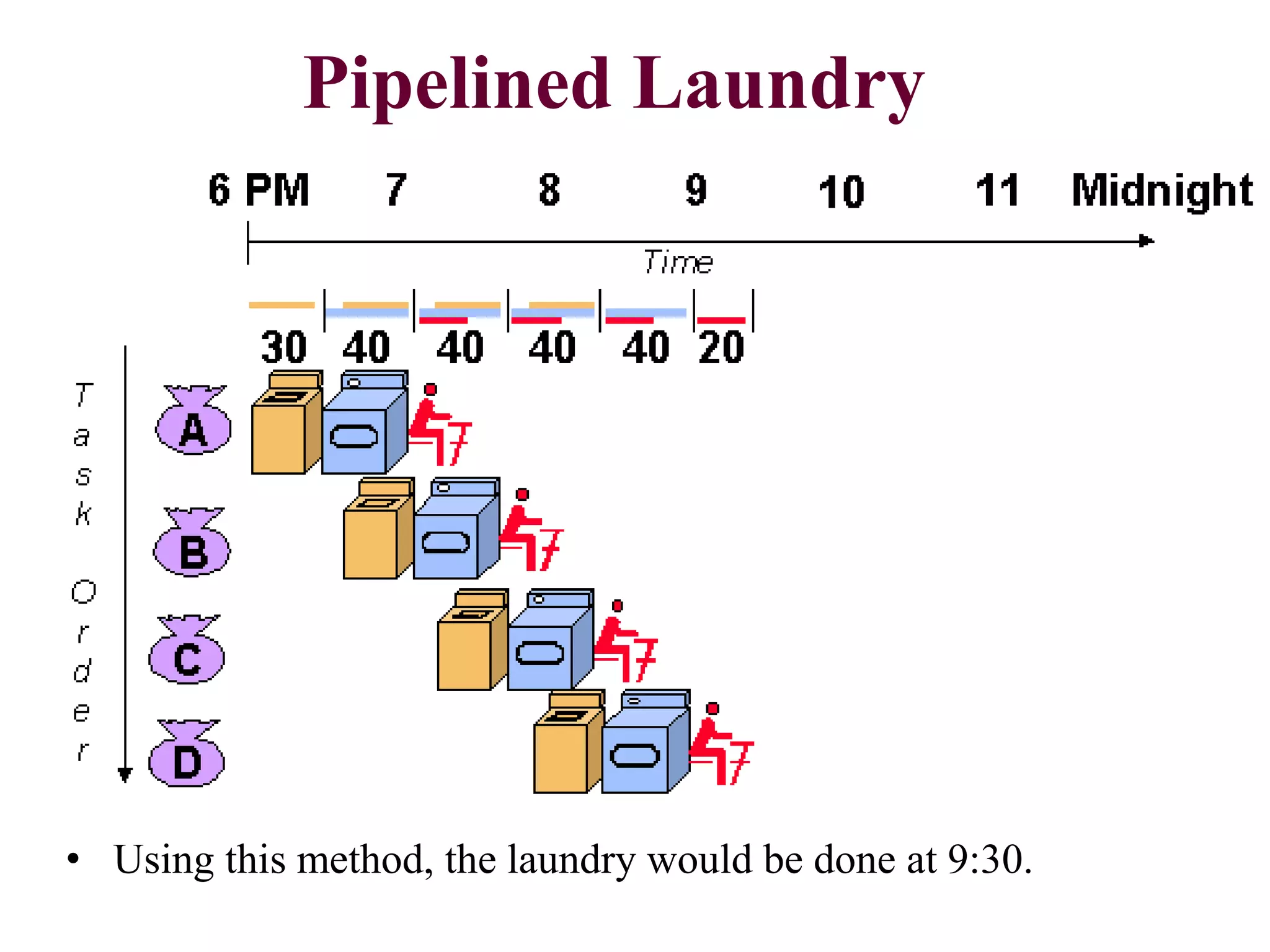
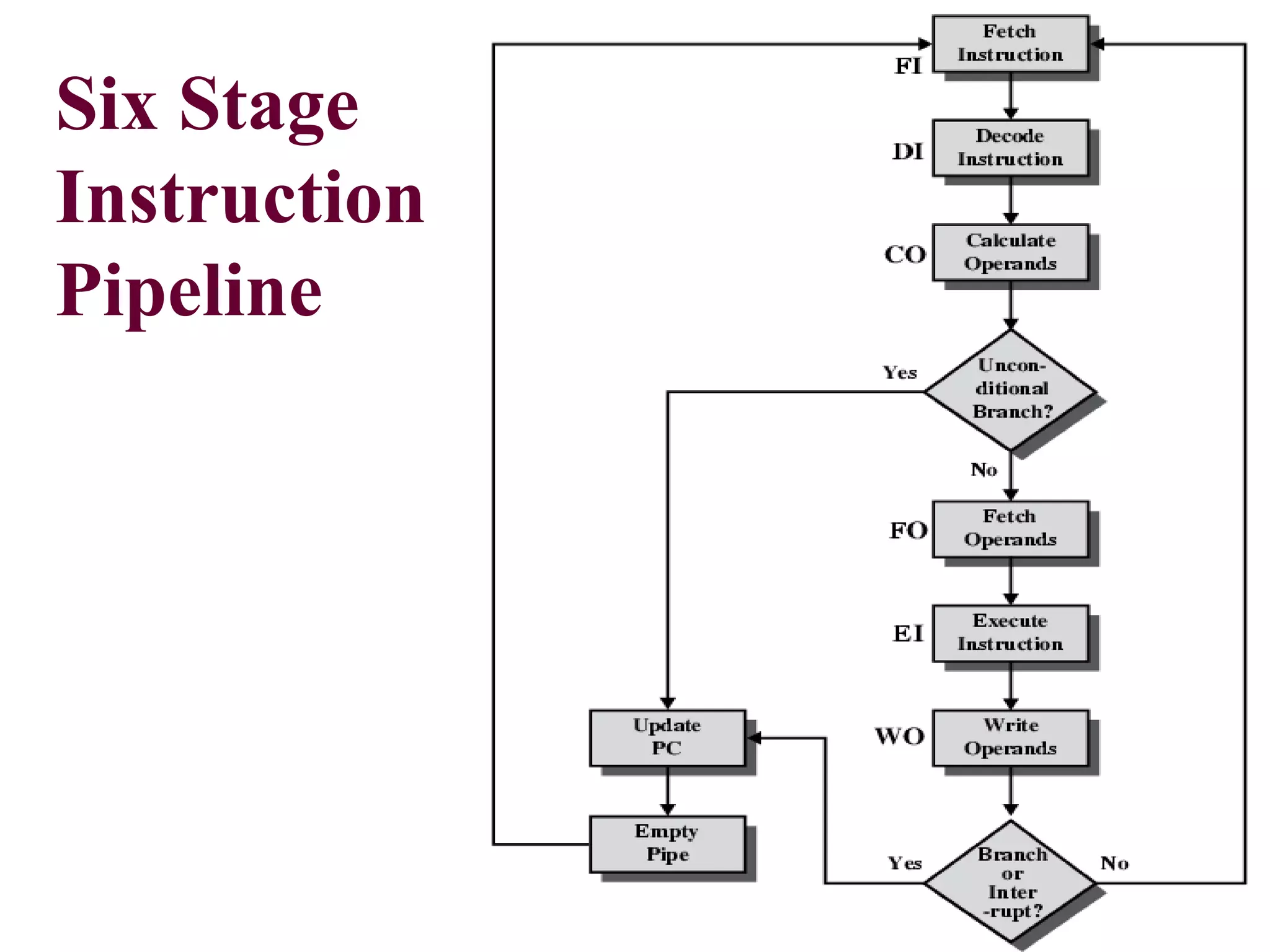
Pipelining is a technique that allows multiple instructions to be executed in overlapping stages, improving efficiency, similar to processing laundry in stages. Each instruction undergoes fetching, decoding, executing, and memory operations in a structured pipeline, which can lead to significant time savings compared to non-pipelined execution. However, there are potential hazards such as structural, data, and control hazards that must be managed to maintain performance.







































































