맵리듀스
• 함수 언어에서사용되던 것에서 유래
• Hadoop 에서 제공하는 프로그래밍 모델
• Map
– 데이터에서 Key,Value를 선출
• Reduce
– Key가 unique해질 때 까지 Value들을 정제
3.
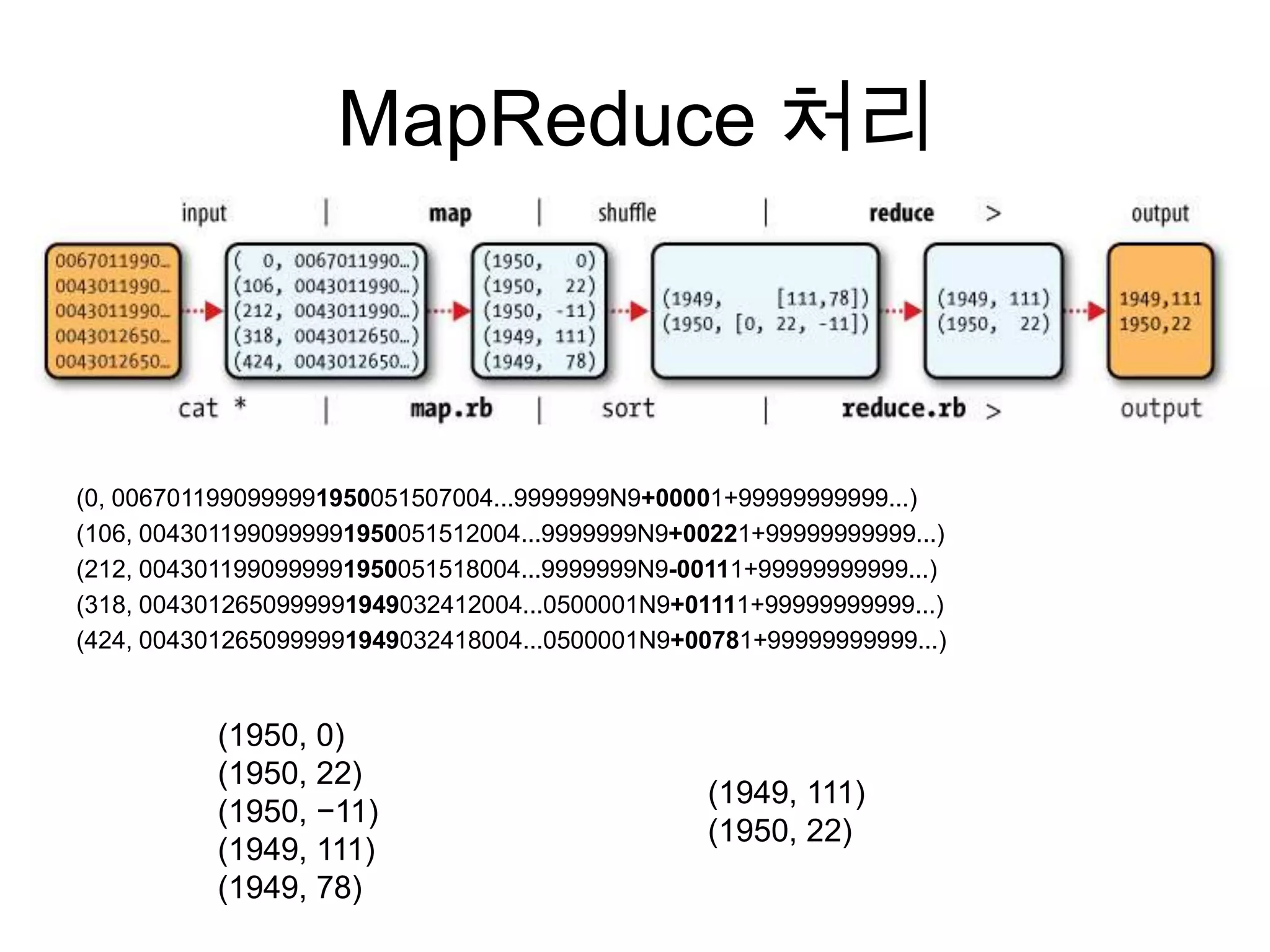
기상 데이터 예제
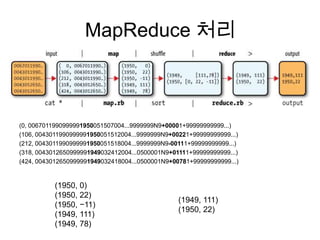
•NCDC의 1901~2001년 기상 데이터
• 0067011990999991950051507004...9999999N9+00001+99999999999...
• 0043011990999991950051512004...9999999N9+00221+99999999999...
• 0043011990999991950051518004...9999999N9-00111+99999999999...
4.
AWK 처리
#!/usr/bin/env bash
foryear in all/*
do
echo -ne `basename $year .gz`"t"
gunzip -c $year |
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
Done
툴 항목 비고
AWK 42분 1core 사용
MapReduce 6분 8core 사용
on a 10-node EC2 cluster running
High-CPU Extra Large Instances
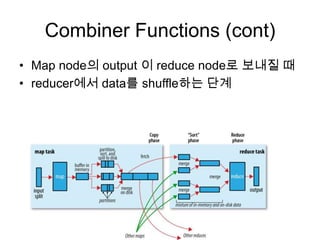
Map함수
모든 데이터는 Serialize 될 수 있어야 하며 Writeable을 구현한다.
Writeable은 DataInput, DataOutput java interface를 이용한다.
Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
emit ( key, value)
7.
Reduce 함수
Reduce는 멱등이어야 한다.
New API에서 Iterable 로 변경
신규 exception
8.
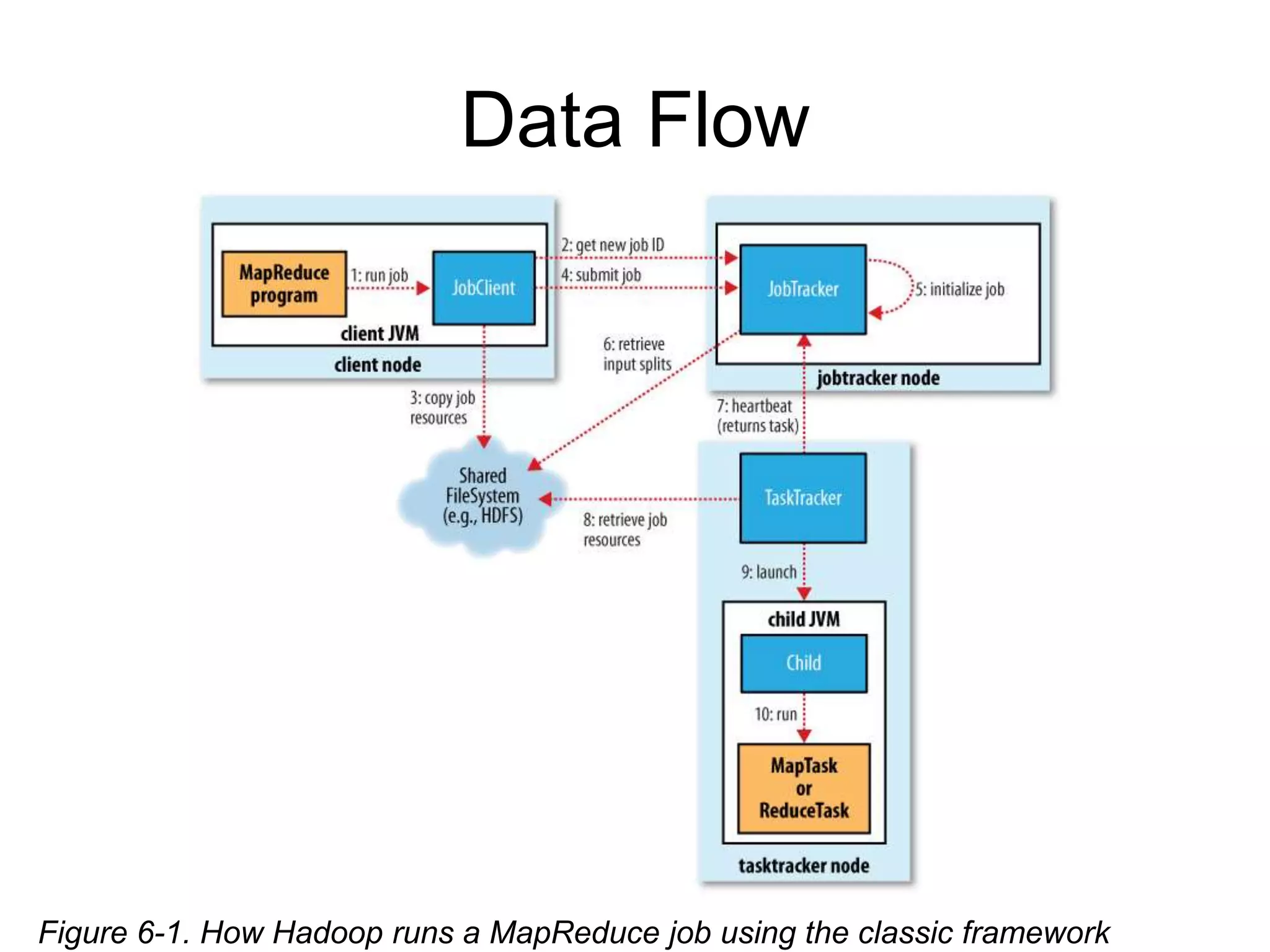
Main
Class이름으로현재 ClassPath에서 jar를
찾아 cluster들에 배포
Local, HDFS, S3 등
Output 만들어져 있어야 함
Job Running
9.
API 차이점
• 추상객체에기본적으로 구현이 되어 있는 것들을 사용
• namespace 이름을 fully 적음org.apache.hadoop.mapreduce
과거 org.apache.hadoop.mapred.
• Context의 역활이 커짐JobConf, the OutputCollector, and the
Reporter 의 역활 포함
• JobConf의 설정이 통합됨
• map, reduce의 run메소드 오버라이딩을 통해서 flow control 이
가능
• JobClient->Job
• java.lang.InterruptedException의 추가로 오버라이딩한 메소드
의 graceFully한 종료 가능
• reduce에서 받는 values가 iterator에서 iterable로 바뀌면서 for
(VALUEIN value : values) { ... } 사용 가능
10.
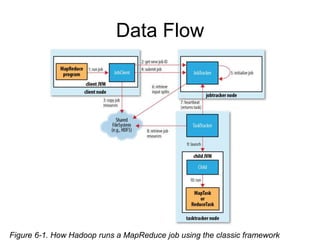
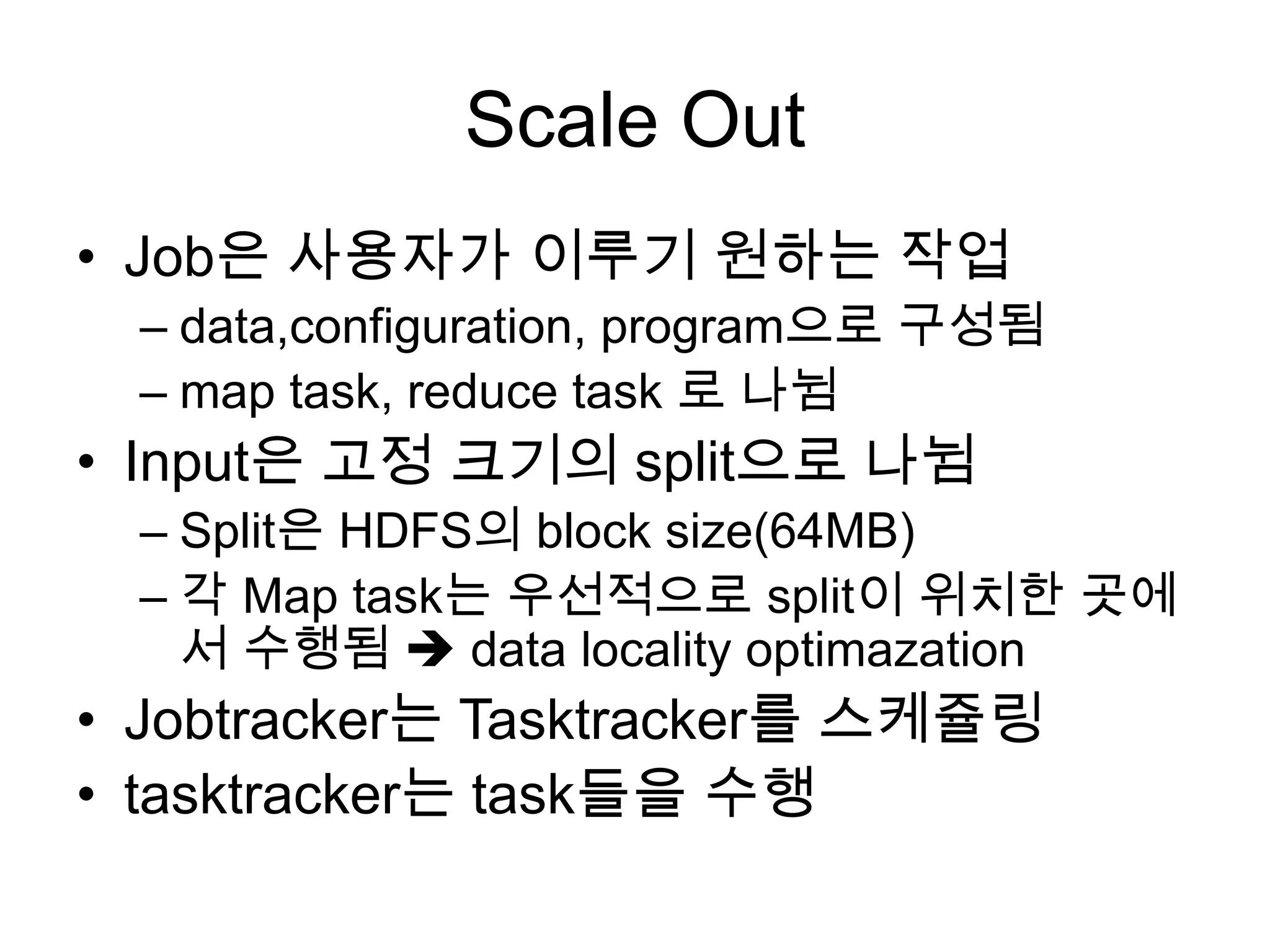
Scale Out
• Job은사용자가 이루기 원하는 작업
– data,configuration, program으로 구성됨
– map task, reduce task 로 나뉨
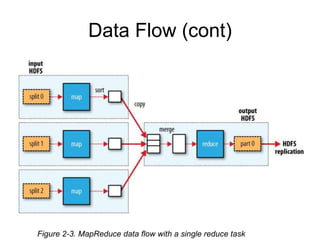
• Input은 고정 크기의 split으로 나뉨
– Split은 HDFS의 block size(64MB)
– 각 Map task는 우선적으로 split이 위치한 곳에
서 수행됨 data locality optimazation
• Jobtracker는 Tasktracker를 스케쥴링
• tasktracker는 task들을 수행
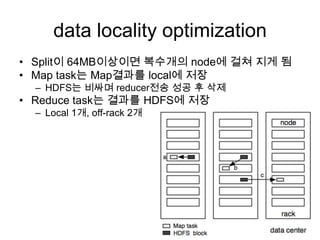
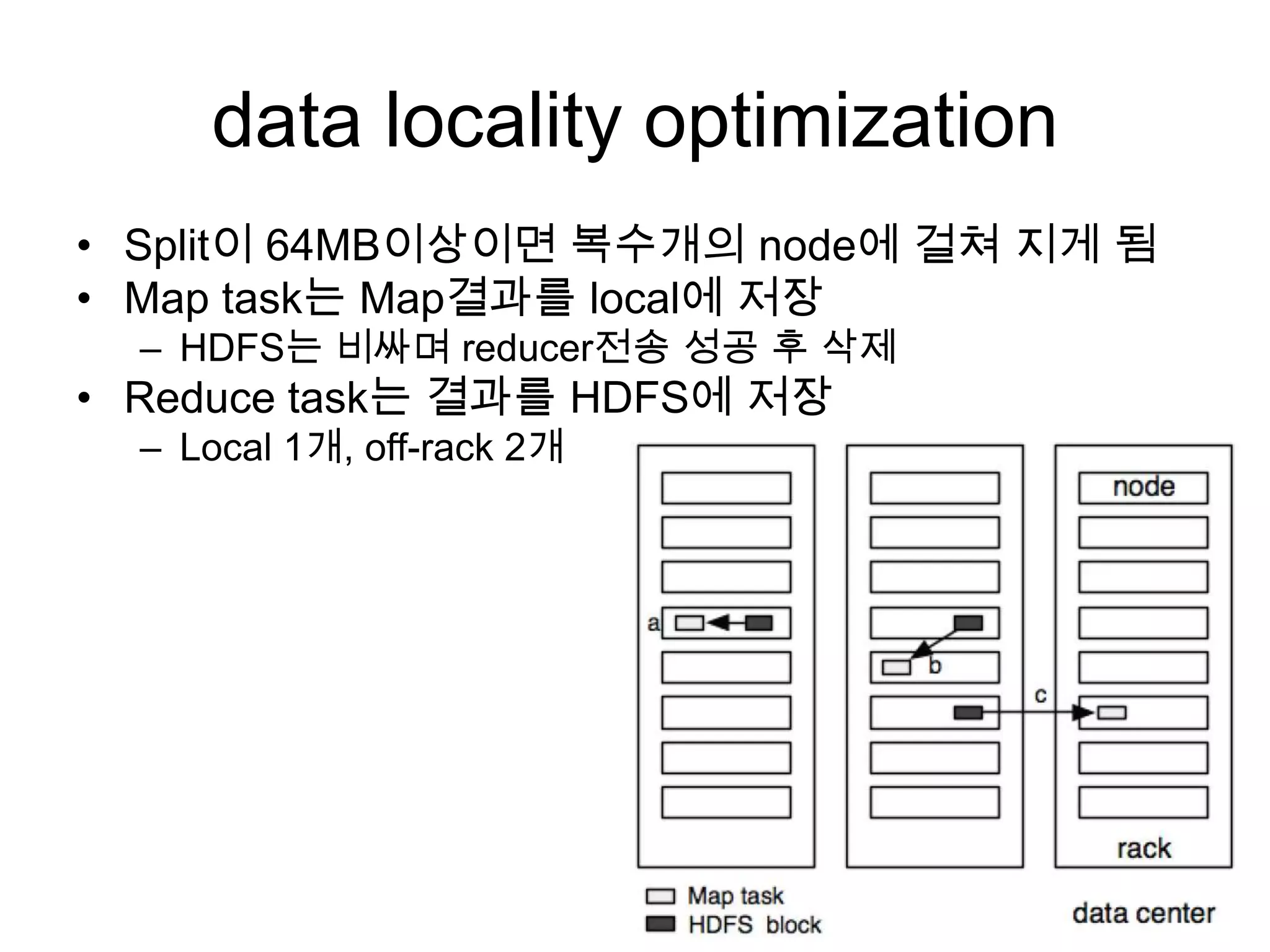
data locality optimization
•Split이 64MB이상이면 복수개의 node에 걸쳐 지게 됨
• Map task는 Map결과를 local에 저장
– HDFS는 비싸며 reducer전송 성공 후 삭제
• Reduce task는 결과를 HDFS에 저장
– Local 1개, off-rack 2개
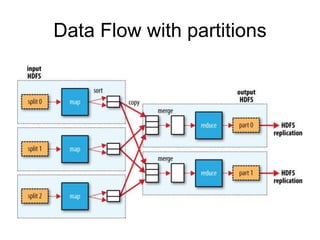
14.
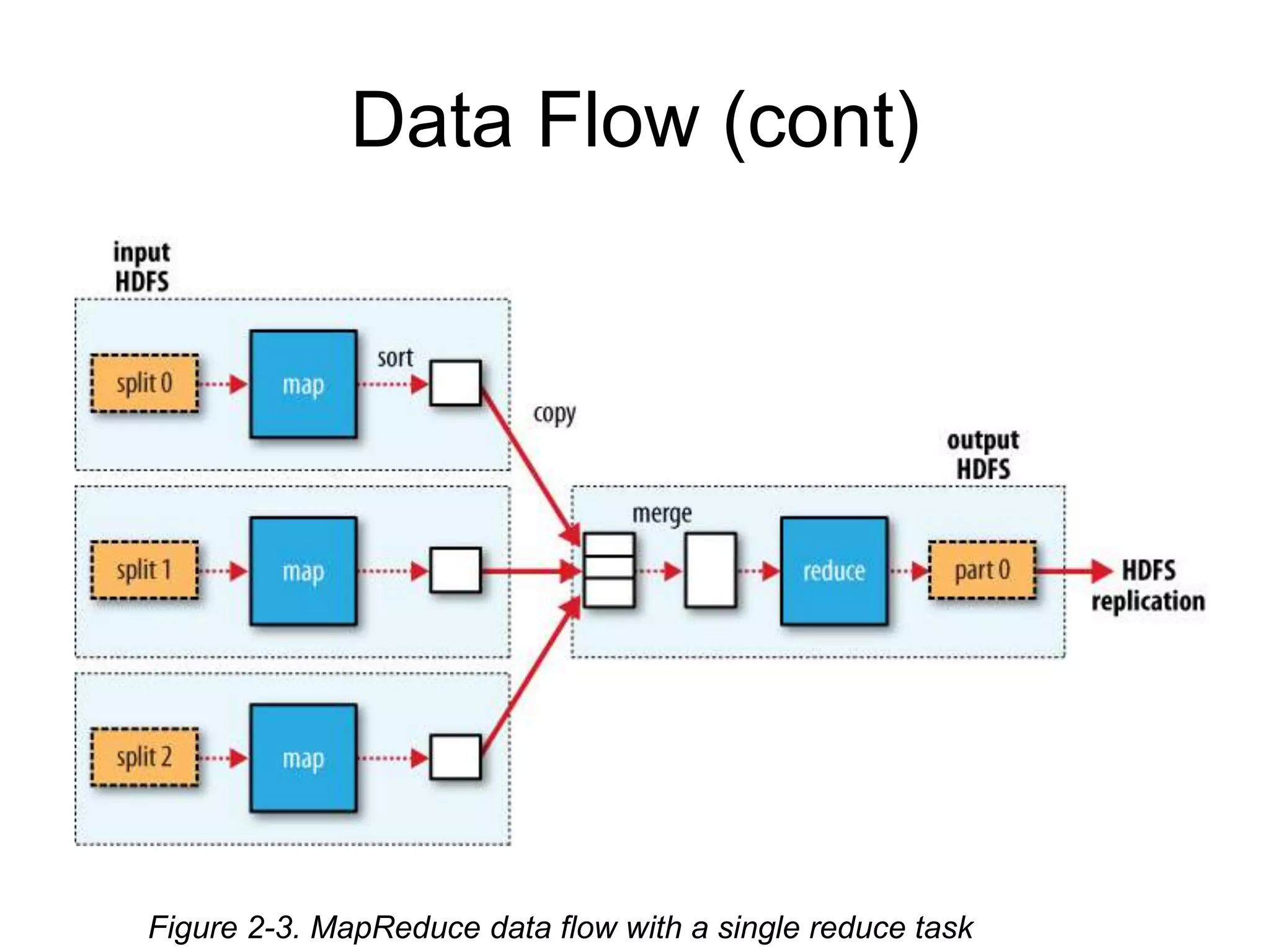
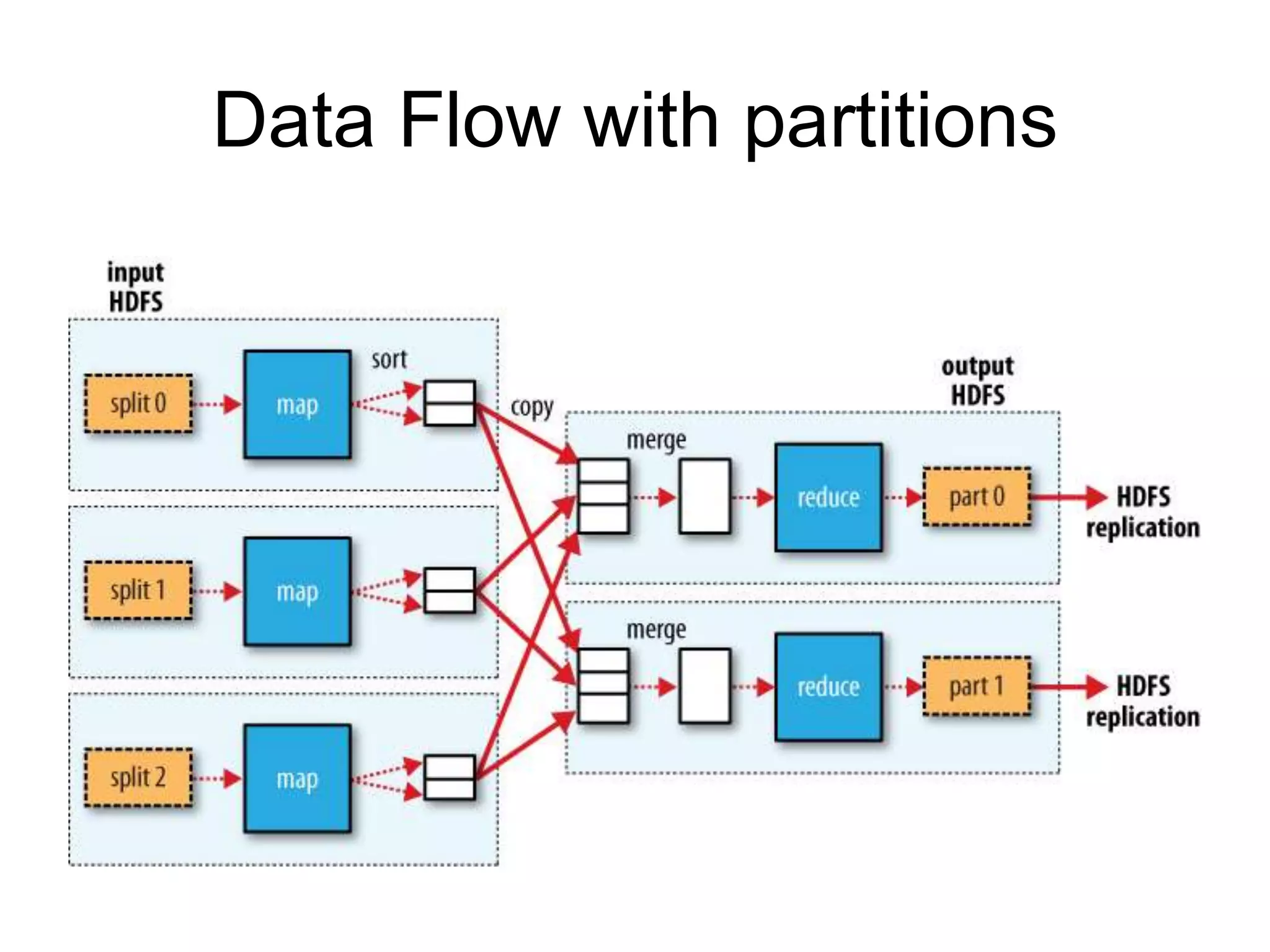
partition
• Reducer 개수는input 크기에 따라 결정되
지 않는다.
• Reduce task가 복수개면 map task는
output을 partition 으로 나눈다.
– 특정 key의 연관 데이터는 모두 한 Partition에
포함 된다.
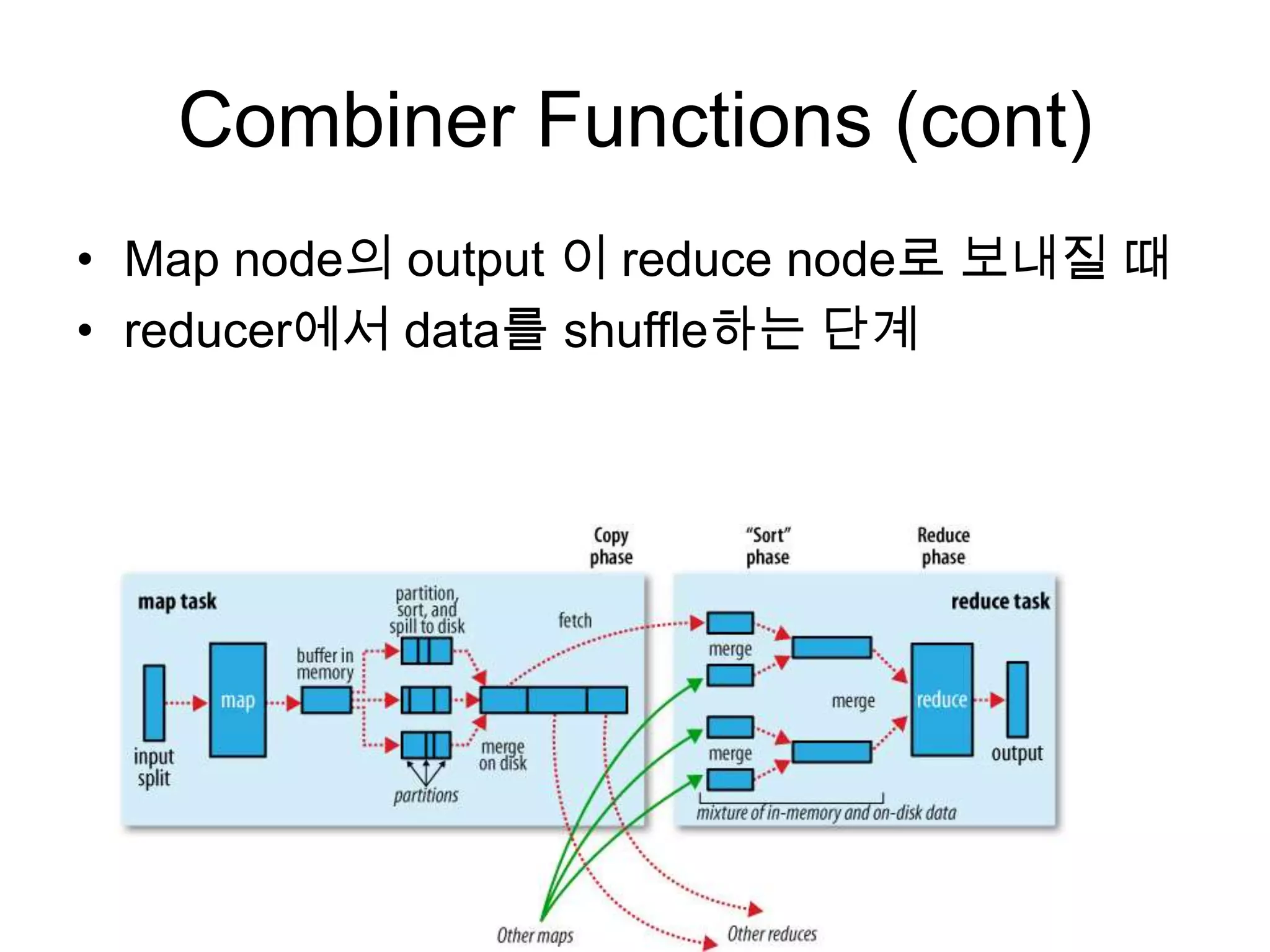
Hadoop Streaming
• stdio를 이용하는 map, reduce를 작성
• Hadoop 에서도 실행 가능 하도록 지원함
% cat input/ncdc/sample.txt | ch02/src/main/ruby/max_temperature_map.rb |
sort | ch02/src/main/ruby/max_temperature_reduce.rb
% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar
-input input/ncdc/sample.txt
-output output
-mapper ch02/src/main/ruby/max_temperature_map.rb
-reducer ch02/src/main/ruby/max_temperature_reduce.rb
19.
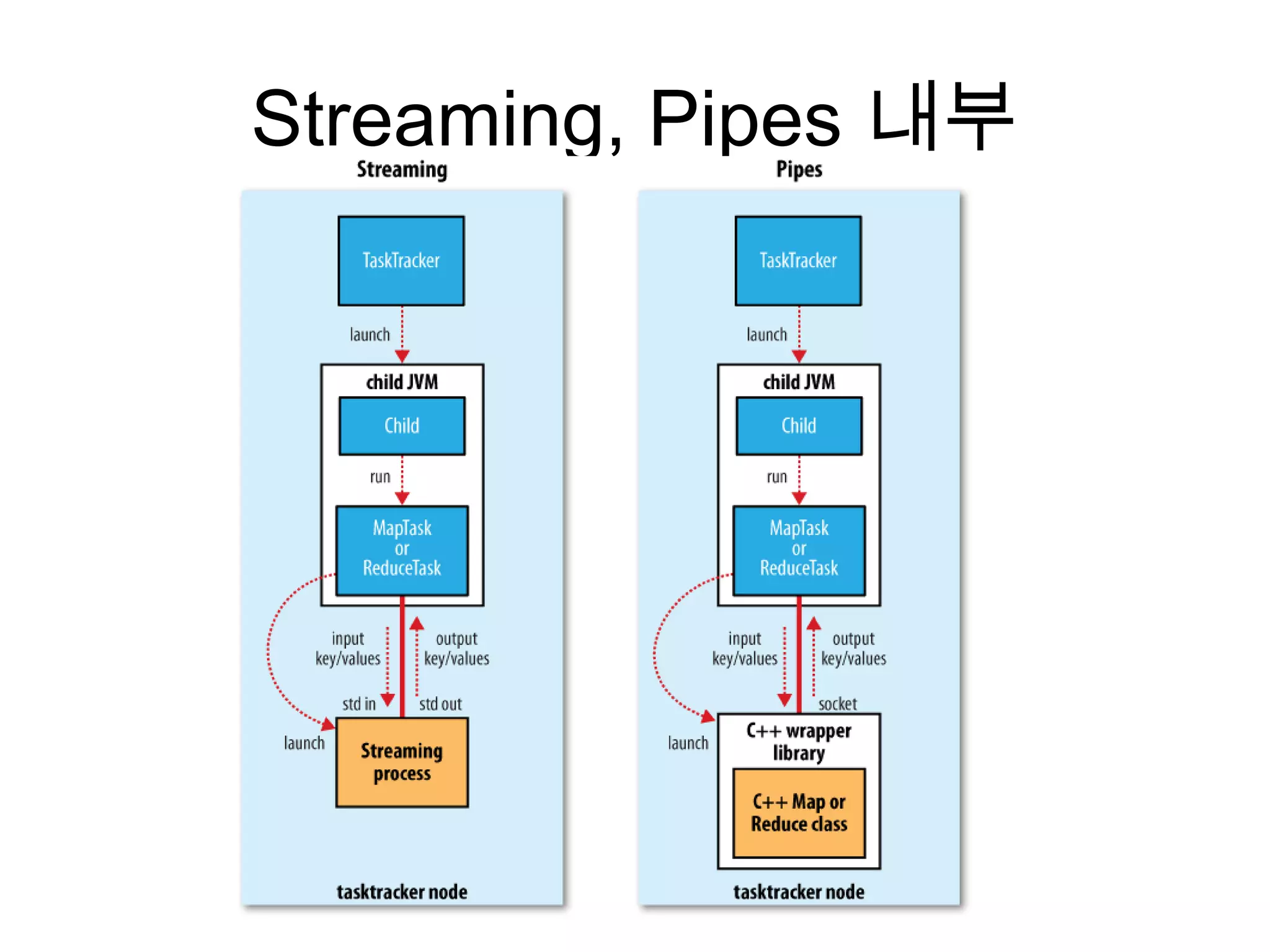
Hadoop Pipes
• C++을 위한 MapReduce interface
• tasktracker와 socket통신을 한다. JNI (X)
• Data가 HDFS에 존재 해야만 한다.
• C++과 Java 로직 혼용이 가능 하다.
Program내에 reader, writer가 존재함을 뜻함
“hadoop fs -put [A] [B]” 파일 배치 필요




![AWK 처리
#!/usr/bin/env bash
for year in all/*
do
echo -ne `basename $year .gz`"t"
gunzip -c $year |
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
Done
툴 항목 비고
AWK 42분 1core 사용
MapReduce 6분 8core 사용
on a 10-node EC2 cluster running
High-CPU Extra Large Instances](https://image.slidesharecdn.com/hadoopmapreduce-120503122500-phpapp01/85/introduce-of-Hadoop-map-reduce-4-320.jpg)








![Hadoop Pipes
• C++을 위한 MapReduce interface
• tasktracker와 socket통신을 한다. JNI (X)
• Data가 HDFS에 존재 해야만 한다.
• C++과 Java 로직 혼용이 가능 하다.
Program내에 reader, writer가 존재함을 뜻함
“hadoop fs -put [A] [B]” 파일 배치 필요](https://image.slidesharecdn.com/hadoopmapreduce-120503122500-phpapp01/85/introduce-of-Hadoop-map-reduce-19-320.jpg)



![AWK 처리
#!/usr/bin/env bash
for year in all/*
do
echo -ne `basename $year .gz`"t"
gunzip -c $year |
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
Done
툴 항목 비고
AWK 42분 1core 사용
MapReduce 6분 8core 사용
on a 10-node EC2 cluster running
High-CPU Extra Large Instances](https://image.slidesharecdn.com/hadoopmapreduce-120503122500-phpapp01/75/introduce-of-Hadoop-map-reduce-4-2048.jpg)







![Hadoop Pipes
• C++을 위한 MapReduce interface
• tasktracker와 socket통신을 한다. JNI (X)
• Data가 HDFS에 존재 해야만 한다.
• C++과 Java 로직 혼용이 가능 하다.
Program내에 reader, writer가 존재함을 뜻함
“hadoop fs -put [A] [B]” 파일 배치 필요](https://image.slidesharecdn.com/hadoopmapreduce-120503122500-phpapp01/75/introduce-of-Hadoop-map-reduce-19-2048.jpg)













![[Pgday.Seoul 2018] Greenplum의 노드 분산 설계](https://cdn.slidesharecdn.com/ss_thumbnails/02-20181103pgdayseminarv1-181112041352-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



![[빅데이터 컨퍼런스 전희원]](https://cdn.slidesharecdn.com/ss_thumbnails/random-120412212952-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
























![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=600ounds&width=560&fit=bounds)












