Downloaded 177 times






![Introducing NLP with R 10/6/14, 19:37
Impor6ng+text+into+R
· Primary importing functions: scan(), readLines()
monty_text = scan('data/grail.txt', what="character", sep="", quote="")
monty_text[1:6]
[1] "SCENE" "1:" "[wind]" "[clop" "clop" "clop]"
malayalam_text = scan('data/mathrubhumi_2014-10_full.txt',
what="character", sep="", quote="")
malayalam_text[15:20]
[1] "#Date:" "01-10-2014"
[3] "#----------------------------------------" "അേമരിkയിെലtിയ"
[5] "+പധാനമ+nി" "നേര+nേമാദി"
· Why might this data structure be a problem for many natural language structures?
7/26
http://docs.supstat.com/NLPwithR/#1 Page 7 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-7-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Condensing+to+single+text+stream
monty_text = paste(monty_text, collapse=" ")
malayalam_text = paste(malayalam_text, collapse=" ")
length(monty_text); length(malayalam_text)
[1] 1
[1] 1
substr(monty_text, 1, 70)
[1] "SCENE 1: [wind] [clop clop clop] KING ARTHUR: Whoa there! [clop clop c"
substr(malayalam_text, 304, 400)
[1] "െത4ായി ഉcരിc് അേdഹെt അനാദരിcുെവn് െക.പി.സി.സി. +പസിഡn് വി.എം. സുധീരD. േമാഹDദ"
8/26
http://docs.supstat.com/NLPwithR/#1 Page 8 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-8-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Regular+Expressions
SYMBOL MEANING EXAMPLE
[] Disjunction (set) / [Gg]oogle / = Google, google
? 0 or 1 characters / savou?r / = savor, savour
* 0 or more characters / hey!* / = hey, hey!, hey!!, ...
Escape character / hey? / = hey?
+ 1 or more characters / a+h / = ah, aah, aaah, ...
{n, m} n to m repetitions / a{1-4}h{1-3} / = aahh, ahhh, ...
. Wildcard (any character) / #.* / = #rstats, #uofl, ...
() Conjunction / (ha)+ / = ha, haha, hahaha, ...
[^ ] NOT (negates bracketed chars) / [^ #.*] / = everything but #...
9/26
http://docs.supstat.com/NLPwithR/#1 Page 9 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-9-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Regular+Expressions
SYMBOL MEANING EXAMPLE
[x-y] Match characters from 'x' to 'y' / [A-Z][1-9] / = A1, Q8, X5, ...
w Word character (alphanumeric) / w's / = that's, Jerry's, ...
W Non-word character
d Digit character (0-9) / d{3} / = 137, 254, ...
D Non-digit character
s Whitespace / w+s+w+ / = I am, I am, ...
S Non-whitespace
b Word boundary / btheb / = the, not then
B Non-word boundary
^ Beginning of line / [a-z] / = non-capitalized beg.
$ End of line / #.*$ / = hashtags at end of line
10/26
http://docs.supstat.com/NLPwithR/#1 Page 10 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-10-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
The advantage of having all the text in a single element is we can now split the text into different-sized
segments for different kinds of natural language tasks.
#sentence level
pattern = "(?<=[.?!])s+"
monty_sentences = strsplit(monty_text, split=pattern, perl=T)
monty_sentences = unlist(monty_sentences)
monty_sentences[5:8]
[1] "King of the Britons, defeator of the Saxons, sovereign of all England!"
[2] "SOLDIER #1: Pull the other one!"
[3] "ARTHUR: I am, ..."
[4] "and this is my trusty servant Patsy."
11/26
http://docs.supstat.com/NLPwithR/#1 Page 11 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-11-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
Of course, depending on the language you're working with you might have different definitions of
sentence boundaries. For example, Hindi uses what's called a danda marker, । , in place of a period.
hindi_text = scan('data/hindustan_full.txt', what="character", sep="")
hindi_text = paste(hindi_text, collapse=" ")
pattern = "(?<=[।?!])s+"
hindi_sentences = strsplit(hindi_text, split=pattern, perl=T)
hindi_sentences = unlist(hindi_sentences)
hindi_sentences[5:8]
[1] "व"# मन# को लोकसभा चuनाव . करारी हार का सामना करना पड़ा था और उसका खाता भी नह9 खuल पाया था।"
[2] "लोकसभा चuनाव . भाजपा और िशव#ना > कuछ छोA दलo D साथ िमलकर 48 . # 42 सीAE जीत9।"
[3] "महाराFG . िशव#ना अब तक भाजपा D बड़e भाई की भLिमका iनभाती रही थी।"
[4] "इन दोनo D बीच उस वOत अलगाव Qआ S जब भाजपा TU . नVU मोदी D >तWXव . पLणZ बQमत D साथ स[ासीन S।"
12/26
http://docs.supstat.com/NLPwithR/#1 Page 12 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-12-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
We can also split the original text according to word boundaries.
#word level
pattern = "[()[]":;,.?!-]*s+[()[]":;,.?!-]*"
monty_words = strsplit(monty_text, split=pattern, perl=T)
monty_words = unlist(monty_words)
monty_words[5:30]
[1] "clop" "clop" "KING" "ARTHUR" "Whoa" "there" "clop" "clop"
[9] "clop" "SOLDIER" "#1" "Halt" "Who" "goes" "there" "ARTHUR"
[17] "It" "is" "I" "Arthur" "son" "of" "Uther" "Pendragon"
[25] "from" "the"
13/26
http://docs.supstat.com/NLPwithR/#1 Page 13 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-13-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Building+a+Lexicon
For many NLP tasks it is useful to have a dictionary, or lexicon, of the language you're working with.
Other researchers may have already built a text-formatted lexicon of the language you're using, but
nevertheless it's useful to see how we might build one.
#convert all words to lowercase
monty_words = tolower(monty_words)
monty_words[1:9]
[1] "scene" "1" "wind" "clop" "clop" "clop" "king" "arthur" "whoa"
#convert vector of tokens to set of unique words
monty_lexicon = unique(monty_words)
monty_lexicon[1:8]
[1] "scene" "1" "wind" "clop" "king" "arthur" "whoa" "there"
14/26
http://docs.supstat.com/NLPwithR/#1 Page 14 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-14-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Building+a+Lexicon
length(monty_words)
[1] 11213
length(monty_lexicon)
[1] 1889
15/26
http://docs.supstat.com/NLPwithR/#1 Page 15 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-15-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
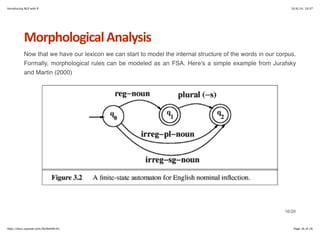
Morphological+Analysis
But since it has already been proven that all regular expressions can be modeled as FSAs, and vice
versa, we can utilize the grep utilities in R to handle this process. First let's see if we can extract all
the agentive nouns (e.g. builder, worker, shopper, etc.).
monty_agents = grep('.+er$', monty_lexicon, perl=T, value=T)
monty_agents[1:30]
[1] "soldier" "uther" "other" "master" "together" "winter"
[7] "plover" "warmer" "matter" "order" "creeper" "under"
[13] "cart-master" "customer" "better" "over" "bother" "ever"
[19] "officer" "her" "water" "power" "mer" "villager"
[25] "whether" "cider" "e'er" "prisoner" "shelter" "wiper"
· This isn't exactly what we want. How can we improve our results?
17/26
http://docs.supstat.com/NLPwithR/#1 Page 17 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-17-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
Morphological+Analysis
Take advantage of the lexicon.
monty_agents = grep('.+er$', monty_lexicon, perl=T, value=T)
new_monty_agents = character(0)
for (i in 1:length(monty_agents)) {
word = monty_agents[i]
stem_end = nchar(word) - 2
stem = substr(word, 1, stem_end)
if (is.element(stem, monty_lexicon)) {
new_monty_agents[i] = word
}
}
new_monty_agents = new_monty_agents[!is.na(new_monty_agents)]
new_monty_agents
[1] "warmer" "creeper" "longer" "nearer" "higher" "killer" "bleeder" "keeper"
18/26
http://docs.supstat.com/NLPwithR/#1 Page 18 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-18-320.jpg)
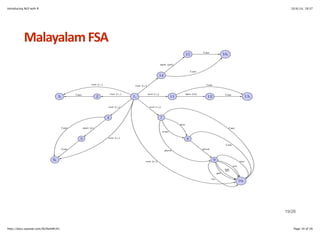

![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
library(ngram)
monty_bigram = ngram(monty_text, n=2)
get.ngrams(monty_bigram)[1:10]
[1] "cannot tell," "away. Just" "not 'is'." "bowels unplugged,"
[5] "well, Arthur," "[twang] Wayy!" "HERBERT: B--" "no. Until"
[9] "trade. I" "down, fell"
monty_trigram = ngram(monty_text, n=3)
get.ngrams(monty_trigram)[1:10]
[1] "a good spanking!" "Oooh! GALAHAD: My" "is the capital" "to you no"
[5] "Who's that then?" "you get back." "no arms left." "want... a shrubbery!"
[9] "Shut up! Um," "to a successful"
21/26
http://docs.supstat.com/NLPwithR/#1 Page 21 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-21-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
print(monty_bigram, full=TRUE)
cannot tell,
suffice {1} |
away. Just
ignore {1} |
not 'is'.
HEAD {1} | You {2} | Not {1} |
bowels unplugged,
And {1} |
well, Arthur,
for {1} |
[twang] Wayy!
[twang] {1} |
22/26
http://docs.supstat.com/NLPwithR/#1 Page 22 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-22-320.jpg)

![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
babble(monty_bigram, 8)
[1] "must go too. OFFICER #1: Back. Right away. "
babble(monty_bigram, 8)
[1] "I'll do you up a treat mate! GALAHAD: "
babble(monty_bigram, 8)
[1] "from just stop him entering the room. GUARD "
24/26
http://docs.supstat.com/NLPwithR/#1 Page 24 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-24-320.jpg)
![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
babble(monty_trigram, 8)
[1] "were still no nearer the Grail. Meanwhile, King "
babble(monty_trigram, 8)
[1] "the Britons. BEDEVERE: My liege! I would be "
babble(monty_trigram, 8)
[1] "Shh! VILLAGER #2: Wood! BEDEVERE: So, why do "
25/26
http://docs.supstat.com/NLPwithR/#1 Page 25 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/85/Introducing-natural-language-processing-NLP-with-r-25-320.jpg)







![Introducing NLP with R 10/6/14, 19:37
Impor6ng+text+into+R
· Primary importing functions: scan(), readLines()
monty_text = scan('data/grail.txt', what="character", sep="", quote="")
monty_text[1:6]
[1] "SCENE" "1:" "[wind]" "[clop" "clop" "clop]"
malayalam_text = scan('data/mathrubhumi_2014-10_full.txt',
what="character", sep="", quote="")
malayalam_text[15:20]
[1] "#Date:" "01-10-2014"
[3] "#----------------------------------------" "അേമരിkയിെലtിയ"
[5] "+പധാനമ+nി" "നേര+nേമാദി"
· Why might this data structure be a problem for many natural language structures?
7/26
http://docs.supstat.com/NLPwithR/#1 Page 7 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-7-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Condensing+to+single+text+stream
monty_text = paste(monty_text, collapse=" ")
malayalam_text = paste(malayalam_text, collapse=" ")
length(monty_text); length(malayalam_text)
[1] 1
[1] 1
substr(monty_text, 1, 70)
[1] "SCENE 1: [wind] [clop clop clop] KING ARTHUR: Whoa there! [clop clop c"
substr(malayalam_text, 304, 400)
[1] "െത4ായി ഉcരിc് അേdഹെt അനാദരിcുെവn് െക.പി.സി.സി. +പസിഡn് വി.എം. സുധീരD. േമാഹDദ"
8/26
http://docs.supstat.com/NLPwithR/#1 Page 8 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-8-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Regular+Expressions
SYMBOL MEANING EXAMPLE
[] Disjunction (set) / [Gg]oogle / = Google, google
? 0 or 1 characters / savou?r / = savor, savour
* 0 or more characters / hey!* / = hey, hey!, hey!!, ...
Escape character / hey? / = hey?
+ 1 or more characters / a+h / = ah, aah, aaah, ...
{n, m} n to m repetitions / a{1-4}h{1-3} / = aahh, ahhh, ...
. Wildcard (any character) / #.* / = #rstats, #uofl, ...
() Conjunction / (ha)+ / = ha, haha, hahaha, ...
[^ ] NOT (negates bracketed chars) / [^ #.*] / = everything but #...
9/26
http://docs.supstat.com/NLPwithR/#1 Page 9 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-9-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Regular+Expressions
SYMBOL MEANING EXAMPLE
[x-y] Match characters from 'x' to 'y' / [A-Z][1-9] / = A1, Q8, X5, ...
w Word character (alphanumeric) / w's / = that's, Jerry's, ...
W Non-word character
d Digit character (0-9) / d{3} / = 137, 254, ...
D Non-digit character
s Whitespace / w+s+w+ / = I am, I am, ...
S Non-whitespace
b Word boundary / btheb / = the, not then
B Non-word boundary
^ Beginning of line / [a-z] / = non-capitalized beg.
$ End of line / #.*$ / = hashtags at end of line
10/26
http://docs.supstat.com/NLPwithR/#1 Page 10 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-10-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
The advantage of having all the text in a single element is we can now split the text into different-sized
segments for different kinds of natural language tasks.
#sentence level
pattern = "(?<=[.?!])s+"
monty_sentences = strsplit(monty_text, split=pattern, perl=T)
monty_sentences = unlist(monty_sentences)
monty_sentences[5:8]
[1] "King of the Britons, defeator of the Saxons, sovereign of all England!"
[2] "SOLDIER #1: Pull the other one!"
[3] "ARTHUR: I am, ..."
[4] "and this is my trusty servant Patsy."
11/26
http://docs.supstat.com/NLPwithR/#1 Page 11 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-11-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
Of course, depending on the language you're working with you might have different definitions of
sentence boundaries. For example, Hindi uses what's called a danda marker, । , in place of a period.
hindi_text = scan('data/hindustan_full.txt', what="character", sep="")
hindi_text = paste(hindi_text, collapse=" ")
pattern = "(?<=[।?!])s+"
hindi_sentences = strsplit(hindi_text, split=pattern, perl=T)
hindi_sentences = unlist(hindi_sentences)
hindi_sentences[5:8]
[1] "व"# मन# को लोकसभा चuनाव . करारी हार का सामना करना पड़ा था और उसका खाता भी नह9 खuल पाया था।"
[2] "लोकसभा चuनाव . भाजपा और िशव#ना > कuछ छोA दलo D साथ िमलकर 48 . # 42 सीAE जीत9।"
[3] "महाराFG . िशव#ना अब तक भाजपा D बड़e भाई की भLिमका iनभाती रही थी।"
[4] "इन दोनo D बीच उस वOत अलगाव Qआ S जब भाजपा TU . नVU मोदी D >तWXव . पLणZ बQमत D साथ स[ासीन S।"
12/26
http://docs.supstat.com/NLPwithR/#1 Page 12 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-12-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Manual+segmenta6on
We can also split the original text according to word boundaries.
#word level
pattern = "[()[]":;,.?!-]*s+[()[]":;,.?!-]*"
monty_words = strsplit(monty_text, split=pattern, perl=T)
monty_words = unlist(monty_words)
monty_words[5:30]
[1] "clop" "clop" "KING" "ARTHUR" "Whoa" "there" "clop" "clop"
[9] "clop" "SOLDIER" "#1" "Halt" "Who" "goes" "there" "ARTHUR"
[17] "It" "is" "I" "Arthur" "son" "of" "Uther" "Pendragon"
[25] "from" "the"
13/26
http://docs.supstat.com/NLPwithR/#1 Page 13 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-13-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Building+a+Lexicon
For many NLP tasks it is useful to have a dictionary, or lexicon, of the language you're working with.
Other researchers may have already built a text-formatted lexicon of the language you're using, but
nevertheless it's useful to see how we might build one.
#convert all words to lowercase
monty_words = tolower(monty_words)
monty_words[1:9]
[1] "scene" "1" "wind" "clop" "clop" "clop" "king" "arthur" "whoa"
#convert vector of tokens to set of unique words
monty_lexicon = unique(monty_words)
monty_lexicon[1:8]
[1] "scene" "1" "wind" "clop" "king" "arthur" "whoa" "there"
14/26
http://docs.supstat.com/NLPwithR/#1 Page 14 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-14-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Building+a+Lexicon
length(monty_words)
[1] 11213
length(monty_lexicon)
[1] 1889
15/26
http://docs.supstat.com/NLPwithR/#1 Page 15 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-15-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
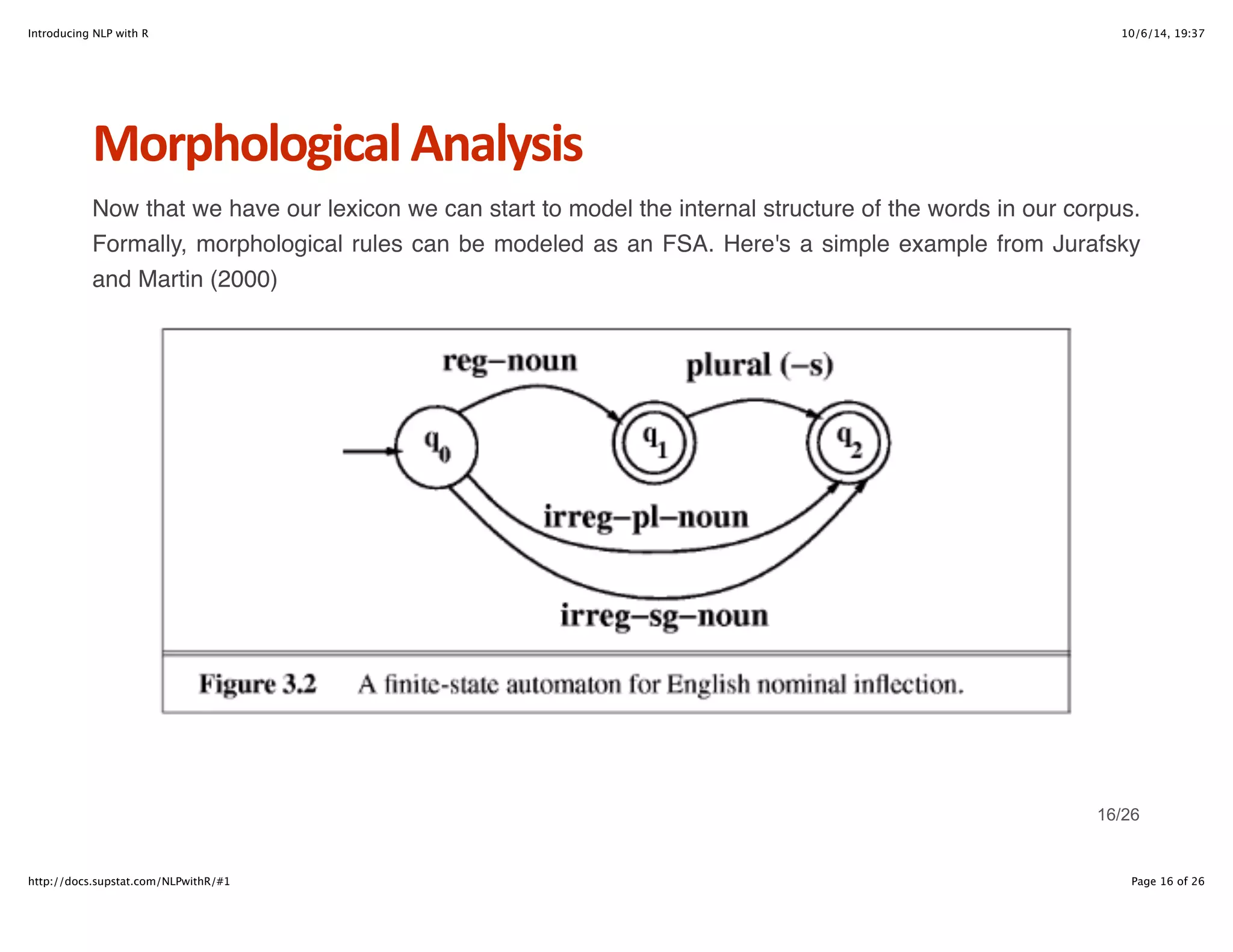
Morphological+Analysis
But since it has already been proven that all regular expressions can be modeled as FSAs, and vice
versa, we can utilize the grep utilities in R to handle this process. First let's see if we can extract all
the agentive nouns (e.g. builder, worker, shopper, etc.).
monty_agents = grep('.+er$', monty_lexicon, perl=T, value=T)
monty_agents[1:30]
[1] "soldier" "uther" "other" "master" "together" "winter"
[7] "plover" "warmer" "matter" "order" "creeper" "under"
[13] "cart-master" "customer" "better" "over" "bother" "ever"
[19] "officer" "her" "water" "power" "mer" "villager"
[25] "whether" "cider" "e'er" "prisoner" "shelter" "wiper"
· This isn't exactly what we want. How can we improve our results?
17/26
http://docs.supstat.com/NLPwithR/#1 Page 17 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-17-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
Morphological+Analysis
Take advantage of the lexicon.
monty_agents = grep('.+er$', monty_lexicon, perl=T, value=T)
new_monty_agents = character(0)
for (i in 1:length(monty_agents)) {
word = monty_agents[i]
stem_end = nchar(word) - 2
stem = substr(word, 1, stem_end)
if (is.element(stem, monty_lexicon)) {
new_monty_agents[i] = word
}
}
new_monty_agents = new_monty_agents[!is.na(new_monty_agents)]
new_monty_agents
[1] "warmer" "creeper" "longer" "nearer" "higher" "killer" "bleeder" "keeper"
18/26
http://docs.supstat.com/NLPwithR/#1 Page 18 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-18-2048.jpg)
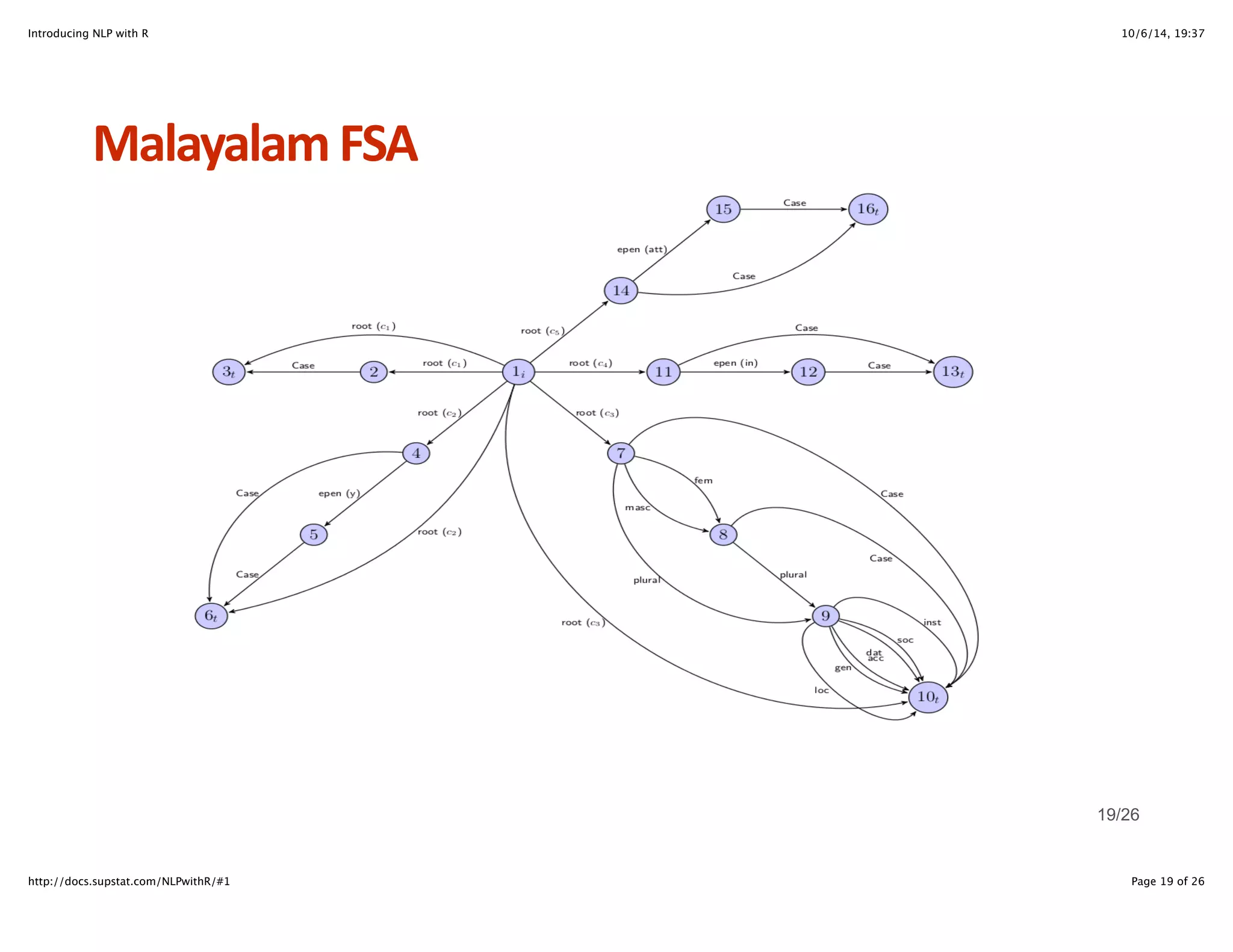

![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
library(ngram)
monty_bigram = ngram(monty_text, n=2)
get.ngrams(monty_bigram)[1:10]
[1] "cannot tell," "away. Just" "not 'is'." "bowels unplugged,"
[5] "well, Arthur," "[twang] Wayy!" "HERBERT: B--" "no. Until"
[9] "trade. I" "down, fell"
monty_trigram = ngram(monty_text, n=3)
get.ngrams(monty_trigram)[1:10]
[1] "a good spanking!" "Oooh! GALAHAD: My" "is the capital" "to you no"
[5] "Who's that then?" "you get back." "no arms left." "want... a shrubbery!"
[9] "Shut up! Um," "to a successful"
21/26
http://docs.supstat.com/NLPwithR/#1 Page 21 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-21-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
print(monty_bigram, full=TRUE)
cannot tell,
suffice {1} |
away. Just
ignore {1} |
not 'is'.
HEAD {1} | You {2} | Not {1} |
bowels unplugged,
And {1} |
well, Arthur,
for {1} |
[twang] Wayy!
[twang] {1} |
22/26
http://docs.supstat.com/NLPwithR/#1 Page 22 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-22-2048.jpg)

![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
babble(monty_bigram, 8)
[1] "must go too. OFFICER #1: Back. Right away. "
babble(monty_bigram, 8)
[1] "I'll do you up a treat mate! GALAHAD: "
babble(monty_bigram, 8)
[1] "from just stop him entering the room. GUARD "
24/26
http://docs.supstat.com/NLPwithR/#1 Page 24 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-24-2048.jpg)
![Introducing NLP with R 10/6/14, 19:37
NHgram+Models
babble(monty_trigram, 8)
[1] "were still no nearer the Grail. Meanwhile, King "
babble(monty_trigram, 8)
[1] "the Britons. BEDEVERE: My liege! I would be "
babble(monty_trigram, 8)
[1] "Shh! VILLAGER #2: Wood! BEDEVERE: So, why do "
25/26
http://docs.supstat.com/NLPwithR/#1 Page 25 of 26](https://image.slidesharecdn.com/introducingnlpwithr-141006183806-conversion-gate02/75/Introducing-natural-language-processing-NLP-with-r-25-2048.jpg)


The document provides an introduction to natural language processing (NLP) with R. It outlines topics like foundational NLP frameworks, working with text in R, regular expressions, n-gram models, and morphological analysis. Regular expressions are discussed as a pattern matching device and their theoretical connection to finite state automata. N-gram models are introduced for recognizing and generating language based on the probabilities of word sequences. Morphological analysis is demonstrated through building a lexicon and applying regular expressions to extract agentive nouns.





![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






































































