
Download as PDF, PPTX



















![Stranica 28ISTRA TECHJavaCro 2015 – Java paralelizacija
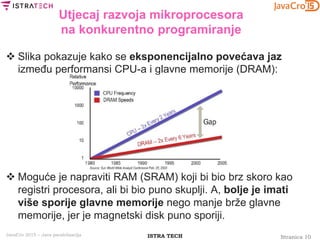
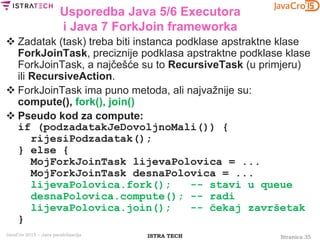
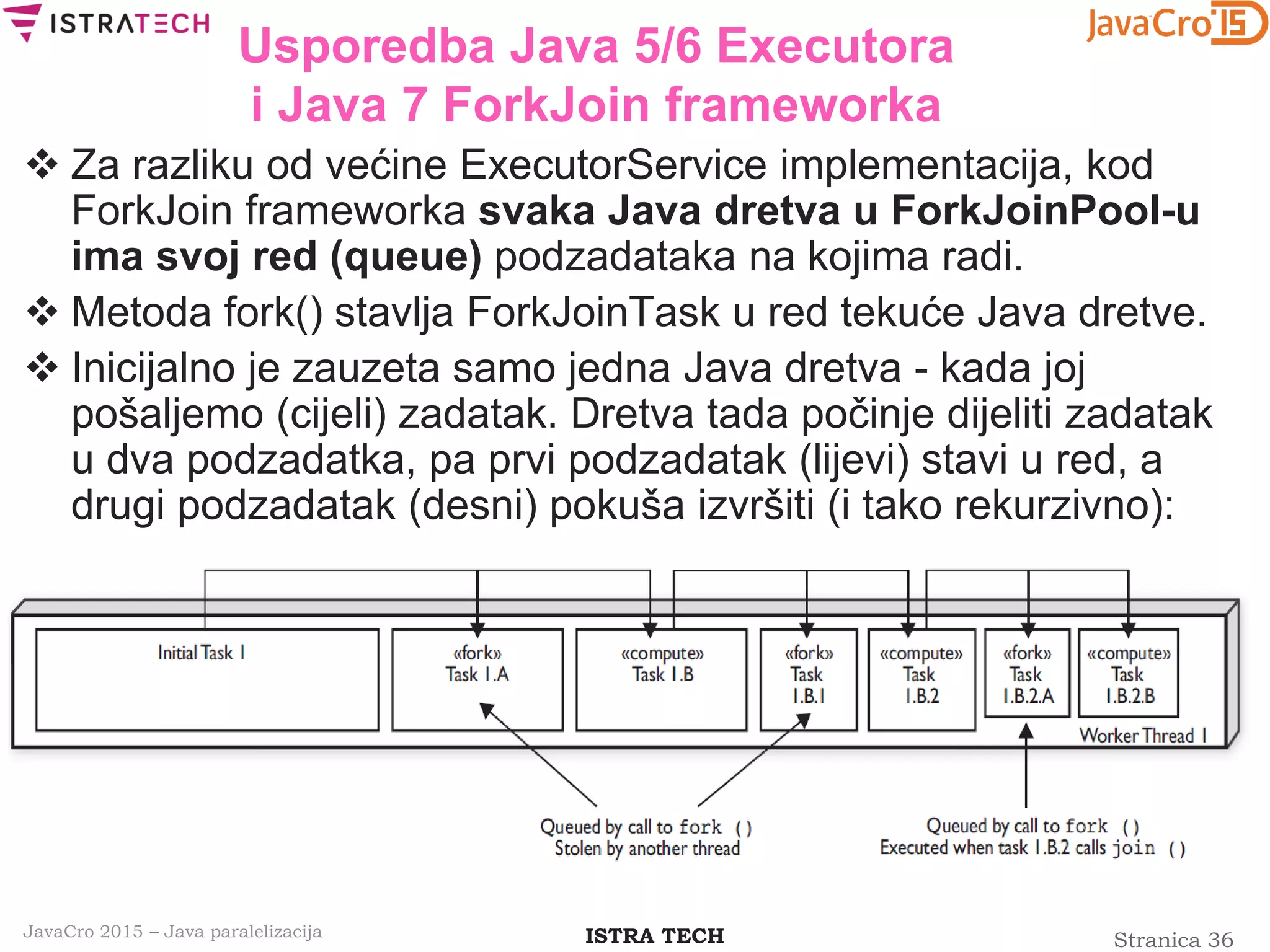
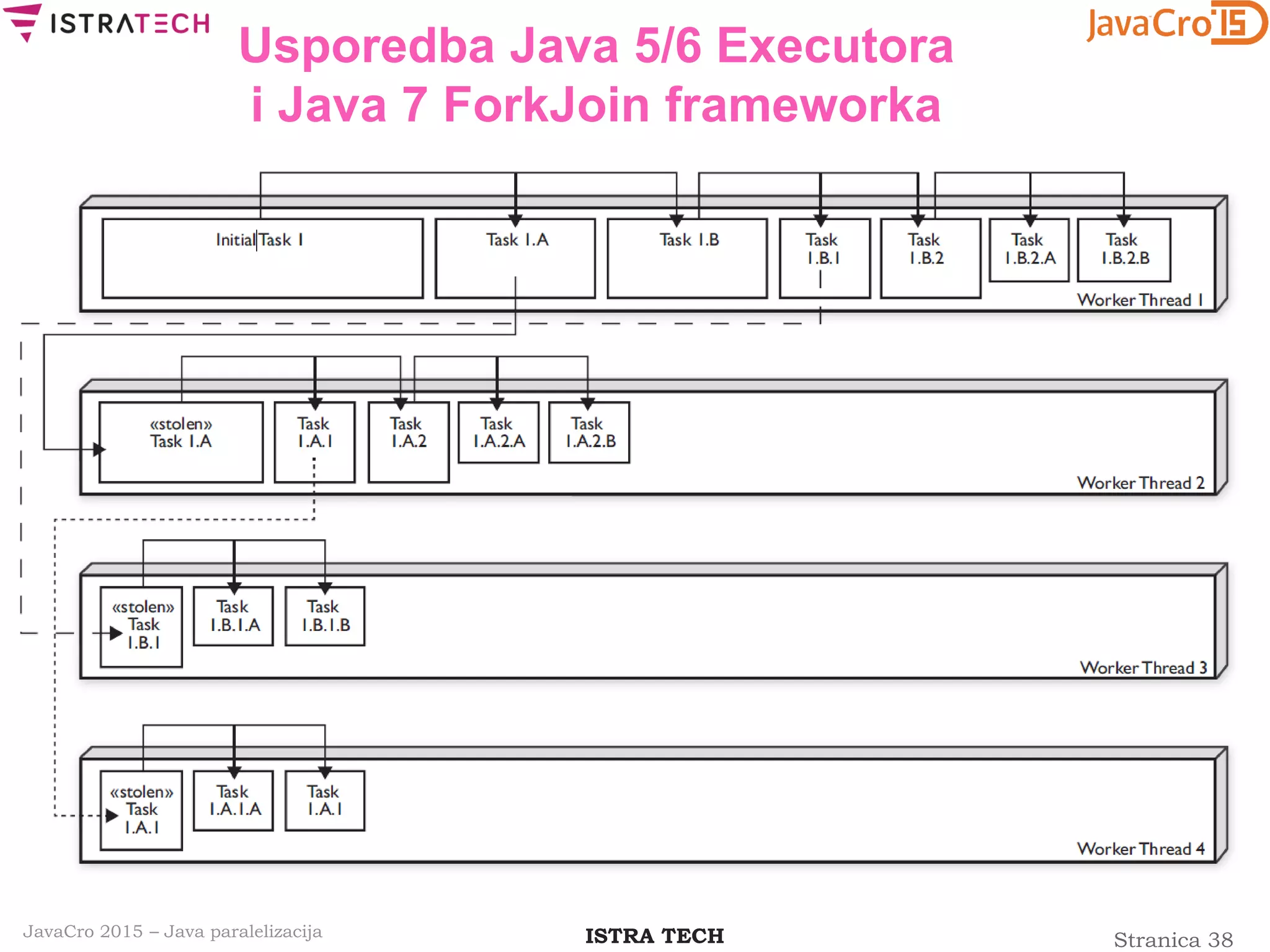
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
import java.util.concurrent.ExecutorService; ...
public class ExecutorPrimeFinder { ...
public static void main(final String[] args) {
if (args.length < 3) {
System.out.println("Usage: number poolSize numberOfParts");
} else {
final int number = Integer.parseInt(args[0]);
final int poolSize = Integer.parseInt(args[1]);
final int numberOfParts = Integer.parseInt(args[2]);
ExecutorPrimeFinder task = new ExecutorPrimeFinder();
final long startTime = System.nanoTime();
final long numberOfPrimes =
task.countPrimes(number, poolSize, numberOfParts);
final long endTime = System.nanoTime();
System.out.printf("Number of primes under %d is %dn",
number, numberOfPrimes, numberOfParts);
System.out.println("Time (seconds) taken is " +
(endTime - startTime) / 1.0e9);
}}}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/85/JavaCro-15-Java-parallelization-Zlatko-Sirotic-28-320.jpg)









![Stranica 41ISTRA TECHJavaCro 2015 – Java paralelizacija
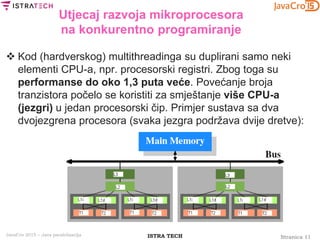
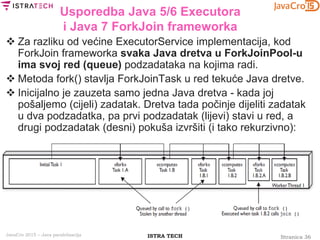
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
import java.util.concurrent.ForkJoinPool;
...
public class ForkJoinPrimeFinderTask
extends RecursiveTask<Integer>
{ private static int threshold;
private int start;
private int end;
public ForkJoinPrimeFinderTask
(final int theStart, final int theEnd)
{ start = theStart; end = theEnd; }
public static void main(final String[] args) {
if (args.length < 1 || args.length > 3) {
System.out.println("Usage: number poolSize threshold
OR number poolSize OR number");
return;
}
...
}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/85/JavaCro-15-Java-parallelization-Zlatko-Sirotic-41-320.jpg)
![Stranica 42ISTRA TECHJavaCro 2015 – Java paralelizacija
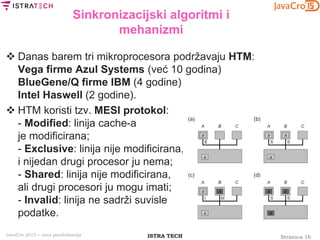
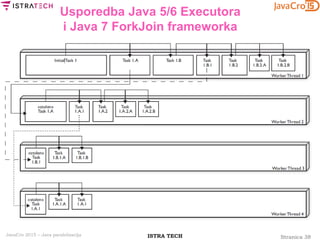
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
public static void main(final String[] args) { ...
final int number = Integer.parseInt(args[0]);
ForkJoinPrimeFinderTask task =
new ForkJoinPrimeFinderTask(1, number);
ForkJoinPool fjPool;
if (args.length == 2 || args.length == 3) {
fjPool = new ForkJoinPool(Integer.parseInt(args[1]));
} else { fjPool = new ForkJoinPool(); }
if (args.length == 3) {
threshold = Integer.parseInt(args[2]);
} else { threshold = 100;
final long startTime = System.nanoTime();
final long numberOfPrimes = fjPool.invoke(task);
final long endTime = System.nanoTime();
System.out.printf("Number of primes under %d is %dn",
number, numberOfPrimes);
System.out.println("Time (seconds) taken is " +
(endTime - startTime) / 1.0e9);
}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/85/JavaCro-15-Java-parallelization-Zlatko-Sirotic-42-320.jpg)









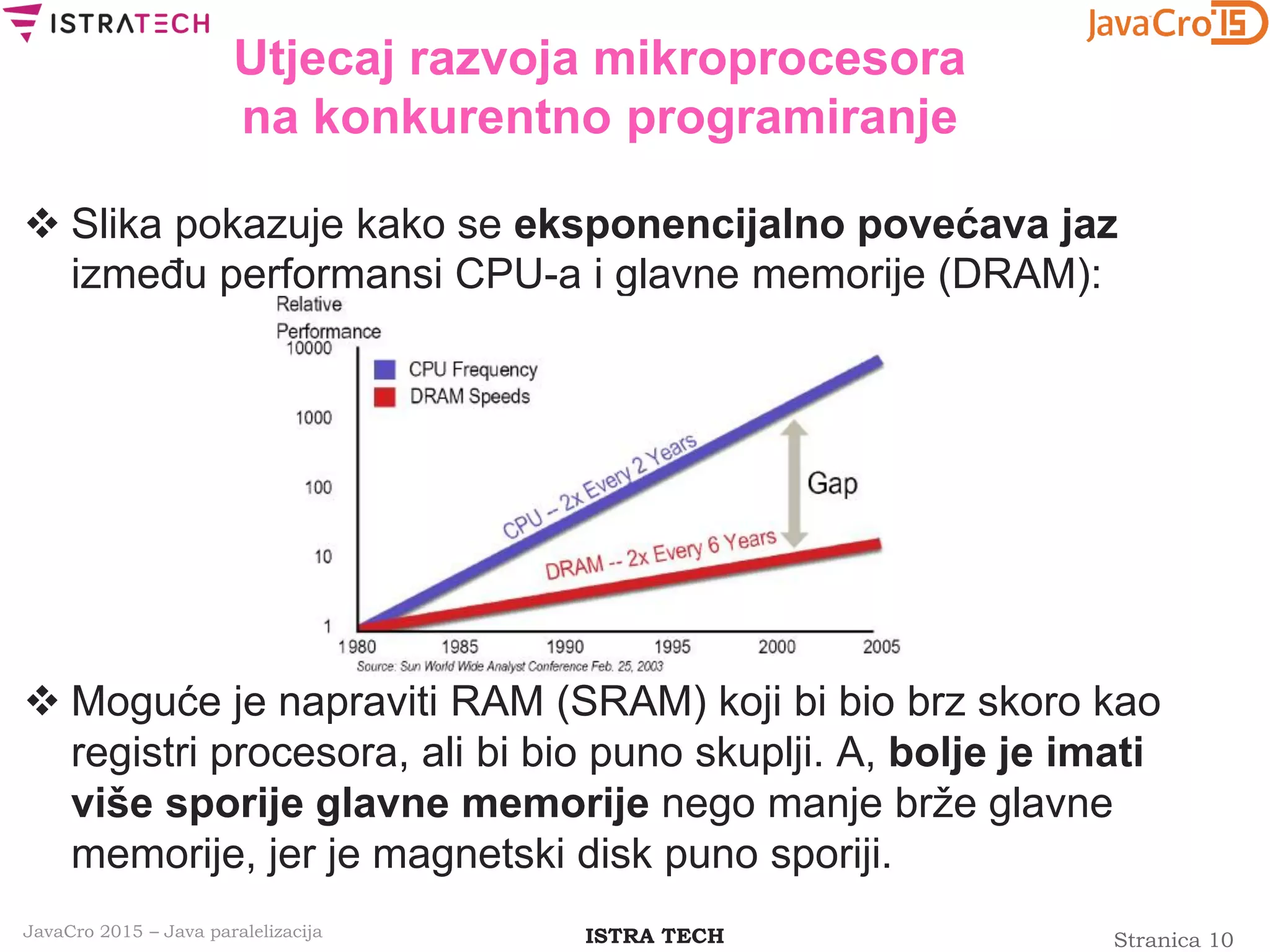
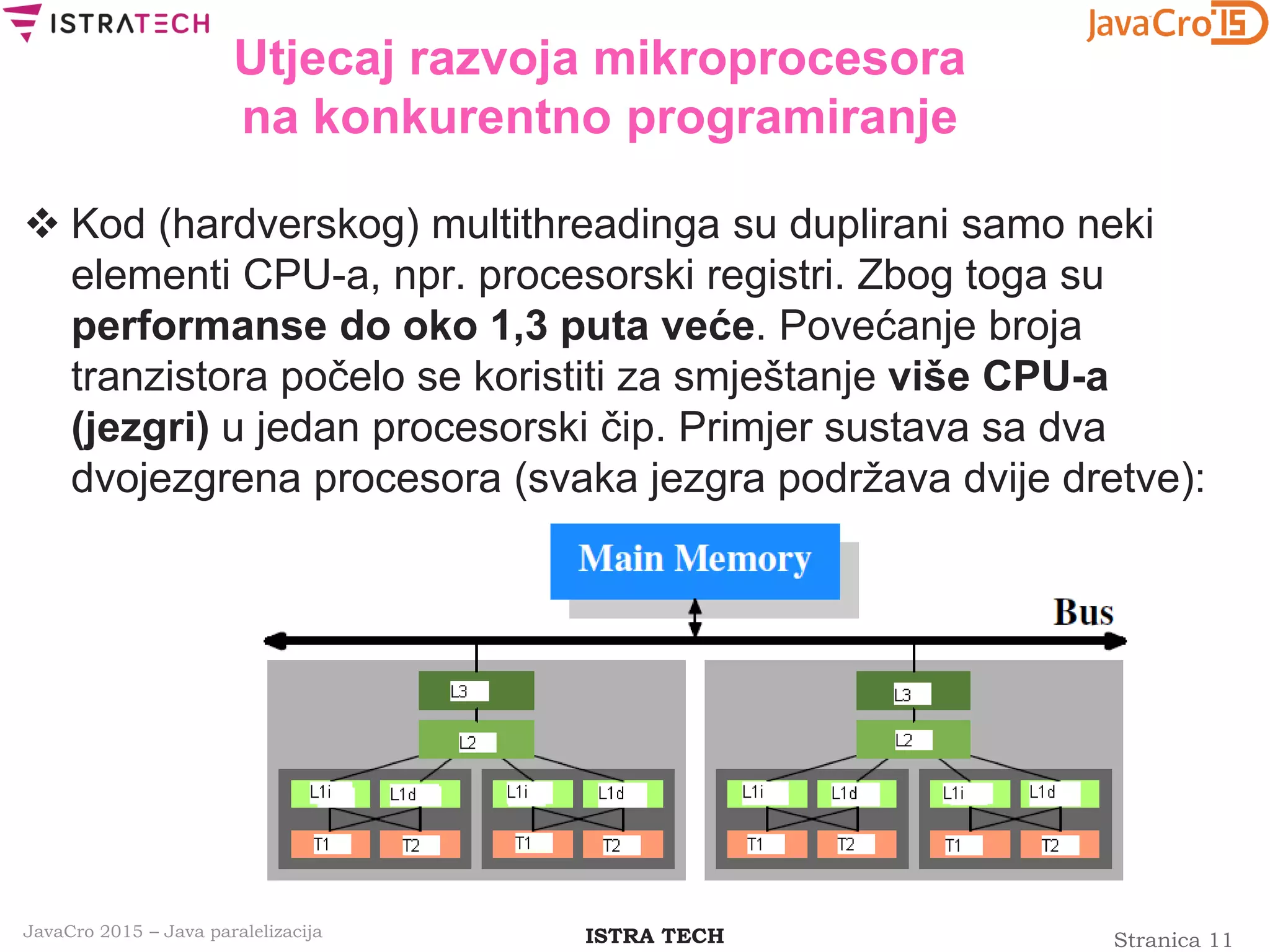




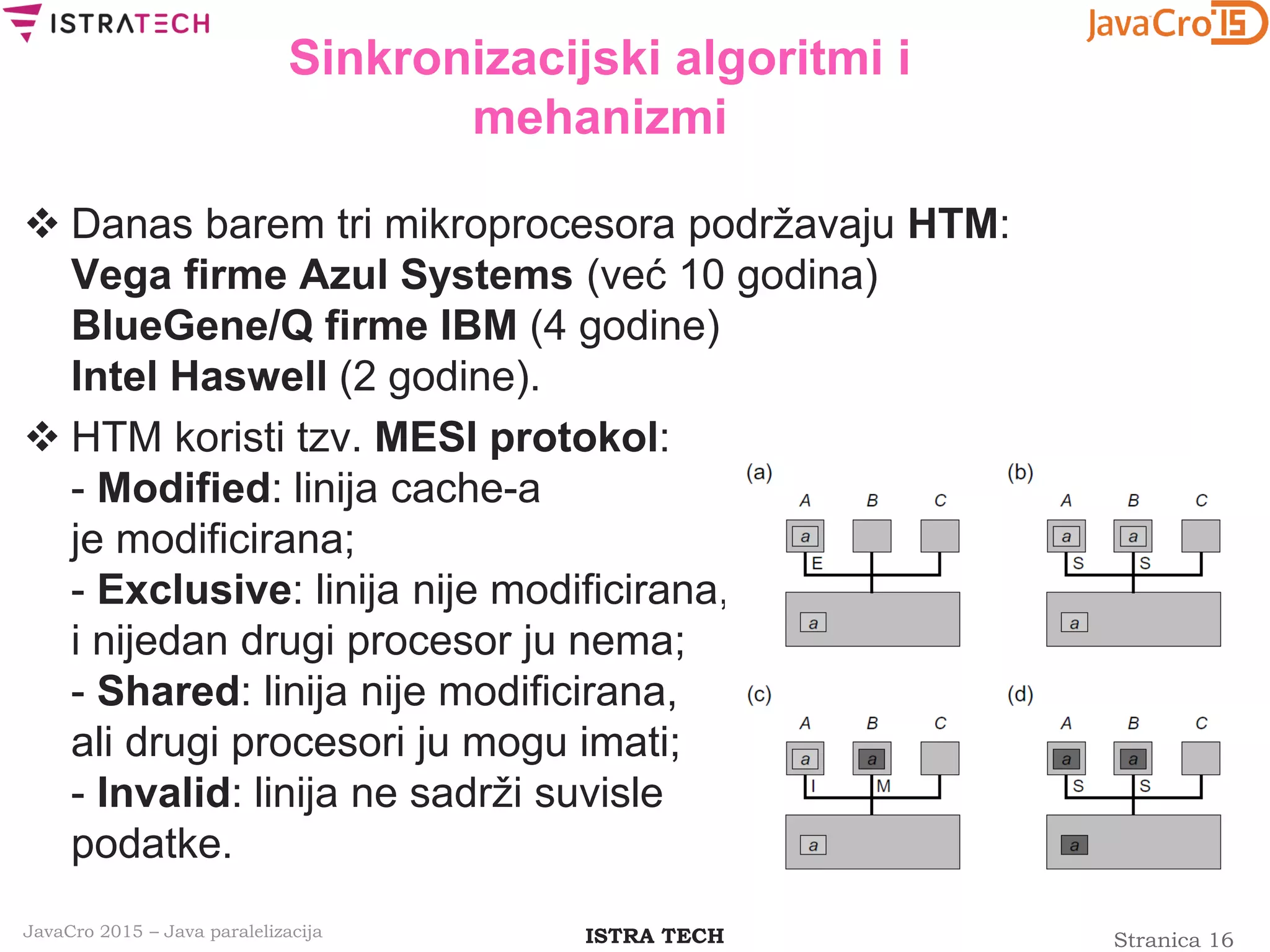










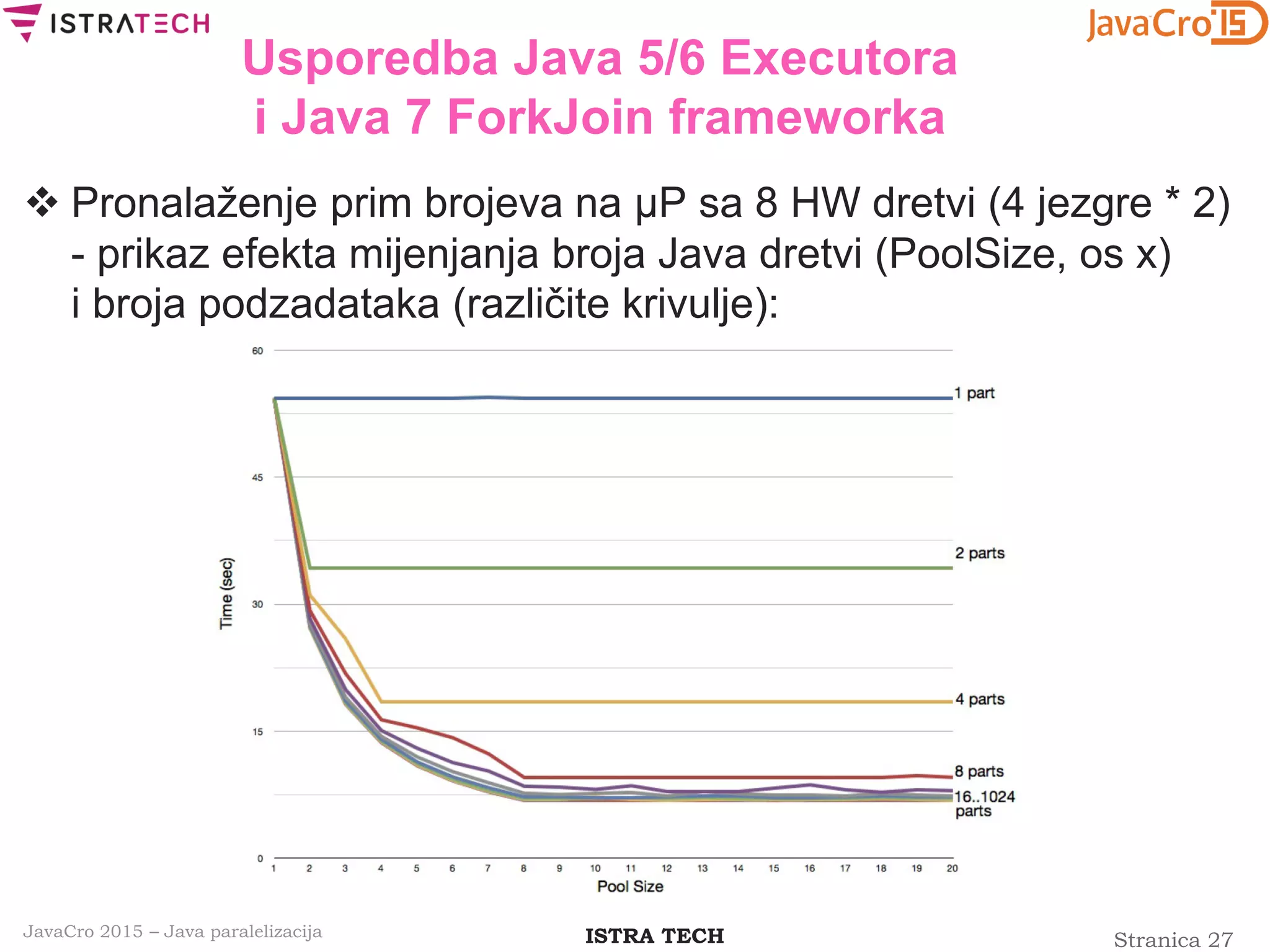
![Stranica 28ISTRA TECHJavaCro 2015 – Java paralelizacija
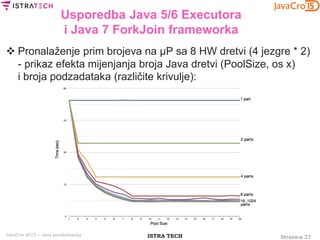
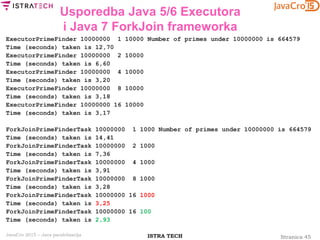
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
import java.util.concurrent.ExecutorService; ...
public class ExecutorPrimeFinder { ...
public static void main(final String[] args) {
if (args.length < 3) {
System.out.println("Usage: number poolSize numberOfParts");
} else {
final int number = Integer.parseInt(args[0]);
final int poolSize = Integer.parseInt(args[1]);
final int numberOfParts = Integer.parseInt(args[2]);
ExecutorPrimeFinder task = new ExecutorPrimeFinder();
final long startTime = System.nanoTime();
final long numberOfPrimes =
task.countPrimes(number, poolSize, numberOfParts);
final long endTime = System.nanoTime();
System.out.printf("Number of primes under %d is %dn",
number, numberOfPrimes, numberOfParts);
System.out.println("Time (seconds) taken is " +
(endTime - startTime) / 1.0e9);
}}}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/75/JavaCro-15-Java-parallelization-Zlatko-Sirotic-28-2048.jpg)










![Stranica 41ISTRA TECHJavaCro 2015 – Java paralelizacija
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
import java.util.concurrent.ForkJoinPool;
...
public class ForkJoinPrimeFinderTask
extends RecursiveTask<Integer>
{ private static int threshold;
private int start;
private int end;
public ForkJoinPrimeFinderTask
(final int theStart, final int theEnd)
{ start = theStart; end = theEnd; }
public static void main(final String[] args) {
if (args.length < 1 || args.length > 3) {
System.out.println("Usage: number poolSize threshold
OR number poolSize OR number");
return;
}
...
}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/75/JavaCro-15-Java-parallelization-Zlatko-Sirotic-41-2048.jpg)
![Stranica 42ISTRA TECHJavaCro 2015 – Java paralelizacija
Usporedba Java 5/6 Executora
i Java 7 ForkJoin frameworka
public static void main(final String[] args) { ...
final int number = Integer.parseInt(args[0]);
ForkJoinPrimeFinderTask task =
new ForkJoinPrimeFinderTask(1, number);
ForkJoinPool fjPool;
if (args.length == 2 || args.length == 3) {
fjPool = new ForkJoinPool(Integer.parseInt(args[1]));
} else { fjPool = new ForkJoinPool(); }
if (args.length == 3) {
threshold = Integer.parseInt(args[2]);
} else { threshold = 100;
final long startTime = System.nanoTime();
final long numberOfPrimes = fjPool.invoke(task);
final long endTime = System.nanoTime();
System.out.printf("Number of primes under %d is %dn",
number, numberOfPrimes);
System.out.println("Time (seconds) taken is " +
(endTime - startTime) / 1.0e9);
}](https://image.slidesharecdn.com/javacro15-javaparallelization-zlatkosiroti-150520122326-lva1-app6891/75/JavaCro-15-Java-parallelization-Zlatko-Sirotic-42-2048.jpg)





Dokument se bavi temom konkurentnog programiranja u Javi, ističući važnost paralelizacije zbog višejezgrenih procesora. Razmatra se utjecaj razvoja mikroprocesora i sinkronizacijskih mehanizama na izvedbu konkurenata programa. Također, obrađene su novine u različitim verzijama Jave, uključujući izvršne okvire i lambda izraze, te se provodi usporedba metoda izvršavanja zadataka.

































