Downloaded 317 times










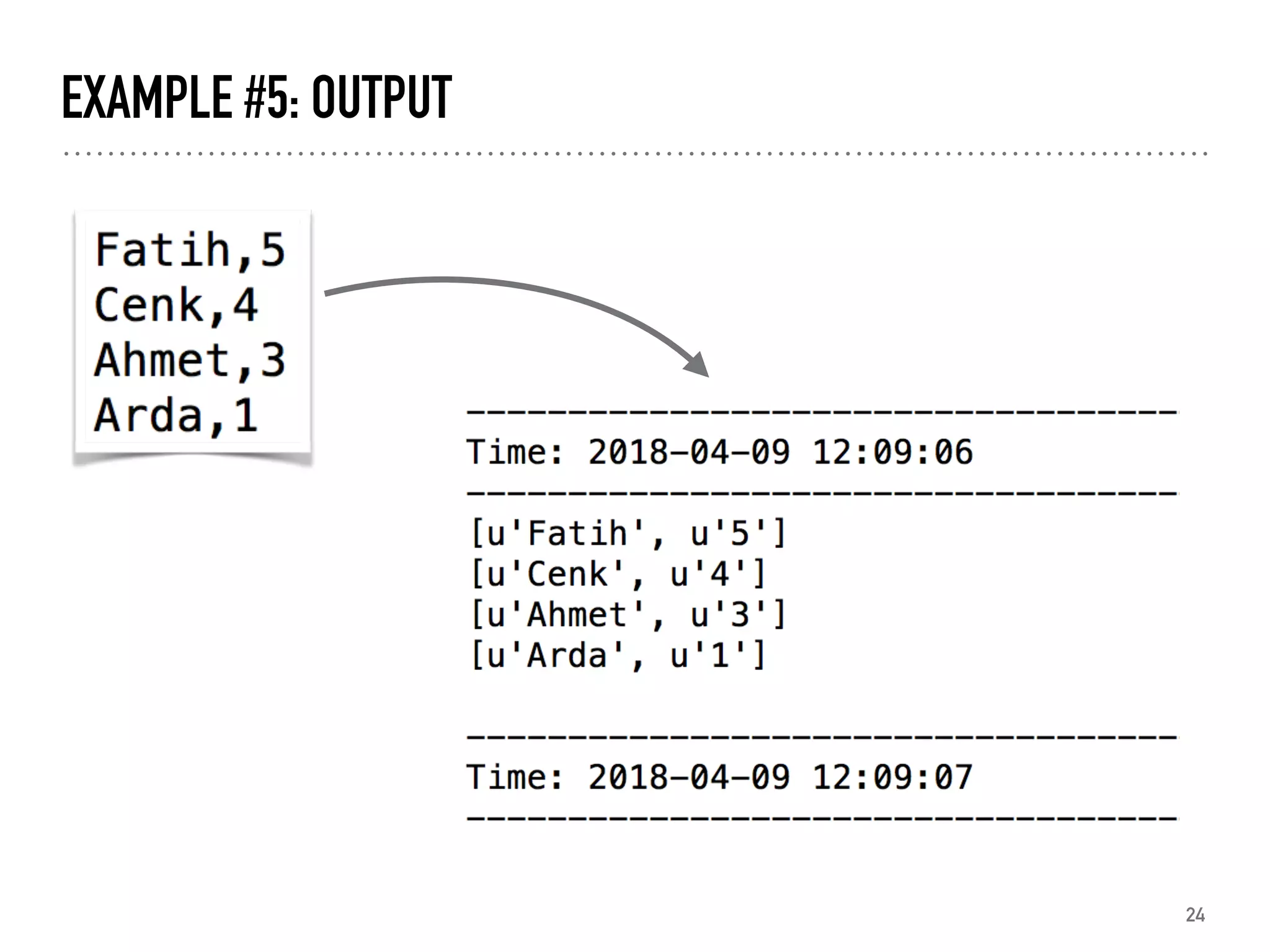
![EXAMPLE #1: USE RDD TO GROUP DATA FROM CSV
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
print sc.textFile( "users.csv" )
.map( lambda x: (x.split("|")[2], 1) )
.reduceByKey(lambda x,y:x+y).collect()
sc.stop()
13
M, 1
M, 1
F, 1
M, 1
[(u'M', 670), (u'F', 273)]](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/85/Introduction-to-Spark-with-Python-13-320.jpg)



![CONVERSION BETWEEN RDD AND DATAFRAME
➤ An RDD can be converted to DataFrame using
createDataFrame or toDF method:
rdd = sc.parallelize([("osman",21),("ahmet",25)])
df = rdd.toDF( "name STRING, age INT" )
df.show()
➤ You can access underlying RDD of a DataFrame using rdd
property:
df.rdd.collect()
[Row(name=u'osman',age=21),Row(name=u'ahmet',age=25)]
19](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/85/Introduction-to-Spark-with-Python-19-320.jpg)





![EXAMPLE #7: GRAPHFRAMES
vertex =
spark.createDataFrame([
(1, "Ahmet"),
(2, "Mehmet"),
(3, "Cengiz"),
(4, "Osman")],
["id", "name"])
edges =
spark.createDataFrame([
( 1, 2, "friend" ),
( 2, 1, "friend" ),
( 2, 3, "friend" ),
( 3, 2, "friend" ),
( 2, 4, "friend" ),
( 4, 2, "friend" ),
( 3, 4, "friend" ),
( 4, 3, "friend" )],
["src","dst", "relation"])
29](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/85/Introduction-to-Spark-with-Python-29-320.jpg)
![EXAMPLE #7: GRAPHFRAMES
pyspark --packages graphframes:graphframes:0.5.0-spark2.1-
s_2.11
import graphframes as gf
g = gf.GraphFrame(vertex, edges)
g.shortestPaths([4]).show()
30
1
2
3
4](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/85/Introduction-to-Spark-with-Python-30-320.jpg)

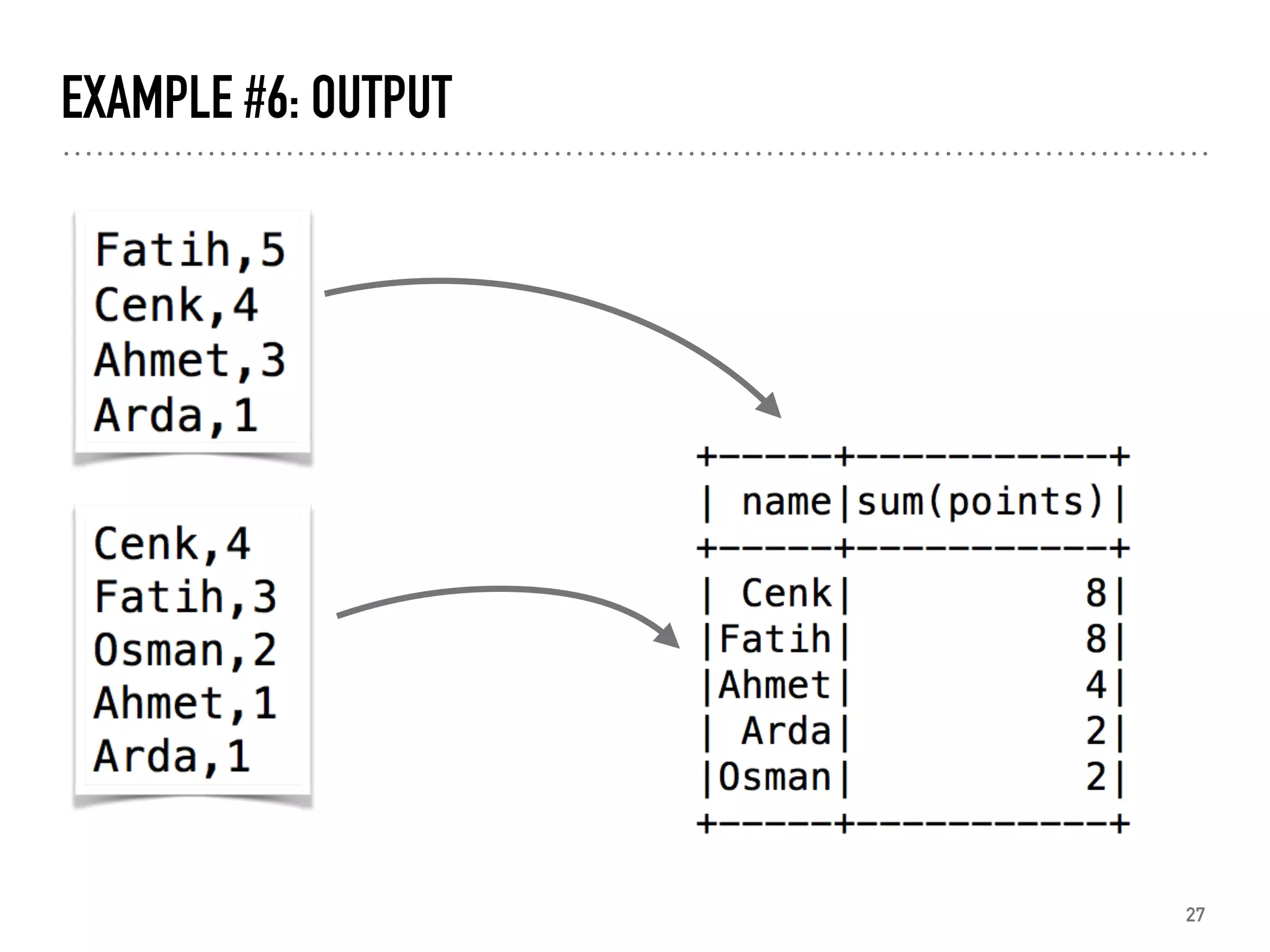
![EXAMPLE #8: ALTERNATING LEAST SQUARES (ALS)
def parseratings( x ):
v = x.split("::")
return (int(v[0]), int(v[1]), float(v[2]))
ratings = sc.textFile("ratings.dat").map(parseratings)
.toDF( ["user", "id", "rating"] )
als = ALS(userCol="user", itemCol="id", ratingCol="rating")
model = als.fit(ratings)
model.recommendForAllUsers(10).show()
32](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/85/Introduction-to-Spark-with-Python-32-320.jpg)











![EXAMPLE #1: USE RDD TO GROUP DATA FROM CSV
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
print sc.textFile( "users.csv" )
.map( lambda x: (x.split("|")[2], 1) )
.reduceByKey(lambda x,y:x+y).collect()
sc.stop()
13
M, 1
M, 1
F, 1
M, 1
[(u'M', 670), (u'F', 273)]](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/75/Introduction-to-Spark-with-Python-13-2048.jpg)

![CONVERSION BETWEEN RDD AND DATAFRAME
➤ An RDD can be converted to DataFrame using
createDataFrame or toDF method:
rdd = sc.parallelize([("osman",21),("ahmet",25)])
df = rdd.toDF( "name STRING, age INT" )
df.show()
➤ You can access underlying RDD of a DataFrame using rdd
property:
df.rdd.collect()
[Row(name=u'osman',age=21),Row(name=u'ahmet',age=25)]
19](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/75/Introduction-to-Spark-with-Python-19-2048.jpg)





![EXAMPLE #7: GRAPHFRAMES
vertex =
spark.createDataFrame([
(1, "Ahmet"),
(2, "Mehmet"),
(3, "Cengiz"),
(4, "Osman")],
["id", "name"])
edges =
spark.createDataFrame([
( 1, 2, "friend" ),
( 2, 1, "friend" ),
( 2, 3, "friend" ),
( 3, 2, "friend" ),
( 2, 4, "friend" ),
( 4, 2, "friend" ),
( 3, 4, "friend" ),
( 4, 3, "friend" )],
["src","dst", "relation"])
29](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/75/Introduction-to-Spark-with-Python-29-2048.jpg)
![EXAMPLE #7: GRAPHFRAMES
pyspark --packages graphframes:graphframes:0.5.0-spark2.1-
s_2.11
import graphframes as gf
g = gf.GraphFrame(vertex, edges)
g.shortestPaths([4]).show()
30
1
2
3
4](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/75/Introduction-to-Spark-with-Python-30-2048.jpg)

![EXAMPLE #8: ALTERNATING LEAST SQUARES (ALS)
def parseratings( x ):
v = x.split("::")
return (int(v[0]), int(v[1]), float(v[2]))
ratings = sc.textFile("ratings.dat").map(parseratings)
.toDF( ["user", "id", "rating"] )
als = ALS(userCol="user", itemCol="id", ratingCol="rating")
model = als.fit(ratings)
model.recommendForAllUsers(10).show()
32](https://image.slidesharecdn.com/introductiontosparkwithpython-bigtalk2-180409184138/75/Introduction-to-Spark-with-Python-32-2048.jpg)



This document provides an introduction and overview of Apache Spark with Python (PySpark). It discusses key Spark concepts like RDDs, DataFrames, Spark SQL, Spark Streaming, GraphX, and MLlib. It includes code examples demonstrating how to work with data using PySpark for each of these concepts.
Introduction of Gökhan Atıl: Database Administrator, Oracle ACE Director, Blogger.
Introduction to Apache Spark, its advantages over Hadoop, and the languages it supports.
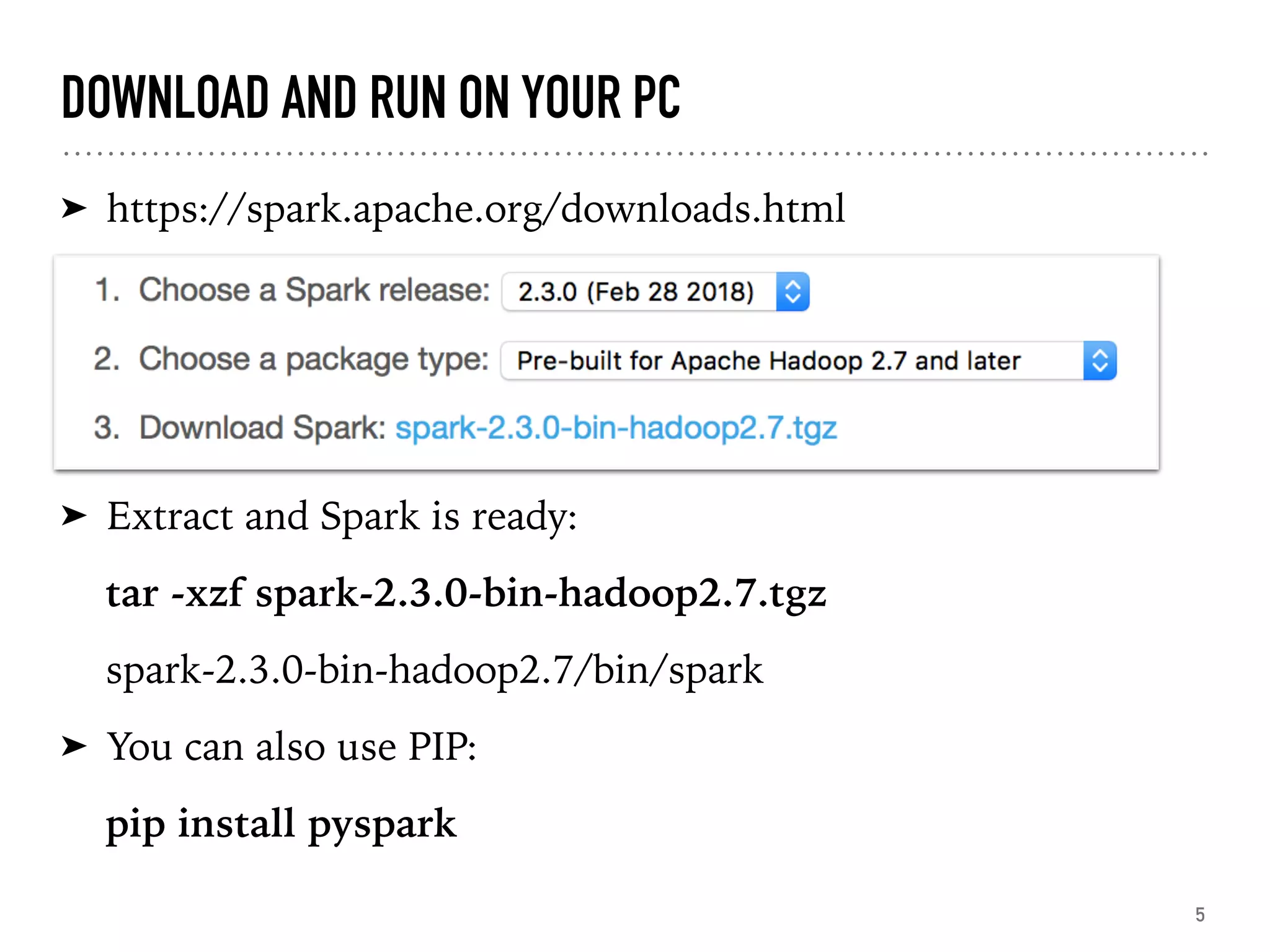
Instructions for downloading and running Apache Spark on a PC, including using PySpark.
Advantages of using Python (PySpark) over Scala, such as ease of use and rich libraries.
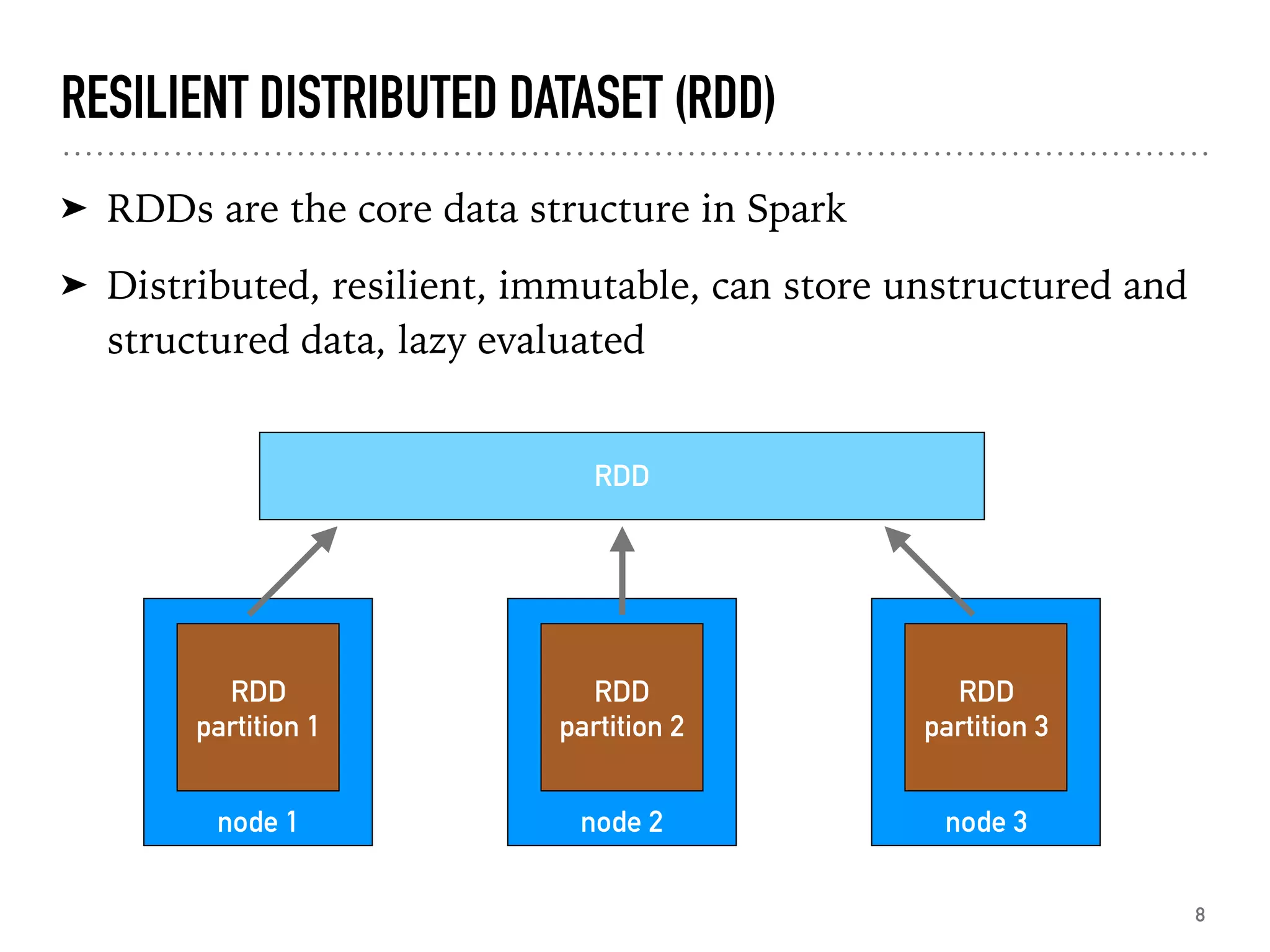
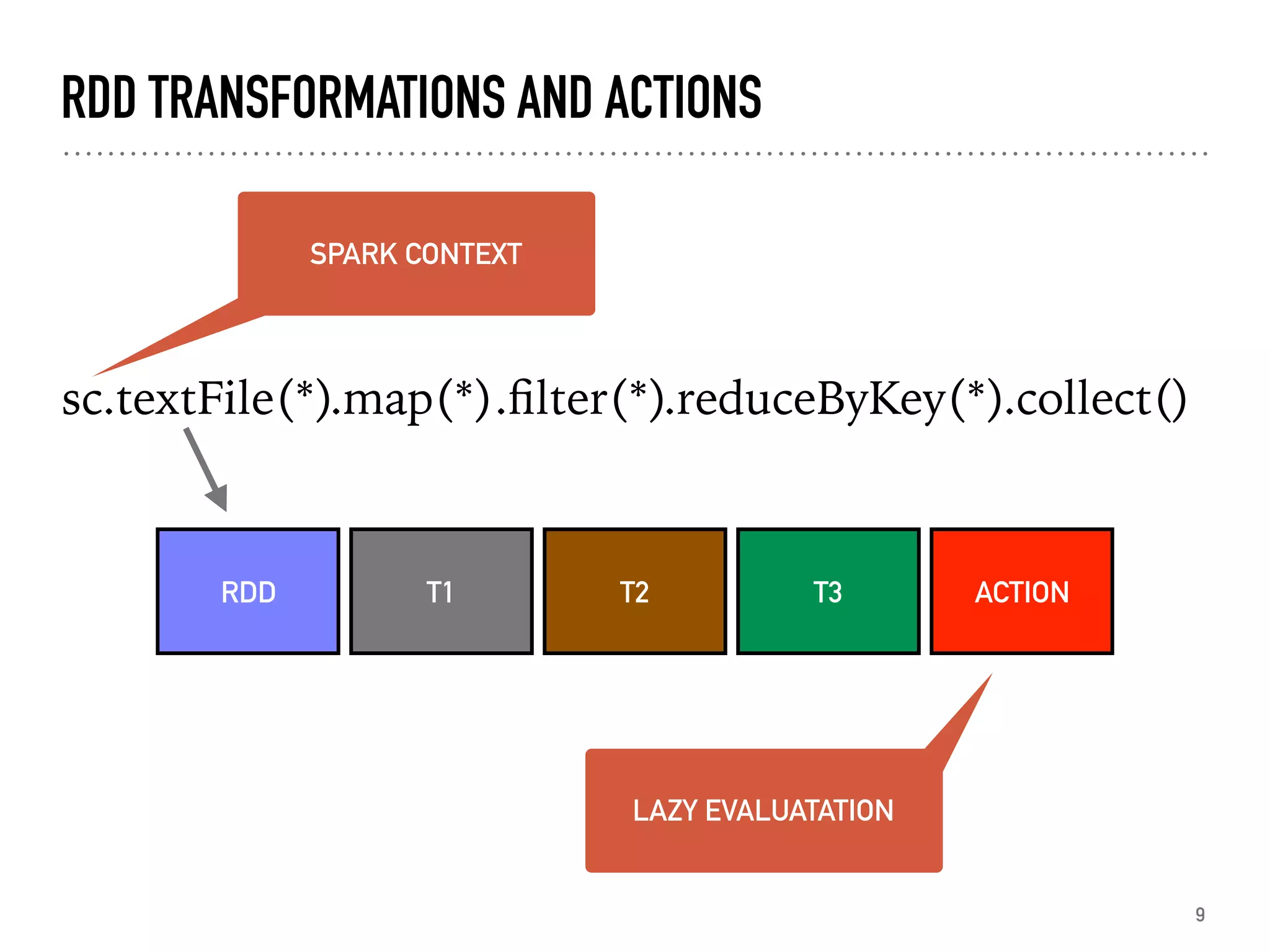
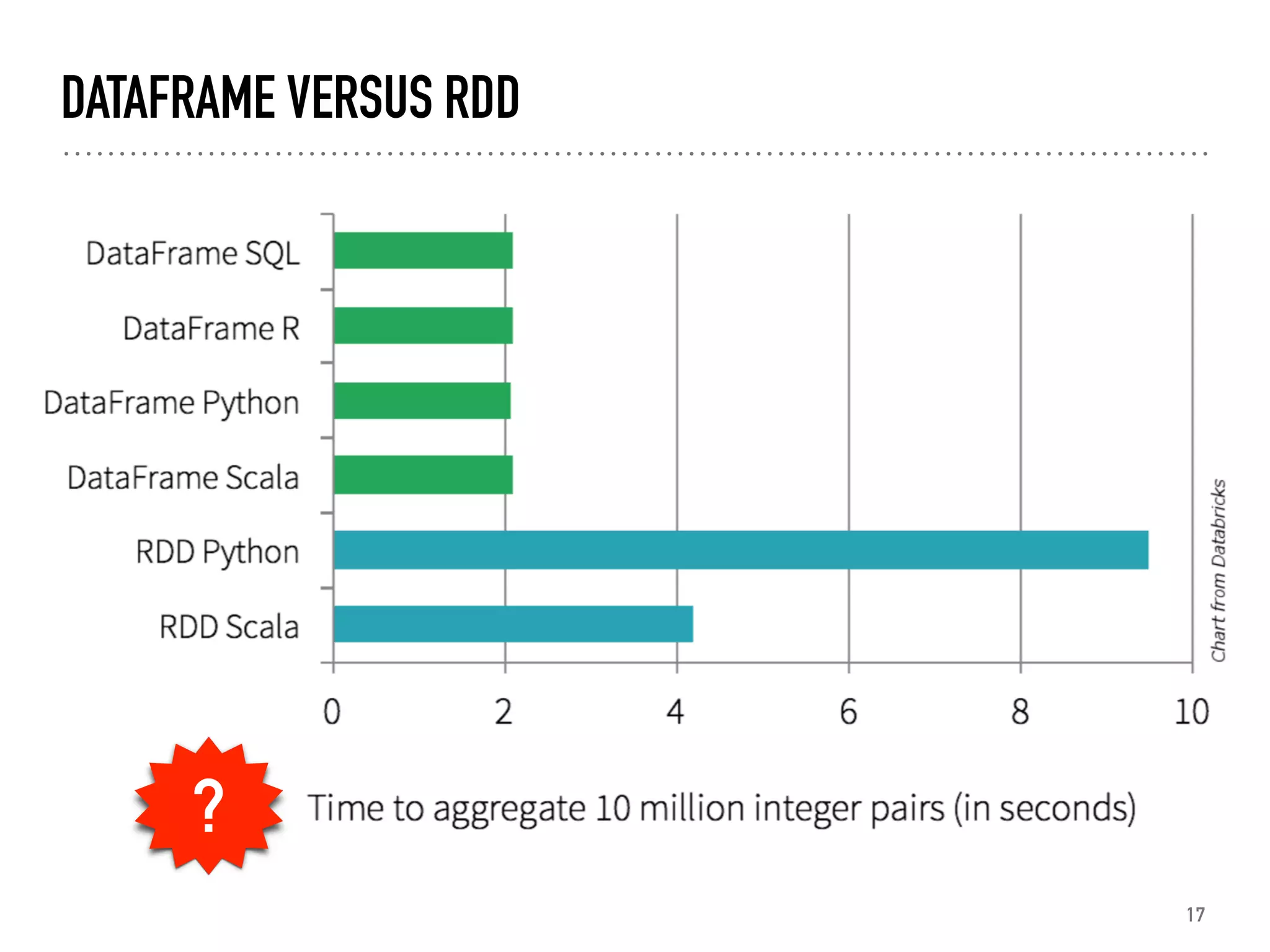
Introduction to RDDs, their characteristics, transformations, and actions.
Different methods to create RDDs in PySpark and an example using users.csv.
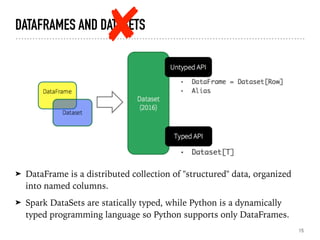
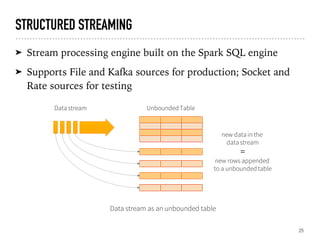
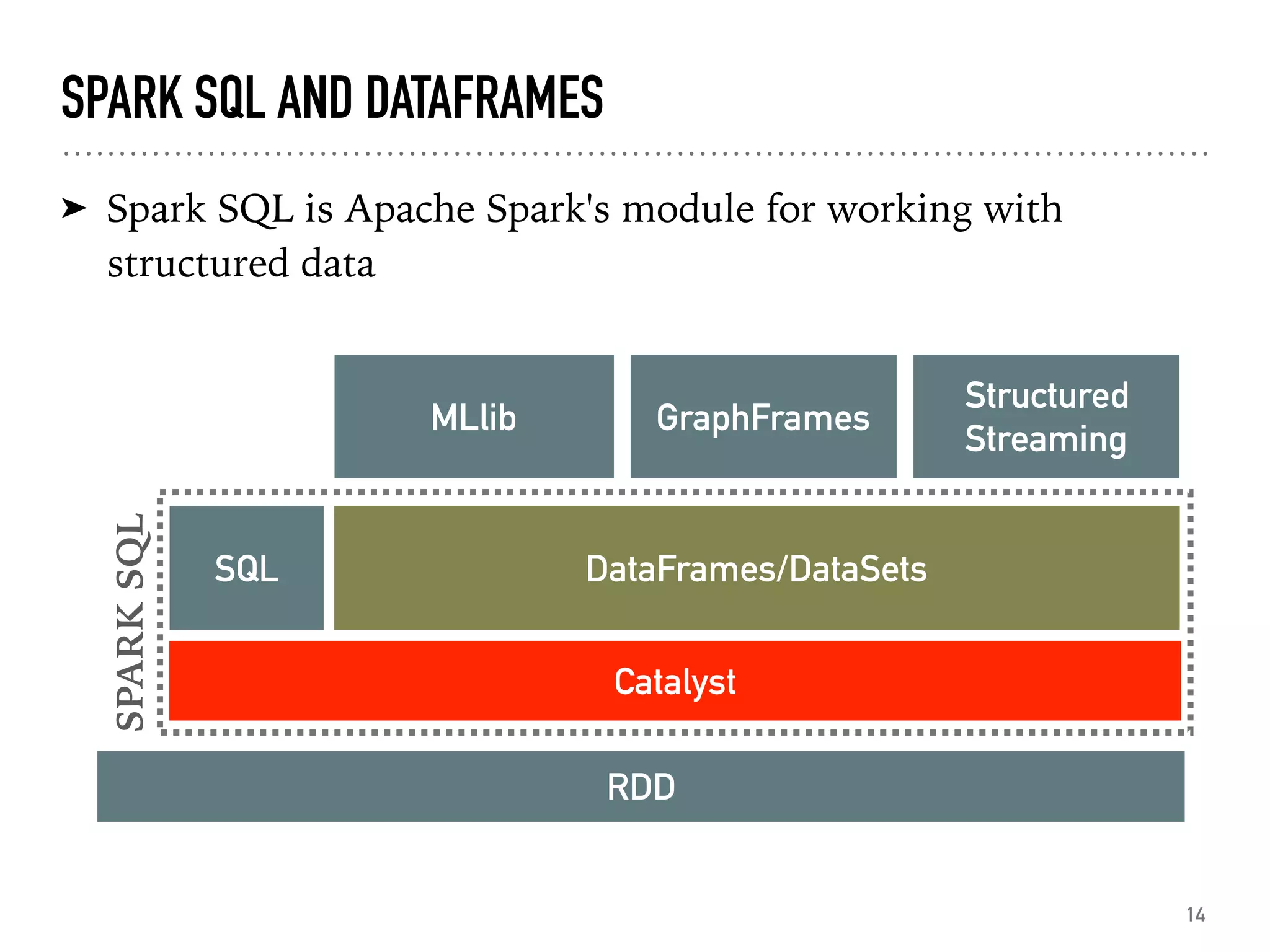
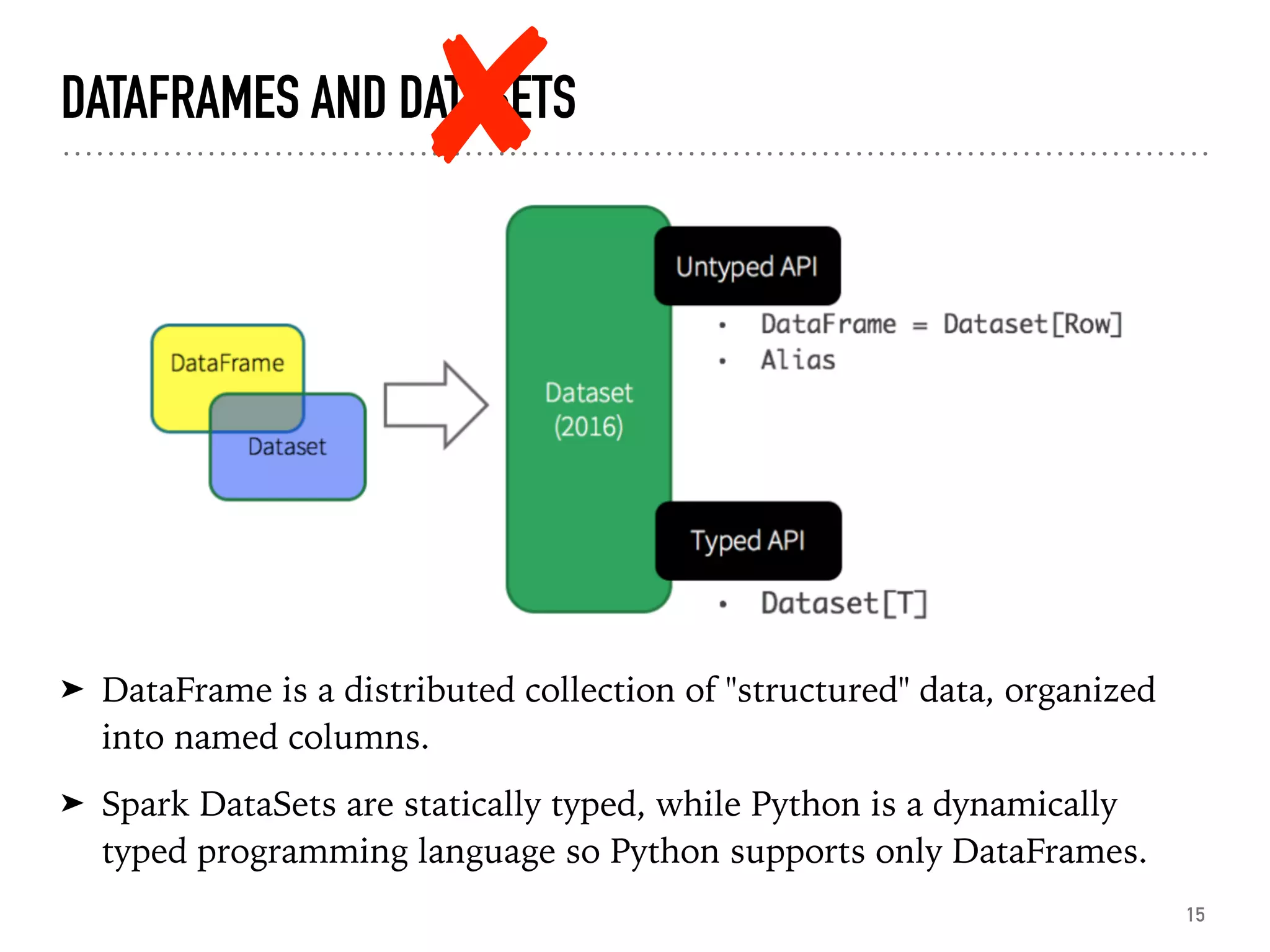
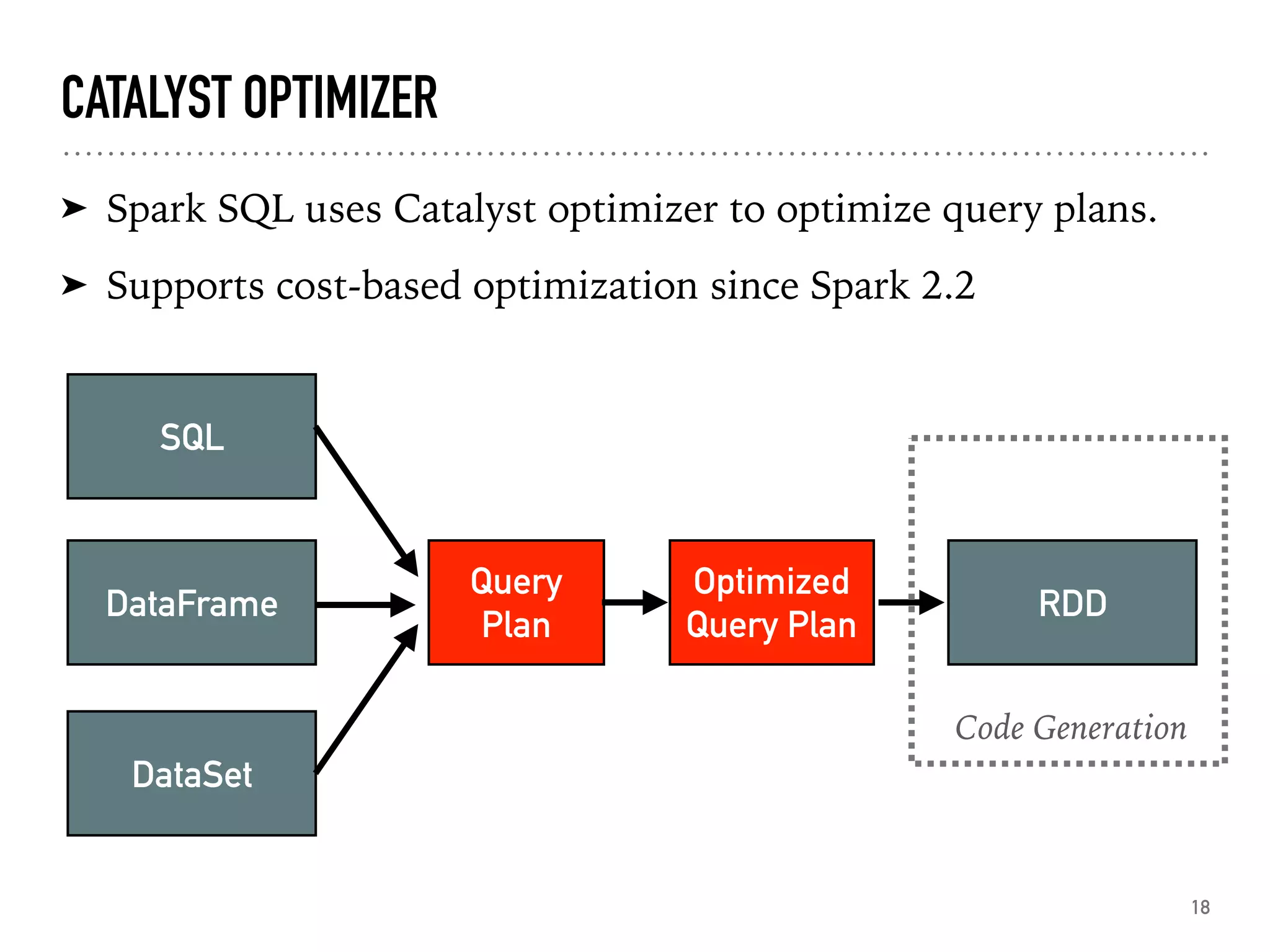
Introduction to Spark SQL, DataFrames, and their structure.
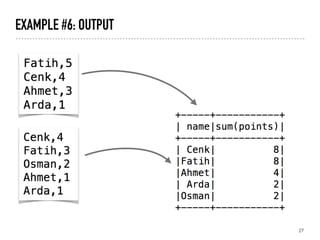
Examples of manipulating CSV data using DataFrames, including grouping and saving data.
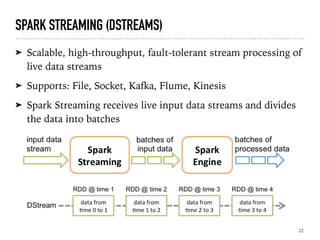
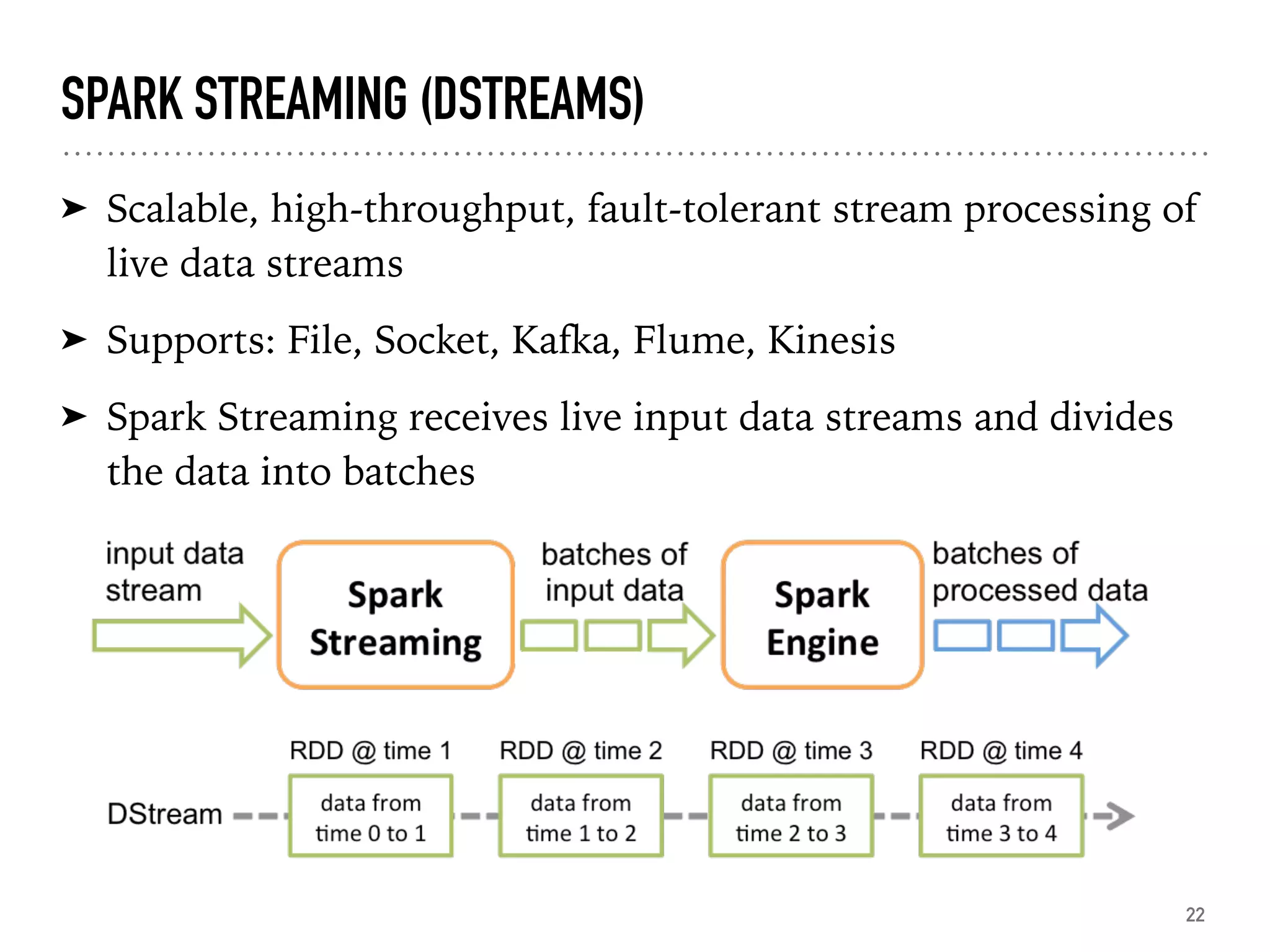
Overview of Spark Streaming, examples of processing live data streams using DStreams.
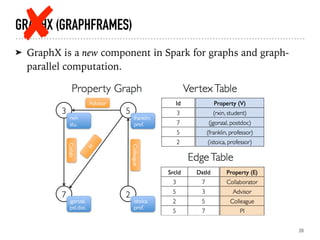
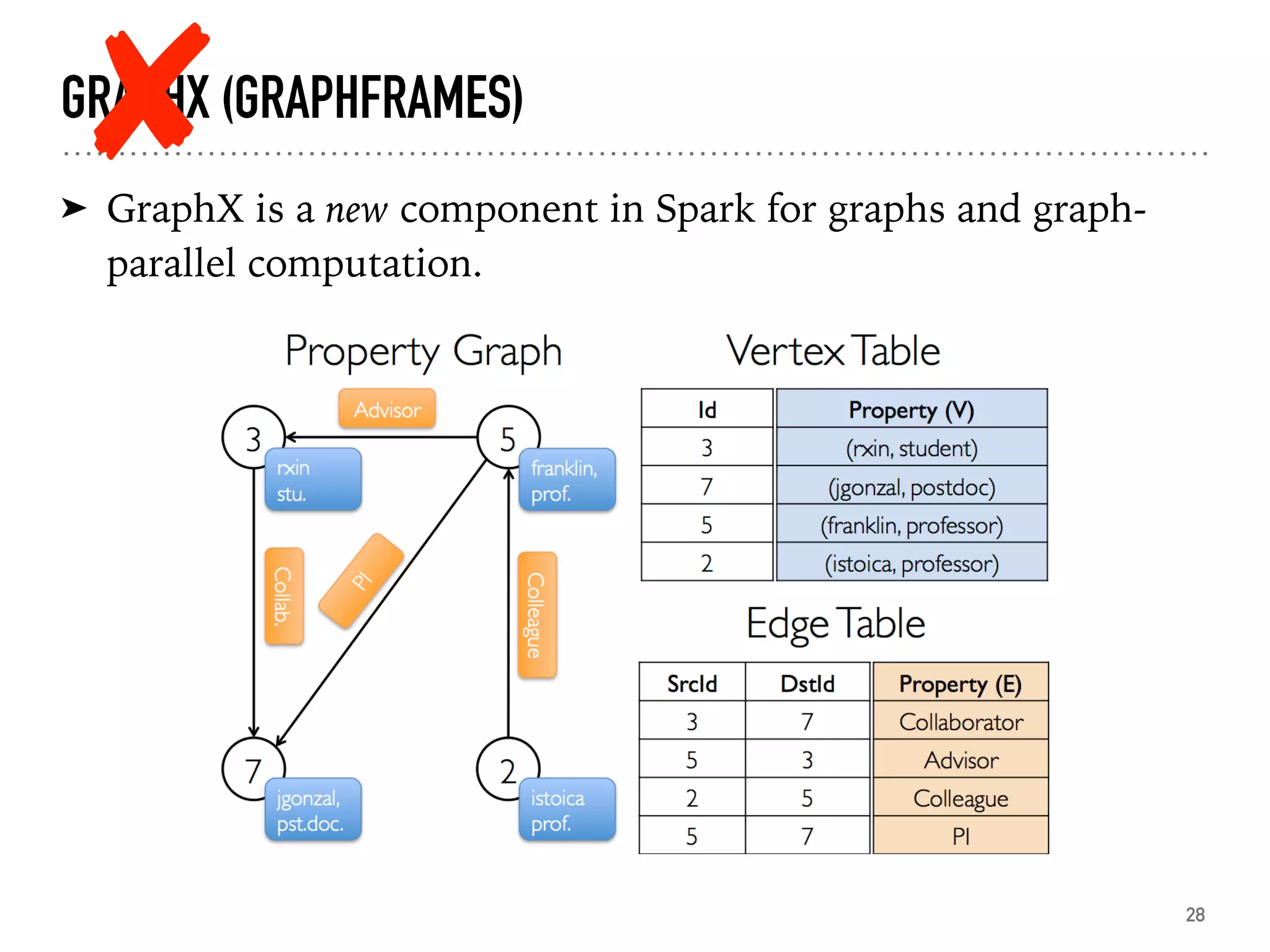
Introduction to GraphX for graph computation and examples of using GraphFrames.
Overview of MLlib, key machine learning algorithms, and an example of the ALS algorithm.
Final slide with contact details for Gökhan Atıl.



































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














































